
機械学習用のKNN分類器:知っておくべきことすべて
公開: 2021-09-28人工知能(AI)がSF小説や映画に限定された概念にすぎなかった時代を覚えていますか? さて、技術の進歩のおかげで、AIは私たちが現在毎日生きているものです。 AlexaとSiriが私たちの手元にいて、OTTプラットフォームに私たちが見たい映画を「厳選」するよう呼びかけていることから、AIはほぼ今日の秩序になり、予見可能な将来のためにここにあります。
これはすべて、高度なMLアルゴリズムのおかげで可能です。 今日は、そのような便利なMLアルゴリズムの1つであるK-NN分類器について説明します。
AIとコンピューターサイエンスの分野である機械学習は、データとアルゴリズムを使用して人間の理解を模倣し、アルゴリズムの精度を徐々に向上させます。 機械学習には、予測や分類を行うためのアルゴリズムのトレーニングと、ビジネスやアプリケーション内での戦略的な意思決定を促進する重要な洞察の発掘が含まれます。
KNN(k最近傍)アルゴリズムは、回帰および分類の問題ステートメントを解決するために使用される基本的な教師あり機械学習アルゴリズムです。 それでは、K-NN分類器について詳しく見ていきましょう。
目次
教師あり機械学習と教師なし機械学習
教師あり学習と教師なし学習は、2つの基本的なデータサイエンスアプローチであり、KNNの詳細に入る前に違いを知ることが適切です。
教師あり学習は、ラベル付けされたデータセットを使用して結果を予測する機械学習アプローチです。 このようなデータセットは、アルゴリズムを「監視」またはトレーニングして、結果を予測したり、データを正確に分類したりするように設計されています。 したがって、ラベル付けされた入力と出力により、モデルは精度を向上させながら時間の経過とともに学習することができます。

教師あり学習には、分類と回帰の2種類の問題があります。 分類問題では、アルゴリズムがテストデータを個別のカテゴリに割り当てます。たとえば、猫と犬を区別します。
重要な実際の例は、スパムメールを受信トレイとは別のフォルダに分類することです。 一方、教師あり学習の回帰法は、独立変数と従属変数の関係を理解するためのアルゴリズムをトレーニングします。 さまざまなデータポイントを使用して、ビジネスの売上高の予測などの数値を予測します。
反対に、教師なし学習では、ラベルのないデータセットの分析とクラスタリングに機械学習アルゴリズムを使用します。 したがって、アルゴリズムがデータ内の隠れたパターンを識別するために人間の介入(「教師なし」)を行う必要はありません。
教師なし学習モデルには、関連付け、クラスタリング、次元削減の3つの主要なアプリケーションがあります。 ただし、説明の範囲を超えているため、詳細については説明しません。
K最近傍法(KNN)
K最近傍法またはKNNアルゴリズムは、教師あり学習モデルに基づく機械学習アルゴリズムです。 K-NNアルゴリズムは、類似したものが互いに近くに存在することを前提として機能します。 したがって、K-NNアルゴリズムは、新しいデータポイントとトレーニングセット内のポイント(利用可能なケース)の間の特徴の類似性を利用して、新しいデータポイントの値を予測します。 本質的に、K-NNアルゴリズムは、トレーニングセット内のポイントにどれだけ類似しているかに基づいて、最新のデータポイントに値を割り当てます。 K-NNアルゴリズムは、分類問題と回帰問題の両方に適用されますが、主に分類問題に使用されます。
K-NN分類器を理解するための例を次に示します。

ソース
上の画像では、入力値は猫と犬の両方に類似している生き物です。 ただし、猫と犬のどちらかに分類したいと思います。 したがって、この分類にはK-NNアルゴリズムを使用できます。 K-NNモデルは、利用可能な猫と犬の画像(トレーニングデータセット)に対する新しいデータセット(入力)間の類似点を見つけます。 その後、モデルは、最も類似した機能に基づいて、猫または犬のカテゴリに新しいデータポイントを配置します。
同様に、カテゴリA(緑色の点)とカテゴリB(オレンジ色の点)には、上記の図の例があります。 また、いずれかのカテゴリに分類される新しいデータポイント(青い点)があります。 K-NNアルゴリズムを使用してこの分類問題を解決し、新しいデータポイントカテゴリを特定できます。
K-NNアルゴリズムのプロパティの定義
次の2つのプロパティは、K-NNアルゴリズムを最もよく定義します。
- K-NNアルゴリズムは、トレーニングセットからすぐに学習するのではなく、データセットを保存し、分類時にデータセットからトレーニングするため、怠惰な学習アルゴリズムです。
- K-NNもノンパラメトリックアルゴリズムであり、基礎となるデータについて何も仮定していません。
K-NNアルゴリズムの動作
それでは、K-NNアルゴリズムがどのように機能するかを理解するために、次の手順を見てみましょう。
ステップ1:トレーニングデータとテストデータを読み込みます。
ステップ2:最も近いデータポイント、つまりKの値を選択します。
ステップ3: K個の近傍の距離(トレーニングデータとテストデータの各行の間の距離)を計算します。 ユークリッド法は、距離の計算に最も一般的に使用されます。
ステップ4:計算されたユークリッド距離に基づいてK最近傍を取ります。
ステップ5:最も近いK近傍の中で、各カテゴリのデータポイントの数を数えます。
ステップ6:ネイバーの数が最大であるカテゴリに新しいデータポイントを割り当てます。
ステップ7:終了します。 これでモデルの準備が整いました。
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインで人工知能コースに参加して、キャリアを早急に進めましょう。
Kの値の選択
Kは、K-NNアルゴリズムの重要なパラメーターです。 したがって、Kの値を決定する前に、いくつかの点に留意する必要があります。
エラー曲線の使用は、Kの値を決定するための一般的な方法です。次の画像は、テストおよびトレーニングデータのさまざまなK値のエラー曲線を示しています。


ソース
上記のグラフの例では、ポイントに最も近い隣接点がそのポイント自体であるため、トレーニングデータのK=1でトレインエラーはゼロです。 ただし、Kの値が低い場合でも、テストエラーは高くなります。これは、高分散またはデータの過剰適合と呼ばれます。 Kの値を大きくすると、テストエラーは減少しますが、Kの特定の値を超えると、バイアスまたはアンダーフィッティングと呼ばれるテストエラーが再び増加することがわかります。 したがって、テストデータの誤差は分散のために最初は高く、その後低下して安定し、Kの値がさらに増加すると、バイアスのためにテスト誤差が再び増加します。
したがって、テスト誤差が安定して低くなるKの値をKの最適値とします。上記の誤差曲線を考慮すると、K=8が最適値です。
K-NNアルゴリズムの動作を理解するための例
次のようにプロットされたデータセットについて考えてみます。

ソース
(60,60)に新しいデータポイント(黒い点)があり、紫または赤のクラスに分類する必要があるとします。 K = 3を使用します。これは、新しいデータポイントが3つの最も近いデータポイントを検出することを意味します。2つは赤のクラスで、1つは紫のクラスです。
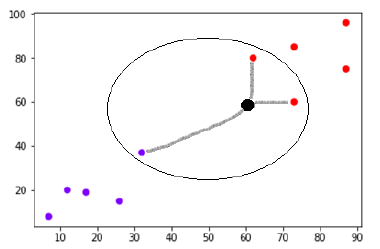
ソース
最も近い近傍は、2点間のユークリッド距離を計算することによって決定されます。 これは、計算がどのように行われるかを示す図です。

ソース
これで、新しいデータポイント(黒い点)の最も近い2つ(3つのうち)が赤いクラスにあるため、新しいデータポイントも赤いクラスに割り当てられます。
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインで機械学習コースに参加して、キャリアを早急に進めましょう。
分類子としてのK-NN(Pythonでの実装)
K-NNアルゴリズムの簡単な説明ができたので、PythonでK-NNアルゴリズムを実装してみましょう。 K-NN分類器のみに焦点を当てます。
ステップ1:必要なPythonパッケージをインポートします。

ソース
ステップ2: UCI MachineLearningRepositoryからアイリスデータセットをダウンロードします。 そのウェブリンクは「https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data」です。
ステップ3:データセットに列名を割り当てます。

ソース
ステップ4:データセットをPandasDataFrameに読み込みます。

ソース
ステップ5:データの前処理は、次のスクリプト行を使用して実行されます。

ソース
ステップ6:データセットをテスト分割とトレーニング分割に分割します。 以下のコードは、データセットを40%のテストデータと60%のトレーニングデータに分割します。

ソース
ステップ7:データのスケーリングは次のように行われます。

ソース
ステップ8: sklearnのKNeighborsClassifierクラスを使用してモデルをトレーニングします。

ソース
ステップ9:次のスクリプトを使用して予測を行います。

ソース
ステップ10:結果を印刷します。

ソース
出力:

ソース
次は何? IITマドラスとupGradからの機械学習の高度な証明書プログラムへのサインアップ
熟練したデータサイエンティストまたは機械学習の専門家になりたいと考えているとします。 その場合、 IITマドラスとupGradの機械学習とクラウドの上級認定コースはあなたにぴったりです!
12か月のオンラインプログラムは、機械学習、ビッグデータ処理、データ管理、データウェアハウジング、クラウド、機械学習モデルの導入の概念を習得しようとしている専門家向けに特別に設計されています。
プログラムが提供するものをよりよく理解するためのコースのハイライトは次のとおりです。
- IITマドラスから世界的に認められた権威ある認証
- 500時間以上の学習、20以上のケーススタディとプロジェクト、25以上の業界メンターシップセッション、8以上のコーディング割り当て
- 7つのプログラミング言語とツールを包括的にカバー
- 4週間の業界キャップストーンプロジェクト
- 実践的な実践的なワークショップ
- オフラインのピアツーピアネットワーキング
プログラムの詳細については、今すぐ登録してください。
結論
時間とともに、ビッグデータは成長を続け、人工知能はますます私たちの生活と絡み合うようになります。 その結果、機械学習モデルの力を活用してデータの洞察を収集し、重要なビジネスプロセス、そして一般的には私たちの世界を改善できるデータサイエンスの専門家に対する需要が急増しています。 間違いなく、人工知能と機械学習の分野は確かに有望に見えます。 upGradを使用すると、機械学習とクラウドでのキャリアがやりがいのあるものになるので安心できます。
K-NNが優れた分類器であるのはなぜですか?
他の機械学習アルゴリズムに対するK-NNの主な利点は、マルチクラス分類にK-NNを便利に使用できることです。 したがって、データを3つ以上のカテゴリに分類する必要がある場合、またはデータが3つ以上のラベルで構成されている場合は、K-NNが最適なアルゴリズムです。 また、非線形データに最適で、精度も比較的高くなっています。
K-NNアルゴリズムの制限は何ですか?
K-NNアルゴリズムは、データポイント間の距離を計算することによって機能します。 したがって、これは比較的時間のかかるアルゴリズムであり、場合によっては分類に時間がかかることは明らかです。 したがって、マルチクラス分類にK-NNを使用するときは、あまり多くのデータポイントを使用しないことが最善です。 その他の制限には、高いメモリストレージと無関係な機能に対する感度が含まれます。
K-NNの実際のアプリケーションは何ですか?
K-NNには、手書き検出、音声認識、ビデオ認識、画像認識など、機械学習における実際の使用例がいくつかあります。 銀行では、K-NNを使用して、個人が債務不履行者と同様の特性を持っているかどうかに基づいて、個人がローンの対象となるかどうかを予測します。 政治では、K-NNを使用して、有権者候補を「党Xに投票する」または「党Yに投票する」などのさまざまなクラスに分類できます。