
ソースコードを読んでJavaScriptの知識を向上させる
公開: 2022-03-10頻繁に使用するライブラリやフレームワークのソースコードを初めて深く掘り下げたのを覚えていますか? 私にとって、その瞬間は3年前のフロントエンド開発者としての私の最初の仕事の間に来ました。
eラーニングコースの作成に使用した内部レガシーフレームワークの書き直しが完了したところです。 書き直しの最初は、Mithril、Inferno、Angular、React、Aurelia、Vue、Polymerなどのさまざまなソリューションの調査に時間を費やしていました。 私は非常に初心者だったので(ジャーナリズムからWeb開発に切り替えたばかりでした)、各フレームワークの複雑さに恐れを感じ、それぞれがどのように機能するかを理解していなかったのを覚えています。
選択したフレームワークであるミスリルをより深く調査し始めたとき、私の理解は深まりました。 それ以来、JavaScriptの知識、そしてプログラミング全般についての知識は、仕事や自分のプロジェクトで毎日使用しているライブラリの内臓を深く掘り下げて過ごした時間によって大いに助けられてきました。 この投稿では、お気に入りのライブラリまたはフレームワークを教育ツールとして使用する方法をいくつか紹介します。
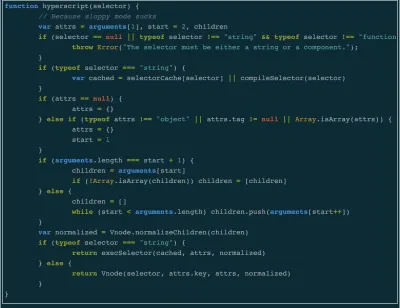
ソースコードを読むことの利点
ソースコードを読むことの主な利点の1つは、学ぶことができることの数です。 Mithrilのコードベースを最初に調べたとき、仮想DOMが何であるかについて漠然とした考えがありました。 終了すると、仮想DOMは、ユーザーインターフェイスがどのように表示されるかを説明するオブジェクトのツリーを作成する手法であることがわかりました。 次に、そのツリーは、 document.createElementなどのDOMAPIを使用してDOM要素に変換されます。 更新は、ユーザーインターフェイスの将来の状態を説明する新しいツリーを作成し、それを古いツリーのオブジェクトと比較することによって実行されます。
私はさまざまな記事やチュートリアルでこれらすべてについて読んだことがあり、それは役に立ちましたが、出荷したアプリケーションのコンテキストで動作中を観察できたことは私にとって非常に明るいものでした。 また、さまざまなフレームワークを比較するときにどの質問をするべきかについても教えてくれました。 たとえば、GitHubのスターを見る代わりに、「各フレームワークが更新を実行する方法がパフォーマンスとユーザーエクスペリエンスにどのように影響するか」などの質問をすることがわかりました。
もう1つの利点は、優れたアプリケーションアーキテクチャに対する理解と理解が深まることです。 ほとんどのオープンソースプロジェクトは通常、リポジトリと同じ構造に従いますが、それぞれに違いがあります。 Mithrilの構造は非常にフラットであり、そのAPIに精通している場合は、 render 、 router 、 requestなどのフォルダー内のコードについて知識に基づいた推測を行うことができます。 一方、Reactの構造はその新しいアーキテクチャを反映しています。 メンテナは、UIの更新を担当するモジュール( react-reconciler )をDOM要素のレンダリングを担当するモジュール( react-dom )から分離しました。
これの利点の1つは、 react-reconcilerパッケージにフックすることで、開発者が独自のカスタムレンダラーを簡単に作成できるようになったことです。 私が最近研究しているモジュールバンドラーであるParcelにも、Reactのようなpackagesフォルダーがあります。 キーモジュールの名前はparcel-bundlerで、バンドルの作成、ホットモジュールサーバーの起動、コマンドラインツールを担当するコードが含まれています。

さらにもう1つの利点は、私にとって歓迎すべき驚きでしたが、言語の動作を定義する公式のJavaScript仕様をより快適に読むことができるようになることです。 仕様を最初に読んだのは、 throw Errorとthrow new Errorの違いを調査していたときでした(ネタバレ注意-何もありません)。 Mithrilがm関数の実装でthrowErrorを使用していることに気づき、 throw Error throw new Errorよりもそれを使用することに利点があるかどうか疑問に思ったのでこれを調べました。 それ以来、論理演算子&&と||も学びました。 必ずしもブール値を返す必要はありません。 ==等式演算子が値を強制する方法とObject.prototype.toString.call({})が'[object Object]'を返す理由を管理するルールを見つけました。
ソースコードを読むためのテクニック
ソースコードにアプローチする方法はたくさんあります。 開始する最も簡単な方法は、選択したライブラリからメソッドを選択し、それを呼び出したときに何が起こるかを文書化することです。 すべてのステップを文書化するのではなく、その全体的なフローと構造を特定するようにしてください。
私は最近ReactDOM.renderでこれを行い、その結果、ReactFiberとその実装の背後にあるいくつかの理由について多くを学びました。 ありがたいことに、Reactは人気のあるフレームワークであるため、同じ問題について他の開発者によって書かれた多くの記事に出くわし、これによりプロセスがスピードアップしました。
この詳細な説明では、協調スケジューリングの概念、 window.requestIdleCallbackメソッド、およびリンクリストの実際の例も紹介しました(Reactは、優先更新のリンクリストであるキューに更新を配置することで更新を処理します)。 これを行うときは、ライブラリを使用して非常に基本的なアプリケーションを作成することをお勧めします。 これにより、他のライブラリによって引き起こされたスタックトレースを処理する必要がなくなるため、デバッグが容易になります。
詳細なレビューを行っていない場合は、作業中のプロジェクトで/node_modulesフォルダーを開くか、GitHubリポジトリに移動します。 これは通常、バグや興味深い機能に遭遇したときに発生します。 GitHubでコードを読むときは、最新バージョンから読んでいることを確認してください。 ブランチの変更に使用するボタンをクリックして「タグ」を選択すると、最新バージョンのタグを使用したコミットからコードを表示できます。 ライブラリとフレームワークは永遠に変更されているので、次のバージョンで削除される可能性のあるものについて知りたくありません。
ソースコードを読み取るもう1つのあまり複雑でない方法は、私が「cursoryglance」メソッドと呼んでいるものです。 コードを読み始めた早い段階で、 express.jsをインストールし、その/node_modulesフォルダーを開いて、その依存関係を調べました。 READMEで十分な説明が得られなかった場合は、ソースを読みました。 これを行うことで、これらの興味深い発見につながりました。
- Expressは、両方ともオブジェクトをマージする2つのモジュールに依存していますが、その方法は大きく異なります。
merge-descriptorsは、ソースオブジェクトで直接見つかったプロパティのみを追加し、列挙できないプロパティもマージします。一方、utils-mergeは、オブジェクトの列挙可能なプロパティとそのプロトタイプチェーンで見つかったプロパティのみを繰り返します。merge-descriptorsはObject.getOwnPropertyNames()とObject.getOwnPropertyDescriptor()を使用し、utils-mergeはfor..inを使用します。 -
setprototypeofモジュールは、インスタンス化されたオブジェクトのプロトタイプを設定するクロスプラットフォームの方法を提供します。 -
escape-htmlは、コンテンツの文字列をエスケープしてHTMLコンテンツに補間できるようにするための78行のモジュールです。
調査結果がすぐに役立つとは限りませんが、ライブラリまたはフレームワークで使用される依存関係を一般的に理解しておくと役立ちます。

フロントエンドコードのデバッグに関しては、ブラウザのデバッグツールが最適です。 特に、プログラムをいつでも停止してその状態を検査したり、関数の実行をスキップしたり、プログラムにステップインまたはステップアウトしたりすることができます。 コードが縮小されているため、これがすぐに不可能になる場合があります。 私はそれを縮小せず、縮小されていないコードを/node_modulesフォルダー内の関連ファイルにコピーする傾向があります。
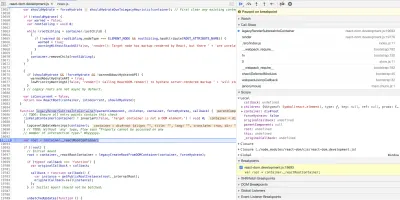
ケーススタディ:Reduxの接続機能
React-Reduxは、Reactアプリケーションの状態を管理するために使用されるライブラリです。 このような人気のあるライブラリを扱うとき、私はその実装について書かれた記事を検索することから始めます。 このケーススタディのためにそうすることで、私はこの記事に出くわしました。 これは、ソースコードを読むことのもう1つの良い点です。 調査段階では通常、このような有益な記事にたどり着きますが、それはあなた自身の思考と理解を向上させるだけです。
connectは、ReactコンポーネントをアプリケーションのReduxストアに接続するReact-Redux関数です。 どのように? まあ、ドキュメントによると、それは次のことをします:
「...渡したコンポーネントをラップする、接続された新しいコンポーネントクラスを返します。」
これを読んだ後、私は次の質問をします:
- 関数が入力を受け取り、同じ入力を追加機能でラップして返すパターンや概念を知っていますか?
- そのようなパターンを知っている場合、ドキュメントに記載されている説明に基づいてこれをどのように実装しますか?
通常、次のステップは、 connectを使用する非常に基本的なサンプルアプリを作成することです。 ただし、今回は、Limejumpで構築している新しいReactアプリを使用することにしました。これは、最終的に本番環境に移行するアプリケーションのコンテキスト内でconnectを理解したかったためです。
私が注目しているコンポーネントは次のようになります。
class MarketContainer extends Component { // code omitted for brevity } const mapDispatchToProps = dispatch => { return { updateSummary: (summary, start, today) => dispatch(updateSummary(summary, start, today)) } } export default connect(null, mapDispatchToProps)(MarketContainer); これは、4つの小さな連結成分をラップするコンテナコンポーネントです。 connectメソッドをエクスポートするファイルで最初に出くわすものの1つは、このコメントです。connectはconnectAdvanced上のファサードです。 遠くまで行かなくても、最初の学習の瞬間があります。それは、実際のファサードデザインパターンを観察する機会です。 ファイルの最後に、 connectがcreateConnectという関数の呼び出しをエクスポートしていることがわかります。 そのパラメータは、次のように分解された一連のデフォルト値です。
export function createConnect({ connectHOC = connectAdvanced, mapStateToPropsFactories = defaultMapStateToPropsFactories, mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories, mergePropsFactories = defaultMergePropsFactories, selectorFactory = defaultSelectorFactory } = {})ここでも、呼び出された関数のエクスポートとデフォルトの関数引数の破棄という別の学習の瞬間に出くわします。 コードが次のように記述されていたため、破壊の部分は学習の瞬間です。
export function createConnect({ connectHOC = connectAdvanced, mapStateToPropsFactories = defaultMapStateToPropsFactories, mapDispatchToPropsFactories = defaultMapDispatchToPropsFactories, mergePropsFactories = defaultMergePropsFactories, selectorFactory = defaultSelectorFactory }) このエラーが発生するUncaught TypeError: Cannot destructure property 'connectHOC' of 'undefined' or 'null'. これは、関数にフォールバックするデフォルトの引数がないためです。
注:これについて詳しくは、DavidWalshの記事をご覧ください。 言語の知識によっては、学習の瞬間が些細なことに思えるかもしれません。そのため、これまでに見たことのないものや、さらに学ぶ必要のあるものに焦点を当てたほうがよい場合があります。
createConnect自体は、関数本体では何もしません。 ここで使用したconnectという関数を返します。
export default connect(null, mapDispatchToProps)(MarketContainer) これは4つの引数を取り、すべてオプションであり、最初の3つの引数はそれぞれ、引数が存在するかどうかと値の型に応じて動作を定義するのに役立つmatch関数を通過します。 ここで、 matchするように提供された2番目の引数は、 connectにインポートされた3つの関数の1つであるため、どのスレッドに従うかを決定する必要があります。
これらの引数が関数である場合にconnect最初の引数をラップするために使用されるプロキシ関数、プレーンオブジェクトをチェックするために使用されるisPlainObjectユーティリティ、またはすべての例外でブレークするようにデバッガーを設定する方法を明らかにするwarningモジュールには、学習の瞬間があります。 一致関数の後で、Reactコンポーネントを取得してReduxに接続する関数であるconnectHOCに到達します。 これは、コンポーネントのストアへの接続を実際に処理する関数であるwrapWithConnectを返す別の関数呼び出しです。
connectHOCの実装を見ると、実装の詳細を非表示にするためにconnectが必要な理由を理解できます。 これはReact-Reduxの心臓部であり、 connectを介して公開する必要のないロジックが含まれています。 ここで詳細を終了しますが、続けていれば、コードベースの非常に詳細な説明が含まれているため、以前に見つけた参考資料を参照するのに最適な時期でした。
概要
ソースコードを読むことは最初は難しいですが、他の場合と同様に、時間の経過とともに簡単になります。 目標は、すべてを理解することではなく、異なる視点と新しい知識を身に付けることです。 重要なのは、プロセス全体について慎重に検討し、すべてについて非常に好奇心をそそることです。
たとえば、 isPlainObject関数は、指定された引数がプレーンオブジェクトであることを確認するためif (typeof obj !== 'object' || obj === null) return falseを使用するため、興味深いことがわかりました。 その実装を最初に読んだとき、なぜObject.prototype.toString.call(opts) !== '[object Object]'を使用しなかったのか疑問に思いました。これはコードが少なく、オブジェクトとDateなどのオブジェクトサブタイプを区別します。物体。 ただし、次の行を読むと、たとえば、 connectを使用している開発者がDateオブジェクトを返すという非常にまれなイベントでは、これはObject.getPrototypeOf(obj) === nullチェックによって処理されることがわかりました。
isPlainObject 1つの興味深い点は、次のコードです。
while (Object.getPrototypeOf(baseProto) !== null) { baseProto = Object.getPrototypeOf(baseProto) }一部のGoogle検索により、このStackOverflowスレッドと、iFrameから発信されたオブジェクトに対するチェックなどのケースをそのコードがどのように処理するかを説明するReduxの問題が発生しました。
ソースコードを読む際の役立つリンク
- 「エンジニアフレームワークをリバースエンジニアリングする方法」、Max Koretskyi、Medium
- 「コードの読み方」、Aria Stewart、GitHub