
コンポーネントベースのAPIの紹介
公開: 2022-03-10この記事は、読者のフィードバックに対応するために2019年1月31日に更新されました。 著者は、コンポーネントベースのAPIにカスタムクエリ機能を追加し、それがどのように機能するかを説明しています。
APIは、アプリケーションがサーバーからデータをロードするための通信チャネルです。 APIの世界では、RESTはより確立された方法論でしたが、最近、RESTよりも重要な利点を提供するGraphQLによって影が薄くなっています。 RESTは、コンポーネントをレンダリングするためにデータのセットをフェッチするために複数のHTTPリクエストを必要としますが、GraphQLは、単一のリクエストでそのようなデータをクエリおよび取得できます。応答は、通常のようにデータをオーバーまたはアンダーフェッチすることなく、まさに必要なものになります。残り。
この記事では、私が設計して「PoP」と呼んだ(ここではオープンソースの)データをフェッチする別の方法について説明します。これは、GraphQLによって導入された単一のリクエストで複数のエンティティのデータをフェッチするというアイデアを拡張し、さらに一歩進んで、つまり、RESTが1つのリソースのデータをフェッチし、GraphQLが1つのコンポーネントのすべてのリソースのデータをフェッチする間、コンポーネントベースのAPIは1つのページのすべてのコンポーネントからすべてのリソースのデータをフェッチできます。
コンポーネントベースのAPIを使用することは、Webサイト自体がコンポーネントを使用して構築されている場合、つまりWebページが他のコンポーネントをラップするコンポーネントで繰り返し構成されている場合に最も意味があります。 たとえば、次の画像に示されているWebページは、正方形で囲まれたコンポーネントで構築されています。
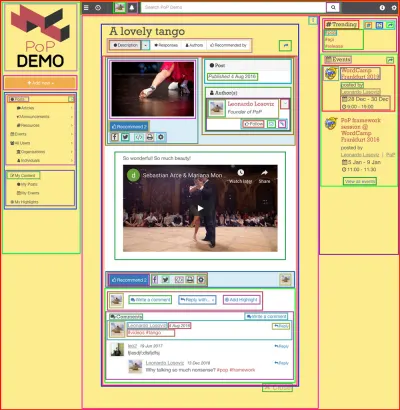
コンポーネントベースのAPIは、各コンポーネントのすべてのリソース(およびページ内のすべてのコンポーネント)のデータを要求することでサーバーに単一の要求を行うことができます。これは、コンポーネント間の関係を維持することによって実現されます。 API構造自体。
特に、この構造には次のいくつかの利点があります。
- 多くのコンポーネントを含むページは、多くではなく1つのリクエストのみをトリガーします。
- コンポーネント間で共有されるデータは、DBから1回だけフェッチし、応答で1回だけ出力できます。
- これにより、データストアの必要性を大幅に減らすことができます(完全に削除することもできます)。
これらについては記事全体で詳しく説明しますが、最初に、実際のコンポーネントと、そのようなコンポーネントに基づいてサイトを構築する方法を調べ、最後に、コンポーネントベースのAPIがどのように機能するかを調べます。
推奨読書: GraphQL入門書:新しい種類のAPIが必要な理由
コンポーネントを介したサイトの構築
コンポーネントは、自律型エンティティを作成するためにすべてを組み合わせたHTML、JavaScript、およびCSSコードの断片のセットです。 これにより、他のコンポーネントをラップしてより複雑な構造を作成し、それ自体を他のコンポーネントでラップすることもできます。 コンポーネントには目的があり、非常に基本的なもの(リンクやボタンなど)から非常に複雑なもの(カルーセルやドラッグアンドドロップの画像アップローダーなど)までさまざまです。 コンポーネントは、汎用的であり、挿入されたプロパティ(または「小道具」)を介してカスタマイズできる場合に最も役立ちます。これにより、さまざまなユースケースに対応できます。 ほとんどの場合、サイト自体がコンポーネントになります。
「コンポーネント」という用語は、機能とデザインの両方を指すためによく使用されます。 たとえば、機能に関しては、ReactやVueなどのJavaScriptフレームワークを使用すると、クライアント側のコンポーネントを作成できます。これらのコンポーネントは、自己レンダリングでき(たとえば、APIが必要なデータをフェッチした後)、propsを使用して構成値を設定できます。ラップされたコンポーネントにより、コードの再利用が可能になります。 デザインに関しては、Bootstrapはフロントエンドコンポーネントライブラリを通じてWebサイトの外観と雰囲気を標準化し、チームがWebサイトを維持するためのデザインシステムを作成することは健全な傾向になりました。これにより、さまざまなチームメンバー(デザイナーと開発者だけでなく、マーケターとセールスマン)は、統一された言語を話し、一貫したアイデンティティを表現します。
サイトをコンポーネント化することは、Webサイトをより保守しやすくするための非常に賢明な方法です。 ReactやVueなどのJavaScriptフレームワークを使用しているサイトは、すでにコンポーネントベースです(少なくともクライアント側では)。 Bootstrapのようなコンポーネントライブラリを使用しても、必ずしもサイトがコンポーネントベースになるとは限りません(HTMLの大きなブロブになる可能性があります)が、ユーザーインターフェイスの再利用可能な要素の概念が組み込まれています。
サイトがHTMLの大きな塊である場合、それをコンポーネント化するには、レイアウトを一連の繰り返しパターンに分割する必要があります。そのために、機能とスタイルの類似性に基づいてページ上のセクションを識別してカタログ化し、これらを分割する必要があります。セクションを可能な限り細かくレイヤーに分割し、各レイヤーを単一の目標またはアクションに集中させようとします。また、異なるセクション間で共通のレイヤーを一致させようとします。
注: Brad Frostの「AtomicDesign」は、これらの一般的なパターンを識別し、再利用可能な設計システムを構築するための優れた方法論です。
したがって、コンポーネントを使用してサイトを構築することは、LEGOで遊ぶことに似ています。 各コンポーネントは、アトミック機能、他のコンポーネントの組み合わせ、または2つの組み合わせのいずれかです。
以下に示すように、基本コンポーネント(アバター)は、上部のWebページを取得するまで、他のコンポーネントによって繰り返し構成されます。

コンポーネントベースのAPI仕様
私が設計したコンポーネントベースのAPIでは、コンポーネントは「モジュール」と呼ばれるため、以降、「コンポーネント」と「モジュール」という用語は同じ意味で使用されます。
最上位のモジュールから最後のレベルまで、互いにラップしているすべてのモジュールの関係は、「コンポーネント階層」と呼ばれます。 この関係は、サーバー側の連想配列(key =>プロパティの配列)を介して表すことができます。各モジュールは、その名前をキー属性として示し、その内部モジュールをプロパティmodulesの下に示します。 次に、APIは、この配列を消費用のJSONオブジェクトとして単純にエンコードします。
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }モジュール間の関係は、厳密にトップダウン方式で定義されます。モジュールは他のモジュールをラップし、それらが誰であるかを知っていますが、どのモジュールが彼をラップしているかはわかりません。
たとえば、上記のJSONコードでは、モジュールmodule-level1 -level1は、モジュールmodule-level11とmodule-level12をラップしていることを認識しており、推移的には、 module-level121をラップしていることも認識しています。 ただし、モジュールmodule-level11は、誰がラップしているのかを気にしないため、 module-level1 module-level11しません。
コンポーネントベースの構造により、各モジュールに必要な実際の情報を追加できるようになりました。この情報は、設定(構成値やその他のプロパティなど)とデータ(クエリされたデータベースオブジェクトのIDやその他のプロパティなど)のいずれかに分類されます。 、それに応じてエントリmodulesettingsおよびmoduledataの下に配置されます:
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } 続いて、APIはデータベースオブジェクトデータを追加します。 この情報は、各モジュールの下ではなく、 databasesと呼ばれる共有セクションの下に配置され、2つ以上の異なるモジュールがデータベースから同じオブジェクトをフェッチするときに情報が重複しないようにします。
さらに、APIは、2つ以上の異なるデータベースオブジェクトが共通のオブジェクト(同じ作成者を持つ2つの投稿など)に関連している場合に情報が重複しないように、データベースオブジェクトデータをリレーショナルに表現します。 つまり、データベースオブジェクトデータは正規化されます。
推奨読書:静的サイトのサーバーレスお問い合わせフォームの作成
構造は辞書であり、最初に各オブジェクトタイプ、次にオブジェクトIDで編成され、そこからオブジェクトのプロパティを取得できます。
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }このJSONオブジェクトは、すでにコンポーネントベースのAPIからの応答です。 その形式はそれ自体が仕様です。サーバーが必要な形式でJSON応答を返す限り、クライアントは実装方法に関係なくAPIを使用できます。 したがって、APIは任意の言語で実装できます(これはGraphQLの美しさの1つです。仕様であり、実際の実装ではないため、無数の言語で使用できるようになりました)。
注:今後の記事では、PHPでのコンポーネントベースのAPIの実装について説明します(これはリポジトリで利用できるものです)。
API応答の例
たとえば、以下のAPI応答には、2つのモジュール( page => post-feed )を持つコンポーネント階層が含まれています。ここで、モジュールpost-feedブログ投稿をフェッチします。 次の点に注意してください。
- 各モジュールは、プロパティ
dbobjectids(ブログ投稿のID4および9)からクエリされたオブジェクトを認識しています。 - 各モジュールは、プロパティ
dbkeysからクエリされたオブジェクトのオブジェクトタイプを認識しています(各投稿のデータはpostsの下にあり、投稿のプロパティauthorの下に指定されたIDを持つ作成者に対応する投稿の作成者データはusersの下にあります) - データベースオブジェクトデータはリレーショナルであるため、プロパティの作成
authorには、作成者データを直接印刷するのではなく、作成者オブジェクトのIDが含まれます。
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }リソースベース、スキーマベース、およびコンポーネントベースのAPIからデータを取得する際の違い
PoPなどのコンポーネントベースのAPIが、データをフェッチするときに、RESTなどのリソースベースのAPIやGraphQLなどのスキーマベースのAPIとどのように比較されるかを見てみましょう。
IMDBに、データを取得する必要のある2つのコンポーネントがあるページがあるとします。「注目の監督」(ジョージルーカスの説明と彼の映画のリストを表示)と「あなたにおすすめの映画」(スターウォーズエピソード1などの映画を表示) —ファントムメナスとターミネーター)。 次のようになります。
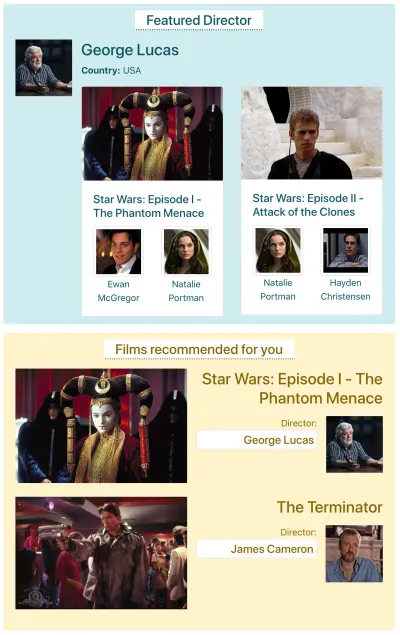
各APIメソッドを介してデータをフェッチするために必要なリクエストの数を見てみましょう。 この例では、「注目の監督」コンポーネントが1つの結果(「ジョージルーカス」)をもたらし、そこから2つの映画(スターウォーズエピソードI —ファントムメナスとスターウォーズエピソードII —クローンの攻撃)を取得します。各映画に2人の俳優(最初の映画は「ユアン・マクレガー」と「ナタリー・ポートマン」、2番目の映画は「ナタリー・ポートマン」と「ヘイデン・クリステンセン」)。 コンポーネント「あなたにおすすめの映画」は2つの結果(スターウォーズエピソード1 —ファントムメナスとターミネーター)をもたらし、次に監督(それぞれ「ジョージルーカス」と「ジェームズキャメロン」)を取得します。
RESTを使用してコンポーネントfeatured-directorをレンダリングするには、次の7つのリクエストが必要になる場合があります(この数は、各エンドポイントによって提供されるデータの量、つまり、実装されているオーバーフェッチの量によって異なります)。
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQLを使用すると、厳密に型指定されたスキーマを介して、コンポーネントごとに1つのリクエストで必要なすべてのデータをフェッチできます。 コンポーネントfeaturedDirectorのGraphQLを介してデータをフェッチするクエリは、次のようになります(対応するスキーマを実装した後)。
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }そして、それは次の応答を生成します:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }また、コンポーネント「あなたにおすすめの映画」をクエリすると、次の応答が生成されます。
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoPは、ページ内のすべてのコンポーネントのすべてのデータをフェッチし、結果を正規化するための1つのリクエストのみを発行します。 呼び出されるエンドポイントは、データを取得する必要のあるURLと単純に同じですが、HTMLとして出力する代わりに、データをJSON形式で取得することを示すパラメーターoutput=jsonを追加するだけです。
GET - /url-of-the-page/?output=json モジュール構造に、 featured-directorおよびfilms-recommended-for-youモジュールを含むpageという名前のトップモジュールがあり、これらにも次のようなサブモジュールがあると仮定します。
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"返される単一のJSON応答は次のようになります。
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }速度と取得されるデータの量の観点から、これら3つの方法が互いにどのように比較されるかを分析してみましょう。
スピード
RESTを使用すると、1つのコンポーネントをレンダリングするためだけに7つのリクエストをフェッチする必要があるため、ほとんどの場合モバイルで不安定なデータ接続では非常に遅くなる可能性があります。 したがって、RESTからGraphQLへのジャンプは、1つのリクエストのみでコンポーネントをレンダリングできるため、速度が大幅に向上します。
PoPは、1回のリクエストで多くのコンポーネントのすべてのデータをフェッチできるため、一度に多くのコンポーネントをレンダリングする場合に高速になります。 ただし、ほとんどの場合、これは必要ありません。 コンポーネントを(ページに表示されるように)順番にレンダリングすることは、すでに良い習慣であり、折り目の下に表示されるコンポーネントについては、それらを急いでレンダリングする必要はありません。 したがって、スキーマベースのAPIとコンポーネントベースのAPIはどちらもすでにかなり優れており、リソースベースのAPIよりも明らかに優れています。
データ量
リクエストごとに、GraphQL応答のデータが複製される場合があります。女優「ナタリーポートマン」が最初のコンポーネントからの応答で2回フェッチされ、2つのコンポーネントの共同出力を考慮すると、映画などの共有データも見つかります。スターウォーズエピソード1—ファントムメナス。
一方、PoPは、データベースデータを正規化し、1回だけ印刷しますが、モジュール構造を印刷するオーバーヘッドが発生します。 したがって、データが重複しているかどうかに応じて、スキーマベースのAPIまたはコンポーネントベースのAPIのいずれかのサイズが小さくなります。
結論として、GraphQLなどのスキーマベースのAPIとPoPなどのコンポーネントベースのAPIは、パフォーマンスに関して同様に優れており、RESTなどのリソースベースのAPIよりも優れています。
推奨読書: RESTAPIの理解と使用
コンポーネントベースのAPIの特定のプロパティ
コンポーネントベースのAPIがスキーマベースのAPIよりもパフォーマンスの点で必ずしも優れているとは限らない場合は、疑問に思われるかもしれませんが、この記事で何を達成しようとしていますか?
このセクションでは、そのようなAPIには信じられないほどの可能性があり、非常に望ましいいくつかの機能を提供し、APIの世界で真剣な競争相手になっていることを納得させようと思います。 以下に、その独自の優れた機能のそれぞれについて説明し、デモンストレーションします。
データベースから取得するデータは、コンポーネント階層から推測できます。
モジュールがDBオブジェクトのプロパティを表示する場合、モジュールはそれがどのオブジェクトであるかを認識または気にしない場合があります。 気になるのは、ロードされたオブジェクトのどのプロパティが必要かを定義することだけです。
たとえば、次の画像について考えてみます。 モジュールがデータベース(この場合は単一の投稿)からオブジェクトをロードすると、その子孫モジュールは、 titleやcontentなど、オブジェクトの特定のプロパティを表示します。
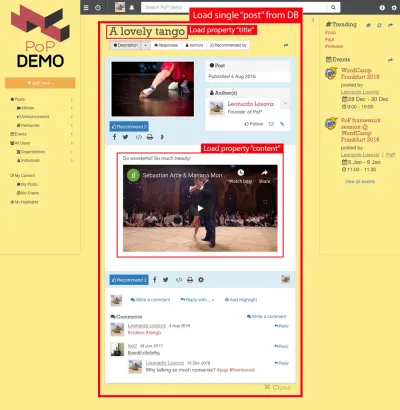
したがって、コンポーネント階層に沿って、「dataloading」モジュールがクエリされたオブジェクトのロードを担当し(この場合、単一の投稿をロードするモジュール)、その子孫モジュールがDBオブジェクトから必要なプロパティを定義します( titleおよびcontent 、この場合)。
DBオブジェクトに必要なすべてのプロパティのフェッチは、コンポーネント階層をトラバースすることで自動的に実行できます。データローディングモジュールから開始して、新しいデータローディングモジュールに到達するまで、またはツリーの最後まで、すべての子孫モジュールを繰り返し処理します。 各レベルで、必要なすべてのプロパティを取得してから、すべてのプロパティをマージしてデータベースからクエリします。これらはすべて1回だけです。
以下の構造では、モジュールsingle-postはDB(ID 37の投稿)から結果をフェッチし、サブモジュールpost-titleとpost-contentは、クエリされたDBオブジェクトにロードされるプロパティ(それぞれtitleとcontent )を定義します。 サブモジュールpost-layoutおよびfetch-next-post-buttonは、データフィールドを必要としません。
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"実行されるクエリは、すべてのモジュールとそのサブモジュールに必要なすべてのプロパティを含む、コンポーネント階層とその必須データフィールドから自動的に計算されます。
SELECT title, content FROM posts WHERE id = 37 モジュールから直接取得するプロパティをフェッチすることにより、コンポーネント階層が変更されるたびにクエリが自動的に更新されます。 たとえば、サブモジュールpost-thumbnailを追加すると、データフィールドのthumbnailが必要になります。
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"次に、クエリが自動的に更新され、追加のプロパティが取得されます。
SELECT title, content, thumbnail FROM posts WHERE id = 37リレーショナル方式で取得するデータベースオブジェクトデータを確立しているため、データベースオブジェクト自体の関係にもこの戦略を適用できます。
次の画像について考えてみます。オブジェクトタイプのpostから始めてコンポーネント階層を下に移動すると、DBオブジェクトタイプをuserとcommentにシフトする必要があります。これは、投稿の作成者と各投稿のコメントにそれぞれ対応し、次に、コメントの場合、コメントの作成者に対応するuserにオブジェクトタイプをもう一度変更する必要があります。
データベースオブジェクトからリレーショナルオブジェクトへの移動( post =>作成authorがpostからuserに移動する場合のようにオブジェクトタイプを変更するか、作成author =>フォロワーがユーザーからuserに移動するuserのように)は、私が「ドメインの切り替え」と呼んでいます。 」。
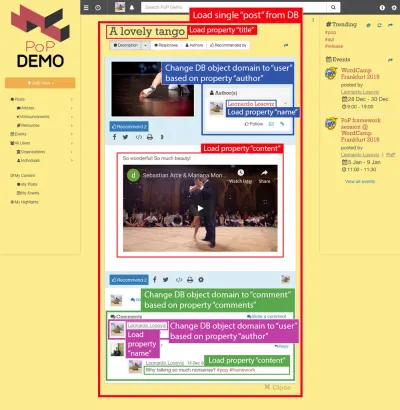
新しいドメインに切り替えた後、コンポーネント階層のそのレベルから下に向かって、必要なすべてのプロパティが新しいドメインの対象になります。
-
nameはuserオブジェクト(投稿の作成者を表す)から取得され、 -
contentはcommentオブジェクト(投稿の各コメントを表す)からフェッチされ、 -
nameはuserオブジェクト(各コメントの作成者を表す)から取得されます。
コンポーネント階層をトラバースすることで、APIは新しいドメインに切り替えるタイミングを認識し、適切にクエリを更新してリレーショナルオブジェクトをフェッチします。
たとえば、投稿の作成者からのデータを表示する必要がある場合、サブモジュールのpost-author者をスタックすると、そのレベルのドメインがpostから対応するuserに変更され、このレベルから下に向かって、モジュールに渡されるコンテキストに読み込まれるDBオブジェクトは次のようになります。ユーザー。 次に、 post-author下のサブモジュールuser-nameとuser-avatarは、 userオブジェクトの下にプロパティnameとavatarをロードします。
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"次のクエリが発生します。
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.id要約すると、各モジュールを適切に構成することにより、コンポーネントベースのAPIのデータをフェッチするためのクエリを作成する必要がなくなります。 クエリは、コンポーネント階層自体の構造から自動的に生成され、データロードモジュールによってロードする必要のあるオブジェクト、各子孫モジュールで定義されたロード済みオブジェクトごとに取得するフィールド、および各子孫モジュールで定義されたドメインスイッチングを取得します。
モジュールを追加、削除、置換、または変更すると、クエリが自動的に更新されます。 クエリを実行した後、取得されたデータはまさに必要なものになります—多かれ少なかれ何もありません。
データの観察と追加のプロパティの計算
データローディングモジュールからコンポーネント階層を下って開始すると、どのモジュールも返された結果を監視し、それらに基づいて追加のデータアイテム、またはエントリmoduledataの下に配置されるfeedback値を計算できます。
たとえば、モジュールfetch-next-post-buttonは、フェッチする結果がまだあるかどうかを示すプロパティを追加できます(このフィードバック値に基づいて、結果がこれ以上ない場合、ボタンは無効または非表示になります)。
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }必要なデータの暗黙知は複雑さを軽減し、「エンドポイント」の概念を時代遅れにします
上に示したように、コンポーネントベースのAPIは、サーバー上のすべてのコンポーネントのモデルと、各コンポーネントに必要なデータフィールドを備えているため、必要なデータを正確にフェッチできます。 次に、必要なデータフィールドの知識を暗黙的にすることができます。
利点は、コンポーネントに必要なデータを定義することで、JavaScriptファイルを再デプロイすることなく、サーバー側で更新できることです。また、必要なデータをサーバーに提供するようにサーバーに要求するだけで、クライアントを馬鹿にすることができます。 、したがって、クライアント側アプリケーションの複雑さを軽減します。
さらに、特定のURLのすべてのコンポーネントのデータを取得するためのAPIの呼び出しは、そのURLをクエリし、ページを印刷する代わりにAPIデータを返すことを示す追加のパラメーターoutput=jsonを追加するだけで実行できます。 したがって、URLはそれ自体のエンドポイントになるか、別の方法で考えると、「エンドポイント」の概念は廃止されます。
データのサブセットの取得:コンポーネント階層の任意のレベルで検出された特定のモジュールのデータを取得できます
ページ内のすべてのモジュールのデータをフェッチする必要はなく、コンポーネント階層の任意のレベルから始まる特定のモジュールのデータをフェッチする必要がある場合はどうなりますか? たとえば、モジュールが無限スクロールを実装している場合、下にスクロールするときは、このモジュールの新しいデータのみをフェッチする必要があり、ページ上の他のモジュールのデータはフェッチしません。

これは、応答に含まれるコンポーネント階層のブランチをフィルタリングして、指定されたモジュールから始まるプロパティのみを含め、このレベルより上のすべてを無視することで実現できます。 私の実装(今後の記事で説明します)では、URLにパラメーターmodulefilter=modulepathsを追加することでフィルタリングが有効になり、選択されたモジュールはmodulepaths[]パラメーターで示されます。 」は、最上位のモジュールから特定のモジュールまでのモジュールのリストです(たとえば、 module1 => module2 => module3にはモジュールパス[ module1 、 module2 、 module3 ]があり、URLパラメーターとしてmodule1.module2.module3として渡されます) 。
たとえば、下のコンポーネント階層には、すべてのモジュールにエントリdbobjectidsがあります。
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] 次に、パラメータmodulefilter=modulepathsおよびmodulepaths[]=module1.module2.module5を追加してWebページのURLを要求すると、次の応答が生成されます。
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] 本質的に、APIはmodule1 => module2 => module2からデータのロードを開始しmodule5 。 そのため、 module6に含まれるmodule5もデータを取得しますが、 module3とmodule4はデータを取得しません。
さらに、カスタムモジュールフィルターを作成して、事前に配置されたモジュールのセットを含めることができます。 たとえば、 modulefilter=userstateを使用してページを呼び出すと、モジュールmodule3やmodule6など、クライアントでレンダリングするためにユーザー状態を必要とするモジュールのみを出力できます。
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] 開始モジュールの情報は、モジュールパスの配列として、セクションrequestmetaの下、エントリfilteredmodulesの下にあります。
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }この機能により、サイトのフレームが最初のリクエストで読み込まれる、単純なシングルページアプリケーションを実装できます。
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] ただし、これら以降、要求されたすべてのURLにパラメーターmodulefilter=pageを追加して、フレームをフィルターで除外し、ページのコンテンツのみを表示することができます。
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] 上記のモジュールフィルターのユーザーuserstateとpageと同様に、任意のカスタムモジュールフィルターを実装して、リッチなユーザーエクスペリエンスを作成できます。
モジュールは独自のAPIです
上に示したように、API応答をフィルタリングして、任意のモジュールからデータを取得できます。 結果として、すべてのモジュールは、モジュールパスが含まれているWebページのURLに追加するだけで、クライアントからサーバーへと相互作用できます。
私の過度の興奮をお許しいただければ幸いですが、この機能の素晴らしさを十分に強調することはできません。 コンポーネントを作成するとき、データ(REST、GraphQL、またはその他)を取得するためにコンポーネントと一緒に使用するAPIを作成する必要はありません。これは、コンポーネントがすでにサーバー内でそれ自体と通信し、独自のコンポーネントをロードできるためです。データ—完全に自律的で自己奉仕的です。
各データローディングモジュールは、セクションdatasetmodulemetaの下からエントリdataloadsourceの下でそれと対話するためにURLをエクスポートします。
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }データのフェッチはモジュール間で分離され、DRY
コンポーネントベースのAPIでデータをフェッチすることは高度に分離されており、DRY( D on't R epeat Y自身)であるということを強調するために、最初にGraphQLなどのスキーマベースのAPIでどのように分離されていないかを示す必要があります。乾かない。
GraphQLでは、データをフェッチするクエリは、サブコンポーネントを含む可能性のあるコンポーネントのデータフィールドを示す必要があり、これらにはサブコンポーネントなども含まれる可能性があります。 次に、最上位のコンポーネントは、そのデータをフェッチするために、そのサブコンポーネントのすべてに必要なデータも知る必要があります。
たとえば、 <FeaturedDirector>コンポーネントをレンダリングするには、次のサブコンポーネントが必要になる場合があります。
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> このシナリオでは、GraphQLクエリは<FeaturedDirector>レベルで実装されます。 次に、サブコンポーネント<Film>が更新され、 titleではなくproperty filmTitleを介してタイトルを要求する場合、この新しい情報をミラーリングするために、 <FeaturedDirector>コンポーネントからのクエリも更新する必要があります(GraphQLには、処理できるバージョン管理メカニズムがあります)この問題が発生しましたが、遅かれ早かれ情報を更新する必要があります)。 これにより、メンテナンスが複雑になり、内部コンポーネントが頻繁に変更されたり、サードパーティの開発者によって作成されたりすると、処理が困難になる可能性があります。 したがって、コンポーネントは互いに完全に分離されていません。
同様に、特定の映画の<Film>コンポーネントを直接レンダリングしたい場合があります。その場合、このレベルでGraphQLクエリを実装して、映画とその俳優のデータをフェッチする必要があります。これにより、冗長なコードが追加されます。同じクエリがコンポーネント構造のさまざまなレベルで機能します。 したがって、 GraphQLはDRYではありません。
コンポーネントベースのAPIは、そのコンポーネントが独自の構造で相互にラップする方法をすでに知っているため、これらの問題は完全に回避されます。 1つは、クライアントは、必要なデータが何であれ、必要なデータを要求するだけです。 if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
ただし、コンポーネントベースのAPIでは、APIですでに説明されているモジュール間の関係を簡単に使用して、モジュールを結合できます。 元々は次のような応答があります。
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Instagramを追加すると、応答がアップグレードされます。
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } また、 modulesettings["share-on-social-media"].modules下のすべての値を繰り返すだけで、コンポーネント<ShareOnSocialMedia>をアップグレードして、JavaScriptファイルを再デプロイせずに<InstagramShare>コンポーネントを表示できます。 したがって、APIは、他のモジュールからのコードを損なうことなくモジュールの追加と削除をサポートし、より高度なモジュール性を実現します。
ネイティブクライアント側のキャッシュ/データストア
取得されたデータベースデータはディクショナリ構造で正規化され、標準化されているため、 dbobjectidsの値から開始して、エントリdbkeysで示されるパスをたどるだけで、 databasesの任意のデータにアクセスできます。 。 したがって、データを整理するためのロジックは、API自体にすでにネイティブです。
私たちはいくつかの方法でこの状況から利益を得ることができます。 たとえば、各リクエストに対して返されたデータは、セッション中にユーザーがリクエストしたすべてのデータを含むクライアント側のキャッシュに追加できます。 したがって、Reduxなどの外部データストアをアプリケーションに追加することを回避できます(つまり、Undo / Redo、コラボレーション環境、タイムトラベルデバッグなどの他の機能ではなく、データの処理に関するものです)。
また、コンポーネントベースの構造はキャッシュを促進します。コンポーネント階層はURLではなく、そのURLに必要なコンポーネントに依存します。 このようにして、 /events/1/と/events/2/の下の2つのイベントが同じコンポーネント階層を共有し、必要なモジュールの情報をそれらの間で再利用できます。 結果として、すべてのプロパティ(データベースデータを除く)は、最初のイベントをフェッチした後にクライアントにキャッシュし、それ以降に再利用できるため、後続の各イベントのデータベースデータのみをフェッチする必要があります。
拡張性と転用
APIのdatabasesセクションを拡張して、その情報をカスタマイズされたサブセクションに分類することができます。 デフォルトでは、すべてのデータベースオブジェクトデータはエントリprimaryの下に配置されますが、特定のDBオブジェクトプロパティを配置するカスタムエントリを作成することもできます。
たとえば、前述のコンポーネント「あなたにおすすめの映画」に、 film DBオブジェクトのプロパティfriendsWhoWatchedFilmでこの映画を視聴したログインユーザーの友達のリストが表示されている場合、この値はログインによって変化するためです。ユーザーは、代わりにこのプロパティをuserstateエントリの下に保存するため、ユーザーがログアウトすると、クライアントのキャッシュされたデータベースからこのブランチのみが削除されますが、すべてのprimaryデータは残ります。
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }さらに、ある時点まで、API応答の構造を再利用できます。 特に、データベースの結果は、デフォルトの辞書の代わりに配列など、異なるデータ構造で印刷できます。
たとえば、オブジェクトタイプが1つだけの場合(たとえば、 films )、配列としてフォーマットして、先行入力コンポーネントに直接フィードすることができます。
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]アスペクト指向プログラミングのサポート
コンポーネントベースのAPIは、データのフェッチに加えて、投稿の作成やコメントの追加などのデータを投稿したり、ユーザーのログインやログアウト、メールの送信、ログ記録、分析など、あらゆる種類の操作を実行したりできます。等々。 制限はありません。基盤となるCMSによって提供される機能は、モジュールを介して、どのレベルでも呼び出すことができます。
コンポーネント階層に沿って、任意の数のモジュールを追加でき、各モジュールは独自の操作を実行できます。 したがって、RESTでPOST、PUT、またはDELETE操作を実行したり、GraphQLでミューテーションを送信したりする場合のように、すべての操作が必ずしもリクエストの予想されるアクションに関連している必要はありませんが、電子メールの送信などの追加機能を提供するために追加できますユーザーが新しい投稿を作成するときに管理者に送信されます。
したがって、依存性注入または構成ファイルを介してコンポーネント階層を定義することにより、APIはアスペクト指向プログラミング、「横断的関心事の分離を可能にすることによってモジュール性を高めることを目的としたプログラミングパラダイム」をサポートすると言えます。
推奨読書:機能ポリシーでサイトを保護する
強化されたセキュリティ
モジュールの名前は、出力に出力されるときに必ずしも固定されているわけではありませんが、短縮、マングル、ランダムに変更、または(要するに)意図した方法で可変にすることができます。 当初はAPI出力を短縮することを考えていましたが(モジュール名のcarousel-featured-postsまたはdrag-and-drop-user-imagesを、本番環境のa1 、 a2などのbase64表記に短縮できるようにするため) )、この機能を使用すると、セキュリティ上の理由から、APIからの応答でモジュール名を頻繁に変更できます。
たとえば、入力名はデフォルトで対応するモジュールとして名前が付けられています。 次に、 usernameおよびpasswordと呼ばれるモジュールは、クライアントでそれぞれ<input type="text" name="{input_name}">および<inputtype <input type="password" name="{input_name}">としてレンダリングされます。入力名(現在はc3oMLBjoとc46oVgN6 、明日はzwH8DSeGとQBG7m6EFなど)にさまざまなランダム値を設定できるため、スパマーやボットがサイトをターゲットにするのがより困難になります。
代替モデルによる多様性
モジュールをネストすると、別のモジュールに分岐して特定のメディアまたはテクノロジーの互換性を追加したり、スタイルや機能を変更してから元の分岐に戻ることができます。
たとえば、Webページの構造が次のようになっているとします。
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" この場合、ウェブサイトをAMPでも機能させたいのですが、モジュールmodule2 、 module4 、 module5はAMPと互換性がありません。 これらのモジュールを同様のAMP互換モジュールmodule2AMP 、 module4AMP 、 module5AMPに分岐できます。その後、元のコンポーネント階層をロードし続けるため、これら3つのモジュールのみが置き換えられます(他には何もありません)。
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"これにより、単一のコードベースからさまざまな出力を生成するのがかなり簡単になり、必要に応じてフォークをあちこちに追加し、常にスコープを設定して個々のモジュールに制限します。
デモンストレーション時間
この記事で説明されているAPIを実装するコードは、このオープンソースリポジトリで入手できます。
デモの目的で、 https://nextapi.getpop.org //nextapi.getpop.orgの下にPoPAPIをデプロイしました。 ウェブサイトはWordPressで実行されているため、URLパーマリンクはWordPressに典型的なものです。 前述のように、パラメーターoutput=jsonを追加することで、これらのURLは独自のAPIエンドポイントになります。
このサイトはPoPDemo Webサイトの同じデータベースに支えられているため、コンポーネント階層と取得したデータの視覚化は、この他のWebサイトの同じURLをクエリして実行できます(たとえば、 https://demo.getpop.org/u/leo/ ://demo.getpop.org/uにアクセスします)。 https://demo.getpop.org/u/leo/は、 https://nextapi.getpop.org/u/leo/?output=json output = jsonからのデータについて説明しています。
以下のリンクは、前述のケースのAPIを示しています。
- ホームページ、単一の投稿、作成者、投稿のリスト、およびユーザーのリスト。
- 特定のモジュールからフィルタリングするイベント。
- タグ、ユーザー状態を必要とするフィルタリングモジュール、およびシングルページアプリケーションからページのみを取得するためのフィルタリング。
- タイプアヘッドにフィードする場所の配列。
- 「私たちが誰であるか」ページの代替モデル:通常、印刷可能、埋め込み可能。
- モジュール名の変更:オリジナルとマングル。
- フィルタリング情報:モジュール設定、モジュールデータおよびデータベースデータのみ。
結論
優れたAPIは、信頼性が高く、保守が容易で強力なアプリケーションを作成するための足がかりです。 この記事では、コンポーネントベースのAPIを強化する概念について説明しました。これは、かなり優れたAPIであると私は信じています。また、皆さんにも納得していただければ幸いです。
これまでのところ、APIの設計と実装には数回の反復が含まれ、5年以上かかりましたが、まだ完全には準備ができていません。 しかし、それはかなりまともな状態にあり、生産の準備ができていませんが、安定したアルファとしてです。 最近、私はまだそれに取り組んでいます。 オープン仕様の定義、追加レイヤーの実装(レンダリングなど)、およびドキュメントの作成に取り組んでいます。
今後の記事では、APIの実装がどのように機能するかについて説明します。 それまで、ポジティブかネガティブかに関係なく、何か考えがあれば、以下のコメントを読んでみたいと思います。
更新(1月31日):カスタムクエリ機能
Alain Schlesserは、クライアントからカスタムクエリを実行できないAPIは無価値であり、RESTまたはGraphQLと競合できないため、SOAPに戻るとコメントしました。 彼のコメントを数日間考えた後、私は彼が正しいことを認めなければなりませんでした。 ただし、コンポーネントベースのAPIを、善意であるがまだ十分ではない取り組みとして却下する代わりに、私はもっと良いことをしました。それに対してカスタムクエリ機能を実装する必要がありました。 そしてそれは魅力のように機能します!
次のリンクでは、リソースまたはリソースのコレクションのデータは、通常、RESTを介して行われるようにフェッチされます。 ただし、パラメータfieldsを使用して、リソースごとに取得する特定のデータを指定し、データのオーバーフェッチまたはアンダーフェッチを回避することもできます。
- パラメータ
fields=title,content,datetimeを追加する単一の投稿と投稿のコレクション - パラメータ
fields=name,username,descriptionを追加するユーザーとユーザーのコレクション
上記のリンクは、クエリされたリソースのデータのみをフェッチする方法を示しています。 彼らの関係はどうですか? たとえば、フィールド"title"と"content"を持つ投稿のリスト、フィールド"content"と"date"を持つ各投稿のコメント、およびフィールド"name"と"url" 」を持つ各コメントの作成者のリストを取得するとします。 "url" 。 GraphQLでこれを実現するには、次のクエリを実装します。
query { post { title content comments { content date author { name url } } } } コンポーネントベースのAPIを実装するために、クエリを対応する「ドット構文」式に変換しました。これは、パラメータfieldsから指定できます。 「投稿」リソースをクエリすると、この値は次のようになります。
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url または、 |を使用して簡略化することもできます。 同じリソースに適用されるすべてのフィールドをグループ化するには:
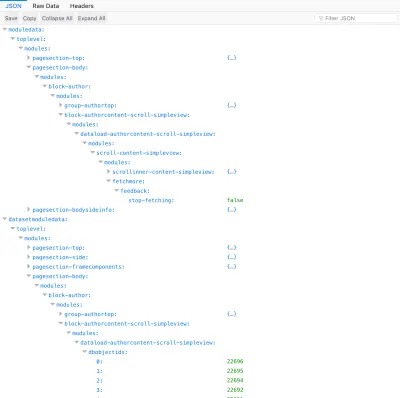
fields=title|content,comments.content|date,comments.author.name|urlこのクエリを単一の投稿で実行すると、関連するすべてのリソースに必要なデータが正確に取得されます。
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } したがって、REST方式でリソースをクエリし、GraphQL方式でスキーマベースのクエリを指定できます。データをオーバーフェッチまたはアンダーフェッチしたり、データが重複しないようにデータベース内のデータを正規化したりすることなく、必要なものを正確に取得できます。 好都合なことに、クエリには任意の数の関係を含めることができ、深くネストされ、これらは線形の複雑さの時間で解決されます。O(n + m)の最悪の場合、nはドメインを切り替えるノードの数です(この場合は2: commentsとcomments.author )およびmは、取得された結果の数(この場合、5:1投稿+2コメント+2ユーザー)、およびO(n)の平均ケースです。 (これは、多項式の複雑さの時間O(n ^ c)を持ち、レベルの深さが増すにつれて実行時間が長くなるという問題があるGraphQLよりも効率的です)。
最後に、このAPIは、データをクエリするときに修飾子を適用することもできます。たとえば、GraphQLを介して実行できるように、取得するリソースをフィルタリングするために使用できます。 これを実現するために、APIは単にアプリケーションの上に配置され、その機能を便利に使用できるため、車輪の再発明を行う必要はありません。 たとえば、パラメータfilter=posts&searchfor=internetを追加すると、投稿のコレクションから"internet"を含むすべての投稿がフィルタリングされます。
この新機能の実装については、今後の記事で説明します。