
HTTP / 3:パフォーマンスの向上(パート2)
公開: 2022-03-10新しいHTTP/3プロトコルに関するこのシリーズへようこそ。 パート1では、HTTP / 3と基盤となるQUICプロトコルが正確に必要な理由と、それらの主な新機能について説明しました。
この第2部では、QUICとHTTP/3がWebページの読み込みのためにテーブルにもたらすパフォーマンスの向上にズームインします。 ただし、実際にこれらの新機能から期待できる影響についても、ある程度懐疑的です。
後で説明するように、QUICとHTTP / 3は確かに優れたWebパフォーマンスの可能性を秘めていますが、主に低速ネットワークのユーザー向けです。 平均的な訪問者が高速ケーブルネットワークまたはセルラーネットワークを使用している場合、新しいプロトコルの恩恵はそれほど受けないでしょう。 ただし、通常はアップリンクが高速な国や地域でも、オーディエンスの最も遅い1%から10%(いわゆる99パーセンタイルまたは90パーセンタイル)でも、多くの利益を得る可能性があることに注意してください。 これは、HTTP / 3とQUICが主に、今日のインターネットで発生する可能性のある、やや珍しいが潜在的に影響の大きい問題に対処するのに役立つためです。
この部分は最初の部分よりも少し技術的ですが、実際に深いもののほとんどを外部ソースにオフロードし、これらが平均的なWeb開発者にとって重要である理由を説明することに焦点を当てています。
- パート1:HTTP/3の歴史とコアコンセプト
この記事は、HTTP / 3とプロトコル全般に不慣れな人を対象としており、主に基本について説明しています。 - パート2:HTTP/3パフォーマンス機能
これはより詳細で技術的です。 すでに基本を知っている人はここから始めることができます。 - パート3:実用的なHTTP/3デプロイメントオプション
シリーズのこの3番目の記事では、HTTP/3を自分でデプロイしてテストする際の課題について説明します。 Webページとリソースも変更する方法と必要があるかどうかについて詳しく説明します。
スピードの入門書
パフォーマンスと「速度」についての議論はすぐに複雑になる可能性があります。これは、基礎となる多くの側面がWebページの読み込みに「ゆっくり」貢献するためです。 ここではネットワークプロトコルを扱っているため、主にネットワークの側面を見ていきます。そのうち、遅延と帯域幅の2つが最も重要です。
遅延は、ポイントA(たとえばクライアント)からポイントB(サーバー)にパケットを送信するのにかかる時間として大まかに定義できます。 それは、光の速度、または実際には、信号がワイヤーまたは屋外でどれだけ速く伝わるかによって物理的に制限されます。 これは、レイテンシがAとBの間の物理的な実際の距離に依存することが多いことを意味します。
地球上では、これは一般的な遅延が概念的に小さく、約10〜200ミリ秒であることを意味します。 ただし、これは1つの方法にすぎません。パケットへの応答も返される必要があります。 双方向の遅延は、ラウンドトリップ時間(RTT)と呼ばれることがよくあります。
輻輳制御(以下を参照)などの機能により、1つのファイルをロードするためにかなりの数のラウンドトリップが必要になることがよくあります。 そのため、50ミリ秒未満の低遅延でも、かなりの遅延が発生する可能性があります。 これが、コンテンツ配信ネットワーク(CDN)が存在する主な理由の1つです。CDNは、遅延を減らして遅延を可能な限り減らすために、サーバーをエンドユーザーの物理的に近くに配置します。
したがって、帯域幅は、大まかに言って、同時に送信できるパケットの数と言えます。 これは、メディアの物理的特性(たとえば、使用される電波の周波数)、ネットワーク上のユーザー数、および異なるサブネットワークを相互接続するデバイス(通常、1秒あたり特定の数のパケットしか処理できません)。
よく使われる比喩は、水を運ぶために使われるパイプの比喩です。 パイプの長さはレイテンシーであり、パイプの幅は帯域幅です。 ただし、インターネット上では、通常、接続されたパイプの長いシリーズがあり、その一部は他のパイプよりも幅が広い場合があります(最も狭いリンクでのいわゆるボトルネックにつながります)。 そのため、ポイントAとBの間のエンドツーエンドの帯域幅は、最も遅いサブセクションによって制限されることがよくあります。
この投稿の残りの部分では、これらの概念を完全に理解する必要はありませんが、共通の高レベルの定義があると便利です。 詳細については、IlyaGrigorikの著書HighPerformanceBrowserNetworkingのレイテンシと帯域幅に関する優れた章を確認することをお勧めします。
輻輳制御
パフォーマンスの1つの側面は、トランスポートプロトコルがネットワークの完全な(物理的な)帯域幅をどれだけ効率的に使用できるか(つまり、1秒あたりのパケット数を送受信できるか)です。 これは、ページのリソースをダウンロードできる速度に影響します。 QUICはTCPよりもはるかに優れていると主張する人もいますが、そうではありません。
知ってますか?
たとえば、TCP接続は、全帯域幅でデータの送信を開始するだけではありません。これは、ネットワークに過負荷(または輻輳)を引き起こす可能性があるためです。 これは、前述したように、各ネットワークリンクには、毎秒(物理的に)処理できる一定量のデータしかないためです。 これ以上与えると、過剰なパケットをドロップする以外に選択肢がなく、パケット損失につながります。
パート1で説明したように、TCPのような信頼性の高いプロトコルの場合、パケット損失から回復する唯一の方法は、データの新しいコピーを再送信することです。これには1回のラウンドトリップが必要です。 特に高遅延ネットワーク(たとえば、RTTが50ミリ秒を超える)では、パケット損失がパフォーマンスに深刻な影響を与える可能性があります。
もう1つの問題は、最大帯域幅がどれくらいになるかを事前に知らないことです。 多くの場合、エンドツーエンド接続のどこかのボトルネックに依存しますが、これがどこにあるかを予測または知ることはできません。 インターネットには、リンク容量をエンドポイントに戻すためのメカニズムも(まだ)ありません。
さらに、利用可能な物理帯域幅を知っていたとしても、それをすべて自分たちで使用できるわけではありません。 通常、複数のユーザーが同時にネットワーク上でアクティブになり、各ユーザーは利用可能な帯域幅の公平なシェアを必要とします。
そのため、接続は、安全にまたは公平に使用できる帯域幅を事前に認識していません。この帯域幅は、ユーザーがネットワークに参加、離脱、および使用するときに変化する可能性があります。 この問題を解決するために、TCPは、輻輳制御と呼ばれるメカニズムを使用して、時間の経過とともに利用可能な帯域幅を常に検出しようとします。
接続の開始時に、わずか数パケット(実際には、10〜100パケット、または約14〜140 KBのデータ)を送信し、受信者がこれらのパケットの確認応答を返すまで1ラウンドトリップを待機します。 それらがすべて確認された場合、これはネットワークがその送信速度を処理できることを意味し、プロセスを繰り返すことを試みることができますが、より多くのデータを使用します(実際には、送信速度は通常、反復ごとに2倍になります)。
このように、送信レートは、一部のパケットが確認応答されなくなるまで増加し続けます(これは、パケット損失とネットワーク輻輳を示します)。 この最初のフェーズは通常、「スロースタート」と呼ばれます。 パケット損失が検出されると、TCPは送信レートを下げ、(しばらくすると)少しずつではありますが、送信レートを再び上げ始めます。 このreduce-then-growロジックは、その後、パケット損失ごとに繰り返されます。 最終的に、これはTCPが常に理想的で公平な帯域幅シェアに到達しようとすることを意味します。 このメカニズムを図1に示します。
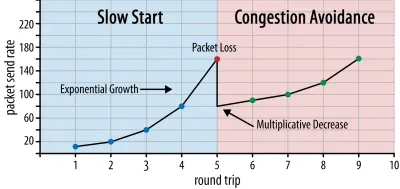
これは、輻輳制御の非常に単純化された説明です。 実際には、bufferbloat、輻輳によるRTTの変動、複数の同時送信者が帯域幅の公平なシェアを取得する必要があるという事実など、他の多くの要因が関係しています。 そのため、多くの異なる輻輳制御アルゴリズムが存在し、今日でも多くのアルゴリズムが発明されており、すべての状況で最適に機能するものはありません。
TCPの輻輳制御により堅牢になりますが、RTTと実際に使用可能な帯域幅によっては、最適な送信レートに到達するまでに時間がかかることも意味します。 Webページの読み込みの場合、最初の数回のラウンドトリップで転送できるデータは少量(数十から数百KB)であるため、このスロースタートアプローチは、最初のコンテンツの多いペイントなどのメトリックにも影響を与える可能性があります。 (重要なデータを14 KB未満に保つという推奨事項を聞いたことがあるかもしれません。)
したがって、より積極的なアプローチを選択すると、特に時折のパケット損失を気にしない場合は、高帯域幅および高遅延のネットワークでより良い結果が得られる可能性があります。 これは、QUICがどのように機能するかについて多くの誤解を再び見た場所です。
パート1で説明したように、QUICは理論上、各リソースのバイトストリームでパケット損失を個別に処理するため、パケット損失(および関連するヘッドオブライン(HOL)ブロッキング)の影響を受けにくくなります。 さらに、QUICはユーザーデータグラムプロトコル(UDP)上で実行されます。UDPはTCPとは異なり、輻輳制御機能が組み込まれていません。 それはあなたが望むどんな速度でも送信を試みることを可能にし、失われたデータを再送信しません。
これにより、QUICも輻輳制御を使用せず、代わりにQUICがUDPを介してはるかに高いレートでデータの送信を開始できる(パケット損失を処理するためにHOLブロッキングの削除に依存している)と主張する多くの記事があります。これが理由です。 QUICはTCPよりもはるかに高速です。
実際には、真実から遠く離れることはできません。QUICは、実際にはTCPと非常によく似た帯域幅管理手法を使用しています。 また、送信レートを低くして開始し、ネットワーク容量を測定するための主要なメカニズムとして確認応答を使用して、時間の経過とともに増加します。 これは(他の理由の中でも)、QUICがHTTPなどの何かに役立つために信頼できる必要があるため、他のQUIC(およびTCP!)接続に対して公平である必要があるため、およびそのHOLブロッキングの削除が行われないためです。実際には、パケット損失を防ぐのに役立ちます(以下で説明します)。
ただし、それは、QUICがTCPよりも帯域幅を管理する方法について(少し)賢くできないという意味ではありません。 これは主に、 QUICがTCPよりも柔軟性があり、進化しやすいためです。 すでに述べたように、輻輳制御アルゴリズムは今日でも大きく進化しており、たとえば、5Gを最大限に活用するために調整が必要になる可能性があります。
ただし、TCPは通常、オペレーティングシステム(OS)のカーネルに実装されます。これは、安全で制限の厳しい環境であり、ほとんどのOSではオープンソースでさえありません。 そのため、輻輳ロジックの調整は通常、選択した少数の開発者によってのみ行われ、進化は遅いです。
対照的に、ほとんどのQUIC実装は現在、「ユーザースペース」(通常はネイティブアプリを実行する場所)で行われており、オープンソースになっています。これは、はるかに幅広い開発者のプールによる実験を促進するためです(たとえば、Facebookなどですでに示されています)。 )。
もう1つの具体的な例は、QUICの遅延確認応答周波数拡張の提案です。 デフォルトでは、QUICは受信した2パケットごとに確認応答を送信しますが、この拡張機能により、エンドポイントは、たとえば10パケットごとに確認応答を行うことができます。 これは、確認応答パケットの送信のオーバーヘッドが低下するため、衛星および非常に高帯域幅のネットワークで大きな速度の利点をもたらすことが示されています。 TCPにこのような拡張機能を追加すると、採用されるまでに長い時間がかかりますが、QUICの場合は展開がはるかに簡単です。
そのため、QUICの柔軟性により、時間の経過とともにより多くの実験とより優れた輻輳制御アルゴリズムがもたらされ、TCPにバックポートして改善することも期待できます。
知ってますか?
公式のQUICRecoveryRFC 9002は、NewReno輻輳制御アルゴリズムの使用を指定しています。 このアプローチは堅牢ですが、やや時代遅れであり、実際には広く使用されていません。 では、なぜそれがQUIC RFCに含まれているのでしょうか? 最初の理由は、QUICが開始されたとき、NewRenoがそれ自体が標準化された最新の輻輳制御アルゴリズムであったことです。 BBRやCUBICなどのより高度なアルゴリズムは、まだ標準化されていないか、最近RFCになりました。
2番目の理由は、NewRenoが比較的単純なセットアップであるということです。 QUICとTCPの違いに対処するには、アルゴリズムにいくつかの調整が必要なため、より単純なアルゴリズムでこれらの変更を説明する方が簡単です。 そのため、RFC 9002は、「これがQUICに使用する必要があるもの」ではなく、「輻輳制御アルゴリズムをQUICに適合させる方法」として読む必要があります。 実際、ほとんどの本番レベルのQUIC実装では、CubicとBBRの両方のカスタム実装が行われています。
輻輳制御アルゴリズムはTCPまたはQUIC固有ではないことを繰り返し述べます。 それらはどちらのプロトコルでも使用でき、QUICの進歩が最終的にTCPスタックにも到達することを期待しています。
知ってますか?
輻輳制御の隣には、フロー制御と呼ばれる関連概念があることに注意してください。 これらの2つの機能は、実際には輻輳ウィンドウとTCP受信ウィンドウの2つのウィンドウがありますが、どちらも「TCPウィンドウ」を使用すると言われているため、TCPでは混同されることがよくあります。 ただし、フロー制御は、関心のあるWebページの読み込みのユースケースではあまり機能しないため、ここではスキップします。 より詳細な情報が利用可能です。
それはどういう意味ですか?
QUICは依然として物理法則に拘束されており、インターネット上の他の送信者に親切にする必要があります。 これは、TCPよりもはるかに速くWebサイトのリソースを魔法のようにダウンロードしないことを意味します。 ただし、QUICの柔軟性は、新しい輻輳制御アルゴリズムの実験が容易になることを意味します。これにより、TCPとQUICの両方で将来的に改善されるはずです。
0-RTT接続のセットアップ
2番目のパフォーマンスの側面は、新しい接続で有用なHTTPデータ(ページリソースなど)を送信できるようになるまでにかかるラウンドトリップの数です。 QUICはTCP+TLSよりも2〜3往復速いと主張する人もいますが、実際には1回だけであることがわかります。
知ってますか?
パート1で述べたように、接続は通常、HTTP要求と応答を交換する前に1つ(TCP)または2つ(TCP + TLS)のハンドシェイクを実行します。 これらのハンドシェイクは、たとえばデータを暗号化するためにクライアントとサーバーの両方が知る必要のある初期パラメーターを交換します。
下の図2に示すように、個々のハンドシェイクは、完了するまでに少なくとも1回(TCP + TLS 1.3、(b))、場合によっては2回(TLS 1.2以前(a))かかります。 これは非効率的です。最初のHTTPリクエストを送信する前に、ハンドシェイク待機時間(オーバーヘッド)を少なくとも2ラウンドトリップする必要があるためです。つまり、最初のHTTP応答データ(赤い矢印が返される)が来るまで少なくとも3ラウンドトリップ待機する必要があります。低速のネットワークでは、これは100〜200ミリ秒のオーバーヘッドを意味する可能性があります。
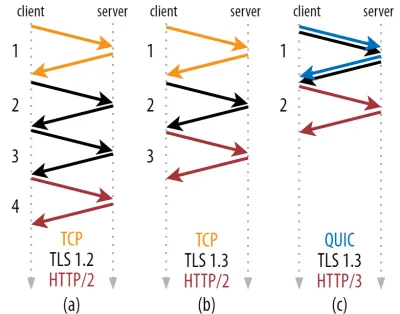
TCP + TLSハンドシェイクを単純に組み合わせて、同じラウンドトリップで実行できないのはなぜか疑問に思われるかもしれません。 これは概念的には可能ですが(QUICはまさにそれを行います)、TLSを使用する場合と使用しない場合でTCPを使用できる必要があるため、当初はこのように設計されていませんでした。 言い換えると、TCPは、ハンドシェイク中にTCP以外のものを送信することを単にサポートしていません。 TCPFastOpen拡張機能でこれを追加するための努力がなされてきました。 ただし、パート1で説明したように、これを大規模に展開することは困難であることが判明しました。
幸い、QUICは最初からTLSを念頭に置いて設計されていたため、トランスポートハンドシェイクと暗号化ハンドシェイクの両方を1つのメカニズムに組み合わせています。 これは、QUICハンドシェイクが完了するまでに合計で1回のラウンドトリップしか必要としないことを意味します。これは、TCP + TLS 1.3よりも1回のラウンドトリップです(上記の図2cを参照)。
QUICはTCPよりも2回または3回のラウンドトリップであり、1回だけではないことを読んだことがあるので、混乱するかもしれません。 これは、ほとんどの記事が最悪のケース(TCP + TLS 1.2、(a))のみを考慮しているためであり、最新のTCP + TLS 1.3も「たった2回の往復」であることに言及していません((b)はめったに表示されません)。 1往復のスピードブーストは素晴らしいですが、それは驚くべきことではありません。 特に高速ネットワーク(たとえば、50ミリ秒未満のRTT)では、これはほとんど目立たないでしょうが、低速のネットワークと離れたサーバーへの接続はもう少し利益があります。
次に、なぜハンドシェイクを待つ必要があるのか疑問に思われるかもしれません。 最初のラウンドトリップでHTTPリクエストを送信できないのはなぜですか? これは主に、その場合、最初のリクエストが暗号化されずに送信され、ネットワーク上の盗聴者が読み取り可能になるためです。これは、プライバシーとセキュリティにとって明らかに優れていません。 そのため、最初のHTTPリクエストを送信する前に、暗号化ハンドシェイクが完了するのを待つ必要があります。 それとも私たちですか?
これは、巧妙なトリックが実際に使用される場所です。 ユーザーは、最初にアクセスしてから短時間でWebページに再度アクセスすることがよくあります。 そのため、最初の暗号化された接続を使用して、将来2番目の接続をブートストラップできます。 簡単に言えば、その存続期間中のある時点で、最初の接続は、クライアントとサーバー間で新しい暗号化パラメーターを安全に通信するために使用されます。 これらのパラメータを使用すると、完全なTLSハンドシェイクが完了するのを待たずに、最初から2番目の接続を暗号化できます。 このアプローチは「セッション再開」と呼ばれます。
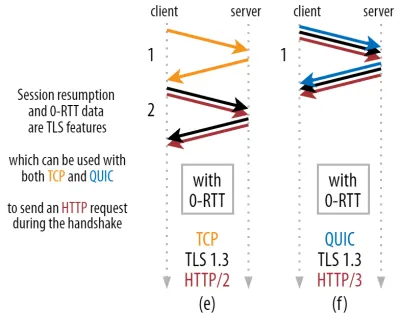
これにより、強力な最適化が可能になります。QUIC/ TLSハンドシェイクとともに最初のHTTPリクエストを安全に送信できるようになり、別のラウンドトリップを節約できます。 TLS 1.3の場合、これによりTLSハンドシェイクの待機時間が効果的になくなります。 このメソッドは、多くの場合0-RTTと呼ばれます(ただし、もちろん、HTTP応答データの到着を開始するのに1回のラウンドトリップが必要です)。
セッション再開と0-RTTはどちらも、QUIC固有の機能であると誤って説明されていることがよくあります。 実際には、これらは実際にはTLS 1.2に何らかの形ですでに存在していたTLS機能であり、現在はTLS1.3で完全に機能しています。
言い換えると、下の図3に示すように、TCP(したがって、HTTP / 2、さらにはHTTP / 1.1)よりもこれらの機能のパフォーマンス上の利点を得ることができます。 0-RTTを使用しても、QUICは最適に機能するTCP +TLS1.3スタックよりも1ラウンドトリップしか高速ではないことがわかります。 QUICが3往復速いという主張は、図2(a)と図3(f)を比較した結果です。これは、これまで見てきたように、実際には公平ではありません。
最悪の部分は、0-RTTを使用する場合、QUICは、セキュリティのために、往復で得られたものを実際に使用することさえできないことです。 これを理解するには、TCPハンドシェイクが存在する理由の1つを理解する必要があります。 まず、クライアントは、上位層のデータを送信する前に、指定されたIPアドレスでサーバーが実際に使用可能であることを確認できます。
次に、ここで非常に重要なことですが、サーバーは、接続を開いているクライアントが、データを送信する前に、実際に誰がどこにいるのかを確認できます。 パート1で4タプルとの接続をどのように定義したかを思い出すと、クライアントは主にそのIPアドレスによって識別されていることがわかります。 そして、これが問題です。IPアドレスがスプーフィングされる可能性があります。
攻撃者がHTTPoverQUIC0-RTTを介して非常に大きなファイルを要求したとします。 ただし、彼らはIPアドレスをスプーフィングし、0-RTT要求が被害者のコンピューターから送信されたように見せかけます。 これを下の図4に示します。 QUICサーバーは、IPがスプーフィングされたかどうかを検出する方法がありません。これは、そのクライアントから見た最初のパケットであるためです。

サーバーがスプーフィングされたIPに大きなファイルを送り返すだけの場合、被害者のネットワーク帯域幅が過負荷になる可能性があります(特に、攻撃者がこれらの偽の要求の多くを並行して実行した場合)。 QUIC応答は、受信データを予期しないため、被害者によってドロップされることに注意してください。ただし、それは問題ではありません。被害者のネットワークは依然としてパケットを処理する必要があります。
これはリフレクションまたは増幅攻撃と呼ばれ、ハッカーが分散型サービス拒否(DDoS)攻撃を実行する重要な方法です。 0-RTT over TCP + TLSが使用されている場合、これは発生しないことに注意してください。これは、0-RTT要求がTLSハンドシェイクと一緒に送信される前に、TCPハンドシェイクを最初に完了する必要があるためです。
そのため、 QUICは、0-RTT要求への応答を慎重に行う必要があり、クライアントが被害者ではなく実際のクライアントであることが確認されるまで、応答で送信するデータの量を制限します。 QUICの場合、このデータ量はクライアントから受信した量の3倍に設定されています。
言い換えると、QUICの最大「増幅率」は3であり、パフォーマンスの有用性とセキュリティリスクの間の許容可能なトレードオフであると判断されました(特に、増幅率が51,000倍を超える一部のインシデントと比較して)。 クライアントは通常、最初に1〜2パケットのみを送信するため、QUICサーバーの0-RTT応答はわずか4〜6 KB (他のQUICおよびTLSオーバーヘッドを含む)に制限されます。
さらに、他のセキュリティ問題により、たとえば「リプレイ攻撃」が発生する可能性があります。これにより、実行できるHTTPリクエストの種類が制限されます。 たとえば、Cloudflareは、0-RTTのクエリパラメータなしでHTTPGETリクエストのみを許可します。 これらは、0-RTTの有用性をさらに制限します。
幸い、QUICにはこれを少し改善するオプションがあります。 たとえば、サーバーは、0-RTTが以前に有効な接続があったIPからのものであるかどうかを確認できます。 ただし、これはクライアントが同じネットワーク上にある場合にのみ機能します(QUICの接続移行機能が多少制限されます)。 そして、それが機能したとしても、QUICの応答は、上で説明した輻輳コントローラーのスロースタートロジックによって制限されます。 したがって、1回の往復が節約される以外に、大幅な速度の向上はありません。
知ってますか?
QUICの3倍の増幅限界は、図2cの通常の非0-RTTハンドシェイクプロセスにもカウントされることに注意してください。 これは、たとえば、サーバーのTLS証明書が大きすぎて4〜6KBに収まらない場合に問題になる可能性があります。 その場合、分割する必要があり、2番目のチャンクは2番目のラウンドトリップが送信されるのを待つ必要があります(最初の数パケットの確認応答が入った後、クライアントのIPがスプーフィングされていないことを示します)。 この場合、 QUICのハンドシェイクはTCP+TLSに等しい2回のラウンドトリップを行うことになります。 これが、QUICの場合、証明書の圧縮などの手法が特に重要になる理由です。
知ってますか?
特定の高度なセットアップでは、これらの問題を十分に軽減して、0-RTTをより便利にすることができる可能性があります。 たとえば、サーバーは、クライアントが最後に表示されたときに使用可能だった帯域幅を記憶できるため、(スプーフィングされていない)クライアントを再接続するための輻輳制御のスロースタートによる制限が少なくなります。 これは学界で調査されており、QUICにはこれを行うための拡張が提案されています。 TCPを高速化するために、すでにいくつかの企業がこの種のことを行っています。
もう1つのオプションは、クライアントに1つまたは2つ以上のパケットを送信させることです(たとえば、パディング付きでさらに7つのパケットを送信します)。そのため、接続の移行後でも、3回の制限はより興味深い12〜14KBの応答に変換されます。 私はこれについて私の論文の1つに書いています。
最後に、(誤動作している)QUICサーバーは、安全であると感じた場合、または潜在的なセキュリティ問題を気にしない場合、意図的に3倍の制限を増やすこともできます(結局のところ、これを防ぐプロトコル警察はありません)。
それはどういう意味ですか?
0-RTTを使用したQUICのより高速な接続設定は、革新的な新機能というよりも、実際にはマイクロ最適化です。 最先端のTCP+TLS 1.3セットアップと比較すると、最大1回のラウンドトリップを節約できます。 最初のラウンドトリップで実際に送信できるデータの量は、セキュリティ上の考慮事項によってさらに制限されます。
そのため、この機能は、ユーザーが非常に待ち時間の長いネットワーク(たとえば、200ミリ秒を超えるRTTを備えた衛星ネットワーク)を使用している場合、または通常は多くのデータを送信しない場合に、主に役立ちます。 後者の例としては、キャッシュの多いWebサイトや、APIやDNS-over-QUICなどの他のプロトコルを介して定期的に小さな更新をフェッチするシングルページアプリがあります。 GoogleがQUICに対して非常に良好な0-RTT結果を確認した理由のひとつは、クエリ応答が非常に小さい、すでに高度に最適化された検索ページでそれをテストしたことです。
他の場合では、せいぜい数十ミリ秒しか得られません。すでにCDNを使用している場合はさらに少なくなります(パフォーマンスを気にする場合は、これを行う必要があります)。
接続の移行
3番目のパフォーマンス機能は、既存の接続をそのまま維持することにより、ネットワーク間で転送するときにQUICを高速化します。 これは確かに機能しますが、このタイプのネットワーク変更はそれほど頻繁には発生せず、接続は送信レートをリセットする必要があります。
パート1で説明したように、QUICの接続ID(CID)を使用すると、ネットワークを切り替えるときに接続の移行を実行できます。 大きなファイルのダウンロードを行いながら、クライアントがWi-Fiネットワークから4Gに移行することでこれを説明しました。 TCPでは、そのダウンロードを中止する必要があるかもしれませんが、QUICでは続行する可能性があります。
ただし、最初に、そのタイプのシナリオが実際に発生する頻度を検討してください。 これは、建物内のWi-Fiアクセスポイント間、または外出中にセルラータワー間を移動するときにも発生すると思われるかもしれません。 ただし、これらの設定では(正しく行われている場合)、ワイヤレス基地局間の移行は下位のプロトコルレイヤーで行われるため、デバイスは通常、IPをそのまま維持します。 そのため、完全に異なるネットワーク間を移動する場合にのみ発生しますが、それほど頻繁には発生しないと思います。
次に、これが大きなファイルのダウンロードやライブビデオ会議やストリーミング以外のユースケースでも機能するかどうかを尋ねることができます。 ネットワークを切り替えた瞬間にWebページをロードしている場合は、実際に(後の)リソースの一部を再要求する必要があるかもしれません。
ただし、ページの読み込みには通常数秒かかるため、ネットワークスイッチとの同時実行もあまり一般的ではありません。 さらに、これが差し迫った懸念事項であるユースケースでは、通常、他の緩和策がすでに実施されています。 たとえば、大きなファイルのダウンロードを提供するサーバーは、HTTP範囲要求をサポートして、再開可能なダウンロードを許可できます。
通常、ネットワーク1がドロップオフしてからネットワーク2が利用可能になるまでにある程度の重複時間が存在するため、ビデオアプリは複数の接続(ネットワークごとに1つ)を開き、古いネットワークが完全になくなる前にそれらを同期できます。 ユーザーは引き続き切り替えに気付くでしょうが、ビデオフィードが完全に削除されるわけではありません。
第三に、新しいネットワークが古いネットワークと同じくらい多くの帯域幅を利用できるという保証はありません。 そのため、概念的な接続が維持されていても、QUICサーバーはデータを高速で送信し続けることはできません。 代わりに、新しいネットワークの過負荷を回避するために、送信レートをリセット(または少なくとも低く)して、輻輳コントローラーのスロースタートフェーズで再開する必要があります。
この初期送信レートは通常、ビデオストリーミングなどを実際にサポートするには低すぎるため、QUICでも品質の低下や一時的な中断が発生します。 ある意味で、接続の移行とは、パフォーマンスの向上ではなく、サーバーでの接続コンテキストのチャーンとオーバーヘッドを防ぐことです。
知ってますか?
上記の0-RTTで説明したように、接続の移行を改善するための高度な手法を考案できることに注意してください。 たとえば、前回、特定のネットワークで使用可能な帯域幅を記憶し、新しい移行のためにそのレベルまでより速くランプアップすることを試みることができます。 さらに、単にネットワークを切り替えるだけでなく、両方を同時に使用することも想定できます。 この概念はマルチパスと呼ばれ、以下で詳しく説明します。
これまで、ユーザーが異なるネットワーク間を移動するアクティブな接続の移行について主に説明してきました。 ただし、特定のネットワーク自体がパラメータを変更するパッシブ接続移行の場合もあります。 この良い例は、ネットワークアドレス変換(NAT)の再バインドです。 NATの完全な説明はこの記事の範囲外ですが、これは主に、接続のポート番号が警告なしにいつでも変更される可能性があることを意味します。 これは、ほとんどのルーターでTCPよりもUDPの方がはるかに頻繁に発生します。
これが発生した場合、QUIC CIDは変更されず、ほとんどの実装では、ユーザーがまだ同じ物理ネットワーク上にいると想定するため、輻輳ウィンドウやその他のパラメーターはリセットされません。 QUICには、これが発生しないようにするためのPINGやタイムアウトインジケーターなどの機能も含まれています。これは通常、アイドル状態の長い接続で発生するためです。
パート1で、QUICはセキュリティ上の理由から単一のCIDを使用するだけではないことを説明しました。 代わりに、アクティブな移行を実行するときにCIDを変更します。 実際には、クライアントとサーバーの両方にCIDの個別のリスト(QUIC RFCでは送信元CIDと宛先CIDと呼ばれる)があるため、さらに複雑になります。 これを下の図5に示します。
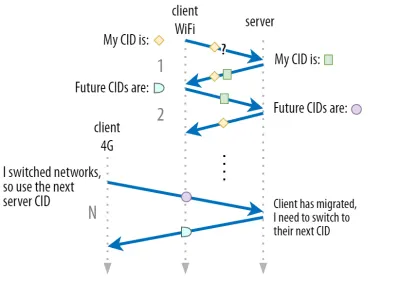
これは、各エンドポイントが独自のCID形式とコンテンツを選択できるようにするために行われます。これは、高度なルーティングと負荷分散ロジックを可能にするために重要です。 接続の移行により、ロードバランサーは4タプルを調べて接続を識別し、それを正しいバックエンドサーバーに送信することができなくなります。 ただし、すべてのQUIC接続でランダムCIDを使用する場合、CIDのマッピングをバックエンドサーバーに保存する必要があるため、ロードバランサーでのメモリ要件が大幅に増加します。 さらに、CIDが新しいランダムな値に変更されるため、これは接続の移行では機能しません。
そのため、ロードバランサーの背後にデプロイされたQUICバックエンドサーバーがCIDの予測可能な形式を備えていることが重要です。これにより、ロードバランサーは、移行後もCIDから正しいバックエンドサーバーを取得できます。 これを行うためのいくつかのオプションは、IETFの提案されたドキュメントに記載されています。 これをすべて可能にするには、サーバーが独自のCIDを選択できる必要があります。これは、接続イニシエーター(QUICの場合は常にクライアント)がCIDを選択した場合は不可能です。 これが、QUICでクライアントCIDとサーバーCIDの間に分割がある理由です。
それはどういう意味ですか?
したがって、接続の移行は状況に応じた機能です。 たとえば、Googleによる初期テストでは、ユースケースの改善率は低いことが示されています。 多くのQUIC実装はまだこの機能を実装していません。 そうするものでさえ、通常、それをモバイルクライアントとアプリに制限し、デスクトップの同等物には制限しません。 ほとんどの場合、0-RTTで新しい接続を開くと同様のパフォーマンス特性が得られるため、この機能は必要ないと考える人もいます。
それでも、ユースケースやユーザープロファイルによっては、大きな影響を与える可能性があります。 ウェブサイトやアプリが移動中に最も頻繁に使用される場合(たとえば、UberやGoogleマップなど)、ユーザーが通常机の後ろに座っている場合よりもメリットがあります。 Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
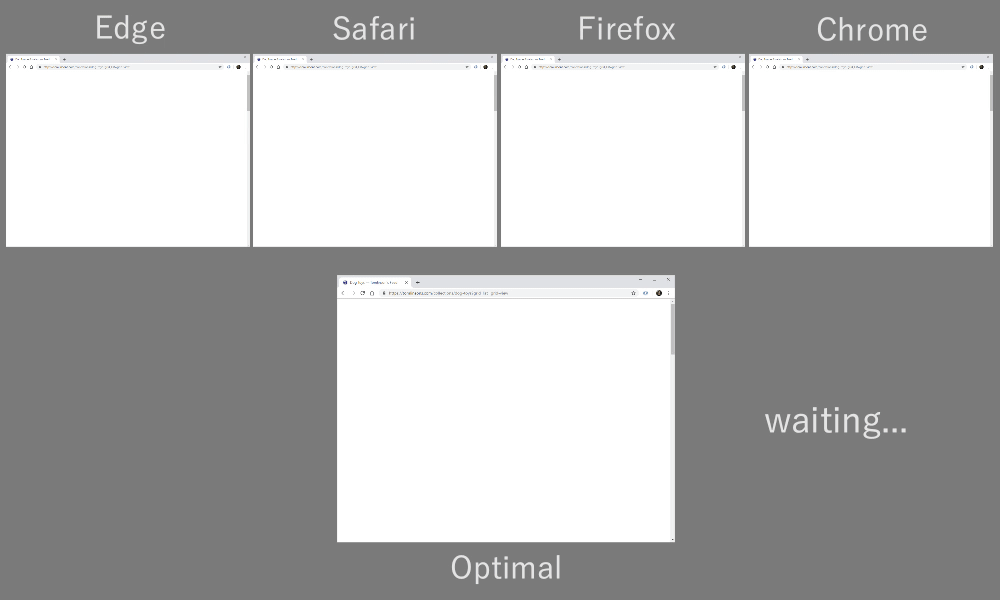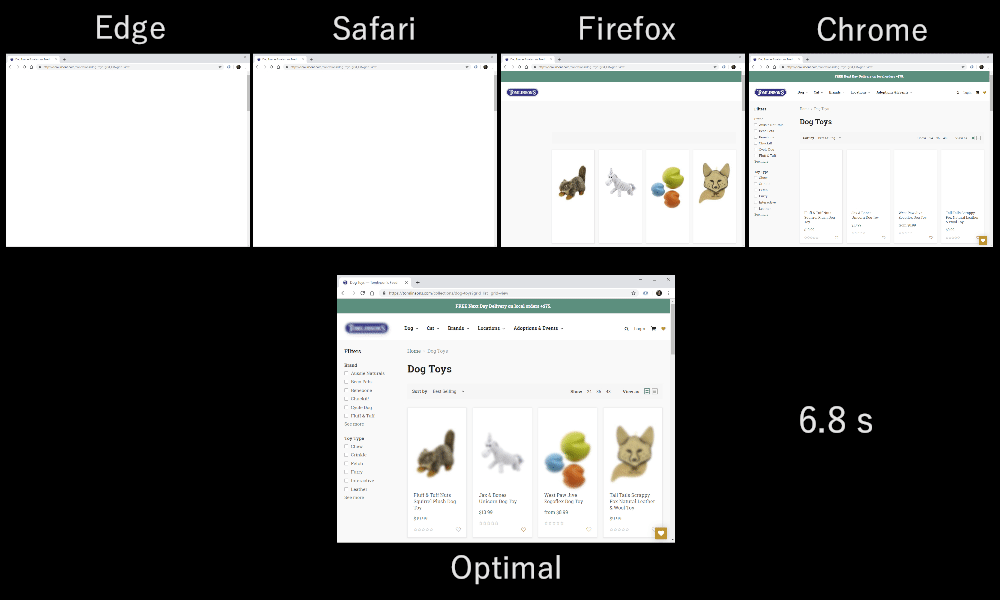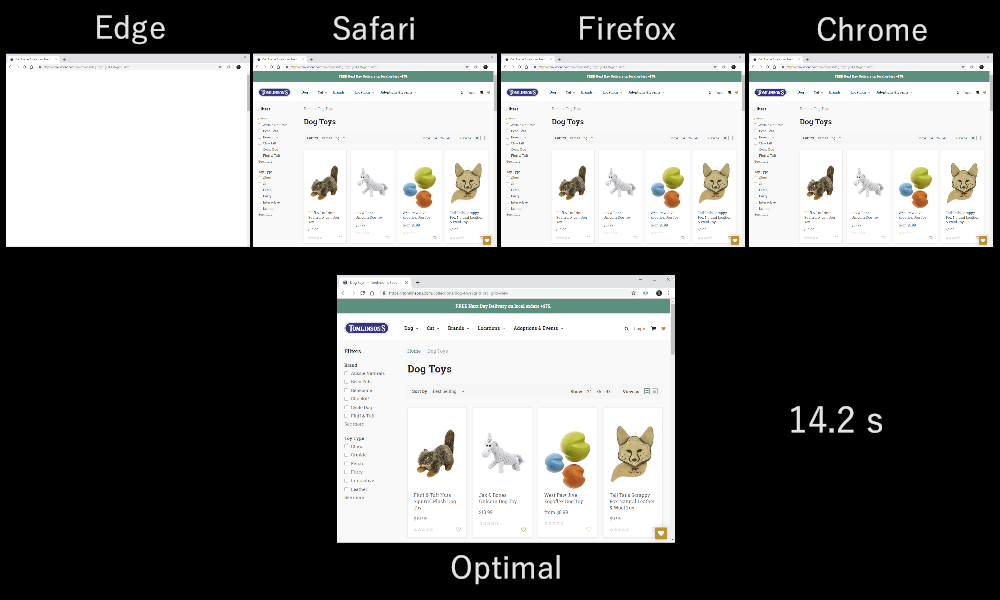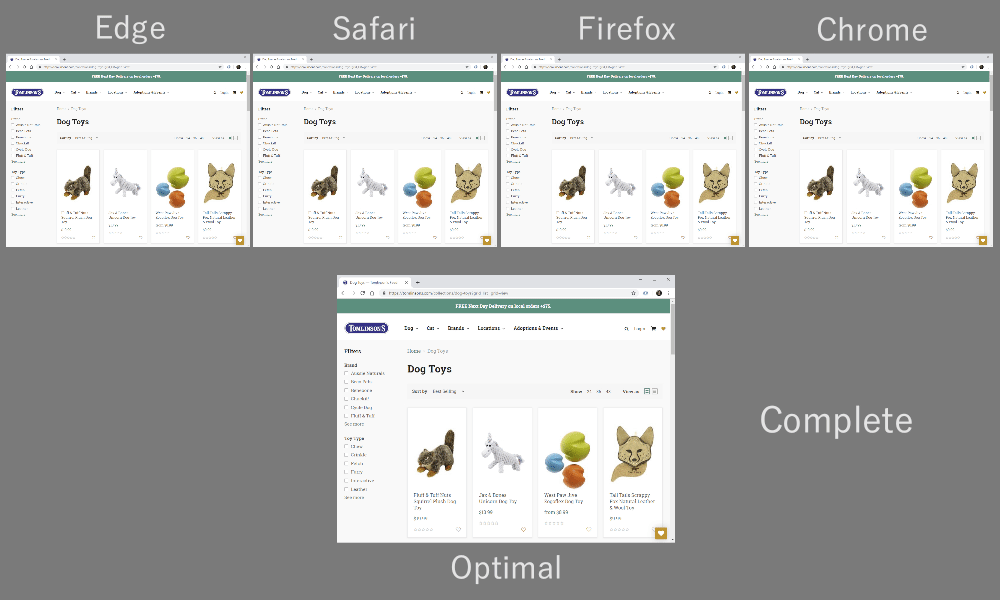
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).

What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
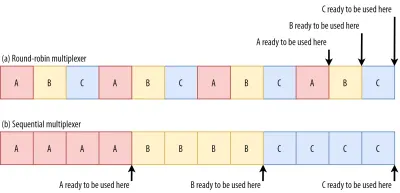
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
そしてそれは悪化します。 Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
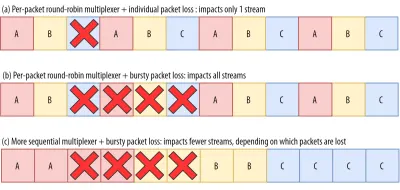
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
それはどういう意味ですか?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
UDPおよびTLSのパフォーマンス
QUICとHTTP/3の5番目のパフォーマンスの側面は、ネットワーク上で実際にパケットを作成して送信できる効率とパフォーマンスです。 QUICでUDPと高度な暗号化を使用すると、TCPよりもかなり遅くなる可能性があります(ただし、状況は改善されています)。
まず、QUICでのUDPの使用は、パフォーマンスよりも柔軟性と展開性に関するものであることはすでに説明しました。 これは、最近まで、UDPを介したQUICパケットの送信は、通常、TCPパケットの送信よりもはるかに遅いという事実によってさらに証明されています。 これは、これらのプロトコルが通常どこでどのように実装されているかが原因の1つです(下の図9を参照)。
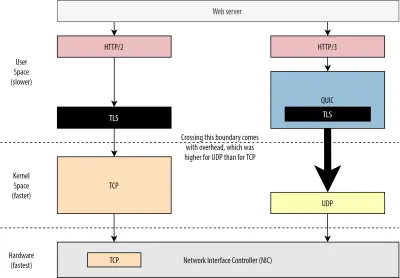
上で説明したように、TCPとUDPは通常、OSの高速カーネルに直接実装されます。 対照的に、TLSとQUICの実装は、ほとんどの場合、低速のユーザースペースにあります(これは、QUICには実際には必要ないことに注意してください。ほとんどの場合、柔軟性が高いために行われます)。 これにより、QUICはすでにTCPよりも少し遅くなります。
さらに、ユーザースペースソフトウェア(ブラウザーやWebサーバーなど)からデータを送信する場合は、このデータをOSカーネルに渡す必要があります。OSカーネルは、TCPまたはUDPを使用して実際にネットワークにデータを配置します。 このデータの受け渡しは、カーネルAPI(システムコール)を使用して行われます。これには、API呼び出しごとに一定量のオーバーヘッドが伴います。 TCPの場合、これらのオーバーヘッドはUDPの場合よりもはるかに低かった。
これは主に、歴史的にTCPがUDPよりもはるかに多く使用されてきたためです。 そのため、時間の経過とともに、パケットの送受信のオーバーヘッドを最小限に抑えるために、TCP実装とカーネルAPIに多くの最適化が追加されました。 多くのネットワークインターフェイスコントローラー(NIC)には、TCP用のハードウェアオフロード機能が組み込まれています。 ただし、UDPの使用が制限されているため、追加の最適化への投資が正当化されなかったため、UDPはそれほど幸運ではありませんでした。 過去5年間で、これは幸運にも変更され、ほとんどのOSはUDP用に最適化されたオプションも追加しました。
第二に、QUICは各パケットを個別に暗号化するため、多くのオーバーヘッドがあります。 これは、TLS over TCPを使用するよりも低速です。これは、パケットをチャンクで暗号化できるため(一度に最大約16 KBまたは11パケット)、より効率的です。 バルク暗号化は独自の形式のHoLブロッキングにつながる可能性があるため、これはQUICで行われた意識的なトレードオフでした。
UDP(したがってQUIC)を高速化するためにAPIを追加できる最初のポイントとは異なり、ここでは、QUICには常にTCP+TLSに固有の欠点があります。 ただし、これは実際には非常に管理しやすく、たとえば、最適化された暗号化ライブラリや、QUICパケットヘッダーを一括で暗号化できる巧妙な方法があります。
その結果、Googleの初期のQUICバージョンはTCP + TLSの2倍の速度でしたが、それ以来、状況は確実に改善されています。 たとえば、最近のテストでは、Microsoftの高度に最適化されたQUICスタックは7.85 Gbpsを取得できましたが、同じシステムでのTCP +TLSの場合は11.85Gbpsです(したがって、ここでは、QUICはTCP + TLSの約66%の速度です)。
これは、UDPを高速化した最近のWindows Updateによるものです(完全な比較のために、そのシステムのUDPスループットは19.5 Gbpsでした)。 GoogleのQUICスタックの最も最適化されたバージョンは、現在TCP + TLSよりも約20%低速です。 Fastlyによる以前のテストでは、それほど高度ではないシステムで、いくつかのトリックを使用して、同等のパフォーマンス(約450 Mbps)を主張しています。これは、ユースケースによっては、QUICがTCPと確実に競合できることを示しています。
ただし、QUICがTCP + TLSの2倍遅い場合でも、それほど悪くはありません。 まず、QUICおよびTCP + TLS処理は、他のロジック(HTTP、キャッシング、プロキシなど)も実行する必要があるため、通常、サーバーで発生する最も重い処理ではありません。 そのため、 QUICを実行するために実際には2倍のサーバーは必要ありません(ただし、大企業のいずれもこれに関するデータをリリースしていないため、実際のデータセンターにどの程度の影響があるかは少し不明です)。
第二に、将来的にQUICの実装を最適化する機会はまだたくさんあります。 たとえば、時間の経過とともに、一部のQUIC実装は(部分的に)OSカーネルに移行するか(TCPのように)、それをバイパスします(MsQuicやQuantのようにすでに移行しているものもあります)。 また、QUIC固有のハードウェアが利用可能になることも期待できます。
それでも、TCP+TLSが引き続き推奨されるオプションとなるユースケースがいくつかある可能性があります。 たとえば、Netflixは、TCP + TLSを介してビデオをストリーミングするためのカスタムFreeBSDセットアップに多額の投資を行っているため、すぐにQUICに移行することはおそらくないだろうと述べています。
同様に、Facebookは、QUICはおそらく主にエンドユーザーとCDNのエッジ間で使用されると述べていますが、オーバーヘッドが大きいため、データセンター間やエッジノードとオリジンサーバー間では使用されません。 一般に、非常に高い帯域幅のシナリオでは、特に今後数年間、TCP+TLSが引き続き使用される可能性があります。
知ってますか?
ネットワークスタックの最適化は、深くて技術的なうさぎの穴であり、上記は表面を傷つけるだけです(そして多くのニュアンスを見逃しています)。 勇気がある場合、またはGRO/GSO、SO_TXTIME、カーネルバイパス、sendmmsg()、recvmmsg()()などの用語の意味を知りたい場合は、CloudflareとFastlyによるQUICの最適化に関する優れた記事もお勧めします。 Microsoftによる広範なコードウォークスルー、およびCiscoからの詳細な講演として。 最後に、Googleのエンジニアが、QUICの実装を長期的に最適化することについて非常に興味深い基調講演を行いました。
それはどういう意味ですか?
QUICのUDPおよびTLSプロトコルの特定の使用法は、歴史的にTCP+TLSよりもはるかに遅くなっています。 ただし、時間の経過とともに、ギャップをいくらか埋めるいくつかの改善が行われました(そして引き続き実装されます)。 Webページの読み込みの一般的な使用例では、これらの不一致に気付かないかもしれませんが、大規模なサーバーファームを維持している場合は、頭痛の種になる可能性があります。
HTTP/3の機能
これまで、主にQUICとTCPの新しいパフォーマンス機能について説明してきました。 しかし、HTTP/3とHTTP/2はどうですか? パート1で説明したように、 HTTP/3は実際にはHTTP/2-over-QUICであるため、新しいバージョンでは実際の大きな新機能は導入されていません。 これは、HTTP/1.1からHTTP/2への移行とは異なります。これは、はるかに大きく、ヘッダー圧縮、ストリームの優先順位付け、サーバープッシュなどの新機能を導入したものです。 これらの機能はすべてHTTP/3に残っていますが、内部での実装方法にはいくつかの重要な違いがあります。
これは主に、QUICによるHoLブロッキングの削除がどのように機能するかによるものです。 すでに説明したように、ストリームBでの損失は、TCPを介した場合のように、ストリームAとCがBの再送信を待機する必要があることを意味しなくなりました。 そのため、A、B、CがそれぞれQUICパケットをこの順序で送信した場合、それらのデータはA、C、Bとしてブラウザに配信(および処理)される可能性があります。 言い換えると、TCPとは異なり、QUICは異なるストリーム間で完全に順序付けられなくなりました。
これは、データチャンクに散在する特別な制御メッセージを使用する多くの機能の設計においてTCPの厳密な順序に実際に依存していたHTTP/2の問題です。 QUICでは、これらの制御メッセージは任意の順序で到着(および適用)される可能性があり、機能が意図したものと反対の動作をする可能性さえあります! 繰り返しになりますが、この記事では技術的な詳細は不要ですが、このペーパーの前半では、これがいかにばかげて複雑になるかについてのアイデアが得られるはずです。
そのため、HTTP / 3では、機能の内部メカニズムと実装を変更する必要がありました。 具体的な例は、 HTTPヘッダー圧縮です。これにより、繰り返される大きなHTTPヘッダー(Cookieやユーザーエージェント文字列など)のオーバーヘッドが削減されます。 HTTP / 2では、これはHPACKセットアップを使用して行われましたが、HTTP / 3では、これはより複雑なQPACKに作り直されました。 どちらのシステムも同じ機能(つまり、ヘッダー圧縮)を提供しますが、方法はまったく異なります。 このトピックに関するいくつかの優れた深い技術的な議論と図は、Litespeedブログで見つけることができます。
ストリーム多重化ロジックを駆動する優先順位付け機能についても同様のことが当てはまります。これについては、上記で簡単に説明しました。 HTTP / 2では、これは複雑な「依存関係ツリー」設定を使用して実装され、すべてのページリソースとそれらの相互関係を明示的にモデル化しようとしました(詳細については、「HTTPリソースの優先順位付けの究極のガイド」を参照してください)。 このシステムをQUICで直接使用すると、ツリーに各リソースを追加すると個別の制御メッセージになるため、非常に間違ったツリーレイアウトになる可能性があります。
さらに、このアプローチは不必要に複雑であることが判明し、多くの実装のバグと非効率性、および多くのサーバーでのパフォーマンスの低下につながりました。 どちらの問題も、優先順位付けシステムをはるかに簡単な方法でHTTP/3用に再設計することになりました。 このより簡単な設定により、一部の高度なシナリオを実施することが困難または不可能になります(たとえば、単一の接続で複数のクライアントからのトラフィックをプロキシする)が、Webページの読み込みを最適化するための幅広いオプションが可能になります。
繰り返しになりますが、2つのアプローチは同じ基本機能(ガイドストリームの多重化)を提供しますが、HTTP / 3のセットアップが簡単になると、実装のバグが少なくなることが期待されます。
最後に、サーバープッシュがあります。 この機能により、サーバーは最初に明示的な要求を待たずにHTTP応答を送信できます。 理論的には、これにより優れたパフォーマンスの向上がもたらされる可能性があります。 ただし、実際には、正しく使用するのは難しく、一貫性のない実装であることが判明しました。 結果として、それはおそらくグーグルクロームから削除されるでしょう。
これらすべてにもかかわらず、HTTP / 3の機能として定義されています(ただし、サポートしている実装はほとんどありません)。 内部の動作は前の2つの機能ほど変更されていませんが、QUICの非決定論的な順序を回避するように調整されています。 残念ながら、しかし、これはその長年の問題のいくつかを解決するためにほとんど何もしません。
それはどういう意味ですか?
前に述べたように、HTTP / 3の可能性のほとんどは、HTTP / 3自体ではなく、基盤となるQUICに由来します。 プロトコルの内部実装はHTTP/2のものとは大きく異なりますが、その高レベルのパフォーマンス機能と、それらを使用できる方法と使用すべき方法は同じままです。
注目すべき将来の展開
このシリーズでは、より速い進化とより高い柔軟性がQUIC(そして、ひいてはHTTP / 3)のコアな側面であることを定期的に強調しました。 そのため、人々がプロトコルの新しい拡張機能やアプリケーションにすでに取り組んでいるのは当然のことです。 以下にリストされているのは、おそらくどこかで遭遇するであろう主なものです:
前方誤り訂正
この手法のこの目的は、パケット損失に対するQUICの回復力を向上させることです。 これは、データの冗長コピーを送信することによって行われます(ただし、データがそれほど大きくならないように巧妙にエンコードおよび圧縮されています)。 その後、パケットが失われたが冗長データが到着した場合、再送信は不要になります。
これは元々GoogleQUICの一部でした(そしてQUICがパケット損失に対して優れていると人々が言う理由の1つです)が、パフォーマンスへの影響がまだ証明されていないため、標準化されたQUICバージョン1には含まれていません。 ただし、研究者は現在それを使って活発な実験を行っています。PQUIC-FECダウンロード実験アプリを使用して彼らを助けることができます。マルチパスQUIC
接続の移行と、たとえばWi-Fiからセルラーに移行するときにどのように役立つかについては前に説明しました。 ただし、それはWi-Fiと携帯電話の両方を同時に使用する可能性があることも意味しませんか? 両方のネットワークを同時に使用すると、利用可能な帯域幅が増え、堅牢性が向上します。 これがマルチパスの背後にある主要な概念です。
これもまた、Googleが実験したものですが、固有の複雑さのためにQUICバージョン1にはなりませんでした。 ただし、その後、研究者はその高い可能性を示しており、QUICバージョン2になる可能性があります。TCPマルチパスも存在しますが、実用化されるまでには10年近くかかります。QUICおよびHTTP/3を介した信頼性の低いデータ
これまで見てきたように、QUICは完全に信頼できるプロトコルです。 ただし、信頼性の低いUDP上で実行されるため、QUICに機能を追加して、信頼性の低いデータを送信することもできます。 これは、提案されたデータグラム拡張で概説されています。 もちろん、これを使用してWebページのリソースを送信することは望ましくありませんが、ゲームやライブビデオストリーミングなどには便利な場合があります。 このようにして、ユーザーはUDPのすべての利点を享受できますが、QUICレベルの暗号化と(オプションの)輻輳制御が利用できます。WebTransport
ブラウザは、主にセキュリティ上の懸念から、TCPまたはUDPをJavaScriptに直接公開しません。 代わりに、FetchなどのHTTPレベルのAPIと、やや柔軟なWebSocketおよびWebRTCプロトコルに依存する必要があります。 この一連のオプションの最新のものはWebTransportと呼ばれ、主にHTTP / 3(および拡張によりQUIC)をより低レベルの方法で使用できるようにします(ただし、必要に応じてTCPおよびHTTP /2にフォールバックすることもできます) )。
重要なのは、HTTP / 3を介して信頼性の低いデータを使用する機能が含まれることです(前のポイントを参照)。これにより、ゲームなどをブラウザーに実装するのがかなり簡単になります。 もちろん、通常の(JSON)API呼び出しでは、引き続きFetchを使用します。これにより、可能な場合は自動的にHTTP/3も使用されます。 WebTransportは現在まだ激しい議論が行われているため、最終的にどのようになるかはまだ明確ではありません。 ブラウザのうち、Chromiumのみが現在パブリックプルーフオブコンセプトの実装に取り組んでいます。DASHおよびHLSビデオストリーミング
非ライブビデオ(YouTubeやNetflixなど)の場合、ブラウザーは通常、動的アダプティブストリーミングオーバーHTTP(DASH)またはHTTPライブストリーミング(HLS)プロトコルを使用します。 どちらも基本的に、ビデオを小さなチャンク(2〜10秒)とさまざまな品質レベル(720p、1080p、4Kなど)にエンコードすることを意味します。
実行時に、ブラウザはネットワークが処理できる最高の品質(または特定のユースケースに最適)を推定し、HTTPを介してサーバーに関連ファイルを要求します。 ブラウザはTCPスタックに直接アクセスできないため(通常はカーネルに実装されているため)、これらの見積もりにいくつかの間違いを犯したり、ネットワークの状態の変化に対応するのに時間がかかる(ビデオのストールにつながる)ことがあります。 。
QUICはブラウザの一部として実装されているため、ストリーミング見積もり担当者が低レベルのプロトコル情報(損失率、帯域幅見積もりなど)にアクセスできるようにすることで、これを大幅に改善できます。 他の研究者は、ビデオストリーミングにも信頼できるデータと信頼できないデータを混合することを試みており、いくつかの有望な結果が得られています。HTTP/3以外のプロトコル
QUICは汎用トランスポートプロトコルであるため、TCP上で実行されるようになった多くのアプリケーション層プロトコルがQUIC上でも実行されることが期待できます。 進行中の作業には、DNS-over-QUIC、SMB-over-QUIC、さらにはSSH-over-QUICが含まれます。 これらのプロトコルには通常、HTTPやWebページの読み込みとは非常に異なる要件があるため、これまでに説明したQUICのパフォーマンスの向上は、これらのプロトコルではるかにうまく機能する可能性があります。
それはどういう意味ですか?
QUICバージョン1はほんの始まりに過ぎません。 Googleが以前に実験した多くの高度なパフォーマンス指向の機能は、この最初のイテレーションにはなりませんでした。 ただし、目標はプロトコルを迅速に進化させ、新しい拡張機能と機能を高頻度で導入することです。 そのため、時間の経過とともに、QUIC(およびHTTP / 3)は、TCP(およびHTTP / 2)よりも明らかに高速で柔軟になるはずです。
結論
シリーズのこの第2部では、HTTP / 3、特にQUICのさまざまなパフォーマンス機能と側面について説明しました。 これらの機能のほとんどは非常に影響力があるように見えますが、実際には、これまで検討してきたWebページの読み込みのユースケースでは、平均的なユーザーにはそれほど効果がない可能性があります。
たとえば、QUICがUDPを使用しているからといって、TCPよりも突然多くの帯域幅を使用できるわけではなく、リソースをより迅速にダウンロードできるわけでもありません。 よく称賛される0-RTT機能は、実際には1回の往復を節約するマイクロ最適化であり、約5 KB(最悪の場合)を送信できます。
バーストパケット損失がある場合、またはレンダリングブロッキングリソースをロードしている場合、HoLブロッキングの削除はうまく機能しません。 接続の移行は非常に状況に応じて行われ、HTTP/3にはHTTP/2よりも高速化できる主要な新機能はありません。
そのため、HTTP/3とQUICをスキップすることをお勧めします。 なんでわざわざね? しかし、私は間違いなくそのようなことはしません! これらの新しいプロトコルは、高速(都市)ネットワークのユーザーにはあまり役立たないかもしれませんが、新しい機能は、モバイル性の高いユーザーや低速ネットワークのユーザーに大きな影響を与える可能性があります。
私自身のベルギーのような西側の市場でも、一般的に高速デバイスと高速セルラーネットワークへのアクセスがありますが、これらの状況は、製品によってはユーザーベースの1%から10%にさえ影響を与える可能性があります。 例としては、電車の中で誰かがあなたのWebサイトで重要な情報を必死に調べようとしているが、それがロードされるまで45秒待たなければならない場合があります。 私は確かに私がそのような状況にあったことを知っています、誰かが私をそれから抜け出すためにQUICを展開したことを望みました。
しかし、事態がさらに悪化している国や地域は他にもあります。 そこでは、平均的なユーザーはベルギーで最も遅い10%のように見える可能性があり、最も遅い1%はロードされたページをまったく見ることができない可能性があります。 世界の多くの地域で、Webパフォーマンスはアクセシビリティと包括性の問題です。
これが、自分のハードウェアでページをテストするだけでなく(Webpagetestなどのサービスも使用する)、 QUICとHTTP/3を確実にデプロイする必要がある理由です。 特に、ユーザーが頻繁に移動している場合や、高速セルラーネットワークにアクセスする可能性が低い場合は、ケーブル接続されたMacBook Proにあまり気づかなくても、これらの新しいプロトコルによって世界が変わる可能性があります。 詳細については、この問題に関するFastlyの投稿を強くお勧めします。
それでも十分に納得できない場合は、QUICとHTTP / 3が今後も進化し、高速化することを考慮してください。 プロトコルの初期の経験を積むことは、将来的に報われるでしょう、あなたができるだけ早く新機能の利益を享受することを可能にします。 さらに、QUICはバックグラウンドでセキュリティとプライバシーのベストプラクティスを実施し、あらゆる場所のすべてのユーザーに利益をもたらします。
ついに納得しましたか? 次に、シリーズのパート3に進み、新しいプロトコルを実際に使用する方法について説明します。
- パート1:HTTP/3の歴史とコアコンセプト
この記事は、HTTP / 3とプロトコル全般に不慣れな人を対象としており、主に基本について説明しています。 - パート2:HTTP/3パフォーマンス機能
これはより詳細で技術的です。 すでに基本を知っている人はここから始めることができます。 - パート3:実用的なHTTP/3デプロイメントオプション
シリーズのこの3番目の記事では、HTTP/3を自分でデプロイしてテストする際の課題について説明します。 Webページとリソースも変更する方法と必要があるかどうかについて詳しく説明します。