
GraphQL入門書:新しい種類のAPIが必要な理由(パート1)
公開: 2022-03-10このシリーズでは、GraphQLを紹介します。 最後に、それが何であるかだけでなく、その起源、欠点、およびそれを操作する方法の基本も理解する必要があります。 この最初の記事では、実装に飛び込むのではなく、RPCから現在までの過去60年間のAPI開発から学んだ教訓を見て、GraphQL(および同様のツール)に到達した方法と理由について説明したいと思います。 結局のところ、マーク・トウェインがカラフルに説明したように、新しいアイデアはありません。
「新しいアイデアというものはありません。それは不可能です。私たちは単にたくさんの古いアイデアを取り入れて、一種の精神的な万華鏡に入れます。」
—「マークトウェイン自身の自伝:北米レビューの章」のマークトウェイン
しかし、最初に、私は部屋の中の象に話しかける必要があります。 新しいものは常にエキサイティングですが、疲れを感じることもあります。 GraphQLについて聞いたことがあるかもしれませんが、「なぜ…」と思ったかもしれません。あるいは、「なぜ新しいAPIデザインのトレンドを気にするのか? RESTは…大丈夫です。」 これらは正当な質問なので、なぜこれに注意を払う必要があるのかを説明させてください。
序章
チームに新しいツールを導入することのメリットは、そのコストと比較検討する必要があります。 測定するものはたくさんあります。 学習にかかる時間、変換にかかる時間、機能開発、2つのシステムを維持するためのオーバーヘッドがあります。 このようにコストが高いため、新しいテクノロジーは、より優れた、より高速な、またはより生産性の高いものでなければなりません。 漸進的な改善は、刺激的ではありますが、投資する価値はありません。 私が話したいAPIの種類、特にGraphQLは、私の意見では大きな前進であり、コストを正当化するのに十分なメリットを提供します。
最初に機能を調べるのではなく、機能をコンテキストに入れて、それらがどのように存在するようになったのかを理解することが役立ちます。 これを行うために、APIの歴史を少し要約することから始めます。
RPC
RPCは、間違いなく最初の主要なAPIパターンであり、その起源は60年代半ばの初期のコンピューティングにまでさかのぼります。 当時、コンピューターはまだ非常に大きくて高価だったため、API主導のアプリケーション開発の概念は、私たちが考えるように、ほとんど理論的なものでした。 帯域幅/遅延、計算能力、共有計算時間、物理的な近接性などの制約により、エンジニアはデータを公開するサービスではなく、分散システムの観点から考える必要がありました。 60年代のARPANETから90年代半ばまで、CORBAやJavaのRMIなどを使用して、ほとんどのコンピューターは、クライアントがプロシージャを実行するクライアント/サーバー相互作用モデルであるリモートプロシージャコール(RPC)を使用して相互に対話しました。 (またはメソッド)リモートサーバーで実行します。
RPCには多くの優れた点があります。 その主な原則は、開発者がリモート環境のコードをローカル環境にあるかのように扱うことを可能にすることです。 ARPANETから出てきた多くのものと同様に、このタイプの継続性は、DBアクセスや外部サービス呼び出しなどの信頼性の低い非同期アクションを処理するときに私たちがまだ努力しているものであるため、時代を先取りしていました。
何十年にもわたって、開発者がこのような非同期動作をプログラムの典型的なフローに組み込むことができるようにする方法について、膨大な量の研究が行われてきました。 当時、Promises、Futures、ScheduledTasksなどが利用可能であった場合、APIランドスケープが異なって見える可能性があります。
RPCのもう1つの優れた点は、データの構造に制約されないため、必要な情報を正確に要求および取得するクライアント向けに高度に特殊化されたメソッドを記述できることです。これにより、ネットワークオーバーヘッドを最小限に抑え、ペイロードを小さくすることができます。
ただし、RPCを困難にするものがあります。 まず、継続性にはコンテキストが必要です。 RPCは、設計上、ローカルシステムとリモートシステムの間に非常に多くの結合を作成します。ローカルコードとリモートコードの境界が失われます。 一部のドメインでは、これはクライアントSDKのように問題ないか、または好まれますが、クライアントコードが十分に理解されていないAPIの場合、よりデータ指向のものよりも柔軟性が大幅に低下する可能性があります。
ただし、より重要なのは、APIメソッドの急増の可能性です。 理論的には、RPCサービスは、あらゆるタスクを処理できる小さな思慮深いAPIを公開します。 実際には、多くの構造がなくても、膨大な数の外部エンドポイントが蓄積する可能性があります。 チームメンバーが行き来し、プロジェクトがピボットするときに、APIの重複や時間の経過による重複を防ぐには、非常に多くの規律が必要です。
確かに、私が述べたような適切なツールとドキュメントの変更で管理できますが、ソフトウェアを作成しているときに、自動ドキュメントと統制のとれたサービスに出くわしたことはほとんどありません。赤いニシン。
石鹸
次に登場する主要なAPIタイプはSOAPで、これは90年代後半にMicrosoftResearchで誕生しました。 SOAP( S imple O bject A ccess P rotocol)は、アプリケーション間のXMLベースの通信のための野心的なプロトコル仕様です。 SOAPが表明した野心は、複雑なWebサービスの適切に構造化された基盤を作成することにより、RPC、特にXML-RPCの実際的な欠点のいくつかに対処することでした。 事実上、これは単に動作型システムをXMLに追加することを意味していました。 悲しいことに、今日作成された新しいSOAPエンドポイントが非常に少ないという事実からも明らかなように、解決したよりも多くの障害が発生しました。
「SOAPは、ほとんどの人が中程度の成功と見なすものです。」
—ドンボックス
SOAPは、その耐え難い冗長性とひどい名前にもかかわらず、いくつかの良いことを行っていました。 クライアントとサーバー間のWSDLとWADLの強制可能なコントラクト(「wizdle」と「waddle」と発音)は、予測可能でタイプセーフな結果を保証し、WSDLを使用して、ドキュメントを生成したり、IDEやその他のツールとの統合を作成したりできます。
APIの進化に関するSOAPの大きな啓示は、よりリソース指向の呼び出しが徐々に、場合によっては意図せずに導入されたことです。 SOAPエンドポイントを使用すると、データの生成に必要なメソッドについて考えるのではなく、事前に定義された構造でデータを要求できます(このように記述されていると仮定します)。
SOAPの最も重大な欠点は、非常に冗長であることです。 多くの工具なしで使用することはほぼ不可能です。 テストを作成するためのツール、サーバーからの応答を検査するためのツール、およびすべてのデータを解析するためのツールが必要です。 多くの古いシステムは依然としてSOAPを使用していますが、ツールの要件により、ほとんどの新しいプロジェクトでは煩雑になり、XML構造に必要なバイト数により、モバイルデバイスやおしゃべりな分散システムにサービスを提供するのに適していません。
詳細については、SOAPの仕様と、元のチームメンバーの1人であるDonBoxの驚くほど興味深いSOAPの歴史を読む価値があります。
残り
最後に、APIデザインパターンdu jour:RESTに到達しました。 2000年にロイフィールディングによって博士論文で紹介されたRESTは、振り子をまったく異なる方向に振りました。 RESTは、多くの点で、SOAPのアンチテーゼであり、それらを並べて見ると、彼の論文が少し怒り狂ったように感じます。
SOAPはHTTPをダムトランスポートとして使用し、要求と応答の本文にその構造を構築します。 一方、RESTは、クライアント/サーバーコントラクト、ツール、XML、および特注のヘッダーを破棄し、HTTP動詞を使用する代わりに構造を選択するため、HTTPセマンティクスに置き換えます。データ。
| 石鹸 | 残り | |
|---|---|---|
| HTTP動詞 | GET、PUT、POST、PATCH、DELETE | |
| データ形式 | XML | あなたが望むものなら、なんでも |
| クライアント/サーバー契約 | 一日中 '毎日! | それらを必要とする人 |
| 型システム | JavaScriptはunsignedshort rightですか? | |
| URL | 操作の説明 | 名前付きリソース |
RESTは、API設計を、相互作用のモデリングからドメインのデータの単純なモデリングに完全かつ明示的に変更します。 REST APIを使用するときに完全にリソース指向であるため、特定のデータを取得するために何が必要かを知る必要も、気にする必要もありません。 また、バックエンドサービスの実装について何も知る必要はありません。

シンプルさは開発者にとって恩恵であるだけでなく、URLは安定した情報を表すため、簡単にキャッシュでき、ステートレスであるため水平方向のスケーリングが容易であり、消費者のニーズを予測するのではなくデータをモデル化するため、APIの表面積を大幅に削減できます。 。
RESTは素晴らしく、その遍在性は驚くべき成功ですが、RESTの前に登場したすべてのソリューションと同様に、RESTにも欠点があります。 その欠点のいくつかについて具体的に話すために、基本的な例を見てみましょう。 ブログ投稿のリストとその作成者の名前を表示するブログのランディングページを作成する必要があるとしましょう。
プレーンなRESTAPIからホームページデータを取得できるコードを書いてみましょう。 リソースをラップするいくつかの関数から始めます。
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/posts/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/authors/${authorId}`);それでは、オーケストレーションしましょう!
const getPostWithAuthor = postId => { return getPost(postId) .then(post => getAuthor(post.author)) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(postIds => { const postDetails = postIds.map(getPostWithAuthor); return Promise.all(postDetails); }) };したがって、コードは次のことを行います。
- すべての投稿を取得します。
- 各投稿の詳細を取得します。
- 各投稿の作成者リソースを取得します。
良い点は、これについて推論するのが非常に簡単で、よく整理されており、各リソースの概念的な境界がうまく描かれていることです。 ここでの残念な点は、8つのネットワーク要求を行ったところです。その多くは連続して発生します。
GET /posts GET /posts/234 GET /posts/456 GET /posts/17 GET /posts/156 GET /author/9 GET /author/4 GET /author/7 GET /author/2 はい、APIにページ化された/postsエンドポイントがある可能性があることを示唆することで、この例を批判することができますが、それは髪の毛を分割しています。 完全なアプリケーションまたはページをレンダリングするために相互に依存するAPI呼び出しのコレクションを作成することがよくあるという事実は変わりません。
RESTクライアントとサーバーの開発は、それ以前のものよりも確かに優れているか、少なくとも馬鹿げた証拠ですが、フィールディングの論文から20年で多くの変化がありました。 当時、すべてのコンピューターはベージュのプラスチックでした。 今、彼らはアルミニウムです! しかし、真剣に、2000年はパーソナルコンピューティングの爆発のピークに近づいていました。 毎年、プロセッサの速度は2倍になり、ネットワークは信じられないほどの速度で高速化しています。 インターネットの市場浸透率は約45%で、どこにも行けませんでした。
その後、2008年頃、モバイルコンピューティングが主流になりました。 モバイルでは、一晩で速度/パフォーマンスの点で10年を効果的に後退させました。 2017年には、国内で80%近く、世界で50%以上のスマートフォンの普及率があり、API設計に関するいくつかの仮定を再考する時が来ました。
RESTの弱点
以下は、クライアントアプリケーション開発者、特にモバイルで作業している開発者の観点からのRESTの批判的な見方です。 GraphQLおよびGraphQLスタイルのAPIは新しいものではなく、REST開発者の理解の及ばない問題を解決しません。 GraphQLの最も重要な貢献は、これらの問題を体系的に解決し、他の場所では容易に利用できないレベルの統合を実現できることです。 言い換えれば、それは「バッテリーを含む」ソリューションです。
Fieldingを含むRESTの主要な著者は、2017年後半にRESTの20年の歴史と、RESTがインスピレーションを得た多くのパターンを反映した論文(RESTアーキテクチャスタイルと「現代のWebアーキテクチャの原理設計」に関する考察)を発表しました。 これは短く、API設計に興味のある人なら誰でも読む価値があります。
いくつかの歴史的背景とリファレンスアプリを使用して、RESTの3つの主な弱点を見てみましょう。
RESTはおしゃべりです
アプリケーションをレンダリングするのに十分なデータを取得するには、クライアントとサーバー間で複数のラウンドトリップが必要になるため、RESTサービスは少なくともある程度「おしゃべり」になる傾向があります。 この一連のリクエストは、特にモバイルでパフォーマンスに壊滅的な影響を及ぼします。 ブログの例に戻ると、新しい電話と4G接続を備えた信頼性の高いネットワークを使用した最良のシナリオでも、データの最初のバイトがダウンロードされる前に、遅延オーバーヘッドにほぼ0.5秒費やしました。
55ms4Gレイテンシ* 8リクエスト= 440msオーバーヘッド
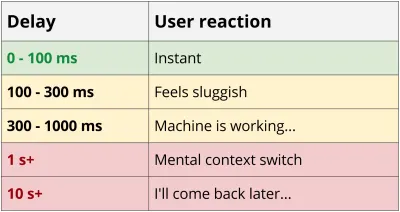
おしゃべりなサービスのもう1つの問題は、多くの場合、1つの大きなリクエストをダウンロードするのに、多くの小さなリクエストよりも時間がかからないことです。 小さなリクエストのパフォーマンスの低下は、TCPスロースタート、ヘッダー圧縮の欠如、gzip効率の欠如など、多くの理由で当てはまります。興味がある場合は、IlyaGrigorikのHigh-PerformanceBrowserNetworkingを読むことを強くお勧めします。 MaxCDNブログにも素晴らしい概要があります。
この問題は、技術的にはRESTではなく、HTTP、特にHTTP / 1にあります。 HTTP / 2は、APIスタイルに関係なく、おしゃべりの問題をほとんど解決し、ブラウザーやネイティブSDKなどのクライアントで幅広くサポートされています。 残念ながら、API側ではロールアウトが遅くなっています。 上位1万のWebサイトの中で、2017年後半の時点で採用率は約20%(および上昇中)です。驚いたことに、Node.jsでさえ8.xリリースでHTTP / 2サポートを取得しました。 能力がある場合は、インフラストラクチャを更新してください。 それまでの間、これは方程式の一部にすぎないので、こだわるのはやめましょう。
HTTPはさておき、おしゃべりが重要である理由の最後の部分は、モバイルデバイス、特にそのラジオがどのように機能するかに関係しています。 その長所と短所は、ラジオの操作は電話の最もバッテリーを消費する部分の1つであるため、OSはあらゆる機会にラジオをオフにします。 無線を開始するとバッテリーが消耗するだけでなく、各要求にさらに多くのオーバーヘッドが追加されます。
TMI(オーバーフェッチ)
RESTスタイルのサービスの次の問題は、必要以上の情報を送信することです。 ブログの例では、必要なのは各投稿のタイトルとその作成者の名前だけです。これは、返されたものの約17%にすぎません。 これは、非常に単純なペイロードの6倍の損失です。 実際のAPIでは、この種のオーバーヘッドは膨大なものになる可能性があります。 たとえば、Eコマースサイトは、多くの場合、単一の製品を数千行のJSONとして表します。 おしゃべりの問題と同様に、RESTサービスは、「スパースフィールドセット」を使用してこのシナリオを処理し、データの一部を条件付きで含めたり除外したりできます。 残念ながら、これのサポートは、ネットワークキャッシングに関して、むらがあるか、不完全であるか、問題があります。
ツーリングとイントロスペクション
REST APIに欠けている最後のことは、イントロスペクションのメカニズムです。 エンドポイントの返品タイプまたは構造に関する情報との契約がなければ、ドキュメントを確実に生成したり、ツールを作成したり、データを操作したりする方法はありません。 この問題をさまざまな程度で解決するために、REST内で作業することが可能です。 OpenAPI、OData、またはJSON APIを完全に実装するプロジェクトは、多くの場合、クリーンで明確に指定されており、さまざまな程度で十分に文書化されていますが、このようなバックエンドはまれです。 何十年にもわたって会議の会談で宣伝されてきたにもかかわらず、比較的低い成果であるハイパーメディアでさえ、たとえあったとしても、それでも頻繁にうまく行われていません。
結論
各APIタイプには欠陥がありますが、すべてのパターンに欠陥があります。 この文章は、ソフトウェアの巨人が築いた驚異的な基礎の判断ではなく、クライアント開発者の観点から「純粋な」形式で適用された、これらの各パターンの冷静な評価にすぎません。 この考え方から離れるのではなく、RESTやRPCのようなパターンが壊れているのではなく、それぞれがどのようにトレードオフを行ったか、エンジニアリング組織が独自のAPIを改善するために努力を集中する可能性のある領域について考えてみてください。
次の記事では、GraphQLと、上記の問題のいくつかに対処することを目的としたGraphQLについて説明します。 GraphQLおよび同様のツールの革新は、それらの実装ではなく、統合のレベルにあります。 あなたまたはあなたのチームが「バッテリーを含む」APIを探していない場合は、今日のより強力な基盤を構築するのに役立つ新しいOpenAPI仕様のようなものを検討することを検討してください。
この記事を楽しんだ場合(またはそれが嫌いな場合)、フィードバックをお寄せになりたい場合は、Twitterで@ebaerbaerbaerまたはLinkedInのericjbaerで私を見つけてください。