
ロジスティック回帰の最急降下法[初心者向けに説明]
公開: 2021-01-08この記事では、ロジスティック回帰で非常に人気のある最急降下アルゴリズムについて説明します。 ロジスティック回帰とは何かを調べてから、ロジスティック回帰の方程式、そのコスト関数、そして最後に最急降下アルゴリズムに徐々に進みます。
目次
ロジスティック回帰とは何ですか?
ロジスティック回帰は、メールが「スパム」であるか「スパムではない」かを予測するなど、個別のカテゴリを予測するために使用される単純な分類アルゴリズムです。 与えられた数字が「9」であるか「9ではない」などであるかを予測します。ここで、名前を見て、なぜそれが回帰と名付けられているのかを考えなければなりません。
その理由は、ロジスティック回帰のアイデアは、回帰問題で使用される基本的な線形回帰アルゴリズムのいくつかの要素を微調整することによって開発されたためです。
ロジスティック回帰は、マルチクラス(3つ以上のクラス)の分類問題にも適用できます。 ただし、このアルゴリズムは二項分類問題にのみ使用することをお勧めします。
シグモイド関数
分類問題は線形関数の問題ではありません。 出力は、特定の離散値に制限されます。たとえば、バイナリ分類問題の場合は0と1です。 線形関数が出力値を1より大きい、または0より小さいと予測することは意味がありません。したがって、出力値を表す適切な関数が必要です。
シグモイド関数は私たちの問題を解決します。 ロジスティック関数とも呼ばれ、実数値を(0,1)間隔にマッピングするS字型の関数であるため、ランダム関数を分類ベースの関数に変換するのに非常に役立ちます。 シグモイド関数は次のようになります。

シグモイド関数
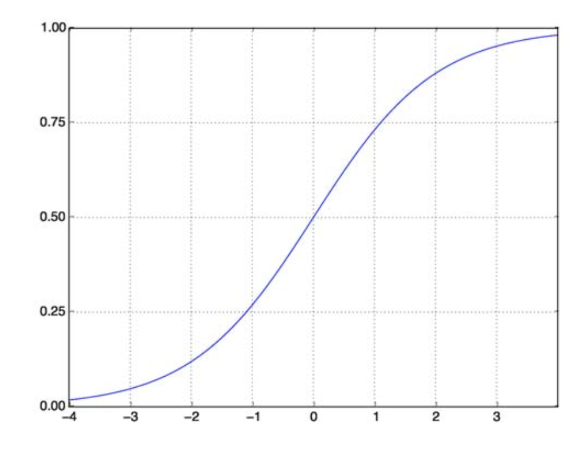
ソース
ここで、パラメーター化されたベクトルと入力ベクトルXのシグモイド関数の数学形式は次のとおりです。
(z)= 11 + exp(-z)ここで、z = TX
(z)は、出力が1である確率を示します。ご存知のとおり、確率値の範囲は0〜1です。これは、離散ベース(0および1のみ)の分類問題に必要な出力ではありません。 。 これで、予測確率を0.5と比較できます。 確率>0.5の場合、y=1になります。 同様に、確率が0.5未満の場合、y=0になります。
コスト関数
離散予測ができたので、今度は予測が本当に正しいかどうかを確認します。 そのために、コスト関数があります。 コスト関数は、データセット全体の予測で行われたすべてのエラーの合計にすぎません。 もちろん、線形回帰で使用されるコスト関数を使用することはできません。 したがって、ロジスティック回帰の新しいコスト関数は次のとおりです。
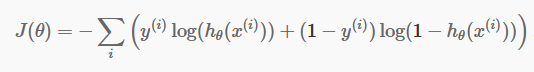 ソース
ソース
方程式を恐れないでください。 とても簡単です。 反復iごとに、予測で作成したエラーを計算し、すべてのエラーを合計してコスト関数J()を定義します。
括弧内の2つの用語は、実際にはy=0とy=1の2つの場合に使用されます。 y = 0の場合、最初の項は消え、2番目の項だけが残ります。 同様に、y = 1の場合、第2項は消え、第1項のみが残ります。
最急降下アルゴリズム
コスト関数の計算に成功しました。 ただし、優れた予測アルゴリズムを作成するには、損失を最小限に抑える必要があります。 そのために、最急降下アルゴリズムがあります。
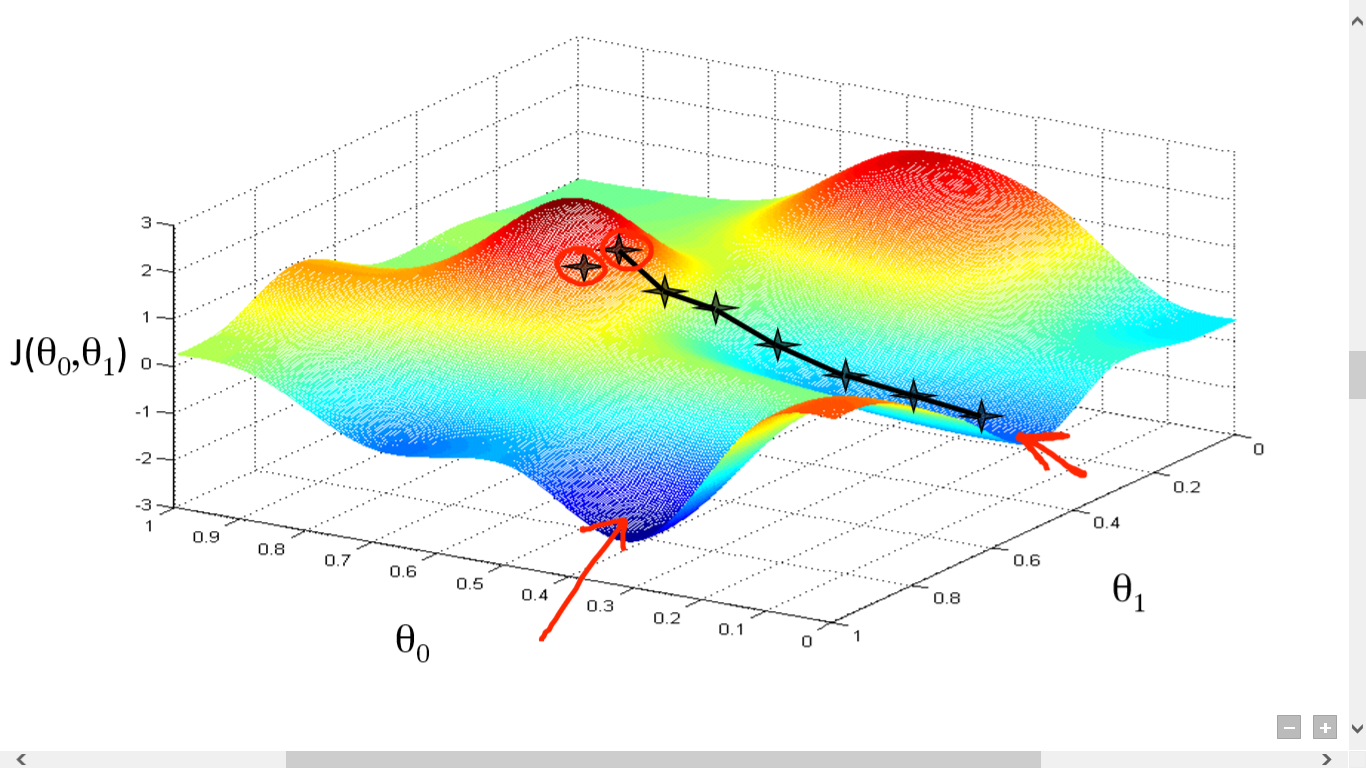 ソース
ソース
ここでは、J()と。の間のグラフをプロットしました。 私たちの目的は、この関数の最も深い点(グローバル最小値)を見つけることです。 ここで最も深いポイントは、J()が最小になる場所です。
最も深いポイントを見つけるには、次の2つのことが必要です。
- 派生物–次のステップの方向性を見つけるため。
- (学習率)–次のステップの規模
アイデアは、最初に関数から任意のランダムな点を選択することです。 次に、J()wrtの導関数を計算する必要があります。 これは、極小の方向を指します。 次に、その結果の勾配に学習率を掛けます。 学習率には固定値はなく、問題に基づいて決定されます。
ここで、から結果を減算して、新しいを取得する必要があります。
この更新は、(i)ごとに同時に実行する必要があります。
ローカルまたはグローバルの最小値に達するまで、これらの手順を繰り返し実行します。 グローバル最小値に到達することにより、予測で可能な限り最小の損失を達成しました。
導関数を取るのは簡単です。 高校でやらなければならない基本的な微積分だけで十分です。 主な問題はLearningRate()です。 良い学習率を取ることは重要であり、しばしば困難です。

学習率が非常に小さい場合、各ステップが小さすぎるため、ローカルの最小値に到達するまでに多くの時間がかかります。
さて、あなたが巨大な学習率の値を取る傾向がある場合、あなたは最小値を超えて、二度と収束することはありません。 完全な学習率についての特定の規則はありません。
最高のモデルを準備するには、それを微調整する必要があります。
最急降下法の式は次のとおりです。
収束するまで繰り返します。
したがって、最急降下アルゴリズムを次のように要約できます。
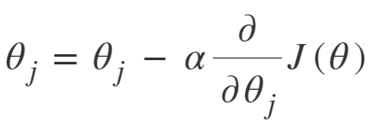
- ランダムから始める
- 収束するまでループします。
- 勾配を計算する
- アップデート
- 戻る
確率的勾配降下アルゴリズム
現在、最急降下アルゴリズムは、特に中小規模のデータの場合、コスト関数を最小化するための優れたアルゴリズムです。 しかし、より大きなデータセットを処理する必要がある場合、最急降下アルゴリズムは計算が遅いことがわかります。 理由は単純です。勾配を計算し、すべてのパラメーターについて同時に値を更新する必要があります。また、すべてのトレーニング例についてもそれを更新する必要があります。
だから、それらすべての計算について考えてください! それは大規模であるため、わずかに修正された最急降下アルゴリズム、つまり確率的勾配降下アルゴリズム(SGD)が必要でした。
SGDとNormalGradientDescentの唯一の違いは、SGDでは、トレーニングインスタンス全体を一度に処理しないことです。 SGDでは、各反復で1つのランダムな例のコスト関数の勾配を計算します。
現在、そうすることで、特に大規模なデータセットの場合、計算にかかる時間が大幅に短縮されます。 SGDがたどる経路は、非常に無計画でノイズが多いです(ただし、ノイズの多いパスは、グローバル最小値に到達する機会を与える可能性があります)。
しかし、それは問題ありません。なぜなら、たどる道を心配する必要がないからです。
より速い時間で最小限の損失に到達する必要があるだけです。
したがって、最急降下アルゴリズムを次のように要約できます。
- 収束するまでループします。
- 単一のデータポイント' i'を選択します
- その単一点の勾配を計算する
- アップデート
- 戻る
ミニバッチ最急降下アルゴリズム
ミニバッチ最急降下法は、最急降下法アルゴリズムのもう1つのわずかな変更です。 これは、通常の最急降下法と確率的勾配降下法の中間にあります。
Mini-Batch Gradient Descentは、データセット全体のより小さなバッチを取得し、その損失を最小限に抑えています。
このプロセスは、上記の2つの最急降下アルゴリズムの両方よりも効率的です。 これで、バッチサイズはもちろん何でもかまいません。
しかし、研究者は、1から100の範囲内に収めた方が良いことを示しており、32が最適なバッチサイズです。
したがって、バッチサイズ= 32は、ほとんどのフレームワークでデフォルトのままです。
- 収束するまでループします。
- ' b 'データポイントのバッチを選択します
- そのバッチの勾配を計算する
- アップデート
- 戻る
結論
これで、ロジスティック回帰の理論的理解が得られました。 ロジスティック関数を数学的に表現する方法を学びました。 コスト関数を使用して予測誤差を測定する方法を知っています。
また、最急降下アルゴリズムを使用してこの損失を最小限に抑える方法も知っています。
最後に、問題に対して最急降下アルゴリズムのどのバリエーションを選択する必要があるかがわかります。 upGradは、機械学習とAIのPGディプロマと、機械学習とAIの科学のマスターを提供します。 これらのコースでは、機械学習の必要性と、勾配降下アルゴリズムからニューラルネットワークに至るまでのさまざまな概念をカバーするこのドメインの知識を収集するためのさらなるステップについて説明します。
最急降下アルゴリズムとは何ですか?
最急降下法は、関数の最小値を見つけるための最適化アルゴリズムです。 y = f(x)のグラフ上の2つの点(a、b)と(c、d)の間の関数f(x)の最小値を見つけたいとします。 次に、最急降下法には3つのステップが含まれます。(1)2つの端点の中間の点を選択し、(2)勾配∇f(x)を計算します。(3)勾配と反対の方向に移動します。つまり、(c、d)から(a、b)。 これについて考える方法は、アルゴリズムがある点で関数の傾きを見つけて、傾きと反対の方向に移動することです。
シグモイド関数とは何ですか?
シグモイド関数、またはシグモイド曲線は、非線形であり、文字S(名前の由来)と形状が非常に似ている数学関数の一種です。 これは、オペレーションズリサーチ、統計、およびその他の分野で、特定の形式の実数値成長をモデル化するために使用されます。 また、コンピュータサイエンスやエンジニアリングの幅広いアプリケーション、特にニューラルネットワークや人工知能に関連する分野でも使用されています。 シグモイド関数は、人工ニューラルネットワークに基づく強化学習アルゴリズムへの入力の一部として使用されます。
確率的勾配降下アルゴリズムとは何ですか?
確率的勾配降下法は、関数の極小値を見つけるための古典的な最急降下法アルゴリズムの一般的なバリエーションの1つです。 アルゴリズムは、値を最小化するために関数が次に進む方向をランダムに選択し、極小値に達するまでその方向が繰り返されます。 目的は、このプロセスを継続的に繰り返すことにより、アルゴリズムが関数のグローバルまたはローカルの最小値に収束することです。