
ExpressおよびES6 + JavaScriptスタックの使用を開始する
公開: 2022-03-10この記事はシリーズの第2部であり、第1部はここにあり、Node.js、ES6 + JavaScript、コールバック関数、矢印関数、API、HTTPプロトコル、JSON、MongoDB、およびもっと。
この記事では、前の記事で習得したスキルに基づいて、ユーザーブックリスト情報を格納するためのMongoDBデータベースを実装およびデプロイする方法、Node.jsとExpress WebApplicationフレームワークを使用してAPIを構築してそのデータベースを公開する方法を学習します。その上でCRUD操作などを実行します。 その過程で、ES6 Object Destructuring、ES6 Object Shorthand、Async / Await構文、Spread Operatorについて説明し、CORS、同一生成元ポリシーなどについて簡単に説明します。
後の記事では、3層アーキテクチャを利用し、依存性注入による制御の反転を実現することで関心の分離についてコードベースをリファクタリングし、JSON WebTokenとFirebaseAuthenticationベースのセキュリティとアクセス制御を実行し、安全な方法を学びますパスワードを保存し、AWS Simple Storage Serviceを使用して、Node.jsバッファーとストリームでユーザーアバターを保存します。その間、データの永続化にPostgreSQLを利用します。 その過程で、TypeScriptでコードベースをゼロから書き直し、古典的なOOPの概念(ポリモーフィズム、継承、構成など)や、ファクトリーやアダプターなどのデザインパターンを調べます。
警告の言葉
今日、Node.jsについて説明している記事の大部分に問題があります。 それらのすべてではなく、ほとんどが、エクスプレスルーティングをセットアップし、Mongooseを統合し、おそらくJSONWebトークン認証を利用する方法を説明するだけです。 問題は、アーキテクチャ、セキュリティのベストプラクティス、クリーンなコーディングの原則、ACIDコンプライアンス、リレーショナルデータベース、第5正規形、CAP定理またはトランザクションについて話していないことです。 入ってくるものすべてについて知っているか、前述の知識を保証するほど大規模または人気のあるプロジェクトを構築しないことを前提としています。
ノード開発者にはいくつかの異なるタイプがあるようです。特に、プログラミング全般に不慣れなものもあれば、C#と.NETFrameworkまたはJavaSpringFrameworkを使用したエンタープライズ開発の長い歴史に由来するものもあります。 記事の大部分は前者のグループに対応しています。
この記事では、あまりにも多くの記事が実行していると述べたとおりに実行しますが、フォローアップ記事では、コードベースを完全にリファクタリングして、依存性注入、3-などの原則を説明できるようにします。レイヤーアーキテクチャ(コントローラー/サービス/リポジトリ)、データマッピングとアクティブレコード、デザインパターン、ユニット、統合、ミューテーションテスト、SOLID原則、作業ユニット、インターフェイスに対するコーディング、HSTS、CSRF、NoSQL、SQLインジェクションなどのセキュリティのベストプラクティス予防など。 また、ORMの代わりにシンプルなクエリビルダーKnexを使用して、MongoDBからPostgreSQLに移行します。これにより、独自のデータアクセスインフラストラクチャを構築し、さまざまなタイプのリレーション(One- to-One、Many-to-Manyなど)など。 したがって、この記事は初心者にアピールする必要がありますが、次のいくつかは、アーキテクチャを改善しようとしているより中級の開発者に対応する必要があります。
これでは、本のデータの永続化についてのみ心配します。 ユーザー認証、パスワードハッシュ、アーキテクチャ、またはそのような複雑なものは処理しません。 そのすべては、次のそして将来の記事で来るでしょう。 今のところ、そして非常に基本的に、データベースに本の情報を保存するために、クライアントがHTTPプロトコルを介してWebサーバーと通信できるようにするメソッドを構築します。
注:この記事自体は非常に長いので、私は意図的にそれを非常に単純にし、おそらくそれほど実用的ではありません。補足的なトピックについて議論するために自由に逸脱したからです。 このように、このシリーズでAPIの品質と複雑さを段階的に改善していきますが、これもExpressの最初の紹介の1つと考えているため、意図的に非常にシンプルにしています。
- ES6オブジェクトの破棄
- ES6オブジェクトの省略形
- ES6スプレッド演算子(...)
- 来る...
ES6オブジェクトの破棄
ES6 Object Destructuring、またはDestructuring Assignment Syntaxは、配列またはオブジェクトから独自の変数に値を抽出またはアンパックする方法です。 オブジェクトのプロパティから始めて、配列要素について説明します。
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // Log properties: console.log('Name:', person.name); console.log('Occupation:', person.occupation); このような操作は非常に原始的ですが、どこでもperson.somethingを参照し続ける必要があることを考えると、多少面倒な場合があります。 私たちのコード全体でそれをしなければならなかった他の10の場所があったとしましょう—それは非常に速く非常に困難になるでしょう。 簡潔にする方法は、これらの値を独自の変数に割り当てることです。
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; const personName = person.name; const personOccupation = person.occupation; // Log properties: console.log('Name:', personName); console.log('Occupation:', personOccupation); おそらくこれは合理的に見えますが、 personオブジェクトに他に10個のプロパティがネストされている場合はどうでしょうか。 これは、変数に値を割り当てるためだけに多くの不要な行になります。オブジェクトのプロパティが変更された場合、変数はその変更を反映しないため、この時点で危険にさらされます( const割り当てでは、オブジェクトへの参照のみが不変であることを忘れないでください。オブジェクトのプロパティではありません)、したがって、基本的に、「状態」を同期させることはできなくなります(そして私はその単語を大まかに使用しています)。 ここでは、参照渡しと値渡しが関係する可能性がありますが、このセクションの範囲から大きく外れたくはありません。
ES6 Object Destructingを使用すると、基本的に次のことが可能になります。
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // This is new. It's called Object Destructuring. const { name, occupation } = person; // Log properties: console.log('Name:', name); console.log('Occupation:', occupation); 新しいオブジェクト/オブジェクトリテラルを作成するのではなく、元のオブジェクトからnameとoccupationのプロパティを解凍し、それらを同じ名前の独自の変数に入れます。 使用する名前は、抽出するプロパティ名と一致する必要があります。
繰り返しますが、構文const { a, b } = someObject; 具体的には、いくつかのプロパティaといくつかのプロパティbがsomeObject内に存在することを期待し(つまり、 someObjectは{ a: 'dataA', b: 'dataB' }など)、値が何であれ配置したいということです。同じ名前のconst変数内のそれらのキー/プロパティの。 そのため、上記の構文では、 const b = someObject.b const a = someObject.a 2つの変数が提供されます。
つまり、オブジェクトの破棄には2つの側面があります。 「テンプレート」側と「ソース」側。const const { a, b }側(左側)がテンプレートで、 someObject側(右側)がソース側です。これは理にかなっています。 —「ソース」側のデータを反映する構造または「テンプレート」を左側に定義しています。
繰り返しますが、これを明確にするために、ここにいくつかの例を示します。
// ----- Destructure from Object Variable with const ----- // const objOne = { a: 'dataA', b: 'dataB' }; // Destructure const { a, b } = objOne; console.log(a); // dataA console.log(b); // dataB // ----- Destructure from Object Variable with let ----- // let objTwo = { c: 'dataC', d: 'dataD' }; // Destructure let { c, d } = objTwo; console.log(c); // dataC console.log(d); // dataD // Destructure from Object Literal with const ----- // const { e, f } = { e: 'dataE', f: 'dataF' }; // <-- Destructure console.log(e); // dataE console.log(f); // dataF // Destructure from Object Literal with let ----- // let { g, h } = { g: 'dataG', h: 'dataH' }; // <-- Destructure console.log(g); // dataG console.log(h); // dataHネストされたプロパティの場合、破棄する割り当てで同じ構造をミラーリングします。
const person = { name: 'Richard P. Feynman', occupation: { type: 'Theoretical Physicist', location: { lat: 1, lng: 2 } } }; // Attempt one: const { name, occupation } = person; console.log(name); // Richard P. Feynman console.log(occupation); // The entire `occupation` object. // Attempt two: const { occupation: { type, location } } = person; console.log(type); // Theoretical Physicist console.log(location) // The entire `location` object. // Attempt three: const { occupation: { location: { lat, lng } } } = person; console.log(lat); // 1 console.log(lng); // 2ご覧のとおり、プルオフすることを決定したプロパティはオプションであり、ネストされたプロパティを解凍するには、破棄構文のテンプレート側で元のオブジェクト(ソース)の構造をミラーリングするだけです。 元のオブジェクトに存在しないプロパティを分解しようとすると、その値は未定義になります。
さらに、次の構文を使用して、最初に変数を宣言せずに(宣言なしの割り当て)変数を非構造化できます。
let name, occupation; const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; ;({ name, occupation } = person); console.log(name); // Richard P. Feynman console.log(occupation); // Theoretical Physicist前の行の関数(そのような関数が存在する場合)を使用してIIFE(即時呼び出し関数式)を誤って作成しないように、式の前にセミコロンを付けます。割り当てステートメントの前後の括弧は、次のように必要です。 JavaScriptが左側(テンプレート)側をブロックとして扱わないようにします。
破壊の非常に一般的なユースケースは、関数の引数内に存在します。
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; // Destructures `baseUrl` and `awsBucket` off `config`. const performOperation = ({ baseUrl, awsBucket }) => { fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);ご覧のとおり、関数内で現在使用している通常の非構造化構文を次のように使用することもできます。
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; const performOperation = someConfig => { const { baseUrl, awsBucket } = someConfig; fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);ただし、関数シグネチャ内に上記の構文を配置すると、自動的に破棄が実行され、行が節約されます。
これの実際のユースケースは、 propsのReact機能コンポーネントにあります。
import React from 'react'; // Destructure `titleText` and `secondaryText` from `props`. export default ({ titleText, secondaryText }) => ( <div> <h1>{titleText}</h1> <h3>{secondaryText}</h3> </div> );とは対照的に:
import React from 'react'; export default props => ( <div> <h1>{props.titleText}</h1> <h3>{props.secondaryText}</h3> </div> );どちらの場合も、プロパティにデフォルト値を設定することもできます。
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(name); console.log(password); return { id: Math.random().toString(36) // <--- Should follow RFC 4122 Spec in real app. .substring(2, 15) + Math.random() .toString(36).substring(2, 15), name: name, // <-- We'll discuss this next. password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt Hash ご覧のとおり、非構造化時にnameが存在しない場合は、デフォルト値を提供します。 これは、前の構文でも実行できます。
const { a, b, c = 'Default' } = { a: 'dataA', b: 'dataB' }; console.log(a); // dataA console.log(b); // dataB console.log(c); // Default配列も分解できます。
const myArr = [4, 3]; // Destructuring happens here. const [valOne, valTwo] = myArr; console.log(valOne); // 4 console.log(valTwo); // 3 // ----- Destructuring without assignment: ----- // let a, b; // Destructuring happens here. ;([a, b] = [10, 2]); console.log(a + b); // 12アレイの破壊の実際的な理由は、Reactフックで発生します。 (そして、他にも多くの理由があります。私は例としてReactを使用しています)。
import React, { useState } from "react"; export default () => { const [buttonText, setButtonText] = useState("Default"); return ( <button onClick={() => setButtonText("Toggled")}> {buttonText} </button> ); } useStateがエクスポートから非構造化されており、配列関数/値がuseStateフックから非構造化されていることに注意してください。 繰り返しになりますが、上記が意味をなさなくても心配しないでください— Reactを理解する必要があります—そして私は単に例としてそれを使用しています。
ES6 Object Destructuringにはまだまだありますが、ここではもう1つのトピックを取り上げます。DestructuringRenamingは、スコープの衝突や変数の影などを防ぐのに役立ちます。personというオブジェクトからnameというプロパティを分解したいとしpersonが、スコープには、 nameという名前の変数がすでに存在します。 コロンを使用して、その場で名前を変更できます。
// JS Destructuring Naming Collision Example: const name = 'Jamie Corkhill'; const person = { name: 'Alan Turing' }; // Rename `name` from `person` to `personName` after destructuring. const { name: personName } = person; console.log(name); // Jamie Corkhill <-- As expected. console.log(personName); // Alan Turing <-- Variable was renamed.最後に、名前を変更してデフォルト値を設定することもできます。
const name = 'Jamie Corkhill'; const person = { location: 'New York City, United States' }; const { name: personName = 'Anonymous', location } = person; console.log(name); // Jamie Corkhill console.log(personName); // Anonymous console.log(location); // New York City, United States ご覧のとおり、この場合、 personのname ( person.name )はpersonNameに名前が変更され、存在しない場合はデフォルト値のAnonymousに設定されます。
そしてもちろん、同じことが関数シグニチャでも実行できます。
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name: personName = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(personName); console.log(password); return { id: Math.random().toString(36).substring(2, 15) + Math.random().toString(36).substring(2, 15), name: personName, password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt HashES6オブジェクトの省略形
次のファクトリがあるとします:(ファクトリについては後で説明します)
const createPersonFactory = (name, location, position) => ({ name: name, location: location, position: position }); 次のように、このファクトリを使用してpersonオブジェクトを作成できます。 また、ファクトリは暗黙的にオブジェクトを返していることに注意してください。これは、Arrow関数の角かっこで囲まれていることから明らかです。
const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person); // { ... } これは、ES5オブジェクトリテラル構文からすでにわかっていることです。 ただし、ファクトリ関数では、各プロパティの値がプロパティ識別子(キー)自体と同じ名前であることに注意してください。 つまり— location: locationまたはname: name 。 それはJS開発者の間でかなり一般的な出来事であることが判明しました。
ES6の短縮構文を使用すると、ファクトリを次のように書き直すことで同じ結果を得ることができます。
const createPersonFactory = (name, location, position) => ({ name, location, position }); const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person);出力の生成:
{ name: 'Jamie', location: 'Texas', position: 'Developer' }この省略形は、作成するオブジェクトが変数に基づいて動的に作成されている場合にのみ使用できることを理解することが重要です。変数名は、変数を割り当てるプロパティの名前と同じです。
これと同じ構文がオブジェクト値で機能します。
const createPersonFactory = (name, location, position, extra) => ({ name, location, position, extra // <- right here. }); const extra = { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] }; const person = createPersonFactory('Jamie', 'Texas', 'Developer', extra); console.log(person);出力の生成:
{ name: 'Jamie', location: 'Texas', position: 'Developer', extra: { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] } }最後の例として、これはオブジェクトリテラルでも機能します。
const id = '314159265358979'; const name = 'Archimedes of Syracuse'; const location = 'Syracuse'; const greatMathematician = { id, name, location };ES6スプレッド演算子(…)
Spread Operatorを使用すると、さまざまなことが可能になります。その一部については、ここで説明します。
まず、あるオブジェクトから別のオブジェクトにプロパティを分散させることができます。
const myObjOne = { a: 'a', b: 'b' }; const myObjTwo = { ...myObjOne }: これには、 myObjTwoのすべてのプロパティをmyObjOneに配置する効果があり、 myObjTwoは{ a: 'a', b: 'b' }になります。 このメソッドを使用して、以前のプロパティをオーバーライドできます。 ユーザーが自分のアカウントを更新したいとします。
const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */
アレイでも同じことができます。
const apollo13Astronauts = ['Jim', 'Jack', 'Fred']; const apollo11Astronauts = ['Neil', 'Buz', 'Michael']; const unionOfAstronauts = [...apollo13Astronauts, ...apollo11Astronauts]; console.log(unionOfAstronauts); // ['Jim', 'Jack', 'Fred', 'Neil', 'Buz, 'Michael'];ここで、配列を新しい配列に分散することにより、両方のセット(配列)の和集合を作成したことに注意してください。
Rest / Spread Operatorにはさらに多くのことがありますが、この記事の範囲外です。 たとえば、関数に対して複数の引数を取得するために使用できます。 詳細については、こちらのMDNドキュメントをご覧ください。
ES6 Async / Await
Async / Awaitは、promiseチェーンの苦痛を和らげるための構文です。
await reservedキーワードを使用すると、promiseの決済を「待機」できますが、 asyncキーワードでマークされた関数でのみ使用できます。 promiseを返す関数があるとします。 新しいasync関数では、 .thenと.catchを使用する代わりに、そのpromiseの結果をawaitことができます。
// Returns a promise. const myFunctionThatReturnsAPromise = () => { return new Promise((resolve, reject) => { setTimeout(() => resolve('Hello'), 3000); }); } const myAsyncFunction = async () => { const promiseResolutionResult = await myFunctionThatReturnsAPromise(); console.log(promiseResolutionResult); }; // Writes the log statement after three seconds. myAsyncFunction(); ここで注意すべきことがいくつかあります。 async関数でawaitを使用すると、解決された値のみが左側の変数に入ります。 関数が拒否した場合、これはすぐにわかるように、キャッチする必要のあるエラーです。 さらに、 asyncとマークされた関数は、デフォルトでpromiseを返します。
2つのAPI呼び出しを行う必要があるとしましょう。1つは前者からの応答です。 promiseとpromisechainingを使用して、次のようにすることができます。
const makeAPICall = route => new Promise((resolve, reject) => { console.log(route) resolve(route); }); const main = () => { makeAPICall('/whatever') .then(response => makeAPICall(response + ' second call')) .then(response => console.log(response + ' logged')) .catch(err => console.error(err)) }; main(); // Result: /* /whatever /whatever second call /whatever second call logged */ ここで起こっていることは、最初にmakeAPICallを呼び出して/whateverを渡し、これが最初にログに記録されることです。 約束はその値で解決されます。 次に、 makeAPICallを再度/whatever second callの呼び出しを渡します。この場合も、promiseはその新しい値で解決されます。 最後に、promiseが解決したばかりの新しい値/whatever second callを取得し、それを最終ログに記録し、最後にloggedを追加します。 これが意味をなさない場合は、promisechainingを調べる必要があります。
async / awaitを使用して、次のようにリファクタリングできます。
const main = async () => { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); }; これが何が起こるかです。 関数全体は、 makeAPICallへの最初の呼び出しからのpromiseが解決されるまで、最初のawaitステートメントで実行を停止します。解決すると、解決された値がresultOneに配置されます。 それが発生すると、関数は2番目のawaitステートメントに移動し、promiseが解決する間再びそこで一時停止します。 約束が解決されると、解決結果はresultTwoに配置されます。 関数の実行に関するアイデアがブロックされているように聞こえても、恐れることはありません。それでも非同期であるため、その理由については後で説明します。
これは「幸せな」道を描いているだけです。 約束の1つが拒否された場合、try / catchでそれをキャッチできます。約束が拒否された場合、エラーがスローされます。これは、約束が拒否されたエラーになります。
const main = async () => { try { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); } catch (e) { console.log(e) } }; 前に述べたように、 asyncとして宣言された関数はすべてpromiseを返します。 したがって、別の関数から非同期関数を呼び出したい場合は、通常のpromiseを使用するか、呼び出し元の関数awaitを宣言する場合はasyncすることができます。 ただし、トップレベルのコードからasync関数を呼び出してその結果を待つ場合は、 .thenと.catchを使用する必要があります。
例えば:
const returnNumberOne = async () => 1; returnNumberOne().then(value => console.log(value)); // 1または、即時呼び出し関数式(IIFE)を使用することもできます。
(async () => { const value = await returnNumberOne(); console.log(value); // 1 })(); async関数でawaitを使用すると、promiseが解決するまで、関数の実行はそのawaitステートメントで停止します。 ただし、他のすべての関数は自由に実行を続行できるため、余分なCPUリソースが割り当てられたり、スレッドがブロックされたりすることはありません。 もう一度言いますが、その特定の時間におけるその特定の関数の操作は、約束が解決するまで停止しますが、他のすべての関数は自由に起動できます。 HTTP Webサーバーについて考えてみましょう。リクエストごとに、リクエストが行われると同時にすべてのユーザーがすべての関数を自由に起動できます。async / await構文により、操作が同期してブロックされているように見えます。作業が簡単になることを約束しますが、繰り返しになりますが、すべてが素晴らしく非同期のままになります。
async / awaitするのはこれだけではありませんが、基本的な原則を理解するのに役立つはずです。
古典的なOOPファクトリー
JavaScriptの世界を離れ、 Javaの世界に入ります。 オブジェクト(この場合、クラスのインスタンス—ここでもJava)の作成プロセスがかなり複雑な場合や、一連のパラメーターに基づいてさまざまなオブジェクトを作成したい場合があります。 例として、さまざまなエラーオブジェクトを作成する関数があります。 ファクトリは、オブジェクト指向プログラミングの一般的なデザインパターンであり、基本的にはオブジェクトを作成する関数です。 これを探求するために、JavaScriptからJavaの世界に移りましょう。 これは、静的に型付けされた言語のバックグラウンドである、古典的なOOP(つまり、プロトタイプではない)から来た開発者にとって意味があります。 そのような開発者でない場合は、このセクションをスキップしてください。 これはわずかな偏差であるため、ここに従うとJavaScriptのフローが中断される場合は、このセクションをスキップしてください。
一般的な作成パターンであるファクトリパターンを使用すると、作成を実行するために必要なビジネスロジックを公開せずに、オブジェクトを作成できます。
n次元でプリミティブ形状を視覚化できるプログラムを作成しているとします。 たとえば、立方体を提供すると、2D立方体(正方形)、3D立方体(立方体)、および4D立方体(Tesseract、またはHypercube)が表示されます。 これは、Javaで、実際の描画部分を除いて、簡単に、これを行う方法です。
// Main.java // Defining an interface for the shape (can be used as a base type) interface IShape { void draw(); } // Implementing the interface for 2-dimensions: class TwoDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 2D."); } } // Implementing the interface for 3-dimensions: class ThreeDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 3D."); } } // Implementing the interface for 4-dimensions: class FourDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 4D."); } } // Handles object creation class ShapeFactory { // Factory method (notice return type is the base interface) public IShape createShape(int dimensions) { switch(dimensions) { case 2: return new TwoDimensions(); case 3: return new ThreeDimensions(); case 4: return new FourDimensions(); default: throw new IllegalArgumentException("Invalid dimension."); } } } // Main class and entry point. public class Main { public static void main(String[] args) throws Exception { ShapeFactory shapeFactory = new ShapeFactory(); IShape fourDimensions = shapeFactory.createShape(4); fourDimensions.draw(); // Drawing a shape in 4D. } } ご覧のとおり、図形を描画する方法を指定するインターフェイスを定義します。 さまざまなクラスにインターフェイスを実装させることで、すべての形状を描画できることを保証できます(インターフェイス定義に従って、すべてのクラスにオーバーライド可能なdrawメソッドが必要です)。 この形状は、表示される寸法に応じて異なる方法で描画されることを考慮して、N次元レンダリングをシミュレートするGPUを多用する作業を実行するように、インターフェイスを実装するヘルパークラスを定義します。 ShapeFactoryは、正しいクラスをインスタンス化する作業を行いますcreateShapeメソッドはファクトリであり、上記の定義と同様に、クラスのオブジェクトを返すメソッドです。 createShapeの戻り型はcreateShapeインターフェイスです。 IShape IShapeがすべてのシェイプの基本タイプであるためです( drawメソッドがあるため)。
このJavaの例は非常に簡単ですが、オブジェクトを作成するためのセットアップがそれほど単純ではない可能性がある大規模なアプリケーションでどれほど役立つかを簡単に確認できます。 この例は、ビデオゲームです。 ユーザーがさまざまな敵を生き残る必要があるとします。 抽象クラスとインターフェースを使用して、すべての敵が利用できるコア機能(およびオーバーライドできるメソッド)を定義できます。おそらく、委任パターン(Gang of Fourが提案したように、継承よりも構成を優先するため、拡張に縛られないようにする)を採用します。単一の基本クラスであり、テスト/モック/ DIを容易にします)。 さまざまな方法でインスタンス化された敵オブジェクトの場合、インターフェイスは、汎用インターフェイスタイプに依存しながら、ファクトリオブジェクトの作成を許可します。 敵が動的に作成された場合、これは非常に重要です。
もう1つの例は、ビルダー関数です。 委任パターンを利用して、インターフェイスを尊重する他のクラスにクラス委任を機能させるとします。 クラスに静的buildメソッドを配置して、独自のインスタンスを構築することができます(依存性注入コンテナ/フレームワークを使用していないと仮定します)。 各セッターを呼び出す代わりに、次のようにすることができます。
public class User { private IMessagingService msgService; private String name; private int age; public User(String name, int age, IMessagingService msgService) { this.name = name; this.age = age; this.msgService = msgService; } public static User build(String name, int age) { return new User(name, age, new SomeMessageService()); } } 委任パターンに慣れていない場合は、後の記事で説明します。基本的に、コンポジションを通じて、オブジェクトモデリングの観点から、「is-a」ではなく「has-a」関係を作成します。継承で得られるような関係。 MammalクラスとDogクラスがあり、 DogがMammalを拡張している場合、 DogはMammalです。 一方、 Barkクラスがあり、 BarkのインスタンスをDogのコンストラクターに渡した場合、 DogにはBarkがあります。 ご想像のとおり、これによりユニットテストが特に簡単になります。モックがテスト環境のインターフェイスコントラクトを尊重している限り、モックを挿入してモックに関する事実を主張できるからです。
上記のstatic 「ビルド」ファクトリメソッドは、単にUserの新しいオブジェクトを作成し、具体的なMessageServiceを渡します。これが上記の定義からどのように続くかに注意してください。クラスのオブジェクトを作成するためのビジネスロジックを公開していません。この場合は、メッセージングサービスの作成をファクトリの呼び出し元に公開しない。
繰り返しになりますが、これは必ずしも現実の世界で物事を行う方法ではありませんが、ファクトリ関数/メソッドのアイデアを非常にうまく示しています。 たとえば、代わりに依存性注入コンテナを使用する場合があります。 ここでJavaScriptに戻ります。
Express以降
Expressは、HTTP Webサーバーの作成を可能にするノード用のWebアプリケーションフレームワーク(NPMモジュールを介して利用可能)です。 これを行うためのフレームワークはExpressだけではなく(Koa、Fastifyなどが存在します)、前の記事で見たように、NodeはExpressなしでスタンドアロンエンティティとして機能できることに注意することが重要です。 (Expressは、Node用に設計されたモジュールにすぎません。ExpressはWebサーバーで人気がありますが、Nodeはそれなしで多くのことを実行できます)。
繰り返しますが、非常に重要な区別をさせてください。 Node / JavaScriptとExpressの間には二分法があります。 JavaScriptを実行するランタイム/環境であるNodeは、React Nativeアプリ、デスクトップアプリ、コマンドラインツールなどのビルドを許可するなど、多くのことを実行できます。Expressは、使用できる軽量のフレームワークに他なりません。 Node / JSは、Nodeの低レベルネットワークとHTTP APIを処理するのではなく、Webサーバーを構築します。 Webサーバーを構築するのにExpressは必要ありません。
このセクションを開始する前に、HTTPおよびHTTPリクエスト(GET、POSTなど)に精通していない場合は、上記にリンクされている以前の記事の対応するセクションを読むことをお勧めします。
Expressを使用して、HTTPリクエストが行われる可能性のあるさまざまなルートと、そのルートにリクエストが行われたときに起動する関連エンドポイント(コールバック関数)を設定します。 ルートとエンドポイントが現在無意味であるかどうかを心配する必要はありません。後で説明します。
他の記事とは異なり、コードベース全体を1つのスニペットにダンプして後で説明するのではなく、ソースコードを1行ずつ記述していくというアプローチを取ります。 まず、ターミナルを開き(WindowsではGit Bashの上にTerminusを使用しています。これは、LinuxサブシステムをセットアップせずにBashシェルが必要なWindowsユーザーにとっては便利なオプションです)、プロジェクトのボイラープレートをセットアップして、それを開きます。 Visual StudioCodeで。
mkdir server && cd server touch server.js npm init -y npm install express code . server.jsファイル内で、 require()関数を使用してexpressを要求することから始めます。
const express = require('express'); require('express')は、Nodeに、以前にインストールしたExpressモジュールを取得するように指示します。これは、現在node_modulesフォルダー内にあります(これは、 npm installが行うことnode_modulesフォルダーを作成し、モジュールとその依存関係をそこに配置します)。 慣例により、Expressを処理する場合、 require('express') expressからの戻り結果を保持する変数を呼び出しますが、これは何と呼んでもかまいません。
この返された結果は、 expressと呼ばれ、実際には関数です。Expressアプリを作成し、ルートを設定するために呼び出す必要のある関数です。 Again, by convention, we call this app — app being the return result of express() — that is, the return result of calling the function that has the name express as express() .
const express = require('express'); const app = express(); // Note that the above variable names are the convention, but not required. // An example such as that below could also be used. const foo = require('express'); const bar = foo(); // Note also that the node module we installed is called express. The line const app = express(); simply puts a new Express Application inside of the app variable. It calls a function named express (the return result of require('express') ) and stores its return result in a constant named app . If you come from an object-oriented programming background, consider this equivalent to instantiating a new object of a class, where app would be the object and where express() would call the constructor function of the express class. Remember, JavaScript allows us to store functions in variables — functions are first-class citizens. The express variable, then, is nothing more than a mere function. It's provided to us by the developers of Express.
I apologize in advance if I'm taking a very long time to discuss what is actually very basic, but the above, although primitive, confused me quite a lot when I was first learning back-end development with Node.
Inside the Express source code, which is open-source on GitHub, the variable we called express is a function entitled createApplication , which, when invoked, performs the work necessary to create an Express Application:
A snippet of Express source code:
exports = module.exports = createApplication; /* * Create an express application */ // This is the function we are storing in the express variable. (- Jamie) function createApplication() { // This is what I mean by "Express App" (- Jamie) var app = function(req, res, next) { app.handle(req, res, next); }; mixin(app, EventEmitter.prototype, false); mixin(app, proto, false); // expose the prototype that will get set on requests app.request = Object.create(req, { app: { configurable: true, enumerable: true, writable: true, value: app } }) // expose the prototype that will get set on responses app.response = Object.create(res, { app: { configurable: true, enumerable: true, writable: true, value: app } }) app.init(); // See - `app` gets returned. (- Jamie) return app; }GitHub: https://github.com/expressjs/express/blob/master/lib/express.js
With that short deviation complete, let's continue setting up Express. Thus far, we have required the module and set up our app variable.
const express = require('express'); const app = express(); From here, we have to tell Express to listen on a port. Any HTTP Requests made to the URL and Port upon which our application is listening will be handled by Express. We do that by calling app.listen(...) , passing to it the port and a callback function which gets called when the server starts running:
const PORT = 3000; app.listen(PORT, () => console.log(`Server is up on port {PORT}.`)); We notate the PORT variable in capital by convention, for it is a constant variable that will never change. You could do that with all variables that you declare const , but that would look messy. It's up to the developer or development team to decide on notation, so we'll use the above sparsely. I use const everywhere as a method of “defensive coding” — that is, if I know that a variable is never going to change then I might as well just declare it const . Since I define everything const , I make the distinction between what variables should remain the same on a per-request basis and what variables are true actual global constants.
Here is what we have thus far:
const express = require('express'); const app = express(); const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`); });Let's test this to see if the server starts running on port 3000.
I'll open a terminal and navigate to our project's root directory. I'll then run node server/server.js . Note that this assumes you have Node already installed on your system (You can check with node -v ).
If everything works, you should see the following in the terminal:
Server is up on port 3000.
Go ahead and hit Ctrl + C to bring the server back down.
If this doesn't work for you, or if you see an error such as EADDRINUSE , then it means you may have a service already running on port 3000. Pick another port number, like 3001, 3002, 5000, 8000, etc. Be aware, lower number ports are reserved and there is an upper bound of 65535.
At this point, it's worth taking another small deviation as to understand servers and ports in the context of computer networking. We'll return to Express in a moment. I take this approach, rather than introducing servers and ports first, for the purpose of relevance. That is, it is difficult to learn a concept if you fail to see its applicability. In this way, you are already aware of the use case for ports and servers with Express, so the learning experience will be more pleasurable.
A Brief Look At Servers And Ports
A server is simply a computer or computer program that provides some sort of “functionality” to the clients that talk to it. More generally, it's a device, usually connected to the Internet, that handles connections in a pre-defined manner. In our case, that “pre-defined manner” will be HTTP or the HyperText Transfer Protocol. Servers that use the HTTP Protocol are called Web Servers.
When building an application, the server is a critical component of the “client-server model”, for it permits the sharing and syncing of data (generally via databases or file systems) across devices. It's a cross-platform approach, in a way, for the SDKs of platforms against which you may want to code — be they web, mobile, or desktop — all provide methods (APIs) to interact with a server over HTTP or TCP/UDP Sockets. It's important to make a distinction here — by APIs, I mean programming language constructs to talk to a server, like XMLHttpRequest or the Fetch API in JavaScript, or HttpUrlConnection in Java, or even HttpClient in C#/.NET. This is different from the kind of REST API we'll be building in this article to perform CRUD Operations on a database.
To talk about ports, it's important to understand how clients connect to a server. A client requires the IP Address of the server and the Port Number of our specific service on that server. An IP Address, or Internet Protocol Address, is just an address that uniquely identifies a device on a network. Public and private IPs exist, with private addresses commonly used behind a router or Network Address Translator on a local network. You might see private IP Addresses of the form 192.168.XXX.XXX or 10.0.XXX.XXX . When articulating an IP Address, decimals are called “dots”. So 192.168.0.1 (a common router IP Addr.) might be pronounced, “one nine two dot one six eight dot zero dot one”. (By the way, if you're ever in a hotel and your phone/laptop won't direct you to the AP captive portal, try typing 192.168.0.1 or 192.168.1.1 or similar directly into Chrome).
For simplicity, and since this is not an article about the complexities of computer networking, assume that an IP Address is equivalent to a house address, allowing you to uniquely identify a house (where a house is analogous to a server, client, or network device) in a neighborhood. One neighborhood is one network. Put together all of the neighborhoods in the United States, and you have the public Internet. (This is a basic view, and there are many more complexities — firewalls, NATs, ISP Tiers (Tier One, Tier Two, and Tier Three), fiber optics and fiber optic backbones, packet switches, hops, hubs, etc., subnet masks, etc., to name just a few — in the real networking world.) The traceroute Unix command can provide more insight into the above, displaying the path (and associated latency) that packets take through a network as a series of “hops”.
ポート番号は、サーバーで実行されている特定のサービスを識別します。 SSH、またはデバイスへのリモートシェルアクセスを許可するセキュアシェルは、通常、ポート22で実行されます。FTPまたはファイル転送プロトコル(たとえば、静的アセットをサーバーに転送するためにFTPクライアントで使用される場合があります)は、通常、ポート21。つまり、上記の例では、ポートは各家の中の特定の部屋であると言えます。家の中の部屋はさまざまなもののために作られています。ポートと同じように、食品などは特定のサービスを実行するプログラムに対応します。 私たちの場合、Webサーバーは通常ポート80で実行されますが、他のサービスで使用されていない(衝突できない)限り、任意のポート番号を自由に指定できます。
Webサイトにアクセスするには、サイトのIPアドレスが必要です。 それにもかかわらず、私たちは通常、URLを介してWebサイトにアクセスします。 舞台裏では、DNSまたはドメインネームサーバーがそのURLをIPアドレスに変換し、ブラウザがサーバーにGETリクエストを送信し、HTMLを取得して、画面にレンダリングできるようにします。 8.8.8.8は、GoogleのパブリックDNSサーバーの1つのアドレスです。 リモートDNSサーバーを介してホスト名をIPアドレスに解決するのに時間がかかることを想像するかもしれませんが、それは正しいことです。 待ち時間を短縮するために、オペレーティングシステムにはDNSキャッシュがあります。これはDNSルックアップ情報を格納する一時データベースであり、これにより、ルックアップが発生しなければならない頻度が減少します。 DNSリゾルバーキャッシュは、Windowsでipconfig /displaydns CMDコマンドを使用して表示し、 ipconfig /flushdnsコマンドを使用して削除できます。
Unixサーバーでは、80などのより一般的な少数のポートには、ルートレベル(Windowsのバックグラウンドから来た場合はエスカレーション)の権限が必要です。 そのため、開発作業にはポート3000を使用しますが、本番環境にデプロイするときにサーバーがポート番号(使用可能なものは何でも)を選択できるようにします。
最後に、Google Chromeの検索バーにIPアドレスを直接入力できるため、DNS解決メカニズムをバイパスできることに注意してください。 たとえば、 216.58.194.36と入力すると、Google.comに移動します。 私たちの開発環境では、開発サーバーとして自分のコンピューターを使用する場合、 localhostとポート3000を使用します。アドレスはhostname:portとしてフォーマットされているため、サーバーはlocalhost:3000で稼働します。 Localhost( 127.0.0.1 )はループバックアドレスであり、「このコンピューター」のアドレスを意味します。 これはホスト名であり、そのIPv4アドレスは127.0.0.1に解決されます。 今すぐマシンでlocalhostにpingを実行してみてください。 ::1が返される可能性があります—これはIPv6ループバックアドレスです。または127.0.0.1が返されます—これはIPv4ループバックアドレスです。 IPv4とIPv6は、異なる標準に関連付けられた2つの異なるIPアドレス形式です。一部のIPv6アドレスはIPv4に変換できますが、すべてではありません。
Expressに戻る
前回の記事「ノード入門:API、HTTP、ES6 + JavaScriptの概要」で、HTTPリクエスト、動詞、ステータスコードについて説明しました。 プロトコルの一般的な理解がない場合は、その部分の「HTTPおよびHTTPリクエスト」セクションにジャンプしてください。
Expressの感触をつかむために、データベースで実行する4つの基本的な操作(作成、読み取り、更新、削除)のエンドポイントを設定します。これらはまとめてCRUDと呼ばれます。
URL内のルートでエンドポイントにアクセスすることを忘れないでください。 つまり、「ルート」と「エンドポイント」という言葉は一般的に同じ意味で使用されますが、エンドポイントは技術的にはサーバー側の操作を実行するプログラミング言語関数(ES6 Arrow関数など)であり、ルートはエンドポイントが背後にあるものです。の。 これらのエンドポイントをコールバック関数として指定します。コールバック関数は、クライアントからエンドポイントが存在するルートに適切な要求が行われたときに起動します。 機能を実行するのはエンドポイントであり、ルートはエンドポイントへのアクセスに使用される名前であることを理解することで、上記を思い出すことができます。 後で説明するように、異なるHTTP動詞を使用して同じルートを複数のエンドポイントに関連付けることができます(ポリモーフィズムを使用する従来のOOPバックグラウンドから来た場合のメソッドのオーバーロードと同様です)。
クライアントがサーバーにリクエストを送信できるようにすることで、REST(REpresentational State Transfer)アーキテクチャに従っていることに注意してください。 結局のところ、これはRESTまたはRESTfulAPIです。 特定のルートに対して行われた特定のリクエストは、特定のことを行う特定のエンドポイントを起動します。 エンドポイントが行う可能性のあるこのような「こと」の例は、データベースへの新しいデータの追加、データの削除、データの更新などです。
Expressは、リクエストメソッド(GET、POSTなど)とルートを明示的に指定するため、起動するエンドポイントを認識します。上記の特定の組み合わせに対して起動する関数を定義し、クライアントはリクエストを行い、ルートと方法。 これをより簡単に言えば、Nodeを使用して、Expressに「誰かがこのルートにGETリクエストを行ったら、先に進んでこの関数を起動します(このエンドポイントを使用します)」と伝えます。 さらに複雑になる可能性があります。「誰かがこのルートにGETリクエストを送信したが、リクエストのヘッダーに有効なAuthorization Bearer Tokenが送信されなかった場合は、 HTTP 401 Unauthorizedで応答してください。 有効なベアラートークンを持っている場合は、エンドポイントを起動して、探していた保護されたリソースを送信してください。 どうもありがとうございました。良い一日を。」 確かに、プログラミング言語が曖昧さを漏らさずにその高レベルであることができればいいのですが、それでもそれは基本的な概念を示しています。
ある意味で、エンドポイントはルートの背後にあることを忘れないでください。 したがって、クライアントがリクエストのヘッダーで、Expressが何をすべきかを理解できるように、使用するメソッドを提供することが不可欠です。 リクエストは特定のルートに対して行われ、クライアントはサーバーに接続するときに(リクエストタイプとともに)指定します。これにより、Expressは必要な処理を実行でき、Expressがコールバックを起動したときに必要な処理を実行できます。 。 それがすべてです。
前のコード例では、 appで使用可能なlisten関数を呼び出し、ポートとコールバックを渡しました。 app自体は、覚えていれば、 express変数を関数(つまり、 express() )として呼び出した結果であり、 express変数は、 node_modulesフォルダーから'express'を要求した結果に名前を付けたものです。 アプリでlistenが呼び出されるのと同じように、 appでHTTPリクエストエンドポイントを呼び出すことでHTTPリクエストエンドポイントを指定しapp 。 GETを見てみましょう:
app.get('/my-test-route', () => { // ... }); 最初のパラメータはstringであり、エンドポイントが存在するルートです。 コールバック関数はエンドポイントです。 もう一度言いますが、コールバック関数(2番目のパラメーター)は、最初の引数として指定したルート(この場合は/my-test-route )に対してHTTPGETリクエストが行われたときに起動するエンドポイントです。
ここで、Expressで作業を行う前に、ルートがどのように機能するかを知る必要があります。 文字列として指定したルートは、 www.domain.com/the-route-we-chose-earlier-as-a-string a-stringにリクエストを送信することで呼び出されます。 この場合、ドメインはlocalhost:3000です。つまり、上記のコールバック関数を起動するには、 localhost:3000/my-test-routeに対してGETリクエストを行う必要があります。 上記の最初の引数として別の文字列を使用した場合、JavaScriptで指定したものと一致するようにURLを変更する必要があります。
そのようなことについて話すとき、あなたはおそらくグロブパターンについて聞くでしょう。 APIのすべてのルートはlocalhost:3000/** Globパターンにあると言えます。 **はワイルドカードで、ルートが親であるディレクトリまたはサブディレクトリ(ルートはディレクトリではないことに注意してください)を意味します—つまり、すべてです。
先に進んで、そのコールバック関数にlogステートメントを追加して、次のようにします。
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); プロジェクトのルートディレクトリでnode server/server.js (ノードがシステムにインストールされ、システム環境変数からグローバルにアクセス可能)を実行して、サーバーを稼働させます。 前と同じように、サーバーが起動しているというメッセージがコンソールに表示されます。 サーバーが実行されているので、ブラウザーを開き、URLバーのlocalhost:3000にアクセスします。
「 Cannot GET / 」というエラーメッセージが表示されます。 ChromeのWindowsでCtrl + Shift + Iを押して、開発者コンソールを表示します。 そこに、 404 (リソースが見つかりません)があることがわかります。 それは理にかなっています—誰かがlocalhost:3000/my-test-routeしたときに何をすべきかをサーバーに指示しただけです。 ブラウザには、 localhost:3000 (スラッシュ付きのlocalhost:3000/と同等)でレンダリングするものはありません。
サーバーが実行されているターミナルウィンドウを見ると、新しいデータはないはずです。 次に、ブラウザのURLバーでlocalhost:3000/my-test-routeにアクセスします。 Chromeのコンソールでも同じエラーが表示される場合がありますが(ブラウザがコンテンツをキャッシュしていて、レンダリングするHTMLがないため)、サーバープロセスが実行されている端末を表示すると、コールバック関数が実際に起動したことがわかります。そして、ログメッセージは実際にログに記録されました。
Ctrl + Cでサーバーをシャットダウンします。
それでは、GETリクエストがそのルートに対して行われたときにブラウザにレンダリングするものを与えて、 Cannot GET /メッセージを失う可能性があるようにします。 以前からapp.get()を取得し、コールバック関数で2つの引数を追加します。 渡すコールバック関数は舞台裏でExpressによって呼び出され、Expressは必要な引数を追加できることを忘れないでください。 実際には2つ追加されます(技術的には3つですが、後で説明します)。どちらも非常に重要ですが、今のところ最初の1つは気にしません。 2番目の引数はresと呼ばれ、 responseの略で、最初のパラメーターとしてundefinedを設定してアクセスします。
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); }); 繰り返しになりますが、 res引数は好きなように呼び出すことができますが、Expressを扱う場合はresが慣例です。 resは実際にはオブジェクトであり、その上にデータをクライアントに送り返すためのさまざまなメソッドが存在します。 この場合、 resで使用可能なsend(...)関数にアクセスして、ブラウザーがレンダリングするHTMLを送り返します。 ただし、HTMLの返送に限定されるものではなく、テキスト、JavaScriptオブジェクト、ストリーム(ストリームは特に美しい)などを返送することを選択できます。
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); res.send('<h1>Hello, World!</h1>'); }); サーバーをシャットダウンしてから元に戻し、ブラウザを/my-test-routeルートで更新すると、HTMLがレンダリングされるのがわかります。
Chromeデベロッパーツールの[ネットワーク]タブでは、ヘッダーに関連するこのGETリクエストをより詳細に確認できます。
この時点で、Expressミドルウェア(クライアントが要求を行った後にグローバルに起動できる機能)について学び始めるのに役立ちます。
エクスプレスミドルウェア
Expressは、アプリケーションのカスタムミドルウェアを定義するためのメソッドを提供します。 実際、Expressミドルウェアの意味は、ここのExpressDocsで最もよく定義されています)
ミドルウェア関数は、要求オブジェクト(
req)、応答オブジェクト(res)、およびアプリケーションの要求/応答サイクルの次のミドルウェア関数にアクセスできる関数です。 次のミドルウェア関数は通常、nextという名前の変数で示されます。
ミドルウェア機能は、次のタスクを実行できます。
- 任意のコードを実行します。
- リクエストオブジェクトとレスポンスオブジェクトに変更を加えます。
- 要求と応答のサイクルを終了します。
- スタック内の次のミドルウェア関数を呼び出します。
つまり、ミドルウェア関数は、私たち(開発者)が定義できるカスタム関数であり、Expressがリクエストを受信してから、適切なコールバック関数が起動するまでの仲介役として機能します。 たとえば、リクエストが行われるたびにログを記録するlog関数を作成する場合があります。 スタック内のどこに配置するかに応じて、エンドポイントが起動した後にこれらのミドルウェア関数を起動するように選択することもできます。これについては後で説明します。
カスタムミドルウェアを指定するには、それを関数として定義し、 app.use(...)に渡す必要があります。
const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } app.use(myMiddleware); // This is the app variable returned from express().すべて一緒に、私たちは今持っています:
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Our middleware function. const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } // Tell Express to use the middleware. app.use(myMiddleware); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); ブラウザを介して再度リクエストを行うと、ミドルウェア関数が起動してタイムスタンプをログに記録していることがわかります。 実験を促進するには、 next関数の呼び出しを削除して、何が起こるかを確認してください。
ミドルウェアのコールバック関数は、 req 、 res 、 next 3つの引数で呼び出されます。 reqは、以前にGETハンドラーを構築するときにスキップしたパラメーターであり、ヘッダー、カスタムヘッダー、パラメーター、およびクライアントから送信された可能性のある本文( POSTリクエストで行います)。 ここでミドルウェアについて話していることは知っていますが、エンドポイントとミドルウェア関数の両方がreqとresで呼び出されます。 reqとresは、クライアントからの単一の要求の範囲内で、ミドルウェアとエンドポイントの両方で同じになります(どちらかがそれを変更しない限り)。 つまり、たとえば、ミドルウェア関数を使用して、SQLまたはNoSQLインジェクションの実行を目的とした文字をすべて削除し、安全な要求をエンドポイントに渡すことで、データをreqできます。
前に見たように、 resを使用すると、いくつかの異なる方法でデータをクライアントに送り返すことができます。
nextは、スタックまたはエンドポイント内の次のミドルウェア関数を呼び出すために、ミドルウェアがジョブの実行を終了したときに実行する必要があるコールバック関数です。 ミドルウェアで起動する非同期関数のthenブロックでこれを呼び出す必要があることに注意してください。 非同期操作に応じて、 catchブロックで呼び出す場合と呼び出さない場合があります。 つまり、 myMiddleware関数は、クライアントからの要求が行われた後、要求のエンドポイント関数が実行される前に実行されます。 このコードを実行してリクエストを行うと、コンソールA GET Request was made to...前にMiddleware has fired...ました...メッセージが表示されます。 next()を呼び出さないと、後者の部分は実行されません。リクエストに対するエンドポイント関数は起動しません。
また、この関数を匿名で定義することもできます(これは私が固執する慣習です)。
app.use((req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); }); JavaScriptとES6を初めて使用する場合、上記の方法がすぐに意味をなさない場合は、以下の例が役立つはずです。 別のコールバック関数( next )を引数として取るコールバック関数(無名関数)を定義しているだけです。 関数の引数を取る関数を高階関数と呼びます。 以下のように見てください。これは、Express SourceCodeが舞台裏でどのように機能するかについての基本的な例を示しています。
console.log('Suppose a request has just been made from the client.\n'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middleware. const next = () => console.log('Terminating Middleware!\n'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the "middleware" function that is passed into "use". // "next" is the above function that pretends to stop the middleware. callback(req, res, next); }; // This is analogous to the middleware function we defined earlier. // It gets passed in as "callback" in the "use" function above. const myMiddleware = (req, res, next) => { console.log('Inside the myMiddleware function!'); next(); } // Here, we are actually calling "use()" to see everything work. use(myMiddleware); console.log('Moving on to actually handle the HTTP Request or the next middleware function.'); まず、 myMiddlewareを引数としてuseを呼び出します。 myMiddlewareは、それ自体で、 req 、 res 、 next 3つの引数を取る関数です。 use内では、 myMiddlwareが呼び出され、これらの3つの引数が渡されますnextは、 useで定義された関数です。 myMiddlewareは、 useメソッドのcallbackとして定義されています。 この例では、 appというオブジェクトをuseした場合、ソケットやネットワーク接続がなくても、Expressのセットアップを完全に模倣できたはずです。

この場合、 myMiddlewareとcallbackはどちらも関数を引数として取るため、高階関数です。
このコードを実行すると、次の応答が表示されます。
Suppose a request has just been made from the client. Inside use() - the "use" function has been called. Inside the middleware function! Terminating Middleware! Moving on to actually handle the HTTP Request or the next middleware function.同じ結果を達成するために無名関数を使用することもできたことに注意してください:
console.log('Suppose a request has just been made from the client.'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middlewear. const next = () => console.log('Terminating Middlewear!'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the function which is passed into "use". // "next" is the above function that pretends to stop the middlewear. callback(req, res, () => { console.log('Terminating Middlewear!'); }); }; // Here, we are actually calling "use()" to see everything work. use((req, res, next) => { console.log('Inside the middlewear function!'); next(); }); console.log('Moving on to actually handle the HTTP Request.');これで問題が解決したので、ミドルウェアのセットアップという実際のタスクに戻ることができます。
問題の事実は、通常、HTTPリクエストを介してデータを送信する必要があるということです。 これを行うには、いくつかの異なるオプションがあります。URLクエリパラメータを送信する、以前に学習したreqオブジェクトでアクセスできるデータを送信するなどです。このオブジェクトは、 app.use()を呼び出すためのコールバックでのみ使用できます。 app.use()だけでなく、任意のエンドポイントにも。 以前はundefinedをフィラーとして使用していたため、 resに焦点を当ててHTMLをクライアントに送り返すことができましたが、今はそれにアクセスする必要があります。
app.use('/my-test-route', (req, res) => { // The req object contains client-defined data that is sent up. // The res object allows the server to send data back down. });HTTP POSTリクエストでは、ボディオブジェクトをサーバーに送信する必要がある場合があります。 クライアントにフォームがあり、ユーザーの名前と電子メールを受け取った場合、リクエストの本文でそのデータをサーバーに送信する可能性があります。
クライアント側でどのように見えるかを見てみましょう。
<!DOCTYPE html> <html> <body> <form action="https://localhost:3000/email-list" method="POST" > <input type="text" name="nameInput"> <input type="email" name="emailInput"> <input type="submit"> </form> </body> </html>サーバー側:
app.post('/email-list', (req, res) => { // What do we now? // How do we access the values for the user's name and email? }); ユーザーの名前と電子メールにアクセスするには、特定の種類のミドルウェアを使用する必要があります。 これにより、 reqで使用可能なbodyというオブジェクトにデータが配置されます。 Body Parserはこれを行うための一般的な方法であり、Express開発者はスタンドアロンのNPMモジュールとして利用できます。 現在、Expressには、これを行うための独自のミドルウェアがあらかじめパッケージ化されており、次のように呼びます。
app.use(express.urlencoded({ extended: true }));今、私たちはできる:
app.post('/email-list', (req, res) => { console.log('User Name: ', req.body.nameInput); console.log('User Email: ', req.body.emailInput); }); これは、クライアントから送信されたユーザー定義の入力を受け取り、それらをreqのbodyオブジェクトで使用できるようにするだけです。 req.bodyに、HTMLのinputタグの名前であるnameInputとemailInputがあることに注意してください。 さて、このクライアント定義のデータは危険であると見なされるべきであり(決してクライアントを信頼しないでください)、サニタイズする必要がありますが、それについては後で説明します。
expressが提供する別のタイプのミドルウェアはexpress.json()です。 express.jsonは、クライアントからのリクエストで送信されたJSONペイロードをreq.bodyにパッケージ化するために使用されます。一方、 express.urlencodedは、文字列、配列、またはその他のURLエンコードされたデータを含む着信リクエストをreq.bodyにパッケージ化します。 つまり、どちらもreq.bodyを操作しますが、 .json()はJSONペイロード用であり、 .urlencoded()は特にPOSTクエリパラメーター用です。
別の言い方をすれば、 Content-Type: application/jsonヘッダーを持つ着信リクエスト( fetch APIでPOST本文を指定するなど)はexpress.json()によって処理されますが、ヘッダーContent-Type: application/x-www-form-urlencodedを持つリクエストはContent-Type: application/x-www-form-urlencoded (HTMLフォームなど)はexpress.urlencoded()で処理されます。 これはうまくいけば今では理にかなっています。
MongoDBのCRUDルートを開始する
注:この記事でPATCHリクエストを実行する場合、JSONPatch RFC仕様には従いません。この問題は、このシリーズの次の記事で修正します。
appで関連する関数を呼び出し、ルートと、リクエストオブジェクトとレスポンスオブジェクトを含むコールバック関数を渡すことで各エンドポイントを指定することを理解していることを考慮して、BookshelfAPIのCRUDルートの定義を開始できます。 確かに、これが紹介記事であることを考えると、HTTPとRESTの仕様に完全に従うように注意することも、可能な限りクリーンなアーキテクチャを使用することもしません。 それは将来の記事で来るでしょう。
これまで使用してきたserver.jsファイルを開き、以下のクリーンな状態から開始するためにすべてを空にします。
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true )); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 上記のファイルの// ...部分を取り上げるには、以下のすべてのコードを検討してください。
エンドポイントを定義するには、REST APIを構築しているため、ルートに名前を付ける適切な方法について説明する必要があります。 繰り返しになりますが、詳細については、以前の記事のHTTPセクションを参照してください。 私たちは本を扱っているので、すべてのルートは/booksの後ろに配置されます(複数形の命名規則が標準です)。
| リクエスト | ルート |
|---|---|
| 役職 | /books |
| 得る | /books/id |
| パッチ | /books/id |
| 消去 | /books/id |
ご覧のとおり、書籍をPOSTするときにIDを指定する必要はありません。これは、サーバー側でIDが自動的に生成されるためです(MongoDB)。 書籍の取得、パッチ適用、削除ではすべて、そのIDをエンドポイントに渡す必要があります。これについては後で説明します。 今のところ、エンドポイントを簡単に作成しましょう。
// HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); :id構文は、 idがURLで渡される動的パラメーターであることをExpressに通知します。 reqで利用可能なparamsオブジェクトでアクセスできます。 「必要に応じてアクセスできる」というのは魔法のようにreqますが、魔法(存在しない)はプログラミングでは危険ですが、Expressはブラックボックスではないことを覚えておく必要があります。 これは、MITライセンスの下でGitHubで利用できるオープンソースプロジェクトです。 動的クエリパラメータがreqオブジェクトにどのように配置されるかを確認したい場合は、そのソースコードを簡単に表示できます。
まとめると、 server.jsファイルに次のようになります。
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 先に進み、ターミナルまたはコマンドラインからnode server.jsを実行してサーバーを起動し、ブラウザーにアクセスします。 Chrome開発コンソールを開き、URL(Uniform Resource Locator)バーでlocalhost:3000/booksにアクセスします。 OSの端末には、サーバーが稼働していることを示すインジケーターと、GETのログステートメントが既に表示されているはずです。
これまで、Webブラウザを使用してGETリクエストを実行してきました。 これは始めたばかりの場合には適していますが、APIルートをテストするためのより優れたツールが存在することがすぐにわかります。 実際、 fetch呼び出しをコンソールに直接貼り付けるか、オンラインサービスを使用することができます。 この場合、時間を節約するために、 cURLとPostmanを使用します。 私はこの記事で両方を使用します(どちらかを使用できますが)。これは、使用したことがない場合に紹介できるようにするためです。 cURLは、さまざまなプロトコルを使用してデータを転送するように設計されたライブラリ(非常に重要なライブラリ)およびコマンドラインツールです。 Postmanは、APIをテストするためのGUIベースのツールです。 オペレーティングシステムで両方のツールに関連するインストール手順を実行した後、サーバーがまだ実行されていることを確認してから、新しいターミナルで次のコマンドを1つずつ実行します。 それらを入力して個別に実行してから、サーバーとは別の端末でログメッセージを確認することが重要です。 また、標準のプログラミング言語のコメント記号//は、BashまたはMS-DOSでは有効な記号ではないことに注意してください。 これらの行は省略する必要があります。ここでは、 cURLコマンドの各ブロックを説明するためにのみ使用します。
// HTTP POST Request (Localhost, IPv4, IPv6) curl -X POST https://localhost:3000/books curl -X POST https://127.0.0.1:3000/books curl -X POST https://[::1]:3000/books // HTTP GET Request (Localhost, IPv4, IPv6) curl -X GET https://localhost:3000/books/123abc curl -X GET https://127.0.0.1:3000/books/book-id-123 curl -X GET https://[::1]:3000/books/book-abc123 // HTTP PATCH Request (Localhost, IPv4, IPv6) curl -X PATCH https://localhost:3000/books/456 curl -X PATCH https://127.0.0.1:3000/books/218 curl -X PATCH https://[::1]:3000/books/some-id // HTTP DELETE Request (Localhost, IPv4, IPv6) curl -X DELETE https://localhost:3000/books/abc curl -X DELETE https://127.0.0.1:3000/books/314 curl -X DELETE https://[::1]:3000/books/217 ご覧のとおり、URLパラメータとして渡されるIDは任意の値にすることができます。 -XフラグはHTTPリクエストのタイプを指定し(GETでは省略できます)、その後リクエストが行われるURLを提供します。 各リクエストを3回複製しました。これにより、ローカルホストのホスト名、 localhostホストが解決するIPv4アドレス( 127.0.0.1 )、またはlocalhost localhostが解決するIPv6アドレス( ::1 )のいずれを使用しても、すべてが機能することがわかります。 。 cURLでは、IPv6アドレスを角かっこで囲む必要があることに注意してください。
私たちは今、まともな場所にいます—ルートとエンドポイントのシンプルな構造が設定されています。 サーバーは正しく実行され、期待どおりにHTTPリクエストを受け入れます。 予想に反して、この時点で長くはかかりません。データベースをセットアップし、ホストし(Database-as-a-Service — MongoDB Atlasを使用)、データを永続化するだけです(そして検証を実行し、エラー応答を作成します)。
本番環境のMongoDBデータベースのセットアップ
本番データベースをセットアップするには、MongoDB Atlasホームページにアクセスして、無料のアカウントにサインアップします。 その後、新しいクラスターを作成します。 デフォルト設定を維持して、料金階層の該当する地域を選択できます。 次に、「クラスターの作成」ボタンを押します。 クラスターの作成には時間がかかります。その後、データベースのURLとパスワードを取得できるようになります。 あなたがそれらを見るとき、これらに注意してください。 今のところそれらをハードコーディングし、後でセキュリティのために環境変数に保存します。 クラスターの作成と接続のヘルプについては、MongoDBドキュメント、特にこのページとこのページを参照するか、以下にコメントを残してサポートを試みます。
マングースモデルの作成
NoSQL(SQLだけでなく—構造化照会言語)のコンテキストでのドキュメントとコレクションの意味を理解することをお勧めします。 参考までに、以前の記事のMongooseクイックスタートガイドとMongoDBセクションの両方を読むことをお勧めします。
これで、CRUD操作を受け入れる準備ができたデータベースができました。 Mongooseはノードモジュール(またはODM — Object Document Mapper)であり、これらの操作を実行(複雑さの一部を抽象化)するだけでなく、データベースコレクションのスキーマまたは構造を設定することもできます。
重要な免責事項として、ORMやActiveRecordやDataMapperなどのパターンについては多くの論争があります。 一部の開発者はORMを罵倒し、他の開発者はORMを罵倒します(邪魔になると信じています)。 ORMは、接続プール、ソケット接続、処理など、多くのことを抽象化することに注意することも重要です。MongoDBネイティブドライバー(別のNPMモジュール)を簡単に使用できますが、より多くの作業が必要になります。 ORMを使用する前にネイティブドライバーで遊ぶことをお勧めしますが、簡潔にするためにここではネイティブドライバーを省略します。 リレーショナルデータベースでの複雑なSQL操作の場合、すべてのORMがクエリ速度に対して最適化されるわけではなく、独自の生のSQLを作成することになる可能性があります。 ORMは、ドメイン駆動設計やCQRSなどと多くの役割を果たすことができます。 これらは.NETの世界で確立された概念であり、Node.jsコミュニティはまだ完全には追いついていない— TypeORMの方が優れていますが、NHibernateやEntityFrameworkではありません。
To create our Model, I'll create a new folder in the server directory entitled models , within which I'll create a single file with the name book.js . Thus far, our project's directory structure is as follows:
- server - node_modules - models - book.js - package.json - server.js Indeed, this directory structure is not required, but I use it here because it's simple. Allow me to note that this is not at all the kind of architecture you want to use for larger applications (and you might not even want to use JavaScript — TypeScript could be a better option), which I discuss in this article's closing. The next step will be to install mongoose , which is performed via, as you might expect, npm i mongoose .
The meaning of a Model is best ascertained from the Mongoose documentation:
Models are fancy constructors compiled from
Schemadefinitions. An instance of a model is called a document. Models are responsible for creating and reading documents from the underlying MongoDB database.
Before creating the Model, we'll define its Schema. A Schema will, among others, make certain expectations about the value of the properties provided. MongoDB is schemaless, and thus this functionality is provided by the Mongoose ODM. Let's start with a simple example. Suppose I want my database to store a user's name, email address, and password. Traditionally, as a plain old JavaScript Object (POJO), such a structure might look like this:
const userDocument = { name: 'Jamie Corkhill', email: '[email protected]', password: 'Bcrypt Hash' };If that above object was how we expected our user's object to look, then we would need to define a schema for it, like this:
const schema = { name: { type: String, trim: true, required: true }, email: { type: String, trim: true, required: true }, password: { type: String, required: true } }; Notice that when creating our schema, we define what properties will be available on each document in the collection as an object in the schema. In our case, that's name , email , and password . The fields type , trim , required tell Mongoose what data to expect. If we try to set the name field to a number, for example, or if we don't provide a field, Mongoose will throw an error (because we are expecting a type of String ), and we can send back a 400 Bad Request to the client. This might not make sense right now because we have defined an arbitrary schema object. However, the fields of type , trim , and required (among others) are special validators that Mongoose understands. trim , for example, will remove any whitespace from the beginning and end of the string. We'll pass the above schema to mongoose.Schema() in the future and that function will know what to do with the validators.
Understanding how Schemas work, we'll create the model for our Books Collection of the Bookshelf API. Let's define what data we require:
タイトル
ISBN Number
著者
ファーストネーム
苗字
Publishing Date
Finished Reading (Boolean)
I'm going to create this in the book.js file we created earlier in /models . Like the example above, we'll be performing validation:
const mongoose = require('mongoose'); // Define the schema: const mySchema = { title: { type: String, required: true, trim: true, }, isbn: { type: String, required: true, trim: true, }, author: { firstName:{ type: String, required: true, trim: true }, lastName: { type: String, required: true, trim: true } }, publishingDate: { type: String }, finishedReading: { type: Boolean, required: true, default: false } } default will set a default value for the property if none is provided — finishedReading for example, although a required field, will be set automatically to false if the client does not send one up.
Mongoose also provides the ability to perform custom validation on our fields, which is done by supplying the validate() method, which attains the value that was attempted to be set as its one and only parameter. In this function, we can throw an error if the validation fails. 次に例を示します。
// ... isbn: { type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } } // ... Now, if anyone supplies an invalid ISBN to our model, Mongoose will throw an error when trying to save that document to the collection. I've already installed the NPM module validator via npm i validator and required it. validator contains a bunch of helper functions for common validation requirements, and I use it here instead of RegEx because ISBNs can't be validated with RegEx alone due to a tailing checksum. Remember, users will be sending a JSON body to one of our POST routes. That endpoint will catch any errors (such as an invalid ISBN) when attempting to save, and if one is thrown, it'll return a blank response with an HTTP 400 Bad Request status — we haven't yet added that functionality.
Finally, we have to define our schema of earlier as the schema for our model, so I'll make a call to mongoose.Schema() passing in that schema:
const bookSchema = mongoose.Schema(mySchema); To make things more precise and clean, I'll replace the mySchema variable with the actual object all on one line:
const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } });Let's take a final moment to discuss this schema. We are saying that each of our documents will consist of a title, an ISBN, an author with a first and last name, a publishing date, and a finishedReading boolean.
-
titlewill be of typeString, it's a required field, and we'll trim any whitespace. -
isbnwill be of typeString, it's a required field, it must match the validator, and we'll trim any whitespace. -
authoris of typeobjectcontaining a required, trimmed,stringfirstName and a required, trimmed,stringlastName. -
publishingDateis of type String (although we could make it of typeDateorNumberfor a Unix timestamp. -
finishedReadingis a requiredbooleanthat will default tofalseif not provided.
With our bookSchema defined, Mongoose knows what data and what fields to expect within each document to the collection that stores books. However, how do we tell it what collection that specific schema defines? We could have hundreds of collections, so how do we correlate, or tie, bookSchema to the Book collection?
The answer, as seen earlier, is with the use of models. We'll use bookSchema to create a model, and that model will model the data to be stored in the Book collection, which will be created by Mongoose automatically.
Append the following lines to the end of the file:
const Book = mongoose.model('Book', bookSchema); module.exports = Book; As you can see, we have created a model, the name of which is Book (— the first parameter to mongoose.model() ), and also provided the ruleset, or schema, to which all data is saved in the Book collection will have to abide. We export this model as a default export, allowing us to require the file for our endpoints to access. Book is the object upon which we'll call all of the required functions to Create, Read, Update, and Delete data which are provided by Mongoose.
Altogether, our book.js file should look as follows:
const mongoose = require('mongoose'); const validator = require('validator'); // Define the schema. const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String, required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } }); // Create the "Book" model of name Book with schema bookSchema. const Book = mongoose.model('Book', bookSchema); // Provide the model as a default export. module.exports = Book;Connecting To MongoDB (Basics)
Don't worry about copying down this code. I'll provide a better version in the next section. To connect to our database, we'll have to provide the database URL and password. We'll call the connect method available on mongoose to do so, passing to it the required data. For now, we are going hardcode the URL and password — an extremely frowned upon technique for many reasons: namely the accidental committing of sensitive data to a public (or private made public) GitHub Repository. Realize also that commit history is saved, and that if you accidentally commit a piece of sensitive data, removing it in a future commit will not prevent people from seeing it (or bots from harvesting it), because it's still available in the commit history. CLI tools exist to mitigate this issue and remove history.
As stated, for now, we'll hard code the URL and password, and then save them to environment variables later. At this point, let's look at simply how to do this, and then I'll mention a way to optimize it.
const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false, useUnifiedTopology: true });これにより、データベースに接続されます。 MongoDB Atlasダッシュボードから取得したURLを提供し、2番目のパラメーターとして渡されたオブジェクトは、特に非推奨の警告を防ぐために使用する機能を指定します。
コアのMongoDBネイティブドライバーを舞台裏で使用するMongooseは、ドライバーに加えられた重大な変更に遅れずについていく必要があります。 新しいバージョンのドライバーでは、接続URLの解析に使用されるメカニズムが変更されたため、 useNewUrlParser: trueフラグを渡して、公式ドライバーから入手可能な最新バージョンを使用することを指定します。
デフォルトでは、データベース内のデータにインデックス(および「インデックス」ではなく「インデックス」と呼ばれる)(この記事では取り上げません)を設定すると、Mongooseはネイティブドライバーから利用できるensureIndex()関数を使用します。 MongoDBは、 createIndex()を優先してその関数を非推奨にしたため、フラグuseCreateIndexをtrueに設定すると、非推奨ではない関数であるドライバーからcreateIndex()メソッドを使用するようにMongooseに指示します。
Mongooseの元のバージョンのfindOneAndUpdate (データベース内のドキュメントを検索して更新する方法)は、ネイティブドライバーのバージョンよりも前のものです。 つまり、 findOneAndUpdate()は元々ネイティブドライバー関数ではなく、Mongooseによって提供されたものであったため、Mongooseは、ドライバーによってバックグラウンドで提供されたfindAndModifyを使用してfindOneAndUpdate機能を作成する必要がありました。 ドライバーが更新されたので、ドライバーにはそのような関数が含まれているため、 findAndModifyを使用する必要はありません。 これは意味をなさないかもしれません、そしてそれは大丈夫です—それは物事の規模に関する重要な情報ではありません。
最後に、MongoDBは古いサーバーとエンジン監視システムを廃止しました。 useUnifiedTopology: trueで新しいメソッドを使用します。
これまでのところ、データベースに接続する方法があります。 しかし、ここに問題があります。スケーラブルでも効率的でもありません。 このAPIの単体テストを作成する場合、単体テストは独自のテストデータベースで独自のテストデータ(またはフィクスチャ)を使用します。 そのため、さまざまな目的で接続を作成できる方法が必要です。テスト環境(自由にスピンアップおよびティアダウンできる)用、開発環境用、本番環境用などです。 そのために、工場を建設します。 (以前から覚えていますか?)
Mongoへの接続—JSファクトリーの実装の構築
実際、JavaオブジェクトはJavaScriptオブジェクトとまったく類似していないため、その後、ファクトリデザインパターンから上記でわかったことは適用されません。 伝統的なパターンを示すために、例としてそれを提供しただけです。 Java、C#、C ++などでオブジェクトを取得するには、クラスをインスタンス化する必要があります。 これは、ヒープ上のオブジェクトにメモリを割り当てるようにコンパイラに指示するnewキーワードを使用して行われます。 C ++では、これにより、自分でクリーンアップする必要のあるオブジェクトへのポインターが得られるため、ポインターがぶら下がったり、メモリリークが発生したりすることはありません(C ++で構築されたNode / V8とは異なり、C ++にはガベージコレクターがありません)。上記を行う必要はありません—オブジェクトを取得するためにクラスをインスタンス化する必要はありません—オブジェクトは単なる{}です。 JavaScriptのすべてがオブジェクトであると言う人もいますが、プリミティブ型はオブジェクトではないため、技術的には正しくありません。
上記の理由により、JSファクトリはより単純になり、オブジェクト(JSオブジェクト)を返す関数であるファクトリの大まかな定義に固執します。 関数はオブジェクトであるため( functionはプロトタイプの継承を介してobjectから継承します)、以下の例はこの基準を満たします。 ファクトリを実装するために、 server内にdbという名前の新しいフォルダーを作成します。 db内に、 mongoose.jsという新しいファイルを作成します。 このファイルはデータベースに接続します。 mongoose.js内に、 connectionFactoryという関数を作成し、デフォルトでエクスポートします。
// Directory - server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; const connectionFactory = () => { return mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false }); }; module.exports = connectionFactory; メソッドシグネチャと同じ行に1つのステートメントを返すArrowFunctionsのES6で提供される省略形を使用して、 connectionFactory定義を削除し、デフォルトでファクトリをエクスポートすることで、このファイルを単純化します。
// server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; module.exports = () => mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: true });これで、ファイルを要求し、エクスポートされるメソッドを次のように呼び出すだけで済みます。
const connectionFactory = require('./db/mongoose'); connectionFactory(); // OR require('./db/mongoose')();MongoDB URLをファクトリ関数のパラメーターとして提供することで制御を反転できますが、環境に基づいて環境変数としてURLを動的に変更します。
関数として接続することの利点は、コードの後半でその関数を呼び出して、本番環境を対象としたファイルと、デバイス上とリモートCI / CDパイプラインの両方を使用したローカルおよびリモート統合テストを目的としたファイルからデータベースに接続できることです。 / buildサーバー。
エンドポイントの構築
ここで、非常に単純なCRUD関連のロジックをエンドポイントに追加し始めます。 前に述べたように、短い免責事項が必要です。 ここでビジネスロジックを実装する方法は、単純なプロジェクト以外の場合にミラーリングする必要がある方法ではありません。 データベースに接続し、エンドポイント内でロジックを直接実行することは、アプリケーション全体のリファクタリングを実行せずにサービスまたはDBMSをスワップアウトする機能を失うため、眉をひそめます(そしてそうすべきです)。 それにもかかわらず、これは初心者向けの記事であることを考慮して、私はここでこれらの悪い慣行を採用しています。 このシリーズの今後の記事では、アーキテクチャの複雑さと品質の両方を向上させる方法について説明します。
とりあえず、 server.jsファイルに戻って、両方の開始点が同じであることを確認しましょう。 データベース接続ファクトリにrequireステートメントを追加し、。 ./models/book.jsからエクスポートしたモデルをインポートしたことに注意してください。
const express = require('express'); // Database connection and model. require('./db/mongoose.js'); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); app.post()から始めます。 Bookモデルは、作成したファイルからエクスポートしたため、アクセスできます。 マングースのドキュメントに記載されているように、 Bookは構築可能です。 新しい本を作成するには、コンストラクターを呼び出して、次のように本のデータを渡します。
const book = new Book(bookData); この場合、リクエストで送信されるオブジェクトとしてbookDataがあり、これはreq.body.bookで利用できます。 express.json()ミドルウェアは、送信するJSONデータをreq.bodyに配置することを忘れないでください。 JSONを次の形式で送信します。
{ "book": { "title": "The Art of Computer Programming", "isbn": "ISBN-13: 978-0-201-89683-1", "author": { "firstName": "Donald", "lastName": "Knuth" }, "publishingDate": "July 17, 1997", "finishedReading": true } } つまり、渡したJSONが解析され、JSONオブジェクト全体(中括弧の最初のペア)がexpress.json()ミドルウェアによってreq.bodyに配置されます。 JSONオブジェクトの唯一のプロパティはbookであるため、 bookオブジェクトはreq.body.bookで利用できます。
この時点で、モデルコンストラクター関数を呼び出してデータを渡すことができます。
app.post('/books', async (req, res) => { // <- Notice 'async' const book = new Book(req.body.book); await book.save(); // <- Notice 'await' }); ここでいくつかのことに注意してください。 コンストラクター関数の呼び出しから戻ったインスタンスでsaveメソッドを呼び出すと、Mongooseモデルで定義したスキーマに準拠している場合に限り、 req.body.bookオブジェクトがデータベースに保持されます。 データをデータベースに保存する動作は非同期操作であり、このsave()メソッドはpromiseを返します。これは、私たちが待ち望んでいる解決策です。 .then()呼び出しをチェーンするのではなく、ES6 Async / Await構文を使用します。 async 、 app.postへのコールバック関数を作成する必要があります。
book.save()は、クライアントが送信したオブジェクトが定義したスキーマに準拠していない場合、 ValidationErrorで拒否します。 現在の設定では、検証に関する失敗が発生した場合にアプリケーションがクラッシュしないようにするため、非常に不安定で不適切に記述されたコードが作成されます。 これを修正するために、危険な操作をtry/catch句で囲みます。 エラーが発生した場合は、HTTP 400 BadRequestまたはHTTP422 UnprocessableEntityを返します。 どちらを使用するかについてはある程度の議論がありますが、より一般的であるため、この記事では400を使用します。
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { return res.status(400).send({ error: 'ValidationError' }); } }); ES6 Object Shorthandを使用して、 res.send({ book })を使用して成功した場合に、 bookオブジェクトをクライアントに返すことに注意してください。これはres.send({ book: book })と同等です。 また、関数が終了することを確認するためだけに式を返します。 catchブロックで、ステータスを明示的に400に設定し、返送されるオブジェクトのerrorプロパティに文字列「ValidationError」を返します。 201は、「CREATED」を意味する成功パスのステータスコードです。
実際、失敗の理由がクライアント側の不正な要求であるかどうかを実際に確認できないため、これも最善の解決策ではありません。 データベースへの接続が失われた可能性があります(ソケット接続が切断されたため、一時的な例外であると想定されます)。この場合、500内部サーバーエラーが返される可能性があります。 これを確認する方法は、 eエラーオブジェクトを読み取り、選択的に応答を返すことです。 今それをやってみましょう、しかし私が何度も言ったように、フォローアップ記事はルーター、コントローラー、サービス、リポジトリ、カスタムエラークラス、カスタムエラーミドルウェア、カスタムエラー応答、データベースモデル/ドメインエンティティデータの観点から適切なアーキテクチャについて議論しますマッピング、およびコマンドクエリ分離(CQS)。
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'ValidationError' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); 先に進み、Postmanを開いて(持っていると仮定します。そうでない場合は、ダウンロードしてインストールします)、新しいリクエストを作成します。 localhost:3000/booksにPOSTリクエストを送信します。 Postman Requestセクションの[Body]タブで、[raw]ラジオボタンを選択し、右端のドロップダウンボタンで[JSON]を選択します。 これにより、 Content-Type: application/jsonヘッダーがリクエストに自動的に追加されます。 次に、以前のBookJSONオブジェクトをコピーして本文のテキスト領域に貼り付けます。 これは私たちが持っているものです:
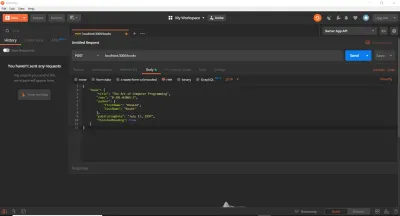
その後、送信ボタンを押すと、Postmanの「Response」セクション(下の行)に201Created応答が表示されます。 これは、Expressに201とBookオブジェクトで応答するように特に要求したためです。ステータスコードなしでres.send()を実行した場合、 expressは自動的に200OKで応答します。 ご覧のとおり、Bookオブジェクトはデータベースに保存され、POSTリクエストへの応答としてクライアントに返されます。
MongoDB Atlasを介してデータベースのBookコレクションを表示すると、その本が実際に保存されていることがわかります。
また、MongoDBが__vフィールドと_idフィールドを挿入したこともわかります。 前者はドキュメントのバージョン(この場合は0)を表し、後者はドキュメントのObjectIDです。これはMongoDBによって自動的に生成され、衝突の可能性が低いことが保証されています。
これまでに取り上げた内容の要約
これまでの記事で多くのことを取り上げてきました。 Express APIを終了するために戻る前に、簡単な要約を確認して、少し時間を取ってみましょう。
ES6 Object Destructuring、ES6 Object Shorthand Syntax、およびES6 Rest / Spread演算子について学びました。 これらの3つすべてで、次のことを実行できます(上記で説明したように、さらに多くのことを実行できます)。
// Destructuring Object Properties: const { a: newNameA = 'Default', b } = { a: 'someData', b: 'info' }; console.log(`newNameA: ${newNameA}, b: ${b}`); // newNameA: someData, b: info // Destructuring Array Elements const [elemOne, elemTwo] = [() => console.log('hi'), 'data']; console.log(`elemOne(): ${elemOne()}, elemTwo: ${elemTwo}`); // elemOne(): hi, elemTwo: data // Object Shorthand const makeObj = (name) => ({ name }); console.log(`makeObj('Tim'): ${JSON.stringify(makeObj('Tim'))}`); // makeObj('Tim'): { "name": "Tim" } // Rest, Spread const [c, d, ...rest] = [0, 1, 2, 3, 4]; console.log(`c: ${c}, d: ${d}, rest: ${rest}`) // c: 0, d: 1, rest: 2, 3, 4 Express、Expessミドルウェア、サーバー、ポート、IPアドレス指定などについても説明しました。require require('express')(); app.getやapp.postなどのHTTP動詞の名前を使用します。
そのrequire('express')()の部分があなたにとって意味をなさなかった場合、これが私が言っていたポイントでした:
const express = require('express'); const app = express(); app.someHTTPVerb以前にマングースのために接続ファクトリを解雇したのと同じように意味があるはずです。
エンドポイント関数(またはコールバック関数)である各ルートハンドラーは、舞台裏でExpressからreqオブジェクトとresオブジェクトに渡されます。 (技術的にはnextも取得します。これについては後で説明します)。 reqには、ヘッダーや送信されたJSONなど、クライアントからの着信リクエストに固有のデータが含まれます。 resは、クライアントに応答を返すことを可能にするものです。 next関数もハンドラーに渡されます。
Mongooseを使用して、2つの方法でデータベースに接続する方法を確認しました。プリミティブな方法と、ファクトリパターンから借用するより高度で実用的な方法です。 これを使用して、Jestを使用したユニットテストと統合テスト(およびミューテーションテスト)について説明します。これにより、アサーションを実行できるシードデータが入力されたDBのテストインスタンスを起動できるようになります。
その後、Mongooseスキーマオブジェクトを作成し、それを使用してモデルを作成し、そのモデルのコンストラクターを呼び出して新しいインスタンスを作成する方法を学びました。 インスタンスで使用できるのは(とりわけ) saveメソッドです。これは本質的に非同期であり、渡したオブジェクト構造がスキーマに準拠していることを確認し、準拠している場合はPromiseを解決し、準拠している場合はValidationErrorでPromiseを拒否します。そうではありません。 解決の場合、新しいドキュメントはデータベースに保存され、HTTP 200 OK / 201 CREATEDで応答します。それ以外の場合は、エンドポイントでスローされたエラーをキャッチし、HTTP 400 BadRequestをクライアントに返します。
エンドポイントの構築を続けると、モデルとモデルインスタンスで使用できるいくつかのメソッドについて詳しく知ることができます。
エンドポイントの仕上げ
POSTエンドポイントが完了したら、GETを処理しましょう。 前述したように、ルート内の:id構文により、Expressは、 idがルートパラメーターであり、 req.paramsからアクセスできることを認識できます。 ルート内のパラメータ「ワイルドカード」のIDを一致させると、初期の例で画面に出力されたことはすでに見てきました。 たとえば、「/ books / test-id-123」に対してGETリクエストを行った場合、パラメータ名はHTTP GET /books/:idとしてルートを持つことでidであったため、 req.params.idは文字列test-id-123になります。 HTTP GET /books/:id 。
したがって、必要なのは、 reqオブジェクトからそのIDを取得し、データベース内のドキュメントが同じIDを持っているかどうかを確認することです。これは、Mongoose(およびネイティブドライバー)によって非常に簡単になりました。
app.get('/books/:id', async (req, res) => { const book = await Book.findById(req.params.id); console.log(book); res.send({ book }); }); モデルでアクセスできるのは、IDでドキュメントを検索する呼び出し可能な関数であることがわかります。 舞台裏では、MongooseはfindByIdに渡したIDを、ドキュメントの_idフィールドのタイプ(この場合はObjectId )にキャストします。 一致するIDが見つかった場合(そしてObjectIdの衝突確率が非常に低い場合は1つしか見つかりません)、そのドキュメントはbook定数変数に配置されます。 そうでない場合、 bookはnullになります—近い将来に使用する事実です。
今のところ、サーバーを再起動して( nodemonを使用している場合を除き、サーバーを再起動する必要があります)、 Booksコレクション内に以前の1冊の本のドキュメントが残っていることを確認します。 先に進み、そのドキュメントのID、下の画像の強調表示された部分をコピーします。

そして、それを使用して、次のようにPostmanで/books/:idにGETリクエストを作成します(本文データは以前のPOSTリクエストから残っていることに注意してください。下の画像に示されているにもかかわらず、実際には使用されていません) :
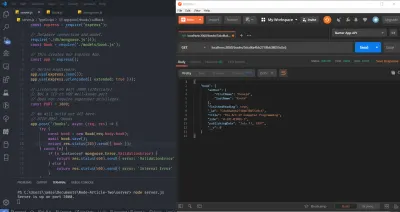
そうすると、指定されたIDの本のドキュメントがPostmanの応答セクションに戻されます。 以前、サーバーに新しいリソースを「POST」または「プッシュ」するように設計されたPOSTルートでは、新しいリソース(またはドキュメント)が作成されたため、201Createdで応答したことに注意してください。 GETの場合、新しいものは何も作成されませんでした。特定のIDを持つリソースをリクエストしただけなので、201 Createdではなく、200OKステータスコードが返されます。
ソフトウェア開発の分野で一般的であるように、エッジケースを考慮する必要があります。ユーザー入力は本質的に安全ではなく誤っています。開発者としての私たちの仕事は、与えられる入力の種類に柔軟に対応し、それに対応することです。によると。 ユーザー(またはAPI呼び出し元)がMongoDB ObjectIDにキャストできないID、またはキャストできるが存在しないIDを渡した場合はどうすればよいですか?
前者の場合、MongooseはCastErrorをスローします。これは、 math-is-funようなIDを提供する場合、それは明らかにObjectIDにキャストできるものではなく、ObjectIDにキャストすることが具体的には何であるかを理解できます。マングースはボンネットの下でやっています。
後者の場合、ヌルチェックまたはガード句を使用して問題を簡単に修正できます。 いずれにせよ、HTTP404が見つかりませんという応答を送り返します。 これを行うためのいくつかの方法、悪い方法、そしてより良い方法を紹介します。
まず、次のことができます。
app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) throw new Error(); return res.send({ book }); } catch (e) { return res.status(404).send({ error: 'Not Found' }); } }); これは機能し、問題なく使用できます。 ID文字列をObjectIDにキャストできない場合、ステートメントawait Book.findById()がMongoose CastErrorをスローし、 catchブロックが実行されることを期待しています。 キャストできるが、対応するObjectIDが存在しない場合、 bookはnullになり、Null Checkはエラーをスローし、 catchブロックを再度起動します。 catch内では、404を返すだけです。ここには2つの問題があります。 まず、本が見つかったが他の不明なエラーが発生した場合でも、クライアントに一般的なキャッチオール500を提供する必要がある場合は、404を送り返します。次に、送信されたIDが有効かどうかを実際に区別していませんが、存在しない、または単に不正なIDであるかどうか。
だから、ここに別の方法があります:
const mongoose = require('mongoose'); app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); これの良いところは、400、404、および汎用500の3つのケースすべてを処理できることです。 bookのヌルチェックの後、応答でreturnキーワードを使用していることに注意してください。 ここでルートハンドラーを確実に終了する必要があるため、これは非常に重要です。
他のいくつかのオプションは、Mongooseがmongoose.Types.ObjectId.isValid mongoose.Types.ObjectId.isValid('id);を使用して暗黙的にキャストすることを許可するのではなく、 req.paramsのidを明示的にObjectIDにキャストできるかどうかを確認することです。 、ただし、これが予期せず機能することがある12バイトの文字列のエッジケースがあります。
たとえば、HTTP応答ライブラリであるBoomを使用して、この繰り返しの苦痛を軽減することも、エラー処理ミドルウェアを使用することもできます。 ここで説明するように、MongooseエラーをMongooseフック/ミドルウェアでより読みやすいものに変換することもできます。 追加のオプションは、カスタムエラーオブジェクトを定義し、グローバルExpressエラー処理ミドルウェアを使用することですが、より良いアーキテクチャ方法について説明する次の記事のためにそれを保存します。
PATCH /books/:idのエンドポイントでは、問題の本の更新を含む更新オブジェクトが渡されることが期待されます。 この記事では、すべてのフィールドの更新を許可しますが、将来的には、特定のフィールドの更新を禁止する方法を示します。 さらに、PATCHエンドポイントのエラー処理ロジックがGETエンドポイントと同じになることがわかります。 これは、DRY Principlesに違反していることを示していますが、これについては後で触れます。
すべての更新がreq.bodyのupdatesオブジェクトで利用可能であり(クライアントがupdatesオブジェクトを含むJSONを送信することを意味します)、更新を実行するために特別なフラグを指定してBook.findByAndUpdate関数を使用することを期待します。
app.patch('/books/:id', async (req, res) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); ここでいくつかのことに注意してください。 まず、 req.paramsからidを分解し、 req.bodyからupdatesします。
Bookモデルで使用できるのは、問題のドキュメントのID、実行する更新、およびオプションのオプションオブジェクトを取得するfindByIdAndUpdateという名前の関数です。 通常、Mongooseは更新操作の検証を再実行しないため、 optionsオブジェクトとして渡されるrunValidators: trueフラグにより、強制的に実行されます。 さらに、Mongoose 4以降、 Model.findByIdAndUpdateは変更されたドキュメントを返さなくなり、代わりに元のドキュメントを返します。 new: trueフラグ(デフォルトではfalse)は、その動作をオーバーライドします。
最後に、他のすべてと非常によく似たDELETEエンドポイントを構築できます。
app.delete('/books/:id', async (req, res) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } });これで、プリミティブAPIが完成し、すべてのエンドポイントにHTTPリクエストを送信してテストできます。
アーキテクチャとそれを修正する方法についての短い免責事項
アーキテクチャの観点から、ここにあるコードは非常に悪く、乱雑で、DRYでも、SOLIDでもありません。実際、それを忌まわしいと呼ぶかもしれません。 これらのいわゆる「ルートハンドラー」は、単なる「ルートの処理」以上のことを行っています。これらは、データベースと直接やり取りしています。 つまり、抽象化はまったくありません。
それに直面しましょう。ほとんどのアプリケーションはこれほど小さくなることはありません。さもないと、FirebaseDatabaseを使用してサーバーレスアーキテクチャを回避できる可能性があります。 後で説明するように、ユーザーは自分の本などからアバター、引用、スニペットをアップロードする機能を望んでいる可能性があります。WebSocketを使用してユーザー間にライブチャット機能を追加したい場合もあります。アプリケーションを開いて、ユーザーが小額の料金で本を互いに借りられるようにします。その時点で、Stripe APIを使用した支払い統合と、ShippoAPIを使用した配送ロジスティクスを検討する必要があります。
現在のアーキテクチャを続行し、この機能をすべて追加するとします。 これらのルートハンドラーは、コントローラーアクションとも呼ばれ、循環的複雑度が高く、非常に大きくなることになります。 このようなコーディングスタイルは、初期の段階ではうまくいくかもしれませんが、データが参照であり、したがってPostgreSQLがMongoDBよりも優れたデータベースの選択肢であると判断した場合はどうでしょうか。 ここで、アプリケーション全体をリファクタリングし、Mongooseを削除し、コントローラーを変更する必要があります。これらはすべて、残りのビジネスロジックに潜在的なバグをもたらす可能性があります。 もう1つの例は、AWS S3が高すぎると判断し、GCPに移行したいという例です。 繰り返しますが、これにはアプリケーション全体のリファクタリングが必要です。
ドメイン駆動設計、コマンドクエリ責任分離、イベントソーシングから、テスト駆動開発、SOILD、階層化アーキテクチャ、オニオンアーキテクチャなど、アーキテクチャについては多くの意見がありますが、ここでは単純な階層化アーキテクチャの実装に焦点を当てます。コントローラー、サービス、リポジトリーで構成され、コンポジション、アダプター/ラッパー、依存性注入による制御の反転などのデザインパターンを採用した今後の記事。 ある程度、これはJavaScriptである程度実行できますが、このアーキテクチャを実現するためのTypeScriptオプションについても検討し、ジェネリックスなどのOOP概念に加えて、EitherMonadsなどの関数型プログラミングパラダイムを採用できるようにします。
今のところ、2つの小さな変更を加えることができます。 エラー処理ロジックはすべてのエンドポイントのcatchブロックで非常に似ているため、スタックの最後にあるカスタムExpressエラー処理ミドルウェア関数に抽出できます。
アーキテクチャのクリーンアップ
現在、すべてのエンドポイントで非常に大量のエラー処理ロジックを繰り返しています。 代わりに、Expressエラー処理ミドルウェア関数を作成できます。これは、エラー、reqオブジェクトとresオブジェクト、および次の関数で呼び出されるExpressミドルウェア関数です。
今のところ、そのミドルウェア関数を構築しましょう。 私がやろうとしているのは、私たちが慣れているのと同じエラー処理ロジックを繰り返すことです。
app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); これはMongooseエラーでは機能しないようですが、一般に、 if/else if/elseを使用してエラーインスタンスを判別するのではなく、エラーのコンストラクターを切り替えることができます。 ただし、持っているものは残しておきます。
同期エンドポイント/ルートハンドラーでは、エラーをスローすると、Expressがエラーをキャッチして処理し、追加の作業は必要ありません。 残念ながら、それは私たちには当てはまりません。 非同期コードを扱っています。 エラー処理を非同期ルートハンドラーを使用してExpressに委任するために、エラーを自分でキャッチしてnext()に渡します。
したがって、 nextをエンドポイントへの3番目の引数にすることを許可し、 catchブロックのエラー処理ロジックを削除して、エラーインスタンスをnextに渡すだけにします。
app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { next(e) } });すべてのルートハンドラーに対してこれを行うと、次のコードになります。
const express = require('express'); const mongoose = require('mongoose'); // Database connection and model. require('./db/mongoose.js')(); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { next(e) } }); // HTTP GET /books/:id app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { next(e); } }); // HTTP PATCH /books/:id app.patch('/books/:id', async (req, res, next) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { next(e); } }); // HTTP DELETE /books/:id app.delete('/books/:id', async (req, res, next) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { next(e); } }); // Notice - bottom of stack. app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); さらに進んで、エラー処理ミドルウェアを別のファイルに分割することは価値がありますが、それは些細なことであり、このシリーズの今後の記事で説明します。 さらに、 express-async-errorsという名前のNPMモジュールを使用して、catchブロックで次に呼び出す必要がないようにすることもできますが、ここでも、公式にどのように行われるかを示しています。
CORSと同一生成元ポリシーについての一言
WebサイトがドメインmyWebsite.comから提供されているが、サーバーがmyOtherDomain.com/apiにあるとします。 CORSはCross-OriginResource Sharingの略で、クロスドメインリクエストを実行できるメカニズムです。 上記の場合、サーバーとフロントエンドJSコードは異なるドメインにあるため、2つの異なるオリジン間でリクエストを行うことになります。これは通常、セキュリティ上の理由からブラウザによって制限され、特定のHTTPヘッダーを提供することで軽減されます。
同一生成元ポリシーは、前述の制限を実行するものです。Webブラウザーは、同じ生成元での作成のみを許可します。
後で、Reactを使用してBook APIのWebpackバンドルフロントエンドを構築するときに、CORSとSOPについて触れます。
結論と次のステップ
この記事では多くのことを議論しました。 おそらくそれはすべて完全に実用的ではありませんでしたが、うまくいけば、ExpressとES6のJavaScript機能をより快適に操作できるようになりました。 プログラミングに不慣れで、Nodeが最初の道である場合は、Java、C ++、C#などの静的型言語への参照が、JavaScriptとそれに対応する静的言語の違いを強調するのに役立つことを願っています。
Next time, we'll finish building out our Book API by making some fixes to our current setup with regards to the Book Routes, as well as adding in User Authentication so that users can own books. We'll do all of this with a similar architecture to what I described here and with MongoDB for data persistence. Finally, we'll permit users to upload avatar images to AWS S3 via Buffers.
In the article thereafter, we'll be rebuilding our application from the ground up in TypeScript, still with Express. We'll also move to PostgreSQL with Knex instead of MongoDB with Mongoose as to depict better architectural practices. Finally, we'll update our avatar image uploading process to use Node Streams (we'll discuss Writable, Readable, Duplex, and Transform Streams). Along the way, we'll cover a great amount of design and architectural patterns and functional paradigms, including:
- Controllers/Controller Actions
- サービス
- リポジトリ
- データマッピング
- The Adapter Pattern
- The Factory Pattern
- The Delegation Pattern
- OOP Principles and Composition vs Inheritance
- Inversion of Control via Dependency Injection
- SOLIDの原則
- Coding against interfaces
- Data Transfer Objects
- Domain Models and Domain Entities
- Either Monads
- 検証
- デコレータ
- Logging and Logging Levels
- Unit Tests, Integration Tests (E2E), and Mutation Tests
- The Structured Query Language
- 関係
- HTTP/Express Security Best Practices
- Node Best Practices
- OWASP Security Best Practices
- もっと。
Using that new architecture, in the article after that, we'll write Unit, Integration, and Mutation tests, aiming for close to 100 percent testing coverage, and we'll finally discuss setting up a remote CI/CD pipeline with CircleCI, as well as Message Busses, Job/Task Scheduling, and load balancing/reverse proxying.
Hopefully, this article has been helpful, and if you have any queries or concerns, let me know in the comments below.