
Pythonのデータ構造–完全ガイド
公開: 2021-06-14目次
データ構造とは何ですか?
データ構造とは、効率的に使用するためのデータの計算ストレージを指します。 簡単に変更およびアクセスできる方法でデータを保存します。 これは、データ値、それらの間の関係、およびデータに対して実行できる操作をまとめて参照します。 データ構造の重要性は、コンピュータプログラムを開発するためのそのアプリケーションにあります。 コンピュータプログラムはデータに大きく依存しているため、簡単にアクセスできるようにデータを適切に配置することは、どのプログラムやソフトウェアにとっても最も重要です。
データ構造の4つの主な機能は次のとおりです。
- 情報を入力するには
- 情報を処理するには
- 情報を維持するため
- 情報を取得するには
Pythonのデータ構造の種類
Pythonでは、データへのアクセスと保存を容易にするために、いくつかのデータ構造がサポートされています。 Pythonデータ構造タイプは、プリミティブデータ型と非プリミティブデータ型に分類できます。 前者のデータ型には整数、浮動小数点数、文字列、ブール値が含まれ、後者のデータ型は配列、リスト、タプル、辞書、セット、ファイルです。 したがって、 Pythonのデータ構造は、組み込みのデータ構造とユーザー定義のデータ構造の両方です。 組み込みのデータ構造は、非プリミティブデータ構造と呼ばれます。
組み込みのデータ構造
Pythonには、他のデータを格納するためのコンテナーとして機能するデータの構造がいくつかあります。 これらのPythonデータ構造は、リスト、辞書、タプル、およびセットです。
ユーザー定義のデータ構造
これらのデータ構造は、Pythonの組み込みデータ構造と同じ機能としてプログラムできます。 ユーザー定義のデータ構造は、リンクリスト、スタック、キュー、ツリー、グラフ、およびハッシュマップです。
ビルド内のデータ構造と説明のリスト
1.リスト
リストに格納されているデータは、データタイプが異なる順に並べられています。 すべてのデータにアドレスが割り当てられ、それはインデックスと呼ばれます。 インデックス値は0から始まり、最後の要素まで続きます。 これはポジティブインデックスと呼ばれます。 要素が逆にアクセスされる場合にも、負のインデックスが存在します。 これはネガティブインデックスと呼ばれます。
リストの作成
リストは角括弧として作成されます。 その後、要素を適宜追加できます。 角かっこ内に追加してリストを作成できます。 要素が追加されていない場合、空のリストが作成されます。 それ以外の場合は、リスト内の要素が作成されます。
| 入力 my_list = []#空のリストを作成 print(my_list) my_list = [1、2、3、'example'、3.132]#データを使用してリストを作成する print(my_list) | 出力 [] [1、2、3、'例'、3.132] |
リスト内に要素を追加する
リスト内の要素の追加には、3つの関数が使用されます。 これらの関数は、append()、extend()、およびinsert()です。
- すべての要素は、append()関数を使用して単一の要素として追加されます。
- リストに要素を1つずつ追加するには、extend()関数を使用します。
- インデックス値で要素を追加するには、insert()関数を使用します。
| 入力 my_list = [1、2、3] print(my_list) my_list.append([555、12])#単一の要素として追加 print(my_list) my_list.extend([234、'more_example'])#異なる要素として追加 print(my_list) my_list.insert(1、'insert_example')#要素を追加i print(my_list) | 出力: [1、2、3] [1、2、3、[555、12]] [1、2、3、[555、12]、234、'more_example'] [1、'insert_example'、2、3、[555、12]、234、'more_example'] |
リスト内の要素の削除
Pythonの組み込みキーワード「del」は、リストから要素を削除するために使用されます。 ただし、この関数は削除された要素を返しません。
- 削除された要素を返すために、pop()関数が使用されます。 削除する要素のインデックス値を使用します。
- remove()関数は、要素をその値で削除するために使用されます。
出力:
[1、2、3、'例'、3.132、30]
[1、2、3、3.132、30]
ポップされた要素:2残りのリスト:[1、3、3.132、30]
[]
リスト内の要素の評価
- リスト内の要素の評価は簡単です。 リストを印刷すると、要素が直接表示されます。
- インデックス値を渡すことで、特定の要素を評価できます。
出力:
1
2
3
例
3.132
10
30
[1、2、3、'例'、3.132、10、30]
例
[1、2]
[30、10、3.132、「例」、3、2、1]
上記の操作に加えて、リストを操作するために、Pythonで他のいくつかの組み込み関数を使用できます。
- len():この関数は、リストの長さを返すために使用されます。
- index():この関数を使用すると、ユーザーは渡された値のインデックス値を知ることができます。
- count()関数は、渡された値のカウントを見つけるために使用されます。
- sort()はリスト内の値をソートし、リストを変更します。
- sorted()はリスト内の値をソートし、リストを返します。
出力
6
3
2
[1、2、3、10、10、30]
[30、10、10、3、2、1]
2.辞書
ディクショナリは、単一の要素ではなく、キーと値のペアが格納されるデータ構造の一種です。 これは、電話番号とともにすべての個人の番号が含まれている電話帳の例で説明できます。 ここでの名前と電話番号は、「キー」である定数値と、そのキーの値としてのすべての個人の番号と名前を定義します。 キーを評価すると、そのキー内に保存されているすべての値にアクセスできるようになります。 Pythonで定義されたこのキー値構造は、ディクショナリと呼ばれます。
辞書の作成
- dict()関数をアイドル状態にする花の中括弧は、辞書の作成に使用できます。
- キーと値のペアは、辞書の作成中に追加されます。
キーと値のペアの変更
辞書の変更は、キーを介してのみ行うことができます。 したがって、最初にキーにアクセスしてから、変更を実行する必要があります。
| 入力 my_dict = {'First':'Python'、'Second':'Java'} print(my_dict)my_dict ['Second'] ='C ++' #changing element print(my_dict)my_dict ['Third'] ='Ruby' #キーと値のペアを追加するprint(my_dict) | 出力: {'First':'Python'、'Second':'Java'} {'First':'Python'、'Second':'C ++'} {'First':'Python'、'Second':'C ++'、'Third':'Ruby'} |
辞書の削除
clear()関数は、辞書全体を削除するために使用されます。 辞書は、get()関数を使用するか、キー値を渡すことで、キーを介して評価できます。
| 入力 dict = {'Month':'January'、'Season':'winter'} print(dict ['First']) print(dict.get('Second') | 出力 一月 冬 |
ディクショナリに関連する他の関数は、keys()、values()、およびitems()です。
3.タプル
リストと同様に、タプルはデータストレージリストですが、唯一の違いは、タプルに格納されているデータを変更できないことです。 タプル内のデータが変更可能である場合にのみ、データを変更できます。
- タプルは、tuple()関数を使用して作成できます。
入力
new_tuple =(10、20、30、40)
print(new_tuple)
出力
(10、20、30、40)
- タプル内の要素は、リスト内の要素を評価するのと同じ方法で評価できます。
入力
new_tuple2 =(10、20、30、'年齢')
new_tuple2のxの場合:
print(x)
print(new_tuple2)
print(new_tuple2 [0])
出力
10
20
30
年
(10、20、30、「年齢」)
10
- '+'演算子は、別のタプルを追加するために使用されます
入力
タプル=(1、2、3)
タプル=タプル+(4、5、6
print(タプル)
出力
(1、2、3、4、5、6)
4.セット
セットのデータ構造は、算術セットに似ています。 それは基本的にユニークな要素のコレクションです。 データが繰り返され続ける場合、セットはその要素を1回だけ追加することを検討します。

- 花括弧内に値を渡すだけでセットを作成できます。
入力
セット={10、20、30、40、40、40}
print(set)
出力
{10、20、30、40}
- add()関数を使用して、要素をセットに追加できます。
- 2つのセットのデータを組み合わせるには、union()関数を使用できます。
- 両方のセットに存在するデータを識別するために、intersection()関数が使用されます。
- Difference()関数は、セットに固有のデータのみを出力し、共通データを削除します。
- symmetric_difference()関数は、両方のセットに固有のデータを出力します。
ユーザー定義のデータ構造と説明のリスト
1.スタック
スタックは、後入れ先出し(LIFO)または後入れ先出し(FIFO)構造のいずれかである線形構造です。 スタックには、プッシュとポップという2つの主要な操作があります。 プッシュはリストの一番上に要素を追加することを意味し、ポップはスタックの一番下から要素を削除することを意味します。 このプロセスは、図1で詳しく説明されています。
スタックの有用性
- 以前の要素は、後方トレースによって評価できます。
- 再帰的要素のマッチング。
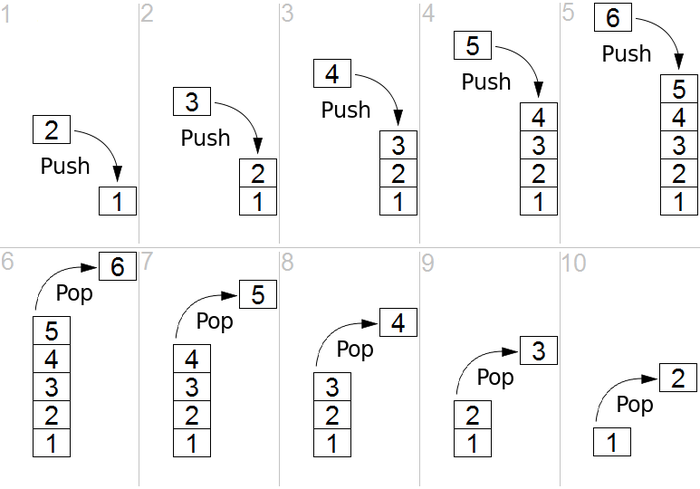
ソース
図1:スタックのグラフィック表現
例

出力
['第一、第二第三']
['最初の'、'2番目の'、'3番目の'、'4番目の'、'5番目の']
5番目
['一番二番三番四番']
2.キュー
スタックと同様に、キューは線形構造であり、一方の端に要素を挿入し、もう一方の端から削除することができます。 2つの操作は、エンキューとデキューとして知られています。 最近追加された要素は、スタックのように最初に削除されます。 キューのグラフィック表現を図2に示します。キューの主な用途の1つは、物が入ったらすぐに処理することです。
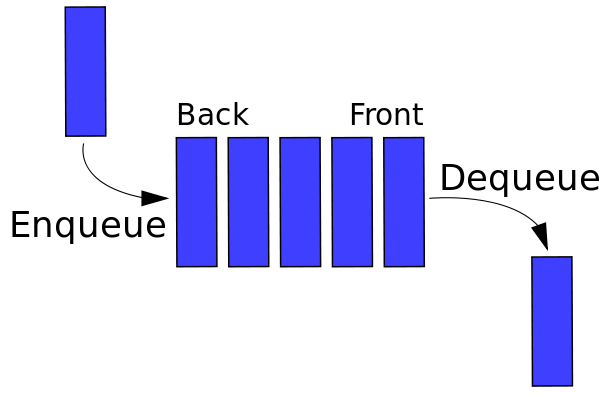
ソース
図2 :キューのグラフィック表現
例

出力
['第一、第二第三']
['最初の'、'2番目の'、'3番目の'、'4番目の'、'5番目の']
最初
5番目
['2番目'、'3番目'、'4番目'、'5番目']
3.ツリー
ツリーは、エッジを介してリンクされたノードで構成される非線形の階層データ構造です。 Pythonツリーのデータ構造には、ルートノード、親ノード、子ノードがあります。 ルートは、データ構造の最上位の要素です。 二分木は、要素が2つ以下の子ノードを持つ構造です。
木の有用性
- データ要素の構造的関係を表示します。
- 各ノードを効率的にトラバースする
- ユーザーは、データの挿入、検索、取得、および削除を行うことができます。
- 柔軟なデータ構造
図3:木のグラフィック表現
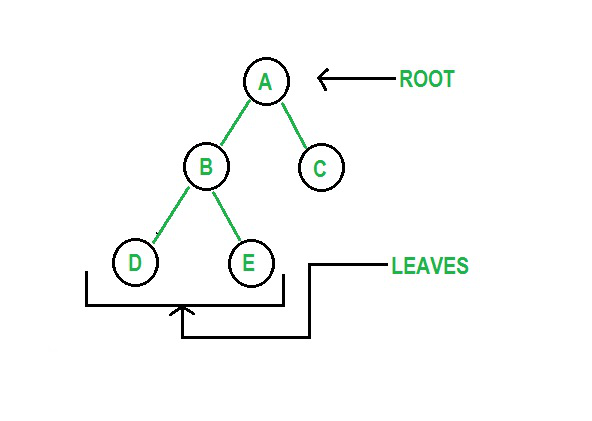
ソース
例:

出力
初め
2番
三番
4.グラフ
Pythonのもう1つの非線形データ構造は、ノードとエッジで構成されるグラフです。 グラフィカルにオブジェクトのセットを表示し、一部のオブジェクトはリンクを介して接続されています。 頂点は相互接続されたオブジェクトですが、リンクはエッジと呼ばれます。 グラフの表現は、Pythonの辞書データ構造を介して行うことができます。ここで、キーは頂点を表し、値はエッジを表します。
グラフで実行できる基本的な操作
- グラフの頂点とエッジを表示します。
- 頂点の追加。
- エッジの追加。
- グラフの作成
グラフの有用性
- グラフの表現は、理解しやすく、理解しやすいものです。
- これは、リンクされた関係、つまりFacebookの友達を表すための優れた構造です。
図4:グラフのグラフ表示
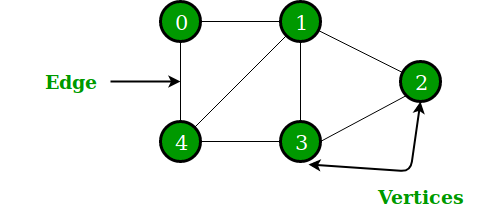
ソース
例

g =グラフ(4)
g.edge(0、2)
g.edge(1、3)
g.edge(3、2)
g.edge(0、3)
g .__ repr __()
出力
頂点0の隣接リスト
頭->3->2
頂点1の隣接リスト
頭->3
頂点2の隣接リスト
頭->3->0
頂点3の隣接リスト
頭->0->2-> 1
5.ハッシュマップ
ハッシュマップは、キーと値のペアの格納に役立つインデックス付きのPythonデータ構造です。 ハッシュマップに格納されたデータは、ハッシュ関数を使用して計算されたキーを介して取得されます。 これらのタイプのデータ構造は、学生データ、顧客の詳細などの保存に役立ちます。Pythonの辞書は、ハッシュマップの例です。
例

出力
0->最初
1->秒
2->3番目
0->最初
1->秒
2->3番目
3->4番目
0->最初
1->秒
2->3番目
使いやすさ
- これは、他のデータ構造よりも情報を取得するための最も柔軟で信頼性の高い方法です。
6.リンクリスト
これは一種の線形データ構造です。 基本的に、これはPythonのリンクを介して結合された一連のデータ要素です。 リンクリスト内の要素は、ポインタを介して接続されます。 このデータ構造の最初のノードはヘッダーと呼ばれ、最後のノードはテールと呼ばれます。 したがって、リンクリストは値を持つノードで構成され、各ノードは別のノードにリンクされたポインタで構成されます。
リンクリストの有用性
- 固定された配列と比較すると、リンクリストは動的な形式のデータ入力です。 ノードのメモリを割り当てるときにメモリが保存されます。 アレイ内では、サイズを事前に定義する必要があり、メモリの浪費につながります。
- リンクリストは、メモリ内のどこにでも保存できます。 リンクリストノードは、更新して別の場所に移動できます。
図6:リンクリストのグラフィック表現
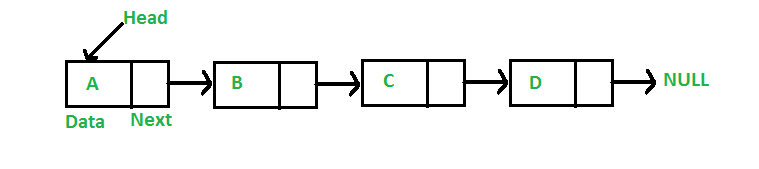
ソース
例

出力:
['第一、第二第三']
['first'、'second'、'third'、'sixth'、'fourth'、'fifth']
['first'、'third'、'sixth'、'fourth'、'fifth']
結論
Pythonのさまざまなタイプのデータ構造が調査されています。 初心者であろうと専門家であろうと、データ構造とアルゴリズムは無視できません。 データに対してあらゆる形式の操作を実行する場合、データ構造の概念が重要な役割を果たします。 データ構造は情報を整理された方法で保存するのに役立ちますが、アルゴリズムはデータ分析全体をガイドするのに役立ちます。 したがって、 Pythonのデータ構造とアルゴリズムはどちらも、コンピューター科学者やユーザーがデータを処理するのに役立ちます。
データ構造について知りたい場合は、IIIT-B&upGradのデータサイエンスのエグゼクティブPGプログラムをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップを提供します。1業界のメンターとの1対1、400時間以上の学習、トップ企業との仕事の支援。
Pythonで高速なデータ構造はどれですか?
辞書では、Pythonがハッシュテーブルを使用してルックアップを実装するため、ルックアップが高速になります。 区別を説明するためにBigOの概念を使用する場合、辞書は一定の時間計算量O(1)を持ちますが、リストは線形の時間計算量O(n)を持ちます。
Pythonでは、辞書は何千ものエントリを含むデータを頻繁に検索する最も簡単な方法です。 辞書はPythonに組み込まれているマッピング型であるため、高度に最適化されています。 ただし、辞書とリストには、一般的な時空のトレードオフがあります。 これは、アプローチに必要な時間を短縮できる一方で、より多くのメモリスペースを使用する必要があることを示しています。
リストでは、必要なものを取得するには、完全なリストを確認する必要があります。 一方、辞書は、すべてのキーを調べなくても、探している値を返します。
Pythonリストと配列のどちらが速いですか?
一般に、Pythonリストは非常に柔軟性があり、完全に異種のランダムなデータを保持するだけでなく、すばやくほぼ一定の時間で追加することができます。 リストをすばやく簡単に縮小および拡張する必要がある場合は、これらの方法を使用できます。 ただし、リスト内の各項目で個別のPythonオブジェクトを作成する必要があることもあり、配列よりもはるかに多くのスペースを占有します。
一方、array.array型は、基本的にC配列の薄いラッパーです。 同種のデータ(つまり、同じタイプのデータ)しか伝送できないため、メモリはsizeof(1つのオブジェクト)*lengthバイトに制限されます。
NumPy配列とリストの違いは何ですか?
Numpyは、Pythonの科学計算コアパッケージです。 大きな多次元配列オブジェクトと、それらを操作するためのユーティリティを使用します。 numpy配列は、非負の整数のタプルによってインデックス付けされた同一タイプの値のグリッドです。
リストはPythonコアライブラリに含まれていました。 リストはPythonの配列に似ていますが、サイズを変更したり、さまざまなタイプの要素を含めることができます。 ここでの本当の違いは何ですか? パフォーマンスがその答えです。 Numpyデータ構造は、サイズ、パフォーマンス、および機能の点でより効率的です。