
Cのデータ構造とその使用方法は何ですか?
公開: 2021-02-26目次
序章
まず、データ構造とは、1つの名前または見出しでまとめられたデータ項目の集合であり、データを効率的に使用できるようにデータを格納および組み立てる特定の方法です。
タイプ
データ構造は一般的であり、ほとんどすべてのソフトウェアシステムで使用されています。 データ構造の最も一般的な例のいくつかは、配列、キュー、スタック、リンクリスト、およびツリーです。
アプリケーション
コンパイラ、オペレーティングシステムの設計、データベースの作成、人工知能アプリケーションなど。
分類
データ構造は、プリミティブデータ構造と非プリミティブデータ構造の2つのカテゴリに分類されます。
1.プリミティブ:プログラミング言語でサポートされている基本的なデータ型です。 この分類の一般的な例は、整数、文字、およびブール値です。
2.非プリミティブ:これらのカテゴリのデータ構造は、プリミティブデータ構造を使用して作成されます。 例としては、リンクスタック、リンクリスト、グラフ、ツリーなどがあります。

配列
配列は、同じデータ型を持つデータ要素の単純なコレクションです。 つまり、整数型の配列は整数値しか格納できません。 データ型floatの配列は、floatデータ型に対応する値を格納できます。
配列に格納された要素は線形にアクセス可能であり、インデックスを使用して参照できる連続したメモリブロックに存在します。
配列の宣言
Cでは、配列は次のように宣言できます。
data_type name [length];
例えば、
intorders [10];
上記のコード行は、整数値を格納できる10個のメモリブロックの配列を作成します。 Cでは、配列のインデックス値は0から始まります。したがって、インデックス値の範囲は0〜9です。その配列の特定の値にアクセスする場合は、次のように入力するだけです。
printf(order [index_number]);
配列を宣言する別の方法は次のとおりです。
data_type array_name [size]={値のリスト};
例えば、
intマーク[5]={9、8、7、9、8};
上記のコマンド行は、各ブロックに固定値を持つ5つのメモリブロックを持つ配列を作成します。 32ビットコンパイラでは、intデータ型が占める32ビットメモリは4バイトです。 したがって、5ブロックのメモリは20バイトのメモリを占有します。
配列を初期化するもう1つの正当な方法は次のとおりです。
intマーク[5]={9、45};
このコマンドは、5つのブロックの配列を作成し、最後の3つのブロックの値は0になります。
別の合法的な方法は次のとおりです。
intマーク[]={9、5、2、1、3,4};
Cコンパイラは、これらのデータを配列に適合させるために必要なブロックは5つだけであることを理解しています。 したがって、サイズ5の名前マークの配列を初期化します。
同様に、2次元配列は次の方法で初期化できます。
intマーク[2][3]= {{9,7,7}、{6,2、1}};
上記のコマンドは、2行3列の2次元配列を作成します。
読む:データ構造プロジェクトのアイデアとトピック
操作
アレイで実行できる操作がいくつかあります。 例えば:
- 配列をトラバースする
- 配列に要素を挿入する
- 配列内の特定の要素を検索する
- 配列から特定の要素を削除する
- 2つのアレイをマージし、
- 配列の並べ替え—昇順または降順。
短所
アレイに割り当てられたメモリは固定されています。 これは実際には問題です。 たとえば、サイズ50の配列を作成し、30ブロックのメモリにのみアクセスしたとします。 残りの20ブロックは、何も使用せずにメモリを占有します。 したがって、この問題に取り組むために、リンクリストがあります。
リンクリスト
リンクリストは、配列がデータをシリアルに格納するのと非常によく似ています。 主な違いは、すべてを一度に保存するわけではないということです。 代わりに、データを保存するか、必要に応じてメモリブロックを使用できるようにします。 リンクリストでは、ブロックは2つの部分に分割されます。 最初の部分には実際のデータが含まれています。
2番目の部分は、リンクリスト内の次のブロックを指すポインターです。 ポインタは、データを保持する次のブロックのアドレスを格納します。 ヘッドポインタと呼ばれるもう1つのポインタがあります。 ヘッドは、リンクリストのメモリの最初のブロックを指します。 以下は、リンクリストの表現です。 これらのブロックは「ノード」とも呼ばれます。

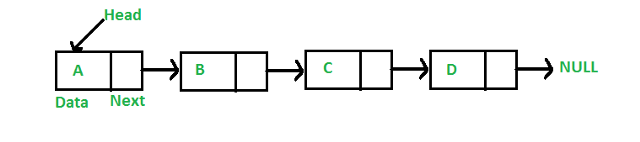
ソース
リンクリストの初期化
リンクリストを初期化するために、構造名ノードを作成します。 構造には2つのものがあります。 1.保持するデータおよび2.次のノードを指すポインター。 ポインタのデータ型は、構造体ノードを指しているため、構造体のデータ型になります。
構造体ノード
{{
intデータ;
構造体ノード*next;
};
リンクリストでは、最後のノードのポインタは何も指さないか、単にnullを指します。
また読む:データ構造のグラフ
リンクリストトラバーサル
リンクリストでは、最後のノードのポインタは何も指さないか、単にnullを指します。 したがって、リンクリスト全体をトラバースするには、最初にヘッドを指すダミーポインタを作成します。 また、リンクリストの長さの間、ポインタはnullを指すか、リンクリストの最後のノードに到達するまで前方に移動し続けます。
ノードの追加
特定のノードの前にノードを追加するアルゴリズムは次のようになります。
- 最初に頭を指す2つのダミーポインタ(ptrとpreptr)を設定します
- ノードを挿入する前に、ptr.dataがデータと等しくなるまでptrを移動します。 preptrはptrの1ノード後ろになります。
- ノードを作成する
- ダミーpreptrが指していたノード、そのノードの次はこの新しいノードを指します
- 新しいノードの次はptrを指します。
特定のデータの後にノードを追加するためのアルゴリズムは、同様の方法で実行されます。
リンクリストの利点
- 配列とは異なり、動的サイズ
- リンクリストでは、配列よりも挿入と削除の方が簡単です。
列
キューは、先入れ先出しまたはFIFOタイプのシステムに従います。 配列の実装では、Queueのユースケースを示すために2つのポインターがあります。
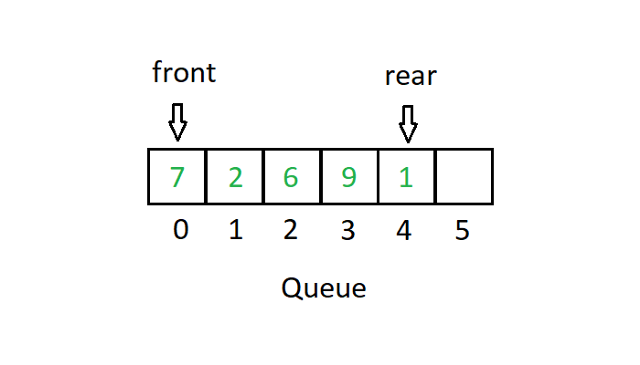
ソース
FIFOは基本的に、最初にスタックに入り、最初に配列を離れる値を意味します。 上記のキュー図では、ポインタのフロントは値7を指しています。最初のブロックを削除(デキュー)すると、フロントは値2をポイントします。同様に、数値(エンキュー)を入力すると、たとえば3位置5。次に、リアポインタが位置5を指します。
オーバーフローとアンダーフローの状態
それでも、キューにデータ値を入力する前に、オーバーフロー条件をチェックする必要があります。 すでにいっぱいになっているキューに要素を挿入しようとすると、オーバーフローが発生します。 Rear = max_size–1の場合、キューはいっぱいになります。
同様に、キューからデータを削除する前に、アンダーフロー状態を確認する必要があります。 すでに空のキューから要素を削除しようとすると、アンダーフローが発生します。つまり、front=nullおよびrear=nullの場合、キューは空です。
スタック
スタックは、スタックの最上位とも呼ばれる、一方の端でのみ要素を挿入および削除するデータ構造です。 したがって、スタック実装は後入れ先出し(LIFO)実装と呼ばれます。 キューとは異なり、スタックの場合、必要なトップポインターは1つだけです。
配列に要素を入力(プッシュ)する場合は、トップポインターが上に移動するか、1ずつ増加します。要素を削除(ポップ)する場合、トップポインターは、1ずつ減少するか、1単位下に移動します。 スタックは、プッシュ、ポップ、およびピープの3つの基本操作をサポートします。 のぞき見操作は、スタックの最上位の要素を表示するだけです。
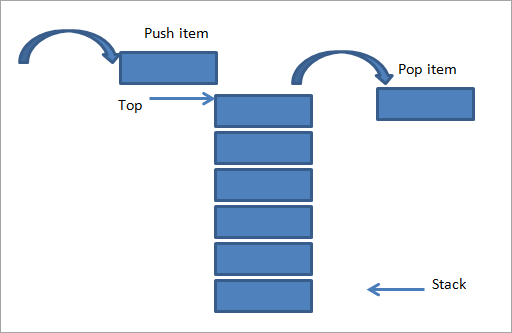
ソース
世界のトップ大学からオンラインでソフトウェアコースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
結論
この記事では、配列、リンクリスト、キュー、スタックの4種類のデータ構造について説明しました。 この記事が気に入って、もっと面白い読み物をお楽しみに。 次回まで。
Javascript、フルスタック開発について詳しく知りたい場合は、upGrad&IIIT-Bのフルスタックソフトウェア開発のエグゼクティブPGプログラムをチェックしてください。これは、働く専門家向けに設計されており、500時間以上の厳格なトレーニング、9以上のプロジェクトを提供します。 、および割り当て、IIIT-B卒業生のステータス、実践的な実践的なキャップストーンプロジェクト、およびトップ企業との雇用支援。
プログラミングのデータ構造とは何ですか?
データ構造は、プログラム内でデータを配置する方法です。 最も重要な2つのデータ構造は、配列とリンクリストです。 配列は最もよく知られているデータ構造であり、最も理解しやすいものです。 配列は基本的に関連アイテムの番号付きリストです。 これらは理解と使用が簡単ですが、大量のデータを処理する場合はあまり効率的ではありません。 リンクリストはより複雑ですが、適切に使用すれば非常に効率的です。 大きなリストの途中でアイテムを追加または削除する必要がある場合、または大きなリストでアイテムを検索する必要がある場合に適しています。
リンクリストと配列の違いは何ですか?
配列では、要素にアクセスするためにインデックスが使用されます。 配列内の要素は順番に編成されているため、インデックスが使用されている場合は要素に簡単にアクセスして変更できます。 配列のサイズも固定されています。 要素は、作成時に割り当てられます。 リンクリストでは、要素にアクセスするためにポインタが使用されます。 リンクリストの要素は、必ずしも順番に格納されるとは限りません。 リンクリストは、作成時にノードを含む可能性があるため、サイズが不明です。 要素にアクセスするためにポインタが使用されるため、メモリの割り当てが簡単になります。
Cのポインタとは何ですか?
ポインタは、変数または関数のアドレスを格納するCのデータ型です。 通常、別のメモリ位置への参照として使用されます。 ポインタは、配列、構造、関数、またはその他のタイプのメモリアドレスを保持できます。 Cはポインターを使用して、関数に値を渡したり、関数から値を受け取ったりします。 ポインタは、メモリ空間を動的に割り当てるために使用されます。