
13初心者のためのエキサイティングなデータサイエンスプロジェクトのアイデアとトピック[2022]
公開: 2021-06-22目次
データサイエンスプロジェクトのアイデアに関する表現
データサイエンスは、この世代の優れたキャリアオプションとして継続的に繁栄しています。 これは、最も有望で起こっている選択肢の1つです。 市場は、データサイエンティストへの需要が高まるにつれて押し上げられています。 最近、需要は今後数倍にさらに増加すると報告されています。 したがって、データサイエンスの初心者の場合、できる最善のことは、リアルタイムのデータサイエンスプロジェクトのアイデアに取り組むことです。
したがって、意欲的なデータサイエンティストである場合は、この分野の効率的な専門家になるためのスキルを練習することを強くお勧めします。 データサイエンスに関する非常に優れた理論的知識を取得した後、専門家のように見えることを本当に楽しみにしているのであれば、今がいくつかの実用的なプロジェクトを行うときです。
キャリアの成長を後押しするために、技術的およびリアルタイムのデータサイエンスプロジェクトのいくつかを実行する必要があります。 データサイエンスプロジェクトで練習すればするほど、健全なデータサイエンティストの専門家になるためのペースを維持できることを保証します。
したがって、ライブデータサイエンスプロジェクトを行うと、知識、技術スキル、および全体的な自信が高まります。 しかし、最も重要なことは、履歴書にいくつかのデータサイエンスプロジェクトを紹介する場合でも、良い仕事を得るのははるかに簡単です。 なんでそうなの? そうすれば、面接官はあなたがデータサイエンスのキャリアに真剣に取り組んでいることを知るでしょう。
ライブデータサイエンスプロジェクトでのリアルタイムの経験により、データサイエンスのトレンドとテクノロジーをしっかりと把握することができます。 だから、リアルタイムのデータサイエンスプロジェクトに手を入れれば、それがあなたのスピーディーなキャリアの成長にどれほど有益であるかがわかるでしょう。 これらすべての議論の結果、データサイエンスプロジェクトに最適なデータサイエンスプロジェクトのアイデアを見つけることは、実際の実装よりもさらに重要であることがわかりました。
このデータサイエンスブログでは、いくつかのデータサイエンスプロジェクトのアイデアの名前をリストアップしました。 そして、あなたの質問に答えるために–「どのような種類のデータサイエンスプロジェクトから始めるのが良いですか?」、私たちはあなたが選択できるいくつかの良いデータサイエンスプロジェクトのアイデアをまとめました。
コーディングの経験は必要ありません。 360°キャリアサポート。 IIIT-BおよびupGradの機械学習とAIのPGディプロマ。
ここにあなたのための50のデータサイエンスプロジェクトのアイデアがあります、そして先のブログで、私たちはこれらのプロジェクトのいくつかを詳細に議論しています。 さあ始めましょう!
- チャットボット
- 気候変動が世界の食料供給に与える影響の分析
- 天気予報
- グーグル広告のキーワード生成
- 交通標識認識
- ワイン品質分析
- 株式市場の予測
- フェイクニュースの検出
- ビデオ分類
- 人間の行動認識
- CTスキャンを使用した医療レポートの生成
- メールの分類
- Uberデータ分析
- 音の分類
- クレジットカード詐欺の検出
- 手話認識
- 花の予測のクラス
- 色検出
- ローン予測
- 道路交通予測
- 収入分類
- 音声感情認識
- 有名人の音声予測
- 店舗売上予測
- パーキンソン病の検出
- 大気汚染の予測
- 年齢と性別の検出
- 製品価格の最適化
- IMDBの予測
- 手書き数字認識
- Quoraの不誠実な質問の分類
- ドライバーの眠気検知
- Webトラフィックの時系列予測
- タイタニック号の生存予測
- 時系列モデリング
- 画像キャプションジェネレータ
- 保険購入予測
- 犯罪分析
- 顧客セグメンテーション
- タクシーのトリップ時間の予測
- 仕事推薦システム
- ボストンの住宅予測
- 感情分析
- 賃貸物件への関心レベル
- Google広告のキーワード生成
- 乳がんの分類
- 従業員のコンピュータアクセスのニーズ
- ツイートの分類
- 映画推薦システム
- 製品価格の提案
最新のデータサイエンスプロジェクトのアイデア
学習者のレベルに応じて、すべてのデータサイエンスプロジェクトのアイデアをセグメント化しました。 したがって、初心者、中級者、上級者向けのデータサイエンスプロジェクトのアイデアに関するいくつかのすばらしいプロジェクト概要のリストが表示されます。
1.初心者レベル| データサイエンスプロジェクトのアイデア
学生向けのデータサイエンスプロジェクトのアイデアのこのリストは、初心者、および一般的にPythonまたはデータサイエンスを始めたばかりの人に適しています。 これらのデータサイエンスプロジェクトのアイデアは、データサイエンス開発者としてのキャリアで成功するために必要なすべての実用性を実現します。
さらに、最終年度のデータサイエンスプロジェクトのアイデアを探している場合は、このリストを参考にしてください。 それで、それ以上の苦労なしに、あなたの基盤を強化し、あなたがはしごを登ることを可能にするいくつかのデータサイエンスプロジェクトのアイデアに直接飛び込みましょう。
1.1世界の食料供給に対する気候変動の影響
頻繁な気候変動と不規則性は、大きな挑戦的な環境問題です。 気候区分のこれらの不規則性は、地球に住む人間の生活に劇的な影響を及ぼしています。 このデータサイエンスプロジェクトは、気候への影響が世界中の世界の食料生産にどのように大きく影響するか、そしてどの程度の定量化が気候変動に影響を与えるかに焦点を当てています。
このプロジェクトの開発の主な目的は、気候変動による主食作物生産の可能性を計算することです。 このプロジェクトを通じて、気温と降水量に関連するすべての影響が変化します。 次に、二酸化炭素が植物の成長にどの程度影響を与えるか、および気候条件で発生する不確実性が考慮されます。 したがって、このプロジェクトは主にデータの視覚化を扱います。 また、さまざまなタイムゾーンでのさまざまな地域の生産量を比較します。
1.2フェイクニュースの検出
ソース
初心者向けのこの驚くべきデータサイエンスプロジェクトのアイデア– Python言語を使用したフェイクニュースの検出で、データサイエンスのキャリアを推進できます。 このプロジェクトでは、デジタルプラットフォームでのジャーナリズムの誤りや誤解を招く行為、または偽のニュースを検出できます。 改ざんは、あらゆる政治的議題を達成するために、ソーシャルメディアプラットフォームやオンラインチャネル、デジタルメディアを介して広がっています。
このデータサイエンスプロジェクトのアイデアを使用すると、Python言語を使用して、ニュースが実際のジャーナリズムであるか誤った情報であるかを正確に検出できる特定のモデルを開発できます。このためには、「TfidfVectorizer」分類子を作成してから「PassiveAggressiveClassifier」を使用する必要があります。 'ニュースを「本物」と「偽物」のいずれかのセグメンテーションに分類します。 7796×4次元の形状のデータセットがあり、これらすべてを「JupyterLab」で実行します。
このデータサイエンスプロジェクトの主なアイデアは、ソーシャルメディアニュースの信憑性を正しく検出できるリアルタイムの機械学習モデルを開発することです。 一般に「用語頻度」として知られる「TF」は、任意の単語が1つのドキュメントに表示される合計回数です。 一方、「IDF」または「逆ドキュメント頻度」は、単語の価値の計算上の尺度であり、さまざまなドキュメントに表示されるその出現の評判の頻度に基づいています。
理論は「一般的な単語」に基づいており、これらの一般的な単語が複数のドキュメントに頻繁に出現する場合、それらは重要性の低い単語と見なされます。 したがって、「TFIDFVectorizer」が行うことは、これらのドキュメントのコレクションを分析し、それに応じて「TF-IDF」マトリックスを作成することです。
これに加えて、「分類結果」が正しい場合、「PassiveAggressive」分類子は「passive」のままになります。 しかし一方で、「分類結果」が正しくない場合、それは積極的に変化します。 したがって、このデータサイエンスプロジェクトのアイデアを使用して、ソーシャルメディアニュースが本物または偽のニュースであることを検出するための機械学習モデルを作成できます。
1.3人間の行動認識
これは、人間の行動認識モデルに関するデータサイエンスプロジェクトです。 特定のアクションを実行している人間について作成された短いビデオを見ていきます。 このモデルは、実行されたアクションに基づいて分類を実行しようとします。 このデータサイエンスプロジェクトでは、複雑なニューラルネットワークを使用する必要があります。 次に、このニューラルネットワークは、これらの短いビデオを含む特定のデータセットでトレーニングされます。 次に、データセットに関連付けられている加速度計データがあります。 加速度計のデータ変換は、最初に「タイムスライス」表現とともに実行されます。 その後、これらのデータセットに基づいてネットワークのトレーニング、検証、およびテストを実行できるように、「 Keras 」ライブラリを使用する必要があります。
1.4森林火災の予測
今日の世界で起こっている憂慮すべき一般的な災害の1つは、山火事です。 これらの災害は生態系に大きな損害を与えます。 このような災害に対処するには、インフラストラクチャと制御および処理に多額の費用が必要です。 「k-meansクラスタリング」を使用してデータサイエンスプロジェクトを構築できます。これにより、森林火災のホットスポットと、その特定のスポットでの火災の重大度を特定できます。
または、応答時間を短縮してリソースをより適切に割り当てるために使用することもできます。 したがって、この種の火災の悲劇が発生する可能性が高い季節や、それらを悪化させるさまざまな気象条件などの気象データを使用すると、これらの結果の精度レベルが向上する可能性があります。
1.5道路車線の検出
初心者向けのもう1つのデータサイエンスプロジェクトのアイデアには、Python言語が組み込まれたライブレーンライン検出システムが含まれます。 このプロジェクトでは、人間のドライバーが道路に描かれた線を介して車線検出のガイダンスを受け取ります。

これだけでなく、ドライバーが車両を操縦する方向をさらに示します。 このデータサイエンスプロジェクトアプリケーションは、自動運転車の開発に不可欠です。 したがって、入力画像または連続ビデオフレームを介してトラックラインを識別する強力な機能を備えたアプリケーションを開発することもできます。
読む:データ分析プロジェクトのトップ4のアイデア:初心者からエキスパートレベル
2.データサイエンスプロジェクトのアイデア|中級レベル
2.1音声感情の認識
ソース
人気のあるデータサイエンスプロジェクトのアイデアの1つは、音声の感情の認識です。 さまざまなライブラリの使用法を学びたい場合は、このプロジェクトが最適です。 私たちのスピーチの感情がどのように現れているかを教えてくれる多くのエディターツールを見たことがあるはずです。 このプログラムモデルは、データサイエンスプロジェクトとして構築できます。
このデータサイエンスプロジェクトでは、「音声感情認識」を実行する「librosa」を使用します。 SERプロセスは、人間の感情を認識できる試行プロセスです。 また、感情的な状態からのスピーチを認識することができます。 トーンとピッチを組み合わせて、声で感情を表現します。
音声感情認識モデルは絶対に可能です。 ただし、人間の感情は非常に主観的であるため、実行するのは難しいプロジェクトになる可能性があります。 人間の音声の注釈も非常に困難です。 したがって、ここではmfcc、mel、およびchroma機能を使用します。 これにより、感情認識プロセスに「RAVDESS」と呼ばれるデータセットも使用します。 このデータサイエンスプロジェクトでは、このモデルの「MLPClassifier」を開発する方法も学習します。
2.2データサイエンスによる性別と年齢の検出

ソース
したがって、データサイエンスに関する印象的なプロジェクトのアイデアの1つは、「OpenCVによる性別と年齢の検出」です。 この種のリアルタイムプロジェクトを使用すると、データサイエンスの面接で採用担当者の注意を簡単につかむことができます。
プロジェクトについて言えば、「性別と年齢の検出」は、コンピューターのビジョンに基づく機械学習プロジェクトです。 このデータサイエンスプロジェクトを通じて、CNNの実用的なアプリケーション、つまり畳み込みニューラルネットワークを学ぶことができます。 将来的には、「Adience」データセットに「TalHassner」と「GilLevi」によってトレーニングされたモデルも使用します。
これに加えて、– .pb、.prototxt、.pbtxt、.caffemodelファイルなどのファイルも使用します。 これらの用語について聞いたことがありますか? これらのファイルについて読みますか? モデルも理解しますか? しかし、それらを実装する方法を知っていますか? さて、あなたがそれにデータサイエンスプロジェクトを開発することを選ぶならば、あなたはそれを学ぶことができます。
画像を介した単一の顔検出の分析を通じて、あらゆる人間の年齢と性別を検出できるモデルを作成するため、これは非常に実用的なプロジェクトです。 したがって、この性別分類では、男性または女性を分類できます。 また、年齢は0-2 / 4-6 / 8- 2 / 15-20 / 25-32 / 38-43 / 48-53/60-100の範囲に分類できます。
しかし、化粧、明るい薄暗い照明、または異常な表情などのさまざまな要因により、単一のソースからの性別と年齢の認識が困難になる可能性があります。 したがって、このデータサイエンスプロジェクトでは、回帰モデルの代わりに分類モデルを使用します。 これらの種類のプロジェクトで技術スキルを向上させるために、多くの実践的および技術的な学習を取得することができます。 ですから、挑戦してそれに向けて一生懸命働き、印象的なデータサイエンスの履歴書を作成してください。
2.3Pythonでの居眠り運転検知
中級レベル向けの優れたデータサイエンスプロジェクトのアイデアは、「Keras&OpenCV眠気検知システム」です。 一晩運転するのは大変なだけでなく、危険な仕事でもあります。 運転中に運転手が寝てしまったために事故が発生するケースが多いと聞いています。
したがって、このプロジェクトは、そのような場合に発生する多数の交通事故を防ぐのに役立ちます。 このプロジェクトの主な目的は、運転中にドライバーが眠気を催して眠りにつく可能性があることを認識することです。 このプロジェクトではPython言語を使用しており、眠いドライバーの行動をタイムリーに検出し、ビープ音の高いアラームでアラートアラームを鳴らすことができるモデルを構築できます。
このプロジェクトでは、「深層学習モデル」を実装できます。これを使用すると、人間の目が開いているか閉じているかを画像間で分類できます。 これだけでなく、このモデルでは、スコアを計算するための別の数式行があります。
このスコアは、目を閉じたままの時間に基づいています。 スコアは運転セッションを通して維持されます。 そのスコアが増加し、指定されたしきい値を超えると、このモデルはワークフローの自動化をスローし、それによってアラームが激しく鳴り始めます。
したがって、これらの種類のデータサイエンスプロジェクトの実装を使用すると、データサイエンスプロジェクトのすべての基本を学ぶことができます。 'Keras'と'OpenCV'を使用して実装します。 では、なぜこれらが使用されるのですか? さて、あなたは顔と目の動きを検出するために「OpenCV」を使用しています。 一方、「Keras」を使用すると、ディープニューラルネットワークの手法を使用しながら、目の状態を開いているか閉じているかを分類できます。
データサイエンスの高度な認定、250以上の採用パートナー、300時間以上の学習、0%EMI
2.4チャットボット

ソース
チャットボットは最近ますます人気が高まっています。 したがって、データサイエンスプロジェクトの場合、ほとんどすべての組織でオンデマンドの要件が高くなります。 それは今日のビジネスの不可欠なセグメントです。 最近、チャットボットはビジネスにおいて非常に重要な役割を果たしています。 彼らはビジネスラインが彼らの人的資源に莫大な時間を節約するのを助けています。 改善されたパーソナライズされたビジネスサービスを同時に提供するために使用されます。
顧客にサービスを提供している多くの企業があります。 大規模な顧客サービスを提供するためには、多くの人材、十分な時間、そして各顧客を時間通りに処理するための多くの努力が必要です。 一方、これらのチャットボットは、顧客からよく寄せられる一連の質問に答えるだけで、顧客との対話サービスを自動化できます。
現在利用可能なチャットボットには、ドメイン固有のチャットボットとオープンドメインのチャットボットの2種類があります。 ドメイン固有のチャットボットは、特定の問題解決に最もよく使用されます。 これらは非常に戦略的かつスマートな方法でカスタマイズされているため、ドメイン仕様に関連して戦略的かつ効果的に機能します。 2番目の「オープンドメイン」チャットボットは、名前のとおり、あらゆる種類の質問に答えるために開発されているため、継続的すぎる多くのトレーニング資料を必要とします。
技術的に言えば、チャットボットは「ディープラーニング」技術を使用してトレーニングされます。 彼らは、語彙リスト、一般的な文からなるリスト、それらの背後にある意図、そして適切な応答を含むデータセットを必要としています。 これは、トレンドのデータサイエンスプロジェクトのアイデアの1つです。
「リカレントニューラルネットワーク」(RNN)は、チャットボットをトレーニングするための一般的な方法です。 これらのボットには、インテントとともに入力文に従って状態を更新できるエンコーダーが含まれています。 次に、指定された状態をチャットボットに渡します。
その後、チャットボットはデコーダーを使用して、入力された単語に応じて、また意図に加えて、適切な後続の応答を検索します。 このデータサイエンスプロジェクトでは、プロジェクト全体がPythonで作成されているため、Python言語の実装を簡単に学ぶことができます。 Pythonの技術スキルをある程度向上させることができます。
学ぶ: Pythonでチャットボットを作成する方法ステップバイステップ
2.5手書き数字および文字認識プロジェクト
ソース
CNNの助けを借りた手書きの数字と文字の認識に関するこのデータサイエンスプロジェクトのアイデアを使用すると、ディープラーニングの概念を実際に学ぶことができます。 したがって、新進のデータサイエンティストまたは機械学習の愛好家であれば、これはあなたにとって完璧なデータサイエンスプロジェクトのアイデアです。 このプロジェクト開発では、手書き数字の「MNISTデータセット」を使用します。 これは、プロジェクト構築のプロセスに関係する驚くべき方法を学ぶため、データサイエンスを実際に体験するのに最適なプロジェクトです。
説明したように、このプロジェクトは「畳み込みニューラルネットワーク」を介して実装されます。 この後、リアルタイムの予測のために、キャンバスに数字を描画するためのクリエイティブなグラフィカルベースのユーザーインターフェイスを構築し、その後、数字の予測に使用されるモデルを構築します。
このプロジェクトの焦点は、コンピューターの能力を開発し、コンピューターシステムを強化して、人間が手書き形式の文字を認識できるようにすることです。 次に、それをさらに評価して、妥当な精度で理解します。 このプロジェクトの実装では、「Keras」ライブラリと「Tkinter」ライブラリの実際の実装を学ぶことができます。
これらは、作業できる中間データサイエンスプロジェクトのアイデアです。 あなたがまだあなたの知識をテストして、いくつかの難しいプロジェクトに取り組むのが好きなら
3.アドバンスレベルのデータサイエンスプロジェクトのアイデア
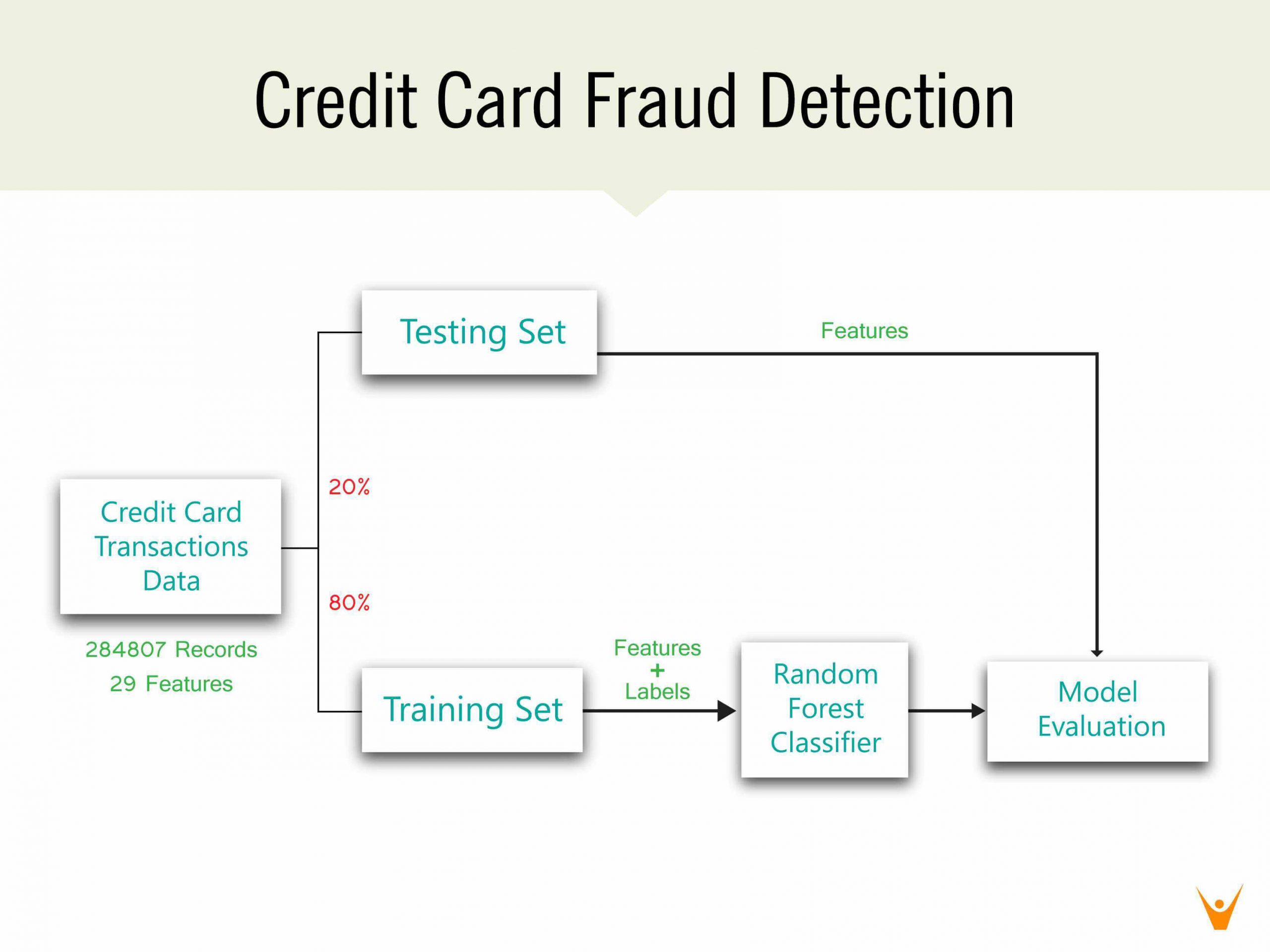
3.1クレジットカード詐欺検出プロジェクト
ソース
簡単なプロジェクトを実装した後、いくつかの高度なデータサイエンスプロジェクトのアイデアに移動して、より多くの概念を学ぶことができます。 そのようなアイデアの1つは、クレジットカード詐欺の検出です。 このプロジェクトでは、ディシジョンツリー、人工ニューラルネットワーク、ロジスティック回帰、勾配ブースティング分類器などのさまざまなアルゴリズムでRを使用する方法を学習します。
また、「カード取引」データセットを使用して、クレジットカード取引を不正行為または本物の取引として分類する方法を学ぶこともできます。 また、すべての異なるタイプのモデルを、それらすべてのプロットパフォーマンス曲線とともに適合させる方法も学習します。 これは、見つけることができる最高のデータサイエンスプロジェクトのアイデアの1つです。
3.2顧客セグメンテーション
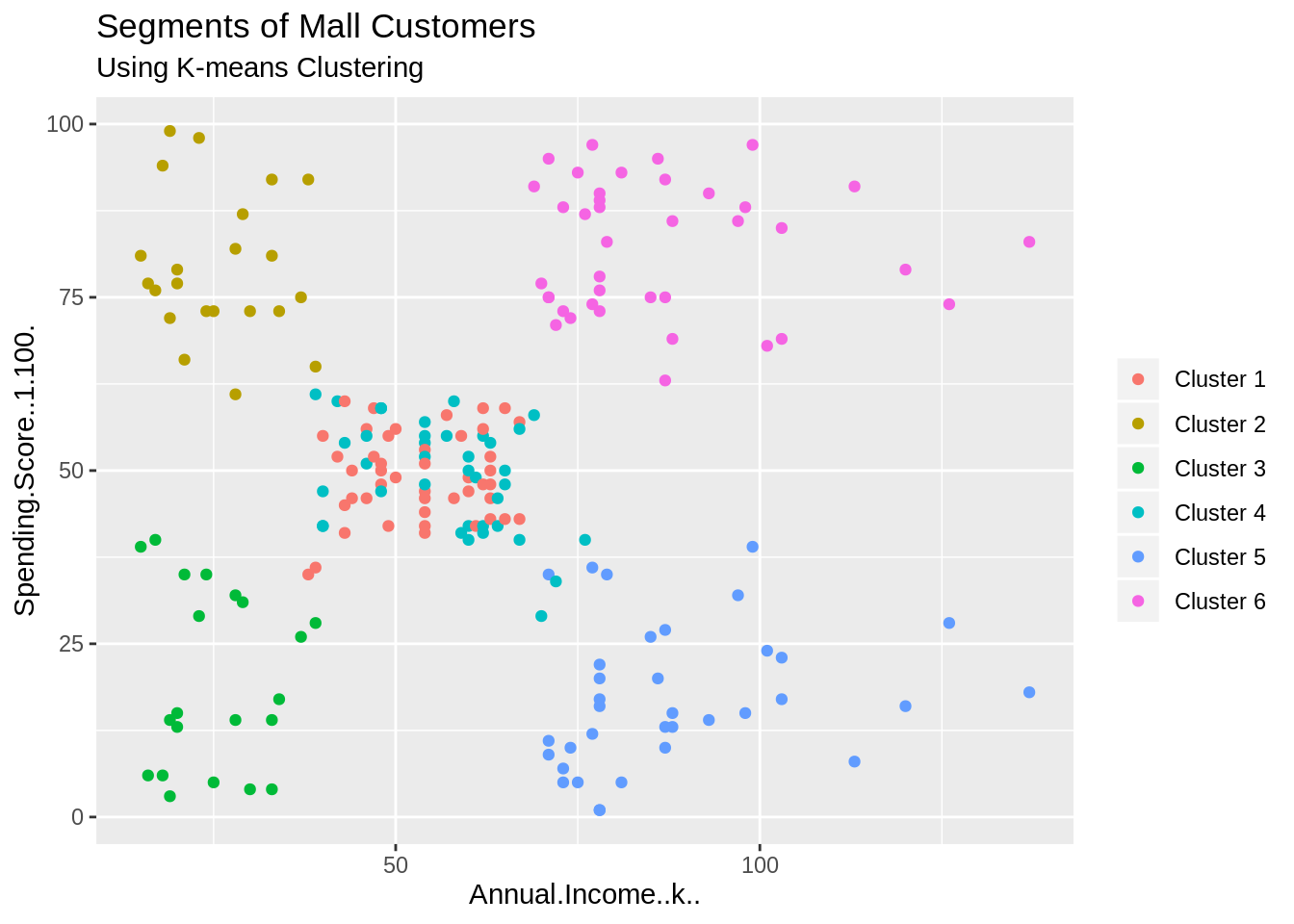
ソース
これは、データサイエンスの分野で最も人気のあるデータサイエンスプロジェクトの1つです。 デジタルマーケティングは、今日のマーケティング目的でのオンラインマーケティング活動を通じて、企業のオーディエンスをターゲットにする高度な方法です。 したがって、マーケティングキャンペーンを実行する前に、さまざまな顧客セグメンテーションが最初に実行されます。
顧客セグメンテーションは、実際に教師なし学習の非常に人気のあるアプリケーションの1つです。 これにより、クラスタリング手法を使用して、企業は潜在的なユーザーベースをターゲットにするために顧客のさまざまなセグメントを簡単に識別できるようになりました。 顧客ごとに分けられ、性別、興味のある分野、年齢、習慣などの共通の特徴に応じてグループが形成されます。
これらの詳細に基づいて、各顧客グループを効果的に売り込むことができます。 このプロジェクトでは「K-meansクラスタリング」を使用しており、性別や年齢などの分布を視覚化する方法を学習します。 顧客の年収と平均スコア値も分析できます。
3.3交通標識認識

ソース
このプロジェクトは、CNN技術を使用して自動運転車の技術で高精度を達成するためのモデルを開発することを目的としています。 交通標識と交通規則はすべてのドライバーにとって最も重要であり、事故を避けるためにそれに従う必要があります。 これらのルールに従うには、ユーザーは信号機がどのように見えるかを理解する必要があります。
運転免許を取得するには、個人がすべての運転信号を学習する必要があるのが一般的なルールです。 しかし、自動運転車の場合、CNNを使用した「交通標識認識」などのプログラムが開発されており、画像の入力によってさまざまな種類の信号を正確に識別できるモデルのプログラミング方法を学ぶことができます。
「ドイツの交通標識認識ベンチマーク」と呼ばれるデータセットがあります。 これは一般にGTSRBとして知られており、ディープニューラルネットワークの開発で、どのクラスタイプに属するすべての交通標識のクラスを認識するために使用されます。 また、アプリケーションの相互作用のためのGUIを構築するための実践的な知識も学びます。
詳細:初心者向けの10のエキサイティングなPythonGUIプロジェクトとトピック
結論
この記事では、データサイエンスプロジェクトのトップアイデアについて説明しました。 私たちはあなたが簡単に解決できるいくつかの初心者プロジェクトから始めました。 これらの単純なデータサイエンスプロジェクトが終了したら、戻ってさらにいくつかの概念を学び、中間プロジェクトを試すことをお勧めします。
自信がついたら、高度なプロジェクトに取り組むことができます。 データサイエンスのスキルを向上させたい場合は、これらのデータサイエンスプロジェクトのアイデアを手に入れる必要があります。 次に、データサイエンスプロジェクトのアイデアガイドを通じて収集したすべての知識をテストして、独自のデータサイエンスプロジェクトを構築してください。
このブログで紹介したプロジェクトのアイデアを使用して、データサイエンスのすべてのスキルを大幅に向上させることを願っています。 ただし、データサイエンスの分野に不慣れで、データサイエンスを学び、技術の進歩のために同様のモデルを構築したい場合は、 upGrad&IIIT-BのPGディプロマプログラムのオンラインコースをチェックして、学習とスキルアップを行うことをお勧めします。経験豊富で専門的な専門家がいるデータサイエンスの世界で。
適切な知識、ガイダンス、ツールのセットがあれば、あらゆるデータサイエンスプロジェクトを学ぶことができます。 学習者にとって難しいレベルはありません。 そのため、これらのライブプロジェクトはすべて、スキルを向上させ、習熟を迅速に進めるための完璧な方法です。 upGradでは、3つのデータサイエンスオンライン認定を提供しています。
1.データサイエンスのエグゼクティブPGプログラム(12か月)
IIITバンガロアから
2.データサイエンスの理学修士(18か月)
リバプールジョンムーア大学から
3.データサイエンスの高度な証明書プログラム(7か月)
IIITバンガロアから
upGradによるこれらのデータサイエンスオンライン認定をお試しください。データサイエンスのキャリアパスに役立つと確信しています。 したがって、遅らせないでください! 今すぐ練習を始めましょう!
データサイエンスプロジェクトを開始する前に、次の点に注意する必要があります。 次のコンポーネントは、データサイエンスプロジェクトの最も一般的なアーキテクチャを強調しています。 以下は、データサイエンス愛好家が習得する必要のある基本的なスキルとツールです。優れたデータサイエンスプロジェクトを作成するにはどうすればよいですか?
使い慣れたプログラミング言語を選択してください。 ただし、選択する言語は、Python、R、Scalaなどの需要の高い言語の1つである必要があります。
信頼できるソースからのデータセットを使用します。 Kaggleデータセットを使用できます。 さらに、使用しているデータセットにエラーが含まれていないことを確認してください。
モデルをトレーニングする前に、データセット内のエラーまたは外れ値を見つけて修正します。 視覚化ツールを使用して、データセット内のエラーを見つけることができます。 データサイエンスプロジェクトに必要な主要なコンポーネントについて説明してください。
問題の説明:これは、プロジェクト全体の基礎となる基本的なコンポーネントです。 モデルが解決しようとしている問題を定義し、プロジェクトが従うアプローチについて説明します。
データセット:これはプロジェクトにとって非常に重要なコンポーネントであり、慎重に選択する必要があります。 プロジェクトには、信頼できるソースからの十分な大きさのデータセットのみを使用する必要があります。
アルゴリズム:これには、データの分析と結果の予測に使用しているアルゴリズムが含まれます。 一般的なアルゴリズム手法には、回帰アルゴリズム、回帰ツリー、ナイーブベイズアルゴリズム、およびベクトル量子化が含まれます。
モデルのトレーニング:これには、さまざまな入力に対してモデルをトレーニングし、出力を予測することが含まれます。 このコンポーネントは、プロジェクトの精度を決定します。 適切なトレーニング手法を使用すると、より良い結果を生み出すことができます。 データサイエンティストになるために必要なスキルは何ですか?
1.確率を含む統計的スキル
2.データを分析およびテストするための分析スキル。
3. Python、R、Scala、JAVAなどのプログラミング言語。
4. Power BI、Tableauなどのデータ視覚化ツール
5.回帰、決定木、ベイズアルゴリズムを含むアルゴリズム
6.微積分と代数。
7.コミュニケーションとプレゼンテーションのスキル
8.SQLなどのデータベース
9.リソースを管理するためのクラウドコンピューティング
これらの技術的なスキルとは別に、プロのデータサイエンティストは、会社に価値を提供し、対人関係を改善するためのソフトスキルも必要です。 これらのスキルには、批判的で好奇心旺盛な思考、ビジネス指向、スマートコミュニケーションスキル、問題解決、チーム管理、および創造性が含まれます。