
Pythonのデータフレーム:Pythonの詳細なチュートリアル2022
公開: 2021-01-09Pythonプログラミング言語で作業する開発者またはコーダーの場合は、最もすばらしいデータ管理ライブラリの1つであるPandasに精通している必要があります。Pandasは、Pythonプログラミングのトップライブラリの1つです。 何年にもわたって、PandasはPythonを使用したデータ分析と管理のための標準ツールになりました。 他の重要なPythonツールについて読んでください。
Pandasは間違いなくデータサイエンスのための最も用途の広いPythonパッケージであり、当然のことながらそうです。 強力で表現力豊かで柔軟なデータ構造を提供し、データの操作と分析を容易にします。Pythonのデータフレームはこれらの構造の1つです。
これはまさにこの投稿での私たちの議論のトピックです-パンダの基本的なデータ形式、つまりパンダデータフレームを紹介します。
目次
データフレームとは何ですか?
Pandasライブラリのドキュメントによると、データフレームは「2次元、サイズ変更可能、潜在的に異種の表形式のデータ構造であり、軸(行と列)にラベルが付けられています」。 簡単に言うと、データフレームは、データが表形式で、つまり行と列に配置されているデータ構造です。
データフレームには通常、次の特性があります。
- 複数の行と列がある場合があります。
- 各行はデータのサンプルを表しますが、各列はサンプル(行)を説明する異なる変数で構成されます。
- すべての列のデータは通常、同じタイプのデータ(たとえば、数値、文字列、日付など)です。
- Excelデータセットとは異なり、値の欠落を回避するため、行または列の間にギャップや空の値はありません。
Pandasデータフレームでは、データフレームのインデックス名と列名を指定することもできます。 インデックスは行の違いを示しますが、列名は列の違いを示します。
Pythonでデータフレームを作成する方法(パンダを使用)
データフレームの作成は、Pythonでデータを変更するための最初のステップです。 次のような入力を使用して、Pandasデータフレームを作成できます。
- ディクト
- リスト
- シリーズ
- ゴツゴツした「ndarray」
- 別のデータフレーム
- CSなどの外部ファイル
- 空のデータフレームの作成
基本的なデータフレーム、別名空のデータフレームを作成するのは非常に簡単です。 次に例を示します。
入力–

出力–

- リストからのデータフレームの作成
単一のリストまたは複数のリストを使用して、データフレームを作成できます。
入力–

出力–

- 「ndarrays」またはリストのディクトからデータフレームを作成する
ndarrayのdictからデータフレームを作成するには、すべてのndarrayが同じ長さである必要があります。 また、インデックスが付けられている場合、インデックスの長さは配列の長さと同じである必要があります。 ただし、インデックスが作成されていない場合、インデックスはデフォルトでrange(n)になります。ここで、「n」は配列の長さを示します。
入力–

出力–

ここで、値0、1、2、3は、関数range(n)を使用して各行に割り当てられたデフォルトのインデックスです。
基本的なデータフレーム操作とは何ですか?
Pythonでデータフレームを作成する3つの方法を見てきました。次に、データフレーム内のさまざまな操作について学習します。
- Pandasデータフレームからインデックスまたは列を選択する
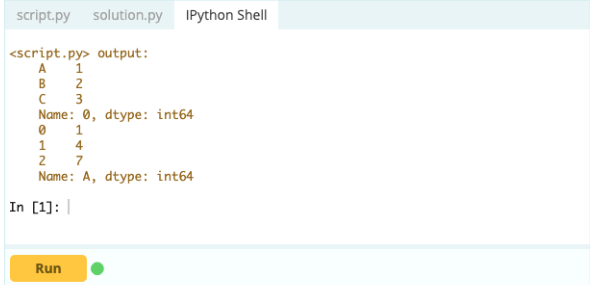
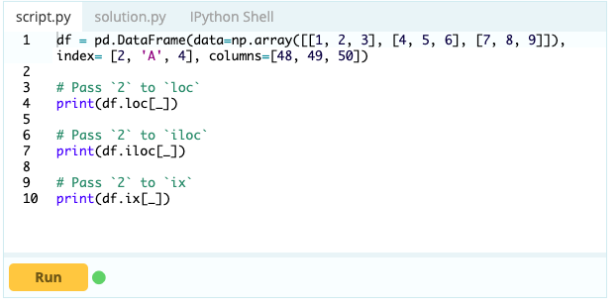
DataFrame内のコンポーネントの追加、削除、および名前変更を開始する前に、インデックスまたは列を選択する方法を知っておくことが重要です。 これがデータフレームであるとします。

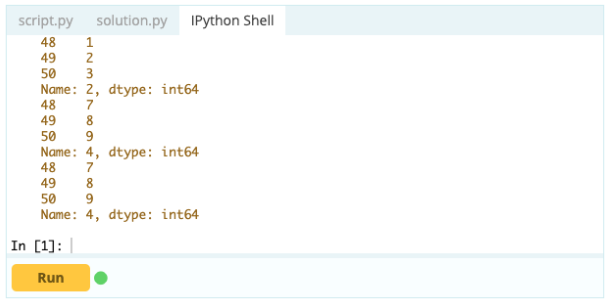
列'A'のインデックス0の下の値にアクセスしたい–値は1です。この値にアクセスする方法はたくさんありますが、最も重要な方法の2つは–.loc[]と.iloc[]です。
入力–
出力–
したがって、ご覧のとおり、ラベルで呼び出すか、インデックスまたは列での位置を宣言することで、値にアクセスできます。 これがデータフレームから値を選択している間に、同じものから行と列をどのように選択できますか?
こうやって:
入力–
出力-
- インデックス、行、または列をPandasDataFrameに追加する方法
値にアクセスしてデータフレームから列を選択する方法を学習したら、Pandasデータフレームにインデックス、行、または列を追加する方法を学習できます。
インデックスの追加:
データフレームの作成中に、「インデックス」引数に入力を追加することを選択できます。 これにより、必要なインデックスに簡単にアクセスできるようになります。 インデックスを指定しない場合、デフォルトでは、0から始まり、DataFrameの最後の行まで続く数値のインデックスが追加されます。 ただし、デフォルトでインデックスが指定された後でも、データフレームでset_index()関数を呼び出すことにより、列を使用してインデックスに変換できます。

行の追加:
追加機能を使用して、DataFrameに行を追加できます。
入力–

出力–

次のように、.locを使用してDataFrameに行を挿入することもできます。
入力–
出力–
列を追加する
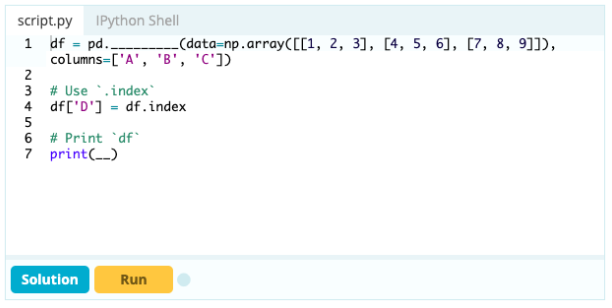
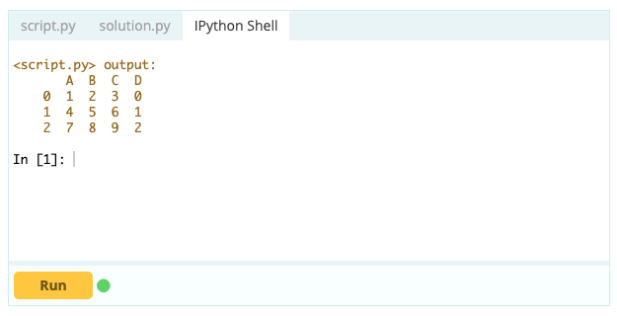
インデックスをデータフレームの一部にしたい場合は、データフレームから列を取得するか、まだ作成されていない列を参照して、次のように.indexプロパティに割り当てることができます。
入力–
出力–
データフレームに列を追加する場合は、データフレームにインデックスを追加する場合と同じアプローチを使用することもできます。つまり、.loc[]または.iloc[]関数を使用できます。 例えば:
入力–
出力
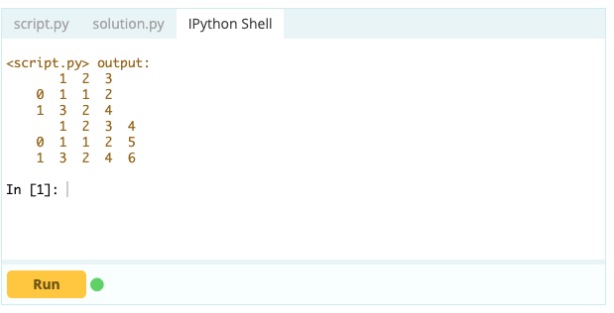
.loc []を使用すると、既存のDataFrameにシリーズを追加できます。 Seriesオブジェクトはデータフレームの列に非常に似ているため、既存のデータフレームにシリーズを追加するのは非常に簡単です。
- データフレームのインデックスをリセットする方法は?
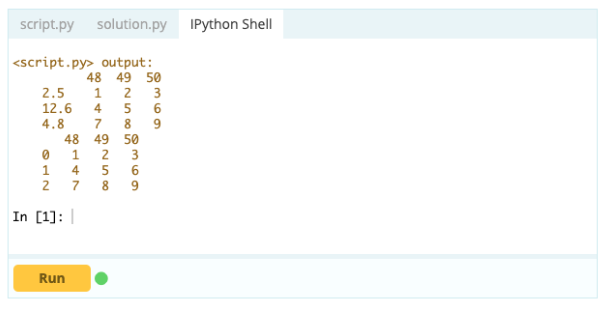
データフレームが希望どおりに形作られていない場合は、データフレームのインデックスをリセットできます。 これを行うには、.reset_index()関数を使用できます。
入力–
出力–
- Pandas DataFrameのインデックス、行、または列を削除する方法
インデックスの削除
- データフレームのインデックスをリセットします。
- del df.index.name関数を使用して、インデックス名(存在する場合)を削除します。
- 行とともにインデックスを削除します。
- インデックスをリセットし、データフレームに追加されたインデックス列の重複を削除し、新しい列(重複インデックスがない)をインデックスとして再度復元することにより、重複するすべてのインデックス値を削除します。
列を削除する
データフレームから列を削除するには、drop()関数を使用できます。
入力–
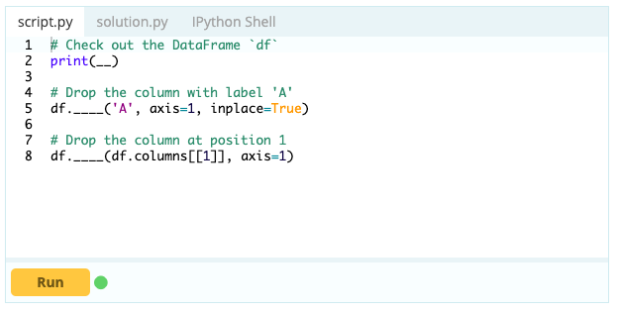
出力–
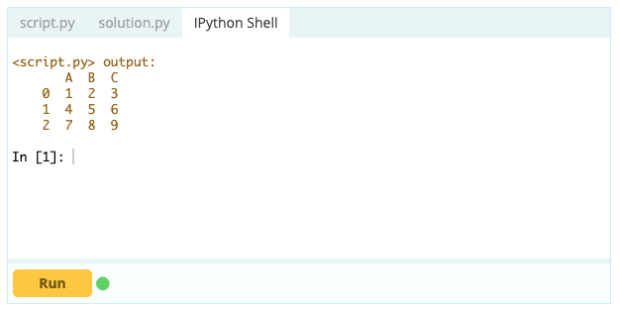
行を削除する
データフレームから行を削除するには、indexプロパティを使用してdrop()関数を使用し、データフレームから削除する行のインデックスを指定できます。
入力–
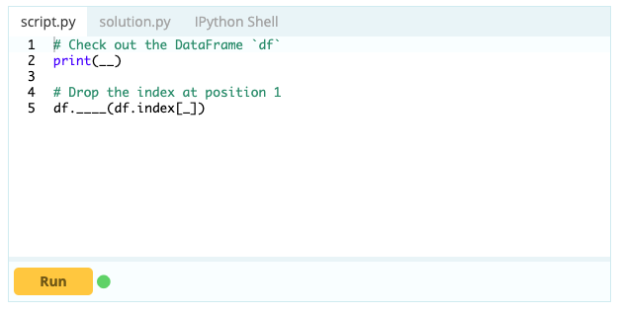
出力–
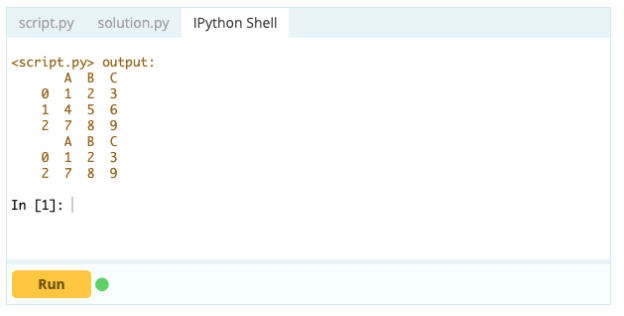
ただし、重複する行を削除するには、df.drop_duplicates()関数を使用できます。
入力–
出力–
出典:Tutorialspoint Datacamp
結論
したがって、Pandasを使用したPythonでのデータフレームの基本的なチュートリアルがあります。
Python、データサイエンスの学習に興味がある場合は、IIIT-BとupGradのデータサイエンスのPGディプロマをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップを提供します。業界のメンターとの1対1、400時間以上の学習、トップ企業との就職支援。
PandasがPythonでデータフレームを作成するのに最も好ましいライブラリの1つであるのはなぜですか?
Pandasライブラリは、データフレームの作成を効率化するさまざまな機能を提供するため、データフレームの作成に最適であると考えられています。 これらの機能の一部は次のとおりです。パンダは、効率的なデータ表現を可能にするだけでなく、それを操作することもできるさまざまなデータフレームを提供します。 データにラベルを付けて整理するインテリジェントな方法を提供する、効率的な配置およびインデックス作成機能を提供します。 Pandasの一部の機能により、コードがクリーンになり、読みやすさが向上するため、コードがより効率的になります。 また、複数のファイル形式を読み取ることもできます。 JSON、CSV、HDF5、およびExcelは、Pandasでサポートされているファイル形式の一部です。 複数のデータセットをマージすることは、多くのプログラマーにとって大きな課題でした。 パンダもこれを克服し、複数のデータセットを非常に効率的にマージします。
Pandasライブラリを補完する他のライブラリとツールは何ですか?
Pandasは、データフレームを作成するための中央ライブラリとして機能するだけでなく、Pythonの他のライブラリやツールと連携してより効率的に機能します。 PandasはNumPyPythonパッケージに基づいて構築されており、Pandasライブラリ構造のほとんどがNumPyパッケージから複製されていることを示しています。 Pandasライブラリのデータの統計分析は、SciPyによって操作され、Matplotlibに関数をプロットし、Scikit-learnの機械学習アルゴリズムを使用します。 Jupyter Notebookは、IDEとして機能し、パンダに適した環境を提供するWebベースのインタラクティブ環境です。
基本的なデータフレーム操作は何ですか?
追加や削除などの操作を開始する前に、インデックスまたは列を選択することが重要です。 値にアクセスしてデータフレームから列を選択する方法を学習したら、Pandasデータフレームにインデックス、行、または列を追加する方法を学習できます。 データフレームのインデックスが希望どおりにならない場合は、リセットできます。 インデックスをリセットするには、「reset_index()」関数を使用できます。