
CNNとRNN:CNNとRNNの違い
公開: 2021-02-25目次
序章
人工知能の分野では、人間の脳に触発されたニューラルネットワークがさまざまなデータから複雑な情報を抽出して処理するために広く使用されており、そのようなアプリケーションで畳み込みニューラルネットワーク(CNN)とリカレントニューラルネットワーク(RNN)の両方が使用されています有用であることが証明されています。
この記事では、畳み込みニューラルネットワークとリカレントニューラルネットワークの両方の背後にある概念を理解し、それらのアプリケーションを確認して、両方の一般的なタイプのニューラルネットワークの違いを区別します。
世界のトップ大学から機械学習トレーニングを学びましょう。 マスター、エグゼクティブPGP、または高度な証明書プログラムを取得して、キャリアを迅速に追跡します。
ニューラルネットワークとディープラーニング
畳み込みニューラルネットワークとリカレントニューラルネットワークの両方の概念に入る前に、ニューラルネットワークの背後にある概念とそれがディープラーニングとどのように関連しているかを理解しましょう。
最近では、ディープラーニングはかつて多くの分野で広く使用されていた概念であるため、最近話題になっています。 しかし、それがそれほど広く話されている理由は何ですか? この質問に答えるために、ニューラルネットワークの概念について学びます。
つまり、ニューラルネットワークはディープラーニングのバックボーンです。 それらは、ニューロンと呼ばれる高度に相互接続された要素で構成される一連の層であり、データに対して一連の変換を実行し、機能という用語で参照するデータの独自の理解を生成します。

ニューラルネットワークとは何ですか?
私たちがやり遂げる必要のある最初の概念は、ニューラルネットワークの概念です。 人間の脳は、これまで研究されてきた複雑な構造の1つであることを私たちは知っています。 その複雑さのために、その内部の働きを解明することは非常に困難でしたが、現在、その秘密を明らかにするためにいくつかの種類の研究が行われています。 この人間の脳は、ニューラルネットワークモデルの背後にあるインスピレーションとして機能します。
定義上、ニューラルネットワークはディープラーニングの機能ユニットであり、これらのニューラルネットワークを利用して脳の活動を模倣し、複雑な問題を解決します。 入力データがニューラルネットワークに送られると、パーセプトロンの層を介して処理され、最終的に出力が得られます。
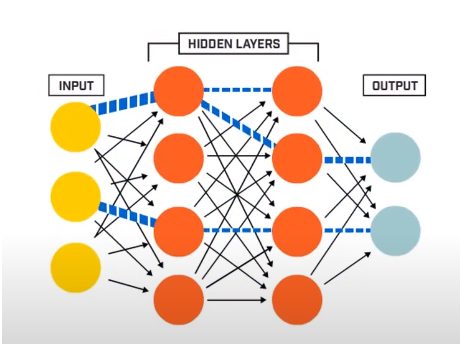
ニューラルネットワークは基本的に3つの層で構成されています–
- 入力レイヤー
- 隠しレイヤー
- 出力層
入力層は、ニューラルネットワークシステムに供給される入力データを読み取り、人工ニューロンの後続の層によるさらなる前処理を行います。 入力レイヤーと出力レイヤーの間に存在するすべてのレイヤーは、非表示レイヤーと呼ばれます。
それらに存在するニューロンが重み付けされた入力とバイアスを利用し、活性化関数を利用して出力を生成するのは、これらの隠れ層にあります。 出力層は、特定のプログラムの出力を提供するニューロンの最後の層です。
ソース
ニューラルネットワークはどのように機能しますか?
ニューラルネットワークの基本構造がわかったので、次に進んで、ニューラルネットワークがどのように機能するかを理解します。 その働きを理解するには、まず、パーセプトロンとして知られるニューラルネットワークの基本構造の1つについて学ぶ必要があります。
パーセプトロンは、最も基本的な形式のニューラルネットワークの一種です。 これは、隠れ層が1つしかない単純なフィードフォワード人工ニューラルネットワークです。 パーセプトロンネットワークでは、各ニューロンは順方向で他のすべてのニューロンに接続されています。
これらのニューロン間の接続には重みが付けられているため、2つのニューロン間で転送される情報は、これらの重みによって強化または減衰されます。 ニューラルネットワークのトレーニングプロセスでは、正しい値を取得するために調整されるのはこれらの重みです。
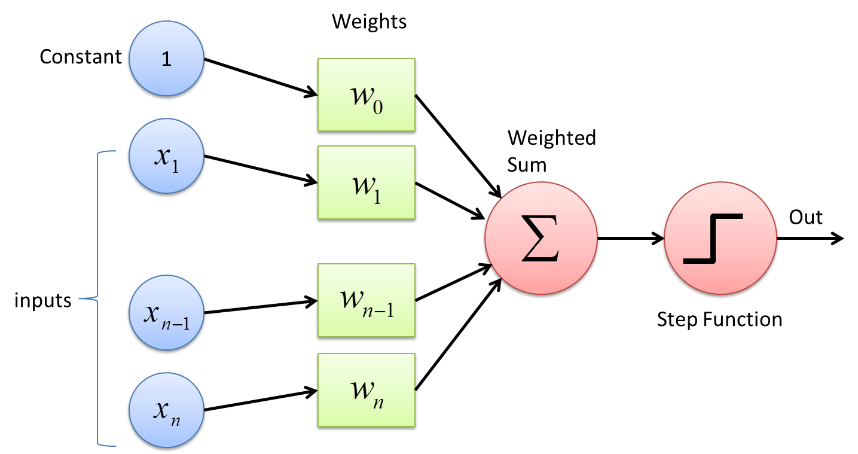
パーセプトロンは、本質的にバイナリである変数のベクトルを単一のバイナリ出力にマップするバイナリ分類関数を利用します。 これは、教師あり学習でも使用できます。 パーセプトロン学習アルゴリズムの手順は次のとおりです–
- すべての入力に重みwを掛けます。ここで、wは、最初に固定またはランダム化できる実数です。
- 積を合計して加重和∑wjxjを取得します
- 入力の加重和が得られると、活性化関数が適用され、適用された活性化関数に応じて、加重和が特定のしきい値より大きいかどうかが判断されます。 出力は、しきい値条件に応じて1または0として割り当てられます。 ここで、値「-threshold」は、バイアスという用語も指します。
このように、パーセプトロン学習アルゴリズムを使用して、今日設計および開発されているニューラルネットワークに存在するニューロンを起動(値= 1)することができます。 パーセプトロン学習アルゴリズムの別の表現は–
f(x) = 1、∑ wjxj+b≥0の場合
0、∑ wj xj +b<0の場合
パーセプトロンは現在広く使用されていませんが、ニューラルネットワークのコアコンセプトの1つとして残っています。 さらなる研究では、1つのパーセプトロンでさえ、重みまたはバイアスのいずれかの小さな変化が、出力を1から0に、またはその逆に大きく変化させる可能性があることが理解されました。 これは、パーセプトロンの大きな欠点の1つでした。 したがって、人工ニューロンの重みとバイアスに中程度の変化のみを導入するReLU、シグモイド関数などのより複雑な活性化関数が開発されました。
ソース
畳み込みニューラルネットワーク
畳み込みニューラルネットワークは、画像を入力として受け取り、画像のさまざまな部分にさまざまな重みとバイアスを割り当てて、それらが互いに微分可能になるようにする深層学習アルゴリズムです。 それらが微分可能になると、畳み込みニューラルネットワークモデルは、さまざまな活性化関数を使用して、画像認識、画像分類、オブジェクトと顔の検出など、画像処理ドメインでいくつかのタスクを実行できます。
畳み込みニューラルネットワークモデルの基本は、入力画像を受け取ることです。 入力画像には、ラベルを付けることも(猫、犬、ライオンなど)、ラベルを付けることもできません。 これに応じて、深層学習アルゴリズムは、画像にラベルが付けられる教師ありアルゴリズムと、画像に特定のラベルが付けられていない教師なしアルゴリズムの2つのタイプに分類されます。
コンピュータマシンにとって、入力画像はピクセルの配列として、より多くの場合は行列の形で見られます。 画像のほとんどはhxwxdの形式です(ここで、h =高さ、w =幅、d =寸法)。 たとえば、サイズ16 x 16 x 3のマトリックス配列の画像はRGB画像を示します(3はRGB値を表します)。 一方、14 x 14 x 1の行列配列の画像は、グレースケール画像を表します。

ソース
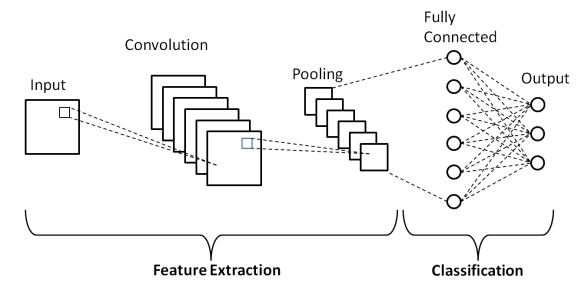
畳み込みニューラルネットワークの層
上記の畳み込みニューラルネットワークの基本アーキテクチャに示されているように、CNNモデルは、入力画像が出力を取得するために前処理を受けるいくつかのレイヤーで構成されています。 基本的に、これらのレイヤーは2つの部分に区別されます–
- 入力レイヤー、畳み込みレイヤー、およびモデルに入力された画像から基本レベルの特徴を導出するための特徴抽出ツールとして機能するプーリングレイヤーを含む最初の3つのレイヤー。
- 最終的な完全接続レイヤーと出力レイヤーは、特徴抽出レイヤーの出力を利用し、抽出された特徴に応じて画像のクラスを予測します。
最初のレイヤーは入力レイヤーであり、画像は行列の配列、つまり32 x 32 x 3の形式で畳み込みニューラルネットワークモデルに送られます。ここで、3は、画像が同じ高さと幅のRGB画像であることを示します。 32ピクセルの。 次に、これらの入力画像は、畳み込みの数学演算が実行される畳み込み層を通過します。
入力画像は、カーネルまたはフィルターと呼ばれる別の正方行列で畳み込まれます。 入力画像のピクセル上でカーネルを1つずつスライドさせることにより、エッジやラインなどの画像の基本レベルの特徴に関する情報を提供する特徴マップと呼ばれる出力画像を取得します。
畳み込み層の後には、特徴マップのサイズを縮小して計算コストを削減することを目的としたプーリング層が続きます。 これは、最大プーリング、平均プーリング、合計プーリングなど、いくつかのタイプのプーリングによって行われます。
Fully Connected (FC)レイヤーは、畳み込みニューラルネットワークモデルの最後から2番目のレイヤーであり、レイヤーが平坦化されてFCレイヤーに供給されます。 ここでは、Sigmoid、ReLU、tanH関数などの活性化関数を使用して、ラベルの予測が行われ、最終的な出力層に出力されます。
CNNが不足している場所
視覚的画像データにおける畳み込みニューラルネットワークの非常に多くの有用なアプリケーションでは、CNNには、一連の画像(ビデオ)ではうまく機能せず、時間情報とテキストのブロックの解釈に失敗するという小さな欠点があります。
文などの時間的または連続的なデータを処理するには、過去のデータとシーケンス内の将来のデータから学習するアルゴリズムが必要です。 幸いなことに、リカレントニューラルネットワークはまさにそれを行います。
リカレントニューラルネットワーク
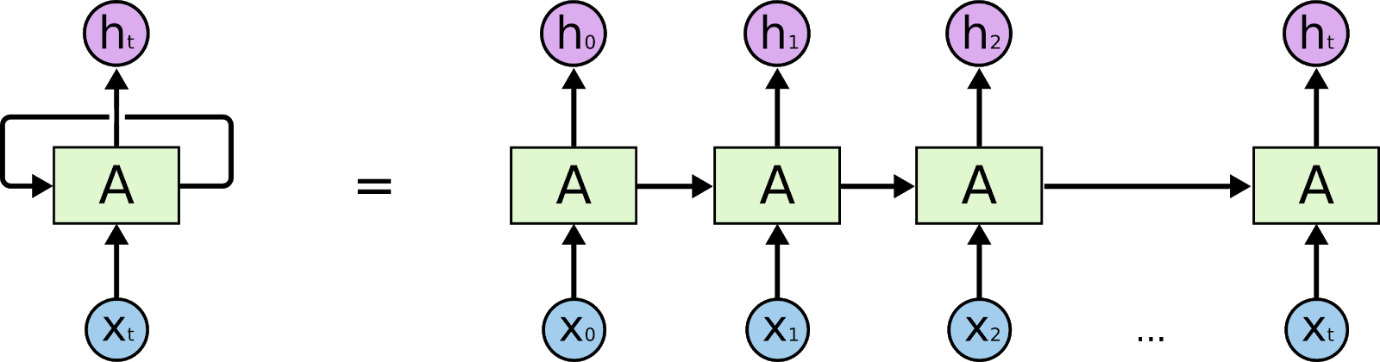
リカレントニューラルネットワークは、時間的または順次的な情報を解釈するように設計されたネットワークです。 RNNは、シーケンス内の他のデータポイントを使用して、より適切な予測を行います。 これは、入力を受け取り、シーケンス内の前のノードまたは後のノードのアクティブ化を再利用して出力に影響を与えることによって行われます。
ソース
内部メモリの結果として、リカレントニューラルネットワークは、受け取った入力などの重要な詳細を記憶できるため、次に何が起こるかを非常に正確に予測できます。 したがって、時系列、音声、テキスト、オーディオ、ビデオなどのシーケンシャルデータに最も適したアルゴリズムです。 リカレントニューラルネットワークは、他のアルゴリズムと比較して、シーケンスとそのコンテキストをより深く理解することができます。
リカレントニューラルネットワークはどのように機能しますか?
リカレントニューラルネットワークでの作業を理解するための基礎は、畳み込みニューラルネットワークの基礎と同じです。これは、パーセプトロンとしても知られる単純なフィードフォワードニューラルネットワークです。 さらに、リカレントニューラルネットワークでは、前のステップからの出力が現在のステップへの入力として供給されます。 ほとんどのニューラルネットワークでは、出力は通常入力から独立しており、その逆も同様です。これがRNNと他のニューラルネットワークの基本的な違いです。
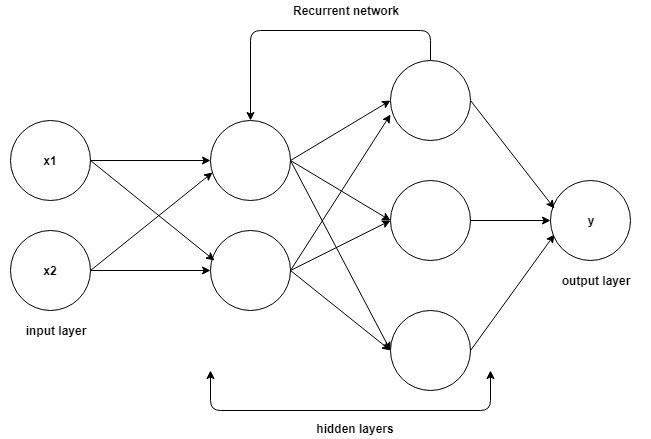
ソース
したがって、RNNには現在と最近の過去の2つの入力があります。 データのシーケンスには次に来るものに関する重要な情報が含まれているため、これは重要です。そのため、RNNは他のアルゴリズムでは実行できないことを実行できます。 リカレントニューラルネットワークの主で最も重要な機能は、シーケンスに関するいくつかの情報を記憶する非表示状態です。
リカレントニューラルネットワークには、計算された内容に関するすべての情報を格納するメモリがあります。 各入力に同じパラメーターを使用し、すべての入力または非表示レイヤーで同じタスクを実行することにより、パラメーターの複雑さが軽減されます。
CNNとRNNの違い
| 畳み込みニューラルネットワーク | リカレントニューラルネットワーク |
| 深層学習では、畳み込みニューラルネットワーク(CNN、またはConvNet)は、視覚的イメージの分析に最も一般的に適用される深層ニューラルネットワークのクラスです。 | リカレントニューラルネットワーク(RNN)は、ノード間の接続が時間シーケンスに沿って有向グラフを形成する人工ニューラルネットワークのクラスです。 |
| 画像などの空間データに適しています。 | RNNは、シーケンシャルデータとも呼ばれる時間データに使用されます。 |
| CNNは、最小限の前処理を使用するように設計された多層パーセプトロンのバリエーションを備えたフィードフォワード人工ニューラルネットワークの一種です。 | RNNは、フィードフォワードニューラルネットワークとは異なり、内部メモリを使用して任意の入力シーケンスを処理できます。 |
| CNNはRNNよりも強力であると考えられています。 | RNNは、CNNと比較した場合、機能の互換性が低くなります。 |
| このCNNは、固定サイズの入力を受け取り、固定サイズの出力を生成します。 | RNNは、任意の入力/出力長を処理できます。 |
| CNNは、画像やビデオの処理に最適です。 | RNNは、テキストおよび音声の分析に最適です。 |
| アプリケーションには、画像認識、画像分類、医療画像分析、顔検出、コンピュータービジョンが含まれます。 | アプリケーションには、テキスト翻訳、自然言語処理、言語翻訳、感情分析、音声分析が含まれます。 |
結論
したがって、この2つの最も人気のあるタイプのニューラルネットワーク、畳み込みニューラルネットワークとリカレントニューラルネットワークの違いについてのこの記事では、ニューラルネットワークの基本構造と、CNNとRNNの両方の基礎を学び、最後に要約しました。それらの2つと実際のアプリケーションとの簡単な比較。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのエグゼクティブPGプログラムをご覧ください。このプログラムは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIITを提供しています。 -B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との雇用支援。
CNNがRNNよりも速いのはなぜですか?
CNNは画像を処理するように設計されているのに対し、RNNはテキストを処理するように設計されているため、RNNよりも高速です。 RNNは画像を処理するようにトレーニングできますが、互いに接近している対照的な機能を分離することは依然として困難です。 たとえば、目、鼻、口のある顔の写真がある場合、RNNは最初に表示する機能を見つけるのに苦労します。 CNNは点のグリッドを使用し、アルゴリズムを使用することで、形状やパターンを認識するようにトレーニングできます。 CNNは、画像の並べ替えにおいてRNNよりも優れています。 計算が簡単で、画像の並べ替えに優れているため、RNNよりも高速です。
RNNは何に使用されますか?
リカレントニューラルネットワーク(RNN)は、ユニット間の接続が有向サイクルを形成する人工ニューラルネットワークのクラスです。 あるニューロンの出力が別のニューロンの入力になるのと同じように、あるユニットの出力が別のユニットの入力になります。 RNNは、音声認識や機械翻訳など、標準的な方法では実行が難しい複雑なタスクを実行するために使用されてきました。
RNNとは何ですか?フィードフォワードニューラルネットワークとはどのように異なりますか?
リカレントニューラルネットワーク(RNN)は、シーケンシャルデータの処理に使用される一種のニューラルネットワークです。 リカレントニューラルネットワークは、入力層、1つ以上の隠れ層、および出力層で構成されます。 非表示レイヤーは、入力データの内部表現を学習するように設計されており、入力データは外部表現として出力レイヤーに提示されます。 RNNは、バックプロパゲーションの助けを借りてトレーニングされます。 RNNは、フィードフォワードニューラルネットワーク(FNN)と比較されることがよくあります。 RNNとFNNはどちらもデータの内部表現を学習できますが、RNNは長期的な依存関係を学習できますが、FNNは学習できません。