畳み込みニューラルネットワーク(CNN)の初心者向けガイド
公開: 2021-07-05過去10年間で、人工知能とよりスマートなマシンが驚異的な成長を遂げました。 この分野は、人間の知性の明確な側面に特化した多くのサブ分野を生み出しました。 たとえば、自然言語処理は人間の音声を理解してモデル化しようとしますが、コンピュータビジョンは人間のような視覚を機械に提供することを目的としています。
畳み込みニューラルネットワークについて説明するので、主にコンピュータービジョンに焦点を当てます。 コンピュータビジョンは、機械が私たちと同じように世界を表示し、画像認識、画像分類などに関連する問題を解決できるようにすることを目的としています。 畳み込みニューラルネットワークは、コンピュータービジョンのさまざまなタスクを実行するために使用されます。 CNNまたはConvNetとも呼ばれ、人間の脳のニューロンのパターンと接続に似たアーキテクチャに従い、脳で発生するさまざまな生物学的プロセスに触発されてコミュニケーションを実現します。
目次
複雑なニューラルネットワークの生物学的重要性
CNNは私たちの視覚野に触発されています。 私たちの脳の視覚処理に関与しているのは大脳皮質の領域です。 視覚野には、視覚刺激に敏感なさまざまな小さな細胞領域があります。
このアイデアは、特定の方向の異なるエッジの存在に異なる異なる神経細胞が応答する(発火する)ことがわかった実験で、ヒューベルとヴィーゼルによって1962年に拡張されました。 たとえば、一部のニューロンは水平エッジの検出時に発火し、他のニューロンは対角エッジの検出時に発火し、他のニューロンは垂直エッジの検出時に発火します。 この実験を通して。 ヒューベルとヴィーゼルは、ニューロンがモジュール方式で編成されており、視覚を生成するためにすべてのモジュールが一緒に必要であることを発見しました。
このモジュラーアプローチ(システム内の特殊なコンポーネントには特定のタスクがあるという考え)が、CNNの基礎を形成します。
それが解決したら、CNNが視覚入力を知覚する方法を学習する方法に移りましょう。

畳み込みニューラルネットワーク学習
画像は、0から255までの数字を表す個々のピクセルで構成されます。したがって、表示される画像は、これらの数字を使用して適切なデジタル表現に変換できます。これは、コンピューターも画像を処理する方法です。
CNNに画像の検出または分類を学習させるための主要な操作を次に示します。 これにより、CNNで学習がどのように行われるかがわかります。
1.畳み込み
畳み込みは、数学的には、2つの異なる関数を組み合わせて統合し、異なる関数の影響を調べたり、相互に変更したりすることとして理解できます。 数学的に定義する方法は次のとおりです。
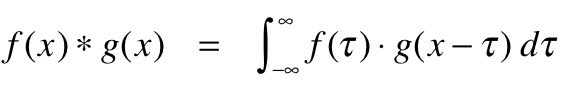
畳み込みの目的は、線、エッジ、色、影など、画像内のさまざまな視覚的特徴を検出することです。 CNNが画像内の特定の特徴の特性を学習すると、後で画像の他の部分のその特徴を認識できるため、これは非常に便利なプロパティです。
CNNは、カーネルまたはフィルターを利用して、任意の画像に存在するさまざまな特徴を検出します。 カーネルは、特定の機能を検出するようにトレーニングされた個別の値(人工ニューラルネットワークの世界では重みとして知られています)の単なるマトリックスです。 フィルタは画像全体を移動して、特徴の存在が検出されたかどうかを確認します。 フィルタは畳み込み演算を実行して、特定の機能が存在することの確信度を表す最終値を提供します。
画像に特徴が存在する場合、畳み込み演算の結果は正の数であり、値が高くなります。 機能がない場合、畳み込み演算の結果は0または非常に低い値になります。
例を使ってこれをよりよく理解しましょう。 下の画像では、プラス記号を検出するためのフィルターがトレーニングされています。 次に、フィルターが元の画像に渡されます。 元の画像の一部には、フィルターがトレーニングされたものと同じ特徴が含まれているため、特徴が存在する各セルの値は正の数になります。 同様に、畳み込み演算の結果も多数になります。
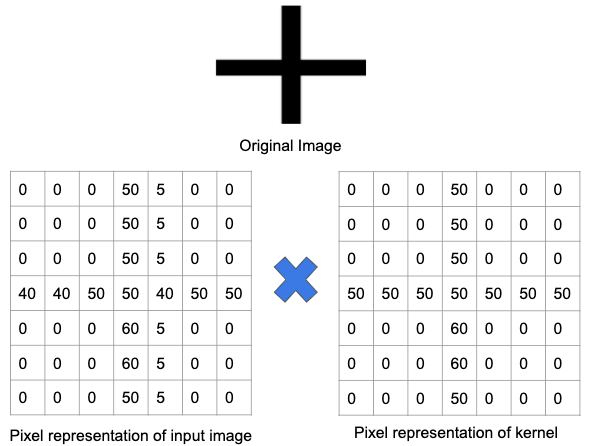
ただし、同じフィルターが異なる特徴とエッジのセットを持つ画像に渡されると、畳み込み演算の出力は低くなります。つまり、画像にプラス記号が強く存在しなかったことを意味します。
したがって、曲線、エッジ、色などのさまざまな特徴を持つ複雑な画像の場合、N個のそのような特徴検出器が必要になります。
このフィルターが画像を通過すると、特徴マップが生成されます。これは基本的に、画像のさまざまな部分に対するこのフィルターの畳み込みを格納する出力行列です。 多くのフィルターの場合、最終的に3D出力になります。 このフィルターは、畳み込み操作を実行するために、入力画像と同じ数のチャネルを持っている必要があります。
さらに、ストライド値を使用して、フィルターをさまざまな間隔で入力画像上でスライドさせることができます。 ストライド値は、各ステップでフィルターが移動する量を示します。
したがって、特定の畳み込みブロックの出力層の数は、次の式を使用して決定できます。

2.パディング
畳み込み層を操作する際の問題の1つは、元の画像の周囲で一部のピクセルが失われる傾向があることです。 一般に、使用されるフィルターは小さいため、フィルターごとに失われるピクセルは少ない場合がありますが、さまざまな畳み込み層を適用すると、多くのピクセルが失われることになります。
パディングの概念は、CNNのフィルターが画像を処理している間に画像にピクセルを追加することです。 これは、画像処理でフィルターを支援する1つのソリューションです。画像にゼロを埋め込んで、カーネルが画像全体をカバーするためのスペースを増やすことができます。 フィルタにゼロパディングを追加することにより、CNNによる画像処理ははるかに正確で正確になります。
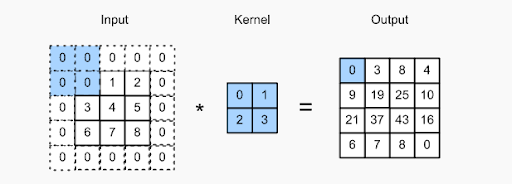

上の画像を確認してください–パディングは、入力画像の境界にゼロを追加することによって行われました。 これにより、ピクセルを失うことなく、すべての個別の機能をキャプチャできます。
3.アクティベーションマップ
特徴マップは、本質的に非線形であるマッピング関数を通過する必要があります。 特徴マップはバイアス項に含まれ、非線形のアクティベーション(ReLu)関数を通過します。 この関数は、検出および検査される画像も本質的に非線形であり、さまざまなオブジェクトで構成されているため、CNNにある程度の非線形性をもたらすことを目的としています。
4.プーリングステージ
アクティベーションフェーズが終了したら、プーリングステップに進みます。ここで、CNNは畳み込み機能をダウンサンプリングし、処理時間を節約します。 これは、画像の全体的なサイズの縮小、過剰適合、および複雑なニューラルネットワークに大量の情報が供給された場合に発生するその他の問題にも役立ちます。特にその情報が画像の分類や検出にあまり関連していない場合に役立ちます。
プーリングには、基本的に最大プーリングと最小プーリングの2つのタイプがあります。 前者では、設定されたストライド値に従ってウィンドウが画像上に渡され、各ステップで、ウィンドウに含まれる最大値が出力行列にプールされます。 最小プーリングでは、最小値が出力マトリックスにプールされます。
出力の結果として形成される新しいマトリックスは、プールされた特徴マップと呼ばれます。
最小および最大プーリングのうち、最大プーリングの利点の1つは、CNNがすべてのニューロンに焦点を合わせるのではなく、高い値を持ついくつかのニューロンに焦点を合わせることができることです。 このようなアプローチにより、トレーニングデータが過剰適合する可能性が非常に低くなり、全体的な予測と一般化がうまくいきます。
5.平坦化
プーリングが完了すると、画像の3D表現が特徴ベクトルに変換されます。 次に、これを多層パーセプトロンに渡して出力を生成します。 平坦化操作をよりよく理解するには、以下の画像を確認してください。
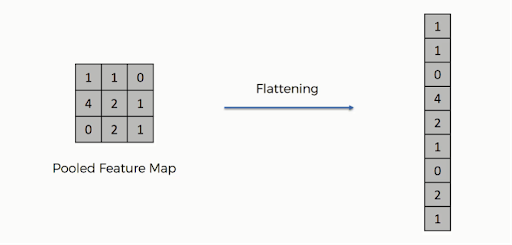
ご覧のとおり、行列の行は1つの特徴ベクトルに連結されています。 複数の入力レイヤーが存在する場合、すべての行が接続されて、より長く平坦化された特徴ベクトルを形成します。
6.完全接続層(FCL)
このステップでは、平坦化されたマップがニューラルネットワークに送られます。 ニューラルネットワークの完全な接続には、入力層、FCL、および最終出力層が含まれます。 完全に接続されたレイヤーは、人工ニューラルネットワークの非表示レイヤーとして理解できます。ただし、非表示レイヤーとは異なり、これらのレイヤーは完全に接続されています。 情報はネットワーク全体を通過し、予測誤差が計算されます。 このエラーは、システムを介してフィードバック(バックプロパゲーション)として送信され、重みを調整して最終出力を改善し、より正確にします。
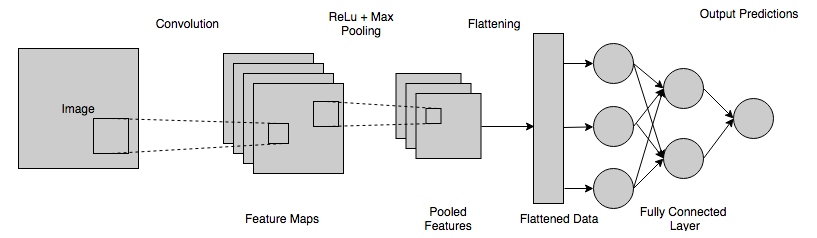
ニューラルネットワークの上の層から得られる最終的な出力は、通常、合計で1つにはなりません。 これらの出力は、[0,1]の範囲の数値に下げる必要があります。これにより、各クラスの確率が表されます。 このために、Softmax関数が使用されます。
高密度層から得られた出力は、Softmax活性化関数に送られます。 これにより、すべての最終出力がベクトルにマッピングされ、すべての要素の合計が1になります。
完全に接続されたレイヤーは、前のレイヤーの出力を確認し、特定のクラスに最も相関する機能を判別することで機能します。 したがって、プログラムが画像に猫が含まれているかどうかを予測する場合、4本の足、足、尾などの特徴を表すアクティベーションマップで高い値を持ちます。 同様に、プログラムが他の何かを予測している場合、さまざまなタイプのアクティベーションマップがあります。 完全に接続されたレイヤーは、特定のクラスと重みに強く相関するさまざまな機能を処理するため、重みと前のレイヤーの間の計算が正確になり、異なるクラスの出力に対して正しい確率が得られます。
CNNの動作の簡単な要約
これは、CNNがどのように機能し、コンピュータービジョンに役立つかについてのプロセス全体の簡単な要約です。
- 画像とは異なるピクセルが畳み込み層に送られ、そこで畳み込み演算が実行されます。
- 前の手順で、畳み込みマップが作成されます。
- このマップは、整流されたマップを生成するために整流関数を通過します。
- 画像は、さまざまな特徴を見つけて検出するためのさまざまな畳み込みおよび活性化関数で処理されます。
- プーリングレイヤーは、画像の特定の異なる部分を識別するために使用されます。
- プールされたレイヤーはフラット化され、完全に接続されたレイヤーへの入力として使用されます。
- 完全に接続されたレイヤーは確率を計算し、[0,1]の範囲の出力を提供します。
結論は
CNNの内部機能は非常にエキサイティングであり、革新と創造のための多くの可能性を開きます。 同様に、人工知能の傘下にある他のテクノロジーは魅力的であり、人間の能力と機械の知能の間で機能しようとしています。 その結果、さまざまなドメインに属する世界中の人々がこの分野への関心を認識し、最初の一歩を踏み出しました。
幸いなことに、AI業界は非常に歓迎されており、学歴に基づいて区別することはできません。 必要なのは、基本的な資格とともにテクノロジーの実用的な知識だけです。これで準備は完了です。
MLとAIの要点をマスターしたい場合、理想的な行動方針は、プロのAI/MLプログラムに登録することです。 たとえば、機械学習とAIのエグゼクティブプログラムは、データサイエンス志望者に最適なコースです。 このプログラムは、統計や探索的データ分析、機械学習、自然言語処理などのテーマをカバーしています。 また、13以上の業界プロジェクト、25以上のライブセッション、6つのキャップストーンプロジェクトが含まれています。 このコースの最大の利点は、世界中の仲間と交流できることです。 それはアイデアの交換を容易にし、学習者が多様なバックグラウンドを持つ人々との永続的なつながりを構築するのに役立ちます。 私たちの360度のキャリア支援は、MLとAIの旅で卓越するために必要なものです!
AI主導の技術革命をリードする