
データ構造の配列–説明、機能、例
公開: 2021-06-21データ構造は、ほとんどのコンピュータプログラムに広く適用されているほとんどすべてのプログラミング言語の重要な部分であることが証明されています。 単一のデータに個別にアクセスして保存することは時間のかかるプロセスであるため、プログラムによってデータを効果的に管理およびアクセスできるのは、データ構造を通じてです。 アルゴリズムは、データ構造に必要な特定の操作を作成するために特別に設計されています。 したがって、データ構造とアルゴリズムが一緒になって、複雑なアプリケーションとプログラムの基盤を築きます。
この記事では、ある種のデータ構造、つまり配列に焦点を当てます。
配列は、要素またはデータが連続した場所に格納されるデータ構造の一種です。 ユーザーが同じデータ型のデータセットを持っている場合は常に、配列データ構造がそのデータを整理するためのオプションです。 配列のサイズは、データのサイズによって異なります。 要素を配列に格納する前に、すべての要素を効果的に組み込むために、配列のサイズを定義する必要があります。 配列に格納されている各要素には、配列内のその要素の場所を識別するのに役立つインデックス値が割り当てられています。 配列の最初の要素のインデックス値はゼロです。
配列データ構造に関連する重要な用語は次のとおりです。
- 要素:要素は、データ構造に格納されているすべてのオブジェクトまたはアイテムを表します。
- インデックス:インデックスは、配列内の要素の場所を表します。 数値があります。
配列のサイズは、プログラミング言語によって異なります。 サイズに基づいて、配列には静的配列と動的配列の2つのタイプがあります。
目次
1.静的アレイ:
これらのタイプのアレイには、作成時に事前定義されたサイズがあります。 このため、静的配列は固定配列または固定長配列とも呼ばれます。 配列は2つの方法で定義できます。 配列の作成中に配列の要素を定義することも、配列の作成中に配列のサイズを定義することもできます。 後者の場合、要素を指定する必要はありません。 デフォルト値は、初期化されていない配列または以前の割り当てからメモリに残っている値に割り当てられる場合があります。
サイズが定義されると、配列は縮小または拡大できません。 配列の宣言中にメモリが割り当てられるため、配列を破棄できるのはコンパイラだけです。 次の要素に割り当てるための空きメモリが存在するかどうかがユーザーにわからないため、要素を追加することはできません。
次の表は、さまざまなプログラミング言語で使用される配列の例を示しています。
| プログラミング言語 | 定義された配列の内容 | コンテンツなしの配列の定義されたサイズ |
| C ++ | intmarks [] = {10、20、30}; | intマーク[3]; |
| C# | int[]マーク={10、20、30}; | int[]マーク==新しいint[3]; |
| Java | int[]マーク={10、20、30}; | int[]マーク==新しいint[3]; |
| JavaScript | varマーク=[10、20、30]; | var mark = new Array(3); |
| Python | マーク=[10、20、30] | マーク=[なし]*3 |
| 迅速 | var values:[Int] = [10、20、30] | varマーク:[Int] = [Int](繰り返し:0、カウント:3) |
2.動的配列
名前が示すように、配列は動的です。つまり、実行時に要素を追加したり、削除したりできます。 長さが固定されている静的配列と比較すると、動的配列には固定された長さやサイズの配列がありません。 動的配列を作成および管理するために、ほとんどのプログラミング言語で標準ライブラリ関数または組み込み関数を使用できます。
次の表は、さまざまなプログラミング言語での配列の作成を示しています
| プログラミング言語 | クラス | 要素の追加 | 要素の削除 |
| C ++ | #include<リスト> std :: list | 入れる | 消去 |
| C# | System.Collections.Generic.List | 追加 | 削除 |
| Java | java.util.ArrayList | 追加 | 削除 |
| JavaScript | 配列 | プッシュ、スプライス | ポップ、スプライス |
| Python | リスト | 追加 | 削除 |
| 迅速 | 配列 | 追加 | 削除 |
配列の表現
配列の表現は、さまざまなプログラミング言語での実装によって異なります。 配列はPythonデータ構造の重要な部分であり、Pythonプログラミング言語で図が示されています。
Pythonのデータ構造では、配列はキーワードarrayを介して処理されます。 キーワード配列を使用する場合は常に、ユーザーは同じデータ型の要素を格納する必要があります。
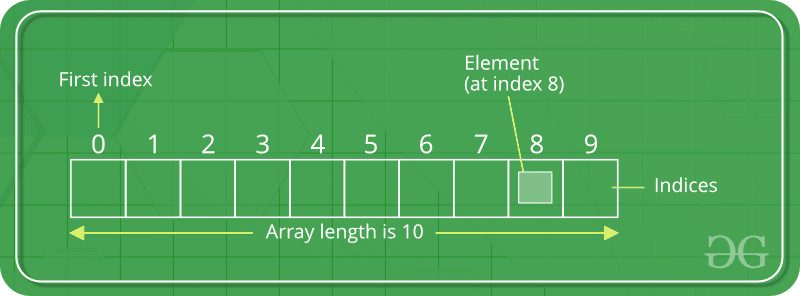
ソース
図1:アレイの例
図1のように、アレイの図は次のことを示しています。
- 配列のサイズは10です。これは、9つの要素を配列に格納できることを意味します。
- インデックス値は、値0で始まる配列の上に記載されています。
- 配列に格納されている要素は任意のデータ型であり、要素にはインデックス値を介してアクセスできます。
別の図を図2に示します。ここでは、PythonとC++の構文が説明されています。
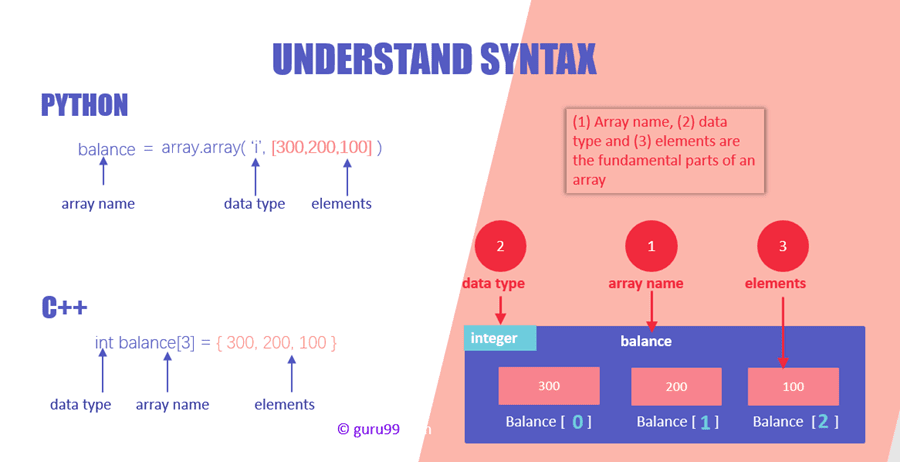
ソース
図2 :PythonとC ++を使用した配列宣言(
配列のプロパティ
配列データ構造にはいくつかのプロパティがあります。
- 配列内に格納されている要素のデータ型とサイズは同じです。つまり、 intのデータ型のサイズは4バイトになります。
- 連続するメモリ位置は、データ構造の要素を格納するために使用されます。 最小のメモリが配列の最初の要素に割り当てられます。
- インデックス値は、配列内の要素の場所を見つけるために使用されます。 インデックスは0から始まり、常に配列内の要素の総数よりも少なくなります。
- 使用可能なインデックス値により、配列内の要素へのランダムアクセスが可能です。 要素のアドレスは、オフセット値に追加されたベースアドレスから計算できます。
- 配列の概念は、すべてのプログラミング言語で同じです。 初期化と宣言のみが異なります。
- 配列名、要素、およびデータ型は、すべての言語で共通する3つの部分です。
アレイの作成
Pythonデータ構造での配列の作成を以下に示します。
- Pythonデータ構造の配列モジュールは、配列を作成するためにインポートできます。
- array(data_type、value_list )は、 Pythonデータ構造で配列を作成するための構文です。
- データ型は実数整数または浮動小数点数である必要があります。 Pythonでは文字列は許可されていません。
図2は、Pythonで配列を作成する方法を示しています。 配列モジュールがPythonにインポートされる方法を示すコードの例
配列をインポート
マーク=array.array('i'、[100,200,300])
印刷(マーク)
配列の宣言は、
arrayName = array.array(データ型の型コード、[array、items])
これは図3で表すことができます
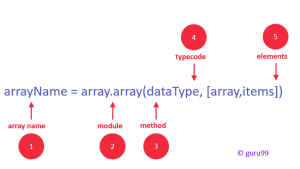
ソース
図3:Pythonでの配列宣言
アレイの作成に使用される重要な用語:
- 識別子:変数の名前のように指定する必要がある名前
- モジュール:配列と呼ばれる特別なモジュールをPythonにインポートする必要があります。
- メソッド: Pythonで配列を初期化するための特定のメソッドです。 タイプコードと要素の2つの引数が使用されました。
- タイプコード:データタイプは、使用可能なタイプコードで指定する必要があります。
- 要素:配列要素は、角かっこで囲む必要があります(例:[200,400,100])。
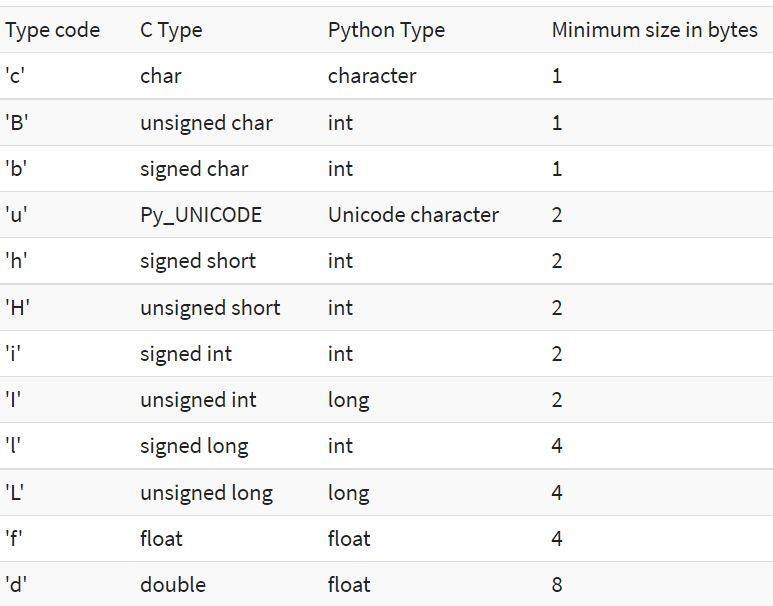
利用可能なタイプコードを以下に示します

配列操作
データ構造とアルゴリズムが利用できるため、あらゆるタイプのデータ構造でいくつかの操作を実行できます。 配列データ構造には、要素の追加、削除、アクセッション、更新などの操作を含めることができます。
Pythonデータ構造の配列で実行できる操作を以下に示します。
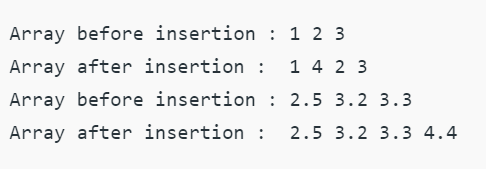
1.配列への要素の追加
- 組み込みのinsert()関数は、配列に要素を追加するために使用されます。
- 使用される構文:arrayName.insert(index、value)
- insert()関数を使用して、1つまたは複数の要素を配列に追加できます。
- 要素は、Input: append()関数を使用して、配列の先頭または特定の位置に追加できます。
配列をインポート
マーク=array.array('i'、[200,500,600])
mark.insert(1、150)
出力:array('i'、[200,150,500,600])
コードの例を以下に示します。

コードの出力:
ソース
2.配列内の要素の削除
- 要素は、その値を介して配列から削除できます。
- 使用される構文:arrayName.remove(value)
- 例:要素100、300、200、500、および800を持つ配列に追加した後、値250を削除します。
入力:
配列をインポート
マーク=array.array('i'、[100,300,200,500,800])
mark.insert(1、250)
印刷(マーク)
mark.remove(250)
出力:array('i'、[100,300,200,500,800])
から取得したコードの例

ソース
コードの出力:

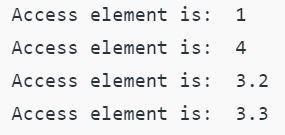
3.配列内の要素へのアクセス
- インデックス演算子[]は、配列内の要素にアクセスするために使用されます。
- インデックス番号は、配列内の任意の要素にアクセスするために使用されます。
コードの例を以下に示します。

コードの出力:
ソース
4.配列内の要素を検索します。
- 組み込みのindex()メソッドは、配列内の要素を検索するために使用されます。
- 検索する要素のインデックス値は、関数によって返されます。
- 例:要素100、250、300、200、500、および800の配列で要素250を検索します。
入力:配列のインポート
マーク=array.array('I'、[100,250,300,200,500,800])
print(marks.index(250))
出力:1
配列内の要素を検索するためのコード

コードの出力は次のとおりです。

ソース
3.配列内の要素を更新する
- 要素を更新するプロセスは挿入方法に似ていますが、既存の値を更新するときに指定されたインデックスで置き換えられる点が異なります。
- 配列内の要素を更新するために、新しい値がインデックスに再割り当てされます。
- 例:要素100、250、300、200、500、および800の配列で要素250を350で更新します。
入力:配列のインポート
マーク=array.array('i'、[100,250,300,200,500,800])
マーク[1]=350
出力:
array('i'、[100,350,300,200,500,800])
要素の更新を示すコードを以下に示します

コードの出力は次のとおりです。

ソース
アレイの利点
- 要素ごとに個別の変数を作成する代わりに、単一の変数に複数の値を格納することができます。
- 配列を使用すると、複数の値を簡単かつ迅速に処理できます。
- 配列の要素は、より高速な方法で並べ替えおよび検索できます。
結論
この記事では、特殊なタイプのデータ構造、つまり配列とそれに関連する操作について説明しました。 基本的な概念を使用すると、実際の問題を対象としたより複雑なプログラムを構築できます。 Pythonでのデータ構造の概念の基盤を強化したい場合は、 upGradによるデータサイエンスのエグゼクティブPGプログラムの次のコースを参照してください。 このコースはIIIT-Bangaloreによって認定されており、業界への旅を準備するための14以上のプログラミングツールと言語が用意されています。 21〜45歳のエントリーレベルの専門家向けに特別に設計されています。 ですから、ここで学習をやめないでください。upGradの過程で、機械学習の世界で言語とその応用を理解してください。 ご不明な点がございましたら、弊社のサポートチームがお手伝いいたします。
配列は強力な線形データ構造です。 ただし、以下に示すいくつかの長所と短所があります。 以下に、配列とリストの違いを示します。 配列データ構造には実際に多くのアプリケーションがあり、他のユーザー定義のデータ構造を実装するためのベースとしても使用されます。 アレイの主な用途のいくつかは次のとおりです。アレイの長所と短所は何ですか?
利点
1.配列では、要素はインデックス番号で簡単にアクセスできます。
2.配列を使用して、複数の類似したエンティティを格納できます。
3.検索操作は非常に便利です。 これは、ソートされた配列のO(n)時間とO(log n)で実行できます。ここで、nは要素の数です。
短所
1.メモリは配列に静的に割り当てられるため、配列のサイズを変更することはできません。
2.同種です。つまり、類似したデータ型を持つ要素のみを配列に格納できます。 配列とリストを区別しますか?
配列 -
1.配列のデータ構造は同種です。つまり、類似したデータ型の要素のみを配列に格納できます。
2.アレイを使用する前に、モジュールをインポートする必要があります。
3.算術演算は直接適用できます。
4.より大きなデータに適しています。
4.はるかにコンパクトで、より少ないメモリを消費します。
リスト-
1.リストは異種であり、その中に複数のデータ型の要素を格納できます。
2. Pythonに組み込まれているため、モジュールをインポートする必要はありません。
3.算術演算を直接操作することはできません。
4.小さいデータに適しています。
5.メモリ消費量が多くなります。 アレイの主な用途を説明してください。
1.配列は、行列演算を実装および実行するために使用されます。 マトリックスは、主に地質調査や科学研究実験で使用されます。
2.配列データ構造を使用して、いくつかのユーザー定義データ構造が実装されます。 これらには、スタック、キュー、ヒープ、ハッシュテーブル、およびリストが含まれます。
3.プログラムは、比較的長い従来のelifステートメントを使用する代わりに、配列を使用して制御フローを調整します。
4. CPUスケジューリングプロセス用に作成されたアルゴリズムも、アレイデータ構造を使用してCPUパフォーマンスを向上させます。
5.グラフは、実装の1つとして隣接リストを使用します。 ベクトル(配列の適用)は、これらの隣接リストを作成するために使用されます。