
2022年のApacheSparkの6つのゲーム変更機能[どのように使用するか]
公開: 2021-01-07ビッグデータがテクノロジーとビジネスの世界を席巻して以来、ビッグデータのツールとプラットフォーム、特にApacheHadoopとApacheSparkが急増しています。 今日は、Apache Sparkのみに焦点を当て、そのビジネス上の利点とアプリケーションについて詳しく説明します。
Apache Sparkは2009年に脚光を浴び、それ以来、業界で徐々にニッチ市場を切り開いてきました。 Apache org。によると、Sparkは、膨大な量のビッグデータを処理するために設計された「超高速の統合分析エンジン」です。 活発なコミュニティのおかげで、今日、Sparkは世界最大のオープンソースビッグデータプラットフォームの1つです。
目次
Apache Sparkとは何ですか?
もともとカリフォルニア大学(バークレー)のAMPLabで開発された、Sparkは、速度と使いやすさに特に重点を置いて、Hadoopデータの堅牢な処理エンジンとして設計されました。 これは、HadoopのMapReduceに代わるオープンソースです。 基本的に、Sparkは、Apache Hadoopと連携して、Hadoopでの高度なビッグデータアプリケーションのスムーズかつ迅速な開発を促進できる並列データ処理フレームワークです。
Sparkには、機械学習(ML)アルゴリズムとグラフアルゴリズム用の幅広いライブラリが含まれています。 それだけでなく、SparkStreamingとSharkを介したリアルタイムストリーミングアプリとSQLアプリもそれぞれサポートします。 Sparkを使用する最大の利点は、Java、Scala、さらにはPythonでSparkアプリを作成できることです。これらのアプリは、MapReduceアプリよりも約10倍高速(ディスク上)および100倍高速(メモリ内)で実行されます。
Apache Sparkは、さまざまな方法でデプロイできるため非常に用途が広く、Java、Scala、Python、およびRプログラミング言語のネイティブバインディングも提供します。 SQL、グラフ処理、データストリーミング、機械学習をサポートしています。 これが、Sparkが銀行、通信会社、ゲーム開発会社、政府機関、そしてもちろん、Apple、Facebook、IBM、Microsoftなどのテクノロジー業界のすべてのトップ企業を含む業界のさまざまなセクターで広く使用されている理由です。
ApacheSparkの6つの最高の機能
Sparkを最も広く使用されているビッグデータプラットフォームの1つにする機能は次のとおりです。

1.非常に速い処理速度
ビッグデータ処理とは、大量の複雑なデータを処理することです。 したがって、ビッグデータ処理に関しては、組織や企業は、大量のデータを高速で処理できるようなフレームワークを求めています。 前述したように、Sparkアプリは、Hadoopクラスターのメモリで最大100倍、ディスクで最大10倍高速に実行できます。
これは、Sparkがデータをメモリに透過的に保存し、必要な場合にのみディスクに読み取り/書き込みできるようにするResilient Distributed Dataset(RDD)に依存しています。 これは、データ処理中のディスクの読み取りおよび書き込み時間のほとんどを削減するのに役立ちます。
2.使いやすさ
Sparkを使用すると、Java、Scala、Python、およびRでスケーラブルなアプリケーションを作成できます。したがって、開発者は、好みのプログラミング言語でSparkアプリケーションを作成および実行することができます。 さらに、Sparkには80を超える高レベルのオペレーターのセットが組み込まれています。 Sparkをインタラクティブに使用して、Scala、Python、R、およびSQLシェルからデータをクエリできます。
3.高度な分析のサポートを提供します
Sparkは、単純な「マップ」および「リデュース」操作をサポートするだけでなく、SQLクエリ、ストリーミングデータ、およびMLやグラフアルゴリズムを含む高度な分析もサポートします。 SQLとDataFrames、MLlib(ML用)、GraphX、SparkStreamingなどの強力なライブラリスタックが付属しています。 魅力的なのは、Sparkを使用すると、これらすべてのライブラリの機能を1つのワークフロー/アプリケーション内で組み合わせることができることです。
4.リアルタイムストリーム処理
Sparkは、リアルタイムのデータストリーミングを処理するように設計されています。 MapReduceは、Hadoopクラスターに既に保存されているデータを処理および処理するように構築されていますが、Sparkは両方を実行でき、SparkStreamingを介してリアルタイムでデータを操作することもできます。
他のストリーミングソリューションとは異なり、Spark Streamingは失われた作業を回復し、追加のコードや構成を必要とせずに、すぐに使用できる正確なセマンティクスを提供できます。 さらに、同じコードをバッチ処理とストリーム処理に再利用したり、ストリーミングデータを履歴データに結合したりすることもできます。
5.柔軟性があります
Sparkはクラスターモードで独立して実行でき、Hadoop YARN、Apache Mesos、Kubernetes、さらにはクラウドでも実行できます。 さらに、さまざまなデータソースにアクセスできます。 たとえば、SparkはYARNクラスターマネージャーで実行し、既存のHadoopデータを読み取ることができます。 HBase、HDFS、Hive、CassandraなどのHadoopデータソースから読み取ることができます。 Sparkのこの側面は、アプリのユースケースがSparkに適している場合、純粋なHadoopアプリケーションを移行するための理想的なツールになります。
6.活発で拡大しているコミュニティ
300社を超える企業の開発者がApacheSparkの設計と構築に貢献してきました。 2009年以来、1200人を超える開発者がSparkを現在の状態にすることに積極的に貢献してきました。 当然のことながら、Sparkは、その機能とパフォーマンスを継続的に改善するために取り組んでいる開発者の活発なコミュニティに支えられています。 Sparkコミュニティに連絡するには、クエリにメーリングリストを利用できます。また、Sparkのミートアップグループや会議に参加することもできます。
Sparkアプリケーションの構造
すべてのSparkアプリケーションは、プライマリドライバープロセスとエグゼキュータープロセスのコレクションの2つのコアプロセスで構成されています。

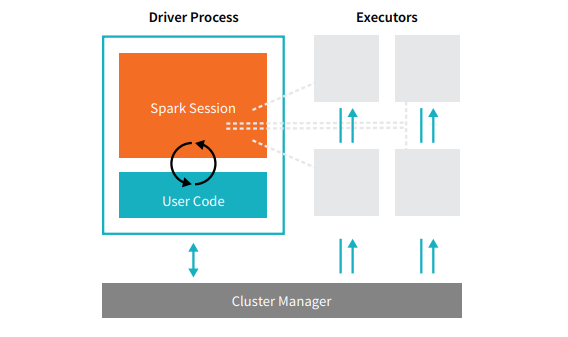
ソース
クラスター内のノード上にあるドライバープロセスは、main()関数の実行を担当します。 また、Sparkアプリケーションに関する情報の維持、ユーザーのコードまたは入力への応答、エグゼキュータ間での作業の分析、分散、およびスケジューリングという3つのタスクも処理します。 ドライバープロセスは、Sparkアプリケーションの心臓部を形成します。これには、Sparkアプリケーションの存続期間をカバーするすべての重要な情報が含まれ、維持されます。
エグゼキュータまたはエグゼキュータプロセスは、ドライバによって割り当てられたタスクを実行する必要があるセカンダリアイテムです。 基本的に、各エグゼキュータは2つの重要な機能を実行します。ドライバによって割り当てられたコードを実行し、(そのエグゼキュータでの)計算の状態をドライバノードに報告します。 ユーザーは、各ノードに必要なエグゼキューターの数を決定および構成できます。
Sparkアプリケーションでは、クラスターマネージャーがすべてのマシンを制御し、アプリケーションにリソースを割り当てます。 ここで、クラスターマネージャーは、YARN(Sparkのスタンドアロンクラスターマネージャー)やMesosなど、Sparkのコアクラスターマネージャーのいずれかになります。 これには、クラスターが複数のSparkアプリケーションを同時に実行できることが必要です。
実際のApacheSparkアプリケーション
Sparkは、現代の業界でトップクラスの広く使用されているBigDaraプラットフォームです。 ApacheSparkアプリケーションの最も評価の高い実際の例のいくつかは次のとおりです。
機械学習のためのSpark
Apache Sparkは、スケーラブルな機械学習ライブラリであるMLlibを誇っています。 このライブラリは、単純さ、スケーラビリティ、および他のツールとのシームレスな統合を容易にするために明示的に設計されています。 MLlibは、Sparkのスケーラビリティ、言語互換性、および速度を備えているだけでなく、分類、クラスタリング、次元削減などの高度な分析タスクのホストを実行することもできます。 MLlibのおかげで、Sparkは予測分析、感情分析、顧客セグメンテーション、および予測インテリジェンスに使用できます。
Apache Sparkのもう1つの印象的な機能は、ネットワークセキュリティドメインにあります。 Spark Streamingを使用すると、ユーザーはデータパケットをストレージにプッシュする前にリアルタイムで監視できます。 このプロセス中に、既知の脅威のソースから発生する疑わしいまたは悪意のあるアクティビティを正常に識別できます。 データパケットがストレージに送信された後でも、SparkはMLlibを使用してデータをさらに分析し、ネットワークに対する潜在的なリスクを特定します。 この機能は、詐欺やイベントの検出にも使用できます。
Spark for Fog Computing
Apache Sparkは、特にモノのインターネット(IoT)に関係する場合、フォグコンピューティングに最適なツールです。 IoTは、大規模な並列処理の概念に大きく依存しています。 IoTネットワークは数千、数百万の接続されたデバイスで構成されているため、このネットワークによって毎秒生成されるデータは理解できません。
当然、IoTデバイスによって生成されたこのような大量のデータを処理するには、並列処理をサポートするスケーラブルなプラットフォームが必要です。 そして、そのような膨大な量のデータを処理するためのSparkの堅牢なアーキテクチャとフォグコンピューティング機能よりも優れています!
フォグコンピューティングは、データとストレージを分散化し、クラウド処理を使用する代わりに、ネットワークのエッジ(主にIoTデバイスに組み込まれている)でデータ処理機能を実行します。
これを行うには、フォグコンピューティングには、低レイテンシー、MLの並列処理、複雑なグラフ分析アルゴリズムの3つの機能が必要です。それぞれがSparkに存在します。 さらに、Spark Streaming、Shark(リアルタイムで機能できるインタラクティブなクエリツール)、MLlib、およびGraphX(グラフ分析エンジン)の存在により、Sparkのフォグコンピューティング機能がさらに強化されます。
インタラクティブ分析のためのSpark
処理速度が比較的遅いMapReduce、Hive、Pigとは異なり、Sparkは高速のインタラクティブ分析を誇ることができます。 データのサンプリングを必要とせずに探索的クエリを処理できます。 また、Sparkは、R、Python、SQL、Java、Scalaなど、ほとんどすべての一般的な開発言語と互換性があります。
Sparkの最新バージョンであるSpark2.0は、StructuredStreamingと呼ばれる新機能を備えています。 この機能を使用すると、ユーザーはストリーミングデータに対して構造化されたインタラクティブなクエリをリアルタイムで実行できます。
Sparkのユーザー
Sparkの機能と機能を十分に理解したところで、Sparkの4人の著名なユーザーについて話しましょう。
1.Yahoo
Yahooは2つのプロジェクトにSparkを使用しています。1つは訪問者向けのニュースページのパーソナライズ用で、もう1つは広告の分析の実行用です。 ニュースページをカスタマイズするために、YahooはSparkで実行されている高度なMLアルゴリズムを利用して、個々のユーザーの興味、好み、ニーズを理解し、それに応じてストーリーを分類します。
2番目のユースケースでは、YahooはHive on Sparkのインタラクティブ機能(Hiveにプラグインする任意のツールと統合する)を利用して、Hadoopで収集されたYahooの広告分析データを表示および照会します。
2.ユーバー
Uberは、Spark StreamingをKafkaおよびHDFSと組み合わせて使用して、離散イベントの膨大な量のリアルタイムデータを構造化された使用可能なデータにETL(抽出、変換、およびロード)してさらに分析します。 このデータは、Uberが顧客向けに改善されたソリューションを考案するのに役立ちます。

3.コンビバ
ビデオストリーミング会社として、Convivaは毎月平均400万を超えるビデオフィードを取得しており、これが大規模な顧客離れにつながります。 この課題は、ライブビデオトラフィックの管理の問題によってさらに悪化します。 これらの課題に効果的に対処するために、ConvivaはSpark Streamingを使用してネットワークの状態をリアルタイムで学習し、それに応じてビデオトラフィックを最適化します。 これにより、Convivaは一貫した高品質の視聴体験をユーザーに提供できます。
4.Pinterest
Pinterestでは、ユーザーはWebやソーシャルメディアを閲覧しながら、好きなときに好きなトピックをピン留めできます。 パーソナライズされた強化されたカスタマーエクスペリエンスを提供するために、PinterestはSparkのETL機能を利用して、個々のユーザーの固有のニーズと関心を識別し、Pinterestでそれらに関連する推奨事項を提供します。
結論
結論として、Sparkは非常に用途の広いビッグデータプラットフォームであり、印象に残るように構築された機能を備えています。 オープンソースのフレームワークであるため、新しい機能が追加され、継続的に改善および進化しています。 ビッグデータのアプリケーションがより多様で広範になるにつれて、ApacheSparkのユースケースも同様になります。
ビッグデータについて詳しく知りたい場合は、ビッグデータプログラムのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。このプログラムは、働く専門家向けに設計されており、7つ以上のケーススタディとプロジェクトを提供し、14のプログラミング言語とツール、実践的なハンズオンをカバーしています。ワークショップ、トップ企業との400時間以上の厳格な学習と就職支援。
upGradで他のソフトウェアエンジニアリングコースを確認してください。