
Apache Kafkaアーキテクチャ:初心者向けの包括的なガイド[2022]
公開: 2021-12-23Apache Kafkaアーキテクチャの詳細を掘り下げる前に、Kafkaが最初に見出しを作る理由に光を当てることは適切です。 まず、Apache Kafkaは、主にリアルタイム分析を提供するためのリアルタイムストリーミングデータアーキテクチャでの使用を見出しています。 耐久性があり、高速で、スケーラブルで、フォールトトレラントなKafkaのパブリッシュ/サブスクライブメッセージングシステムには、IoTセンサーデータの追跡やサービスコールの追跡などのユースケースがあります。
LinkedIn、Netflix、Microsoft、Uber、Spotify、Goldman Sachs、Cisco、PayPalなどの企業は、リアルタイムストリーミングデータの処理にApacheKafkaを採用しています。 たとえば、Kafkaが生まれたLinkedInは、Kafkaを使用して運用メトリックとアクティビティデータを追跡します。 同様に、Netflixの場合、Apache Kafkaは、メッセージング、イベント、およびストリーム処理のニーズの事実上の標準です。
世界のトップ大学からオンラインソフトウェア開発トレーニングを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
Apache Kafkaの有用性は、ApacheKafkaアーキテクチャとその基盤となるコンポーネントを理解することでよりよく理解されます。 それでは、Kafkaのアーキテクチャの詳細を調べてみましょう。
目次
基本的なカフカアーキテクチャの概念
次の概念は、ApacheKafkaアーキテクチャを理解するための基本です。
1.トピック
Kafkaトピックは、データがストリーミングされるチャネルを定義します。 したがって、プロデューサーはトピックにメッセージを公開し、コンシューマーはサブスクライブしているトピックからメッセージを読み取ります。 Kafkaクラスター内で作成されるトピックの数に制限はなく、一意の名前で各トピックを識別します。

2.ブローカー
ブローカーは、コンテナーとして機能し、個別のパーティションを持つ複数のトピックを保持するKafkaクラスター内のサーバーです。 一意の整数IDは、Kafkaクラスター内のブローカーを識別します。これらのブローカーのいずれかとの接続は、クラスター全体との接続を意味します。
3.パーティション
Kafkaのトピックは、パーティションと呼ばれる多くの部分に分かれています。 パーティションは順番に分離され、複数のコンシューマーが特定のトピックからデータを並行して読み取ることができます。 トピックのパーティションはKafkaクラスター内の複数のサーバーに分散されており、各サーバーはデータとその多くのパーティションの要求を管理します。 メッセージはブローカーとキーに到達し、キーは特定のメッセージが送信されるパーティションを決定します。 したがって、同じキーを持つメッセージは同じパーティションに送られます。 キーが指定されていない場合、パーティションはラウンドロビンアプローチに従って決定されます。
4.レプリカ
Kafkaでは、レプリカはパーティションバックアップのようなものであり、計画的なシャットダウンや障害が発生した場合にデータが失われることはありません。 つまり、レプリカはパーティションのコピーです。
5.パーティションオフセット
Kafkaのメッセージまたはレコードはパーティションに割り当てられるため、各レコードには、パーティション内の位置を指定するためのオフセットが提供されます。 したがって、レコードに関連付けられたオフセット値は、パーティション内での識別を容易にするのに役立ちます。 パーティションオフセットは、その特定のパーティション内でのみ意味を持ち、レコードはパーティションの端に追加されるため、古いレコードのオフセット値は低くなります。
6.プロデューサー
Kafkaプロデューサーは、1つ以上のトピックにメッセージを公開し、Kafkaクラスターにデータを送信します。 プロデューサーがKafkaトピックにメッセージを公開するとすぐに、ブローカーはメッセージを受信し、特定のパーティションに追加します。 次に、プロデューサーはメッセージを公開するパーティションを選択できます。
7.消費者および消費者グループ
消費者はKafkaクラスターからのメッセージを読みます。 コンシューマーがメッセージを受信する準備ができると、データはブローカーからプルされます。 コンシューマーはコンシューマーグループに属し、特定のグループ内の各コンシューマーは、サブスクライブされているすべてのトピックのパーティションのサブセットを読み取る責任があります。
8.リーダーとフォロワー
すべてのKafkaパーティションには、リーダーの役割を果たす1つのサーバーがあります。 リーダーは、その特定のパーティションのすべての読み取りおよび書き込みタスクを実行します。 一方、フォロワーの仕事はリーダーのデータを複製することです。 特定のパーティションのリーダーに障害が発生すると、フォロワーノードの1つがリーダーの役割を引き受けます。 パーティションには、フォロワーがないか、多く存在する可能性があります。
次の図は、上記のApacheKafkaアーキテクチャコンポーネント間の相互関係を簡略化したものです。
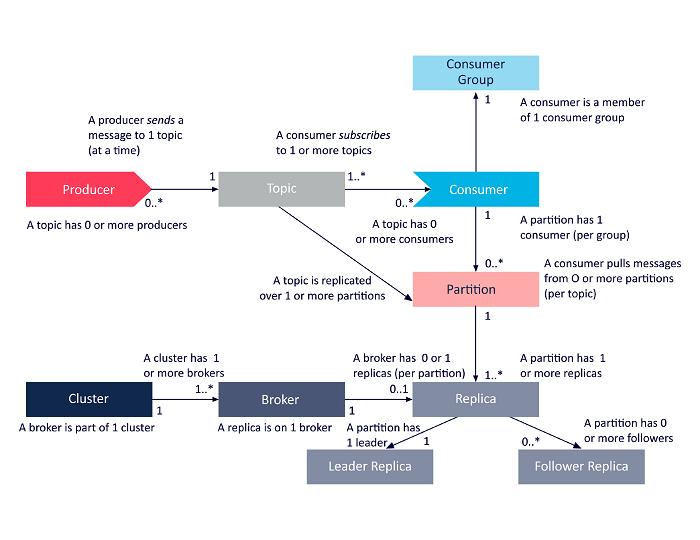

ソース
ApacheKafkaクラスターアーキテクチャ
Kafkaの主要なアーキテクチャコンポーネントの詳細は次のとおりです。
1.カフカブローカー
Kafkaクラスターには通常、ブローカーと呼ばれる複数のノードが含まれています。 ブローカーは負荷分散を維持します。 各Kafkaブローカーは、毎秒数百、数千の読み取りと書き込みを処理できます。 ブローカーは、特定の1つのパーティションのリーダーとして機能します。 リーダーには1つまたは複数のフォロワーがあり、リーダーのデータはその特定のパーティションのフォロワー間で複製されます。
フォロワーはリーダーのデータを常に最新の状態に保つ必要があります。 次に、リーダーは、リーダーと同期しているフォロワーを追跡します。 フォロワーがリーダーに追いつかないか、生きていない場合、特定のリーダーに関連付けられている同期レプリカリストからフォロワーが削除されます。 リーダーの死後、フォロワーの中から新しいリーダーが選出され、ZooKeeperが選挙を監督します。 ブローカーはステートレスであるため、ZooKeeperはクラスター状態を維持します。 クラスター内のノードは、ハートビートメッセージをZooKeeperに送信して、ZooKeeperにそれらが生きていることを通知します。
2.カフカプロデューサー
Kafkaプロデューサーは、特定のパーティションのリーダーの役割を果たすブローカーにデータを直接送信します。 Kafkaクラスターのブローカーまたはノードは、プロデューサーがダイレクトメッセージを送信するのに役立ちます。 これは、サーバーが稼働しているメタデータとトピックのパーティションリーダーのライブステータスのリクエストに応答することで実現し、プロデューサーがそれに応じてリクエストを送信できるようにします。 プロデューサーは、メッセージを公開するパーティションを決定します。 Kafkaのメッセージは、レコードバッチと呼ばれるバッチで送信されます。 プロデューサーは、メモリー内のメッセージを収集し、一定期間が経過した後、または特定の数のメッセージが蓄積された後に、それらをバッチで送信します。
3.カフカの消費者
Kafkaコンシューマーは、消費したいパーティションを示すリクエストをブローカーに発行します。 コンシューマーは、要求でパーティションオフセットを指定し、ブローカーから(オフセット位置から開始して)ログを受け取ります。 ログには、保持期間と呼ばれる構成可能な期間のレコードが含まれます。
ログにデータが含まれている限り、消費者はデータを再消費することもできます。 Kafkaのコンシューマーはプルベースのアプローチに取り組んでいます。つまり、ブローカーはデータをコンシューマーにすぐにプッシュしません。 代わりに、最初に、コンシューマーはブローカーに要求を送信して、データを消費する準備ができていることを通知します。 したがって、プルベースのシステムは、消費者がメッセージに圧倒されないようにし、遅れた場合に追いつくことができるようにします。
以下は、簡略化されたApacheKafkaアーキテクチャ図です。
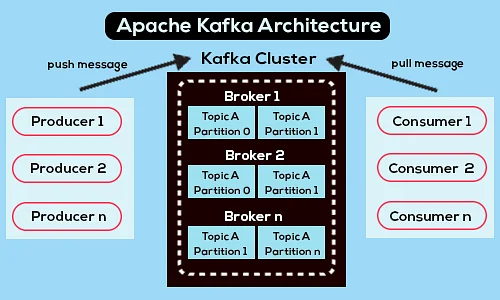
ソース
ApacheKafkaの詳細をご覧ください。
ApacheKafkaAPIアーキテクチャ
Apache Kafkaには、Streams API、Connector API、Producer API、ConsumerAPIの4つの主要なAPIがあります。 ApacheKafkaの機能を強化する上でそれぞれが果たすべき役割を見てみましょう。
1. Streams API
KafkaのStreamsAPIを使用すると、アプリケーションはストリーム処理アルゴリズムを使用してデータを処理できます。 Streams APIを使用すると、アプリケーションは1つまたは複数のトピックからの入力ストリームを消費し、ストリーム操作で処理し、出力ストリームを生成し、最終的に1つ以上のトピックに送信できます。 したがって、Streams APIは、入力ストリームから出力ストリームへの変換を容易にします。
2.コネクタAPI
KafkaのConnectorAPIは、Kafkaトピックを既存のデータシステムまたはアプリケーションに接続する再利用可能なプロデューサーとコンシューマーを構築、実行、および管理するのに役立ちます。 たとえば、リレーショナルデータベースへのコネクタは、すべての更新をキャプチャし、Kafkaトピック内で変更が利用可能であることを確認できます。

3.プロデューサーAPI
KafkaのProducerAPIを使用すると、アプリケーションはレコードのストリームをKafkaトピックに公開できます。
4.コンシューマーAPI
KafkaのコンシューマーAPIアプリケーションがKafkaトピックをサブスクライブできるようにします。 また、アプリケーションは、これらのKafkaトピックに対して生成されたレコードストリームを処理できます。
今後の方向性
Apache Kafkaアーキテクチャは、ソフトウェア開発者が扱うツールと言語の膨大なレパートリーのほんの一部にすぎません。 あなたがビッグデータに傾倒している新進のソフトウェア開発者であると仮定します。 その場合、ソフトウェア開発におけるupGradのエグゼクティブPGプログラム–ビッグデータの専門化で目標に向けた第一歩を踏み出すことができます。
プログラムの概要といくつかの重要なハイライトは次のとおりです。
- データサイエンスとクラウドインフラストラクチャの認定を受けたIIITバンガロアのエグゼクティブPGP
- 400時間以上のコンテンツを含むオンラインセッションとライブ講義
- 7つ以上のケーススタディとプロジェクト
- 14以上のプログラミング言語とツール
- 360度のキャリアサポート
- ピアと業界のネットワーキング
詳細についてはサインアップしてください コースについて!
カフカは何に使われていますか?
Apache Kafkaは主に、リアルタイムストリーミングデータパイプラインとそれらのデータストリームに適応するアプリケーションを構築するために使用されます。 メッセージング、ストレージ、およびストリーム処理の組み合わせにより、リアルタイムデータと履歴データの保存と分析の両方が可能になります。
Kafkaはフレームワークですか?
Apache Kafkaは、ストリーミングデータを保存、読み取り、分析するためのフレームワークを提供するオープンソースソフトウェアです。 Kafkaはオープンソースであるため、新しい機能、更新、および新しいユーザーのサポートに貢献する多くの開発者やユーザーと自由に使用できます。
なぜKafkaストリームが必要なのですか?
Kafka Streamsは、入力データと出力データがApacheKafkaクラスターに格納されるマイクロサービスとストリーミングアプリケーションを構築するためのクライアントライブラリです。 一方では、ApacheKafkaのサーバー側クラスターテクノロジーの利点を提供します。 一方、クライアント側での標準のScalaおよびJavaアプリケーションの作成とデプロイを簡素化します。