
Apache Kafka:アーキテクチャ、コンセプト、機能、アプリケーション
公開: 2021-03-09Kafkaは、LinkedInのおかげで2011年に発売されました。 それ以来、フォーチュン500にリストされているほとんどの企業が現在それを使用するまで、信じられないほどの成長を遂げています。 これは、大量のストリーミングデータを処理できる、拡張性が高く、耐久性があり、スループットの高い製品です。 しかし、それがその絶大な人気の背後にある唯一の理由ですか? うーん、ダメ。 その機能、それが生み出す品質、そしてそれがユーザーに提供する容易さについてさえ、私たちは始めていません。
これについては後で詳しく説明します。 まず、Kafkaとは何か、どこで使用されているかを理解しましょう。
目次
Apache Kafkaとは何ですか?
Apache Kafkaは、リアルタイムデータを管理しながら、高スループットと低遅延を実現することを目的としたオープンソースのストリーム処理ソフトウェアです。 JavaとScalaで記述されたKafkaは、メモリ内マイクロサービスを介して耐久性を提供し、CEPまたは自動化システムとしても知られる複雑なイベントストリーミングサービスへの供給イベントを維持する上で不可欠な役割を果たします。
これは非常に用途が広く、障害のない分散システムであり、Uberのような企業が乗客とドライバーのマッチングを管理できるようにします。 また、LinkedInが複数のリアルタイムサービスを追跡するのを支援するだけでなく、BritishGasのスマートホーム製品のリアルタイムデータとプロアクティブなメンテナンスも提供します。
リアルタイム分析を提供するためにリアルタイムストリーミングデータアーキテクチャでよく使用されるKafkaは、迅速で堅牢、スケーラブルなパブリッシュ/サブスクライブメッセージングシステムです。 Apache Kafkaは、優れた互換性と柔軟なアーキテクチャにより、サービスコールやIoTセンサーデータを追跡できるため、従来のMOMの代わりに使用できます。
Kafkaは、Apache Flume / Flafka、Apache Spark Streaming、Apache Storm、HBase、Apache Flink、およびApache Sparkと見事に連携して、ストリーミングデータのリアルタイムの取り込み、調査、分析、および処理を行います。 Kafkaの仲介者は、HadoopまたはSparkでの低遅延のフォローアップレポートも容易にします。 Kafkaには、リアルタイム分析の効果的なツールとして機能するKafkaStreamという名前の補助プロジェクトもあります。

Kafkaのアーキテクチャとコンポーネント
Kafkaは、リアルタイムデータを複数の受信者システムにストリーミングするために使用されます。 Kafkaは、リアルタイムデータパイプラインを分離するための中央レイヤーとして機能します。 直接計算ではあまり使用されません。 バッチデータ分析のために大量のデータをストリーミングするために、リアルタイムまたは運用データベースの高速レーン供給システムと最も互換性があります。
Storm、Flink、Spark、およびCEPフレームワークは、Kafkaがリアルタイム分析を実行し、バックアップや監査などを作成するために使用するいくつかのデータシステムです。 また、ビッグデータプラットフォームやRDBMSなどのデータベースシステム、Cassandra、Sparkなどと統合して、データサイエンスの処理、レポート作成などを行うこともできます。
次の図は、Kafkaエコシステムを示しています。
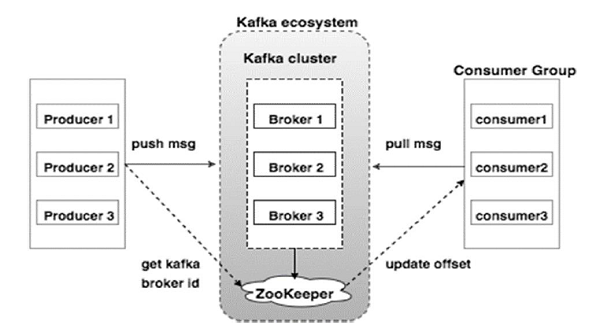
ソース
Kafkaアーキテクチャ図に示されているKafkaエコシステムのさまざまなコンポーネントは次のとおりです。
1.カフカブローカー
Kafkaは、それぞれが「ブローカー」と呼ばれる複数のサーバーで構成されるクラスターをエミュレートします。 クライアントとサーバー間の通信はすべて、高性能TCPプロトコルに準拠しています。 重い負荷を処理するために、複数のステートレスブローカーで構成されています。 単一のKafkaブローカーは、パフォーマンスを損なうことなく、毎秒数ラックの読み取りと書き込みを管理できます。 彼らはZooKeeperを使用してクラスターを維持し、ブローカーリーダーを選出します。
2. Kafka ZooKeeper
前述のように、ZooKeeperはKafkaブローカーの管理を担当しています。 Kafkaエコシステムでブローカーが新たに追加または失敗した場合は、ZooKeeperを介してプロデューサーまたはコンシューマーに通知されます。
3.カフカプロデューサー
彼らはブローカーにデータを送信する責任があります。 プロデューサーは、メッセージの受信を確認するためにブローカーに依存しません。 代わりに、ブローカーが処理できる量を決定し、それに応じてメッセージを送信します。

4.カフカの消費者
パーティションオフセットによって消費されたメッセージの数を記録するのは、Kafkaコンシューマーの責任です。 メッセージの確認は、メッセージが消費される前に送信されたことを示します。 ブローカーがコンシューマーに送信する準備ができているバイトのバッファーを確実に持つために、コンシューマーは非同期プル要求を開始します。 ZooKeeperには、メッセージのスキップまたは巻き戻しのオフセット値を維持する上で果たす役割があります。
Kafkaのメカニズムには、分散システム内のアプリケーション間でメッセージを送信することが含まれます。 Kafkaはコミットログを採用しています。コミットログは、サブスクライブすると、存在するデータをさまざまなストリーミングアプリケーションに公開します。 送信者はKafkaにメッセージを送信し、受信者はKafkaによって配信されたストリームからメッセージを受信します。
メッセージはトピックにまとめられます—Kafkaによる効果的な審議。 特定のトピックは、特定のタイプまたは分類に基づいて整理された一連のデータを表します。 プロデューサーは、トピックに基づいて、コンシューマーが読むためのメッセージを書き込みます。
すべてのトピックには一意の名前が付けられています。 送信者によって送信された特定のトピックからのメッセージは、そのトピックに同調しているすべてのユーザーによって受信されます。 公開されると、トピックのデータを更新または変更することはできません。
カフカの特徴
- Kafkaは、永続的なコミットログで構成されており、サブスクライブして、複数のシステムまたはリアルタイムアプリケーションにデータを公開できます。
- これにより、アプリケーションはそのデータが来たときにそれを制御できるようになります。 ApacheKafkaのStreamsAPIは、オンザフライのバッチデータ処理を容易にする強力で軽量なライブラリです。
- これは、ワークフローを調整し、メンテナンスの必要性を大幅に減らすことができるJavaアプリケーションです。
- Kafkaは、複数のデータシステムを介したデータ展開を可能にすることにより、複数のノードにデータを分散する「真実のストレージ」として機能します。
- Kafkaのコミットログにより、信頼性の高いストレージシステムになります。 Kafkaは、データ損失の防止に役立つパーティションのレプリカ/バックアップを作成します(適切な構成により、データ損失がゼロになる可能性があります)。 これにより、サーバーの障害が防止され、Kafkaの耐久性が向上します。
- Kafkaのトピックには数千のパーティションがあり、任意の量のデータと大量の負荷を処理できます。
- Kafkaは、データを高速で移動するためにOSカーネルに依存しています。 これらの情報のクラスターは、エンドツーエンドで暗号化され、プロデューサーからファイルシステム、そしてエンドコンシューマーになります。
- Kafkaでのバッチ処理により、データ圧縮効率が向上し、I/O遅延が減少します。
カフカの応用
毎日大量のデータを扱う多くの企業がKafkaを使用しています。

- LinkedInは、Kafkaを使用してユーザーアクティビティとパフォーマンスメトリックを追跡します。 TwitterはそれをStormと組み合わせて、ストリーム処理フレームワークを有効にします。
- SquareはKafkaを使用して、すべてのシステムイベントを他のSquareデータセンターに移動しやすくしています。 これには、ログ、カスタムイベント、およびメトリックが含まれます。
- Kafkaのメリットを利用できるその他の人気企業には、Netflix、Spotify、Uber、Tumblr、CloudFlare、PayPalなどがあります。
なぜApacheKafkaを学ぶ必要があるのですか?
Kafkaは、リアルタイムデータを効率的に処理、追跡、監視できる優れたイベントストリーミングプラットフォームです。 そのフォールトトレラントでスケーラブルなアーキテクチャにより、低遅延のデータ統合が可能になり、ストリーミングイベントのスループットが向上します。 Kafkaは、データの「価値実現までの時間」を大幅に短縮します。
データに関する「ログ」を排除することにより、組織に情報を提供する基盤システムとして機能します。 これにより、データサイエンティストやスペシャリストは、いつでも簡単に情報にアクセスできます。
これらの理由から、これは多くのトップ企業に選ばれるトップストリーミングプラットフォームであり、したがって、ApacheKafkaの資格を持つ候補者は非常に求められています。
ビッグデータであるKafkaについて詳しく知りたい場合は、upGradのビッグデータのソフトウェア開発スペシャライゼーションのPGディプロマをチェックしてください。これは、7つ以上のケーススタディとプロジェクト、および世界クラスの教員と業界の専門家による指導を提供します。 13か月のプログラムは、14のプログラミング言語をカバーし、データ処理、MapReduce、データウェアハウジング、リアルタイム処理、クラウドでのビッグデータ処理などのスキルを教えます。
upGradで他のソフトウェアエンジニアリングコースを確認してください。