
Scikitを使用した線形回帰のガイド[例付き]
公開: 2021-06-18教師あり学習アルゴリズムには、一般に2つのタイプがあります。回帰と連続および離散出力の予測による分類です。
次の記事では、Pythonの最も人気のある機械学習ライブラリの1つであるScikit-learnライブラリを使用した線形回帰とその実装について説明します。 機械学習と統計モデルのツールは、分類、回帰、クラスタリング、および次元削減のためにpythonライブラリで利用できます。 Pythonプログラミング言語で記述されたこのライブラリは、NumPy、SciPy、およびMatplotlibのPythonライブラリに基づいて構築されています。
目次
線形回帰
線形回帰は、教師あり学習法の下で回帰のタスクを実行します。 独立変数に基づいて、目標値が予測されます。 この方法は主に、変数間の関係を予測および識別するために使用されます。
代数では、線形性という用語は変数間の線形関係を意味します。 2次元空間の変数間で直線が推定されます。
線がX軸の独立変数とY軸の従属変数の間のプロットである場合、直線はデータポイントに最適な線形回帰によって達成されます。
直線の方程式は次の形式になります。

Y = mx + b
ここで、b=切片
m=線の傾き
したがって、線形回帰により、
- 切片と勾配の最適な値は、2次元で決定されます。
- x変数とy変数はデータ機能であり、したがって同じままであるため、変更はありません。
- 切片と勾配の値のみを制御できます。
- 傾きと切片の値に基づく複数の直線が存在する可能性がありますが、線形回帰のアルゴリズムにより、複数の線がデータポイントに適合され、エラーが最小の線が返されます。
Pythonによる線形回帰
Pythonで線形回帰を実装するには、適切なパッケージをその関数とクラスとともに適用する必要があります。 PythonのパッケージNumPyはオープンソースであり、単一配列と多次元配列の両方で、配列に対して複数の操作を実行できます。
Pythonで広く使用されているもう1つのライブラリは、機械学習の問題に使用されるScikit-learnです。
Scikit-learN
Scikit-learnライブラリは、教師あり学習と教師なし学習の両方に基づくアルゴリズムを開発者に提供します。 Pythonのオープンソースライブラリは、機械学習タスク用に設計されています。
データサイエンティストは、scikit-learnを使用して、データのインポート、前処理、プロット、およびデータの予測を行うことができます。
David Cournapeauは2007年に最初にscikit-learnを開発し、ライブラリは数十年以来成長を遂げてきました。
scikit-learnが提供するツールは次のとおりです。
- 回帰:ロジスティック回帰と線形回帰が含まれます
- 分類:K最近傍法を含みます
- モデルの選択
- クラスタリング:K-Means++とK-Meansの両方が含まれます
- 前処理
ライブラリの利点は次のとおりです。
- ライブラリの学習と実装は簡単です。
- これはオープンソースライブラリであるため、無料です。
- 機械学習の側面は、ディープラーニングを含めてカバーできます。
- 強力で用途の広いパッケージです。
- ライブラリには詳細なドキュメントがあります。
- 機械学習で最もよく使用されるツールキットの1つ。
scikit-learnのインポート
scikit-learnは、最初にpipまたはcondaを介してインストールする必要があります。
- 要件:ライブラリNumPyおよびScipyがインストールされた64ビットバージョンのPython3。 データプロットの視覚化にも、matplotlibが必要です。
インストールコマンド:pip install -U scikit-learn
次に、インストールが完了したかどうかを確認します
Numpy、Scipy、およびmatplotlibのインストール
インストールは次の方法で確認できます。
ソース
Scikit-learnによる線形回帰
パッケージscikit-learnによる線形回帰の実装には、次の手順が含まれます。
- 必要なパッケージとクラスをインポートする必要があります。
- データは、適切な変換を処理し、実行するために必要です。
- 回帰モデルを作成し、既存のデータに適合させます。
- 作成されたモデルが満足のいくものであるかどうかを分析するために、モデルフィッティングデータをチェックする必要があります。
- 予測は、モデルの適用を通じて行われます。
パッケージNumPyとクラスLinearRegressionは、sklearn.linear_modelからインポートされます。

ソース
sklearn線形回帰に必要な機能はすべて、最終的に線形回帰を実装するために存在します。 sklearn.linear_model.LinearRegressionクラスは、回帰分析(線形および多項式の両方)の実行と予測の実行に使用されます。
機械学習アルゴリズムとscikitlearn線形回帰の場合、最初にデータセットをインポートする必要があります。 Scikitでは3つのオプションが利用可能です-データを取得する方法を学びます:
- アイリス分類やボストンの住宅価格の回帰のセットなどのデータセット。
- 実世界のデータセットは、Scikit-learnの事前定義された関数を介してインターネットから直接ダウンロードできます。
- Scikit-learnデータジェネレーターを使用して、特定のパターンと照合するためのデータセットをランダムに生成できます。
どのオプションを選択した場合でも、モジュールデータセットをインポートする必要があります。

sklearn.datasetsをデータセットとしてインポートする
1.アイリスの分類セット
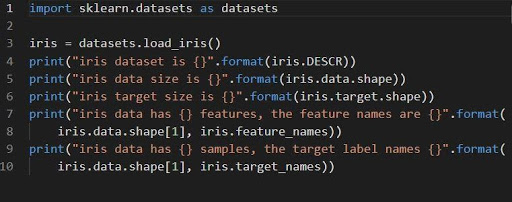
iris =datasets.load_iris()
データセットアイリスは、n_samples*n_featuresの2D配列データフィールドとして保存されます。 そのインポートは、辞書のオブジェクトとして実行されます。 メタデータとともに必要なすべてのデータが含まれています。
関数DESCR、shape、および_namesを使用して、データの説明とフォーマットを取得できます。 関数の結果を印刷すると、アイリスデータセットでの作業中に必要になる可能性のあるデータセットの情報が表示されます。
次のコードは、アイリスデータセットの情報をロードします。
ソース
2.回帰データの生成
組み込みデータの要件がない場合は、選択可能な分布を介してデータを生成できます。
1つの有益な機能と1つの機能のセットを使用して回帰のデータを生成します。
X、Y =datasets.make_regression(n_features = 1、n_informative = 1)
生成されたデータは、オブジェクトxおよびyとともに2Dデータセットに保存されます。 生成されたデータの特性は、関数make_regressionのパラメーターを変更することで変更できます。
この例では、有益な機能と機能のパラメーターがデフォルト値の10から1に変更されています。
考慮される他のパラメーターは、追跡されるターゲットとサンプル変数の数が制御されるサンプルとターゲットです。
- MLのアルゴリズムに有用な情報を提供する機能は有益な機能と呼ばれ、役に立たない機能は有益な機能と呼ばれます。
3.データのプロット
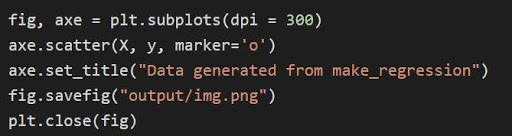
データはmatplotlibライブラリを使用してプロットされます。 まず、matplotlibをインポートする必要があります。
matplotlib.pyplotをpltとしてインポートします
上記のグラフは、コードを介してmatplotlibを介してプロットされています
ソース
上記のコードでは:
- タプル変数は解凍され、コードの1行目に個別の変数として保存されます。 したがって、個別の属性を操作して保存することができます。
- データセットx、yは、線2を通る散布図を生成するために使用されます。matplotlibでマーカーパラメーターを使用できるため、データポイントをドット(o)でマークすることにより、ビジュアルが強化されます。
- 生成されたプロットのタイトルは、3行目で設定されます。
- フィギュアは.png画像ファイルとして保存でき、現在のフィギュアを閉じます。
上記のコードによって生成された回帰プロットは次のとおりです。
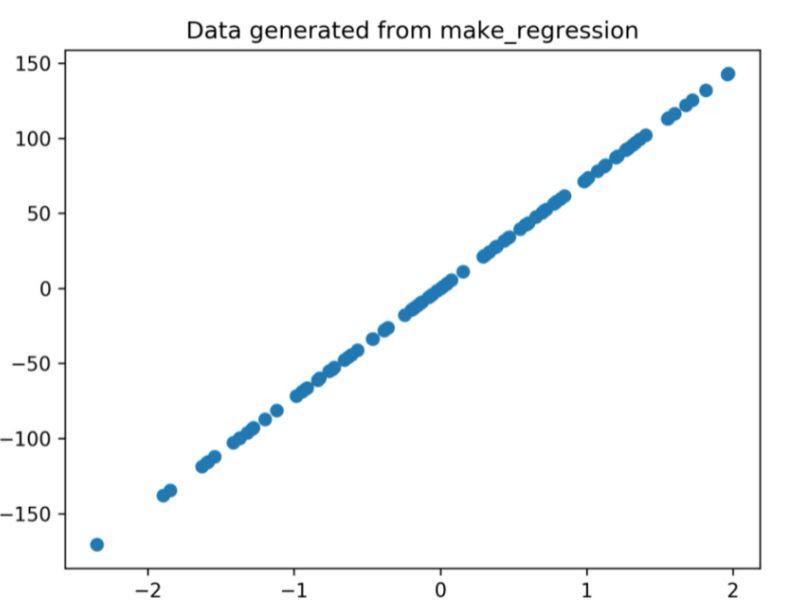
図1:上記のコードから生成された回帰プロット。
4.線形回帰のアルゴリズムの実装
ボストンの住宅価格のサンプルデータを使用して、 Scikit-learn線形回帰のアルゴリズムを次の例で実装します。 他のMLアルゴリズムと同様に、データセットがインポートされ、前のデータを使用してトレーニングされます。
線形回帰法は、数値とその変数と出力値との関係を予測する予測モデルであり、実際に値を持つことを意味するため、企業で使用されています。
以前のデータのログが存在する場合、パターンの継続がある場合に将来何が起こるかについての将来の結果を予測できるため、モデルを最適に適用できます。
数学的には、データポイントと予測値の間に存在するすべての残差の合計を最小化するためにデータを適合させることができます。
次のスニペットは、 sklearn線形回帰の実装を示しています。
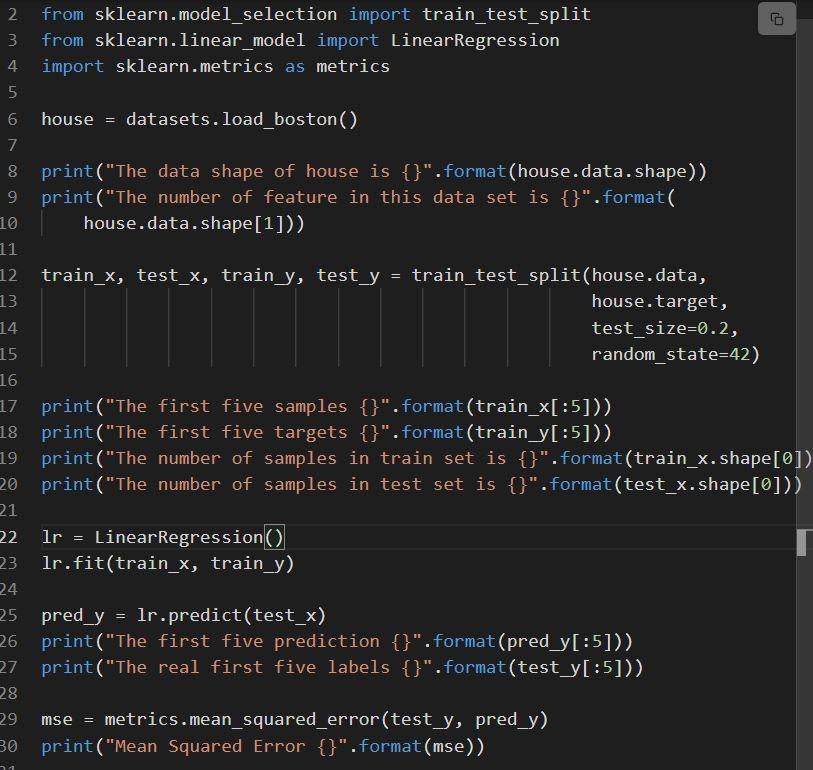
ソース
コードは次のように説明されています。
- 6行目は、load_bostonというデータセットをロードします。
- データセットは12行目に分割されています。つまり、80%のデータを含むトレーニングセットと20%のデータを含むテストのセットです。
- 23行目で線形回帰のモデルを作成し、でトレーニングしました。
- モデルのパフォーマンスは、mean_squared_errorを呼び出すことによってリネン29で評価されます。
sklearn線形回帰プロットを以下に示します。
ボストンの住宅価格サンプルデータの線形回帰モデル
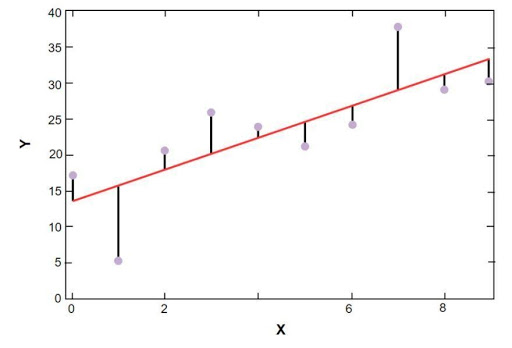
ソース
上の図で、赤い線はボストンの住宅価格のサンプルデータに対して解かれた線形モデルを表しています。 青い点は元のデータを表し、赤い線と青い点の間の距離は残差の合計を表します。 scikit-learn線形回帰モデルの目標は、残差の合計を減らすことです。
結論
この記事では、scikit-learnと呼ばれるオープンソースのPythonパッケージを使用した線形回帰とその実装について説明しました。 これで、このパッケージを介して線形回帰を実装する方法の概念を理解できるようになりました。 データ分析にライブラリを使用する方法を学ぶことは価値があります。
機械学習でのPythonパッケージの実装や、AI関連の問題など、トピックをさらに詳しく調べることに興味がある場合は、 upGradが提供する機械学習とAIの科学のマスターコースを確認できます。 このコースは、21〜45歳の初級レベルの専門家を対象としており、650時間以上のオンライントレーニング、25以上のケーススタディ、および課題を通じて、機械学習の学生をトレーニングすることを目的としています。 LJMUの認定を受けたこのコースは、完璧なガイダンスと就職支援を提供します。 ご不明な点やご質問がございましたら、メッセージを残していただければ、喜んでご連絡いたします。