
Was ist maschinelles Lernen mit Java? Wie wird es implementiert?
Veröffentlicht: 2021-03-10Inhaltsverzeichnis
Was ist maschinelles Lernen?
Maschinelles Lernen ist ein Bereich der künstlichen Intelligenz, der aus verfügbaren Daten, Beispielen und Erfahrungen lernt, um menschliches Verhalten und menschliche Intelligenz nachzuahmen. Ein mit maschinellem Lernen erstelltes Programm kann selbst Logik erstellen, ohne dass ein Mensch den Code manuell schreiben muss.
Alles begann mit dem Turing-Test in den frühen 1950er Jahren, als Alan Turning zu dem Schluss kam, dass ein Computer, um wirklich intelligent zu sein, einen Menschen manipulieren oder davon überzeugen muss, dass er auch ein Mensch ist. Maschinelles Lernen ist ein relativ altes Konzept, aber erst heute wird dieses aufstrebende Gebiet realisiert, da Computer jetzt komplexe Algorithmen verarbeiten können. Algorithmen für maschinelles Lernen haben sich in den letzten zehn Jahren dahingehend weiterentwickelt, dass sie komplexe Rechenfähigkeiten beinhalten, was wiederum zu einer Verbesserung ihrer Nachahmungsfähigkeiten geführt hat.
Auch Anwendungen für maschinelles Lernen haben alarmierend zugenommen. Von Gesundheitswesen, Finanzen, Analytik und Bildung bis hin zu Fertigung, Marketing und Regierungsbetrieben hat jede Branche nach der Implementierung von Technologien für maschinelles Lernen einen erheblichen Qualitäts- und Effizienzschub erlebt. Weltweit gab es weit verbreitete qualitative Verbesserungen, was die Nachfrage nach Fachleuten für maschinelles Lernen ankurbelte.
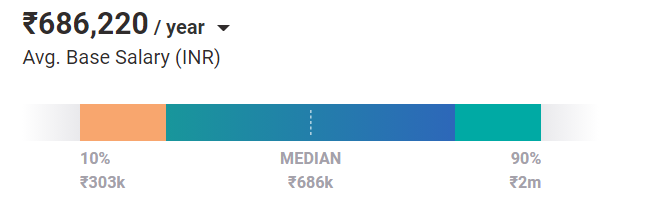
Im Durchschnitt verdienen Ingenieure für maschinelles Lernen heute 686.220 ₹/Jahr. Und das gilt für eine Einstiegsposition. Mit Erfahrung und Fähigkeiten können sie in Indien bis zu 2 Mio. £/Jahr verdienen.
Arten von Algorithmen für maschinelles Lernen
Es gibt drei Arten von Algorithmen für maschinelles Lernen:
1. Überwachtes Lernen : Bei dieser Art des Lernens leiten Trainingsdatensätze einen Algorithmus, um genaue Vorhersagen oder analytische Entscheidungen zu treffen. Es nutzt das Lernen aus früheren Trainingsdatensätzen, um neue Daten zu verarbeiten. Hier sind einige Beispiele für Modelle des überwachten maschinellen Lernens:

- Lineare Regression
- Logistische Regression
- Entscheidungsbaum
2. Unüberwachtes Lernen : Bei dieser Art des Lernens lernt ein maschinelles Lernmodell aus unbeschrifteten Informationen. Es verwendet Daten-Clustering, indem es Objekte gruppiert oder die Beziehung zwischen ihnen versteht oder ihre statistischen Eigenschaften zur Durchführung von Analysen ausnutzt. Beispiele für unüberwachte Lernalgorithmen sind:
- K-bedeutet Clustering
- Hierarchisches Clustering
3. Reinforcement Learning : Dieser Prozess basiert auf Hit and Trial. Es ist Lernen durch Interaktion mit dem Raum oder einer Umgebung. Ein RL-Algorithmus lernt aus seinen vergangenen Erfahrungen, indem er mit der Umgebung interagiert und die beste Vorgehensweise bestimmt.
Wie implementiert man maschinelles Lernen mit Java?
Java gehört zu den Top-Programmiersprachen, die für die Implementierung von Algorithmen für maschinelles Lernen verwendet werden. Die meisten seiner Bibliotheken sind Open Source und bieten umfassende Dokumentationsunterstützung, einfache Wartung, Marktfähigkeit und einfache Lesbarkeit.
Abhängig von der Popularität sind hier die Top 10 der maschinellen Lernbibliotheken, die zur Implementierung des maschinellen Lernens in Java verwendet werden.
1. Adams
Advanced-Data Mining And Machine Learning System oder ADAMS befasst sich mit dem Aufbau neuartiger und flexibler Workflow-Systeme und der Verwaltung komplexer realer Prozesse. ADAMS verwendet eine baumartige Architektur, um den Datenfluss zu verwalten, anstatt manuelle Eingabe-Ausgabe-Verbindungen herzustellen.
Es eliminiert jegliche Notwendigkeit für explizite Verbindungen. Es basiert auf dem „Weniger ist mehr“-Prinzip und führt Abruf, Visualisierung und datengesteuerte Visualisierungen durch. ADAMS ist versiert in Datenverarbeitung, Datenstreaming, Datenbankverwaltung, Scripting und Dokumentation.
2. JavaML
JavaML bietet eine Vielzahl von ML- und Data-Mining-Algorithmen, die für Java geschrieben wurden, um Softwareingenieure, Programmierer, Datenwissenschaftler und Forscher zu unterstützen. Jeder Algorithmus hat eine gemeinsame Schnittstelle, die einfach zu verwenden ist und umfangreiche Dokumentationsunterstützung bietet, obwohl es keine GUI gibt.
Es ist im Vergleich zu anderen Clustering-Algorithmen ziemlich einfach und unkompliziert zu implementieren. Zu den Kernfunktionen gehören Datenmanipulation, Dokumentation, Datenbankverwaltung, Datenklassifizierung, Clustering, Funktionsauswahl und so weiter.
Nehmen Sie online am Machine Learning-Kurs der weltbesten Universitäten teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
3. WEKA
Weka ist auch eine für Java geschriebene Open-Source-Bibliothek für maschinelles Lernen, die Deep Learning unterstützt. Es bietet eine Reihe von Algorithmen für maschinelles Lernen und findet neben anderen Datenoperationen umfangreiche Anwendung in Data Mining, Datenaufbereitung, Datenclustering, Datenvisualisierung und Regression.
Beispiel: Wir demonstrieren dies anhand eines kleinen Diabetes-Datensatzes.
Schritt 1 : Laden Sie die Daten mit Weka
| weka.core.Instanzen importieren; import weka.core.converters.ConverterUtils.DataSource; öffentliche Klasse Main { public static void main(String[] args) löst Exception { // Angabe der Datenquelle Datenquelle dataSource = neue Datenquelle („data.arff“); // Laden des Datensatzes Instanzen dataInstances = dataSource.getDataSet(); // Anzeige der Anzahl der Instanzen log.info(“Die Anzahl der geladenen Instanzen ist: ” + dataInstances.numInstances()); log.info(“data:” + dataInstances.toString()); } } |
Schritt 2: Der Datensatz hat 768 Instanzen. Wir müssen auf die Anzahl der Attribute zugreifen, dh 9.
| log.info(“Die Anzahl der Attribute (Merkmale) im Datensatz: ” + dataInstances.numAttributes()); |
Schritt 3 : Wir müssen die Zielspalte bestimmen, bevor wir ein Modell erstellen und die Anzahl der Klassen finden.
| // Identifizieren des Label-Index dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // Abrufen der Anzahl von log.info(“Die Anzahl der Klassen: ” + dataInstances.numClasses()); |
Schritt 4 : Wir werden nun das Modell mit einem einfachen Baumklassifikator, J48, erstellen.
| // Einen Entscheidungsbaumklassifizierer erstellen J48 treeClassifier = new J48(); treeClassifier.setOptions(new String[] { „-U“ }); treeClassifier.buildClassifier (dataInstances); |
Der obige Code zeigt, wie ein nicht beschnittener Baum erstellt wird, der aus den Dateninstanzen besteht, die für das Modelltraining erforderlich sind. Sobald die Baumstruktur nach dem Modelltraining gedruckt ist, können wir feststellen, wie die Regeln intern aufgebaut wurden.
| plas <= 127 | Masse <= 26,4 | | schwanger <= 7: getestet_negativ (117,0/1,0) | | Schwangerschaft > 7 | | | Masse <= 0: getestet_positiv (2,0) | | | Masse > 0: getestet_negativ (13,0) | Masse > 26,4 | | Alter <= 28: getestet_negativ (180,0/22,0) | | Alter > 28 | | | Plas <= 99: getestet_negativ (55,0/10,0) | | | Plas > 99 | | | | Kinder <= 0,56: getestet_negativ (84,0/34,0) | | | | pedi > 0,56 | | | | | Schwangerschaft <= 6 | | | | | | Alter <= 30: getestet_positiv (4,0) | | | | | | Alter > 30 | | | | | | | Alter <= 34: getestet_negativ (7,0/1,0) | | | | | | | Alter > 34 | | | | | | | | Masse <= 33,1: getestet_positiv (6,0) | | | | | | | | Masse > 33,1: getestet_negativ (4,0/1,0) | | | | | Schwangerschaft > 6: getestet_positiv (13,0) Plas > 127 | Masse <= 29,9 | | Plas <= 145: getestet_negativ (41,0/6,0) | | Plas > 145 | | | Alter <= 25: getestet_negativ (4,0) | | | Alter > 25 | | | | Alter <= 61 | | | | | Masse <= 27,1: getestet_positiv (12,0/1,0) | | | | | Masse > 27,1 | | | | | | <= 82 drücken | | | | | | | Kinder <= 0,396: getestet_positiv (8,0/1,0) | | | | | | | pedi > 0,396: getestet_negativ (3,0)  | | | | | | Druck > 82: getestet_negativ (4,0) | | | | Alter > 61: getestet_negativ (4,0) | Masse > 29,9 | | plas <= 157 | | | press <= 61: getestet_positiv (15,0/1,0) | | | drücken Sie > 61 | | | | Alter <= 30: getestet_negativ (40,0/13,0) | | | | Alter > 30: getestet_positiv (60,0/17,0) | | plas > 157: getestet_positiv (92,0/12,0) Anzahl der Blätter: 22 Größe des Baumes: 43 |
4. Apache Mahaut
Mahaut ist eine Sammlung von Algorithmen zur Implementierung von maschinellem Lernen mit Java. Es ist ein skalierbares Framework für lineare Algebra, mit dem Entwickler Mathematik und Statistiker Analysen durchführen können. Es wird normalerweise von Datenwissenschaftlern, Forschungsingenieuren und Analyseexperten verwendet, um unternehmenstaugliche Anwendungen zu erstellen. Seine Skalierbarkeit und Flexibilität ermöglicht es Benutzern, schnell und einfach Daten-Clustering und Empfehlungssysteme zu implementieren und leistungsstarke Apps für maschinelles Lernen zu erstellen.
5. Tiefes Lernen4j
Deeplearning4j ist eine Programmierbibliothek, die in Java geschrieben ist und umfangreiche Unterstützung für Deep Learning bietet. Es ist ein Open-Source-Framework, das Deep Neural Networks und Deep Reinforcement Learning kombiniert, um den Geschäftsbetrieb zu unterstützen. Es ist kompatibel mit Scala, Kotlin, Apache Spark, Hadoop und anderen JVM-Sprachen und Big-Data-Computing-Frameworks.
Es wird normalerweise verwendet, um Muster und Emotionen in Stimme, Sprache und geschriebenem Text zu erkennen. Es dient als DIY-Tool, das Diskrepanzen in Transaktionen erkennen und mehrere Aufgaben erledigen kann. Es handelt sich um eine kommerzielle, verteilte Bibliothek, die aufgrund ihrer Open-Source-Natur über eine detaillierte API-Dokumentation verfügt.
Hier ist ein Beispiel dafür, wie Sie maschinelles Lernen mit Deeplearning4j implementieren können.
Beispiel : Mit Deeplearning4j werden wir ein Convolution Neural Network (CNN)-Modell erstellen, um die handschriftlichen Ziffern mit Hilfe der MNIST-Bibliothek zu klassifizieren.
Schritt 1 : Laden Sie den Datensatz, um seine Größe anzuzeigen.
| DataSetIterator MNISTTrain = new MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = new MnistDataSetIterator(batchSize,false,seed); |
Schritt 2 : Stellen Sie sicher, dass der Datensatz uns zehn eindeutige Labels gibt.
| log.info(“Die Gesamtanzahl der im Trainingsdatensatz gefundenen Labels ” + MNISTTrain.totalOutcomes()); log.info(“Die Gesamtanzahl der im Testdatensatz gefundenen Labels” + MNISTTest.totalOutcomes()); |
Schritt 3 : Jetzt konfigurieren wir die Modellarchitektur mit zwei Faltungsschichten zusammen mit einer abgeflachten Schicht, um die Ausgabe anzuzeigen.
Es gibt Optionen in Deeplearning4j, mit denen Sie das Gewichtsschema initialisieren können.
| // Erstellen des CNN-Modells MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) // Zufallsstartwert .l2(0.0005) // Regularisierung .weightInit(WeightInit.XAVIER) // Initialisierung des Gewichtsschemas .updater(new Adam(1e-3)) // Einstellen des Optimierungsalgorithmus .Liste() .layer(neu ConvolutionLayer.Builder(5, 5) //Festlegen der Schrittweite, der Kernelgröße und der Aktivierungsfunktion. .nIn(nKanäle) .schritt(1,1) .nAus(20) .activation(Aktivierung.IDENTITÄT) .bauen()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // Downsampling der Faltung .kernelSize(2,2) .schritt(2,2) .bauen()) .layer(neu ConvolutionLayer.Builder(5, 5) // Schrittweite, Kernelgröße und Aktivierungsfunktion festlegen. .schritt(1,1) .nAus(50) .activation(Aktivierung.IDENTITÄT) .bauen()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // Downsampling der Faltung .kernelSize(2,2) .schritt(2,2) .bauen()) .layer(neuer DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(Ausgangsnummer) .activation(Aktivierung.SOFTMAX) .bauen()) // Die letzte Ausgabeebene ist 28×28 mit einer Tiefe von 1. .setInputType(InputType.convolutionalFlat(28,28,1)) .bauen(); |
Schritt 4 : Nachdem wir die Architektur konfiguriert haben, initialisieren wir den Modus und den Trainingsdatensatz und beginnen mit dem Modelltraining.
| MultiLayerNetwork-Modell = new MultiLayerNetwork(conf); // Modellgewichte initialisieren. model.init(); log.info(“Schritt 2: Training des Modells starten”); //Setzen eines Listeners alle 10 Iterationen und Auswerten des Testsets für jede Epoche model.setListeners(neuer ScoreIterationListener(10), neuer EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // Training des Modells model.fit(MNISTTrain, nEpochen); |
Wenn das Modelltraining beginnt, haben Sie die Konfusionsmatrix der Klassifikationsgenauigkeit.
Hier ist die Genauigkeit des Modells nach zehn Trainingsepochen:
| ========================Verwirrungsmatrix======================= == 0 1 2 3 4 5 6 7 8 9 ————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. ELKI
Umgebung für die Entwicklung von KDD-Anwendungen unterstützt durch Index-Struktur oder ELKI ist eine Sammlung von eingebauten Algorithmen und Programmen, die für das Data-Mining verwendet werden. Es ist in Java geschrieben und eine Open-Source-Bibliothek, die hochgradig konfigurierbare Parameter in Algorithmen umfasst. Es wird in der Regel von Forschern und Studenten verwendet, um Einblicke in Datensätze zu erhalten. Wie der Name schon sagt, bietet es eine Umgebung für die Entwicklung anspruchsvoller Data-Mining-Programme und Datenbanken unter Verwendung einer Indexstruktur.
7. JSAT
Java Statistical Analysis Tool oder JSAT ist eine GPL3-Bibliothek, die ein objektorientiertes Framework verwendet, um Benutzern bei der Implementierung von maschinellem Lernen mit Java zu helfen. Es wird in der Regel von Studenten und Entwicklern zu Selbstbildungszwecken verwendet. Im Vergleich zu anderen KI-Implementierungsbibliotheken hat JSAT die höchste Anzahl an ML-Algorithmen und ist das schnellste aller Frameworks. Ohne externe Abhängigkeiten ist es hochflexibel und effizient und bietet eine hohe Leistung.
8. Das Encog-Framework für maschinelles Lernen
Encog ist in Java und C# geschrieben und umfasst Bibliotheken, die bei der Implementierung von Algorithmen für maschinelles Lernen helfen. Es wird zum Erstellen von genetischen Algorithmen, Bayes'schen Netzwerken, statistischen Modellen wie dem Hidden-Markov-Modell und mehr verwendet.
9. Hammer
Machine Learning for Language Toolkit oder Mallet wird in der Verarbeitung natürlicher Sprache (NLP) verwendet. Wie die meisten anderen ML-Implementierungsframeworks bietet Mallet auch Unterstützung für Datenmodellierung, Datenclustering, Dokumentenverarbeitung, Dokumentenklassifizierung und so weiter.
10. Spark-MLlib
Spark MLlib wird von Unternehmen verwendet, um die Effizienz und Skalierbarkeit des Workflow-Managements zu verbessern. Es verarbeitet große Datenmengen und unterstützt stark ausgelastete ML-Algorithmen.
Kasse: Projektideen für maschinelles Lernen
Fazit
Damit sind wir am Ende des Artikels angelangt. Für weitere Informationen zu Konzepten des maschinellen Lernens wenden Sie sich über das Programm „Master of Science in Machine Learning & AI“ von upGrad an die Spitzenfakultät des IIIT Bangalore und der Liverpool John Moores University.
Warum sollten wir Java zusammen mit maschinellem Lernen verwenden?
Fachleute für maschinelles Lernen werden es einfacher finden, sich mit aktuellen Code-Repositories zu verbinden, wenn sie Java als Programmiersprache für ihre Projekte wählen. Aufgrund von Funktionen wie Benutzerfreundlichkeit, Paketdiensten, besserer Benutzerinteraktion, schneller Fehlerbehebung und grafischer Darstellung von Daten ist es eine bevorzugte Sprache für maschinelles Lernen. Java macht es Entwicklern von maschinellem Lernen leicht, ihre Systeme zu skalieren, was es zu einer ausgezeichneten Wahl für die Erstellung großer, anspruchsvoller maschineller Lernanwendungen von Grund auf macht. Java Virtual Machine (JVM) unterstützt eine Reihe integrierter Entwicklungsumgebungen (IDEs), mit denen maschinell Lernende schnell neue Tools entwerfen können.
Ist das Erlernen von Java einfach?
Da Java eine Hochsprache ist, ist es einfach zu verstehen. Als Lernender müssen Sie nicht so sehr ins Detail gehen, da es sich um eine gut strukturierte, objektorientierte Sprache handelt, die für Anfänger einfach genug ist, um sie zu erlernen. Da es zahlreiche Abläufe gibt, die automatisch ablaufen, können Sie diese schnell beherrschen. Sie müssen nicht ins Detail gehen, wie die Dinge dort funktionieren. Java ist eine plattformunabhängige Programmiersprache. Es ermöglicht einem Programmierer, eine mobile Anwendung zu erstellen, die auf jedem Gerät verwendet werden kann. Es ist die bevorzugte Sprache des Internets der Dinge und das beste Werkzeug für die Entwicklung von Anwendungen auf Unternehmensebene.
Was ist ADAMS und wie ist es beim maschinellen Lernen hilfreich?
Das Advanced Data Mining And Machine Learning System (ADAMS) ist eine GPLv3-lizenzierte Workflow-Engine zum schnellen Erstellen und Verwalten von datengesteuerten, reaktiven Workflows, die problemlos in Geschäftsprozesse integriert werden können. Das Herzstück von ADAMS ist die Workflow-Engine, die dem Prinzip weniger ist mehr folgt. ADAMS verwendet eine baumartige Struktur, anstatt es dem Benutzer zu ermöglichen, Operatoren (oder Akteure im ADAMS-Jargon) auf einer Leinwand anzuordnen und dann Eingaben und Ausgaben manuell zu verknüpfen. Es sind keine expliziten Verbindungen erforderlich, da diese Struktur und die Kontrollakteure bestimmen, wie die Daten im Prozess fließen. Die interne Objektdarstellung und die Verschachtelung von Unteroperatoren innerhalb von Operatorhandlern führen zu einer baumartigen Struktur. ADAMS bietet eine Vielzahl von Agenten für den Abruf, die Verarbeitung, das Mining und die Anzeige von Daten.