
Was ist ein Entscheidungsbaum im Data Mining? Typen, Beispiele und Anwendungen aus der Praxis
Veröffentlicht: 2021-06-15Inhaltsverzeichnis
Einführung in das Data-Mining
Daten liegen oft als Rohdaten vor, die effektiv verarbeitet werden müssen, um sie in nützliche Informationen umzuwandeln. Die Vorhersage der Ergebnisse beruht oft auf dem Prozess, Muster, Anomalien oder Korrelationen innerhalb der Daten zu finden. Der Prozess wurde als „Knowledge Discovery in Databases“ bezeichnet.
Erst in den 1990er Jahren wurde der Begriff „Data Mining“ geprägt. Data Mining wurde in drei Disziplinen gegründet: Statistik, künstliche Intelligenz und maschinelles Lernen. Automatisiertes Data Mining hat den Analyseprozess von einem langwierigen zu einem schnelleren Ansatz verlagert. Data Mining ermöglicht es dem Benutzer
- Entfernen Sie alle verrauschten und chaotischen Daten
- Verstehen Sie die relevanten Daten und nutzen Sie sie für die Vorhersage nützlicher Informationen.
- Der Prozess der Vorhersage fundierter Entscheidungen wird beschleunigt .
Data Mining kann auch als der Prozess der Identifizierung verborgener Informationsmuster bezeichnet werden, die einer Kategorisierung bedürfen. Erst dann können die Daten in Nutzdaten umgewandelt werden. Die nützlichen Daten können in ein Data Warehouse, Data-Mining-Algorithmen und Datenanalysen zur Entscheidungsfindung eingespeist werden.
Entscheidungsbaum im Data Mining
Der Entscheidungsbaum im Data Mining ist eine Art Data-Mining-Technik und erstellt ein Modell zur Klassifizierung von Daten. Die Modelle sind in Form der Baumstruktur aufgebaut und gehören damit zur überwachten Lernform. Anders als die Klassifizierungsmodelle werden Entscheidungsbäume zum Erstellen von Regressionsmodellen zum Vorhersagen von Klassenbezeichnungen oder Werten verwendet, die den Entscheidungsprozess unterstützen. Sowohl die numerischen als auch die kategorialen Daten wie Geschlecht, Alter usw. können von einem Entscheidungsbaum verwendet werden.
Aufbau eines Entscheidungsbaums
Die Struktur eines Entscheidungsbaums besteht aus einem Wurzelknoten, Zweigen und Blattknoten. Die verzweigten Knoten sind die Ergebnisse eines Baums und die internen Knoten repräsentieren den Test auf ein Attribut. Die Blattknoten repräsentieren eine Klassenbezeichnung.
Arbeiten eines Entscheidungsbaums
1. Ein Entscheidungsbaum funktioniert nach dem Ansatz des überwachten Lernens sowohl für diskrete als auch für kontinuierliche Variablen. Der Datensatz wird auf der Grundlage des wichtigsten Attributs des Datensatzes in Teilmengen aufgeteilt. Die Identifizierung des Attributs und die Aufteilung erfolgt durch die Algorithmen.
2. Die Struktur des Entscheidungsbaums besteht aus dem Wurzelknoten, der der signifikante Prädiktorknoten ist. Der Aufteilungsprozess erfolgt von den Entscheidungsknoten, die die Unterknoten des Baums sind. Die Knoten, die sich nicht weiter teilen, werden als Blatt- oder Endknoten bezeichnet.
3. Der Datensatz wird nach einem Top-down-Ansatz in homogene und nicht überlappende Regionen unterteilt. Die oberste Schicht stellt die Beobachtungen an einer einzigen Stelle bereit, die sich dann in Zweige aufteilt. Der Prozess wird als „Greedy Approach“ bezeichnet, da er sich nur auf den aktuellen Knoten und nicht auf die zukünftigen Knoten konzentriert.
4. Solange kein Stoppkriterium erreicht ist, läuft der Entscheidungsbaum weiter.
5. Beim Aufbau eines Entscheidungsbaums werden viel Rauschen und Ausreißer erzeugt. Um diese Ausreißer und verrauschten Daten zu entfernen, wird eine Methode des „Tree Pruning“ angewendet. Dadurch erhöht sich die Genauigkeit des Modells.
6. Die Genauigkeit eines Modells wird auf einem Testsatz überprüft, der aus Testtupeln und Klassenetiketten besteht. Ein genaues Modell wird basierend auf den Prozentsätzen von Klassifikationstestset-Tupeln und -Klassen durch das Modell definiert.
Abbildung 1 : Ein Beispiel für einen unbeschnittenen und einen beschnittenen Baum
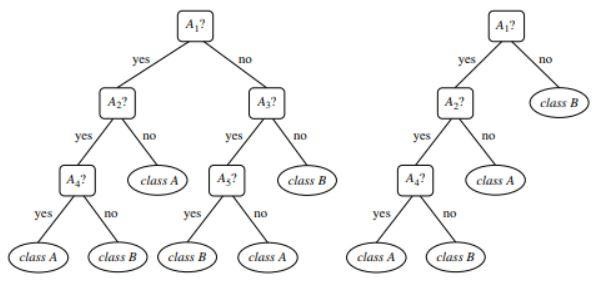
Quelle
Arten von Entscheidungsbäumen
Entscheidungsbäume führen zur Entwicklung von Modellen zur Klassifikation und Regression basierend auf einer baumartigen Struktur. Die Daten werden in kleinere Teilmengen zerlegt. Das Ergebnis eines Entscheidungsbaums ist ein Baum mit Entscheidungsknoten und Blattknoten. Im Folgenden werden zwei Arten von Entscheidungsbäumen erläutert:
1. Klassifizierung
Die Klassifikation beinhaltet den Aufbau von Modellen, die wichtige Klassenbezeichnungen beschreiben. Sie werden in den Bereichen maschinelles Lernen und Mustererkennung eingesetzt. Entscheidungsbäume beim maschinellen Lernen durch Klassifizierungsmodelle führen zur Betrugserkennung, medizinischen Diagnose usw. Der zweistufige Prozess eines Klassifizierungsmodells umfasst:
- Lernen: Ein Klassifizierungsmodell basierend auf den Trainingsdaten wird erstellt.
- Klassifizierung: Die Modellgenauigkeit wird überprüft und dann zur Klassifizierung der neuen Daten verwendet. Klassenbezeichnungen haben die Form diskreter Werte wie „Ja“ oder „Nein“ usw.
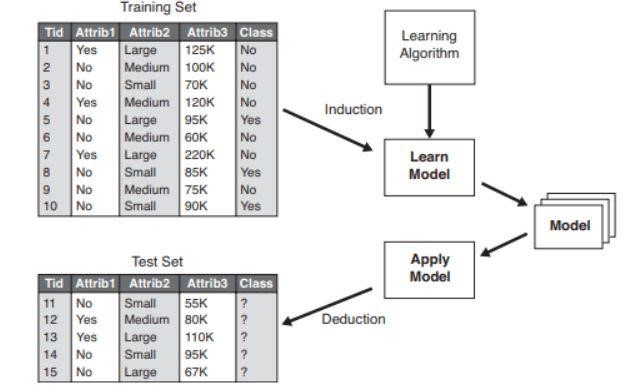
Abbildung 2 : Beispiel eines Klassifikationsmodells .
Quelle
2. Rückschritt
Regressionsmodelle dienen der Regressionsanalyse von Daten, also der Vorhersage numerischer Eigenschaften. Diese werden auch kontinuierliche Werte genannt. Anstatt die Klassenbezeichnungen vorherzusagen, sagt das Regressionsmodell daher die kontinuierlichen Werte voraus.
Liste der verwendeten Algorithmen
Ein als „ID3“ bekannter Entscheidungsbaumalgorithmus wurde 1980 von einem Maschinenforscher namens J. Ross Quinlan entwickelt. Dieser Algorithmus wurde von anderen Algorithmen wie dem von ihm entwickelten C4.5 abgelöst. Beide Algorithmen wendeten den Greedy-Ansatz an. Der Algorithmus C4.5 verwendet kein Backtracking und die Bäume werden in einer rekursiven „Divide and Conquer“-Methode von oben nach unten konstruiert. Der Algorithmus verwendete einen Trainingsdatensatz mit Klassenbezeichnungen, die beim Erstellen des Baums in kleinere Teilmengen unterteilt werden.
- Anfänglich werden drei Parameter ausgewählt – Attributliste, Attributauswahlverfahren und Datenpartition. Attribute des Trainingssatzes werden in der Attributliste beschrieben.
- Das Zuordnungsauswahlverfahren umfasst das Verfahren zur Auswahl des besten Attributs zur Unterscheidung unter den Tupeln.
- Eine Baumstruktur hängt von der Attributauswahlmethode ab.
- Die Konstruktion eines Baums beginnt mit einem einzelnen Knoten.
- Das Aufteilen der Tupel tritt auf, wenn unterschiedliche Klassenbezeichnungen in einem Tupel dargestellt werden. Dies führt zur Verzweigung des Baumes.
- Die Aufteilungsmethode bestimmt, welches Attribut für die Datenpartition ausgewählt werden sollte. Basierend auf dieser Methode werden die Zweige basierend auf dem Ergebnis des Tests von einem Knoten aus gewachsen.
- Das Verfahren des Splittens und Partitionierens wird rekursiv durchgeführt, was letztendlich zu einem Entscheidungsbaum für die Tupel des Trainingsdatensatzes führt.
- Der Prozess der Baumbildung wird fortgesetzt, bis die verbleibenden Tupel nicht weiter partitioniert werden können.
- Die Komplexität des Algorithmus wird mit bezeichnet
n * |D| * log |D|
Wobei n die Anzahl der Attribute in Trainingsdatensatz D und |D| ist ist die Anzahl der Tupel.
Quelle
Abbildung 3: Eine diskrete Wertaufteilung
Die Listen der in einem Entscheidungsbaum verwendeten Algorithmen sind:
ID3
Der gesamte Datensatz S wird beim Bilden des Entscheidungsbaums als Wurzelknoten betrachtet. Anschließend wird über jedes Attribut iteriert und die Daten in Fragmente zerlegt. Der Algorithmus prüft und nimmt diejenigen Attribute, die vor den iterierten nicht genommen wurden. Das Aufteilen von Daten im ID3-Algorithmus ist zeitaufwändig und kein idealer Algorithmus, da er die Daten überpasst.
C4.5
Es ist eine fortgeschrittene Form eines Algorithmus, da die Daten als Proben klassifiziert werden. Im Gegensatz zu ID3 können sowohl kontinuierliche als auch diskrete Werte effizient verarbeitet werden. Es ist eine Schnittmethode vorhanden, die die unerwünschten Zweige entfernt.
WAGEN
Sowohl Klassifizierungs- als auch Regressionsaufgaben können durch den Algorithmus durchgeführt werden. Im Gegensatz zu ID3 und C4.5 werden Entscheidungspunkte unter Berücksichtigung des Gini-Index erstellt. Für das Aufteilungsverfahren wird ein Greedy-Algorithmus angewendet, der darauf abzielt, die Kostenfunktion zu reduzieren. Bei Klassifizierungsaufgaben wird der Gini-Index als Kostenfunktion verwendet, um die Reinheit von Blattknoten anzuzeigen. Bei Regressionsaufgaben wird die Summe des quadratischen Fehlers als Kostenfunktion verwendet, um die beste Vorhersage zu finden.
CHAID
Wie der Name schon sagt, steht es für Chi-square Automatic Interaction Detector, ein Prozess, der sich mit jeder Art von Variablen befasst. Sie können nominale, ordinale oder kontinuierliche Variablen sein. Regressionsbäume verwenden den F-Test, während der Chi-Quadrat-Test im Klassifizierungsmodell verwendet wird.
MARS

Es steht für Multivariate Adaptive Regression Splines. Der Algorithmus wird speziell in Regressionsaufgaben implementiert, bei denen die Daten meist nichtlinear sind.
Gierige rekursive binäre Aufspaltung
Es tritt ein binäres Teilungsverfahren auf, das zu zwei Zweigen führt. Das Splitten der Tupel wird mit der Berechnung der Split-Cost-Funktion durchgeführt. Die niedrigste Kostenaufteilung wird ausgewählt und der Prozess wird rekursiv ausgeführt, um die Kostenfunktion der anderen Tupel zu berechnen.
Entscheidungsbaum mit realem Beispiel
Prognostizieren Sie den Prozess der Kreditwürdigkeit anhand der angegebenen Daten.
Schritt 1: Laden der Daten
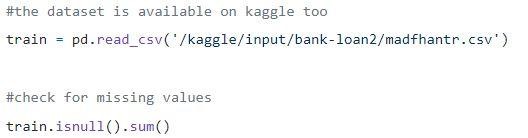
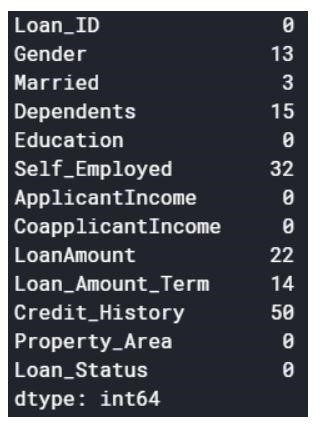
Die Nullwerte können entweder weggelassen oder mit einigen Werten gefüllt werden. Die Form des ursprünglichen Datensatzes war (614,13), und der neue Datensatz nach dem Löschen der Nullwerte ist (480,13).
Schritt 2: Ein Blick auf den Datensatz.

Schritt 3: Aufteilen der Daten in Trainings- und Testsätze.
Schritt 4: Modell bauen und Zuggarnitur montieren

Vor der Visualisierung sind einige Berechnungen durchzuführen.
Berechnung 1: Berechnen Sie die Entropie des gesamten Datensatzes.

Berechnung 2: Finden Sie die Entropie und den Gewinn für jede Spalte.
- Spalte Geschlecht
- Bedingung 1: Datensatz mit allen Männchen darin und dann,
p = 278, n = 116 , p + n = 489
Entropie (G=männlich) = 0,87
- Bedingung 2: Datensatz mit allen Frauen darin und dann,
p = 54 , n = 32 , p+n = 86
Entropie (G = weiblich) = 0,95
- Durchschnittsangabe in Spalte Geschlecht

- Verheiratete Spalte
- Bedingung 1: Verheiratet = Ja(1)
In diesem Split der gesamte Datensatz mit dem Status Verheiratet ja
p = 227 , n = 84 , p+n = 311
E(Verheiratet = Ja) = 0,84
- Bedingung 2: Verheiratet = Nein(0)
In dieser Aufteilung wird der gesamte Datensatz mit Verheiratet-Status-Nr
p = 105 , n = 64 , p+n = 169
E(Verheiratet = Nein) = 0,957
- Durchschnittliche Informationen in der Spalte „Verheiratet“ sind
- Bildungskolumne
- Bedingung 1: Bildung = Absolvent(1)
p = 271 , n = 112 , p+n = 383
E(Bildung = Absolvent) = 0,87
- Bedingung 2: Ausbildung = kein Abschluss(0)
p = 61 , n = 36 , p+n = 97
E (Bildung = kein Abschluss) = 0,95
- Durchschnittliche Bildungsinformationsspalte = 0,886
Verstärkung = 0,01
4) Selbständige Spalte
- Bedingung 1: Selbstständig = Ja(1)
p = 43 , n = 23 , p+n = 66
E (Selbstständig = Ja) = 0,93
- Bedingung 2: Selbstständig = Nein(0)
p = 289 , n = 125 , p+n = 414
E(Selbstständig = Nein) = 0,88
- Durchschnittliche Angaben in der Spalte „Selbständige in Ausbildung“ = 0,886
Verstärkung = 0,01
- Spalte „Credit Score“: Die Spalte hat einen Wert von 0 und 1.
- Bedingung 1: Kreditwürdigkeit = 1
p = 325 , n = 85 , p+n = 410
E(Kreditpunktzahl = 1) = 0,73
- Bedingung 2: Kreditwürdigkeit = 0
p = 63 , n = 7 , p+n = 70
E(Kreditpunktzahl = 0) = 0,46
- Durchschnittliche Informationen in der Spalte Kreditwürdigkeit = 0,69
Gewinn = 0,2
Vergleichen Sie alle Verstärkungswerte

Kredit-Score hat den höchsten Gewinn. Daher wird er als Root-Knoten verwendet.
Schritt 5: Visualisieren Sie den Entscheidungsbaum

Abbildung 5: Entscheidungsbaum mit Kriterium Gini
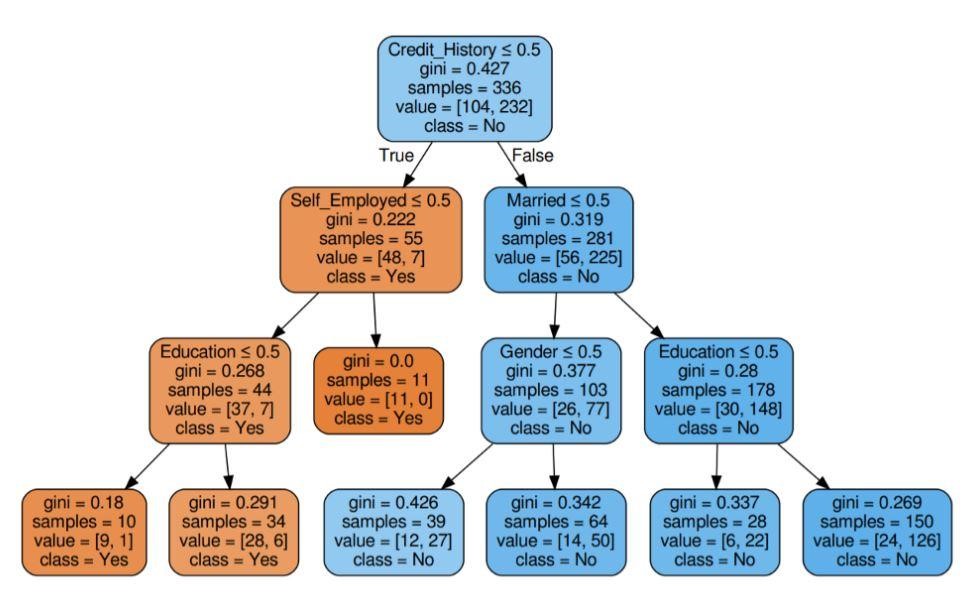 Quelle
Quelle
Abbildung 6: Entscheidungsbaum mit Kriterium Entropie
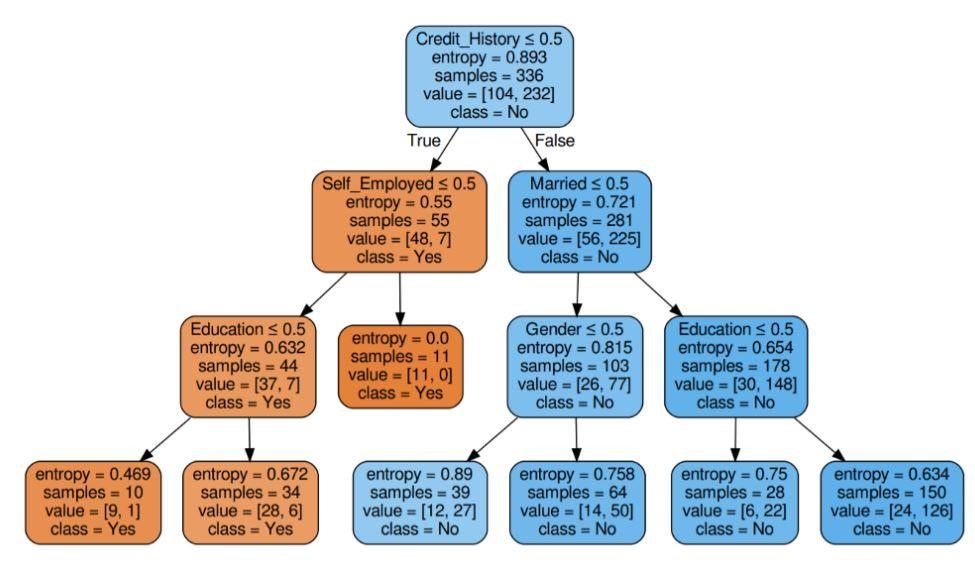
Quelle
Schritt 6: Überprüfen Sie die Punktzahl des Modells
Fast 80 % Prozent Genauigkeit erzielt.
Liste der Anwendungen
Entscheidungsbäume werden meist von Informationsexperten verwendet, um eine analytische Untersuchung durchzuführen. Sie können ausgiebig für geschäftliche Zwecke verwendet werden, um Schwierigkeiten zu analysieren oder vorherzusagen. Die Flexibilität des Entscheidungsbaums ermöglicht den Einsatz in einem anderen Bereich:
1. Gesundheitswesen
Entscheidungsbäume ermöglichen die Vorhersage, ob ein Patient an einer bestimmten Krankheit leidet, unter Berücksichtigung von Alter, Gewicht, Geschlecht usw. Andere Vorhersagen umfassen die Entscheidung über die Wirkung von Medikamenten unter Berücksichtigung von Faktoren wie Zusammensetzung, Herstellungszeitraum usw.
2. Bankensektoren
Entscheidungsbäume helfen bei der Vorhersage, ob eine Person unter Berücksichtigung ihrer finanziellen Situation, ihres Gehalts, ihrer Familienmitglieder usw. für einen Kredit in Frage kommt. Sie können auch Kreditkartenbetrug, Kreditausfälle usw. identifizieren.
3. Bildungssektoren
Mit Hilfe von Entscheidungsbäumen kann entschieden werden, ob ein Student aufgrund seiner Leistungspunktzahl, Anwesenheit usw. in die engere Wahl gezogen wird.
Liste der Vorteile
- Die interpretierbaren Ergebnisse eines Entscheidungsmodells können dem Senior Management und Stakeholdern präsentiert werden.
- Beim Erstellen eines Entscheidungsbaummodells ist eine Vorverarbeitung der Daten, dh Normalisierung, Skalierung usw., nicht erforderlich.
- Beide Arten von Daten – numerisch und kategorisch – können von einem Entscheidungsbaum verarbeitet werden, der seine höhere Nutzungseffizienz gegenüber anderen Algorithmen zeigt.
- Fehlender Wert in Daten beeinflusst den Prozess eines Entscheidungsbaums nicht und macht ihn somit zu einem flexiblen Algorithmus.
Was als nächstes?
Wenn Sie daran interessiert sind, praktische Erfahrungen im Bereich Data Mining zu sammeln und von Experten geschult zu werden, können Sie sich das Executive PG Program in Data Science von upGrad ansehen. Der Kurs richtet sich an alle Altersgruppen zwischen 21 und 45 Jahren mit einem Mindestauswahlkriterium von 50 % oder gleichwertigen bestandenen Noten beim Abschluss. Alle Berufstätigen können an diesem vom IIIT Bangalore zertifizierten PG-Programm für Führungskräfte teilnehmen.
Entscheidungsbäume im Data Mining können mit sehr komplizierten Daten umgehen. Alle Entscheidungsbäume haben drei wichtige Knoten oder Teile. Lassen Sie uns jeden von ihnen unten besprechen. Nachdem wir nun die Funktionsweise von Entscheidungsbäumen verstanden haben, versuchen wir, uns einige Vorteile der Verwendung von Entscheidungsbäumen beim Data Mining anzusehenWas ist ein Entscheidungsbaum im Data Mining?
Ein Entscheidungsbaum ist eine Möglichkeit, Modelle im Data Mining zu erstellen. Es kann als invertierter binärer Baum verstanden werden. Es enthält einen Wurzelknoten, einige Zweige und Blattknoten am Ende.
Jeder der internen Knoten in einem Entscheidungsbaum bezeichnet eine Studie zu einem Attribut. Jede der Unterteilungen bezeichnet die Folge dieses bestimmten Studiums oder dieser Prüfung. Und schließlich repräsentiert jeder Blattknoten ein Klassen-Tag.
Das Hauptziel des Aufbaus eines Entscheidungsbaums besteht darin, ein Ideal zu erstellen, das verwendet werden kann, um die bestimmte Klasse vorherzusagen, indem Beurteilungsverfahren für frühere Daten verwendet werden.
Wir beginnen mit dem Wurzelknoten, stellen einige Beziehungen mit der Wurzelvariablen her und nehmen Divisionen vor, die diesen Werten entsprechen. Basierend auf der Basisauswahl springen wir zu nachfolgenden Knoten. Was sind einige der wichtigen Knoten, die in Entscheidungsbäumen verwendet werden?
Wenn wir all diese Knoten verbinden, erhalten wir Divisionen. Wir können Bäume mit einer Vielzahl von Schwierigkeiten bilden, indem wir diese Knoten und Unterteilungen unendlich oft verwenden. Welche Vorteile bietet die Verwendung von Entscheidungsbäumen?
1. Wenn wir sie mit anderen Methoden vergleichen, erfordern Entscheidungsbäume nicht so viel Berechnung für das Training von Daten während der Vorverarbeitung.
2. Die Stabilisierung von Informationen ist in Entscheidungsbäumen nicht enthalten.
3. Außerdem erfordern sie nicht einmal eine Skalierung von Informationen.
4. Auch wenn einige Werte im Datensatz weggelassen werden, stört dies nicht bei der Konstruktion von Bäumen.
5. Diese Modelle sind instinktiv identisch. Sie sind auch stressfrei für die Beschreibung.