
Sollte das Web Hardware-Fähigkeiten offenlegen?
Veröffentlicht: 2022-03-10Ich habe mich in letzter Zeit für die Meinungsverschiedenheiten zwischen den verschiedenen Browseranbietern über die Zukunft des Webs interessiert – insbesondere für die verschiedenen Bemühungen, die Fähigkeiten von Webplattformen näher an native Plattformen heranzuführen, wie etwa das Projekt Fugu von Chromium.
Die wichtigsten Positionen lassen sich wie folgt zusammenfassen:
- Google (zusammen mit Partnern wie Intel, Microsoft und Samsung) drängt aggressiv voran und führt Innovationen mit einer Fülle neuer APIs wie denen in Fugu ein und liefert sie in Chromium aus;
- Apple drängt mit einem konservativeren Ansatz zurück und markiert viele der neuen APIs als Anlass zu Sicherheits- und Datenschutzbedenken;
- Dies hat (zusammen mit Apples Einschränkungen bei der Browserauswahl in iOS) zu einer Haltung geführt, die Safari als den neuen IE bezeichnet, während behauptet wird, dass Apple den Fortschritt des Webs verlangsamt;
- Mozilla scheint in dieser Hinsicht näher an Apple als an Google zu sein.
Meine Absicht in diesem Artikel ist es, Behauptungen zu betrachten, die mit Google identifiziert wurden, insbesondere diejenigen in der Platform Adjacency Theory von Project Fugu-Leiter Alex Russell, die in diesen Behauptungen vorgelegten Beweise zu betrachten und vielleicht zu meiner eigenen Schlussfolgerung zu gelangen.
Insbesondere beabsichtige ich, in WebUSB (eine besonders umstrittene API von Project Fugu) einzutauchen, zu prüfen, ob die Sicherheitsansprüche dagegen berechtigt sind, und zu versuchen, zu sehen, ob sich eine Alternative ergibt.
Die Plattformadjazenztheorie
Die oben genannte Theorie stellt die folgenden Behauptungen auf:
- Software verlagert sich ins Web, weil es eine bessere Version des Computing ist;
- Das Web ist eine Metaplattform – eine Plattform, die von ihrem Betriebssystem abstrahiert ist;
- Der Erfolg einer Metaplattform basiert darauf, dass sie die Dinge leistet, die wir von den meisten Computern erwarten;
- Die Weigerung, der Web-Metaplattform aus Sicherheitsgründen angrenzende Funktionen hinzuzufügen, während die gleichen Sicherheitsprobleme in nativen Plattformen ignoriert werden, wird das Web letztendlich immer weniger relevant machen;
- Apple und Mozilla tun genau das – sie lehnen es ab, dem Web benachbarte Rechenkapazitäten hinzuzufügen, und „werfen das Web in Bernstein“.
Ich beziehe mich auf die Leidenschaft des Autors, das offene Web relevant zu halten, und auf die Sorge, dass eine zu langsame Erweiterung des Webs um neue Funktionen es irrelevant machen würde. Hinzu kommt meine Abneigung gegen App Stores und andere Walled Gardens. Aber als Benutzer kann ich mich auf die entgegengesetzte Perspektive beziehen – mir wird manchmal schwindelig, wenn ich nicht weiß, was Websites, die ich durchsuche, können oder nicht können, und ich finde Plattformbeschränkungen und Audits beruhigend.
Meta-Plattformen
Um den Begriff „Meta-Plattform“ zu verstehen, habe ich mir angesehen, wofür die Theorie diesen Namen verwendet – Java und Flash, beides Produkte der Jahrtausendwende.
Ich finde es verwirrend, Java oder Flash mit dem Web zu vergleichen. Sowohl Java als auch Flash wurden, wie in der Theorie erwähnt, zu dieser Zeit durch Browser-Plug-ins weit verbreitet, was sie eher zu einer alternativen Laufzeitumgebung machte, die auf der Browserplattform aufsetzt. Heutzutage wird Java hauptsächlich auf dem Server und als Teil der Android-Plattform verwendet, und beide haben außer der Sprache nicht viel gemeinsam.
Heute ist serverseitiges Java vielleicht eine Metaplattform, und node.js ist auch ein gutes Beispiel für eine serverseitige Metaplattform. Es ist eine Reihe von APIs, eine plattformübergreifende Laufzeit und ein Paket-Ökosystem. Tatsächlich fügt node.js immer mehr Funktionen hinzu, die bisher nur als Teil einer Plattform möglich waren.
Auf der Client-Seite kommt Qt, ein C++-basiertes plattformübergreifendes Framework, nicht mit einer separaten Laufzeit, es ist lediglich eine (gute!) plattformübergreifende Bibliothek für die UI-Entwicklung.
Gleiches gilt für Rust – es ist ein Sprach- und Paketmanager, aber nicht auf vorinstallierte Laufzeiten angewiesen.
Die anderen Möglichkeiten zur Entwicklung clientseitiger Anwendungen sind hauptsächlich plattformspezifisch, umfassen aber auch einige plattformübergreifende mobile Lösungen wie Flutter und Xamarin.
Fähigkeiten vs. Zeit
Das Hauptdiagramm in der Theorie zeigt die Relevanz von Metaplattformen auf einer 2D-Achse von Fähigkeiten vs. Zeit:

Ich kann sehen, wie sinnvoll das obige Diagramm ist, wenn es um die oben erwähnten plattformübergreifenden Entwicklungsframeworks wie Qt, Xamarin, Flutter und Rust und auch um Serverplattformen wie node.js und Java/Scala geht.
Aber alle oben genannten haben einen entscheidenden Unterschied zum Web.
Die 3. Dimension
Die oben erwähnten Meta-Plattformen konkurrieren zwar im Rennen um Fähigkeiten mit ihren Host-Betriebssystemen, aber im Gegensatz zum Web haben sie keine Meinung zu Vertrauen und Verteilung – die 3. Dimension, die meiner Meinung nach in der obigen Grafik fehlt.
Qt und Rust sind gute Möglichkeiten, Apps zu erstellen, die über WebAssembly verteilt, heruntergeladen und direkt auf dem Host-Betriebssystem installiert oder über Paketmanager wie Cargo oder Linux-Distributionen wie Ubuntu verwaltet werden. React Native, Flutter und Xamarin sind gute Möglichkeiten, Apps zu erstellen, die über App Stores vertrieben werden. node.js- und Java-Dienste werden normalerweise über einen Docker-Container, eine virtuelle Maschine oder einen anderen Servermechanismus verteilt.
Die Benutzer wissen meistens nicht, was zur Entwicklung ihrer Inhalte verwendet wurde, wissen aber bis zu einem gewissen Grad, wie sie verbreitet werden. Benutzer wissen nicht, was Xamarin und node.js sind, und wenn ihre Swift-App eines Tages durch eine Flutter-App ersetzt würde, wäre und sollte es den meisten Benutzern egal sein.
Aber Benutzer kennen das Web – sie wissen, dass sie beim „Browsen“ in Chrome oder Firefox „online“ sind und auf Inhalte zugreifen können, denen sie nicht unbedingt vertrauen. Sie wissen, dass das Herunterladen und Installieren von Software eine mögliche Gefahr darstellt und möglicherweise von ihrem IT-Administrator blockiert wird. Tatsächlich ist es für die Webplattform wichtig, dass Benutzer wissen, dass sie gerade „im Internet surfen“. Deshalb wird dem Benutzer beispielsweise beim Wechsel in den Vollbildmodus eine klare Aufforderung angezeigt, mit Anweisungen, wie er wieder herauskommt.
Das Web ist erfolgreich geworden, weil es nicht transparent ist – aber klar von seinem Host-Betriebssystem getrennt ist. Wenn ich meinem Browser nicht vertrauen kann, zufällige Websites davon abzuhalten, Dateien auf meiner Festplatte zu lesen, würde ich wahrscheinlich keine Website besuchen.
Benutzer wissen auch, dass ihre Computersoftware „Windows“ oder „Mac“ ist, ob ihre Telefone Android- oder iOS-basiert sind und ob sie derzeit eine App verwenden (wenn auf iOS oder Android und bis zu einem gewissen Grad auf Mac OS). . Das Betriebssystem und das Verteilungsmodell sind dem Benutzer im Allgemeinen bekannt – der Benutzer vertraut darauf, dass sein Betriebssystem und das Web unterschiedliche Dinge tun, und zwar mit unterschiedlichem Vertrauen.
Daher kann das Web nicht mit plattformübergreifenden Entwicklungs-Frameworks verglichen werden, ohne sein einzigartiges Vertriebsmodell zu berücksichtigen.
Andererseits werden Webtechnologien auch für die plattformübergreifende Entwicklung mit Frameworks wie Electron und Cordova verwendet. Aber das ist nicht gerade „das Web“. Im Vergleich zu Java oder node.js muss der Begriff „Das Web“ durch „Web-Technologien“ ersetzt werden. Und so eingesetzte „Web-Technologien“ müssen nicht unbedingt standardbasiert sein oder auf mehreren Browsern funktionieren. Das Gespräch über Fugu-APIs ist etwas tangential zu Electron und Cordova.
Native Apps
Beim Hinzufügen von Funktionen zur Webplattform darf die dritte Dimension – das Vertrauens- und Vertriebsmodell – nicht ignoriert oder auf die leichte Schulter genommen werden. Wenn der Autor behauptet, dass „das Posieren von Apple und Mozilla über Risiken durch neue Funktionen durch akzeptierte Risiken nativer Plattformen Lügen gestraft wird“ , stellt er das Internet und native Plattformen in Bezug auf Vertrauen in die gleiche Dimension.
Zugegeben, native Apps haben ihre eigenen Sicherheitsprobleme und Herausforderungen. Aber ich verstehe nicht, wie das ein Argument für mehr Webfähigkeiten wie hier sein soll. Dies ist ein Trugschluss – die Schlussfolgerung sollte darin bestehen, Sicherheitsprobleme mit nativen Apps zu beheben, und nicht die Sicherheit für Web-Apps zu lockern, weil sie sich in einem Relevanz-Aufholspiel mit Betriebssystemfunktionen befinden.
Native und Web lassen sich hinsichtlich der Fähigkeiten nicht vergleichen, ohne die 3. Dimension des Vertrauens- und Vertriebsmodells zu berücksichtigen.
App Store-Einschränkungen
Einer der Kritikpunkte an nativen Apps in der Theorie ist die mangelnde Auswahl an Browser-Engines auf iOS. Dies ist ein häufiger Thread der Kritik an Apple, aber es gibt mehr als eine Perspektive dazu.
Die Kritik bezieht sich speziell auf Punkt 2.5.6 von Apples App Store Review Guidelines:
„Apps, die im Internet surfen, müssen das entsprechende WebKit-Framework und WebKit-JavaScript verwenden.“
Dies mag wettbewerbswidrig erscheinen, und ich habe meine eigenen Bedenken, wie restriktiv iOS ist. Punkt 2.5.6 kann jedoch nicht ohne den Kontext der übrigen Richtlinien zur Überprüfung von App-Stores gelesen werden, z. B. Punkt 2.3.12:
„Apps müssen neue Funktionen und Produktänderungen in ihrem ‚What's New‘-Text klar beschreiben.“
Wenn eine App Gerätezugriffsberechtigungen erhalten und dann ihr eigenes Framework enthalten könnte, das Code von jeder Website ausführen könnte, würden diese Elemente in den Überprüfungsrichtlinien des App Stores bedeutungslos. Im Gegensatz zu Apps müssen Websites ihre Funktionen und Produktänderungen nicht bei jeder Überarbeitung beschreiben.
Dies wird zu einem noch größeren Problem, wenn Browser experimentelle Funktionen wie die im Projekt Fugu ausliefern, die noch nicht als Standard gelten. Wer definiert, was ein Browser ist? Indem Apps erlaubt werden, beliebige Web-Frameworks zu liefern, würde der App Store der „App“ im Wesentlichen erlauben, ungeprüften Code auszuführen oder das Produkt vollständig zu ändern, wodurch der Überprüfungsprozess des Stores umgangen wird.
Als Benutzer von Websites und Apps denke ich, dass beide einen Platz in der Computerwelt haben, obwohl ich hoffe, dass sich so viel wie möglich ins Web verlagern könnte. Aber wenn ich den aktuellen Stand der Webstandards betrachte und wie die Dimension von Vertrauen und Sandboxing bei Dingen wie Bluetooth und USB noch lange nicht gelöst ist, sehe ich nicht, wie es für Benutzer von Vorteil wäre, Apps die freie Ausführung von Inhalten aus dem Web zu ermöglichen .
Das Streben nach Appiness
In einem anderen verwandten Blogbeitrag spricht derselbe Autor einiges davon an, wenn er über native Apps spricht:
„Eine App zu sein bedeutet lediglich, eine Reihe willkürlicher und veränderbarer Betriebssystemkonventionen zu erfüllen.“
Ich stimme der Vorstellung zu, dass die Definition von „App“ willkürlich ist und dass ihre Definition davon abhängt, wer die App-Store-Richtlinien definiert. Aber heute gilt dasselbe für Browser. Auch die Behauptung aus dem Post, Webanwendungen seien standardmäßig sicher, ist etwas willkürlich. Wer zieht die Grenze in den Sand, „was ist ein Browser“? Ist die Facebook-App mit integriertem Browser „ein Browser“?
Die Definition einer App ist willkürlich, aber auch wichtig. Die Tatsache, dass jede Revision einer Anwendung, die Low-Level-Fähigkeiten verwendet, von jemandem geprüft wird, dem ich vertrauen könnte, selbst wenn dieser jemand willkürlich ist, macht Apps zu dem, was sie sind. Wenn dieser jemand der Hersteller der Hardware ist, für die ich bezahlt habe, wird es noch weniger willkürlich – die Firma, von der ich meinen Computer gekauft habe, ist diejenige, die Auditing-Software mit geringeren Fähigkeiten für diesen Computer hat.
Alles kann ein Browser sein
Ohne eine Grenze zu ziehen, was der Apple App Store im Wesentlichen tut, könnte jede App ihre eigene Web-Engine liefern, den Benutzer dazu verleiten, mit seinem In-App-Browser zu jeder Website zu navigieren, und beliebigen Tracking-Code hinzufügen es will, kollabiert der 3. Dimension Unterschied zwischen Apps und Websites.
Wenn ich eine App auf iOS verwende, weiß ich, dass meine Aktionen derzeit zwei Akteuren ausgesetzt sind: Apple und dem identifizierten App-Hersteller. Wenn ich eine Website in Safari oder in Safari WebView verwende, werden meine Aktionen Apple und dem Besitzer der Top-Level-Domain der Website, die ich gerade ansehe, angezeigt. Wenn ich einen In-App-Browser mit einer nicht identifizierten Engine verwende, bin ich Apple, dem Hersteller der App, und dem Eigentümer der Top-Level-Domain ausgesetzt. Dies kann zu vermeidbaren Same-Origin-Verstößen führen, z. B. dass der Eigentümer der App alle meine Klicks auf fremde Websites verfolgt.
Ich stimme zu, dass der Strich im Sand von „Only WebKit“ vielleicht zu hart ist. Was wäre eine alternative Definition eines Browsers, der keine Hintertür zum Verfolgen des Benutzer-Browsings erstellen würde?
Andere Kritik an Apple
Die Theorie besagt, dass Apples Weigerung, Funktionen zu implementieren, nicht auf Datenschutz-/Sicherheitsbedenken beschränkt ist. Es enthält einen Link, der tatsächlich viele Funktionen zeigt, die in Chrome und nicht in Safari implementiert sind. Wenn Sie jedoch nach unten scrollen, listet es auch eine beträchtliche Anzahl anderer Funktionen auf, die in Safari und nicht in Chrome implementiert sind.
Diese beiden Browser-Projekte haben unterschiedliche Prioritäten, aber sie sind weit entfernt von der kategorischen Aussage „Das Spiel wird klar, wenn man herauszoomt“ und von der harschen Kritik an Apples Versuch, das Web in Bernstein zu tauchen.
Außerdem führen die Links mit dem Titel „ es ist schwer und wir wollen es nicht versuchen “ zu Apples Aussagen, dass sie Funktionen implementieren würden, wenn Sicherheits-/Datenschutzbedenken erfüllt würden. Ich denke, dass es irreführend ist, diese Links mit diesen Titeln zu versehen.
Ich würde einer ausgewogeneren Aussage zustimmen, dass Google viel optimistischer als Apple ist, wenn es um die Implementierung von Funktionen und die Weiterentwicklung des Webs geht.
Berechtigungsaufforderung
Google geht in der 3. Dimension innovative Wege und entwickelt neue Wege, um Vertrauen zwischen dem Nutzer, dem Entwickler und der Plattform zu vermitteln, manchmal mit großem Erfolg, wie im Fall von Trusted Web Activities.
Dennoch konzentriert sich die meiste Arbeit in der 3. Dimension in Bezug auf Geräte-APIs auf Berechtigungsaufforderungen und macht sie beängstigender oder Dinge wie Zeitfenster-Berechtigungsgewährungen und gesperrte Domänen.
„Beängstigende“ Eingabeaufforderungen, wie die in diesem Beispiel, die wir von Zeit zu Zeit sehen, sehen so aus, als sollten sie Menschen davon abhalten, Seiten zu besuchen, die potenziell bösartig erscheinen. Da sie so offensichtlich sind, ermutigen diese Warnungen Entwickler, auf sicherere APIs umzusteigen und ihre Zertifikate zu erneuern.
Ich wünschte, wir könnten für Gerätezugriffsfunktionen Eingabeaufforderungen entwickeln, die das Engagement fördern und sicherstellen, dass das Engagement sicher ist, anstatt davon abzuraten und die Haftung auf den Benutzer zu übertragen, ohne dass der Webentwickler Abhilfe schaffen kann. Dazu später mehr.
Ich stimme dem Argument zu, dass Mozilla und Apple zumindest versuchen sollten, in diesem Bereich innovativ zu sein, anstatt „die Implementierung abzulehnen“. Aber vielleicht sind sie es? Ich denke zum Beispiel isLoggedIn von Apple ist ein interessanter und relevanter Vorschlag in der 3. Dimension, auf dem zukünftige Geräte-APIs aufbauen könnten – zum Beispiel können Geräte-APIs, die anfällig für Fingerabdrücke sind, verfügbar gemacht werden, wenn die aktuelle Website bereits deren Identität kennt der Benutzer.
WebUSB
Im nächsten Abschnitt werde ich in WebUSB eintauchen, prüfen, was es erlaubt und wie es in der 3. Dimension gehandhabt wird – was ist das Vertrauens- und Verteilungsmodell? Ist es ausreichend? Was sind die Alternativen?

Die Voraussetzung
Die WebUSB-API ermöglicht vollen Zugriff auf das USB-Protokoll für Geräteklassen, die nicht auf der Sperrliste stehen.
Es kann leistungsstarke Dinge wie das Verbinden mit einem Arduino-Board oder das Debuggen eines Android-Telefons erreichen.
Es ist spannend, die Videos von Suz Hinton darüber zu sehen, wie diese API dabei helfen kann, Dinge zu erreichen, die zuvor sehr teuer zu erreichen waren.
Ich wünsche mir wirklich, dass Plattformen Wege finden, offener zu sein und beispielsweise schnelle Iterationen bei Hardware-/Softwareprojekten für Bildungszwecke zu ermöglichen.
Lustiges Gefühl
Trotzdem bekomme ich ein komisches Gefühl, wenn ich mir ansehe, was WebUSB ermöglicht und welche Sicherheitsprobleme bei USB im Allgemeinen bestehen.
USB fühlt sich als Protokoll, das dem Internet ausgesetzt ist, zu leistungsfähig an, selbst mit Aufforderungen zur Berechtigung.
Also habe ich weiter recherchiert.
Mozillas offizielle Ansicht
Ich begann damit, zu lesen, was David Baron darüber zu sagen hatte, warum Mozilla WebUSB in Mozillas offizieller Position zu Standards ablehnte:
„Da viele USB-Geräte nicht darauf ausgelegt sind, potenziell böswillige Interaktionen über die USB-Protokolle zu verarbeiten, und weil diese Geräte erhebliche Auswirkungen auf den Computer haben können, an den sie angeschlossen sind, sind die Sicherheitsrisiken, die mit der Offenlegung von USB-Geräten im Internet verbunden sind, unserer Meinung nach ebenso breit, um das Risiko einzugehen, Benutzer ihnen auszusetzen, oder Endbenutzern richtig zu erklären, um eine sinnvolle informierte Zustimmung zu erhalten.
Die Eingabeaufforderung für die aktuelle Berechtigung
So sieht die WebUSB-Berechtigungsaufforderung von Chrome zum Zeitpunkt der Veröffentlichung dieses Beitrags aus:
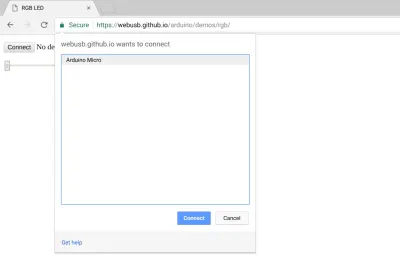
Eine bestimmte Domäne Foo möchte eine Verbindung zu einem bestimmten Gerät Bar herstellen. Um was zu tun? und wie kann ich das sicher wissen?
Bei der Gewährung des Zugriffs auf Drucker, Kamera, Mikrofon, GPS oder sogar auf einige der enthalteneren WebBluetooth-GATT-Profile wie die Herzfrequenzüberwachung ist diese Frage relativ klar und konzentriert sich eher auf den Inhalt oder die Aktion als auf das Gerät . Es gibt ein klares Verständnis darüber, welche Informationen ich von dem Peripheriegerät haben möchte oder welche Aktion ich damit ausführen möchte, und der Benutzeragent vermittelt und stellt sicher, dass diese bestimmte Aktion gehandhabt wird.
USB ist generisch
Im Gegensatz zu den oben genannten Geräten, die über spezielle APIs bereitgestellt werden, ist USB nicht inhaltsspezifisch. Wie im Intro der Spezifikation erwähnt, geht WebUSB noch weiter und ist absichtlich für unbekannte oder noch nicht erfundene Gerätetypen konzipiert, nicht für bekannte Geräteklassen wie Tastaturen oder externe Laufwerke.
Anders als in den Fällen von Drucker, GPS und Kamera kann ich mir also keine Eingabeaufforderung vorstellen, die den Benutzer darüber informiert, was das Erteilen einer Seitenberechtigung zum Herstellen einer Verbindung zu einem Gerät mit WebUSB im Inhaltsbereich ermöglichen würde, ohne ein tiefes Verständnis der bestimmtes Gerät und Auditieren des Codes, der darauf zugreift.
Der Yubikey-Vorfall und Schadensbegrenzung
Ein gutes Beispiel aus nicht allzu langer Zeit ist der Yubikey-Vorfall, bei dem WebUSB von Chrome verwendet wurde, um Daten von einem USB-betriebenen Authentifizierungsgerät zu phishing.
Da es sich um ein Sicherheitsproblem handelt, das angeblich behoben ist, war ich neugierig, in Chromes Minderungsbemühungen in Chrome 67 einzutauchen, zu denen das Blockieren einer bestimmten Gruppe von Geräten und einer bestimmten Gruppe von Klassen gehört.
Klassen-/Gerätesperrliste
Die eigentliche Verteidigung von Chrome gegen WebUSB-Exploits, die in freier Wildbahn stattfanden, bestand also neben der derzeit sehr allgemeinen Berechtigungsabfrage darin, bestimmte Geräte und Geräteklassen zu blockieren.
Dies kann eine unkomplizierte Lösung für eine neue Technologie oder ein neues Experiment sein, wird aber immer schwieriger zu bewerkstelligen sein, wenn (und falls) WebUSB populärer wird.
Ich befürchte, dass die Leute, die über WebUSB an Bildungsgeräten innovativ sind, in eine schwierige Situation geraten könnten. Wenn sie mit dem Prototyping fertig sind, könnten sie mit einer Reihe sich ständig ändernder, nicht standardmäßiger Sperrlisten konfrontiert sein, die nur zusammen mit Browserversionen aktualisiert werden, basierend auf Sicherheitsproblemen, die nichts mit ihnen zu tun haben.
Ich denke, dass die Standardisierung dieser API, ohne dies anzugehen, für die Entwickler, die sich darauf verlassen, kontraproduktiv sein wird. Zum Beispiel könnte jemand Zyklen damit verbringen, eine WebUSB-Anwendung für Bewegungsmelder zu entwickeln, nur um später herauszufinden, dass Bewegungsmelder entweder aus Sicherheitsgründen oder weil das Betriebssystem beschließt, sie zu handhaben, zu einer blockierten Klasse werden, was dazu führt, dass seine gesamte WebUSB-Bemühung wegfällt Abfall.
Sicherheit vs. Funktionen
Die Theorie der Plattformadjazenz betrachtet Fähigkeiten und Sicherheit in gewisser Weise als Nullsummenspiel, und dass eine zu konservative Betrachtung von Sicherheits- und Datenschutzbedenken dazu führen würde, dass Plattformen ihre Relevanz verlieren würden.
Nehmen wir als Beispiel Arduino. Arduino-Kommunikation ist mit WebUSB möglich und ein wichtiger Anwendungsfall. Jemand, der ein Arduino-Gerät entwickelt, muss nun ein neues Bedrohungsszenario in Betracht ziehen, bei dem eine Website versucht, über WebUSB (mit einer gewissen Benutzerberechtigung) auf ihr Gerät zuzugreifen. Gemäß der Spezifikation muss dieser Gerätehersteller nun „seine Geräte so konzipieren, dass sie nur signierte Firmware akzeptieren“. Dies kann die Firmware-Entwickler zusätzlich belasten und die Entwicklungskosten erhöhen, während der ganze Zweck der Spezifikation darin besteht, das Gegenteil zu bewirken.
Was unterscheidet WebUSB von anderen Peripheriegeräten?
In Browsern gibt es eine klare Unterscheidung zwischen Benutzerinteraktionen und synthetischen Interaktionen (von der Webseite instanziierte Interaktionen).
Beispielsweise kann eine Webseite nicht selbst entscheiden, auf einen Link zu klicken oder die CPU/das Display aufzuwecken. Aber externe Geräte können das – zum Beispiel kann eine Maus im Namen des Benutzers auf einen Link klicken und fast jedes USB-Gerät kann je nach Betriebssystem die CPU aufwecken.
Selbst mit der aktuellen WebUSB-Spezifikation können Geräte also mehrere Schnittstellen implementieren, z. B. Debug für ADB und HID für die Zeigereingabe, und mit bösartigem Code, der ADB ausnutzt, zu einem Keylogger werden und Websites im Namen des Benutzers durchsuchen, sofern dies der Fall ist richtigen ausnutzbaren Firmware-Flashing-Mechanismus.
Das Hinzufügen dieses Geräts zu einer Sperrliste wäre zu spät für Geräte mit Firmware, die mit ADB oder anderen zulässigen Formen des Flashens kompromittiert wurde, und würde Gerätehersteller noch abhängiger als zuvor von Browserversionen für Sicherheitsfixes im Zusammenhang mit ihren Geräten machen.
Einverständniserklärung & Inhalt
Das Problem mit Einverständniserklärung und USB besteht, wie bereits erwähnt, darin, dass USB (insbesondere in den extra-generischen WebUSB-Anwendungsfällen) nicht inhaltsspezifisch ist. Benutzer wissen, was ein Drucker ist, was eine Kamera ist, aber „USB“ ist für die meisten Benutzer lediglich ein Kabel (oder eine Steckdose) – ein Mittel zum Zweck – nur sehr wenige Benutzer wissen, dass USB ein Protokoll ist und was es zwischen Websites ermöglicht und Geräte bedeutet.
Ein Vorschlag war eine „beängstigende“ Aufforderung, etwas in der Art von „Erlaube dieser Webseite, das Gerät zu übernehmen“ (was eine Verbesserung gegenüber dem scheinbar harmlosen „Möchte verbinden“).
Aber so beängstigend Eingabeaufforderungen auch sein mögen, sie können nicht die Bandbreite möglicher Dinge erklären, die mit einem rohen Zugriff auf ein USB-Peripheriegerät getan werden können, das der Browser nicht genau kennt, und wenn dies der Fall wäre, würde kein Benutzer, der bei klarem Verstand ist, auf „Ja“ klicken “, es sei denn, es handelt sich um ein Gerät, dem sie voll und ganz vertrauen, dass es fehlerfrei ist, und um eine Website, der sie wirklich vertrauen, dass sie auf dem neuesten Stand und nicht bösartig ist.
Eine mögliche Eingabeaufforderung wie diese lautet „Erlauben Sie dieser Webseite, Ihren Computer möglicherweise zu übernehmen“. Ich glaube nicht, dass eine beängstigende Eingabeaufforderung wie diese für die WebUSB-Community von Vorteil wäre, und ständige Änderungen an diesen Dialogen werden die Community verwirren.
Prototyping vs. Produkt
Ich sehe hier eine mögliche Ausnahme. Wenn die Prämisse von WebUSB und den anderen Fugu-APIs des Projekts darin bestand, Prototyping statt Geräte in Produktqualität zu unterstützen, könnten allumfassende generische Eingabeaufforderungen sinnvoll sein.
Um das zu ermöglichen, muss meiner Meinung nach Folgendes passieren:
- Verwenden Sie Sprache in den Spezifikationen, die Erwartungen an dieses Wesen für das Prototyping setzen;
- Stellen Sie diese APIs erst nach einer Opt-in-Geste zur Verfügung, z. B. wenn der Benutzer sie manuell in den Browsereinstellungen aktiviert;
- Haben Sie „beängstigende“ Berechtigungsaufforderungen, wie die für ungültige SSL-Zertifikate.
Wenn ich das oben Genannte nicht habe, denke ich, dass diese APIs eher für echte Produkte als für Prototypen sind, und als solches gilt das Feedback.
Ein Alternativvorschlag
Einer der Teile des ursprünglichen Blogbeitrags, dem ich zustimme, ist, dass es nicht ausreicht, „nein“ zu sagen – große Akteure in der Webwelt, die bestimmte APIs als schädlich ablehnen, sollten auch angreifen und Wege vorschlagen, wie diese Fähigkeiten von Bedeutung sind Benutzern und Entwicklern sicher zugänglich gemacht werden können. Ich vertrete keinen großen Spieler, aber ich werde es bescheiden versuchen.
Ich glaube, dass die Antwort darauf in der 3. Dimension von Vertrauen und Beziehung liegt und dass sie außerhalb der Box von Erlaubnis-Eingabeaufforderungen und Sperrlisten liegt.
Unkomplizierte und verifizierte Eingabeaufforderung
Das Hauptargument, das ich vorbringen werde, ist, dass sich die Aufforderung auf den Inhalt oder die Aktion beziehen sollte und nicht auf das Peripheriegerät, und dass die informierte Zustimmung für eine bestimmte einfache Aktion mit einem bestimmten Satz verifizierter Parameter erteilt werden kann, nicht für a allgemeine Aktionen wie „Übernehmen“ oder „Verbinden mit“ einem Gerät.
Das 3D-Drucker-Beispiel
In der WebUSB-Spezifikation werden 3D-Drucker als Beispiel angeführt, also werde ich sie hier verwenden.
Wenn ich eine WebUSB-Anwendung für einen 3D-Drucker entwickle, möchte ich, dass die Browser-/Betriebssystem-Eingabeaufforderung mich etwas in der Art von Allow AutoDesk 3ds-mask to print a model to your CreatBot 3D printer? , wird ein Browser/OS-Dialog mit einigen Druckparametern wie Verfeinerung, Dicke und Ausgabeabmessungen sowie mit einer Vorschau dessen angezeigt, was gedruckt werden soll. Alle diese Parameter sollten von einem vertrauenswürdigen Benutzeragenten überprüft werden, nicht von einer Drive-by-Webseite.
Derzeit kennt der Browser den Drucker nicht und kann nur einige der Behauptungen in der Eingabeaufforderung überprüfen:
- Die anfordernde Domäne verfügt über ein bei AutoDesk registriertes Zertifikat, daher besteht eine gewisse Sicherheit, dass es sich um AutoDesk Inc handelt.
- Das angeforderte Peripheriegerät nennt sich „CreatBot 3D-Drucker“;
- Dieses Gerät, diese Geräteklasse und diese Domäne werden nicht in den Sperrlisten des Browsers gefunden;
- Der Benutzer hat auf eine allgemeine Frage, die ihm gestellt wurde, mit „Ja“ oder „Nein“ geantwortet.
Aber um eine wahrheitsgemäße Eingabeaufforderung und einen Dialog mit den obigen Details anzuzeigen, müsste der Browser auch Folgendes überprüfen:
- Wenn die Erlaubnis erteilt wird, besteht die durchgeführte Aktion darin, ein 3D-Modell zu drucken, und nichts anderes;
- Die gewählten Parameter (Feinheit/Dicke/Abmessungen etc.) werden eingehalten;
- Eine verifizierte Vorschau dessen, was gedruckt werden soll, wurde dem Benutzer angezeigt;
- In bestimmten sensiblen Fällen eine zusätzliche Überprüfung, ob es sich tatsächlich um AutoDesk handelt, möglicherweise mit so etwas wie einem widerruflichen kurzlebigen Token.
Ohne das Obige zu überprüfen, kann eine Website, der die Erlaubnis erteilt wurde, sich mit einem 3D-Drucker zu „verbinden“ oder „zu übernehmen“, aufgrund eines Fehlers (oder bösartigen Codes in einer ihrer Abhängigkeiten) mit dem Drucken riesiger 3D-Modelle beginnen.
Außerdem würde eine imaginäre vollständige Web-3D-Druckfunktion viel mehr leisten als das, was WebUSB bieten kann – zum Beispiel das Spoolen und Einreihen verschiedener Druckanforderungen. Wie würde das gehandhabt werden, wenn das Browserfenster geschlossen ist? Ich habe nicht alle möglichen Anwendungsfälle für WebUSB-Peripheriegeräte recherchiert, aber ich vermute, dass die meisten mehr als nur USB-Zugriff benötigen, wenn man sie aus einer Inhalts-/Aktionsperspektive betrachtet.
Aus diesem Grund wird die Verwendung von WebUSB für den 3D-Druck wahrscheinlich hacky und kurzlebig sein, und Entwickler, die sich darauf verlassen, müssen irgendwann einen „echten“ Treiber für ihren Drucker bereitstellen. Wenn beispielsweise Betriebssystemanbieter beschließen, integrierte Unterstützung für 3D-Drucker hinzuzufügen, würden alle Websites, die diesen Drucker mit WebUSB verwenden, nicht mehr funktionieren.
Vorschlag: Fahrerprüfstelle
Daher sind übergreifende Berechtigungen wie „Peripherie übernehmen“ problematisch, wir haben nicht genügend Informationen, um einen vollwertigen Parameterdialog anzuzeigen und zu überprüfen, ob seine Ergebnisse respektiert werden, und wir wollen nicht senden der Benutzer auf einer unsicheren Reise, um eine zufällige ausführbare Datei aus dem Internet herunterzuladen.
Aber was wäre, wenn es einen geprüften Code gibt, einen Treiber, der die WebUSB-API intern verwendet und Folgendes tut:
- Befehl „Drucken“ implementiert;
- Zeigt einen Out-of-Page-Druckdialog an;
- Verbunden mit einem bestimmten Satz von USB-Geräten;
- Führt einige seiner Aktionen aus, wenn sich die Seite im Hintergrund befindet (z. B. bei einem Servicemitarbeiter) oder sogar wenn der Browser geschlossen ist.
Eine Prüfung eines solchen Treibers kann sicherstellen, dass das, was er tut, auf „Drucken“ hinausläuft, dass er die Parameter respektiert und dass er die Druckvorschau anzeigt.
Ich sehe dies ähnlich wie Zertifizierungsstellen, ein wichtiges Element im Web-Ökosystem, das etwas von den Browseranbietern getrennt ist.
Treiber-Syndikation
Die Treiber müssen nicht von Google/Apple geprüft werden, obwohl der Anbieter des Browsers/Betriebssystems die Treiber selbst prüfen kann. Es kann wie SSL-Zertifizierungsstellen funktionieren – der Aussteller ist eine sehr vertrauenswürdige Organisation; B. der Hersteller des jeweiligen Peripheriegeräts oder eine Organisation, die viele Treiber zertifiziert, oder eine Plattform wie Arduino. (Ich stelle mir vor, dass Organisationen ähnlich wie Let's Encrypt auftauchen.)
Es könnte ausreichen, den Benutzern zu sagen: „Arduino vertraut darauf, dass dieser Code Ihren Uno mit dieser Firmware flashen wird“ (mit einer Vorschau der Firmware).
Vorbehalte
Dies ist natürlich nicht frei von möglichen Problemen:
- Der Treiber selbst kann fehlerhaft oder bösartig sein. Aber zumindest ist es geprüft;
- Es ist weniger „webby“ und erzeugt eine zusätzliche Entwicklungslast;
- Es existiert heute nicht und kann nicht durch interne Innovationen in Browser-Engines gelöst werden.
Andere Alternativen
Andere Alternativen könnten darin bestehen, die Cross-Browser-Weberweiterungs-API irgendwie zu standardisieren und zu verbessern und die vorhandenen Browser-Add-on-Stores wie den Chrome Web Store zu einer Art Prüfinstanz für Treiber zu machen, die zwischen Benutzeranfragen und Peripheriezugriff vermittelt.
Zusammenfassung der Stellungnahme
Die mutigen Bemühungen des Autors, von Google und Partnern, das offene Web durch Verbesserung seiner Möglichkeiten relevant zu halten, sind inspirierend.
Wenn ich zu den Details komme, sehe ich die konservativere Sichtweise von Apple und Mozilla auf das Internet und ihre defensive Herangehensweise an neue Gerätefunktionen als technisch wertvoll. Kernprobleme mit informierter Zustimmung zu offenen Hardwarefunktionen sind noch lange nicht gelöst.
Apple könnte in der Diskussion, neue Wege zur Aktivierung von Gerätefunktionen zu finden, entgegenkommender sein, aber ich glaube, dies kommt aus einer anderen Perspektive über Computer, ein Standpunkt, der jahrzehntelang Teil der Identität von Apple war, und nicht aus einem wettbewerbsfeindlichen Standpunkt.
Um Dinge wie die etwas offenen Hardwarefunktionen im Projekt Fugu und insbesondere WebUSB zu unterstützen, muss sich das Vertrauensmodell des Webs über Berechtigungsaufforderungen und Sperrlisten für Domänen/Geräte hinaus entwickeln und sich von Vertrauensökosystemen wie Zertifizierungsstellen und inspirieren lassen Paketverteilungen.
Weiterführende Literatur zu SmashingMag:
- Wie die Verbesserung der Website-Leistung helfen kann, den Planeten zu retten
- Auf dem Weg zu einem werbefreien Web: Diversifizierung der Online-Wirtschaft
- Gibt es eine Zukunft jenseits des Schreibens von großartigem Code?
- Verwendung von Ethik im Webdesign