
Voice Skills für Google Assistant und Amazon Alexa erstellen
Veröffentlicht: 2022-03-10In den letzten zehn Jahren hat es eine seismische Verschiebung hin zu Konversationsschnittstellen gegeben. Wenn die Menschen den „Spitzenbildschirm“ erreichen und sogar beginnen, ihre Gerätenutzung einzuschränken, werden digitale Wohlfühlfunktionen in die meisten Betriebssysteme integriert.
Um der Bildschirmermüdung entgegenzuwirken, sind Sprachassistenten auf den Markt gekommen, um eine bevorzugte Option zum schnellen Abrufen von Informationen zu werden. Eine häufig wiederholte Statistik besagt, dass 50 % der Suchanfragen im Jahr 2020 per Sprache erfolgen werden. Außerdem liegt es bei steigender Akzeptanz an den Entwicklern, „Conversational Interfaces“ und „Voice Assistants“ in ihren Werkzeuggürtel aufzunehmen.
Das Unsichtbare gestalten
Für viele kann der Einstieg in ein Voice UI (VUI)-Projekt ein bisschen wie der Eintritt ins Unbekannte sein. Erfahren Sie mehr über die Lektionen, die William Merrill beim Design für Voice gelernt hat. Lesen Sie einen verwandten Artikel →
Was ist eine Konversationsschnittstelle?
Eine Conversational Interface (manchmal als CUI abgekürzt) ist eine beliebige Schnittstelle in einer menschlichen Sprache. Sie gilt als natürlichere Schnittstelle für die breite Öffentlichkeit als die grafische Benutzeroberfläche GUI, an deren Erstellung Frontend-Entwickler gewöhnt sind. Eine GUI erfordert Menschen um die spezifischen Syntaxen der Benutzeroberfläche zu lernen (denken Sie an Schaltflächen, Schieberegler und Dropdown-Menüs).
Dieser entscheidende Unterschied bei der Verwendung menschlicher Sprache macht CUI für Menschen natürlicher; es erfordert wenig Wissen und legt die Last des Verständnisses auf das Gerät.
Üblicherweise gibt es CUIs in zwei Erscheinungsformen: Chatbots und Sprachassistenten. Beide haben in den letzten zehn Jahren dank der Fortschritte in der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) einen massiven Anstieg der Akzeptanz erlebt.
Sprachjargon verstehen

| Stichwort | Bedeutung |
|---|---|
| Fähigkeit/Aktion | Eine Sprachanwendung, die eine Reihe von Absichten erfüllen kann |
| Absicht | Beabsichtigte Aktion, die der Skill erfüllen soll, was der Benutzer mit dem Skill als Reaktion auf das, was er sagt, tun möchte. |
| Äußerung | Der Satz, den ein Benutzer sagt oder äußert. |
| Wachwort | Das Wort oder der Satz, mit dem ein Sprachassistent zuhört, z. B. „Hey Google“, „Alexa“ oder „Hey Siri“. |
| Kontext | Die Kontextinformationen innerhalb einer Äußerung, die der Fähigkeit helfen, eine Absicht zu erfüllen, z. B. „heute“, „jetzt“, „wenn ich nach Hause komme“. |
Was ist ein Sprachassistent?
Ein Sprachassistent ist eine NLP-fähige Software (Natural Language Processing). Es empfängt einen Sprachbefehl und gibt eine Antwort im Audioformat zurück. In den letzten Jahren hat sich der Umfang, wie Sie mit einem Assistenten interagieren können, erweitert und weiterentwickelt, aber der Kern der Technologie ist natürliche Sprache rein, viel Berechnung, natürliche Sprache raus.
Für diejenigen, die etwas mehr Details suchen:
- Die Software empfängt eine Audioanfrage von einem Benutzer, verarbeitet den Ton zu Phonemen, den Bausteinen der Sprache.
- Durch die Magie der KI (speziell Speech-To-Text) werden diese Phoneme in eine Zeichenfolge der angenäherten Anfrage umgewandelt, diese wird in einer JSON-Datei gespeichert, die auch zusätzliche Informationen über den Benutzer, die Anfrage und die Sitzung enthält.
- Das JSON wird dann verarbeitet (normalerweise in der Cloud), um den Kontext und die Absicht der Anfrage zu ermitteln.
- Basierend auf der Absicht wird eine Antwort zurückgegeben, wiederum innerhalb einer größeren JSON-Antwort, entweder als Zeichenfolge oder als SSML (dazu später mehr).
- Die Antwort wird mithilfe von KI zurückverarbeitet (natürlich umgekehrt - Text-To-Speech), die dann an den Benutzer zurückgegeben wird.
Da ist viel los, von denen das meiste keine weiteren Überlegungen erfordert. Aber jede Plattform macht das anders, und es sind die Nuancen der Plattform, die ein bisschen mehr Verständnis erfordern.

Sprachfähige Geräte
Die Anforderungen an ein Gerät, um einen Sprachassistenten einbrennen zu können, sind ziemlich gering. Sie benötigen ein Mikrofon, eine Internetverbindung und einen Lautsprecher. Intelligente Lautsprecher wie Nest Mini und Echo Dot bieten diese Art von Low-Fi-Sprachsteuerung.
Als nächstes in den Reihen steht Voice + Screen, dies wird als „multimodales“ Gerät bezeichnet (dazu später mehr), und es handelt sich um Geräte wie den Nest Hub und die Echo Show. Da Smartphones über diese Funktionalität verfügen, können sie auch als eine Art multimodales sprachfähiges Gerät betrachtet werden.
Stimmfähigkeiten
Zunächst einmal hat jede Plattform einen anderen Namen für ihre „Voice Skills“, Amazon geht mit Skills, bei denen ich als allgemein verständlichen Begriff bleiben werde. Google entscheidet sich für „Aktionen“ und Samsung für „Kapseln“.
Jede Plattform hat ihre eigenen eingebauten Fähigkeiten, wie die Frage nach Uhrzeit, Wetter und Sportspielen. Von Entwicklern erstellte Fähigkeiten (Drittanbieter) können mit einem bestimmten Satz oder, wenn die Plattform es mag, implizit ohne einen Schlüsselsatz aufgerufen werden.
Explizite Aufforderung : „Hey Google, sprich mit <App-Name>.“
Es wird explizit angegeben, welche Fähigkeit gefragt ist:
Implizite Aufforderung : „Hey Google, wie ist das Wetter heute?“
Aus dem Kontext der Anforderung geht hervor, welchen Dienst der Benutzer wünscht.
Welche Sprachassistenten gibt es?
Auf dem westlichen Markt sind Sprachassistenten ein Drei-Pferde-Rennen. Apple, Google und Amazon haben sehr unterschiedliche Herangehensweisen an ihre Assistenten und sprechen daher unterschiedliche Arten von Entwicklern und Kunden an.
Apples Siri
Gerätename : „Siri“
Wecksatz : „Hey Siri“
Siri hat über 375 Millionen aktive Benutzer, aber der Kürze halber gehe ich bei Siri nicht zu sehr ins Detail. Obwohl es weltweit gut angenommen und in die meisten Apple-Geräte integriert werden kann, erfordert es, dass Entwickler bereits eine App auf einer der Apple-Plattformen haben, und ist schnell geschrieben (während die anderen in Jedermanns Favorit geschrieben werden können: Javascript). Sofern Sie kein App-Entwickler sind, der das Angebot seiner App erweitern möchte, können Sie derzeit an Apple vorbeispringen, bis sie ihre Plattform öffnen.
Google-Assistent
Gerätenamen : „Google Home, Nest“
Wake-Phrase : „Hey Google“
Google hat die meisten Geräte der großen Drei, mit über 1 Milliarde weltweit, dies liegt vor allem an der Masse an Android-Geräten, die Google Assistant eingebaut haben, in Bezug auf ihre dedizierten Smart Speaker sind die Zahlen etwas geringer. Die allgemeine Mission von Google mit seinem Assistenten besteht darin, die Benutzer zu begeistern, und sie waren schon immer sehr gut darin, leichte und intuitive Benutzeroberflächen bereitzustellen.
Ihr primäres Ziel auf der Plattform ist es, Zeit zu nutzen – mit der Idee, ein fester Bestandteil des Kundenalltags zu werden. Als solche konzentrieren sie sich in erster Linie auf Nutzen, Familienspaß und schöne Erlebnisse.
Skills, die für Google entwickelt wurden, sind am besten, wenn es sich um Verlobungsstücke und Spiele handelt, die sich in erster Linie auf familienfreundlichen Spaß konzentrieren. Die kürzlich hinzugefügte Leinwand für Spiele ist ein Beweis für diesen Ansatz. Die Google-Plattform ist viel strenger für die Übermittlung von Fähigkeiten, und daher ist ihr Verzeichnis viel kleiner.
Amazon Alexa
Gerätenamen : „Amazon Fire, Amazon Echo“
Wecksatz : „Alexa“
Amazon hat 2019 die Marke von 100 Millionen Geräten überschritten, dies stammt hauptsächlich aus dem Verkauf seiner intelligenten Lautsprecher und intelligenten Displays sowie seiner „Feuer“-Reihe oder Tablets und Streaming-Geräte.
Skills, die für Amazon entwickelt wurden, zielen in der Regel auf den Kauf von Skills ab. Wenn Sie nach einer Plattform suchen, um Ihren E-Commerce/Service zu erweitern oder ein Abonnement anzubieten, dann ist Amazon genau das Richtige für Sie. Davon abgesehen ist ISP keine Voraussetzung für Alexa Skills, sie unterstützen alle Arten von Anwendungen und sind viel offener für Einreichungen.
Die Anderen
Es gibt noch mehr Sprachassistenten wie Bixby von Samsung, Cortana von Microsoft und den beliebten Open-Source-Sprachassistenten Mycroft. Alle drei haben eine passable Fangemeinde, sind aber im Vergleich zu den drei Goliaths von Amazon, Google und Apple noch in der Minderheit.
Aufbauend auf Amazon Alexa
Das Sprach-Ökosystem von Amazon hat sich so entwickelt, dass Entwickler alle ihre Fähigkeiten in der Alexa-Konsole aufbauen können. Als einfaches Beispiel werde ich die integrierten Funktionen verwenden.
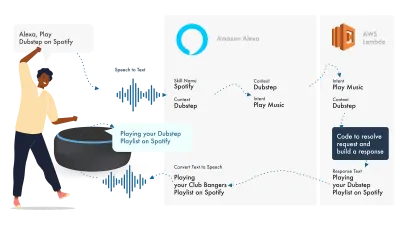
Alexa befasst sich mit der Verarbeitung natürlicher Sprache und findet dann einen geeigneten Intent, der an unsere Lambda-Funktion übergeben wird, um sich mit der Logik zu befassen. Dadurch werden einige Konversationsbits (SSML, Text, Karten usw.) an Alexa zurückgegeben, das diese Bits in Audio und Bild konvertiert, um sie auf dem Gerät anzuzeigen.
Die Arbeit bei Amazon ist relativ einfach, da Sie alle Teile Ihres Skills in der Alexa Developer Console erstellen können. Die Flexibilität besteht darin, AWS oder einen HTTPS-Endpunkt zu verwenden, aber für einfache Fähigkeiten sollte es ausreichen, alles innerhalb der Dev-Konsole auszuführen.
Lassen Sie uns einen einfachen Alexa-Skill erstellen
Gehen Sie zur Amazon Alexa-Konsole, erstellen Sie ein Konto, falls Sie noch keines haben, und melden Sie sich an.
Klicken Sie auf Create Skill und geben Sie ihm einen Namen.
Wählen Sie custom als Ihr Modell,
und wählen Sie Alexa-Hosted (Node.js) für Ihre Back-End-Ressource aus.
Sobald die Bereitstellung abgeschlossen ist, haben Sie eine grundlegende Alexa-Fähigkeit, Ihre Absicht wird für Sie erstellt, und etwas Back-End-Code, um Ihnen den Einstieg zu erleichtern.
Wenn Sie in Ihren Absichten auf den HelloWorldIntent klicken, sehen Sie einige Beispieläußerungen, die bereits für Sie eingerichtet wurden. Lassen Sie uns oben eine neue hinzufügen. Unser Skill heißt „Hello World“, also fügen Sie „Hello World“ als Beispieläußerung hinzu. Die Idee ist, alles zu erfassen, was der Benutzer sagen könnte, um diese Absicht auszulösen. Dies könnte „Hallo Welt“, „Hallo Welt“ und so weiter sein.
Was passiert in The Fulfillment JS?
Was macht der Code also? Hier ist der Standardcode:
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; Dies nutzt den ask-sdk-core und erstellt im Wesentlichen JSON für uns. canHandle lässt ask wissen, dass es Absichten verarbeiten kann, insbesondere „HelloWorldIntent“. handle übernimmt die Eingabe und erstellt die Antwort. Was dies generiert, sieht so aus:

{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
Wir können sehen, dass speak ssml in unserem json ausgibt, was der Benutzer so hört, wie es von Alexa gesprochen wird.
Aufbau für Google Assistant
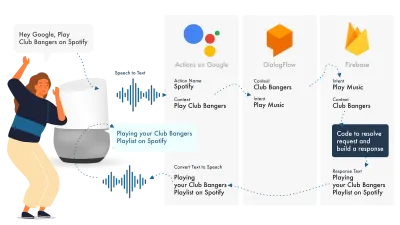
Der einfachste Weg, Aktionen auf Google zu erstellen, ist die Verwendung der AoG-Konsole in Kombination mit Dialogflow. Sie können Ihre Fähigkeiten mit Firebase erweitern, aber wie beim Amazon Alexa-Tutorial sollten wir die Dinge einfach halten.
Google Assistant verwendet drei Hauptteile, AoG, das sich mit dem NLP befasst, Dialogflow, das Ihre Absichten ausarbeitet, und Firebase, das die Anfrage erfüllt und die Antwort erzeugt, die an AoG zurückgesendet wird.
Genau wie bei Alexa können Sie mit Dialogflow Ihre Funktionen direkt auf der Plattform erstellen.
Lassen Sie uns eine Aktion auf Google erstellen
Es gibt drei Plattformen gleichzeitig mit der Lösung von Google zu jonglieren, auf die über drei verschiedene Konsolen zugegriffen wird, also Tab hoch!
Dialogflow einrichten
Beginnen wir mit der Anmeldung bei der Dialogflow-Konsole. Nachdem Sie sich angemeldet haben, erstellen Sie über das Dropdown-Menü direkt unter dem Dialogflow-Logo einen neuen Agenten.
Geben Sie Ihrem Agenten einen Namen und fügen Sie ihn dem „Google-Projekt-Dropdown“ hinzu, während Sie „Neues Google-Projekt erstellen“ ausgewählt haben.
Klicken Sie auf die Schaltfläche „Erstellen“ und lassen Sie es wirken. Es dauert ein wenig, bis der Agent eingerichtet ist. Seien Sie also geduldig.
Firebase-Funktionen einrichten
Richtig, jetzt können wir damit beginnen, die Fulfillment-Logik einzufügen.
Gehen Sie weiter zur Registerkarte Erfüllung. Aktivieren Sie das Kontrollkästchen, um den Inline-Editor zu aktivieren, und verwenden Sie die folgenden JS-Snippets:
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);Paket.json
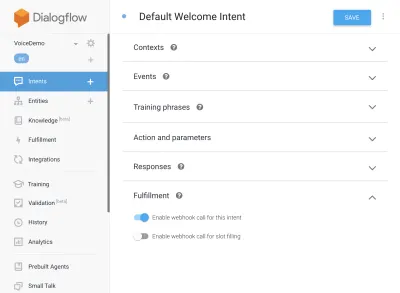
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }Kehren Sie nun zu Ihren Absichten zurück, gehen Sie zu Standard-Begrüßungsabsicht und scrollen Sie nach unten zu Erfüllung. Stellen Sie sicher, dass „Webhook-Aufruf für diese Absicht aktivieren“ für alle Absichten aktiviert ist, die Sie mit Javascript erfüllen möchten. Klicken Sie auf Speichern.
AoG einrichten
Wir nähern uns jetzt der Ziellinie. Gehen Sie zur Registerkarte Integrationen und klicken Sie oben in der Google Assistant-Option auf Integrationseinstellungen. Dadurch wird ein Modal geöffnet, also klicken Sie auf Test, wodurch Ihr Dialogflow in Google integriert wird, und öffnen Sie ein Testfenster für Actions on Google.
Im Testfenster können wir auf Mit meiner Test-App sprechen klicken (Wir werden dies gleich ändern), und voila, wir haben die Nachricht von unserem Javascript, die auf einem Google Assistant-Test angezeigt wird.
Wir können den Namen des Assistenten auf der Registerkarte „Entwickeln“ ganz oben ändern.
Was passiert also in The Fulfillment JS?
Erstens verwenden wir zwei npm-Pakete, actions-on-google, das die gesamte Erfüllung bietet, die sowohl AoG als auch Dialogflow benötigen, und zweitens firebase-functions, wie Sie es erraten haben, enthält Helfer für Firebase.
Dann erstellen wir die „App“, die ein Objekt ist, das alle unsere Absichten enthält.
Jeder erstellte Intent hat „conv“ übergeben, das das Konversationsobjekt ist, das von Actions On Google gesendet wird. Wir können den Inhalt von conv verwenden, um Informationen über frühere Interaktionen mit dem Benutzer zu ermitteln (z. B. seine ID und Informationen über seine Sitzung mit uns).
Wir geben ein „conv.ask-Objekt“ zurück, das unsere Antwortnachricht an den Benutzer enthält, damit er mit einer anderen Absicht antworten kann. Wir könnten 'conv.close' verwenden, um das Gespräch zu beenden, wenn wir das Gespräch dort beenden wollten.
Schließlich verpacken wir alles in einer Firebase-HTTPS-Funktion, die sich für uns um die serverseitige Request-Response-Logik kümmert.
Nochmals, wenn wir uns die Antwort ansehen, die generiert wird:
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } Wir können sehen, dass der Text von conv.ask in den textToSpeech Bereich eingefügt wurde. Wenn wir conv.close gewählt hätten, würde die expectUserResponse auf „ false “ gesetzt und die Konversation würde geschlossen, nachdem die Nachricht zugestellt wurde.
Voice Builder von Drittanbietern
Ähnlich wie in der App-Branche tauchen mit zunehmender Bedeutung von Voice auch Tools von Drittanbietern auf, um die Entwickler zu entlasten, indem sie es ihnen ermöglichen, einmal zu erstellen und zweimal bereitzustellen.
Jovo und Voiceflow sind derzeit die beiden beliebtesten, insbesondere seit der Übernahme von PullString durch Apple. Jede Plattform bietet eine andere Abstraktionsebene, also hängt es wirklich nur davon ab, wie einfach Sie Ihre Benutzeroberfläche gestalten.
Erweitern Sie Ihre Fähigkeiten
Nachdem Sie sich nun mit dem Aufbau einer grundlegenden „Hello World“-Fähigkeit beschäftigt haben, gibt es jede Menge Glocken und Pfeifen, die zu Ihrer Fertigkeit hinzugefügt werden können. Diese sind das i-Tüpfelchen auf dem Kuchen der Sprachassistenten und bieten Ihren Benutzern einen großen Mehrwert, was zu wiederholten Kundenwünschen und potenziellen kommerziellen Möglichkeiten führt.
SSML
SSML steht für Speech Synthesis Markup Language und arbeitet mit einer ähnlichen Syntax wie HTML, der Hauptunterschied besteht darin, dass Sie eine gesprochene Antwort aufbauen und keine Inhalte auf einer Webseite.
Der Begriff „SSML“ ist ein wenig irreführend, er kann so viel mehr als Sprachsynthese! Sie können Stimmen parallel laufen lassen, Sie können Umgebungsgeräusche, Speechcons (an sich schon hörenswert, denken Sie an Emojis für berühmte Sätze) und Musik einbeziehen.
Wann sollte ich SSML verwenden?
SSML ist großartig; Es macht eine viel ansprechendere Erfahrung für den Benutzer, aber was es auch tut, ist die Flexibilität der Audioausgabe zu reduzieren. Ich empfehle die Verwendung für eher statische Sprachbereiche. Sie können darin Variablen für Namen usw. verwenden, aber wenn Sie nicht beabsichtigen, einen SSML-Generator zu erstellen, wird die meiste SSML ziemlich statisch sein.
Beginnen Sie mit einfacher Sprache in Ihrem Skill, und verbessern Sie nach Abschluss statischer Bereiche mit SSML, aber bringen Sie Ihren Kern in Ordnung, bevor Sie mit dem Schnickschnack fortfahren. Davon abgesehen sagt ein kürzlich erschienener Bericht, dass 71 % der Benutzer eine menschliche (echte) Stimme einer synthetischen vorziehen. Wenn Sie also die Möglichkeit dazu haben, gehen Sie raus und tun Sie es!

Beim Skill-Kauf
In-Skill-Käufe (oder ISP) ähneln dem Konzept der In-App-Käufe. Skills sind in der Regel kostenlos, aber einige ermöglichen den Kauf von „Premium“-Inhalten/-Abonnements innerhalb der App. Diese können das Erlebnis für einen Benutzer verbessern, neue Spielstufen freischalten oder den Zugriff auf Paywall-Inhalte ermöglichen.
Multimodal
Multimodale Antworten decken so viel mehr als Sprache ab, hier können Sprachassistenten mit ergänzenden visuellen Elementen auf Geräten, die sie unterstützen, wirklich glänzen. Die Definition von multimodalen Erfahrungen ist viel weiter gefasst und bedeutet im Wesentlichen mehrere Eingaben (Tastatur, Maus, Touchscreen, Sprache usw.).
Multimodale Fähigkeiten sollen das zentrale Spracherlebnis ergänzen und zusätzliche ergänzende Informationen bereitstellen, um die UX zu verbessern. Denken Sie beim Aufbau eines multimodalen Erlebnisses daran, dass die Stimme der primäre Informationsträger ist. Viele Geräte haben keinen Bildschirm, daher muss Ihr Skill auch ohne einen funktionieren, also stellen Sie sicher, dass Sie ihn mit mehreren Gerätetypen testen; Entweder real oder im Simulator.

Mehrsprachig
Mehrsprachige Fähigkeiten sind Fähigkeiten, die in mehreren Sprachen funktionieren und Ihre Fähigkeiten für mehrere Märkte öffnen.
Die Komplexität, Ihren Skill mehrsprachig zu machen, hängt davon ab, wie dynamisch Ihre Antworten sind. Fertigkeiten mit relativ statischen Antworten, z. B. jedes Mal die gleiche Phrase zurückzugeben oder nur eine kleine Gruppe von Phrasen zu verwenden, sind viel einfacher mehrsprachig zu machen als ausgedehnte dynamische Fertigkeiten.
Der Trick bei der Mehrsprachigkeit besteht darin, einen vertrauenswürdigen Übersetzungspartner zu haben, sei es durch eine Agentur oder einen Übersetzer auf Fiverr. Sie müssen den bereitgestellten Übersetzungen vertrauen können, insbesondere wenn Sie die Sprache, in die übersetzt wird, nicht verstehen. Google Translate schneidet hier nicht den Senf ab!
Fazit
Wenn es jemals einen Zeitpunkt gegeben hätte, in die Voice-Branche einzusteigen, dann jetzt. Sowohl in seiner Blütezeit und in den Kinderschuhen als auch die großen Neun stecken Milliarden in den Anbau und bringen Sprachassistenten in die Häuser und den Alltag aller.
Die Wahl der zu verwendenden Plattform kann schwierig sein, aber basierend auf dem, was Sie bauen möchten, sollte die zu verwendende Plattform durchscheinen oder, falls dies nicht möglich ist, ein Drittanbieter-Tool verwenden, um Ihre Wetten abzusichern und auf mehreren Plattformen aufzubauen, insbesondere wenn Sie Ihre Fähigkeiten besitzen ist weniger kompliziert mit weniger beweglichen Teilen.
Ich jedenfalls bin gespannt auf die Zukunft der Stimme, da sie allgegenwärtig wird; Die Bildschirmabhängigkeit wird reduziert und die Kunden werden in der Lage sein, auf natürliche Weise mit ihrem Assistenten zu interagieren. Aber zuerst liegt es an uns, die Fähigkeiten aufzubauen, die die Leute von ihrem Assistenten erwarten.