
TypeScript-Generika verstehen
Veröffentlicht: 2022-03-10In diesem Artikel lernen wir das Konzept von Generics in TypeScript kennen und untersuchen, wie Generics verwendet werden können, um modularen, entkoppelten und wiederverwendbaren Code zu schreiben. Unterwegs werden wir kurz erörtern, wie sie in bessere Testmuster, Ansätze zur Fehlerbehandlung und die Trennung von Domänen- und Datenzugriff passen.
Ein Beispiel aus der Praxis
Ich möchte in die Welt der Generika einsteigen, nicht indem ich erkläre, was sie sind, sondern indem ich ein intuitives Beispiel dafür gebe, warum sie nützlich sind. Angenommen, Sie wurden beauftragt, eine funktionsreiche dynamische Liste zu erstellen. Sie können es ein Array, eine ArrayList , eine List , einen std::vector oder was auch immer nennen, abhängig von Ihrem Sprachhintergrund. Vielleicht muss diese Datenstruktur auch eingebaute oder austauschbare Puffersysteme haben (wie eine Option zum Einfügen eines Ringpuffers). Es wird ein Wrapper um das normale JavaScript-Array sein, sodass wir mit unserer Struktur anstelle von einfachen Arrays arbeiten können.
Das unmittelbare Problem, auf das Sie stoßen werden, sind Einschränkungen, die durch das Typsystem auferlegt werden. Sie können an dieser Stelle nicht jeden gewünschten Typ in einer Funktion oder Methode auf schöne, saubere Weise akzeptieren (wir werden diese Anweisung später noch einmal aufgreifen).
Die einzig offensichtliche Lösung besteht darin, unsere Datenstruktur für alle verschiedenen Typen zu replizieren:
const intList = IntegerList.create(); intList.add(4); const stringList = StringList.create(); stringList.add('hello'); const userList = UserList.create(); userList.add(new User('Jamie')); Die .create() Syntax hier mag willkürlich aussehen, und tatsächlich wäre new SomethingList() geradliniger, aber Sie werden später sehen, warum wir diese statische Factory-Methode verwenden. Intern ruft die create -Methode den Konstruktor auf.
Das ist fürchterlich. Wir haben viel Logik in dieser Sammlungsstruktur, und wir duplizieren sie offenkundig, um verschiedene Anwendungsfälle zu unterstützen, und brechen dabei vollständig das DRY-Prinzip. Wenn wir uns entscheiden, unsere Implementierung zu ändern, müssen wir diese Änderungen manuell über alle Strukturen und Typen, die wir unterstützen, einschließlich benutzerdefinierter Typen, wie im letzten Beispiel oben, verbreiten/reflektieren. Angenommen, die Sammlungsstruktur selbst wäre 100 Zeilen lang – es wäre ein Albtraum, mehrere verschiedene Implementierungen zu verwalten, bei denen der einzige Unterschied zwischen ihnen die Typen sind.
Eine unmittelbare Lösung, die Ihnen in den Sinn kommen könnte, insbesondere wenn Sie eine OOP-Denkweise haben, besteht darin, wenn Sie so wollen, einen Wurzel-„Supertyp“ in Betracht zu ziehen. In C# gibt es beispielsweise einen Typ namens object und object ist ein Alias für die Klasse System.Object . Im Typsystem von C# erben alle Typen, ob vordefiniert oder benutzerdefiniert, ob Verweistypen oder Werttypen, entweder direkt oder indirekt von System.Object . Das bedeutet, dass einer Variablen vom Typ object ein beliebiger Wert zugewiesen werden kann (ohne in die Stack/Heap- und Boxing/Unboxing-Semantik einzusteigen).
In diesem Fall scheint unser Problem gelöst zu sein. Wir können einfach einen any Typ verwenden, der es uns ermöglicht, alles, was wir wollen, in unserer Sammlung zu speichern, ohne die Struktur duplizieren zu müssen, und das ist in der Tat sehr wahr:
const intList = AnyList.create(); intList.add(4); const stringList = AnyList.create(); stringList.add('hello'); const userList = AnyList.create(); userList.add(new User('Jamie')); Schauen wir uns die tatsächliche Implementierung unserer Liste mit any an:
class AnyList { private values: any[] = []; private constructor (values: any[]) { this.values = values; // Some more construction work. } public add(value: any): void { this.values.push(value); } public where(predicate: (value: any) => boolean): AnyList { return AnyList.from(this.values.filter(predicate)); } public select(selector: (value: any) => any): AnyList { return AnyList.from(this.values.map(selector)); } public toArray(): any[] { return this.values; } public static from(values: any[]): AnyList { // Perhaps we perform some logic here. // ... return new AnyList(values); } public static create(values?: any[]): AnyList { return new AnyList(values ?? []); } // Other collection functions. // ... }Alle Methoden sind relativ einfach, aber wir beginnen mit dem Konstruktor. Seine Sichtbarkeit ist privat, da wir davon ausgehen, dass unsere Liste komplex ist und wir willkürliche Konstruktionen verbieten möchten. Möglicherweise möchten wir auch Logik vor der Konstruktion ausführen, und aus diesen Gründen und um den Konstruktor rein zu halten, delegieren wir diese Bedenken an statische Fabrik-/Hilfsprogrammmethoden, was als gute Praxis angesehen wird.
Die statischen Methoden from und create werden bereitgestellt. Die Methode from akzeptiert ein Array von Werten, führt benutzerdefinierte Logik aus und verwendet sie dann zum Erstellen der Liste. Die statische Methode create nimmt ein optionales Array von Werten für den Fall, dass wir unsere Liste mit Anfangsdaten füllen möchten. Der „Nullish Coalescing Operator“ ( ?? ) wird verwendet, um die Liste mit einem leeren Array zu erstellen, falls eines nicht bereitgestellt wird. Wenn die linke Seite des Operanden null oder undefined ist, greifen wir auf die rechte Seite zurück, denn in diesem Fall ist values optional und kann daher undefined sein. Auf der entsprechenden TypeScript-Dokumentationsseite erfahren Sie mehr über Nullish Coalescing.
Ich habe auch eine select und eine where -Methode hinzugefügt. Diese Methoden umschließen lediglich die map und den filter von JavaScript. select erlaubt es uns, ein Array von Elementen basierend auf der bereitgestellten Selektorfunktion in eine neue Form zu projizieren, und where erlaubt uns, bestimmte Elemente basierend auf der bereitgestellten Prädikatfunktion herauszufiltern. Die toArray Methode wandelt die Liste einfach in ein Array um, indem sie die Array-Referenz zurückgibt, die wir intern halten.
Nehmen wir schließlich an, dass die User -Klasse eine getName Methode enthält, die einen Namen zurückgibt und auch einen Namen als erstes und einziges Konstruktorargument akzeptiert.
Hinweis: Einige Leser werdenWhereundSelectaus dem LINQ von C# erkennen, aber denken Sie daran, dass ich versuche, dies einfach zu halten, daher mache ich mir keine Sorgen über Faulheit oder verzögerte Ausführung. Das sind Optimierungen, die im wirklichen Leben gemacht werden könnten und sollten.
Außerdem möchte ich als interessante Anmerkung die Bedeutung von „Prädikat“ erörtern. In der Diskreten Mathematik und Aussagenlogik haben wir das Konzept einer „Proposition“. Eine Aussage ist eine Aussage, die als wahr oder falsch betrachtet werden kann, wie zum Beispiel „vier ist durch zwei teilbar“. Ein „Prädikat“ ist ein Satz, der eine oder mehrere Variablen enthält, daher hängt der Wahrheitsgehalt des Satzes von dem dieser Variablen ab. Sie können sich das wie eine Funktion vorstellen, z. B.P(x) = x is divisible by two, denn wir müssen den Wert vonxkennen, um festzustellen, ob die Aussage wahr oder falsch ist. Hier erfahren Sie mehr über die Prädikatenlogik.
Es gibt ein paar Probleme, die sich aus der Verwendung von any ergeben werden. Der TypeScript-Compiler weiß nichts über die Elemente innerhalb des Listen-/internen Arrays, daher bietet er keine Hilfe innerhalb von where oder select oder beim Hinzufügen von Elementen:
// Providing seed data. const userList = AnyList.create([new User('Jamie')]); // This is fine and expected. userList.add(new User('Tom')); userList.add(new User('Alice')); // This is an acceptable input to the TS Compiler, // but it's not what we want. We'll definitely // be surprised later to find strings in a list // of users. userList.add('Hello, World!'); // Also acceptable. We have a large tuple // at this point rather than a homogeneous array. userList.add(0); // This compiles just fine despite the spelling mistake (extra 's'): // The type of `users` is any. const users = userList.where(user => user.getNames() === 'Jamie'); // Property `ssn` doesn't even exist on a `user`, yet it compiles. users.toArray()[0].ssn = '000000000'; // `usersWithId` is, again, just `any`. const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Oops, it's "id" not "ID", but TS doesn't help us. // We compile just fine. console.log(usersWithId.toArray()[0].ID); Da TypeScript nur weiß, dass der Typ aller Array-Elemente any ist, kann es uns zur Kompilierzeit nicht mit den nicht vorhandenen Eigenschaften oder der Funktion getNames , die nicht einmal existiert, sodass dieser Code zu mehreren unerwarteten Laufzeitfehlern führt .
Um ehrlich zu sein, sieht es langsam ziemlich düster aus. Wir haben versucht, unsere Datenstruktur für jeden konkreten Typ zu implementieren, den wir unterstützen wollten, aber wir haben schnell festgestellt, dass das in keiner Weise wartbar war. Dann dachten wir, wir würden etwas erreichen, indem wir any verwenden, was analog zu der Abhängigkeit von einem Root-Supertyp in einer Vererbungskette ist, von der alle Typen abgeleitet sind, aber wir kamen zu dem Schluss, dass wir mit dieser Methode die Typsicherheit verlieren. Was ist dann die Lösung?
Es stellt sich heraus, dass ich am Anfang des Artikels (irgendwie) gelogen habe:
"Zu diesem Zeitpunkt können Sie nicht jeden beliebigen Typ auf schöne, saubere Weise in eine Funktion oder Methode übernehmen."
Das können Sie tatsächlich, und hier kommen Generika ins Spiel. Beachten Sie, dass ich „an dieser Stelle“ gesagt habe, da ich davon ausgegangen bin, dass wir an dieser Stelle des Artikels nichts über Generika wussten.
Ich beginne damit, die vollständige Implementierung unserer Listenstruktur mit Generika zu zeigen, und dann treten wir einen Schritt zurück, diskutieren, was sie tatsächlich sind, und bestimmen ihre Syntax formaler. Ich habe es TypedList genannt, um es von unserer früheren AnyList zu unterscheiden:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. }Lassen Sie uns versuchen, die gleichen Fehler wie zuvor noch einmal zu machen:
// Here's the magic. `TypedList` will operate on objects // of type `User` due to the `<User>` syntax. const userList = TypedList.create<User>([new User('Jamie')]); // The compiler expects this. userList.add(new User('Tom')); userList.add(new User('Alice')); // Argument of type '0' is not assignable to parameter // of type 'User'. ts(2345) userList.add(0); // Property 'getNames' does not exist on type 'User'. // Did you mean 'getName'? ts(2551) // Note: TypeScript infers the type of `users` to be // `TypedList<User>` const users = userList.where(user => user.getNames() === 'Jamie'); // Property 'ssn' does not exist on type 'User'. ts(2339) users.toArray()[0].ssn = '000000000'; // TypeScript infers `usersWithId` to be of type // `TypedList<`{ id: string, name: string }> const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Property 'ID' does not exist on type '{ id: string; name: string; }'. // Did you mean 'id'? ts(2551) console.log(usersWithId.toArray()[0].ID)Wie Sie sehen können, unterstützt uns der TypeScript-Compiler aktiv bei der Typsicherheit. Alle diese Kommentare sind Fehler, die ich vom Compiler erhalte, wenn ich versuche, diesen Code zu kompilieren. Generics haben es uns ermöglicht, einen Typ anzugeben, auf dem unsere Liste arbeiten soll, und davon kann TypeScript die Typen von allem bis hin zu den Eigenschaften einzelner Objekte innerhalb des Arrays erkennen.
Die von uns bereitgestellten Typen können so einfach oder komplex sein, wie wir es wünschen. Hier können Sie sehen, dass wir sowohl primitive als auch komplexe Schnittstellen übergeben können. Wir könnten auch andere Arrays oder Klassen oder irgendetwas übergeben:
const numberList = TypedList.create<number>(); numberList.add(4); const stringList = TypedList.create<string>(); stringList.add('Hello, World'); // Example of a complex type interface IAircraft { apuStatus: ApuStatus; inboardOneRPM: number; altimeter: number; tcasAlert: boolean; pushBackAndStart(): Promise<void>; ilsCaptureGlidescope(): boolean; getFuelStats(): IFuelStats; getTCASHistory(): ITCASHistory; } const aircraftList = TypedList.create<IAircraft>(); aircraftList.add(/* ... */); // Aggregate and generate report: const stats = aircraftList.select(a => ({ ...a.getFuelStats(), ...a.getTCASHistory() })); Die besonderen Verwendungen von T und U sowie <T> und <U> in der TypedList<T> sind Beispiele für Generics in Aktion. Nachdem wir unsere Anweisung zum Erstellen einer typsicheren Sammlungsstruktur erfüllt haben, lassen wir dieses Beispiel vorerst hinter uns und kehren zu ihm zurück, sobald wir verstanden haben, was Generics eigentlich sind, wie sie funktionieren und welche Syntax sie haben. Wenn ich ein neues Konzept lerne, beginne ich immer gerne mit einem komplexen Beispiel des verwendeten Konzepts, damit ich, wenn ich anfange, die Grundlagen zu lernen, Verbindungen zwischen den grundlegenden Themen und dem bestehenden Beispiel herstellen kann, das ich in meinem habe Kopf.
Was sind Generika?
Eine einfache Art, Generics zu verstehen, besteht darin, sie als relativ analog zu Platzhaltern oder Variablen zu betrachten, jedoch für Typen. Das soll nicht heißen, dass Sie mit einem generischen Typplatzhalter dieselben Operationen ausführen können wie mit einer Variablen, aber eine generische Typvariable könnte man sich als einen Platzhalter vorstellen, der einen konkreten Typ darstellt, der in Zukunft verwendet wird. Das heißt, die Verwendung von Generics ist eine Methode, Programme in Bezug auf Typen zu schreiben, die zu einem späteren Zeitpunkt spezifiziert werden sollen. Der Grund, warum dies nützlich ist, liegt darin, dass es uns ermöglicht, Datenstrukturen zu erstellen, die für die verschiedenen Typen, auf denen sie arbeiten, wiederverwendbar sind (oder typunabhängig).
Das ist nicht gerade die beste Erklärung, um es einfacher auszudrücken, wie wir gesehen haben, ist es bei der Programmierung üblich, dass wir möglicherweise eine Funktion/Klasse/Datenstruktur erstellen müssen, die mit einem bestimmten Typ arbeitet, aber Es ist ebenso üblich, dass eine solche Datenstruktur auch über eine Vielzahl unterschiedlicher Typen hinweg funktionieren muss. Wenn wir in einer Position feststecken müssten, in der wir den konkreten Typ statisch deklarieren müssten, auf dem eine Datenstruktur zum Zeitpunkt des Entwerfens der Datenstruktur (zur Kompilierzeit) arbeiten würde, würden wir sehr schnell feststellen, dass wir diese neu erstellen müssen Strukturen auf fast genau die gleiche Weise für jeden Typ, den wir unterstützen möchten, wie wir in den obigen Beispielen gesehen haben.
Generika helfen uns bei der Lösung dieses Problems, indem sie uns erlauben, die Forderung nach einem konkreten Typ aufzuschieben, bis dieser tatsächlich bekannt ist.
Generika in TypeScript
Wir haben jetzt eine ungefähre Vorstellung davon, warum Generika nützlich sind, und wir haben ein etwas kompliziertes Beispiel dafür in der Praxis gesehen. Für die meisten ist die TypedList<T> wahrscheinlich bereits sehr sinnvoll, insbesondere wenn Sie aus einem statisch typisierten Sprachhintergrund kommen, aber ich kann mich erinnern, dass ich Schwierigkeiten hatte, das Konzept zu verstehen, als ich zum ersten Mal lernte, also möchte ich es tun bauen Sie auf dieses Beispiel auf, indem Sie mit einfachen Funktionen beginnen. Konzepte im Zusammenhang mit der Abstraktion in Software können notorisch schwer zu verinnerlichen sein. Wenn der Begriff Generics also noch nicht ganz angekommen ist, ist das völlig in Ordnung, und hoffentlich wird die Idee am Ende dieses Artikels zumindest einigermaßen intuitiv sein.
Um dieses Beispiel zu verstehen, gehen wir von einfachen Funktionen aus. Wir beginnen mit der „Identitätsfunktion“, die von den meisten Artikeln, einschließlich der TypeScript-Dokumentation selbst, gerne verwendet wird.
Eine „Identitätsfunktion“ in der Mathematik ist eine Funktion, die ihre Eingabe direkt auf ihre Ausgabe abbildet, wie z. B. f(x) = x . Was man reinsteckt, bekommt man raus. Wir können das in JavaScript so darstellen:
function identity(input) { return input; }Oder, knapper:
const identity = input => input; Der Versuch, dies auf TypeScript zu portieren, bringt die gleichen Typsystemprobleme zurück, die wir zuvor gesehen haben. Die Lösungen sind die Eingabe mit any , von der wir wissen, dass sie selten eine gute Idee ist, das Duplizieren/Überladen der Funktion für jeden Typ (unterbricht DRY) oder die Verwendung von Generics.
Mit letzterer Option können wir die Funktion wie folgt darstellen:
// ES5 Function function identity<T>(input: T): T { return input; } // Arrow Function const identity = <T>(input: T): T => input; console.log(identity<number>(5)); // 5 console.log(identity<string>('hello')); // hello Die <T> -Syntax hier deklariert diese Funktion als generisch. So wie es uns eine Funktion erlaubt, einen beliebigen Eingabeparameter an ihre Argumentliste zu übergeben, können wir mit einer generischen Funktion auch einen beliebigen Typparameter übergeben.
Der Teil <T> der Signatur von identity<T>(input: T): T und <T>(input: T): T deklariert in beiden Fällen, dass die betreffende Funktion einen generischen Typparameter namens T akzeptiert. So wie Variablen einen beliebigen Namen haben können, so können das auch unsere generischen Platzhalter, aber es ist eine Konvention, einen Großbuchstaben „T“ („T“ für „Typ“) zu verwenden und sich nach Bedarf im Alphabet nach unten zu bewegen. Denken Sie daran, dass T ein Typ ist, also geben wir auch an, dass wir ein Funktionsargument der input mit einem Typ von T akzeptieren und dass unsere Funktion einen Typ von T . Das ist alles, was die Unterschrift sagt. Versuchen Sie, T = string in Ihrem Kopf zu lassen – ersetzen Sie alle T s durch string in diesen Signaturen. Sehen Sie, wie nichts so Magisches vor sich geht? Sehen Sie, wie ähnlich es der nicht-generischen Art und Weise ist, wie Sie Funktionen jeden Tag verwenden?
Denken Sie daran, was Sie bereits über TypeScript und Funktionssignaturen wissen. Wir sagen nur, dass T ein beliebiger Typ ist, den der Benutzer beim Aufrufen der Funktion bereitstellt, genau wie input ein beliebiger Wert ist, den der Benutzer beim Aufrufen der Funktion bereitstellt. In diesem Fall muss die input unabhängig vom Typ T sein, wenn die Funktion in der Zukunft aufgerufen wird.
Als nächstes „übergeben“ wir in der „Zukunft“ in den beiden Log-Anweisungen den konkreten Typ, den wir verwenden möchten, genau wie bei einer Variablen. Beachten Sie hier den Wechsel in der Wortwahl – in der Anfangsform der <T> signature -Signatur, wenn unsere Funktion deklariert wird, ist sie generisch – das heißt, sie funktioniert mit generischen Typen oder Typen, die später angegeben werden. Das liegt daran, dass wir nicht wissen, welchen Typ der Aufrufer verwenden möchte, wenn wir die Funktion tatsächlich schreiben. Aber wenn der Aufrufer die Funktion aufruft, weiß er genau, mit welchen Typen er arbeiten möchte, in diesem Fall string und number .
Sie können sich die Idee vorstellen, eine Protokollfunktion auf diese Weise in einer Bibliothek eines Drittanbieters zu deklarieren – der Autor der Bibliothek hat keine Ahnung, welche Typen die Entwickler, die die Bibliothek verwenden, verwenden möchten, also machen sie die Funktion generisch und verschieben im Wesentlichen die Notwendigkeit für konkrete Typen, bis sie tatsächlich bekannt sind.
Ich möchte betonen, dass Sie sich diesen Prozess ähnlich vorstellen sollten wie die Übergabe einer Variablen an eine Funktion, um ein intuitiveres Verständnis zu erlangen. Alles, was wir jetzt tun, ist, auch einen Typ zu übergeben.
An dem Punkt, an dem wir die Funktion mit dem number aufgerufen haben, könnte die Originalsignatur praktisch als identity(input: number): number angesehen werden. Und an dem Punkt, an dem wir die Funktion mit dem string Parameter aufgerufen haben, hätte die ursprüngliche Signatur genauso gut identity(input: string): string sein können. Sie können sich vorstellen, dass beim Anruf jedes generische T durch den konkreten Typ ersetzt wird, den Sie in diesem Moment angeben.
Erkundung der generischen Syntax
Es gibt unterschiedliche Syntaxen und Semantiken zum Angeben von Generika im Kontext von ES5-Funktionen, Pfeilfunktionen, Typaliasen, Schnittstellen und Klassen. Wir werden diese Unterschiede in diesem Abschnitt untersuchen.
Erkunden der generischen Syntax – Funktionen
Sie haben jetzt einige Beispiele für generische Funktionen gesehen, aber es ist wichtig zu beachten, dass eine generische Funktion mehr als einen generischen Typparameter akzeptieren kann, genau wie es Variablen können. Sie können wählen, ob Sie einen, zwei oder drei oder wie viele Typen Sie möchten, alle durch Kommas getrennt (wiederum genau wie Eingabeargumente).
Diese Funktion akzeptiert drei Eingabetypen und gibt zufällig einen davon zurück:
function randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } // Calling the function. // `value` has type `string | number | IAircraft` const value = randomValue< string, number, IAircraft >( myString, myNumber, myAircraft );Sie können auch sehen, dass die Syntax etwas anders ist, je nachdem, ob wir eine ES5-Funktion oder eine Pfeilfunktion verwenden, aber beide deklarieren die Typparameter in der Signatur:
const randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } Denken Sie daran, dass den Typen keine „Eindeutigkeitsbeschränkung“ auferlegt wird – Sie können jede beliebige Kombination übergeben, z. B. zwei string s und eine number . Genauso wie die Eingabeargumente für den Hauptteil der Funktion „im Gültigkeitsbereich“ sind, sind dies auch die generischen Typparameter. Das vorherige Beispiel zeigt, dass wir innerhalb des Hauptteils der Funktion vollen Zugriff auf T , U und V haben, und wir haben sie verwendet, um ein lokales 3-Tupel zu deklarieren.
Sie können sich vorstellen, dass diese Generika in einem bestimmten „Kontext“ oder innerhalb einer bestimmten „Lebensdauer“ wirken, und das hängt davon ab, wo sie deklariert werden. Generika für Funktionen befinden sich innerhalb der Funktionssignatur und des Funktionskörpers (und von verschachtelten Funktionen erstellte Closures), während Generika, die für eine Klasse oder Schnittstelle oder einen Typalias deklariert sind, für alle Member der Klasse oder Schnittstelle oder des Typalias gültig sind.
Der Begriff der Generika für Funktionen ist nicht auf „freie Funktionen“ oder „Floating-Funktionen“ (Funktionen, die nicht an ein Objekt oder eine Klasse angehängt sind, ein C++-Begriff) beschränkt, sondern sie können auch auf Funktionen verwendet werden, die an andere Strukturen angehängt sind.
Wir können diesen randomValue in einer Klasse platzieren und ihn genauso nennen:
class Utils { public randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // ... } // Or, as an arrow function: public randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // ... } }Wir könnten auch eine Definition innerhalb einer Schnittstelle platzieren:
interface IUtils { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }Oder innerhalb eines Typ-Alias:
type Utils = { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }Genau wie zuvor sind diese generischen Typparameter für diese bestimmte Funktion „im Geltungsbereich“ – sie sind nicht klassen-, schnittstellen- oder typaliasweit. Sie leben nur innerhalb der bestimmten Funktion, für die sie spezifiziert sind. Um einen generischen Typ für alle Mitglieder einer Struktur freizugeben, müssen Sie den Namen der Struktur selbst annotieren, wie wir weiter unten sehen werden.
Erkunden der generischen Syntax – Geben Sie Aliase ein
Bei Typaliasen wird die generische Syntax für den Namen des Alias verwendet.
Zum Beispiel könnte eine „Aktions“-Funktion, die einen Wert akzeptiert, möglicherweise diesen Wert mutiert, aber void zurückgibt, wie folgt geschrieben werden:
type Action<T> = (val: T) => void;Hinweis : Dies sollte C#-Entwicklern bekannt sein, die den Action<T>-Delegaten verstehen.
Oder eine Callback-Funktion, die sowohl einen Fehler als auch einen Wert akzeptiert, könnte als solche deklariert werden:
type CallbackFunction<T> = (err: Error, data: T) => void; const usersApi = { get(uri: string, cb: CallbackFunction<User>) { /// ... } }Mit unserem Wissen über Funktionsgenerika könnten wir noch weiter gehen und die Funktion auf dem API-Objekt ebenfalls generisch machen:
type CallbackFunction<T> = (err: Error, data: T) => void; const api = { // `T` is available for use within this function. get<T>(uri: string, cb: CallbackFunction<T>) { /// ... } } Nun, wir sagen, dass die get -Funktion einen generischen Typparameter akzeptiert, und was auch immer das ist, CallbackFunction empfängt ihn. Wir haben das T , das in get einfließt, im Wesentlichen als T für CallbackFunction „übergeben“. Vielleicht wäre dies sinnvoller, wenn wir die Namen ändern:
type CallbackFunction<TData> = (err: Error, data: TData) => void; const api = { get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } } Das Voranstellen von Typparametern mit T ist lediglich eine Konvention, genau wie das Präfixieren von Schnittstellen mit I oder Elementvariablen mit _ . Was Sie hier sehen können, ist, dass CallbackFunction einen Typ ( TData ) akzeptiert, der die für die Funktion verfügbare Datennutzlast darstellt, während get einen Typparameter akzeptiert, der den Datentyp/die Form der HTTP-Antwort ( TResponse ) darstellt. Der HTTP-Client ( api ) verwendet ähnlich wie Axios diese TResponse als TData für CallbackFunction . Dadurch kann der API-Aufrufer den Datentyp auswählen, den er von der API zurückerhält (angenommen, an anderer Stelle in der Pipeline haben wir Middleware, die JSON in ein DTO parst).
Wenn wir etwas weiter gehen wollten, könnten wir die generischen Typparameter von CallbackFunction ändern, um auch einen benutzerdefinierten Fehlertyp zu akzeptieren:
type CallbackFunction<TData, TError> = (err: TError, data: TData) => void;Und genau wie Sie Funktionsargumente optional machen können, können Sie dies auch mit Typparametern tun. Für den Fall, dass der Benutzer keinen Fehlertyp angibt, setzen wir ihn standardmäßig auf den Fehlerkonstruktor:
type CallbackFunction<TData, TError = Error> = (err: TError, data: TData) => void;Damit können wir jetzt einen Callback-Funktionstyp auf mehrere Arten angeben:
const apiOne = { // `Error` is used by default for `CallbackFunction`. get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } }; apiOne.get<string>('uri', (err: Error, data: string) => { // ... }); const apiTwo = { // Override the default and use `HttpError` instead. get<TResponse>(uri: string, cb: CallbackFunction<TResponse, HttpError>) { // ... } }; apiTwo.get<string>('uri', (err: HttpError, data: string) => { // ... });Diese Idee von Standardparametern ist für alle Funktionen, Klassen, Schnittstellen usw. akzeptabel – sie ist nicht nur auf Typaliase beschränkt. In allen Beispielen, die wir bisher gesehen haben, hätten wir jedem gewünschten Typparameter einen Standardwert zuweisen können. Typaliase können genau wie Funktionen beliebig viele generische Typparameter annehmen.
Erkundung der generischen Syntax – Schnittstellen
Wie Sie gesehen haben, kann einer Funktion auf einer Schnittstelle ein generischer Typparameter bereitgestellt werden:
interface IUselessFunctions { // Not generic printHelloWorld(); // Generic identity<T>(t: T): T; } In diesem Fall lebt T nur für die identity als Eingabe- und Rückgabetyp.
Wir können einen Typparameter auch allen Membern einer Schnittstelle zur Verfügung stellen, genau wie bei Klassen und Typaliasen, indem wir angeben, dass die Schnittstelle selbst ein Generikum akzeptiert. Wir werden etwas später über das Repository-Muster sprechen, wenn wir komplexere Anwendungsfälle für Generika diskutieren, also ist es in Ordnung, wenn Sie noch nie davon gehört haben. Das Repository-Muster ermöglicht es uns, unsere Datenspeicherung zu abstrahieren, um die Persistenz der Geschäftslogik unabhängig zu machen. Wenn Sie eine generische Repository-Schnittstelle erstellen möchten, die mit unbekannten Entitätstypen funktioniert, könnten wir sie wie folgt eingeben:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; removeById(id: string): Promise<void>; }Hinweis : Es gibt viele verschiedene Gedanken rund um Repositories, von der Definition von Martin Fowler bis zur Definition von DDD Aggregate. Ich versuche lediglich, einen Anwendungsfall für Generika zu zeigen, daher mache ich mir nicht allzu viele Gedanken darüber, bei der Implementierung vollständig korrekt zu sein. Es spricht definitiv etwas dafür, keine generischen Repositories zu verwenden, aber wir werden später darüber sprechen.
Wie Sie hier sehen können, ist IRepository eine Schnittstelle, die Methoden zum Speichern und Abrufen von Daten enthält. Es arbeitet mit einem generischen Typparameter namens T , und T wird als Eingabe für add und updateById sowie für das Ergebnis der Promise-Auflösung von findById .
Denken Sie daran, dass es einen sehr großen Unterschied gibt, ob Sie einen generischen Typparameter für den Schnittstellennamen akzeptieren oder ob Sie jeder Funktion selbst erlauben, einen generischen Typparameter zu akzeptieren. Ersteres stellt, wie wir es hier getan haben, sicher, dass jede Funktion innerhalb der Schnittstelle auf demselben Typ T arbeitet. Das heißt, für ein IRepository<User> arbeitet jetzt jede Methode, die T in der Schnittstelle verwendet, an User . Mit der letzteren Methode könnte jede Funktion mit dem gewünschten Typ arbeiten. Es wäre sehr eigenartig, nur User zum Repository hinzufügen zu können, aber zum Beispiel Policies oder Orders zurückerhalten zu können, was die potenzielle Situation wäre, in der wir uns befinden würden, wenn wir nicht erzwingen könnten, dass der Typ ist einheitlich über alle Methoden.
Eine bestimmte Schnittstelle kann nicht nur einen gemeinsam genutzten Typ enthalten, sondern auch Typen, die für ihre Mitglieder eindeutig sind. Wenn wir beispielsweise ein Array nachahmen möchten, könnten wir eine Schnittstelle wie folgt eingeben:
interface IArray<T> { forEach(func: (elem: T, index: number) => void): this; map<U>(func: (elem: T, index: number) => U): IArray<U>; } In diesem Fall haben sowohl forEach als auch map über den Schnittstellennamen Zugriff auf T Wie bereits erwähnt, können Sie sich vorstellen, dass T für alle Member der Schnittstelle gilt. Trotzdem hindert nichts einzelne Funktionen daran, auch ihre eigenen Typparameter zu akzeptieren. Die map funktioniert mit U . Jetzt hat map Zugriff auf T und U . Wir mussten dem Parameter einen anderen Buchstaben geben, z. B. U , weil T bereits vergeben ist und wir keine Namenskollision wollen. Wie der Name schon sagt, wird map Elemente des Typs T innerhalb des Arrays auf neue Elemente des Typs U „abbilden“. Es bildet T s auf U s ab. Der Rückgabewert dieser Funktion ist die Schnittstelle selbst, die jetzt mit dem neuen Typ U arbeitet, sodass wir die fließende verkettbare Syntax von JavaScript für Arrays etwas nachahmen können.
Wir werden in Kürze ein Beispiel für die Leistungsfähigkeit von Generics und Interfaces sehen, wenn wir das Repository-Pattern implementieren und Dependency Injection diskutieren. Auch hier können wir beliebig viele generische Parameter akzeptieren sowie einen oder mehrere Standardparameter auswählen, die am Ende einer Schnittstelle gestapelt sind.
Erkunden der generischen Syntax – Klassen
Ähnlich wie wir einen generischen Typparameter an einen Typalias, eine Funktion oder eine Schnittstelle übergeben können, können wir auch einen oder mehrere an eine Klasse übergeben. Dadurch wird dieser Typparameter allen Mitgliedern dieser Klasse sowie erweiterten Basisklassen oder implementierten Schnittstellen zugänglich.
Lassen Sie uns eine weitere Sammlungsklasse erstellen, die jedoch etwas einfacher als TypedList oben ist, damit wir die Interoperabilität zwischen generischen Typen, Schnittstellen und Membern sehen können. Etwas später sehen wir ein Beispiel für die Übergabe eines Typs an eine Basisklasse und Schnittstellenvererbung.
Unsere Sammlung unterstützt lediglich grundlegende CRUD-Funktionen zusätzlich zu einer map und einer forEach Methode.
class Collection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): Collection<U> { return new Collection<U>(this.elements.map(func)); } } const stringCollection = new Collection<string>(); stringCollection.add('Hello, World!'); const numberCollection = new Collection<number>(); numberCollection.add(3.14159); const aircraftCollection = new Collection<IAircraft>(); aircraftCollection.add(myAircraft); Lassen Sie uns diskutieren, was hier vor sich geht. Die Collection -Klasse akzeptiert einen generischen Typparameter namens T . Dieser Typ wird für alle Mitglieder der Klasse zugänglich. Wir verwenden es, um ein privates Array vom Typ T[] zu definieren, das wir auch in der Form Array<T> hätten bezeichnen können (Siehe wieder Generics für die normale Typisierung von TS-Arrays). Darüber hinaus verwenden die meisten Memberfunktionen dieses T auf irgendeine Weise, indem sie beispielsweise die Typen steuern, die hinzugefügt und entfernt werden, oder prüfen, ob die Sammlung ein Element enthält.

Schließlich benötigt die map -Methode, wie wir bereits gesehen haben, ihren eigenen generischen Typparameter. We need to define in the signature of map that some type T is mapped to some type U through a callback function, thus we need a U . That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named U , and that'd be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can't do is have another function that accepts a generic parameter named T , for that'd conflict with the T from the class signature.
You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with string s, number s, and IAircraft s.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we'll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let's define it:
interface ICollection<T> { add(t: T): void; contains(t: T): boolean; remove(t: T): void; forEach(func: (elem: T, index: number) => void): void; map<U>(func: (elem: T, index: number) => U): ICollection<U>; }Now, let's suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.
class InMemoryCollection<T> implements ICollection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): ICollection<U> { return new InMemoryCollection<U>(this.elements.map(func)); } } The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don't know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type T , and whatever it is, it's immediately passed to the interface, and the interface methods are implemented using that type.
Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the // tutorial. const userCollection: ICollection<User> = new InMemoryCollection<User>(); function manageUsers(userCollection: ICollection<User>) { userCollection.add(new User()); } With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection<T> (for example) with InMemoryCollection<T> instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
At this point, we should have worked up to the point where we can understand that first TypedList<T> example. Here it is again:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. } The class itself accepts a generic type parameter named T , and all members of the class are provided access to it. The instance method select and the two static methods from and create , which are factories, accept their own generic type parameter named U .
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[] . When it calls the list's constructor with new , it passes that type U as the generic parameter to TypedList . This creates a new list where the type of every element is U . It is exactly the same as how we could call the constructor of our collection class earlier with new Collection<SomeType>() . The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I've stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass { private constructor (t: number) {} public static create(u: number) { return new MyClass(u); } } const myClass = MyClass.create(2.17); This is very similar to what is happening with the more-involved example, the difference being that we're working on generic type parameters, not variables. Here, 2.17 becomes the u in create , which ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass<T> { private constructor () {} public static create<U>() { return new MyClass<U>(); } } const myClass = MyClass.create<number>(); The U passed to create is ultimately passed in as the T for MyClass<T> . When calling create , we provided number as U , thus now U = number . We put that U (which, again, is just number ) into the T for MyClass<T> , so that MyClass<T> effectively becomes MyClass<number> . The benefit of generics is that we're opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U . It uses that type U , just like create , to construct a new instance of the TypedList class, now passing in that type U for T .
The where instance method performs a filtering operation based upon a predicate function. There's no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript's array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don't satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type T , which is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T . The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we'll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we've used generics, we've explicitly defined the type we're operating on. It's important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number :
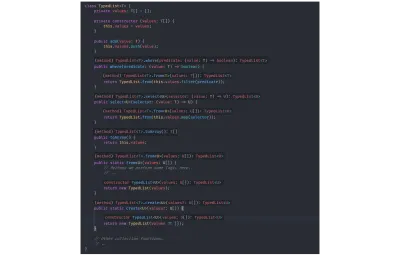
// `value` is inferred as type `number`. const value = identity(getRandomNumber()); Um die Typinferenz zu demonstrieren, habe ich zuvor alle technisch irrelevanten Typannotationen aus unserer TypedList Struktur entfernt, und Sie können anhand der folgenden Bilder sehen, dass TSC immer noch alle Typen korrekt ableitet:
TypedList ohne überflüssige Typdeklarationen:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T) { this.values.push(value); } public where(predicate: (value: T) => boolean) { return TypedList.from(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U) { return TypedList.from(this.values.map(selector)); } public toArray() { return this.values; } public static from<U>(values: U[]) { // Perhaps we perform some logic here. // ... return new TypedList(values); } public static create<U>(values?: U[]) { return new TypedList(values ?? []); } // Other collection functions. // .. } Basierend auf den Rückgabewerten der Funktion und basierend auf den Eingabetypen, die from und dem Konstruktor übergeben werden, versteht TSC alle Typinformationen. Auf dem Bild unten habe ich mehrere Bilder zusammengefügt, die die Spracherweiterung von Visual Studio Code TypeScript (und damit den Compiler) zeigen, die alle Typen ableitet:
Allgemeine Einschränkungen
Manchmal möchten wir einen generischen Typ einschränken. Vielleicht können wir nicht jeden existierenden Typ unterstützen, aber wir können eine Teilmenge davon unterstützen. Angenommen, wir möchten eine Funktion erstellen, die die Länge einer Sammlung zurückgibt. Wie oben gesehen, könnten wir viele verschiedene Arten von Arrays/Sammlungen haben, vom Standard-JavaScript Array bis zu unseren benutzerdefinierten. Wie teilen wir unserer Funktion mit, dass ein generischer Typ eine length hat? Wie schränken wir in ähnlicher Weise die konkreten Typen, die wir an die Funktion übergeben, auf diejenigen ein, die die benötigten Daten enthalten? Ein Beispiel wie dieses würde beispielsweise nicht funktionieren:
function getLength<T>(collection: T): number { // Error. TS does not know that a type T contains a `length` property. return collection.length; }Die Antwort ist die Verwendung generischer Beschränkungen. Wir können eine Schnittstelle definieren, die die Eigenschaften beschreibt, die wir brauchen:
interface IHasLength { length: number; }Wenn wir nun unsere generische Funktion definieren, können wir den generischen Typ auf einen Typ beschränken, der diese Schnittstelle erweitert:
function getLength<T extends IHasLength>(collection: T): number { // Restricting `collection` to be a type that contains // everything within the `IHasLength` interface. return collection.length; }Beispiele aus der Praxis
In den nächsten Abschnitten werden wir einige reale Beispiele für Generika besprechen, die eleganteren und einfacher zu begründenden Code erzeugen. Wir haben viele triviale Beispiele gesehen, aber ich möchte einige Ansätze zur Fehlerbehandlung, Datenzugriffsmuster und Front-End-React-Status/Requisiten diskutieren.
Beispiele aus der Praxis – Ansätze zur Fehlerbehandlung
JavaScript enthält wie die meisten Programmiersprachen einen erstklassigen Mechanismus zur Fehlerbehandlung – try / catch . Trotzdem bin ich kein großer Fan davon, wie es aussieht, wenn es verwendet wird. Das soll nicht heißen, dass ich den Mechanismus nicht benutze, aber ich neige dazu, ihn so gut wie möglich zu verstecken. Indem ich try / catch away abstrahiere, kann ich auch die Fehlerbehandlungslogik für wahrscheinlich fehlschlagende Operationen wiederverwenden.
Angenommen, wir bauen eine Datenzugriffsschicht. Dies ist eine Schicht der Anwendung, die die Persistenzlogik für den Umgang mit der Datenspeichermethode umschließt. Wenn wir Datenbankoperationen durchführen und diese Datenbank in einem Netzwerk verwendet wird, treten wahrscheinlich bestimmte DB-spezifische Fehler und vorübergehende Ausnahmen auf. Einer der Gründe für eine dedizierte Datenzugriffsschicht besteht darin, die Datenbank von der Geschäftslogik zu abstrahieren. Aus diesem Grund können solche DB-spezifischen Fehler nicht auf den Stapel und aus dieser Schicht geworfen werden. Wir müssen sie zuerst einpacken.
Schauen wir uns eine typische Implementierung an, die try / catch verwenden würde:
async function queryUser(userID: string): Promise<User> { try { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Das Umschalten auf true ist lediglich eine Methode, um die switch case -Anweisungen für meine Fehlerprüflogik verwenden zu können, anstatt eine Kette von if/else if deklarieren zu müssen – ein Trick, den ich zum ersten Mal von @Jeffijoe gehört habe.
Wenn wir mehrere solcher Funktionen haben, müssen wir diese Error-Wrapping-Logik replizieren, was eine sehr schlechte Praxis ist. Für eine Funktion sieht es ganz gut aus, aber für viele wird es ein Albtraum. Um diese Logik zu abstrahieren, können wir sie in eine benutzerdefinierte Fehlerbehandlungsfunktion einschließen, die das Ergebnis durchläuft, aber alle Fehler abfängt und umschließt, falls sie ausgelöst werden:
async function withErrorHandling<T>( dalOperation: () => Promise<T> ): Promise<T> { try { // This unwraps the promise and returns the type `T`. return await dalOperation(); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } Um sicherzustellen, dass dies sinnvoll ist, haben wir eine Funktion mit dem withErrorHandling , die einen generischen Typparameter T akzeptiert. Dieses T stellt den Typ des erfolgreichen Auflösungswerts des Versprechens dar, das wir von der Callback-Funktion dalOperation . Da wir nur das Rückgabeergebnis der dalOperation Funktion zurückgeben, müssten wir normalerweise nicht darauf await , da dies die Funktion in ein zweites irrelevantes Promise packen würde, und wir könnten das await dem aufrufenden Code überlassen. In diesem Fall müssen wir alle Fehler abfangen, daher ist await erforderlich.
Wir können diese Funktion jetzt verwenden, um unsere DAL-Operationen von früher zu umschließen:
async function queryUser(userID: string) { return withErrorHandling<User>(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); }); }Und los geht's. Wir haben eine typsichere und fehlersichere Benutzerabfragefunktion.
Außerdem müssen Sie, wie Sie bereits gesehen haben, wenn der TypeScript-Compiler über genügend Informationen verfügt, um die Typen implizit abzuleiten, diese nicht explizit übergeben. In diesem Fall weiß TSC, dass das Rückgabeergebnis der Funktion der generische Typ ist. Wenn also mapper.toDomain(user) den Typ User zurückgibt, müssten Sie den Typ überhaupt nicht übergeben:
async function queryUser(userID: string) { return withErrorHandling(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(user); }); } Ein weiterer Ansatz zur Fehlerbehandlung, der mir eher gefällt, ist der der monadischen Typen. Die Entweder-Monade ist ein algebraischer Datentyp der Form Either<T, U> , wobei T einen Fehlertyp und U einen Fehlertyp darstellen kann. Die Verwendung monadischer Typen orientiert sich an der funktionalen Programmierung, und ein großer Vorteil besteht darin, dass Fehler typsicher werden – eine normale Funktionssignatur sagt dem API-Aufrufer nichts darüber, welche Fehler diese Funktion auslösen könnte. Angenommen, wir werfen einen NotFound Fehler innerhalb von queryUser aus. Eine Signatur von queryUser(userID: string): Promise<User> sagt uns nichts darüber. Aber eine Signatur wie queryUser(userID: string): Promise<Either<NotFound, User>> tut es absolut. Ich werde in diesem Artikel nicht erklären, wie Monaden wie die Entweder-Monade funktionieren, da sie ziemlich komplex sein können und es eine Vielzahl von Methoden gibt, die sie als monadisch betrachten müssen, wie z. B. Mapping/Binding. Wenn Sie mehr darüber erfahren möchten, empfehle ich zwei von Scott Wlaschins NDC-Vorträgen, hier und hier, sowie den Vortrag von Daniel Chambers hier. Diese Website sowie diese Blog-Posts können ebenfalls nützlich sein.
Beispiele aus der Praxis – Repository-Muster
Werfen wir einen Blick auf einen anderen Anwendungsfall, bei dem Generika hilfreich sein könnten. Die meisten Back-End-Systeme müssen auf irgendeine Weise mit einer Datenbank verbunden sein – dies könnte eine relationale Datenbank wie PostgreSQL, eine Dokumentendatenbank wie MongoDB oder vielleicht sogar eine Graphdatenbank wie Neo4j sein.
Da wir als Entwickler niedrig gekoppelte und hoch kohäsive Designs anstreben sollten, wäre es ein faires Argument, darüber nachzudenken, welche Auswirkungen die Migration von Datenbanksystemen haben könnte. Es wäre auch fair zu berücksichtigen, dass unterschiedliche Datenzugriffsanforderungen möglicherweise unterschiedliche Datenzugriffsansätze bevorzugen (dies fängt an, ein wenig in CQRS einzudringen, was ein Muster zum Trennen von Lese- und Schreibvorgängen ist. Siehe Martin Fowlers Beitrag und die MSDN-Liste, wenn Sie möchten Weitere Informationen finden Sie in den Büchern „Implementing Domain Driven Design“ von Vaughn Vernon und „Patterns, Principles, and Practices of Domain-Driven Design“ von Scott Millet. Wir sollten auch automatisierte Tests in Betracht ziehen. Die meisten Tutorials, die den Aufbau von Back-End-Systemen mit Node.js erklären, vermischen Datenzugriffscode mit Geschäftslogik und Routing. Das heißt, sie neigen dazu, MongoDB mit dem Mongoose-ODM zu verwenden, einen Active-Record-Ansatz zu verfolgen und keine saubere Trennung von Bedenken zu haben. Solche Techniken sind in großen Anwendungen verpönt; In dem Moment, in dem Sie sich entscheiden, ein Datenbanksystem auf ein anderes zu migrieren, oder in dem Sie feststellen, dass Sie einen anderen Ansatz für den Datenzugriff bevorzugen, müssen Sie diesen alten Datenzugriffscode herausreißen und durch neuen Code ersetzen. und hoffen, dass Sie unterwegs keine Fehler in Routing und Geschäftslogik eingeführt haben.
Sicher, Sie könnten argumentieren, dass Unit- und Integrationstests Regressionen verhindern, aber wenn diese Tests gekoppelt und abhängig von Implementierungsdetails sind, von denen sie unabhängig sein sollten, werden sie wahrscheinlich ebenfalls in dem Prozess brechen.
Ein gängiger Ansatz zur Lösung dieses Problems ist das Repository Pattern. Es besagt, dass wir beim Aufrufen von Code zulassen sollten, dass unsere Datenzugriffsschicht eine bloße In-Memory-Sammlung von Objekten oder Domänenentitäten nachahmt. Auf diese Weise können wir das Design eher dem Unternehmen als der Datenbank (Datenmodell) überlassen. Für große Anwendungen wird ein Architekturmuster namens Domain-Driven Design nützlich. Repositories im Repository Pattern sind Komponenten, am häufigsten Klassen, die die gesamte Logik für den Zugriff auf Datenquellen kapseln und intern enthalten. Damit können wir den Datenzugriffscode auf einer Ebene zentralisieren, was ihn leicht testbar und leicht wiederverwendbar macht. Darüber hinaus können wir eine Zuordnungsschicht dazwischen platzieren, die es uns ermöglicht, datenbankunabhängige Domänenmodelle auf eine Reihe von Eins-zu-Eins-Tabellenzuordnungen abzubilden. Jede im Repository verfügbare Funktion kann optional eine andere Datenzugriffsmethode verwenden, wenn Sie dies wünschen.
Es gibt viele verschiedene Ansätze und Semantiken für Repositories, Arbeitseinheiten, Datenbanktransaktionen über Tabellen hinweg und so weiter. Da dies ein Artikel über Generika ist, möchte ich nicht zu sehr ins Unkraut gehen, daher werde ich hier ein einfaches Beispiel veranschaulichen, aber es ist wichtig zu beachten, dass verschiedene Anwendungen unterschiedliche Anforderungen haben. Ein Repository für DDD-Aggregate wäre zum Beispiel ganz anders als das, was wir hier tun. Wie ich die Repository-Implementierungen hier darstelle, ist nicht so, wie ich sie in realen Projekten implementiere, da viele fehlende Funktionen und weniger als erwünschte Architekturpraktiken verwendet werden.
Nehmen wir an, wir haben Users und Tasks als Domänenmodelle. Dies könnten nur POTOs sein – einfache alte TypeScript-Objekte. Es gibt keine Vorstellung von einer darin gebackenen Datenbank, daher würden Sie beispielsweise User.save() nicht aufrufen, wie Sie es mit Mongoose tun würden. Mithilfe des Repository-Patterns können wir wie folgt einen Benutzer beibehalten oder eine Aufgabe aus unserer Geschäftslogik löschen:
// Querying the DB for a User by their ID. const user: User = await userRepository.findById(userID); // Deleting a Task by its ID. await taskRepository.deleteById(taskID); // Deleting a Task by its owner's ID. await taskRepository.deleteByUserId(userID);Sie können deutlich sehen, wie die ganze unordentliche und vorübergehende Datenzugriffslogik hinter dieser Repository-Fassade/Abstraktion verborgen ist, wodurch die Geschäftslogik unabhängig von Persistenzbedenken wird.
Beginnen wir mit dem Erstellen einiger einfacher Domänenmodelle. Dies sind die Modelle, mit denen der Anwendungscode interagiert. Sie sind hier anämisch, würden aber ihre eigene Logik haben, um Geschäftsinvarianten in der realen Welt zu befriedigen, das heißt, sie wären keine bloßen Datenbeutel.
interface IHasIdentity { id: string; } class User implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _username: string ) {} public get id() { return this._id; } public get username() { return this._username; } } class Task implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _title: string ) {} public get id() { return this._id; } public get title() { return this._title; } } Sie werden gleich sehen, warum wir Informationen zur Identitätstypisierung in eine Schnittstelle extrahieren. Diese Methode, Domänenmodelle zu definieren und alles durch den Konstruktor zu leiten, ist nicht so, wie ich es in der realen Welt machen würde. Darüber hinaus wäre es besser gewesen, sich auf eine abstrakte Domänenmodellklasse zu verlassen als auf die Schnittstelle, um die id -Implementierung kostenlos zu erhalten.
Da wir in diesem Fall davon ausgehen, dass viele der gleichen Persistenzmechanismen von verschiedenen Domänenmodellen gemeinsam genutzt werden, können wir für das Repository unsere Repository-Methoden auf eine generische Schnittstelle abstrahieren:
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; deleteById(id: string): Promise<void>; existsById(id: string): Promise<boolean>; }Wir könnten noch weiter gehen und auch ein generisches Repository erstellen, um Duplikate zu reduzieren. Der Kürze halber werde ich das hier nicht tun, und ich sollte anmerken, dass generische Repository-Schnittstellen wie diese und generische Repositorys im Allgemeinen dazu neigen, verpönt zu sein, da Sie möglicherweise bestimmte Entitäten haben, die schreibgeschützt oder schreibgeschützt sind -only, oder die nicht gelöscht werden können, oder ähnliches. Es kommt auf die Anwendung an. Außerdem haben wir keine Vorstellung von einer „Arbeitseinheit“, um eine Transaktion über Tabellen hinweg zu teilen, eine Funktion, die ich in der realen Welt implementieren würde, aber da dies eine kleine Demo ist, tue ich das nicht möchte zu technisch werden.
Beginnen wir mit der Implementierung unseres UserRepository . Ich werde eine IUserRepository -Schnittstelle definieren, die benutzerspezifische Methoden enthält, sodass der aufrufende Code von dieser Abstraktion abhängen kann, wenn wir die konkreten Implementierungen abhängig machen:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository implements IUserRepository { // There are 6 methods to implement here all using the // concrete type of `User` - Five from IRepository<User> // and the one above. }Das Task Repository wäre ähnlich, würde aber je nach Bedarf der Anwendung unterschiedliche Methoden enthalten.
Hier definieren wir eine Schnittstelle, die eine generische erweitert, also müssen wir den konkreten Typ übergeben, an dem wir arbeiten. Wie Sie an beiden Schnittstellen sehen können, haben wir die Vorstellung, dass wir diese POTO-Domänenmodelle einsenden und sie herausbekommen. Der aufrufende Code hat keine Ahnung, was der zugrunde liegende Persistenzmechanismus ist, und das ist der Punkt.
Die nächste Überlegung ist, dass wir abhängig von der gewählten Datenzugriffsmethode datenbankspezifische Fehler behandeln müssen. Wir könnten zum Beispiel Mongoose oder den Knex Query Builder hinter diesem Repository platzieren, und in diesem Fall müssen wir diese spezifischen Fehler behandeln – wir wollen nicht, dass sie in die Geschäftslogik münden, da dies die Trennung von Bedenken beeinträchtigen würde und einen größeren Kopplungsgrad einführen.
Lassen Sie uns ein Basis-Repository für die Datenzugriffsmethoden definieren, die wir verwenden möchten und die Fehler für uns behandeln können:
class BaseKnexRepository { // A constructor. /** * Wraps a likely to fail database operation within a function that handles errors by catching * them and wrapping them in a domain-safe error. * * @param dalOp The operation to perform upon the database. */ public async withErrorHandling<T>(dalOp: () => Promise<T>) { try { return await dalOp(); } catch (e) { // Use a proper logger: console.error(e); // Handle errors properly here. } } }Jetzt können wir diese Basisklasse im Repository erweitern und auf diese generische Methode zugreifen:
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository extends BaseKnexRepository implements IUserRepository { private readonly dbContext: Knex | Knex.Transaction; public constructor (private knexInstance: Knex | Knex.Transaction) { super(); this.dbContext = knexInstance; } // Example `findById` implementation: public async findById(id: string): Promise<User> { return this.withErrorHandling<User>(async () => { const dbUser = await this.dbContext<DbUser>() .select() .where({ user_id: id }) .first(); // Maps type DbUser to User return mapper.toDomain(dbUser); }); } // There are 5 methods to implement here all using the // concrete type of `User`. } Beachten Sie, dass unsere Funktion einen DbUser aus der Datenbank abruft und ihn einem User zuordnet, bevor er ihn zurückgibt. Dies ist das Data Mapper-Muster und es ist entscheidend für die Aufrechterhaltung der Trennung von Bedenken. DbUser ist eine Eins-zu-eins-Zuordnung zur Datenbanktabelle – es ist das Datenmodell, auf dem das Repository arbeitet – und ist daher stark von der verwendeten Datenspeichertechnologie abhängig. Aus diesem Grund verlassen DbUser s niemals das Repository und werden einem User zugeordnet, bevor sie zurückgegeben werden. Ich habe die DbUser Implementierung nicht gezeigt, aber es könnte auch nur eine einfache Klasse oder Schnittstelle sein.
Bisher ist es uns mit dem von Generics unterstützten Repository-Pattern gelungen, Bedenken hinsichtlich des Datenzugriffs in kleine Einheiten zu abstrahieren sowie die Typsicherheit und Wiederverwendbarkeit aufrechtzuerhalten.
Nehmen wir zum Schluss für Unit- und Integrationstests an, dass wir eine In-Memory-Repository-Implementierung beibehalten, sodass wir in einer Testumgebung dieses Repository einfügen und zustandsbasierte Assertionen auf der Festplatte ausführen können, anstatt uns über a lustig zu machen spöttischer Rahmen. Diese Methode zwingt alles dazu, sich auf die öffentlich zugänglichen Schnittstellen zu verlassen, anstatt zuzulassen, dass Tests an Implementierungsdetails gekoppelt werden. Da die einzigen Unterschiede zwischen den einzelnen Repositorys die Methoden sind, die sie unter der Schnittstelle ISomethingRepository hinzufügen, können wir ein generisches In-Memory-Repository erstellen und dieses innerhalb typspezifischer Implementierungen erweitern:
class InMemoryRepository<T extends IHasIdentity> implements IRepository<T> { protected entities: T[] = []; public findById(id: string): Promise<T> { const entityOrNone = this.entities.find(entity => entity.id === id); return entityOrNone ? Promise.resolve(entityOrNone) : Promise.reject(new NotFound()); } // Implement the rest of the IRepository<T> methods here. } Der Zweck dieser Basisklasse besteht darin, die gesamte Logik für die Handhabung der In-Memory-Speicherung auszuführen, damit wir sie nicht innerhalb von In-Memory-Testrepositorys duplizieren müssen. Aufgrund von Methoden wie findById muss dieses Repository verstehen, dass Entitäten ein id -Feld enthalten, weshalb die generische Einschränkung für die IHasIdentity Schnittstelle erforderlich ist. Wir haben diese Schnittstelle schon einmal gesehen – sie wurde von unseren Domänenmodellen implementiert.
Wenn es darum geht, das In-Memory-Benutzer- oder Aufgaben-Repository zu erstellen, können wir diese Klasse einfach erweitern und die meisten Methoden automatisch implementieren lassen:
class InMemoryUserRepository extends InMemoryRepository<User> { public async existsByUsername(username: string): Promise<boolean> { const userOrNone = this.entities.find(entity => entity.username === username); return Boolean(userOrNone); // or, return !!userOrNone; } // And that's it here. InMemoryRepository implements the rest. } Hier muss unser InMemoryRepository wissen, dass Entitäten Felder wie id und username haben, daher übergeben wir User als generischen Parameter. Der User implementiert bereits IHasIdentity , sodass die generische Einschränkung erfüllt ist, und wir geben auch an, dass wir auch eine username -Eigenschaft haben.
Wenn wir nun diese Repositories aus der Geschäftslogikschicht verwenden möchten, ist es ganz einfach:
class UserService { public constructor ( private readonly userRepository: IUserRepository, private readonly emailService: IEmailService ) {} public async createUser(dto: ICreateUserDTO) { // Validate the DTO: // ... // Create a User Domain Model from the DTO const user = userFactory(dto); // Persist the Entity await this.userRepository.add(user); // Send a welcome email await this.emailService.sendWelcomeEmail(user); } } (Beachten Sie, dass wir in einer echten Anwendung den Aufruf von emailService wahrscheinlich in eine Auftragswarteschlange verschieben würden, um der Anfrage keine Latenz hinzuzufügen und in der Hoffnung, bei Fehlern idempotente Wiederholungsversuche durchführen zu können (— nicht, dass das Senden von E-Mails besonders ist idempotent in erster Linie).Außerdem ist es auch fragwürdig, das gesamte Benutzerobjekt an den Dienst zu übergeben.Das andere zu beachtende Problem ist, dass wir uns hier in einer Position befinden könnten, in der der Server abstürzt, nachdem der Benutzer persistiert wurde, aber bevor die E-Mail vorhanden ist Es gibt Minderungsmuster, um dies zu verhindern, aber aus pragmatischen Gründen wird menschliches Eingreifen mit ordnungsgemäßer Protokollierung wahrscheinlich gut funktionieren).
Und los geht's – unter Verwendung des Repository-Patterns mit der Leistungsfähigkeit von Generics haben wir unsere DAL vollständig von unserer BLL entkoppelt und es geschafft, eine typsichere Schnittstelle mit unserem Repository herzustellen. Wir haben auch eine Möglichkeit entwickelt, schnell gleichermaßen typsichere In-Memory-Repositorys für Einheiten- und Integrationstests zu erstellen, die echte Blackbox- und Implementierungs-agnostische Tests ermöglichen. All dies wäre ohne generische Typen nicht möglich gewesen.
Als Haftungsausschluss möchte ich noch einmal darauf hinweisen, dass dieser Repository-Implementierung einiges fehlt. Ich wollte das Beispiel einfach halten, da der Fokus auf der Verwendung von Generika liegt, weshalb ich mich nicht um die Duplizierung gekümmert oder mich um Transaktionen gekümmert habe. Anständige Repository-Implementierungen würden einen eigenen Artikel benötigen, um sie vollständig und korrekt zu erklären, und die Implementierungsdetails ändern sich je nachdem, ob Sie N-Tier-Architektur oder DDD verwenden. Das heißt, wenn Sie das Repository-Pattern verwenden möchten, sollten Sie meine Implementierung hier in keiner Weise als Best Practice betrachten.
Beispiele aus der Praxis – React State & Requisiten
State, ref und der Rest der Hooks für React Functional Components sind ebenfalls generisch. Wenn ich eine Schnittstelle mit Eigenschaften für Task habe und eine Sammlung davon in einer React-Komponente speichern möchte, könnte ich dies wie folgt tun:
import React, { useState } from 'react'; export const MyComponent: React.FC = () => { // An empty array of tasks as the initial state: const [tasks, setTasks] = useState<Task[]>([]); // A counter: // Notice, type of `number` is inferred automatically. const [counter, setCounter] = useState(0); return ( <div> <h3>Counter Value: {counter}</h3> <ul> { tasks.map(task => ( <li key={task.id}> <TaskItem {...task} /> </li> )) } </ul> </div> ); }; Wenn wir außerdem eine Reihe von Props an unsere Funktion übergeben möchten, können wir den generischen Typ React.FC<T> verwenden und Zugriff auf props erhalten:
import React from 'react'; interface IProps { id: string; title: string; description: string; } export const TaskItem: React.FC<IProps> = (props) => { return ( <div> <h3>{props.title}</h3> <p>{props.description}</p> </div> ); }; Der Typ der props wird vom TS-Compiler automatisch als IProps abgeleitet.
Fazit
In diesem Artikel haben wir viele verschiedene Beispiele für Generics und ihre Anwendungsfälle gesehen, von einfachen Sammlungen über Ansätze zur Fehlerbehandlung bis hin zur Isolierung der Datenzugriffsebene und so weiter. Einfach ausgedrückt erlauben uns Generics, Datenstrukturen aufzubauen, ohne dass wir die genaue Zeit kennen müssen, zu der sie zur Kompilierzeit arbeiten werden. Hoffentlich trägt dies dazu bei, das Thema ein wenig mehr zu öffnen, den Begriff Generika ein wenig intuitiver zu machen und ihre wahre Kraft zu vermitteln.