
Der ultimative Leitfaden zum Erstellen skalierbarer Web Scraper mit Scrapy
Veröffentlicht: 2022-03-10Web Scraping ist eine Möglichkeit, Daten von Websites abzurufen, ohne Zugriff auf APIs oder die Datenbank der Website zu benötigen. Sie benötigen nur Zugriff auf die Daten der Website – solange Ihr Browser auf die Daten zugreifen kann, können Sie sie auslesen.
Realistischerweise könnten Sie die meiste Zeit einfach manuell durch eine Website gehen und die Daten per Kopieren und Einfügen „von Hand“ abrufen, aber in vielen Fällen würde Sie das viele Stunden manueller Arbeit kosten, die Sie am Ende kosten könnte viel mehr, als die Daten wert sind, besonders wenn Sie jemanden eingestellt haben, der die Aufgabe für Sie erledigt. Warum jemanden einstellen, der 1–2 Minuten pro Abfrage arbeitet, wenn Sie ein Programm bekommen können, das alle paar Sekunden automatisch eine Abfrage durchführt?
Angenommen, Sie möchten eine Liste der Oscar-Preisträger für den besten Film zusammen mit ihrem Regisseur, den Hauptdarstellern, dem Veröffentlichungsdatum und der Laufzeit zusammenstellen. Wenn Sie Google verwenden, können Sie sehen, dass es mehrere Websites gibt, die diese Filme nach Namen und möglicherweise einigen zusätzlichen Informationen auflisten, aber im Allgemeinen müssen Sie Links folgen, um alle gewünschten Informationen zu erfassen.
Offensichtlich wäre es unpraktisch und zeitaufwändig, jeden Link von 1927 bis heute durchzugehen und manuell zu versuchen, die Informationen auf jeder Seite zu finden. Beim Web Scraping müssen wir nur eine Website mit Seiten finden, die all diese Informationen enthalten, und dann unser Programm mit den richtigen Anweisungen in die richtige Richtung lenken.
In diesem Tutorial verwenden wir Wikipedia als unsere Website, da sie alle Informationen enthält, die wir benötigen, und verwenden dann Scrapy on Python als Tool zum Scrapen unserer Informationen.
Ein paar Vorbehalte, bevor wir beginnen:
Data Scraping beinhaltet die Erhöhung der Serverlast für die Site, die Sie scrapen, was höhere Kosten für die Unternehmen bedeutet, die die Site hosten, und eine geringere Qualität für andere Benutzer dieser Site. Die Qualität des Servers, auf dem die Website läuft, die Datenmenge, die Sie zu erhalten versuchen, und die Rate, mit der Sie Anfragen an den Server senden, werden die Auswirkungen, die Sie auf den Server haben, moderieren. Vor diesem Hintergrund müssen wir sicherstellen, dass wir uns an einige Regeln halten.
Die meisten Websites haben auch eine Datei namens robots.txt in ihrem Hauptverzeichnis. Diese Datei legt Regeln dafür fest, auf welche Verzeichnisse Seiten Scraper nicht zugreifen sollen. Auf der Seite mit den Allgemeinen Geschäftsbedingungen einer Website erfahren Sie normalerweise, welche Richtlinien zum Data Scraping gelten. Beispielsweise enthält die Konditionsseite von IMDB die folgende Klausel:
Roboter und Screen Scraping: Sie dürfen Data Mining, Roboter, Screen Scraping oder ähnliche Tools zum Sammeln und Extrahieren von Daten auf dieser Website nicht verwenden, außer mit unserer ausdrücklichen schriftlichen Zustimmung, wie unten angegeben.
Bevor wir versuchen, die Daten einer Website zu erhalten, sollten wir immer die Bedingungen der Website und robots.txt überprüfen, um sicherzustellen, dass wir legale Daten erhalten. Beim Erstellen unserer Scraper müssen wir auch sicherstellen, dass wir einen Server nicht mit Anfragen überfordern, die er nicht verarbeiten kann.
Glücklicherweise erkennen viele Websites die Notwendigkeit für Benutzer, Daten zu erhalten, und stellen die Daten über APIs zur Verfügung. Wenn diese verfügbar sind, ist es normalerweise viel einfacher, Daten über die API zu erhalten als durch Scraping.
Wikipedia erlaubt Data Scraping, solange die Bots nicht „viel zu schnell“ sind, wie in ihrer robots.txt angegeben. Sie bieten auch herunterladbare Datensätze, damit Benutzer die Daten auf ihren eigenen Maschinen verarbeiten können. Wenn wir zu schnell gehen, blockieren die Server automatisch unsere IP, also implementieren wir Timer, um ihre Regeln einzuhalten.
Erste Schritte, Installation relevanter Bibliotheken mit Pip
Lassen Sie uns zunächst Scrapy installieren.
Windows
Installieren Sie die neueste Version von Python von https://www.python.org/downloads/windows/
Hinweis: Windows-Benutzer benötigen außerdem Microsoft Visual C++ 14.0, das Sie hier von „Microsoft Visual C++ Build Tools“ herunterladen können.
Sie sollten auch sicherstellen, dass Sie die neueste Version von Pip haben.
Geben Sie in cmd.exe Folgendes ein:
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyDadurch werden Scrapy und alle Abhängigkeiten automatisch installiert.
Linux
Zuerst möchten Sie alle Abhängigkeiten installieren:
Geben Sie im Terminal Folgendes ein:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devSobald das alles installiert ist, geben Sie einfach Folgendes ein:
pip install --upgrade pipUm sicherzustellen, dass Pip aktualisiert wird, und dann:
pip install scrapyUnd es ist alles fertig.
Mac
Zuerst müssen Sie sicherstellen, dass Sie einen C-Compiler auf Ihrem System haben. Geben Sie im Terminal Folgendes ein:
xcode-select --installInstallieren Sie danach Homebrew von https://brew.sh/.
Aktualisieren Sie Ihre PATH-Variable, sodass Homebrew-Pakete vor Systempaketen verwendet werden:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcPython installieren:
brew install pythonUnd dann stellen Sie sicher, dass alles aktualisiert ist:
brew update; brew upgrade pythonDanach installieren Sie einfach Scrapy mit pip:
pip install Scrapy > ## Überblick über Scrapy, wie die Teile zusammenpassen, Parser, Spinnen uswSie werden ein Skript namens „Spider“ schreiben, das Scrapy ausführen soll, aber keine Sorge, Scrapy-Spinnen sind trotz ihres Namens überhaupt nicht beängstigend. Die einzige Ähnlichkeit, die Scrapy-Spinnen und echte Spinnen haben, ist, dass sie gerne im Netz kriechen.
Innerhalb der Spinne befindet sich eine von Ihnen definierte class , die Scrapy mitteilt, was zu tun ist. Zum Beispiel, wo mit dem Crawlen begonnen werden soll, welche Arten von Anfragen gestellt werden, wie Links auf Seiten gefolgt werden und wie Daten geparst werden. Sie können sogar benutzerdefinierte Funktionen hinzufügen, um Daten zu verarbeiten, bevor Sie sie wieder in eine Datei ausgeben.
Um unsere erste Spinne zu starten, müssen wir zuerst ein Scrapy-Projekt erstellen. Geben Sie dazu Folgendes in Ihre Befehlszeile ein:
scrapy startproject oscarsDadurch wird ein Ordner mit Ihrem Projekt erstellt.
Wir beginnen mit einer einfachen Spinne. Der folgende Code ist in ein Python-Skript einzugeben. Öffnen Sie ein neues Python-Skript in /oscars/spiders und nennen Sie es oscars_spider.py
Wir werden Scrapy importieren.
import scrapyDann beginnen wir mit der Definition unserer Spider-Klasse. Zuerst legen wir den Namen fest und dann die Domains, die der Spider schaben darf. Schließlich sagen wir der Spinne, wo sie mit dem Kratzen beginnen soll.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']Als nächstes brauchen wir eine Funktion, die die gewünschten Informationen erfasst. Im Moment nehmen wir nur den Seitentitel. Wir verwenden CSS, um das Tag zu finden, das den Titeltext trägt, und extrahieren es dann. Schließlich geben wir die Informationen an Scrapy zurück, damit sie protokolliert oder in eine Datei geschrieben werden.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data Speichern Sie nun den Code in /oscars/spiders/oscars_spider.py
Um diese Spinne auszuführen, gehen Sie einfach zu Ihrer Befehlszeile und geben Sie Folgendes ein:
scrapy crawl oscarsSie sollten eine Ausgabe wie diese sehen:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Herzlichen Glückwunsch, Sie haben Ihren ersten einfachen Scrapy-Schaber gebaut!

Vollständiger Code:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield dataNatürlich möchten wir, dass es ein bisschen mehr leistet, also schauen wir uns an, wie Scrapy zum Analysieren von Daten verwendet wird.
Machen wir uns zunächst mit der Scrapy-Shell vertraut. Die Scrapy-Shell kann Ihnen helfen, Ihren Code zu testen, um sicherzustellen, dass Scrapy die gewünschten Daten erfasst.
Um auf die Shell zuzugreifen, geben Sie Folgendes in Ihre Befehlszeile ein:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”Dadurch wird im Grunde die Seite geöffnet, auf die Sie es geleitet haben, und Sie können einzelne Codezeilen ausführen. Beispielsweise können Sie den Roh-HTML-Code der Seite anzeigen, indem Sie Folgendes eingeben:
print(response.text)Oder öffnen Sie die Seite in Ihrem Standardbrowser, indem Sie Folgendes eingeben:
view(response)Unser Ziel hier ist es, den Code zu finden, der die gewünschten Informationen enthält. Lassen Sie uns zunächst versuchen, nur die Namen der Filmtitel zu erfassen.
Der einfachste Weg, den benötigten Code zu finden, besteht darin, die Seite in unserem Browser zu öffnen und den Code zu untersuchen. In diesem Beispiel verwende ich Chrome DevTools. Klicken Sie einfach mit der rechten Maustaste auf einen beliebigen Filmtitel und wählen Sie „Inspizieren“:
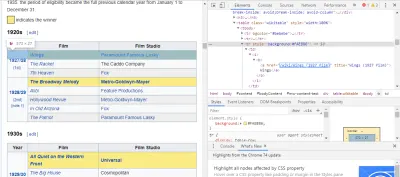
Wie Sie sehen können, haben die Oscar-Gewinner einen gelben Hintergrund, während die Nominierten einen einfachen Hintergrund haben. Es gibt auch einen Link zum Artikel über den Filmtitel, und die Links für Filme enden mit film) . Jetzt, da wir das wissen, können wir einen CSS-Selektor verwenden, um die Daten zu erfassen. Geben Sie in der Scrapy-Shell Folgendes ein:
response.css(r"tr[] a[href*='film)']").extract()Wie Sie sehen können, haben Sie jetzt eine Liste aller Oscar-Gewinner für den besten Film!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']Zurück zu unserem Hauptziel: Wir möchten eine Liste der Oscar-Gewinner für den besten Film zusammen mit ihrem Regisseur, den Hauptdarstellern, dem Veröffentlichungsdatum und der Laufzeit. Dazu benötigen wir Scrapy, um Daten von jeder dieser Filmseiten zu erfassen.
Wir müssen ein paar Dinge umschreiben und eine neue Funktion hinzufügen, aber keine Sorge, es ist ziemlich einfach.
Wir beginnen damit, den Scraper auf die gleiche Weise wie zuvor zu initiieren.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] Aber dieses Mal werden sich zwei Dinge ändern. Zuerst importieren wir time zusammen mit scrapy , weil wir einen Timer erstellen möchten, um zu beschränken, wie schnell der Bot scrapt. Wenn wir die Seiten zum ersten Mal analysieren, möchten wir außerdem nur eine Liste der Links zu jedem Titel erhalten, damit wir stattdessen Informationen von diesen Seiten abrufen können.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req Hier machen wir eine Schleife, um nach jedem Link auf der Seite zu suchen, film) mit dem gelben Hintergrund darin endet, und dann fügen wir diese Links zu einer Liste von URLs zusammen, die wir an die Funktion parse_titles senden, um sie weiterzugeben. Wir fügen auch einen Timer ein, damit er nur alle 5 Sekunden Seiten anfordert. Denken Sie daran, dass wir die Scrapy-Shell verwenden können, um unsere response.css -Felder zu testen, um sicherzustellen, dass wir die richtigen Daten erhalten!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data Die eigentliche Arbeit wird in unserer Funktion parse_data erledigt, wo wir ein Wörterbuch namens data erstellen und dann jeden Schlüssel mit den gewünschten Informationen füllen. Auch hier wurden alle diese Selektoren wie zuvor gezeigt mit Chrome DevTools gefunden und dann mit der Scrapy-Shell getestet.
Die letzte Zeile gibt das Datenwörterbuch zum Speichern an Scrapy zurück.
Vollständiger Code:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataManchmal möchten wir Proxys verwenden, da Websites versuchen, unsere Scraping-Versuche zu blockieren.
Dazu müssen wir nur ein paar Dinge ändern. In unserem Beispiel müssen wir es in unserem def parse() wie folgt ändern:
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqDadurch werden die Anfragen über Ihren Proxy-Server geleitet.
Bereitstellung und Protokollierung, zeigen, wie man einen Spider in der Produktion tatsächlich verwaltet
Jetzt ist es Zeit, unsere Spinne laufen zu lassen. Um Scrapy mit dem Scrapen zu beginnen und dann in eine CSV-Datei auszugeben, geben Sie Folgendes in Ihre Eingabeaufforderung ein:
scrapy crawl oscars -o oscars.csvSie sehen eine große Ausgabe, und nach ein paar Minuten ist sie abgeschlossen und Sie haben eine CSV-Datei in Ihrem Projektordner.
Ergebnisse kompilieren, zeigen, wie die in den vorherigen Schritten zusammengestellten Ergebnisse verwendet werden
Wenn Sie die CSV-Datei öffnen, sehen Sie alle gewünschten Informationen (sortiert nach Spalten mit Überschriften). Es ist wirklich so einfach.
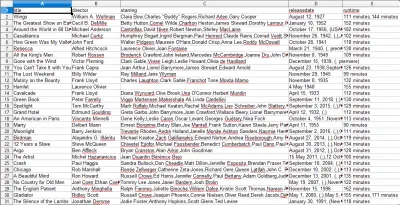
Mit Data Scraping können wir fast jeden benutzerdefinierten Datensatz erhalten, den wir wollen, solange die Informationen öffentlich verfügbar sind. Was Sie mit diesen Daten machen möchten, bleibt Ihnen überlassen. Diese Fähigkeit ist äußerst nützlich, um Marktforschung zu betreiben, Informationen auf einer Website auf dem neuesten Stand zu halten und vieles mehr.
Es ist ziemlich einfach, Ihren eigenen Web Scraper einzurichten, um selbst benutzerdefinierte Datensätze zu erhalten, aber denken Sie immer daran, dass es möglicherweise andere Möglichkeiten gibt, die benötigten Daten zu erhalten. Unternehmen investieren viel in die Bereitstellung der von Ihnen gewünschten Daten, daher ist es nur fair, dass wir ihre Geschäftsbedingungen respektieren.
Zusätzliche Ressourcen, um mehr über Scrapy und Web Scraping im Allgemeinen zu erfahren
- Die offizielle Scrapy-Website
- Scrapys GitHub-Seite
- „Die 10 besten Data Scraping Tools und Web Scraping Tools“, Scraper API
- „5 Tipps für Web Scraping, ohne blockiert oder auf die schwarze Liste gesetzt zu werden“, Scraper API
- Parsel, eine Python-Bibliothek zur Verwendung regulärer Ausdrücke zum Extrahieren von Daten aus HTML.