
Bäume in der Datenstruktur: 8 Arten von Bäumen, die jeder Datenwissenschaftler kennen sollte
Veröffentlicht: 2021-05-26Inhaltsverzeichnis
Einführung
In der Computerdomäne beziehen sich Datenstrukturen auf das Muster der Datenanordnung auf einer Platte, was eine bequeme Speicherung und Anzeige ermöglicht. Sie beziehen sich auf den Bereich Data Science, der für 2021 als lukrative Berufswahl prognostiziert wird. Basierend auf den Prognosen für die nächsten Jahre werden groß angelegte Deep-Learning-Modelle und Smart Devices der nächsten Generation die Zukunft von ebnen diesen Sektor.
Daher wäre der Erwerb von Kenntnissen über Datenstrukturen unerlässlich, um inmitten des technologischen Fortschritts eine geeignete Karriere zu finden. Laut der Prognose der Data Science Industry für 2021 würden die USA und Indien etwa 50.000 Datenwissenschaftler und 300.000 Datenanalysten in ihren über 2.50.000 Unternehmen beschäftigen. [1]
Datenstrukturen werden zum Entwerfen der Pfade zum Zuordnen, Verwalten und Abrufen von Informationen verwendet. Datenstrukturen sind insbesondere für die Erstellung und Verbesserung der Effizienz der insgesamt verarbeiteten Daten erforderlich. Sie verwalten die Daten, indem sie sie gruppieren und organisieren, um den Informationsaustausch effektiv zu erleichtern.
Bäume in Datenstrukturen
„Bäume“ sind eine Art von ADTs (Abstract Data Types), die bei ihrer Datenzuordnung einem hierarchischen Muster folgen. Im Wesentlichen ist ein Baum eine Sammlung mehrerer Knoten, die durch Kanten verbunden sind. Diese „Bäume“ bilden ein Datenstrukturdesign, das einem Baum ähnelt, wobei der „Wurzel“-Knoten zu „Eltern“-Knoten führt, die schließlich zu „Kind“-Knoten führen. Die Verbindungen werden mit Linien hergestellt, die als "Kanten" bekannt sind.
„Blatt“-Knoten sind Endpunkte, von denen keine weiteren Kinderknoten ausgehen. Bäume in Datenstrukturen spielen aufgrund der nichtlinearen Natur ihrer Anordnung eine entscheidende Rolle. Dies ermöglicht eine schnellere Reaktionszeit während einer Suche sowie Komfort während der gesamten Entwurfsphase.
Arten von Bäumen in der Datenstruktur
Die verschiedenen Arten von Bäumen in Datenstrukturen werden im Folgenden ausführlich erläutert:
1. Allgemeiner Baum
Ein allgemeiner Baum ist durch das Fehlen jeglicher Spezifikation oder Einschränkungen hinsichtlich der Anzahl von Kindern gekennzeichnet, die ein Knoten haben kann. Jeder Baum mit einer hierarchischen Struktur kann als allgemeiner Baum klassifiziert werden. Ein Knoten kann mehrere Kinder haben, und es kann jede Art von Kombination für die Ausrichtung des Baums geben. Die Knoten können jeden Grad haben, von 0 bis n.
Das Folgende ist ein klassisches Beispiel für einen allgemeinen Baum in der Datenstruktur, wobei „2“ ganz oben der Wurzelknoten ist.
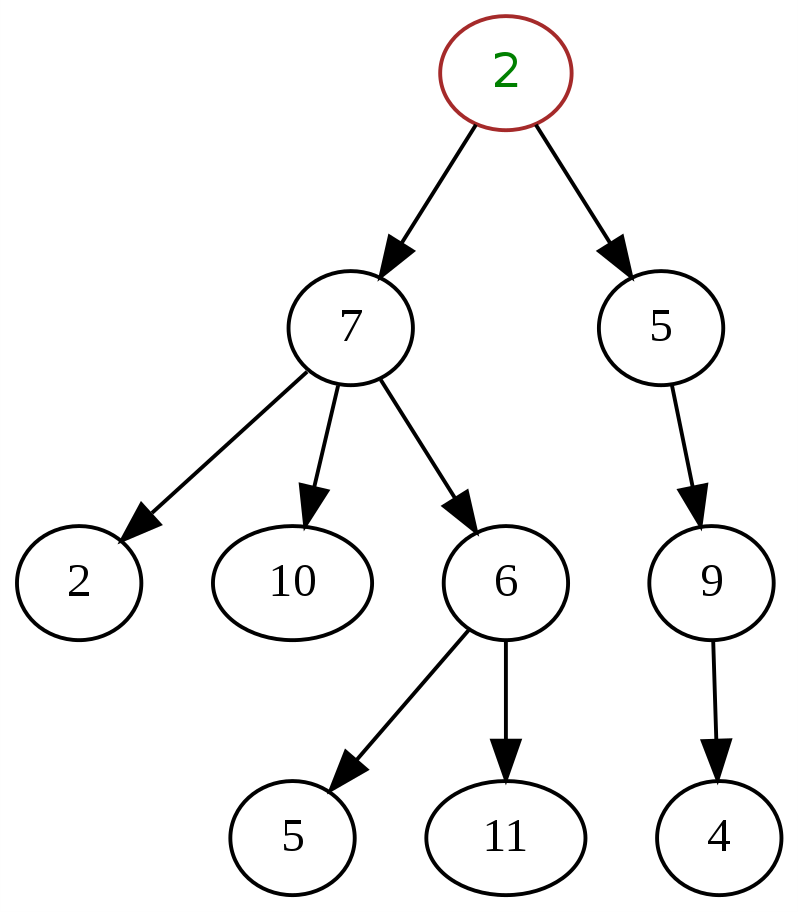
Quelle
2. Binärer Baum
Wie durch das Wort „binär“ definiert, was zwei Zahlen bedeutet, besteht ein binärer Baum aus Knoten, die zwei untergeordnete Knoten haben können. Jeder Knoten in einem Binärbaum kann höchstens 0, 1 oder 2 Knoten haben. Binäre Bäume in Datenstrukturen sind hochfunktionale ADTs und können weiter in viele Typen unterteilt werden. Sie werden hauptsächlich in Datenstrukturen für zwei Zwecke verwendet:
- Für den Zugriff auf Knoten und deren Kennzeichnung, wie in binären Suchbäumen beobachtet.
- Zur Darstellung von Daten durch eine Verzweigungsstruktur.
Das Folgende ist ein grundlegendes Diagramm eines binären Baums in einer Datenstruktur:
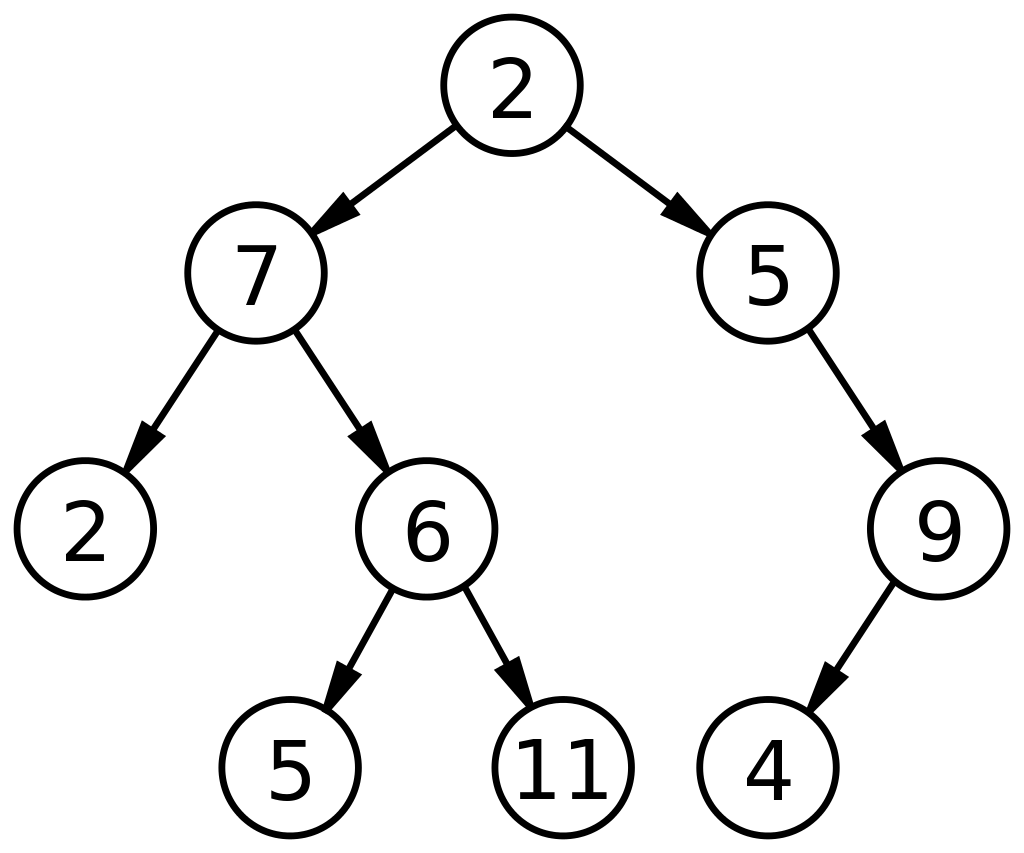
Quelle
3. Binärer Suchbaum
Ein binärer Suchbaum (BST) ist ein einzigartiger Untertyp binärer Bäume, die so angeordnet sind, dass sie ein schnelleres Suchen/Nachschlagen oder Hinzufügen/Entfernen von Daten ermöglichen. Ein BST wird durch die Darstellung der Knoten basierend auf drei Feldern definiert: den Daten, seinem linken Kind und seinem rechten Kind. Die bestimmenden Faktoren für BST sind:
- Jeder Knoten auf der linken Seite (linkes Kind) muss einen Wert enthalten, der kleiner ist als sein Elternknoten.
- Jeder Knoten auf der rechten Seite (rechtes Kind) muss einen Wert halten, der höher ist als sein Elternknoten.
Eine solche Anordnung reduziert die Suchzeiten auf die Hälfte einer linearen Suche, wie sie in einem Array gefunden wird. Somit sind binäre Suchbäume in Datenstrukturen im Vergleich zu anderen ADTs weit verbreitet zum Suchen und Sortieren anwendbar.
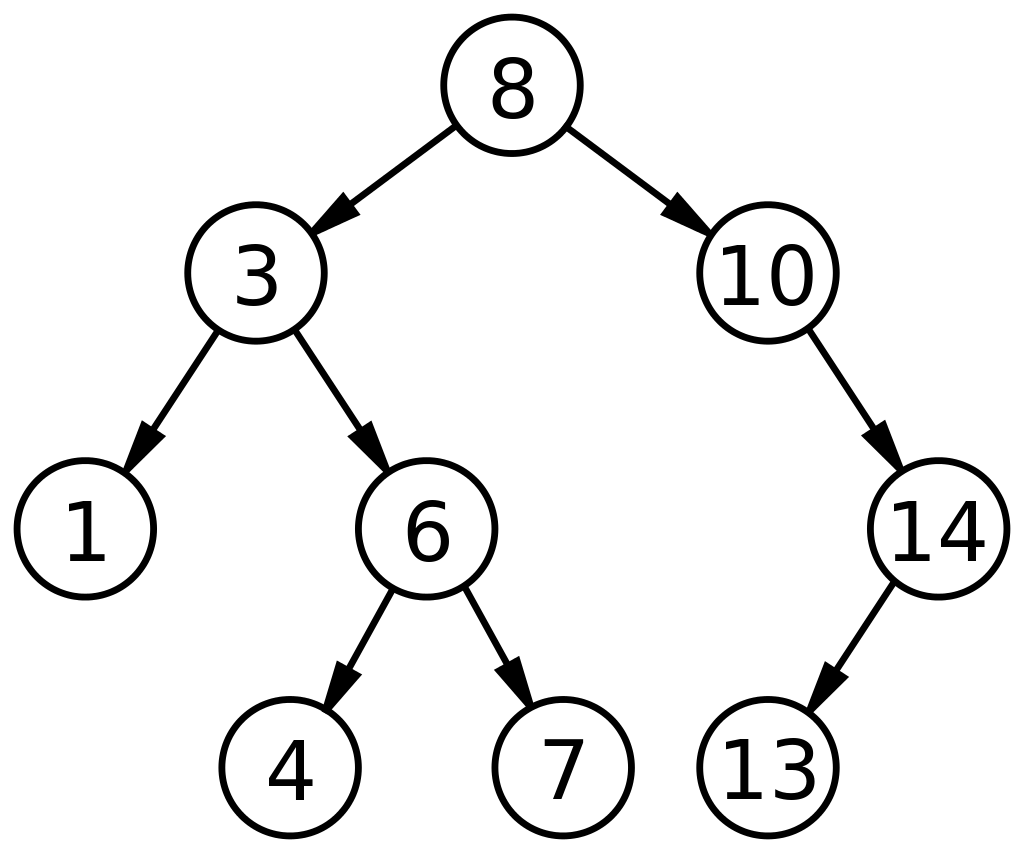
Quelle
Auch wenn sowohl BTs als auch BSTs im Wesentlichen Bäume in Datenstrukturen sind , lassen Sie sich nicht durch die Ähnlichkeit ihrer Namen verwirren. Erfahren Sie den Unterschied zwischen einem binären Baum und einem binären Suchbaum im Detail bei upGrad.
4. AVL-Baum
Der AVL-Baum leitet seinen Namen von seinen Erfindern ab: Adelson-Velsky und Landis. Der AVL-Baum zeichnet sich durch eine selbstausgleichende Natur aus. Die Höhen von zwei Teilbäumen seiner Wurzelknoten sind auf weniger als zwei beschränkt. Wenn der Höhenunterschied über 1 steigt, werden die untergeordneten Knoten neu ausbalanciert.
AVL-Bäume sind höhenausgeglichen, und dieser Ausgleich erfolgt durch einfache oder doppelte Drehungen. Der Ausgleichsfaktor ist die Differenz zwischen den Höhen des linken Teilbaums und des rechten Teilbaums, und die Werte sind -1, 0 und 1.
5. Roter schwarzer Baum
Diese Art ähnelt den AVL-Bäumen, da auch Rotschwarzbäume höhenausgeglichen sind. Was sie unterscheidet, ist, dass nicht mehr als zwei Umdrehungen erforderlich sind, um sie auszugleichen. Sie enthalten ein zusätzliches Bit, das die rote oder schwarze Farbe eines Knotens definiert, wodurch sichergestellt wird, dass die Bäume beim Löschen und Einfügen ausgeglichen sind. Die rot-schwarze Farbcodierung wird bei Änderungen ebenfalls neu gestrichen, jedoch fast ohne zusätzliche Speicherkosten.

6. Spreizbaum
Ein weiterer Untertyp des binären Suchbaums, der Splay-Baum, hat die einzigartige Eigenschaft, Rotationsoperationen durchzuführen, um den letzten Knoten anzupassen. Der Knoten, auf den kürzlich zugegriffen wurde, wird durch Ausführen einer Rotation als Wurzelknoten angeordnet. Es ist ein balancierter Baum, aber kein höhenbalancierter.
Der Akt des „Spreizens“ wird nach der anfänglichen binären Baumsuche ausgeführt, da Baumrotationen auf eine bestimmte Art und Weise durchgeführt werden. Nach jeder Operation wird der Baum gedreht, um sich selbst auszubalancieren, und das gesuchte Element wird oben als Wurzelknoten angeordnet.
7. Falle
„Treaps“ in Datenstrukturen sind eine Kombination aus Bäumen und Haufen. In BSTs muss der Wert des linken Kindes kleiner als der Wurzelknoten sein, und der Wert des rechten Kindes muss höher sein. In einer Heap-Datenstruktur hat der Wurzelknoten den niedrigsten Wert und seine untergeordneten Knoten (links und rechts) haben größere Werte.
Somit enthält ein Treap einen Wert in Form eines Schlüssels (ähnlich BSTs) und einer Priorität (wie Heaps). Die Knoten mit der höchsten Priorität werden zuerst so in einen binären Suchbaum eingefügt, dass die Prioritätszahlen unabhängige Zufallszahlen sind. Sie verwalten einen dynamischen Satz geordneter Schlüssel und ermöglichen binäre Suchen innerhalb ihrer Schlüssel.
8. B-Baum
Als selbstausgleichender Baum in Datenstrukturen sortiert B-Tree Daten, um Suchen, sequenziellen Zugriff, Löschungen und Einfügungen in logarithmischer Zeit zu ermöglichen. Im Gegensatz zu einem binären Baum erlaubt ein B-Baum seinen Knoten, mehr als zwei Kinder zu haben. Sie sind mit Datenbanken und Dateisystemen kompatibel, die größere Datenblöcke lesen und schreiben.
Ein B-Baum in Datenstrukturen wird für größere Speichersysteme wie Platten verwendet. Alle Blätter enthalten keine Informationen und erscheinen auf derselben Ebene. Interne Knoten eines B-Baums können eine variable Größe von untergeordneten Knoten haben, die durch einen Bereich gebunden sind.
Dies sind die Bäume in Datenstrukturen , die von Programmierern implementiert werden, die den Datenfluss entwerfen. Das Erlernen ihrer einzigartigen Eigenschaften und Anwendungen ist für Ihre Reise zum Data Scientist von entscheidender Bedeutung. Eine andere Methode, sich weiterzubilden, wäre das Üben durch verschiedene Projekte, die das Wissen über Bäume in Datenstrukturen und andere Formen von ADTs erfordern.
Um Ihr Wissen für DS-Projekte anzuwenden, finden Sie unter den folgenden Blog-Links 13 interessante Datenstruktur-Projektideen und Themen für Anfänger [2021] .
Fazit
Das Erlernen von Konzepten wie Bäumen in einer Datenstruktur kann schwierig sein, und Programmieraspiranten benötigen fachkundige Anleitung, um sich weiterzubilden. Um mehr über Bäume in einer Datenstruktur zu erfahren, besuchen Sie die Online-Kurse von upGrad . Executive PG Program in Software Development – Spezialisierung auf DevOps mit DevOps by IIIT-B & upGrad kann Ihnen helfen, Ihre Karriere als Programmierer aufzubauen.
Da die Beherrschung von Datenstrukturen ein wesentlicher Bestandteil des Codierungsprozesses ist, kann dies dem Studenten helfen, ein erfahrener Programmierer und Softwareentwickler zu werden. Programmierer und Data Scientists werden in den kommenden Jahrzehnten sicherlich gefragt sein .
Wir haben 500 Millionen Internetnutzer in Indien, die große Datenmengen generieren und verbrauchen, was die Beschäftigung von Tausenden von Datenwissenschaftlern erfordert, um die Nachfrage zu befriedigen. [2] Diese Datenwissenschaftler benötigen die richtige Ausbildung mit relevantem technologischem Fachwissen, um eine Anstellung in diesem Sektor zu finden.
Ein Executive PG Program in Software Development – Specialization in Full Stack Development , kuratiert von upGrad & IIIT-Bangalore, kann Ihnen helfen, Ihr Profil zu verbessern und sich bessere Beschäftigungsmöglichkeiten als Programmierer zu sichern.
- Ein Suchbaum ist eine Datenstruktur, die verwendet wird, um bestimmte Schlüssel innerhalb eines Datensatzes zu finden. Der Schlüssel jedes Knotens muss größer sein als alle Schlüssel in Unterbäumen auf der linken Seite, aber kleiner als die Schlüssel in Unterbäumen direkt rechts, damit ein Baum als Suchbaum fungiert. Hierarchische Daten wie Ordnerstruktur, Organisationsstruktur und XML/HTML-Daten sollten in Bäumen gespeichert werden. Ein perfekter binärer Baum ist einer, in dem jeder innere Knoten zwei Abkömmlinge hat und jedes Blatt die gleiche Tiefe oder Ebene hat. Das (nicht inzestuöse) Ahnendiagramm einer Person bis zu einer bestimmten Tiefe ist ein Beispiel für einen perfekten binären Baum, da jede Person genau zwei biologische Eltern (eine Mutter und einen Vater) hat.Welche Art von Bäumen kann für die Suche verwendet werden?<br />
- Wenn der Baum ziemlich ausgeglichen ist, das heißt, die Blätter an beiden Enden gleich tief sind, haben Suchbäume einen Vorteil in Bezug auf die Suchzeit. Es gibt eine Vielzahl von Suchbaum-Datenstrukturen, von denen einige zusätzlich ein effizientes Einfügen und Löschen von Elementen ermöglichen, wobei diese Aktionen dann das Baumgleichgewicht bewahren müssen.
- Ein assoziatives Array wird häufig mit Hilfe von Suchbäumen implementiert. Der Suchbaumalgorithmus lokalisiert einen Ort mithilfe des Schlüssels aus dem Schlüssel-Wert-Paar, und die Anwendung speichert dann das vollständige Schlüssel-Wert-Paar an diesem Ort.
- Binäre Suchbäume, B-Bäume, (a,b)-Bäume und ternäre Suchbäume sind Beispiele für Suchbäume. Was sind die Hauptanwendungen der Baumdatenstruktur?
1. Ein binärer Suchbaum ist ein Baum, mit dem Sie sortierte Daten schnell suchen, einfügen und löschen können. Es hilft Ihnen auch, den Artikel zu finden, der Ihnen am nächsten ist.
2. Heap ist eine Baumdatenstruktur, die Arrays verwendet und verwendet wird, um Prioritätswarteschlangen aufzubauen.
3. B-Tree und B+ Tree sind zwei Arten von Indizierungsbäumen, die in Datenbanken verwendet werden.
4. Compiler verwenden den Syntaxbaum.
5. Ein Raumunterteilungsbaum, der verwendet wird, um Punkte im K-dimensionalen Raum zu organisieren, ist als KD-Baum bekannt.
6. Trie ist eine Datenstruktur, die zum Erstellen von Wörterbüchern mit Präfixsuche verwendet wird.
7. Suffix Tree wird verwendet, um schnell nach Mustern in einem festen Text zu suchen.
8. In Computernetzwerken verwenden Router und Bridges Spanning Trees bzw. Shortest-Path Trees. Was ist ein perfekter Baum?