
Die 15 wichtigsten Fragen und Antworten zu Hadoop-Interviews im Jahr 2022
Veröffentlicht: 2021-01-09Mit der zunehmenden Dynamik der Datenanalyse ist die Nachfrage nach Menschen, die gut mit Big Data umgehen können, stark gestiegen. Von Datenanalysten bis hin zu Datenwissenschaftlern schafft Big Data heute eine Reihe von Berufsprofilen. Das Erste und Wichtigste, womit Sie praktisch umgehen müssen, ist Hadoop.
Unabhängig von Ihrer beruflichen Rolle/Ihrem Profil werden Sie wahrscheinlich auf die eine oder andere Weise an Hadoop arbeiten. Sie können also immer davon ausgehen, dass die Interviewer ein paar Hadoop-Fragen auf Ihre Art beantworten.
Sehen wir uns dazu und mehr die 15 wichtigsten Hadoop-Interviewfragen an, die Sie in jedem Vorstellungsgespräch erwarten können.
Was ist Hadoop? Was sind die Hauptkomponenten von Hadoop?
Hadoop ist eine Infrastruktur, die mit relevanten Tools und Diensten ausgestattet ist, die zur Verarbeitung und Speicherung von Big Data erforderlich sind. Genauer gesagt ist Hadoop die „Lösung“ für alle Big-Data-Herausforderungen. Darüber hinaus hilft das Hadoop-Framework Unternehmen auch dabei, Big Data zu analysieren und bessere Geschäftsentscheidungen zu treffen.
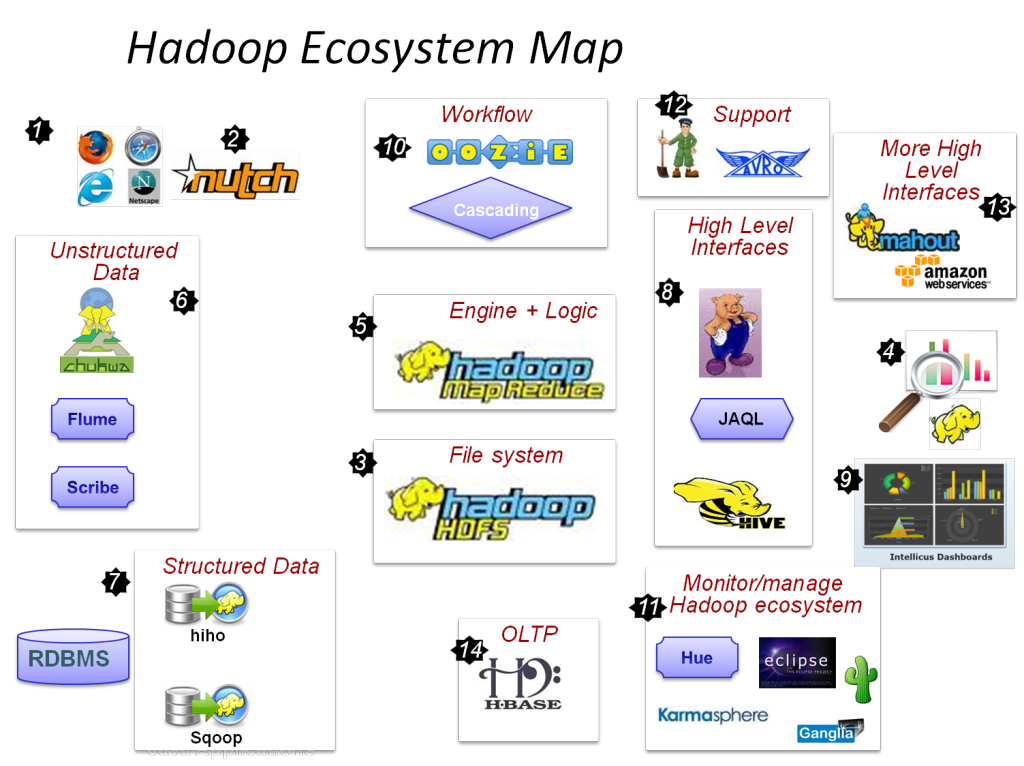
Die Hauptkomponenten von Hadoop sind:
- HDFS
- Hadoop MapReduce
- Hadoop-Common
- GARN
- PIG und HIVE – Die Datenzugriffskomponenten.
- HBase – Zur Datenspeicherung
- Ambari, Oozie und ZooKeeper – Datenverwaltungs- und Überwachungskomponente
- Thrift und Avro – Datenserialisierungskomponenten
- Apache Flume, Sqoop, Chukwa – Die Datenintegrationskomponenten
- Apache Mahout und Drill – Datenintelligenzkomponenten
Was sind die Kernkonzepte des Hadoop-Frameworks?
Hadoop basiert grundsätzlich auf zwei Kernkonzepten. Sie sind:
- HDFS: HDFS oder Hadoop Distributed File System ist ein Java-basiertes zuverlässiges Dateisystem, das zum Speichern großer Datensätze im Blockformat verwendet wird. Die Master-Slave-Architektur treibt es an.
- MapReduce: MapReduce ist eine Programmierstruktur, die bei der Verarbeitung großer Datensätze hilft. Diese Funktion ist weiter in zwei Teile unterteilt – während „map“ die Datensätze in Tupel aufteilt, verwendet „reduce“ die Map-Tupel und erstellt eine Kombination kleinerer Tupel-Blöcke.
Nennen Sie die gängigsten Eingabeformate in Hadoop?
Es gibt drei gängige Eingabeformate in Hadoop:
- Texteingabeformat: Dies ist das Standardeingabeformat in Hadoop.
- Sequence File Input Format: Dieses Eingabeformat wird zum sequenziellen Lesen von Dateien verwendet.
- Schlüsselwert-Eingabeformat: Dieses wird verwendet, um reine Textdateien zu lesen.
Was ist GARN?
YARN ist die Abkürzung für Yet Another Resource Negotiator. Es ist das Datenverarbeitungs-Framework von Hadoop, das Datenressourcen verwaltet und eine Umgebung für eine erfolgreiche Verarbeitung schafft. 
Was ist „Rack Awareness“?
„Rack Awareness“ ist ein Algorithmus, den NameNode verwendet, um das Muster zu bestimmen, in dem die Datenblöcke und ihre Replikate im Hadoop-Cluster gespeichert werden. Dies wird mit Hilfe von Rack-Definitionen erreicht, die die Überlastung zwischen Datenknoten reduzieren, die im selben Rack enthalten sind.

Was sind aktive und passive NameNodes?
Ein hochverfügbares Hadoop-System enthält normalerweise zwei NameNodes – Active NameNode und Passive NameNode.
Der NameNode, der den Hadoop-Cluster ausführt, wird als Active NameNode bezeichnet, und der Standby-NameNode, der die Daten des Active NameNode speichert, ist der Passive NameNode.
Der Zweck von zwei Namensknoten besteht darin, dass bei einem Absturz des aktiven Namensknotens der passive Namensknoten die Führung übernehmen kann. Somit läuft der NameNode immer im Cluster und das System fällt nie aus.
Was sind die verschiedenen Scheduler im Hadoop-Framework?
Es gibt drei verschiedene Planer im Hadoop-Framework:
- COSHH – COSHH hilft bei Planungsentscheidungen, indem es Cluster und Workload in Kombination mit Heterogenität überprüft.
- FIFO-Scheduler – FIFO ordnet Jobs basierend auf ihrer Ankunftszeit in einer Warteschlange an, ohne Heterogenität zu verwenden.
- Fair Sharing – Fair Sharing erstellt einen Pool für einzelne Benutzer, der mehrere Karten enthält, und reduziert Slots auf einer Ressource, die sie verwenden können, um bestimmte Jobs auszuführen.
Was ist spekulative Hinrichtung?
Im Hadoop-Framework werden einige Knoten häufig langsamer ausgeführt als die anderen. Dies neigt dazu, das gesamte Programm einzuschränken. Um dies zu umgehen, erkennt oder „spekuliert“ Hadoop zunächst, wenn eine Aufgabe langsamer als gewöhnlich ausgeführt wird, und startet dann ein entsprechendes Backup für diese Aufgabe. Während des Prozesses führt der Master-Knoten also beide Aufgaben gleichzeitig aus, und die zuerst erledigte wird akzeptiert, während die andere beendet wird. Diese Sicherungsfunktion von Hadoop ist als spekulative Ausführung bekannt.

Nennen Sie die Hauptkomponenten von Apache HBase?
Apache HBase besteht aus drei Komponenten:
- Region Server: Nachdem eine Tabelle in mehrere Regionen aufgeteilt wurde, werden Cluster dieser Regionen über den Region Server an die Clients weitergeleitet.
- HMaster: Dies ist ein Tool, das hilft, den Region-Server zu verwalten und zu koordinieren.
- ZooKeeper: ZooKeeper ist ein Koordinator innerhalb der verteilten HBase-Umgebung. Es hilft, einen Serverstatus innerhalb des Clusters durch Kommunikation in Sitzungen aufrechtzuerhalten.
Was ist „Checkpointing“? Was ist sein Nutzen?
Checkpointing bezieht sich auf das Verfahren, bei dem ein FsImage und ein Bearbeitungsprotokoll kombiniert werden, um ein neues FsImage zu bilden. Anstatt das Bearbeitungsprotokoll wiederzugeben, kann der NameNode daher direkt den endgültigen In-Memory-Zustand aus dem FsImage laden. Für diesen Vorgang ist der sekundäre NameNode zuständig.
Der Vorteil von Checkpointing besteht darin, dass es die Startzeit des NameNode minimiert und dadurch den gesamten Prozess effizienter macht.
Big Data-Anwendungen in der Popkultur
Wie debuggt man einen Hadoop-Code?
Um einen Hadoop-Code zu debuggen, müssen Sie zunächst die Liste der derzeit ausgeführten MapReduce-Aufgaben überprüfen. Dann müssen Sie überprüfen, ob gleichzeitig verwaiste Tasks ausgeführt werden. Wenn dies der Fall ist, müssen Sie den Speicherort der Resource Manager-Protokolle finden, indem Sie diesen einfachen Schritten folgen:
Führen Sie „ps –ef | grep –I ResourceManager“ und versuchen Sie im angezeigten Ergebnis herauszufinden, ob ein Fehler in Bezug auf eine bestimmte Job-ID vorliegt.
Identifizieren Sie nun den Worker-Knoten, der zum Ausführen der Aufgabe verwendet wurde. Melden Sie sich beim Knoten an und führen Sie „ps –ef | grep –iNodeManager.“
Untersuchen Sie abschließend das Node Manager-Protokoll. Die meisten Fehler werden aus Protokollen auf Benutzerebene für jeden Map-Reduce-Job generiert.
Was ist der Zweck von RecordReader in Hadoop?
Hadoop zerlegt Daten in Blockformate. RecordReader hilft bei der Integration dieser Datenblöcke in einen einzigen lesbaren Datensatz. Wenn zum Beispiel die Eingabedaten in zwei Blöcke aufgeteilt werden –
Reihe 1 – Willkommen bei
Reihe 2 – UpGrad
RecordReader liest dies als „Willkommen bei UpG rad“.
In welchen Modi kann Hadoop ausgeführt werden?
Die Modi, in denen Hadoop ausgeführt werden kann, sind:
- Eigenständiger Modus – Dies ist ein Standardmodus von Hadoop, der für Debugging-Zwecke verwendet wird. HDFS wird nicht unterstützt.
- Pseudo-verteilter Modus – Dieser Modus erforderte die Konfiguration der Dateien mapred-site.xml, core-site.xml und hdfs-site.xml. Sowohl der Master- als auch der Slave-Knoten sind hier gleich.
- Vollständig verteilter Modus – Der vollständig verteilte Modus ist die Produktionsphase von Hadoop, in der Daten über verschiedene Knoten in einem Hadoop-Cluster verteilt werden. Hier werden die Master- und die Slave-Knoten getrennt zugewiesen.
Nennen Sie einige praktische Anwendungen von Hadoop.
Hier sind einige Fälle aus dem wirklichen Leben, in denen Hadoop einen Unterschied macht:
- Straßenverkehr regeln
- Betrugserkennung und -prävention
- Analysieren Sie Kundendaten in Echtzeit, um den Kundenservice zu verbessern
- Zugriff auf unstrukturierte medizinische Daten von Ärzten, HCPs usw., um die Gesundheitsdienste zu verbessern.
Was sind die wichtigsten Hadoop-Tools, die die Leistung von Big Data verbessern können?
Die Hadoop-Tools, die die Leistung von Big Data erheblich steigern, sind

• Bienenstock
• HDFS
• HBase
• SQL
• NoSQL
• Oozie
• Wolken
• Avro
• Gerinne
• Tierpfleger
Big-Data-Ingenieure: Mythen vs. Realitäten
Fazit
Diese Hadoop-Interviewfragen sollten Ihnen bei Ihrem nächsten Vorstellungsgespräch eine große Hilfe sein. Auch wenn Interviewer manchmal dazu neigen, einige Hadoop-Interviewfragen zu verdrehen, sollte es für Sie kein Problem sein, wenn Sie Ihre Grundlagen geklärt haben.
Wenn Sie mehr über Big Data erfahren möchten, schauen Sie sich unser PG Diploma in Software Development Specialization in Big Data-Programm an, das für Berufstätige konzipiert ist und mehr als 7 Fallstudien und Projekte bietet, 14 Programmiersprachen und Tools abdeckt und praktische praktische Übungen enthält Workshops, mehr als 400 Stunden gründliches Lernen und Unterstützung bei der Stellenvermittlung bei Top-Unternehmen.