
Die Mathematik hinter maschinellem Lernen: Was Sie wissen müssen
Veröffentlicht: 2021-03-10Maschinelles Lernen ist ein Bereich der KI, der sich auf die Entwicklung von Anwendungen konzentriert, indem verfügbare Daten genau verarbeitet werden. Das Hauptziel des maschinellen Lernens besteht darin, Computern dabei zu helfen, Berechnungen ohne menschliches Eingreifen zu verarbeiten. Dies wird ermöglicht, indem einer Maschine ermöglicht wird, durch überwachte oder nicht überwachte Lernmethoden zu lernen, menschliche Intelligenz nachzuahmen.
Maschinelles Lernen ist eine Kombination aus vielen Bereichen, darunter Statistik, Wahrscheinlichkeit, lineare Algebra, Analysis usw., auf deren Grundlage ein maschinelles Lernmodell Algorithmen erstellen oder mit Algorithmen füttern kann, um gemäß der menschlichen Intelligenz zu improvisieren. Je komplexer die Anwendung, desto komplexer wird ihr Algorithmus sein.
Von digitalen Assistenten und intelligenten Geräten bis hin zu Websites, die Ihre Lieblingsprodukte basierend auf Ihren Online-Aktivitäten empfehlen, und Mobiltelefonen, die Sie über Ihren Flugplan informieren, sind auf maschinellem Lernen basierende Produkte und Tools überall um uns herum. Mit zunehmender Abhängigkeit von intelligenten Geräten und Anwendungen steigt auch der Bedarf an der Implementierung von maschinellem Lernen.
Zu diesem Zweck werden wir in diesem Artikel die mathematischen Konzepte untersuchen, die zum Schreiben von Algorithmen für maschinelles Lernen und deren Implementierung erforderlich sind.
Inhaltsverzeichnis
Welche Bedeutung hat Mathematik für maschinelles Lernen?
Anwendungen für maschinelles Lernen liefern Analysen und Erkenntnisse aus verfügbaren Daten, die zu umsetzbaren Entscheidungen in Unternehmen beitragen. Da sich maschinelles Lernen um das Studium und die Implementierung von Algorithmen dreht, ist es wichtig, Ihre mathematischen Fähigkeiten zu stärken. Es hilft bei der Eliminierung von Unsicherheiten und der genauen Vorhersage von Datenwerten, wenn komplexe Datenparameter und -merkmale involviert sind. Es hilft uns auch dabei, den Bias-Varianz-Trade-off besser zu verstehen.
Die Beherrschung des maschinellen Lernens erfordert Kenntnisse mathematischer Konzepte wie lineare Algebra, Vektorrechnung, analytische Geometrie, Matrixzerlegung, Wahrscheinlichkeit und Statistik. Ein starkes Verständnis dieser hilft bei der Erstellung intuitiver Anwendungen für maschinelles Lernen.

Lineare Algebra
Lineare Algebra befasst sich mit Vektoren und Matrizen und dreht sich hauptsächlich um Berechnungen. Es spielt eine wesentliche Rolle beim maschinellen Lernen und bei Deep-Learning-Techniken. Laut Skyler Speakman ist es die Mathematik des 21. Jahrhunderts.
Lineare Algebra wird in der Regel von ML-Ingenieuren und Datenwissenschaftlern oder Forschern verwendet, um lineare Algorithmen, logistische Regressionen, Entscheidungsbäume und Support Vector Machines zu erstellen.
Infinitesimalrechnung
Calculus treibt maschinelle Lernalgorithmen an. Ohne Kenntnis seiner Konzepte wäre es nicht möglich, Ergebnisse anhand eines bestimmten Datensatzes vorherzusagen. Calculus hilft bei der Analyse der Geschwindigkeit, mit der sich Mengen ändern, und befasst sich mit der optimalen Leistung von maschinellen Lernalgorithmen. Integrationen, Differentiale, Grenzwerte und Ableitungen sind einige Konzepte des Kalküls, die helfen, tiefe neuronale Netze zu trainieren.
Wahrscheinlichkeit
Die Wahrscheinlichkeit beim maschinellen Lernen sagt die Menge der Ergebnisse voraus, während Statistiken das günstige Ergebnis zu seiner Schlussfolgerung führen. Das Ereignis könnte so einfach sein wie das Werfen einer Münze. Die Wahrscheinlichkeit kann in zwei Kategorien unterteilt werden: Bedingte Wahrscheinlichkeit und gemeinsame Wahrscheinlichkeit. Die gemeinsame Wahrscheinlichkeit tritt auf, wenn die Ereignisse unabhängig voneinander sind, während die bedingte Wahrscheinlichkeit auftritt, wenn ein Ereignis das andere ersetzt.
Statistiken
Statistik konzentriert sich auf die quantitativen und qualitativen Aspekte des Algorithmus. Es hilft uns, Ziele zu identifizieren und gesammelte Daten in präzise Beobachtungen umzuwandeln, indem es sie prägnant darstellt. Die Statistik im maschinellen Lernen konzentriert sich auf die beschreibende Statistik und die Inferenzstatistik.
Die deskriptive Statistik befasst sich mit der Beschreibung und Zusammenfassung des kleinen Datensatzes, an dem ein Modell arbeitet. Die hier verwendeten Methoden sind Mittelwert, Median, Modus, Standardabweichung und Streuung. Die Endergebnisse werden als bildliche Darstellungen präsentiert.
Inferenzstatistik befasst sich mit dem Extrahieren von Erkenntnissen aus einer bestimmten Stichprobe bei der Arbeit mit einem großen Datensatz. Inferenzstatistiken ermöglichen es Maschinen, Daten über den Umfang der bereitgestellten Informationen hinaus zu analysieren. Hypothesentests, Stichprobenverteilungen, Varianzanalysen sind einige Aspekte der Inferenzstatistik.
Abgesehen davon sind Programmierkenntnisse eine entscheidende Voraussetzung für maschinelles Lernen. Kenntnisse in Sprachen wie Python und Java helfen beim besseren Verständnis der Datenmodellierung. Zeichenkettenformatierung, Definition von Funktionen, Schleifen mit mehreren variablen Iteratoren, if-or-else-Bedingungsausdrücke sind einige seiner Grundfunktionen.
Bei der Datenmodellierung handelt es sich um den Prozess, durch den wir die Struktur von Datensätzen schätzen und mögliche Variationen und Muster erkennen. Um genaue Vorhersagen treffen zu können, muss man sich der verschiedenen Eigenschaften der gesammelten Daten bewusst sein.
Wie kann man maschinelles Lernen lernen?
Obwohl maschinelles Lernen ein lukratives Feld ist, erfordert es viel Übung und Geduld. Angesichts seiner Anwendungen in fast jeder Branche sind Ingenieure für maschinelles Lernen heute sehr gefragt.
Das durchschnittliche Gehalt eines Einstiegsingenieurs mit einem Hintergrund im maschinellen Lernen beträgt 686.000 Rs / Jahr. Und mit Erfahrung und Weiterbildung steigt das Potenzial, ein höheres Gehalt zu verdienen, exponentiell.
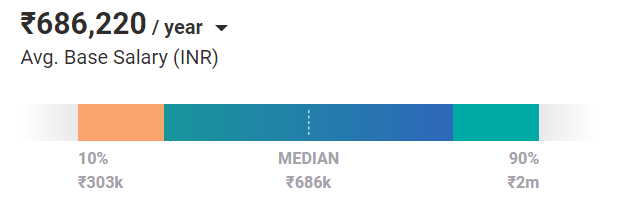
Es gibt mehrere Kurse für jemanden, der seine Wissensbasis im maschinellen Lernen erweitern möchte. Es würde Sie mindestens 6 Monate bis 2 Jahre brauchen, um das Fach zu beherrschen.
Mit mindestens einem Bachelor-Abschluss und einem Jahr Berufserfahrung, besser noch einem Abschluss in Mathematik oder Statistik, können Sie einen der folgenden Kurse auf upGrad absolvieren , um Ihre Erfolgschancen in diesem Bereich zu erhöhen.
- Advanced Certificate Program in Machine Learning und Deep Learning vom IIT Bangalore (6 Monate)
- Advanced Certificate Program in Machine Learning und NLP vom IIT Bangalore (6 Monate)
- Executive PG Program in Machine Learning & AI vom IIT Bangalore (12 Monate)
- Advanced Certification in Machine Learning and Cloud von IIT Madras (12 Monate)
- Master of Science in Machine Learning and AI von LJMU und IIT Bangalore (18 Monate)
Alle diese Kurse bieten mindestens 240+ Lernstunden und mindestens 5 Fallstudien, die Ihnen helfen, ein tiefes Verständnis des maschinellen Lernens und seiner verschiedenen Hilfsbereiche zu erlangen. Sie können grundlegende Themen wie Python, MySQL, Tensor, NLTK, Statistikmodelle, Excel usw. behandeln, die das Rückgrat der Codierung bilden. Hier finden Sie einen detaillierten Überblick über die verschiedenen upGrad-Kurse zum maschinellen Lernen , damit Sie den für Sie am besten geeigneten auswählen können.

Nehmen Sie online an den Kursen für künstliche Intelligenz von den besten Universitäten der Welt teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
Anwendungen des maschinellen Lernens
Maschinelles Lernen spielt eine entscheidende Rolle in unserem täglichen Leben, sowohl im beruflichen als auch im privaten Bereich. Seine analytischen und intuitiven Fähigkeiten haben das Potenzial, die Art und Weise, wie wir unsere täglichen Aufgaben erledigen, drastisch zu beeinflussen. Es hat sich als einfallsreich erwiesen, Geld und Zeit für eine Organisation zu sparen.
Während maschinelles Lernen ein weites Feld mit Anwendungen in fast jeder Branche ist, sind hier einige prominente Beispiele:
- Die Bilderkennung ist eine der am häufigsten verwendeten Anwendungen, da sie bei der Gesichtserkennung hilft und somit eine separate Datenbank für jede Person erstellt. Es kann auch verwendet werden, um Handschriftstile zu identifizieren.
- Maschinelles Lernen im Gesundheitssektor hat die Fähigkeiten von Gesundheitsdienstleistern verbessert. Es kann für eine schnellere medizinische Diagnose verwendet werden. In vielen Fällen hat die KI bei der Früherkennung von Krankheiten geholfen, sodass Ärzte Behandlungen und vorbeugende Maßnahmen vorschlagen können, die das Potenzial haben, Leben zu retten.
- Maschinelles Lernen hat wichtige Anwendungen im Finanzsektor, wo es um Investitionen, Fusionen und Übernahmen geht. Es hilft Banken und anderen Wirtschaftsinstituten, kluge Entscheidungen zu treffen.
- Seine Wirksamkeit zeigt sich möglicherweise am deutlichsten in der Kundenbetreuungs- und Dienstleistungsbranche, da maschinelles Lernen Abläufe rationalisiert und Lösungen schneller und effizienter bereitstellt.
- Maschinelles Lernen automatisiert Aufgaben, die sonst von einem Menschen auf dem Feld erledigt werden müssten. Wenn wir zum Beispiel virtuelle Assistenten in Betracht ziehen, könnte es so einfach sein, das Passwort zu ändern oder abends den Kontostand zu überprüfen. Mit maschinellem Lernen ist es jetzt möglich, Personal dringenderen Aufgaben zuzuweisen, die komplizierte Entscheidungsfindung oder menschliche Berührung erfordern.
Zukünftiger Umfang des maschinellen Lernens
Obwohl es maschinelles Lernen schon seit Jahrzehnten gibt, ist seine Anwendung heute am offensichtlichsten. Die Branche muss noch florieren und improvisieren, was bedeutet, dass die Zukunft des maschinellen Lernens rosig ist. Die meisten großen Unternehmen profitieren bereits von den Vorteilen des maschinellen Lernens und skalieren ihre Dienstleistungen und Produkte, um das Wachstum voranzutreiben.
Natürlich sind ML-Ingenieure sehr gefragt, und maschinelles Lernen bietet sich als lukrative Karriere an. Es verschafft Unternehmen den Vorteil, den sie brauchen. KI hat bisher schätzungsweise 2,3 Millionen Stellenangebote geschaffen. Es wird prognostiziert, dass die globale ML-Branche bis Ende 2022 mit einer CAGR von 42,2 % auf 9 Mrd. USD wachsen wird .
Hier sind einige Top-Trends im maschinellen Lernen:
- Immer mehr Algorithmen lernen hin zu unüberwachten Implementierungen. Unternehmen investieren in Quantum Computing auf der Grundlage dieser unbeaufsichtigten Algorithmen, die das Potenzial haben, maschinelles Lernen zu transformieren. Diese tragen dazu bei, aussagekräftige Erkenntnisse zu analysieren und zu gewinnen, und helfen Unternehmen so, bessere Ergebnisse zu erzielen, die mit klassischen maschinellen Lerntechniken nicht möglich gewesen wären.
- KI-betriebene Roboter werden eingesetzt, um Geschäftsvorgänge durchzuführen. Diese Technologien befinden sich jedoch noch in der Anfangsphase, und da Unternehmen in die Etablierung von KI und ML investieren, werden Roboter bald dazu beitragen, die Produktivität exponentiell zu steigern. Als Beispiel nennen wir Drohnen, die sich als leistungsstarke Geschäftswerkzeuge auf dem Verbrauchermarkt ausgeben, wo sie eingesetzt werden, um kommerzielle Operationen und einfache Aufgaben wie die Lieferung von Waren zu erledigen.
- Algorithmen für maschinelles Lernen unterstützen eine verbesserte Personalisierung. Diese Algorithmen erheben das Online-Verhalten potenzieller Kunden und senden Informationen an die Unternehmen zurück. Die Unternehmen wiederum senden ihnen Produkt- und Serviceempfehlungen. Diese Techniken des maschinellen Lernens helfen dabei, die Vorlieben und Abneigungen von Kunden zu identifizieren. Durch maschinelles Lernen geben Unternehmen ihren Kunden, was sie wünschen und wann sie es wünschen, was die Kundenbindung erhöht und mehr Geschäfte für das Unternehmen anzieht. Verbesserte Personalisierung ist die Zukunft des maschinellen Lernens.
- Dank verbesserter Algorithmen für maschinelles Lernen sind mobile und Webanwendungen jetzt intelligenter als je zuvor. Verbesserte kognitive Dienste ermöglichen es Entwicklern, separate Datenbanken für jeden Kunden zu erstellen, basierend auf visueller Erkennung, ihrer Sprache, ihrem Ton, ihrer Stimme usw.
Damit sind wir am Ende des Artikels angelangt. Wir hoffen, Sie fanden diese Informationen hilfreich!
Warum ist bei der linearen Regression Homoskedastizität erforderlich?
Homoskedastizität beschreibt, wie ähnlich oder wie weit die Daten vom Mittelwert abweichen. Dies ist eine wichtige Annahme, da parametrische statistische Tests empfindlich auf Unterschiede reagieren. Heteroskedastizität führt nicht zu Verzerrungen bei Koeffizientenschätzungen, verringert jedoch deren Genauigkeit. Bei geringerer Genauigkeit ist es wahrscheinlicher, dass die Koeffizientenschätzungen vom korrekten Populationswert abweichen. Um dies zu vermeiden, ist Homoskedastizität eine entscheidende Annahme.
Was sind die zwei Arten von Multikollinearität in der linearen Regression?
Daten- und strukturelle Multikollinearität sind die beiden Grundtypen von Multikollinearität. Wenn wir aus anderen Termen einen Modellterm machen, erhalten wir strukturelle Multikollinearität. Mit anderen Worten, es ist nicht in den Daten selbst vorhanden, sondern ein Ergebnis des von uns bereitgestellten Modells. Während Datenmultikollinearität kein Artefakt unseres Modells ist, ist sie in den Daten selbst vorhanden. Datenmultikollinearität tritt häufiger bei Beobachtungsuntersuchungen auf.
Was sind die Nachteile der Verwendung von t-Test für unabhängige Tests?
Es gibt Probleme mit wiederholten Messungen anstelle von Unterschieden zwischen den Gruppendesigns, wenn t-Tests mit gepaarten Stichproben verwendet werden, was zu Übertragungseffekten führt. Aufgrund von Fehlern erster Art kann der t-Test nicht für Mehrfachvergleiche verwendet werden. Es wird schwierig sein, die Nullhypothese abzulehnen, wenn ein gepaarter t-Test an einer Reihe von Stichproben durchgeführt wird. Die Beschaffung der Probanden für die Beispieldaten ist ein zeitaufwändiger und kostspieliger Aspekt des Forschungsprozesses.