
Testpipeline 101 für Frontend-Tests
Veröffentlicht: 2022-03-10Stellen Sie sich folgende Situation vor: Sie nähern sich schnell einem Abgabetermin und Sie nutzen jede freie Minute, um Ihr Ziel zu erreichen, dieses komplexe Refactoring mit vielen Änderungen in Ihren CSS-Dateien abzuschließen. Während der Busfahrt arbeiten Sie sogar an den letzten Schritten. Ihre lokalen Tests scheinen jedoch jedes Mal fehlzuschlagen, und Sie können sie nicht zum Laufen bringen. Ihr Stresslevel steigt .
Tatsächlich gibt es eine ähnliche Szene in einer bekannten Serie: Sie stammt aus der dritten Staffel der Netflix-TV-Serie „How to Sell Drugs Online (Fast)“:
Cypress + Vue wird *IN EINER NETFLIX-TV-SHOW* vorgestellt
– jess (@_jessicasachs) 7. August 2021
Es ist eine Komödie mit dem Titel „Wie man Drogen verkauft (schnell)“ und enthält einige der realistischsten Darstellungen von Webdev.
Staffel 3, Folge 1 @ 20:20 und ein- oder zweimal davor. pic.twitter.com/ICSAwMxyFB
Nun, er benutzt zumindest Tests, könnte man meinen. Warum ist er immer noch in Not, fragen Sie sich vielleicht? Es gibt noch viel Raum für Verbesserungen und um eine solche Situation zu vermeiden, auch wenn Sie Tests schreiben. Wie denken Sie über die Überwachung Ihrer Codebasis und all Ihrer Änderungen von Anfang an? Damit erlebst du solche bösen Überraschungen nicht, oder? Es ist nicht allzu schwierig, solche automatisierten Testroutinen einzubinden: Lassen Sie uns diese Testpipeline von Anfang bis Ende gemeinsam erstellen.
Lass uns gehen!
Das Wichtigste zuerst: Grundbegriffe
Eine Erstellungsroutine kann Ihnen dabei helfen, auch bei Ihren kleinen Nebenprojekten zuversichtlich in komplexere Umgestaltungen zu bleiben. Das bedeutet jedoch nicht, dass Sie ein DevOps-Ingenieur sein müssen. Es ist wichtig, ein paar Begriffe und Strategien zu lernen, und dafür sind Sie hier, richtig? Zum Glück sind Sie an der richtigen Stelle! Beginnen wir mit den grundlegenden Begriffen, denen Sie bald begegnen werden, wenn Sie sich mit einer Testpipeline für Ihr Frontend-Projekt befassen.
Wenn Sie sich allgemein durch die Welt des Testens googeln, kann es passieren, dass Sie bereits auf den Begriff „CI/CD“ als einen der ersten Begriffe gestoßen sind. Es ist die Abkürzung für „Continuous Integration, Continuous Delivery“ und „Continuous Deployment“ und beschreibt genau das: Wie Sie wahrscheinlich schon gehört haben, handelt es sich um eine Softwareverteilungsmethode, die von Entwicklungsteams verwendet wird, um Codeänderungen häufiger und zuverlässiger bereitzustellen. CI/CD umfasst zwei komplementäre Ansätze, die stark auf Automatisierung angewiesen sind.
- Kontinuierliche Integration
Es ist ein Begriff für Automatisierungsmaßnahmen, um kleine, regelmäßige Codeänderungen zu implementieren und sie in einem gemeinsamen Repository zusammenzuführen. Continuous Integration umfasst die Schritte zum Erstellen und Testen Ihres Codes.
CD ist das Akronym für „Continuous Delivery“ und „Continuous Deployment“, beides Konzepte, die einander ähnlich sind, aber manchmal in unterschiedlichen Kontexten verwendet werden. Der Unterschied zwischen beiden liegt im Umfang der Automatisierung:
- Kontinuierliche Lieferung
Es bezieht sich auf den Prozess Ihres Codes, der bereits zuvor getestet wurde, von wo aus das Betriebsteam ihn nun in einer Live-Produktionsumgebung bereitstellen kann. Dieser letzte Schritt kann jedoch manuell erfolgen. - Kontinuierliche Bereitstellung
Es konzentriert sich auf den Aspekt „Bereitstellung“, wie der Name schon sagt. Es ist ein Begriff für den vollautomatisierten Freigabeprozess von Entwickleränderungen aus dem Repository bis hin zur Produktion, wo der Kunde sie direkt verwenden kann.
Diese Prozesse zielen darauf ab, Entwicklern und Teams ein Produkt zu ermöglichen, das Sie jederzeit veröffentlichen können, wenn sie möchten: Das Vertrauen einer kontinuierlich überwachten, getesteten und bereitgestellten Anwendung zu haben.
Um eine gut konzipierte CI/CD-Strategie zu erreichen, verwenden die meisten Menschen und Organisationen Prozesse, die als „Pipelines“ bezeichnet werden. „Pipeline“ ist ein Wort, das wir bereits in diesem Leitfaden verwendet haben, ohne es zu erklären. Wenn man an solche Pipelines denkt, ist es nicht abwegig, an Rohre zu denken, die als Fernleitungen dienen, um beispielsweise Gas zu transportieren. Ganz ähnlich funktioniert eine Pipeline im DevOps-Bereich: Sie „transportiert“ Software zum Deployment.
Warten Sie, das klingt nach einer Menge Dinge, die Sie lernen und sich merken müssen, oder? Haben wir nicht über Tests gesprochen? Damit haben Sie Recht: Die Abdeckung des vollständigen Konzepts einer CI/CD-Pipeline bietet genug Inhalt für mehrere Artikel, und wir möchten uns um eine Testpipeline für kleine Frontend-Projekte kümmern. Oder Sie vermissen nur den Testaspekt Ihrer Pipelines und konzentrieren sich daher allein auf Continuous-Integration-Prozesse. Daher konzentrieren wir uns insbesondere auf den „Testing“-Teil von Pipelines. Daher werden wir in diesem Leitfaden eine „kleine“ Testpipeline erstellen.
Okay, der „Testteil“ ist unser Hauptaugenmerk. Welche Tests kennen Sie in diesem Zusammenhang bereits und kommen Ihnen auf den ersten Blick in den Sinn? Wenn ich so über das Testen nachdenke, fallen mir spontan diese Arten von Tests ein:
- Unit-Tests sind eine Art Test, bei dem kleinere testbare Teile oder Einheiten einer Anwendung, Units genannt, einzeln und unabhängig auf ordnungsgemäßen Betrieb getestet werden.
- Integrationstests konzentrieren sich auf die Interaktion zwischen Komponenten oder Systemen. Bei dieser Art des Testens prüfen wir das Zusammenspiel der Einheiten und wie sie zusammenarbeiten.
- End-to-End-Testing oder E2E-Testing bedeutet, dass tatsächliche Benutzerinteraktionen vom Computer simuliert werden; Dabei sollte das E2E-Testing möglichst viele Funktionsbereiche und Teile des in der Anwendung verwendeten Technologie-Stacks umfassen.
- Beim visuellen Testen wird die sichtbare Ausgabe einer Anwendung überprüft und mit den erwarteten Ergebnissen verglichen. Anders ausgedrückt, es hilft, „visuelle Fehler“ im Erscheinungsbild einer Seite oder eines Bildschirms zu finden, die sich von rein funktionalen Fehlern unterscheiden.
- Statische Analyse ist nicht gerade Testen, aber ich denke, es ist wichtig, es hier zu erwähnen. Sie können sich vorstellen, dass es wie eine Rechtschreibkorrektur funktioniert: Es debuggt Ihren Code, ohne das Programm auszuführen, und erkennt Codestilprobleme. Diese einfache Maßnahme kann viele Fehler verhindern.
Um zuversichtlich zu sein, ein massives Refactoring in unserem einzigartigen Projekt zusammenzuführen, sollten wir in Betracht ziehen, alle diese Testtypen in unserer Testpipeline zu verwenden. Aber ein Vorsprung führt schnell zu Frustration: Sie könnten sich verloren fühlen, wenn Sie diese Testtypen bewerten. Wo soll ich anfangen? Wie viele Tests welcher Art sind sinnvoll?
Strategieplanung: Pyramiden und Trophäen
Wir müssen an einer Teststrategie arbeiten, bevor wir uns in den Aufbau unserer Pipeline stürzen. Auf der Suche nach Antworten auf all diese Fragen finden Sie möglicherweise eine mögliche Lösung in einigen Metaphern: Im Internet und insbesondere in Testing-Communities neigen die Leute dazu, Analogien zu verwenden, um Ihnen eine Vorstellung davon zu geben, wie viele Tests Sie welchen Typs verwenden sollten.
Die erste Metapher, der Sie wahrscheinlich begegnen werden, ist die Testautomatisierungspyramide. Mike Cohn hat dieses Konzept in seinem Buch „Succeeding with Agile“ entwickelt, das von Martin Fowler als „Practical Test Pyramid“ weiterentwickelt wurde. Es sieht aus wie das:
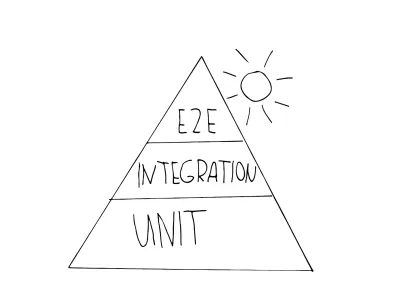
Wie Sie sehen, besteht er aus drei Stufen, die den drei vorgestellten Teststufen entsprechen. Die Pyramide soll die richtige Mischung verschiedener Tests verdeutlichen und Sie bei der Entwicklung einer Teststrategie anleiten:
- Einheit
Sie finden diese Tests auf der Basisebene der Pyramide, weil sie schnell ausgeführt und einfach zu warten sind. Dies liegt an ihrer Isolation und der Tatsache, dass sie auf die kleinsten Einheiten abzielen. Sehen Sie sich dieses Beispiel für einen typischen Komponententest an, der ein sehr kleines Produkt testet. - Integration
Diese befinden sich in der Mitte der Pyramide, da sie in Bezug auf die Ausführungsgeschwindigkeit noch akzeptabel sind, Ihnen aber dennoch das Vertrauen geben, näher am Benutzer zu sein, als es Unit-Tests sein können. Ein Beispiel für einen Test vom Integrationstyp ist ein API-Test, auch Komponententests können als dieser Typ betrachtet werden. - E2E-Tests (auch UI-Tests genannt)
Wie wir gesehen haben, simulieren diese Tests einen echten Benutzer und seine Interaktion. Diese Tests benötigen mehr Zeit für die Ausführung und sind daher teurer – sie werden an der Spitze der Pyramide platziert. Wenn Sie ein typisches Beispiel für einen E2E-Test inspizieren möchten, gehen Sie zu diesem.
In den letzten Jahren fühlte sich diese Metapher jedoch aus der Zeit gefallen an. Vor allem einer ihrer Fehler ist für mich entscheidend: Statische Analysen werden bei dieser Strategie umgangen. Die Verwendung von Fixern im Code-Stil oder anderen Linting-Lösungen wird in dieser Metapher nicht berücksichtigt, was meiner Meinung nach ein großer Fehler ist. Lint und andere statische Analysetools sind ein integraler Bestandteil der verwendeten Pipeline und sollten nicht ignoriert werden.
Also, lassen Sie uns das kurz machen: Wir sollten eine modernere Strategie verwenden. Aber fehlende Flusenwerkzeuge sind nicht der einzige Fehler – es gibt sogar einen wichtigeren Punkt, den es zu beachten gilt. Stattdessen könnten wir unseren Fokus etwas verschieben: Das folgende Zitat fasst es ziemlich gut zusammen:
„Tests schreiben. Nicht zu viele. Meistens Integration.“
– Guillermo Rauch
Lassen Sie uns dieses Zitat aufschlüsseln, um mehr darüber zu erfahren:
- Tests schreiben
Ganz selbsterklärend – man sollte immer Tests schreiben. Tests sind entscheidend, um Vertrauen in Ihre Anwendung zu schaffen – für Benutzer und Entwickler gleichermaßen. Auch für sich selbst! - Nicht zu viele
Das willkürliche Schreiben von Tests bringt Sie nicht weiter; Die Testpyramide ist immer noch gültig in ihrer Aussage, Tests priorisiert zu halten. - Meist Integration
Ein Trumpf der „teuren“ Tests, den die Pyramide ignoriert, ist, dass das Vertrauen in die Tests steigt, je weiter man in der Pyramide aufsteigt. Dieser Anstieg bedeutet, dass sowohl der Benutzer als auch Sie als Entwickler diesen Tests am ehesten vertrauen werden.
Das bedeutet, dass wir uns für Tests entscheiden sollten, die vom Design her näher am Benutzer sind. Infolgedessen zahlen Sie möglicherweise mehr, erhalten aber viel Wert zurück. Sie fragen sich vielleicht, warum Sie sich nicht für den E2E-Test entscheiden sollten? Da sie Benutzer imitieren, sind sie dem Benutzer nicht zunächst einmal am nächsten? Das stimmt, aber sie sind immer noch viel langsamer in der Ausführung und erfordern den vollständigen Anwendungsstapel. Dieser Return of Investment wird also später erreicht als bei Integrationstests: Folglich bieten Integrationstests eine faire Balance zwischen Vertrauen einerseits und Geschwindigkeit und Aufwand andererseits.
Wenn Sie Kent C. Dodds folgen, werden Ihnen diese Argumente vielleicht bekannt vorkommen, besonders wenn Sie diesen Artikel von ihm lesen. Diese Argumente kommen nicht von ungefähr: Er hat in seiner Arbeit eine neue Strategie entwickelt. Ich stimme seinen Punkten voll und ganz zu und verlinke die wichtigsten hier und andere im Ressourcenbereich. Sein vorgeschlagener Ansatz stammt von der Testpyramide, hebt sie jedoch auf eine andere Ebene, indem er ihre Form ändert, um die höhere Priorität von Integrationstests widerzuspiegeln. Es heißt „Testing Trophy“.
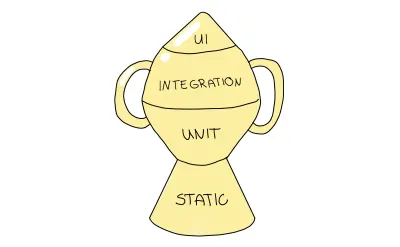
Die Testtrophäe ist eine Metapher, die die Granularität von Tests auf eine etwas andere Weise darstellt; Sie sollten Ihre Tests in die folgenden Testtypen aufteilen:
- Die statische Analyse spielt in dieser Metapher eine entscheidende Rolle. Auf diese Weise fangen Sie Tippfehler, Tippfehler und andere Fehler ab, indem Sie einfach die erwähnten Debugging-Schritte ausführen.
- Einheitentests sollten sicherstellen, dass Ihre kleinste Einheit angemessen getestet wird, aber die Testtrophäe wird sie nicht im gleichen Maße hervorheben wie die Testpyramide.
- Integration ist das Hauptaugenmerk, da sie die Kosten und das höhere Vertrauen am besten ausgleicht.
- UI-Tests , einschließlich E2E- und visueller Tests, stehen an der Spitze der Testtrophäe, ähnlich wie ihre Rolle in der Testpyramide.
Ich habe mich bei den meisten meiner Projekte für diese Strategie zum Testen von Trophäen entschieden, und ich werde dies auch in diesem Leitfaden tun. Allerdings muss ich hier einen kleinen Disclaimer geben: Meine Auswahl basiert natürlich auf den Projekten, an denen ich in meinem täglichen Leben arbeite. Somit sind der Nutzen und die Auswahl einer passenden Teststrategie immer abhängig von dem Projekt, an dem Sie arbeiten. Also, fühlen Sie sich nicht schlecht, wenn es nicht Ihren Bedürfnissen entspricht, ich werde Ressourcen zu anderen Strategien im entsprechenden Abschnitt hinzufügen.
Kleiner Spoiler-Alarm: In gewisser Weise muss auch ich von diesem Konzept ein wenig abweichen, wie Sie bald sehen werden. Ich denke jedoch, dass das in Ordnung ist, aber wir werden gleich darauf zurückkommen. Mir geht es darum, über die Priorisierung und Verteilung von Testtypen nachzudenken, bevor Sie Ihre Pipelines planen und implementieren.
So erstellen Sie diese Pipelines online (schnell)
Der Protagonist in der dritten Staffel der Netflix-TV-Serie „How To Sell Drugs Online (Fast)“ wird gezeigt, wie er Cypress für E2E-Tests verwendet, während er kurz vor einer Frist steht, aber es war wirklich nur ein lokaler Test. Es war kein CI/CD zu sehen, was ihn unnötig stresste. Dem Druck des jeweiligen Protagonisten in den entsprechenden Episoden sollten wir mit der erlernten Theorie ausweichen. Doch wie können wir diese Erkenntnisse auf die Realität anwenden?
Zunächst einmal benötigen wir zunächst eine Codebase als Testgrundlage. Idealerweise sollte es ein Projekt sein, dem viele von uns Frontend-Entwicklern begegnen werden. Sein Anwendungsfall sollte häufig vorkommen, sich gut für einen praktischen Ansatz eignen und es uns ermöglichen, eine Testpipeline von Grund auf neu zu implementieren. Was könnte ein solches Projekt sein?
Mein Vorschlag einer primären Pipeline
Das erste, was mir in den Sinn kam, war selbstverständlich: Meine Website, dh meine Portfolio-Seite, eignet sich gut als Beispiel-Codebasis, die von unserer aufstrebenden Pipeline getestet werden soll. Es ist Open Source auf Github veröffentlicht, sodass Sie es anzeigen und frei verwenden können. Ein paar Worte zum Tech-Stack der Seite: Grundsätzlich habe ich diese Seite auf Vue.js (leider noch auf Version 2, als ich diesen Artikel geschrieben habe) als JavaScript-Framework mit Nuxt.js als zusätzlichem Web-Framework aufgebaut. Das vollständige Implementierungsbeispiel finden Sie in seinem GitHub-Repository.
Mit unserer ausgewählten Beispiel-Codebasis sollten wir beginnen, unsere Erkenntnisse anzuwenden. Angesichts der Tatsache, dass wir die Testing Trophy als Ausgangspunkt für unsere Teststrategie nutzen wollen, habe ich mir folgendes Konzept ausgedacht:
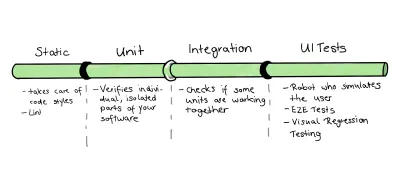
Da wir es mit einer relativ kleinen Codebasis zu tun haben, werde ich die Teile von Unit- und Integrationstests zusammenführen. Allerdings ist das nur ein kleiner Grund dafür. Andere und wichtigere Gründe sind:
- Die Definition einer Einheit ist oft „zu diskutieren“: Fragt man eine Gruppe von Entwicklern, eine Einheit zu definieren, erhält man meist verschiedene, unterschiedliche Antworten. Da sich einige auf eine Funktion, Klasse oder einen Dienst – kleinere Einheiten – beziehen, zählt ein anderer Entwickler die vollständige Komponente.
- Zusätzlich zu diesen Definitionskämpfen kann es schwierig sein, eine Grenze zwischen Einheit und Integration zu ziehen, da sie sehr verschwommen ist. Dieser Kampf ist real, insbesondere für Frontend, da wir oft das DOM benötigen, um die Testbasis erfolgreich zu validieren.
- Es ist normalerweise möglich, dieselben Tools und Bibliotheken zu verwenden, um beide Integrationstests zu schreiben. Wir könnten also Ressourcen sparen, indem wir sie zusammenführen.
Werkzeug der Wahl: GitHub-Aktionen
Da wir wissen, was wir uns in einer Pipeline vorstellen wollen, steht als nächstes die Wahl der Continuous Integration and Delivery (CI/CD)-Plattform an. Bei der Auswahl einer solchen Plattform für unser Projekt denke ich an diejenigen, mit denen ich bereits Erfahrungen gesammelt habe:
- GitLab, durch die tägliche Routine an meinem Arbeitsplatz,
- GitHub-Aktionen in den meisten meiner Nebenprojekte.
Es stehen jedoch viele andere Plattformen zur Auswahl. Ich würde vorschlagen, dass Sie Ihre Wahl immer auf Ihre Projekte und ihre spezifischen Anforderungen stützen und die verwendeten Technologien und Frameworks berücksichtigen – damit keine Kompatibilitätsprobleme auftreten. Denken Sie daran, dass wir ein Vue 2-Projekt verwenden, das bereits auf GitHub veröffentlicht wurde und zufällig mit meinen bisherigen Erfahrungen übereinstimmt. Außerdem benötigen die erwähnten GitHub-Aktionen nur das GitHub-Repository Ihres Projekts als Ausgangspunkt; um einen GitHub Actions-Workflow speziell dafür zu erstellen und auszuführen. Daher verwende ich für diesen Leitfaden GitHub Actions.
Diese GitHub-Aktionen bieten Ihnen also eine Plattform, um speziell definierte Workflows auszuführen, wenn bestimmte Ereignisse eintreten. Diese Ereignisse sind bestimmte Aktivitäten in unserem Repository, die den Workflow auslösen, z. B. das Pushen von Änderungen an einen Zweig. In diesem Leitfaden sind diese Ereignisse an CI/CD gebunden, aber solche Workflows können auch andere Workflows automatisieren, z. B. das Hinzufügen von Labels zu Pull-Requests. GitHub kann sie auf virtuellen Windows-, Linux- und macOS-Maschinen ausführen.

Um einen solchen Workflow zu visualisieren, würde es so aussehen:
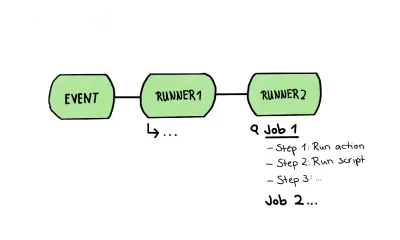
In diesem Artikel werde ich einen Workflow verwenden, um eine Pipeline darzustellen; Das bedeutet, dass ein Workflow alle unsere Testschritte enthält, von der statischen Analyse bis hin zu UI-Tests aller Art. Diese Pipeline, in den folgenden Abschnitten als „Workflow“ bezeichnet, besteht aus einem oder sogar mehreren Jobs, bei denen es sich um eine Reihe von Schritten handelt, die auf demselben Runner ausgeführt werden.
Dieser Workflow ist genau die Struktur, die ich in der obigen Zeichnung skizzieren wollte. Darin werfen wir einen genaueren Blick auf einen solchen Runner, der mehrere Jobs enthält; Die Schritte eines Jobs selbst bestehen aus verschiedenen Schritten. Diese Schritte können einer von zwei Arten sein:
- Ein Schritt kann ein einfaches Skript ausführen.
- Ein Schritt kann eine Aktion ausführen können. Eine solche Aktion ist eine wiederverwendbare Erweiterung und oft eine vollständige, benutzerdefinierte Anwendung.
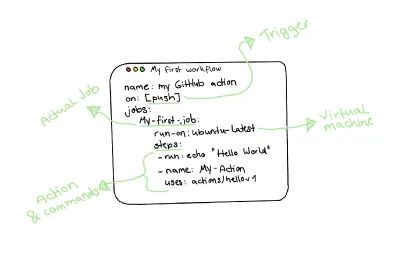
Vor diesem Hintergrund sieht ein tatsächlicher Workflow einer GitHub-Aktion folgendermaßen aus:
Wir schreiben unsere allererste GitHub-Aktion
Endlich können wir unsere erste eigene Github-Aktion schreiben und etwas Code schreiben! Wir beginnen mit unserem grundlegenden Arbeitsablauf und einer ersten Skizze der Jobs, die wir darstellen möchten. In Erinnerung an unsere Testtrophäe wird jeder Job einer Ebene in der Testtrophäe ähneln. Die Schritte sind die Dinge, die wir tun müssen, um diese Ebenen zu automatisieren.
Daher erstelle ich zuerst das .github/workflows/ , um unsere Workflows zu speichern. Wir werden eine neue Datei namens tests.yml , die unseren Test-Workflow in diesem Verzeichnis enthält. Neben der Standard-Workflow-Syntax, die in der obigen Zeichnung zu sehen ist, werde ich wie folgt vorgehen:
- Ich nenne unseren Workflow
Tests CI. - Da ich meinen Workflow bei jedem Push an meine Remote-Zweige ausführen und eine manuelle Option zum Starten meiner Pipeline bereitstellen möchte, werde ich meinen Workflow so konfigurieren, dass er bei
pushundworkflow_dispatchausgeführt wird. - Zu guter Letzt wird mein Workflow, wie im Abschnitt „Mein Vorschlag einer einfachen Pipeline“ erwähnt, drei Jobs enthalten:
-
static-eslintfür statische Analysen; -
unit-integration-jestfür Unit- und Integrationstests in einem Job zusammengeführt; -
ui-cypressals UI-Stufe, einschließlich grundlegender E2E-Tests und visueller Regressionstests.
-
- Eine Linux-basierte virtuelle Maschine sollte alle Jobs ausführen, also werde ich mich für
ubuntu-latest.
Wenn Sie die korrekte Syntax einer YAML -Datei eingeben, könnte die erste Gliederung unseres Workflows wie folgt aussehen:
name: Tests CI on: [push, workflow_dispatch] # On push and manual jobs: static-eslint: runs-on: ubuntu-latest steps: # 1 steps unit-integration-jest: runs-on: ubuntu-latest steps: # 1 step ui-cypress: runs-on: ubuntu-latest steps: # 2 steps: e2e and visualWenn Sie in Details zu Workflows in GitHub-Aktionen eintauchen möchten, können Sie jederzeit zur Dokumentation wechseln. So oder so, Sie sind sich zweifellos bewusst, dass die Schritte noch fehlen. Keine Sorge – ich bin mir dessen auch bewusst. Um diese Workflow-Skizze mit Leben zu füllen, müssen wir diese Schritte definieren und entscheiden, welche Testwerkzeuge und Frameworks für unser kleines Portfolio-Projekt verwendet werden sollen. Alle folgenden Abschnitte beschreiben die jeweiligen Jobs und enthalten mehrere Schritte, um die Automatisierung dieser Tests zu ermöglichen.
Statische Analyse
Wie die Test-Trophäe andeutet, werden wir mit Linters und anderen Fixern im Code-Stil in unserem Workflow beginnen. In diesem Zusammenhang können Sie aus vielen Tools wählen, einige Beispiele sind:
- Eslint als Stilfixierer für Javascript-Code.
- Stylelint zur Reparatur von CSS-Code.
- Wir können darüber nachdenken, noch weiter zu gehen, zB um die Code-Komplexität zu analysieren, Sie könnten sich Tools wie Scrutinizer ansehen.
Diese Tools haben gemeinsam, dass sie auf Fehler in Mustern und Konventionen hinweisen. Bitte beachten Sie jedoch, dass einige dieser Regeln Geschmackssache sind. Es liegt an Ihnen, zu entscheiden, wie streng Sie sie durchsetzen möchten. Um ein Beispiel zu nennen, wenn Sie einen Einzug von zwei oder vier Tabulatoren tolerieren. Es ist viel wichtiger, sich darauf zu konzentrieren, einen konsistenten Codestil zu fordern und kritischere Fehlerursachen abzufangen, wie z. B. die Verwendung von „==“ vs. „===“.
Für unser Portfolio-Projekt und diesen Leitfaden möchte ich mit der Installation von Eslint beginnen, da wir viel Javascript verwenden. Ich werde es mit dem folgenden Befehl installieren:
npm install eslint --save-dev Natürlich kann ich auch einen alternativen Befehl mit dem Yarn-Paketmanager verwenden, wenn ich NPM lieber nicht verwenden möchte. Nach der Installation muss ich eine Konfigurationsdatei namens .eslintrc.json . Lassen Sie uns zunächst eine grundlegende Konfiguration verwenden, da dieser Artikel Ihnen nicht beibringt, wie Sie Eslint überhaupt konfigurieren:
{ "extends": [ "eslint:recommended", ] } Wenn Sie mehr über die Eslint-Konfiguration im Detail erfahren möchten, gehen Sie zu dieser Anleitung. Als nächstes wollen wir unsere ersten Schritte unternehmen, um die Ausführung von Eslint zu automatisieren. Zunächst möchte ich den Befehl so einstellen, dass Eslint als NPM-Skript ausgeführt wird. Ich erreiche dies, indem ich diesen Befehl in unserer Datei package.json im script verwende:
"scripts": { "lint": "eslint --ext .js .", }, Dieses neu erstellte Skript kann ich dann in unserem GitHub-Workflow ausführen. Wir müssen jedoch sicherstellen, dass unser Projekt verfügbar ist, bevor wir dies tun. Daher verwenden wir die vorkonfigurierte GitHub-Aktion actions/checkout@v2 , die genau das tut: Unser Projekt auschecken, damit der Workflow Ihrer GitHub-Aktion darauf zugreifen kann. Der nächste Schritt wäre die Installation aller NPM-Abhängigkeiten, die wir für mein Portfolio-Projekt benötigen. Danach sind wir endlich bereit, unser Eslint-Skript auszuführen! Unser letzter Job zur Verwendung von Linting sieht jetzt so aus:
static-eslint: runs-on: ubuntu-latest steps: # Action to check out my codebase - uses: actions/checkout@v2 # install NPM dependencies - run: npm install # Run lint script - run: npm run lint Sie fragen sich jetzt vielleicht: Fällt diese Pipeline automatisch aus, wenn unser npm run lint ausführt? Ja, das funktioniert out of the box. Sobald wir unseren Workflow fertig geschrieben haben, schauen wir uns die Screenshots auf Github an.
Einheit und Integration
Als Nächstes möchte ich unseren Job erstellen, der die Einheit und die Integrationsschritte enthält. In Bezug auf das in diesem Artikel verwendete Framework möchte ich Ihnen das Jest-Framework für Frontend-Tests vorstellen. Natürlich müssen Sie Jest nicht verwenden, wenn Sie nicht möchten – es stehen viele Alternativen zur Auswahl:
- Cypress bietet auch Komponententests an, die sich gut für Integrationstests eignen.
- Jasmine ist ein weiteres Framework, das Sie sich ebenfalls ansehen sollten.
- Und es gibt noch viele mehr; Ich wollte nur einige nennen.
Jest wird von Facebook als Open Source bereitgestellt. Das Framework zeichnet sich durch seinen Fokus auf Einfachheit aus und ist gleichzeitig mit vielen JavaScript-Frameworks und -Projekten kompatibel, darunter Vue.js, React oder Angular. Ich kann Jest auch zusammen mit TypeScript verwenden. Das macht das Framework gerade für mein kleines Portfolio-Projekt sehr interessant, da es kompatibel und gut geeignet ist.
Wir können die Installation von Jest direkt aus diesem Stammordner meines Portfolio-Projekts starten, indem Sie den folgenden Befehl eingeben:
npm install --save-dev jest Nach der Installation kann ich bereits mit dem Schreiben von Tests beginnen. Dieser Artikel konzentriert sich jedoch auf die Automatisierung dieser Tests mithilfe von Github-Aktionen. Um also zu lernen, wie man einen Unit- oder Integrationstest schreibt, lesen Sie bitte die folgende Anleitung. Beim Einrichten des Jobs in unserem Workflow können wir ähnlich wie beim static-eslint Job vorgehen. Der erste Schritt besteht also wieder darin, ein kleines NPM-Skript zu erstellen, das wir später in unserem Job verwenden können:
"scripts": { "test": "jest", }, Danach werden wir den Job namens unit-integration-jest ähnlich definieren, wie wir es bereits für unsere Linters getan haben. Der Workflow überprüft also unser Projekt. Darüber hinaus werden wir zwei geringfügige Unterschiede zu unserem ersten static-eslint Job verwenden:
- Wir werden eine Aktion als Schritt zum Installieren von Node verwenden.
- Danach werden wir unser neu erstelltes npm-Skript verwenden, um unseren Jest-Test auszuführen.
Auf diese Weise sieht unser unit-integration-jest Job folgendermaßen aus:
unit-integration-jest: runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 # Set up node - name: Run jest uses: actions/setup-node@v1 with: node-version: '12' - run: npm install # Run jest script - run: npm testUI-Tests: E2E und visuelle Tests
Zu guter Letzt werden wir unseren ui-cypress Job schreiben, der sowohl E2E-Tests als auch visuelle Tests enthalten wird. Es ist clever, diese beiden in einem Job zu kombinieren, da ich das Cypress-Framework für beide verwenden werde. Natürlich können Sie auch andere Frameworks wie NightwatchJS und CodeceptJS in Betracht ziehen.
Auch hier behandeln wir nur die Grundlagen zur Einrichtung in unserem GitHub-Workflow. Wenn Sie lernen möchten, wie man Cypress-Tests im Detail schreibt, habe ich Sie mit einem anderen meiner Leitfäden behandelt, der genau das angeht. Dieser Artikel führt Sie durch alles, was wir zum Definieren unserer E2E-Testschritte benötigen. In Ordnung, zuerst installieren wir Cypress, genauso wie wir es mit den anderen Frameworks getan haben, indem wir den folgenden Befehl in unserem Stammordner verwenden:
npm install --save-dev cypress Diesmal müssen wir kein NPM-Skript definieren. Cypress stellt uns bereits eine eigene GitHub-Aktion zur Verfügung, cypress-io/github-action@v2 . Dort müssen wir nur einige Dinge konfigurieren, um es zum Laufen zu bringen:
- Wir müssen sicherstellen, dass unsere Anwendung vollständig eingerichtet ist und funktioniert, da für einen E2E-Test der vollständige verfügbare Anwendungsstapel erforderlich ist.
- Wir müssen den Browser benennen, in dem wir unseren E2E-Test ausführen.
- Wir müssen warten, bis der Webserver voll funktionsfähig ist, damit sich der Computer wie ein echter Benutzer verhalten kann.
Glücklicherweise hilft uns unsere Cypress-Aktion dabei, all diese Konfigurationen mit dem with -Bereich zu speichern. So sieht unser aktueller GitHub-Job so aus:
steps: - name: Checkout uses: actions/checkout@v2 # Install NPM dependencies, cache them correctly # and run all Cypress tests - name: Cypress Run uses: cypress-io/github-action@v2 with: browser: chrome headless: true # Setup: Nuxt-specific things build: npm run generate start: npm run start wait-on: 'http://localhost:3000'Sehtests: Verleihen Sie Ihrem Test ein paar Augen
Erinnern Sie sich an unsere erste Absicht, diesen Leitfaden zu schreiben: Ich habe mein bedeutendes Refactoring mit vielen Änderungen in SCSS-Dateien – ich möchte Tests als Teil der Build-Routine hinzufügen, um sicherzustellen, dass nichts anderes beschädigt wurde. Mit statischen Analysen, Einheiten-, Integrations- und E2E-Tests sollten wir ziemlich zuversichtlich sein, oder? Stimmt, aber ich kann noch etwas tun, um meine Pipeline noch kugelsicherer und perfekter zu machen. Man könnte sagen, es wird zum Creamer. Gerade beim Umgang mit CSS-Refactoring kann ein E2E-Test nur bedingt helfen, da er nur das tut, was Sie ihm gesagt haben, indem er es in Ihrem Test niederschreibt.
Glücklicherweise gibt es neben den geschriebenen Befehlen und damit dem Konzept eine andere Möglichkeit, Fehler zu finden. Das nennt sich visuelles Testen: Man kann sich diese Art des Testens wie ein Finde-den-Unterschied-Puzzle vorstellen. Technisch gesehen ist visuelles Testen ein Screenshot-Vergleich, bei dem Screenshots Ihrer Anwendung erstellt und mit dem Status Quo verglichen werden, z. B. aus dem Hauptzweig Ihres Projekts. Auf diese Weise bleibt kein versehentliches Styling-Problem unbemerkt – zumindest in Bereichen, in denen Sie visuelle Tests verwenden. Dies kann das visuelle Testen zu einem Lebensretter für große CSS-Refaktorisierungen machen, zumindest meiner Erfahrung nach.
Es gibt viele visuelle Testwerkzeuge zur Auswahl, die einen Blick wert sind:
- Percy.io, ein Tool von Browserstack, das ich für diese Anleitung verwende;
- Visual Regression Tracker, wenn Sie es vorziehen, keine SaaS-Lösung zu verwenden und gleichzeitig vollständig Open Source zu werden;
- Applitools mit KI-Unterstützung. Im Magazin Smashing gibt es einen spannenden Leitfaden zu diesem Tool;
- Chromatisch von Storybook.
Für diesen Leitfaden und im Grunde für mein Portfolio-Projekt war es wichtig, meine vorhandenen Cypress-Tests für visuelle Tests wiederzuverwenden. Wie bereits erwähnt, verwende ich Percy für dieses Beispiel aufgrund seiner einfachen Integration. Obwohl es sich um eine SaaS-Lösung handelt, werden viele Teile Open Source bereitgestellt, und es gibt einen kostenlosen Plan, der für viele Open Source- oder andere Nebenprojekte ausreichen sollte. Wenn Sie sich jedoch wohler fühlen, vollständig selbst gehostet zu werden und gleichzeitig ein Open-Source-Tool zu verwenden, können Sie dem Visual Regression Tracker eine Chance geben.
Dieser Leitfaden gibt Ihnen nur einen kurzen Überblick über Percy, der ansonsten Inhalt für einen völlig neuen Artikel liefern würde. Ich gebe Ihnen jedoch die Informationen, um Ihnen den Einstieg zu erleichtern. Wenn Sie jetzt in die Details eintauchen möchten, empfehle ich Ihnen, sich Percys Dokumentation anzusehen. Also, wie können wir unseren Tests sozusagen Augen geben? Nehmen wir an, wir haben bereits einen oder zwei Cypress-Tests geschrieben. Stell sie dir so vor:
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); });Sicher, wenn wir Percy als unsere visuelle Testlösung installieren möchten, können wir das mit einem Cypress-Plugin tun. Also, wie wir es heute schon ein paar Mal getan haben, installieren wir es in unserem Stammordner, indem wir NPM verwenden:
npm install --save-dev @percy/cli @percy/cypress Anschließend müssen Sie nur noch das Paket percy/cypress in Ihre Indexdatei cypress/support/index.js :
import '@percy/cypress';Dieser Import ermöglicht es Ihnen, den Snapshot-Befehl von Percy zu verwenden, der einen Snapshot von Ihrer Anwendung erstellt. In diesem Zusammenhang bedeutet ein Schnappschuss eine Sammlung von Screenshots, die von verschiedenen Ansichtsfenstern oder Browsern aufgenommen wurden, die Sie konfigurieren können.
it('should load home page (visual)', () => { cy.get('[data-cy=Polaroid]').should('be.visible'); cy.get('[data-cy=FeaturedPosts]').should('be.visible'); // Take a snapshot cy.percySnapshot('Home page'); }); Um auf unsere Workflow-Datei zurückzukommen, möchte ich das Percy-Testen als zweiten Schritt des Jobs definieren. Darin führen wir das Skript npx percy exec -- cypress run , um unseren Test zusammen mit Percy auszuführen. Um unsere Tests und Ergebnisse mit unserem Percy-Projekt zu verbinden, müssen wir unser Percy-Token weitergeben, das durch ein GitHub-Geheimnis verborgen ist.
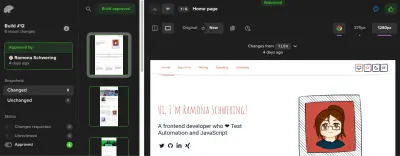
steps: # Before: Checkout, NPM, and E2E steps - name: Percy Test run: npx percy exec -- cypress run env: PERCY_TOKEN: ${{ secrets.PERCY_TOKEN }}Warum brauche ich ein Percy-Token? Das liegt daran, dass Percy eine SaaS-Lösung zur Verwaltung unserer Screenshots ist. Es wird die Screenshots und den Status quo zum Vergleich aufbewahren und uns einen Screenshot-Genehmigungs-Workflow zur Verfügung stellen. Dort können Sie anstehende Änderungen genehmigen oder ablehnen:
Anzeigen unserer Werke: GitHub-Integration
Glückwünsche! Wir haben erfolgreich unseren allerersten GitHub-Aktionsworkflow erstellt. Werfen wir einen letzten Blick auf unsere vollständige Workflow-Datei im Repository meiner Portfolio-Seite. Wundern Sie sich nicht, wie es in der Praxis aussieht? Sie finden Ihre funktionierenden GitHub-Aktionen auf der Registerkarte „Aktionen“ Ihres Repositorys:
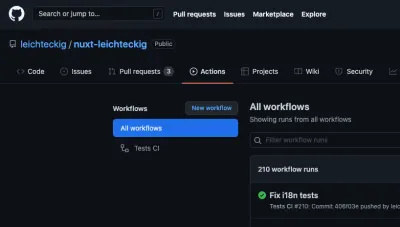
Darin finden Sie alle Workflows, die Ihren Workflow-Dateien entsprechen. Wenn Sie sich einen Workflow ansehen, z. B. meinen „Tests CI“-Workflow, können Sie alle Jobs davon einsehen:
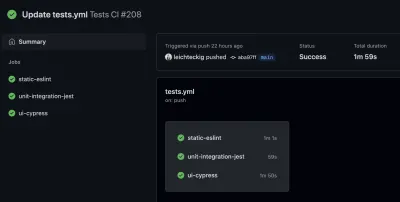
Wenn Sie sich einen Ihrer Jobs ansehen möchten, können Sie ihn auch in der Seitenleiste auswählen. Dort können Sie das Protokoll Ihrer Jobs einsehen:
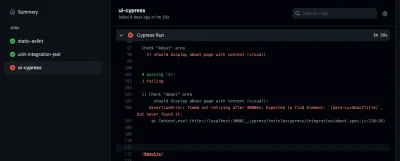
Sie sehen, Sie können Fehler erkennen, wenn sie innerhalb Ihrer Pipeline auftreten. Übrigens ist die Registerkarte „Aktion“ nicht der einzige Ort, an dem Sie die Ergebnisse Ihrer GitHub-Aktionen überprüfen können. Sie können sie auch in Ihren Pull-Requests überprüfen:
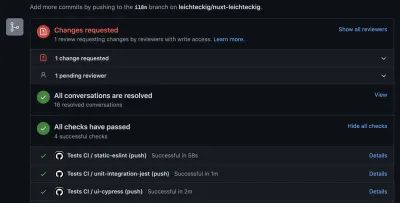
I like to configure those GitHub actions the way they need to be executed successfully: Otherwise, it's not possible to merge any pull requests into my repository.
Fazit
CI/CD helps us perform even major refactorings — and dramatically minimizes the risk of running into nasty surprises. The testing part of CI/CD is taking care of our codebase being continuously tested and monitored. Consequently, we will notice errors very early, ideally before anyone merges them into your main branch. Plus, we will not get into the predicament of correcting our local tests on the way to work — or even worse — actual errors in our application. I think that's a great perspective, right?
To include this testing build routine, you don't need to be a full DevOps engineer: With the help of some testing frameworks and GitHub actions, you're able to implement these for your side projects as well. I hope I could give you a short kick-off and got you on the right track.
I'm looking forward to seeing more testing pipelines and GitHub action workflows out there! ️
Ressourcen
- An excellent guide on CI/CD by GitHub
- “The practical test pyramid”, Ham Vocke
- Articles on the testing trophy worth reading, by Kent C.Dodds:
- “Write tests. Not too many. Mostly integration”
- “The Testing Trophy and Testing Classifications”
- “Static vs Unit vs Integration vs E2E Testing for Frontend Apps”
- I referred to some examples of the Cypress real world app
- Documentation of used tools and frameworks:
- GitHub actions
- Eslint docs
- Witzige Dokumentation
- Cypress-Dokumentation
- Percy documentation