
Strategien für Headless-Projekte mit strukturierten Content-Management-Systemen
Veröffentlicht: 2022-03-10Dies ist der Leitfaden, den ich mir in den letzten Jahren gewünscht hätte, wenn ich Projekte mit Headless-Content-Management-Systemen (CMSs) durchgeführt habe. Ich war Entwickler, Berater für Benutzererfahrung und Technologie, Projektmanager, Informationsarchitekt und Autor. Die unterschiedlichen Hüte haben mir klar gemacht, dass, auch wenn wir schon seit einiger Zeit so genannte „headless“ CMS haben, es noch einiges zu tun gibt, um darüber nachzudenken, wie man sie am besten einsetzt.
Wir sind jetzt an einem Punkt angelangt, an dem sich viele von uns auf JavaScript-Frameworks für die Frontend-Arbeit verlassen und Designsysteme verwenden, die aus Komponenten und Kompositionen bestehen, anstatt nur flache Seitenlayouts zu implementieren. JAMstacks und isomorphe/universelle Apps, die sowohl auf dem Server als auch auf dem Client laufen, sind stark im Kommen. Das letzte Puzzleteil ist dann, wie wir alle Inhalte verwalten.
Herkömmliche CMS fügen APIs hinzu, um Inhalte über Netzwerkanfragen und das JSON-Format bereitzustellen. Darüber hinaus sind „kopflose“ CMS entstanden, die Inhalte ausschließlich über APIs bereitstellen. Mein Argument in diesem Artikel ist jedoch, dass wir weniger Zeit damit verbringen sollten, über „headless“ und mehr über „strukturierte Inhalte“ zu sprechen . Denn das ist die wesentliche Qualität dieser Systeme. Diese Systeme haben viele Auswirkungen auf unser Handwerk, und wir haben noch einen weiten Weg vor uns, um die guten Muster herauszufinden, wie wir mit diesen Technologien umgehen sollten.
Da ich von einem geisteswissenschaftlichen Hintergrund zur Technologieberatung gekommen bin, habe ich viel über die Organisation und Arbeit mit Webprojekten gelernt, die einen inhaltszentrierten Ansatz verfolgen – sowohl mit den neueren API-basierten als auch mit den traditionellen CMS. Ich habe zu schätzen gelernt, wie man früh mit tatsächlichen Live-Inhalten von einem CMS beginnt; dies in einem interdisziplinären rahmen zu tun, hat es nicht nur ermöglicht, komplexitäten früher aufzudecken, sondern gibt allen beteiligten auch eine handlungskraft und gibt möglichkeiten, über die herausforderungen und möglichkeiten von technologie und design im weitesten sinne nachzudenken.
Kopfloses WordPress
Jeder weiß, dass Benutzer eine langsame Website verlassen werden. Schauen wir uns die Grundlagen zum Erstellen eines entkoppelten WordPress genauer an. Lesen Sie einen verwandten Artikel →
In diesem Artikel schlage ich einige übergreifende Strategien vor, mit einigen konkreten Beispielen aus der Praxis, wie man über die Arbeit mit strukturierten Inhalten nachdenkt. Zum Zeitpunkt des Schreibens habe ich gerade angefangen, für ein SaaS-Unternehmen zu arbeiten, das einen solchen Content-Management-Service zum Hosten von Inhalten anbietet, die über APIs bereitgestellt werden. Ich werde darauf verweisen, sowohl aufgrund meiner früheren Erfahrungen damit in Projekten, an denen ich als Berater beteiligt war, als auch, weil ich denke, dass es die Punkte, die ich ansprechen möchte, treffend veranschaulicht. Betrachten Sie dies also als eine Art Haftungsausschluss.
Abgesehen davon denke ich seit ein paar Jahren darüber nach, diesen Artikel zu schreiben, und ich habe mich bemüht, ihn für jede Plattform anwendbar zu machen, für die Sie sich entscheiden. Lassen Sie uns also kurzerhand zwanzig Jahre in die Vergangenheit springen, um ein bisschen mehr zu verstehen, wo wir heute stehen.
Erste Schritte mit Webstandards
In den frühen 2000er Jahren inspirierte die Webstandards-Bewegung eine Branche dazu, ihre Arbeitsweise zu ändern. Ausgehend von einem „Layout-First“-Ansatz lenkten sie unsere Aufmerksamkeit darauf, wie Inhalte auf einer Seite semantisch mit HTML ausgezeichnet werden sollten: Das Menü einer Website ist kein <table> , es ist ein <nav> ; Eine Überschrift ist kein <b> , sondern ein <h1> . Es war ein bedeutender Schritt, über die verschiedenen Rollen von Inhalten nachzudenken, die das Web spielt, um Benutzern zu helfen, sie zu finden, zu identifizieren und aufzunehmen.
Die Web-Standards-Bewegung führte das Argument ein, dass semantisches Markup die Zugänglichkeit verbesserte, was auch das Ranking in den Google-Suchergebnissen verbesserte. Es markierte auch eine Veränderung in der Art und Weise, wie wir über Webinhalte dachten . Ihre Website war nicht mehr der einzige Ort, an dem Ihre Inhalte präsentiert wurden. Sie mussten auch darüber nachdenken, wie Ihre Webseiten in anderen visuellen Kontexten dargestellt werden, beispielsweise in Suchergebnissen oder Screenreadern. Dies wurde später durch soziale Medien und eingebettete Vorschauen geteilter Links angeheizt. Die Denkweise verlagerte sich von der Art und Weise, wie der Inhalt aussehen sollte, hin zu seiner Bedeutung . Dies ist auch der Schlüssel zum Arbeiten mit strukturierten Inhalten.
Mit der Einführung von Geräten im Taschenformat, die mit dem Internet verbunden sind, wurde das Internet plötzlich zu einem ernsthaften Anwärter auf Apps. Die Konkurrenz galt jedoch hauptsächlich den Augäpfeln des Endbenutzers. Viele Organisationen mussten immer noch Informationen über ihre Produkte und Dienstleistungen sowohl in ihren Apps als auch in ihren verschiedenen Webpräsenzen verbreiten. Gleichzeitig reifte das Web, und JavaScript und AJAX machten es einfacher, verschiedene Inhaltsquellen über APIs zu verbinden. Heute haben wir GraphQL und Tools, die das Abrufen von Inhalten und die Zustandsverwaltung vereinfachen. Und so beginnen sich die Teile des technologischen Puzzles zu fügen.
„Einmal erstellen, überall veröffentlichen“
Obwohl dies meist als „technologischer Wandel“ beschrieben wird, hat die Einbettung von Inhalten in JSON-Nutzlasten (Reise entlang HTTP-Röhren) einen übergroßen Einfluss darauf, wie wir über digitale Inhalte und die umgebenden Arbeitsabläufe denken. In gewisser Weise hat es das bereits. Vor fast zehn Jahren bloggte Daniel Jacobson vom National Public Radio (NPR) als Gast auf programmierbarweb.com über ihren Ansatz, der im Akronym COPE zusammengefasst ist, das für „Create Once, Publish Everywhere“ steht. In dem Artikel stellt er ein Content-Management-System vor, das Inhalte für mehrere digitale Schnittstellen über eine API bereitstellt – nicht über eine HTML-Rendering-Maschine – wie es die meisten CMS zu dieser Zeit (und wohl auch heute) taten.
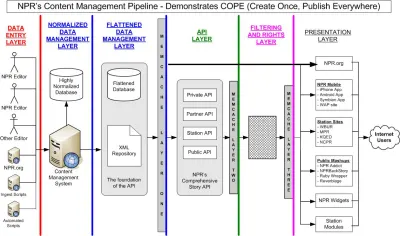
Die COPE-„Datenverwaltungsschicht“ von NPR ist das, was zu dem Begriff „ein kopfloses CMS“ werden sollte. In den Anfängen von COPE wurde dies durch die Strukturierung des Inhalts in XML erreicht. Heute ist JSON das dominierende Datenformat für die Übertragung von Daten über APIs, einschließlich Internet-of-Things-Geräten und anderen Systemen außerhalb des Webs. Wenn Sie Inhalte mit Chatbots, Sprachschnittstellen und sogar Software für visuelles Prototyping austauschen möchten, sprechen Sie HTTP sehr oft mit einem JSON-Akzent.
„Uncoining“ Der Begriff „Headless CMS“
Laut Google Trends gewann die Suche nach „headless CMS“ erst 2015 an Popularität, also sechs Jahre nach dem COPE-Artikel von NPR. Der Begriff „kopflos“ (zumindest in Bezug auf die digitale Technologie und nicht auf die französische Aristokratie des späten 18. Jahrhunderts) wird schon seit geraumer Zeit verwendet, um über Systeme zu sprechen, die ohne grafische Benutzeroberfläche laufen.
Hinweis : Man könnte argumentieren, dass eine Befehlszeilenschnittstelle tatsächlich „grafisch“ ist, wie Software auf Servern oder Testumgebungen (aber heben wir uns das für einen anderen Artikel auf).
Ich bin zwiegespalten, wenn ich diese neuen CMS als „kopflos“ bezeichne. Wir könnten sie genauso gut „polyzephal“ nennen – das, was viele Köpfe hat. Sie sind die Hydras und Cerbeuses von CMSs. „Headless“ definiert diese Systeme auch durch die ihnen fehlenden Fähigkeiten (dh eine Template-Engine zum Rendern von Webseiten), anstatt sie durch ihre wahre Stärke zu definieren: die Möglichkeit, Inhalte ohne die Einschränkungen des Webs zu strukturieren. Allerdings könnten viele der Lösungen in dieser Kategorie Stand heute auch „Nearly Headless Nick“ heißen. Denn die Redaktionsoberfläche ist nach wie vor eng an das System gekoppelt. Ihre „Kopflosigkeit“ ergibt sich aus dem Fehlen einer Templating-Engine, d. h. der Maschinerie, die Markup aus Inhalten erzeugt.
Hinweis : Ich würde aber mit ziemlicher Sicherheit ein CMS namens „Mimsy-Porpington“ (bekannt aus dem Harry-Potter-Universum) verwenden.
Stattdessen stellen sie Inhalte über eine API zur Verfügung, wodurch Sie mehr Flexibilität dafür haben, wie, was und wo Sie diese Inhalte anzeigen und verwenden möchten. Dies macht sie zu perfekten Begleitern für beliebte JavaScript-Frontend-Frameworks wie React, Angular und Vue. Und trotz des Anspruchs, Inhalte an „Websites, Apps und Geräte“ liefern zu können, sind die meisten von ihnen immer noch durch die Funktionsweise von Webinhalten eingeschränkt. Dies macht sich am deutlichsten in der Art und Weise bemerkbar, wie die meisten mit Rich Text umgehen – es wird entweder als HTML oder Markdown gespeichert.
Traditionelle CMS haben auch begonnen, zusätzlich zu ihren Template-Rendering-Systemen etwas generische APIs hinzuzufügen, und nennen dies „entkoppelt“, um sich von ihren frischen Konkurrenten abzuheben. „Das alles und APIs auch!“* lautet der Claim. Einige dieser CMS sind auch ziemlich agnostisch, wenn es um die Inhaltsmodellierung geht. Zum Beispiel macht Craft CMS fast keine Annahmen über Ihr Inhaltsmodell, wenn Sie es zum ersten Mal installieren. Wordpress bewegt sich auch in Richtung der Verwendung von APIs für die Bereitstellung von Inhalten. Ich vermute, dass die Kluft zwischen den alten Playern im CMS-Bereich und den neuen im Laufe der Zeit kleiner werden wird.
Nichtsdestotrotz ist es ein wichtiger Schritt hin zu anspruchsvolleren Arbeitsweisen in einer Zeit, in der die Texte, Bilder, Videos und Medien eines Unternehmens digitalisiert und internen und externen Benutzern und Kunden zugänglich gemacht werden, die Inhaltsverwaltung hinter APIs (anstelle eines HTML-Renderers) zu stellen. Es ist jedoch an der Zeit, sich von der Definition ihrer fehlenden Frontend-Rendering-Fähigkeiten zu dem zu bewegen, was sie wirklich für uns tun können: uns eine Möglichkeit zu geben, mit strukturierten Inhalten zu arbeiten . Sollten wir sie also „Structured Content Management Systems“ nennen? Wie in: „Nein Bob, das ist nicht dein übliches CMS. Das ist ein SCMS, glauben Sie mir, es wird eine Sache.“
Es geht nicht um die Köpfe, es geht um strukturierte Inhalte
Die radikalste Änderung, die das Structured Content Management System (SCMS) mit sich bringt, ist die Abkehr von der Anordnung von Inhalten gemäß einer Seitenhierarchie hin zu einer Strukturierung von Inhalten für jeden Zweck, den Sie für richtig halten. Die Vermeidung von Duplicate Content ist ein klarer Vorteil, da es die Zuverlässigkeit erhöht und den Verwaltungsaufwand verringert (Sie müssen sich nicht mit duplizierten Inhalten über mehrere Kanäle hinweg auseinandersetzen). Mit anderen Worten: Einmal erstellen, überall veröffentlichen . Wenn Sie Ihre Produktbeschreibung nur einmal aktualisieren müssen – in einem System – und sie überall dort aktualisiert wird, wo Ihr Produkt dem Benutzer ausgesetzt ist, ist das eindeutig ein Vorteil.
Während SCMS-Anbieter häufig „Ihre Website und eine App“ verwenden, um eine andere Denkweise bei der Seitenstruktur zu rechtfertigen, müssen Sie nicht den Fluss überqueren, um Vorteile aus einer strukturierten Inhaltsstruktur zu ziehen. Mit der Popularität von JavaScript-Frameworks wird es immer üblicher, Websites als Zusammenstellung einzelner Komponenten zu erstellen, die je nach Zustand und Kontext mit unterschiedlichen Inhalten „gefüllt“ werden können. Möglicherweise haben Sie eine Produktkarte, die in vielen verschiedenen Kontexten in Ihrer Webanwendung angezeigt wird. Wir sehen, dass sich die moderne Webentwicklung weg von der Erstellung von Dokumenten und Seiten hin zur Zusammenstellung von Komponenten gemäß einer Mischung aus Benutzereingaben, Algorithmen und Anpassung bewegt.
Diese Trends, wie Designsysteme erstellt werden und wie wir ermutigt werden, in Teams durch Prozesse des Testens, Lernens und Iterierens zu arbeiten, machen den Bereich des Content-Managements reif für einige neue Denkweisen. Einige Muster haben sich herausgebildet, aber wir haben noch viele Wege zu gehen. Basierend auf meiner Erfahrung aus der Arbeit in Teams und Projekten, die Inhalte in den Mittelpunkt gestellt haben und jetzt Teil eines Teams sind, das einen Service dafür aufbaut (und ich fordere Sie auf, sich hier jeglicher Voreingenommenheit bewusst zu sein), möchte ich dies tun einige Strategien vorschlagen, von denen ich glaube, dass sie hilfreich sein können, und Punkte für weitere Diskussionen schaffen.
1. Inhalte in multidisziplinären Teams angehen
Ich glaube, es gehört der Vergangenheit an, dass ein Grafikdesigner altbackene, pixelgenaue Seiten an einen Frontend-Entwickler übergeben kann, der für die „Umsetzung“ des Designs zuständig war. Wir stellen jetzt Designsysteme her, die aus kleineren Komponenten bestehen, die in Kompositionen angeordnet sind, die sofort mit mehreren möglichen Zuständen geliefert werden. In den meisten Fällen müssen diese Komponenten gegenüber benutzergenerierten Eingaben widerstandsfähig sein, was bedeutet, dass je früher Sie Live-Inhalte in den Prozess einführen, desto besser. Die Verantwortung eines Frontend-Entwicklers besteht nicht darin, die Vision eines Grafikdesigners zu reproduzieren ; Es geht darum, ein komplexes Feld zu manövrieren, wie Browser HTML, CSS und JavaScript rendern, und sicherzustellen, dass die Benutzeroberflächen reaktionsschnell, zugänglich und leistungsfähig sind.
Als ich als Technologieberater bei Netlife (einem auf Benutzererfahrung spezialisierten Beratungsunternehmen) arbeitete, sah ich, wie große Schritte in Richtung Zusammenarbeit zwischen Entwicklern, Designern und Benutzerforschern gemacht wurden. Obwohl unsere Content-Redakteure immer von Anfang an in das Projekt involviert waren, gelangten ihre Beiträge hauptsächlich aufgrund technischer Reibung nicht in den Design-Workflow.
Der Engpass war oft ein veraltetes CMS, das wir nicht anfassen konnten, oder dass es Zeit gekostet hat, die Inhaltsstruktur aufzubauen, weil sie vom Designlayout abhängig war. Dies führte oft zu Doppelarbeit: Wir erstellten einen HTML-Prototyp, oft basierend auf Inhalten, die aus Markdown-Dateien geparst wurden, die im CMS-Stack neu implementiert werden mussten, als die Benutzertests abgeschlossen waren, und alle waren pixelgenau zufrieden . Dies war oft ein kostspieliger Prozess, da Einschränkungen im CMS erst spät im Prozess entdeckt wurden. Es erzeugt auch Druck auf alle Teile, es gleich beim ersten Mal richtig zu machen, und lässt weniger Raum für die Art von Experimenten, die Sie in einem Designprojekt wünschen würden.
Multidisziplinäres Arbeiten erfordert flinke Systeme
Der Wechsel zu einem SCMS, bei dem es Minuten dauerte, ein Inhaltsmodell zu programmieren (wo Felder und API sofort bereit waren), stellte unseren Prozess auf den Kopf – und zwar zum Besseren. Ich erinnere mich, dass ich in den ersten Tagen des Projekts mit dem Inhaltseditor des neuen u4.no zusammensaß. Sprechen darüber, wie sie gearbeitet haben und mit ihren Inhalten arbeiten möchten. Ziemlich schnell übersetzten wir unsere Schlussfolgerungen in einfache JavaScript-Objekte, die sofort in eine Bearbeitungsumgebung im Browser umgewandelt wurden. Herausfinden hilfreicher Titel und Beschreibungen für die Titel. Wir sprachen darüber, wie sie Textausschnitte wollten, die sie auf verschiedenen Seiten und in verschiedenen Kontexten wiederverwenden konnten, die sie intern „Nuggets“ nannten, die wir dann und dort erstellten.
Diese Art der Erforschung früh in der Projektentwicklung zuzulassen – ein Redakteur und ein Entwickler, die miteinander sprechen, während die Benutzeroberfläche vor unseren Augen erstellt wurde – fühlte sich kraftvoll an. In dem Wissen, dass wir das Frontend in React weiter entwerfen konnten, während sie und ihre Kollegen mit der Arbeit an den Inhalten begannen. Und wir müssen uns keine Gedanken darüber machen, uns selbst in die Ecke zu drängen, wie wir es oft bei CMS getan haben, bei denen die Struktur eng damit gekoppelt war, wie man den Frontend-Teil davon codieren musste.
Ein Inhaltssystem sollte Experimente und Wiederholungen zulassen
Abgesehen von kreativen Redesign-Projekten sollte ein System für strukturierte Inhalte es Ihnen auch ermöglichen, Ihre Inhalte als Teil Ihres gesamten Designsystems weiter zu verbessern, zu testen und zu iterieren. UX-Designer sollten in der Lage sein, mithilfe von Tools wie Sketch oder Framer X schnell Prototypen mit echten Inhalten zu erstellen. Sie sollten in der Lage sein, das Inhaltsmanagement mit quantitativen Messungen zu erweitern, sei es Lesbarkeitsskalen oder wie der Inhalt dort abschneidet, wo er verwendet wird.
Hinweis : Ich habe oben den Begriff „UX-Designer“ verwendet, obwohl ich der Meinung bin, dass wir uns alle – in gewisser Weise – auf den Prozess beziehen sollten, gute Benutzererfahrungen zu machen. Wir sind alle UX-Designer in unseren verschiedenen Designbereichen.
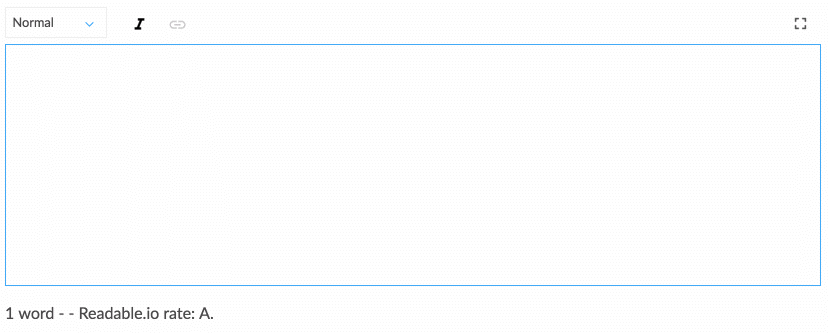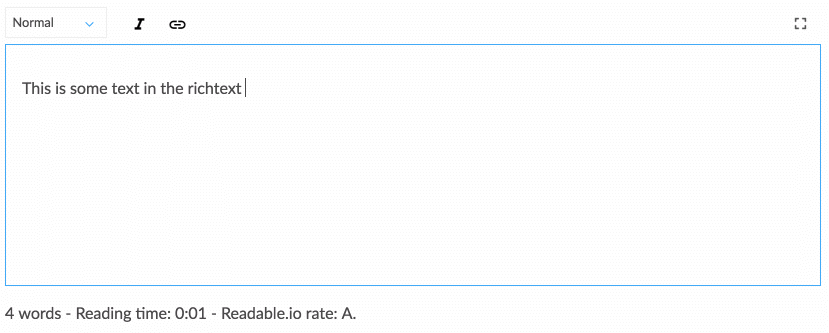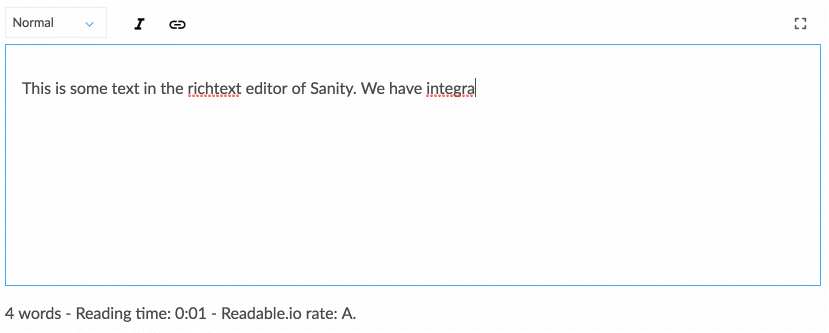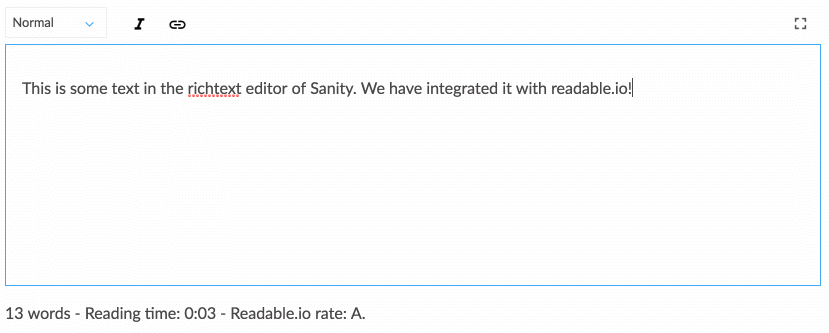
Das Arbeiten mit strukturierten Inhalten ist etwas gewöhnungsbedürftig, wenn Sie es gewohnt sind, Inhalte direkt in Ihrem Webseiten-Layout per WYSIWYG zu erstellen. Es eignet sich jedoch für ein Gespräch, das eher der Entwicklung des digitalen Designbereichs entspricht. Strukturierter Inhalt lässt ein Team aus Designern, Entwicklern, Inhaltsredakteuren, Benutzerforschern und Projektmanagern gemeinsam darüber nachdenken, wie ein System funktionieren sollte, um die Bedürfnisse und strategischen Ziele der Benutzer zu unterstützen. Dies erfordert auch, dass Sie anders darüber nachdenken, wie Inhalte strukturiert werden, was uns zur nächsten Strategie führt.
2. Möglicherweise benötigen Sie keine Hackordnung
Eine der bemerkenswertesten Änderungen für viele ist, dass Systeme für strukturierte Inhalte auf Sammlungen und Listen von Dokumenten ausgerichtet sind und nicht auf ordnerartige Hierarchien, die die Navigationsstrukturen von Websites widerspiegeln. Diese Strukturen machen keinen Sinn mehr, sobald ein Teil der Inhalte in anderen Kontexten verwendet werden soll – seien es Chatbots, Printmedien oder andere Websites. Herkömmliche CMS haben versucht, dies zu mildern, indem sie wiederverwendbare Inhaltsblöcke zulassen, aber sie müssen immer noch in Seitenlayouts platziert werden und sind umständlich über APIs zu verstehen.
Jede Seite für sich
Wie in Das Kernmodell dargelegt, sollten Sie jede Seite als Zielseite betrachten, wenn einer Ihrer Hauptverweiser entweder Google ist oder in sozialen Medien geteilt wird. Und wenn Sie sich die Verteilung der Seitenaufrufe ansehen, werden Sie feststellen, dass einige Ihrer Seiten viel beliebter sind als andere. Sofern Sie keine Nachrichten-Website sind, sind dies in der Regel nicht die Nachrichten, sondern diejenigen, mit denen der Benutzer auf Ihrer Website erreichen kann, was er sich erhofft hat. Sie sind der Ort, an dem das Geschäft tatsächlich stattfindet.
Ihre digitalen Inhalte sollten im Dienste der Schnittmenge Ihrer eigenen strategischen Ziele und der individuellen Ziele Ihrer Nutzer stehen. Als die Digitalagentur Bengler (Vorgänger von sanity.io) die neue Website für oma.eu erstellte, strukturierte sie die Inhalte nicht nach einer ausgeklügelten Seitenhierarchie. Sie erstellten Inhaltstypen, die die organisatorische Alltagsrealität widerspiegelten, dh nach Projekten , Personen und Veröffentlichungen . Tatsächlich ist die OMA-Website in Bezug auf die Inhaltshierarchie fast vollständig flach, und die Startseite wird aus einer Mischung aus algorithmischen und redaktionellen Regeln generiert.

Wie also vorgehen? Ich glaube, eine Mischung aus Denken über Ihre Inhalte als Spiegelbild dessen, wie das mentale Modell Ihrer Organisation ist und was es sein muss, um für alles, wofür Ihre Benutzer es brauchen, nützlich zu sein.
Hier ist ein einfaches Beispiel: Wenn Sie eine Seite mit Mitarbeitern erstellen, sollten Sie wahrscheinlich mit einem Inhaltstyp namens person beginnen. Eine Person kann einen Namen, Kontaktinformationen, ein Bild, verschiedene organisatorische Rollen und eine kurze Biographie haben. Ein Personendokument kann in Kontaktlisten, Verfasser-Bylines von Artikeln, Chat-Support-Schnittstellen und Gebäude-Zugriffsausweisen wiederverwendet werden. Vielleicht haben Sie bereits ein internes System, das weiß, wer diese Personen sind, und das mit einer API ausgestattet ist? Super, dann synchronisiere damit.
Verlieren Sie sich nicht in einem ontologischen Kaninchenbau
Es ist nützlich, auf die Art und Weise, wie Google Webseiten indexiert, zurückzukommen und wie sie versuchen, die Informationen der Welt zu indexieren. Deshalb investieren sie Zeit und Mühe in verknüpfte Daten (RDFa, Mikroformat, JSON-LD). Wenn Sie Ihre Webseiten mit JSON-LD-Elementen annotieren, erscheinen Sie prominenter in den Suchergebnissen. Es ist auch relevant, wenn Ihre Informationen von Sprachassistenten gesprochen und in einer Assistenten-Benutzeroberfläche angezeigt werden sollen. Wenn Ihre Inhalte bereits strukturiert und in einer API leicht verfügbar sind, wird es für Sie relativ einfach sein, sie in diesen Mikroformaten zu implementieren.
Ich bin mir jedoch nicht sicher, ob ich empfehlen würde, mich auf die Ontologien von schema.org und verschiedene verknüpfte Datenressourcen einzulassen, zumindest nicht für Editorzwecke. Sie können sich schnell in einem Kaninchenbau verlieren, wenn Sie versuchen, perfekte platonische Strukturen zu erstellen, in denen alles passt.
Newsflash : Das wird es nie, weil die Welt ein unordentlicher Ort ist und weil die Menschen anders über Dinge denken.
Wichtiger ist es, Ihre Inhalte in einem System zu strukturieren, das intuitiv sinnvoll ist und sich an veränderte Bedürfnisse anpassen lässt. Aus diesem Grund ist es wichtig, früh im Design- und Entwicklungsprozess mit der Inhaltsmodellierung zu beginnen – Sie müssen lernen, wie sie verwendet werden muss.
Abstrakt von der Realität, nicht von CMS-Konventionen
Es kann verlockend sein, einfach den Konventionen Ihres CMS zu folgen. Erinnern Sie sich, wie Wordpress Ihnen „Posts“ und „Pages“ gibt und plötzlich alles in diese Boxen passen muss? Ein WYSIWYG-Rich-Text-Feld ist insofern flexibel, als Sie alles eingeben können, aber der Inhalt ist nicht strukturiert und leicht anpassbar – es ist nur einmal flexibel. Aber Sie brauchen einen Ort, an dem Sie mit der Abbildung eines Inhaltsmodells beginnen können. Mein Vorschlag ist, zunächst mit den Menschen zu sprechen, also mit den Autoren und Lesern.
Wie wird intern über die Inhalte gesprochen? Wie nennen die Menschen verschiedene Dinge? Sie könnten eine kostenlose Listenübung durchführen, eine Methode, die von Ethnographen verwendet wird, um Volkstaxonomien abzubilden. Du könntest zum Beispiel fragen:
„Nennen Sie die verschiedenen Arten von Inhalten in unserer Organisation.“
Oder auf einer spezifischeren Ebene:
„Können Sie die verschiedenen Arten von Berichten nennen, die wir in dieser Organisation haben?“
Bei dieser Umfrage geht es darum, die verinnerlichten Taxonomien der Menschen herauszuarbeiten, und nicht ihre Meinungen oder Gefühle zu Dingen (etwas, das oft dazu neigt, Designprozesse zu entgleisen). Sie müssen nicht besonders viele Fragen stellen, bevor Sie eine ziemlich erschöpfende Liste haben, mit der Sie arbeiten können. Sie werden wahrscheinlich feststellen, dass Teile Ihrer Liste aus Konventionen in Ihrem aktuellen CMS stammen (das ist gut zu wissen, wenn Sie etwas umgestalten müssen). Jetzt sollten Sie mit Ihrem Redakteur sprechen und versuchen herauszufinden, wozu der Inhalt benötigt wird.
Einige Fragen, die Sie stellen können, könnten die folgenden sein:
- Müssen Sie diese Inhalte an mehr als einem Ort verwenden? Woher?
- Welche unterschiedlichen Beziehungen bestehen zwischen den Inhaltstypen?
- Wo brauchen wir die Inhalte, die heute und morgen angezeigt werden sollen?
- Auf welche Weise müssen Inhalte sortiert werden? Kann die Bestellung algorithmisch durch den Benutzer erfolgen oder muss sie manuell erfolgen?
- Gibt es Systeme oder Datenbanken in anderen Systemen, mit denen wir synchronisieren können, um Doppelarbeit zu vermeiden?
- Wo sollen die kanonischen Inhalte leben? Soll das SCMS die Quelle dafür sein oder nur vorhandene Inhalte ergänzen, zB Marketingtexte für Produkte, die in einem Produktmanagementsystem leben?
Das bedeutet nicht, dass Sie die traditionelle Informationsarchitektur mit dem mittlerweile lauwarmen Badewasser ausschütten müssen. Es ist immer noch sinnvoll, Artikel als Inhaltstyp zu haben, wenn Artikel Teil der Inhaltsrealität Ihrer Organisation sind. Aber vielleicht brauchen Sie die abstrakte Konvention der Kategorien nicht wirklich, weil diese Artikel Verweise auf die Art der Dienstleistungen oder Produkte in ihnen haben. Und diese Beziehung ermöglicht es, diese Artikel unter Umständen abzufragen, in denen es sinnvoll ist, ohne dass jemand „Artikelkategorieverwaltung“ als Teil seiner Stellenbeschreibung haben muss.
Der Artikel macht es auch schwierig, Inhalte vollständig von der Präsentationsebene zu entkoppeln. Wir sind so daran gewöhnt, über das Layout und die Gestaltung des Artikels nachzudenken, aber in einer Zeit, in der von Ihnen erwartet wird, dass Sie Ihre eigenen Inhalte auf Ihrer eigenen Domain hosten und sie dann auf Plattformen wie medium.com syndizieren, haben Sie bereits aufgegeben Kontrolle über die visuelle Darstellung. Dies bringt uns zur nächsten Strategie.
3. Präsentationskontexte sind auch Inhaltstypen
Seien Sie bereit für die Neugestaltung
Sie möchten auch die Navigationsstruktur Ihrer Website anpassen und schnell ändern können, ohne entweder Ihre gesamte Content-Architektur neu aufbauen oder gegen eine stringente Ordner-ähnliche Oberfläche kämpfen zu müssen. Sie möchten auch in der Lage sein, eine Inhaltshierarchie zu haben, da dies manchmal sinnvoll ist und manchmal tiefer als zwei Ebenen geht, wo die meisten Schnittstellen in der Abteilung von API-First-CMS keine große Hilfe bieten.
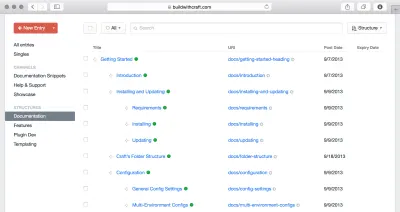
Interessanterweise neigen Content-Management-Systeme für Chatbots dazu, ähnliche hierarchische Strukturen zum Anordnen von Absichtsbäumen und Dialogabläufen zu verwenden. Das bedeutet, dass Inhaltshierarchien in verschiedenen Kanälen unterschiedliche Rollen spielen, aber oft bieten sie Möglichkeiten, durch Inhalte zu navigieren. Eine Möglichkeit, dies zu erreichen, besteht darin, Typen für die Navigation zu erstellen, bei denen Sie Inhalte nach Verweisen anordnen und entweder Routen für Webseiten, Menüs oder Pfade für Konversationsschnittstellen erstellen können.
Beziehungsratschlag
Referenzen (oder Beziehungen) machen ein System für strukturierte Inhalte möglich, und sie sind wirklich der Kern von allem, womit wir es zu tun haben, wenn es um Inhalte im Web geht (das ist der Grund, warum es überhaupt metaphorisch Web genannt wird). In der Lage zu sein, Verweise zwischen Inhaltsteilen herzustellen, ist eine sehr mächtige Sache, aber es kann auch kostspielig sein, wenn es darum geht, wie die Backends solche Daten schreiben und abrufen können. Wenn Sie also über eine Vielzahl von Dokumenten verfügen, müssen Sie möglicherweise anders denken, da Skalierung selten kostenlos ist.
Es ist auch zu bedenken, dass Sie nicht immer eine explizite Referenz benötigen, um Daten zu verknüpfen. Meistens kann dies nach inhaltlichen Kriterien erfolgen, zB „Geben Sie mir alle Personen und alle Gebäude innerhalb dieser Geolokalisierung“. Das Gebäude und die Personen müssen keinen ausdrücklichen Bezug zueinander haben, solange dies in einem Standortfeld in beiden Inhaltstypen impliziert ist.
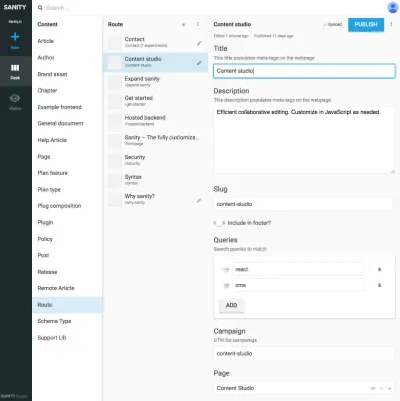
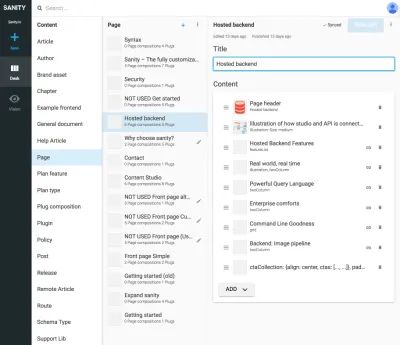
Verweise zwischen Präsentationstypen und anderen Inhaltstypen sind nützlich, wenn Sie es nicht einem Algorithmus in der Präsentationsebene überlassen können, Daten zu verbinden. Es mag etwas umständlich erscheinen, diese Präsentationstypen explizit zu zeichnen und Zusammenstellungen von verwiesenen Inhalten zu erstellen, aber es ist eine Lösung für ein Problem, auf das Sie bei SCMSs häufig stoßen: Es ist schwer zu wissen, wo Inhalte verwendet werden. Durch das Einbeziehen von Navigationstypen binden Sie den Inhalt ausdrücklich an die Präsentation, aber nicht nur an eine. Dies ermöglicht es, sinnvoll mit Navigationsstrukturen zu arbeiten, unabhängig von den Inhalten, zu denen sie führen.
Beispielsweise haben wir in den Screenshots Google Experiments an den Routentyp gebunden, was das Hinzufügen mehrerer Seiten ermöglicht, die aus Verweisen auf Inhalte bestehen, was bedeutet, dass wir A/B-Tests mit nahezu keiner Duplizierung von Inhalten durchführen können. Da wir auch eine Warnung erhalten, wenn wir versuchen, Inhalte zu löschen, auf die von anderen Dokumenten verwiesen wird, hält uns diese Art der Strukturierung davon ab, etwas zu löschen, was wir nicht sollten.
Beziehungen zwischen Inhaltstypen sind ein zweischneidiges Schwert. Es erhöht die Nachhaltigkeit und ist der Schlüssel zur Vermeidung von Doppelarbeit. Andererseits können Sie sich leicht schneiden, weil Sie Abhängigkeiten zwischen Inhalten herstellen, die (wenn nicht transparent gemacht) zu unbeabsichtigten Änderungen über die Kanäle hinweg führen können, auf denen Ihre Daten angezeigt werden. Es wäre zum Beispiel schlecht, wenn wir eine „Seite“, die von einer „Route“ verwendet wird, ohne Vorwarnung entfernen könnten.
Dies führt uns zur nächsten Strategie, die (zugegeben!) teilweise außerhalb der Macht des normalen Benutzers liegt, da sie damit zu tun hat, wie unterschiedliche Systeme aufgebaut sind. Dennoch lohnt es sich, darüber nachzudenken.
4. Stellen Sie Rich-Text nicht in eine Ecke
Rich-Text ist mehr als HTML
Ich kann verstehen, warum HTML in digitalen Inhalten so weit verbreitet ist, aber ich weiß, dass es auch von etwas kommt; Es ist eine Teilmenge von SGML, einer verallgemeinerten Art, maschinenlesbare Dokumente zu strukturieren. Wie Claire L. Evans in dem wunderbaren Buch „Broad Band: The Untold Story of the Women who made the Internet“ (2018) aufzeigt, gab es bereits bei der Einführung von HTML eine lebendige Community von Menschen, die über verlinkte Dokumente nachdachten. Der Vorschlag von Tim Berners-Lee war viel einfacher als viele der anderen Systeme zu dieser Zeit, aber wahrscheinlich hat er sich deshalb durchgesetzt und das – ab sofort – offene, kostenlose Web ermöglicht.
Wenn Sie sich in einem Browser im World Wide Web befinden, ist HTML großartig. Wenn Sie ein Autor sind, der etwas veröffentlichen möchte, das in einfachem HTML endet, ist Markdown großartig. Wenn Sie möchten, dass Ihre Rich-Text-Inhalte einfach in etwas integriert werden können, das kein Browser ist, oder in ein beliebtes JavaScript-Framework, mit dem Sie HTML mit JavaScript in komplexen Komponenten erweitern können (ja, wir sprechen von React und Vue.js) , HTML in Ihren API-Antworten zu haben, wird ein bisschen mühsam – besonders wenn Sie es parsen müssen.
Fast jeder macht es jedoch, sogar die neuen Kids auf dem Block: Ich bin alle Anbieter auf headlesscms.org durchgegangen und habe die Dokumentation durchgesehen und mich auch für diejenigen angemeldet, die es nicht erwähnt haben. Mit zwei Ausnahmen speicherten sie alle Rich Text entweder als HTML oder Markdown. Das ist in Ordnung, wenn Sie nur Jekyll verwenden, um eine Website zu rendern, oder wenn Sie gefährlich SetInnerHTML in React verwenden. Aber was ist, wenn Sie Ihre Inhalte in Schnittstellen wiederverwenden möchten, die nicht im Web vorhanden sind? Oder möchten Sie mehr Kontrolle und Funktionalität in Ihrem Rich-Text-Editor? Oder möchten Sie einfach, dass es einfacher ist, Ihren Rich-Text in einem der beliebten Frontend-Frameworks zu rendern, und Ihre Komponenten sich um verschiedene Teile Ihres Rich-Text-Inhalts kümmern sollen? Nun, Sie müssen entweder einen intelligenten Weg finden, diesen Markdown oder HTML in das zu parsen, was Sie brauchen, oder, was bequemer ist, ihn einfach sinnvoller speichern lassen.
Was ist zum Beispiel, wenn Sie Ihren Rich-Text an eine Sprachschnittstelle ausgeben möchten? Wir wissen, dass Sprachassistenten immer beliebter werden. Die beliebtesten Plattformen für diese Assistenten haben die Möglichkeit, den Text für gesprochene Inhalte über APIs abzurufen. Dann möchten Sie etwas wie Speech Synthesis Markup Language nutzen. Ein System für portablen Text verfolgt einen agnostischeren Ansatz für Rich Text, wodurch Sie denselben Inhalt für verschiedene Arten von Schnittstellen anpassen können.
Empfohlene Lektüre : Experimentieren mit der SpeechSynthesis-Schnittstelle
Portabler Text als agnostisches Rich-Text-Modell
Portabler Text ist auch nützlich, wenn Sie hauptsächlich Inhalte für das Web erstellen. Was ist, wenn Sie die Möglichkeit haben möchten, Ihren Text zu verschachteln und mit Datenstrukturen zu erweitern, wie z. B. eine Rich-Text-Fußnote oder einen redaktionellen Kommentar? Oder einen alternativen Ausdruck oder Wortlaut für A/B-Testfälle? Markdown und HTML kommen schnell zu kurz, und Sie müssen sich darauf verlassen, so etwas wie spezielle Shortcode-Tags hinzuzufügen, so wie es Wordpress gelöst hat. With portable text, you have an agnostic representation of content structures, without having to marry a certain implementation. Your content ends up being more sustainable and flexible for new redesigns and implementations.
There are also other advantages to portable text, especially if you want to be able to edit content collaboratively and in real time (as you do in Google Docs); you need to store rich text in another structure than HTML. If you do, you'll also be able to take advantage of microservices and bots, such as spaCy, in order to annotate and augment your content without locking the document.
As for now, portable text isn't widely adopted, but we're seeing movements towards it. The specification isn't very complex and can be explored at portabletext.org.
5. Make Sure Your SCMS Is In Service For Your Editors, And Not The Other Way Around
Digital content isn't just used for your organization's online web page leaflets anymore. For most of us, it encapsulates and defines how your organization is understood by the world, both from those within it and those outside: From product copy, micro texts to blog posts, chatbot responses, and strategy documents. We are millions of people that have to log into some CMS every day and navigate interfaces that were imagined twenty years ago with the assumptions of people who have never made much effort to user test or challenge their interfaces. Countless hours have been wasted away trying to fit a modern frontend experience into a page layout machine. Fortunately, this is soon a thing of the past.
As a technology consultant, I had to read through pages of technical specification whenever someone thought it was time to acquire a new CMS for themselves. There were demands from which server architecture it should run on (Windows servers, of course) to their ability to render “carousels” and “being able to edit web pages in place”, despite also requesting a “modular redesign”. When editors had been allowed to contribute to these specifications, they were also often dated to the what the editors had begotten used to. They seemed not aware that they could demand better user experiences, because enterprise software has to be big, lumpy and boring.
This is partly the fault of us making these systems. We tend to communicate technology features and specifications, and less what the everyday situation working with these systems look like. Sure, for a frontend designer, something supporting GraphQL is shorthand for how conveniently she is able to work against the backend, but on a higher level, it's about the systems ability to accommodate for emerging workflows, where a content model could survive visual redesigns and design systems should be resilient to changes of its content.
Questions To Ask Of Your (S)CMS
If we are to embrace design processes, we can't know prior to solving the problem whether the user tasks are best solved by making carousels ( newsflash: most probably not ), or whether A/B-testing makes sense for your case, even though it sounds cool.
Instead, ask questions like this:
- Is it possible, and how exactly will multi-disciplinary teams work with this system?
- How easy is it to change and migrate the content model?
- How does it deal with file and image assets?
- Has the editorial interface been user tested?
- To what extent can the system be configured and customized to special workflows and needs of the editorial team?
- How easy is it to export the content in a moveable format?
- How does the system accommodate for collaboration?
- Can content models be version controlled?
- How easy is it to integrate the system with a larger ecosystem of flowing information?
The goal of these questions is to explore to what degree a content management system allows for a cross-disciplinary team to work effortlessly together, without too many bottle-necks or long deployment cycles. They also push the focus to be more about the content should be doing, and less about how things should look in a given context. Leave that for the design processes, where user testing probably will challenge assumptions one may have when looking into getting a new content system.
There are, of course, many factors in addition to this that probably have to be taken into consideration. The easiest thing to assess is the fiscal cost of software licenses and API-related costs if you are on a hosted service. The invisible cost (in time and attention spent by the team working with the system), is harder to estimate. From my experience, many of the SCMSs in combination with one of the popular frontend frameworks can significantly cut development time and allow for an agile ( there's my coin for the swear jar ) design process. With the caveat that your team is prepared to solve some of the problems that come out of the box with traditional CMSs.
Towards Structured Content
The ways we work with digital content has changed dramatically since the World Wide Web made working with interconnected documents mainstream. Organizations, businesses, and corporations have amassed gigabytes of this content, which now is stuck in rigid page hierarchies, HTML markup, and clunky user interfaces.
Using a Structured Content Management System can be a great way to free your content from a paradigm that begins to feel its age. But it isn't a trivial exercise, and success comes from being able to work multi-disciplinary and put your content model to the test. You need to get rid of some conventions you have grown used to by dealing with CMSs designed to output hierarchical websites. That means that you need to think differently about ordering content, make presentations types in order to make it easier to orchestrate content across multiple channels and to consider how you structure rich text so that it can be used outside of HTML contexts.
This article deals with some of the high-level concerns working with SCMSs. There are, of course, loads of exciting challenges when you start working with this in your team. You have to rethink stuff we've taken for granted for many years, but that's probably a good thing. Because we are forced to evaluate our content, not only from its place on a digital page but from its role in a larger system that works for whatever goals your organization and your users may have.
I believe that we can achieve content models that are more meaningful and easier to sustain in the long run, and that means saving time and expenses. It means more flexibility in terms of inventing new outputs and services, and less tie in with software vendors. Because a well-made Structured Content Management System will make it easy for you to take your content and go elsewhere. And that makes for some interesting competition. Hopefully, all in favor of the users.