
Verwendung von SSE anstelle von WebSockets für unidirektionalen Datenfluss über HTTP/2
Veröffentlicht: 2022-03-10Beim Erstellen einer Webanwendung muss berücksichtigt werden, welche Art von Bereitstellungsmechanismus verwendet wird. Nehmen wir an, wir haben eine plattformübergreifende Anwendung, die mit Echtzeitdaten arbeitet; eine Börsenanwendung, die die Möglichkeit bietet, Aktien in Echtzeit zu kaufen oder zu verkaufen. Diese Anwendung besteht aus Widgets, die den verschiedenen Benutzern unterschiedliche Werte bringen.
Bei der Datenlieferung vom Server zum Client beschränken wir uns auf zwei allgemeine Ansätze: Client-Pull oder Server-Push . Als einfaches Beispiel für jede Webanwendung ist der Client der Webbrowser. Wenn die Website in Ihrem Browser den Server nach Daten fragt, wird dies als Client-Pull bezeichnet. Umgekehrt, wenn der Server proaktiv Updates auf Ihre Website überträgt, wird dies als Server-Push bezeichnet.
Heutzutage gibt es einige Möglichkeiten, diese umzusetzen:
- Long/Short-Polling (Client-Pull)
- WebSockets (Server-Push)
- Vom Server gesendete Ereignisse (Server-Push).
Nachdem wir die Anforderungen für unseren Business Case festgelegt haben, werden wir uns die drei Alternativen eingehend ansehen.
Der Geschäftsfall
Um neue Widgets für unsere Börsenanwendung schnell und Plug'n'Play ohne Neuinstallation der gesamten Plattform liefern zu können, müssen diese in sich geschlossen sein und ihre eigenen Daten-I/O verwalten. Die Widgets sind in keiner Weise miteinander gekoppelt. Im Idealfall abonnieren alle einen API-Endpunkt und fangen an, Daten von ihm zu erhalten. Neben einer schnelleren Markteinführung neuer Funktionen gibt uns dieser Ansatz die Möglichkeit, Inhalte auf Websites von Drittanbietern zu exportieren, während unsere Widgets alles selbst mitbringen, was sie benötigen.
Der größte Fallstrick hier ist, dass die Anzahl der Verbindungen linear mit der Anzahl der Widgets wachsen wird, die wir haben, und wir die Browser-Grenze für die Anzahl der gleichzeitig verarbeiteten HTTP-Anforderungen erreichen werden.
Die Daten, die unsere Widgets erhalten, bestehen hauptsächlich aus Zahlen und Aktualisierungen ihrer Zahlen: Die erste Antwort enthält zehn Aktien mit einigen Marktwerten für sie. Dies beinhaltet Aktualisierungen von Hinzufügen/Entfernen von Beständen und Aktualisierungen der Marktwerte der aktuell präsentierten. Wir übertragen kleine Mengen an JSON-Strings für jedes Update so schnell wie möglich.
HTTP/2 bietet Multiplexing der Anfragen, die von derselben Domain kommen, was bedeutet, dass wir nur eine Verbindung für mehrere Antworten erhalten können. Das klingt so, als könnte es unser Problem lösen. Wir beginnen damit, die verschiedenen Optionen zu erkunden, um die Daten zu erhalten und zu sehen, was wir daraus machen können.
- Wir werden NGINX für den Lastenausgleich und den Proxy verwenden, um alle unsere Endpunkte hinter derselben Domäne zu verstecken. Dadurch können wir HTTP/2-Multiplexing sofort verwenden.
- Wir wollen das Netz und den Akku der Mobilgeräte effizient nutzen.
Die Alternativen
Lange Abfrage

Client Pull ist das Softwareimplementierungsäquivalent des nervigen Kindes, das auf dem Rücksitz Ihres Autos sitzt und ständig fragt: „Sind wir schon da?“ Kurz gesagt, der Client fragt den Server nach Daten. Der Server hat keine Daten und wartet einige Zeit, bevor er die Antwort sendet:
- Wenn während des Wartens etwas auftaucht, sendet der Server es und schließt die Anfrage;
- Wenn nichts zu senden ist und die maximale Wartezeit erreicht ist, sendet der Server eine Antwort, dass keine Daten vorhanden sind;
- In beiden Fällen öffnet der Client die nächste Datenanforderung;
- Aufschäumen, ausspülen, wiederholen.
AJAX-Aufrufe arbeiten mit dem HTTP-Protokoll, was bedeutet, dass Anfragen an dieselbe Domäne standardmäßig gemultiplext werden sollten. Wir sind jedoch auf mehrere Probleme gestoßen, als wir versuchten, dies wie erforderlich zum Laufen zu bringen. Einige der Fallstricke, die wir bei unserem Widget-Ansatz identifiziert haben:
Kopfzeilen oben
Jede Abfrageanforderung und -antwort ist eine vollständige HTTP-Nachricht und enthält einen vollständigen Satz von HTTP-Headern im Nachrichtenrahmen. In unserem Fall, in dem wir kleine, häufige Nachrichten haben, stellen die Header tatsächlich den größeren Prozentsatz der übertragenen Daten dar. Die tatsächlich nutzbare Nutzlast ist viel geringer als die insgesamt übertragenen Bytes (z. B. 15 KB Header für 5 KB Daten).Maximale Latenz
Nachdem der Server geantwortet hat, kann er keine Daten mehr an den Client senden, bis der Client die nächste Anfrage sendet. Während die durchschnittliche Latenz für lange Abfragen nahe bei einem Netzwerktransit liegt, liegt die maximale Latenz bei drei Netzwerktransits: Antwort, Anfrage, Antwort. Aufgrund von Paketverlust und erneuter Übertragung beträgt die maximale Latenz für jedes TCP/IP-Protokoll jedoch mehr als drei Netzwerktransits (vermeidbar mit HTTP-Pipelining). Während dies bei einer direkten LAN-Verbindung kein großes Problem darstellt, wird es eines, wenn man unterwegs ist und Netzwerkzellen wechselt. Bis zu einem gewissen Grad ist dies bei SSE und WebSockets zu beobachten, am größten ist der Effekt jedoch bei Polling.Verbindungsaufbau
Obwohl dies vermieden werden kann, indem eine persistente HTTP-Verbindung verwendet wird, die für viele Polling-Anfragen wiederverwendbar ist, ist es schwierig, alle Ihre Komponenten so zu timen, dass sie in kurzen Zeitabfragen abfragen, um die Verbindung aufrechtzuerhalten. Abhängig von den Serverantworten werden Ihre Umfragen schließlich desynchronisiert.Leistungsverschlechterung
Ein Client (oder Server) mit langen Abfragen, der unter Last steht, hat eine natürliche Tendenz, die Leistung auf Kosten der Nachrichtenlatenz zu verringern. In diesem Fall werden Ereignisse, die an den Client gepusht werden, in die Warteschlange gestellt. Dies hängt wirklich von der Implementierung ab; In unserem Fall müssen wir alle Daten zusammenfassen, wenn wir Ereignisse zum Hinzufügen/Entfernen/Aktualisieren an unsere Widgets senden.Zeitüberschreitungen
Lange Polling-Anforderungen müssen ausstehend bleiben, bis der Server etwas an den Client zu senden hat. Dies kann dazu führen, dass die Verbindung vom Proxyserver geschlossen wird, wenn sie zu lange inaktiv bleibt.Multiplexing
Dies kann passieren, wenn die Antworten gleichzeitig über eine dauerhafte HTTP/2-Verbindung erfolgen. Dies kann schwierig sein, da Umfrageantworten nicht wirklich synchron sein können.
Weitere Informationen zu realen Problemen, die bei langen Umfragen auftreten können, finden Sie hier .
WebSockets

Als erstes Beispiel für die Server-Push- Methode betrachten wir WebSockets.
Über MDN:
WebSockets ist eine fortschrittliche Technologie, die es ermöglicht, eine interaktive Kommunikationssitzung zwischen dem Browser des Benutzers und einem Server zu öffnen. Mit dieser API können Sie Nachrichten an einen Server senden und ereignisgesteuerte Antworten erhalten, ohne den Server nach einer Antwort abzufragen.
Dies ist ein Kommunikationsprotokoll, das Vollduplex-Kommunikationskanäle über eine einzelne TCP-Verbindung bereitstellt.
Sowohl HTTP als auch WebSockets befinden sich auf der Anwendungsschicht des OSI-Modells und hängen als solche von TCP auf Schicht 4 ab.
- Anwendung
- Präsentation
- Sitzung
- Transport
- Netzwerk
- Datenverbindung
- Physisch
RFC 6455 besagt, dass WebSocket „so konzipiert ist, dass es über die HTTP-Ports 80 und 443 funktioniert und HTTP-Proxys und -Vermittler unterstützt“, wodurch es mit dem HTTP-Protokoll kompatibel ist. Um Kompatibilität zu erreichen, verwendet der WebSocket-Handshake den HTTP-Upgrade-Header, um vom HTTP-Protokoll zum WebSocket-Protokoll zu wechseln.
Es gibt auch einen sehr guten Artikel, der alles erklärt, was Sie über WebSockets auf Wikipedia wissen müssen. Ich ermutige Sie, es zu lesen.
Nachdem wir festgestellt hatten, dass Steckdosen tatsächlich für uns funktionieren könnten, begannen wir, ihre Fähigkeiten in unserem Business Case zu untersuchen, und trafen Wand für Wand für Wand.
Proxy-Server : Im Allgemeinen gibt es einige unterschiedliche Probleme mit WebSockets und Proxys:
- Der erste bezieht sich auf Internetdienstanbieter und die Art und Weise, wie sie mit ihren Netzwerken umgehen. Probleme mit Radius-Proxys blockierten Ports und so weiter.
- Die zweite Art von Problemen hängt mit der Art und Weise zusammen, wie der Proxy konfiguriert ist, um den ungesicherten HTTP-Datenverkehr und langlebige Verbindungen zu verarbeiten (die Auswirkungen werden mit HTTPS verringert).
- Das dritte Problem: „Bei WebSockets sind Sie gezwungen, TCP-Proxys im Gegensatz zu HTTP-Proxys auszuführen. TCP-Proxys können keine Header einfügen, URLs umschreiben oder viele der Rollen übernehmen, die wir traditionell unseren HTTP-Proxys überlassen.“
Eine Anzahl von Verbindungen : Das berühmte Verbindungslimit für HTTP-Anfragen, das sich um die Zahl 6 dreht, gilt nicht für WebSockets. 50 Steckdosen = 50 Anschlüsse. Zehn Browser-Tabs mal 50 Sockets = 500 Verbindungen und so weiter. Da WebSocket ein anderes Protokoll zum Übermitteln von Daten ist, wird es nicht automatisch über HTTP/2-Verbindungen gemultiplext (es läuft überhaupt nicht wirklich auf HTTP). Das Implementieren von benutzerdefiniertem Multiplexing sowohl auf dem Server als auch auf dem Client ist zu kompliziert, um Sockets im angegebenen Geschäftsfall nützlich zu machen. Darüber hinaus koppelt dies unsere Widgets an unsere Plattform, da sie eine Art API auf dem Client benötigen, um sie zu abonnieren, und wir sie ohne diese nicht verteilen können.
Lastausgleich (ohne Multiplexing) : Wenn jeder einzelne Benutzer
nSockets öffnet, ist ein ordnungsgemäßer Lastausgleich sehr kompliziert. Wenn Ihre Server überlastet sind und Sie je nach Implementierung Ihrer Software neue Instanzen erstellen und alte beenden müssen, können die Aktionen, die beim „Wiederverbinden“ ausgeführt werden, eine massive Kette von Aktualisierungen und neuen Datenanforderungen auslösen, die Ihr System überlasten . WebSockets müssen sowohl auf dem Server als auch auf dem Client gepflegt werden. Es ist nicht möglich, Socket-Verbindungen auf einen anderen Server zu verschieben, wenn der aktuelle stark ausgelastet ist. Sie müssen geschlossen und wieder geöffnet werden.DoS : Dies wird normalerweise von Front-End-HTTP-Proxys gehandhabt, die nicht von TCP-Proxys gehandhabt werden können, die für die WebSockets benötigt werden. Man kann sich mit dem Socket verbinden und beginnt, Ihre Server mit Daten zu überfluten. WebSockets machen Sie anfällig für diese Art von Angriffen.
Das Rad neu erfinden : Bei WebSockets muss man viele Probleme, die in HTTP erledigt werden, alleine bewältigen.
Weitere Informationen zu realen Problemen mit WebSockets finden Sie hier.
Einige gute Anwendungsfälle für WebSockets sind Chats und Multiplayer-Spiele, bei denen die Vorteile die Implementierungsprobleme überwiegen. Da ihr Hauptvorteil die Duplexkommunikation ist und wir sie nicht wirklich brauchen, müssen wir weitermachen.
Einfluss
Wir haben einen erhöhten Betriebsaufwand in Bezug auf Entwicklung, Tests und Skalierung; die Software und ihre IT-Infrastruktur mit beiden: Polling und WebSockets.
Wir bekommen das gleiche Problem über mobile Geräte und Netzwerke mit beiden. Das Hardwaredesign dieser Geräte hält eine offene Verbindung aufrecht, indem es die Antenne und die Verbindung zum Mobilfunknetz aufrechterhält. Dies führt zu einer verkürzten Batterielebensdauer, Hitze und in einigen Fällen zu zusätzlichen Gebühren für Daten.
Aber warum haben wir immer noch Probleme mit Mobilgeräten?
Betrachten wir, wie das Standard-Mobilgerät eine Verbindung zum Internet herstellt:
Eine einfache Erklärung, wie ein Mobilfunknetz funktioniert: Typischerweise haben mobile Geräte eine Antenne mit geringer Leistung, die Daten von einer Zelle empfangen kann. Sobald das Gerät Daten von einem eingehenden Anruf empfängt, fährt es auf diese Weise die Vollduplex-Antenne hoch, um den Anruf aufzubauen. Dieselbe Antenne wird verwendet, wenn Sie telefonieren oder auf das Internet zugreifen möchten (wenn kein WLAN verfügbar ist). Die Vollduplex-Antenne muss eine Verbindung zum Mobilfunknetz herstellen und eine Authentifizierung durchführen. Sobald die Verbindung hergestellt ist, findet eine gewisse Kommunikation zwischen Ihrem Gerät und der Zelle statt, um unsere Netzwerkanforderung auszuführen. Wir werden auf den internen Proxy des Mobilfunkanbieters umgeleitet, der Internetanfragen verarbeitet. Von da an ist das Verfahren bereits bekannt: Es fragt einen DNS, wo www.domainname.ext tatsächlich ist, erhält die URI zur Ressource und wird schließlich dorthin umgeleitet.
Wie Sie sich vorstellen können, verbraucht dieser Vorgang ziemlich viel Batterieleistung. Aus diesem Grund geben die Mobiltelefonanbieter eine Standby-Zeit von wenigen Tagen und eine Sprechzeit von nur wenigen Stunden an.
Ohne WiFi erfordern sowohl WebSockets als auch Abfragen, dass die Vollduplex-Antenne fast ständig funktioniert. Wir sind also mit einem erhöhten Datenverbrauch und einer erhöhten Leistungsaufnahme konfrontiert – und je nach Gerät auch mit Hitze.
Wenn die Dinge düster erscheinen, sieht es so aus, als müssten wir die Geschäftsanforderungen für unsere Anwendung überdenken. Vermissen wir etwas?
SSE
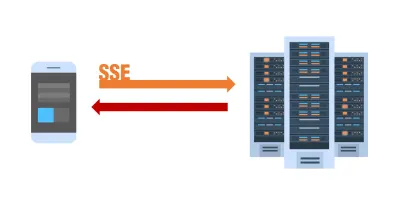
Über MDN:

„Die EventSource-Schnittstelle wird verwendet, um vom Server gesendete Ereignisse zu empfangen. Es stellt über HTTP eine Verbindung zu einem Server her und empfängt Ereignisse im Text-/Ereignisstromformat, ohne die Verbindung zu schließen.“
Der Hauptunterschied zum Polling besteht darin, dass wir nur eine Verbindung erhalten und einen Ereignisstrom darüber laufen lassen. Langes Polling erstellt für jeden Pull eine neue Verbindung – ergo die Header-Overheads und andere Probleme, mit denen wir dort konfrontiert waren.
Über html5doctor.com:
Vom Server gesendete Ereignisse sind Echtzeitereignisse, die vom Server gesendet und vom Browser empfangen werden. Sie ähneln WebSockets insofern, als sie in Echtzeit stattfinden, aber sie sind in hohem Maße eine Einweg-Kommunikationsmethode vom Server.
Es sieht irgendwie seltsam aus, aber nach einiger Überlegung – unser Hauptdatenfluss verläuft vom Server zum Client und in viel selteneren Fällen vom Client zum Server.
Es sieht so aus, als könnten wir dies für unseren Hauptgeschäftsfall der Bereitstellung von Daten verwenden. Wir können Kundenkäufe lösen, indem wir eine neue Anfrage senden, da das Protokoll unidirektional ist und der Client darüber keine Nachrichten an den Server senden kann. Dies wird schließlich die Zeitverzögerung der Vollduplex-Antenne haben, um auf mobilen Geräten hochzufahren. Wir können jedoch damit leben, dass es von Zeit zu Zeit passiert – diese Verzögerung wird schließlich in Millisekunden gemessen.
Einzigartige Funktionen
- Der Verbindungsstream kommt vom Server und ist schreibgeschützt.
- Sie verwenden reguläre HTTP-Anforderungen für die dauerhafte Verbindung, kein spezielles Protokoll. Multiplexing über HTTP/2 sofort einsatzbereit.
- Wenn die Verbindung unterbrochen wird, löst EventSource ein Fehlerereignis aus und versucht automatisch, die Verbindung wiederherzustellen. Der Server kann auch die Zeitüberschreitung steuern, bevor der Client versucht, erneut eine Verbindung herzustellen (wird später ausführlicher erklärt).
- Clients können eine eindeutige ID mit Nachrichten senden. Wenn ein Client nach einem Verbindungsabbruch versucht, sich wieder zu verbinden, sendet er die letzte bekannte ID. Dann kann der Server sehen, dass der Client
nNachrichten verpasst hat, und den Rückstand der verpassten Nachrichten bei der Wiederverbindung senden.
Beispiel-Client-Implementierung
Diese Ereignisse ähneln gewöhnlichen JavaScript-Ereignissen, die im Browser auftreten – wie Klickereignisse –, außer dass wir den Namen des Ereignisses und die damit verbundenen Daten steuern können.
Sehen wir uns die einfache Codevorschau für die Clientseite an:
// subscribe for messages var source = new EventSource('URL'); // handle messages source.onmessage = function(event) { // Do something with the data: event.data; };Was wir aus dem Beispiel sehen, ist, dass die Clientseite ziemlich einfach ist. Es verbindet sich mit unserer Quelle und wartet auf den Empfang von Nachrichten.
Um es Servern zu ermöglichen, Daten über HTTP oder dedizierte Server-Push-Protokolle an Webseiten zu senden, führt die Spezifikation die Schnittstelle „EventSource“ auf dem Client ein. Die Verwendung dieser API besteht aus der Erstellung eines „EventSource“-Objekts und der Registrierung eines Ereignis-Listeners.
Die Client-Implementierung für WebSockets sieht dieser sehr ähnlich. Die Komplexität bei Sockets liegt in der IT-Infrastruktur und der Serverimplementierung.
Ereignisquelle
Jedes EventSource Objekt hat die folgenden Mitglieder:
- URL: während der Erstellung festgelegt.
- Request: initial ist null.
- Reconnection time: Wert in ms (vom User-Agent definierter Wert).
- Letzte Ereignis-ID: anfänglich eine leere Zeichenkette.
- Bereitschaftszustand: Zustand der Verbindung.
- VERBINDEN (0)
- OFFEN (1)
- GESCHLOSSEN (2)
Abgesehen von der URL werden alle wie privat behandelt und sind von außen nicht zugänglich.
Eingebaute Ereignisse:
- Offen
- Nachricht
- Fehler
Umgang mit Verbindungsabbrüchen
Bei einem Verbindungsabbruch wird die Verbindung vom Browser automatisch neu aufgebaut. Der Server sendet möglicherweise eine Zeitüberschreitung, um die Verbindung erneut zu versuchen oder die Verbindung dauerhaft zu schließen. In einem solchen Fall wird der Browser entweder versuchen, die Verbindung nach dem Timeout wiederherzustellen, oder überhaupt nicht versuchen, wenn die Verbindung beendet wurde. Scheint ziemlich einfach zu sein – und ist es tatsächlich.
Beispielserverimplementierung
Nun, wenn der Client so einfach ist, ist die Serverimplementierung vielleicht komplex?
Nun, der Server-Handler für SSE könnte so aussehen:
function handler(response) { // setup headers for the response in order to get the persistent HTTP connection response.writeHead(200, { 'Content-Type': 'text/event-stream', 'Cache-Control': 'no-cache', 'Connection': 'keep-alive' }); // compose the message response.write('id: UniqueID\n'); response.write("data: " + data + '\n\n'); // whenever you send two new line characters the message is sent automatically }Wir definieren eine Funktion, die die Antwort verarbeiten wird:
- Kopfzeilen einrichten
- Nachricht erstellen
- Schicken
Beachten Sie, dass Sie keinen send() oder push() Methodenaufruf sehen. Denn der Standard definiert, dass die Nachricht gesendet wird, sobald sie zwei \n\n Zeichen wie im Beispiel erhält: response.write("data: " + data + '\n\n'); . Dadurch wird die Nachricht sofort an den Client weitergeleitet. Bitte beachten Sie, dass die data eine Escape-Zeichenfolge sein müssen und keine Zeilenumbruchzeichen am Ende haben.
Nachrichtenaufbau
Wie bereits erwähnt, kann die Nachricht einige Eigenschaften enthalten:
- ICH WÜRDE
Wenn der Feldwert nicht U+0000 NULL enthält, setzen Sie den letzten Ereignis-ID-Puffer auf den Feldwert. Andernfalls ignorieren Sie das Feld. - Daten
Hängen Sie den Feldwert an den Datenpuffer an, und fügen Sie dann ein einzelnes Zeichen U+000A LINE FEED (LF) an den Datenpuffer an. - Fall
Legen Sie den Ereignistyppuffer auf den Feldwert fest. Dies führt dazu, dassevent.typeIhren benutzerdefinierten Ereignisnamen erhält. - Wiederholen
Wenn der Feldwert nur aus ASCII-Ziffern besteht, interpretieren Sie den Feldwert als Ganzzahl auf der Basis zehn und legen Sie die Wiederverbindungszeit des Ereignisstroms auf diese Ganzzahl fest. Andernfalls ignorieren Sie das Feld.
Alles andere wird ignoriert. Wir können keine eigenen Felder einführen.
Beispiel mit hinzugefügtem event :
response.write('id: UniqueID\n'); response.write('event: add\n'); response.write('retry: 10000\n'); response.write("data: " + data + '\n\n'); Dann wird dies auf dem Client mit addEventListener als solches behandelt:
source.addEventListener("add", function(event) { // do stuff with data event.data; });Sie können mehrere Nachrichten, getrennt durch eine neue Zeile, senden, solange Sie unterschiedliche IDs angeben.
... id: 54 event: add data: "[{SOME JSON DATA}]" id: 55 event: remove data: JSON.stringify(some_data) id: 56 event: remove data: { data: "msg" : "JSON data"\n data: "field": "value"\n data: "field2": "value2"\n data: }\n\n ...Das vereinfacht enorm, was wir mit unseren Daten machen können.
Spezifische Serveranforderungen
Während unseres POC für das Back-End haben wir festgestellt, dass es einige Besonderheiten gibt, die angegangen werden müssen, um eine funktionierende Implementierung von SSE zu haben. Im besten Fall verwenden Sie einen auf Ereignisschleifen basierenden Server wie NodeJS, Kestrel oder Twisted. Die Idee ist, dass Sie mit der Thread-basierten Lösung einen Thread pro Verbindung haben → 1000 Verbindungen = 1000 Threads. Mit der Event-Loop-Lösung haben Sie einen Thread für 1000 Verbindungen.
- Sie können EventSource-Anfragen nur akzeptieren, wenn die HTTP-Anfrage besagt, dass sie den Event-Stream-MIME-Typ akzeptieren kann;
- Sie müssen eine Liste aller verbundenen Benutzer führen, um neue Ereignisse auszugeben;
- Sie sollten auf unterbrochene Verbindungen lauschen und diese aus der Liste der verbundenen Benutzer entfernen;
- Sie sollten optional einen Nachrichtenverlauf verwalten, damit Clients, die erneut eine Verbindung herstellen, verpasste Nachrichten nachholen können.
Es funktioniert wie erwartet und sieht zunächst wie Zauberei aus. Wir bekommen alles, was wir wollen, damit unsere Anwendung effizient funktioniert. Wie bei allen Dingen, die zu gut aussehen, um wahr zu sein, stehen wir manchmal vor einigen Problemen, die angegangen werden müssen. Sie sind jedoch nicht kompliziert zu implementieren oder zu umgehen:
Legacy-Proxy-Server sind dafür bekannt, in bestimmten Fällen HTTP-Verbindungen nach einem kurzen Timeout zu unterbrechen. Zum Schutz vor solchen Proxy-Servern können Autoren etwa alle 15 Sekunden eine Kommentarzeile einfügen (eine, die mit einem „:“-Zeichen beginnt).
Autoren, die Ereignisquellenverbindungen miteinander oder mit bestimmten zuvor bereitgestellten Dokumenten in Beziehung setzen möchten, stellen möglicherweise fest, dass es nicht funktioniert, sich auf IP-Adressen zu verlassen, da einzelne Clients mehrere IP-Adressen (aufgrund mehrerer Proxyserver) und einzelne IP-Adressen haben können mehrere Clients (aufgrund der gemeinsamen Nutzung eines Proxy-Servers). Es ist besser, eine eindeutige Kennung in das Dokument aufzunehmen, wenn es bereitgestellt wird, und diese Kennung dann als Teil der URL weiterzugeben, wenn die Verbindung hergestellt wird.
Die Autoren werden auch darauf hingewiesen, dass das HTTP-Chunking unerwartete negative Auswirkungen auf die Zuverlässigkeit dieses Protokolls haben kann, insbesondere wenn das Chunking von einer anderen Schicht durchgeführt wird, die sich der Timing-Anforderungen nicht bewusst ist. Wenn dies ein Problem darstellt, kann Chunking für die Bereitstellung von Ereignisströmen deaktiviert werden.
Clients, die die HTTP-Verbindungsbeschränkung pro Server unterstützen, können beim Öffnen mehrerer Seiten von einer Site Probleme bekommen, wenn jede Seite eine EventSource für dieselbe Domäne hat. Autoren können dies vermeiden, indem sie den relativ komplexen Mechanismus verwenden, eindeutige Domänennamen pro Verbindung zu verwenden, oder indem sie dem Benutzer erlauben, die EventSource-Funktionalität pro Seite zu aktivieren oder zu deaktivieren, oder indem sie ein einzelnes EventSource-Objekt mit einem gemeinsam genutzten Worker freigeben.
Browserunterstützung und Polyfills: Edge hinkt dieser Implementierung hinterher, aber ein Polyfill ist verfügbar, das Sie retten kann. Das wichtigste Argument für SSE betrifft jedoch mobile Geräte, bei denen IE/Edge keinen brauchbaren Marktanteil haben.
Einige der verfügbaren Polyfills:
- Jaffle
- amvtek
- remy
Verbindungsloser Push und andere Funktionen
Benutzeragenten, die in kontrollierten Umgebungen ausgeführt werden, z. B. Browser auf Mobiltelefonen, die an bestimmte Netzbetreiber gebunden sind, können die Verwaltung der Verbindung an einen Proxy im Netzwerk auslagern. In einer solchen Situation wird davon ausgegangen, dass der Benutzeragent zum Zwecke der Konformität sowohl die Handset-Software als auch den Netzwerk-Proxy umfasst.
Beispielsweise könnte ein Browser auf einem mobilen Gerät nach dem Herstellen einer Verbindung erkennen, dass es sich in einem unterstützenden Netzwerk befindet, und anfordern, dass ein Proxy-Server im Netzwerk die Verwaltung der Verbindung übernimmt. Der Zeitplan für eine solche Situation könnte wie folgt aussehen:
- Der Browser stellt eine Verbindung zu einem Remote-HTTP-Server her und fordert die vom Autor im EventSource-Konstruktor angegebene Ressource an.
- Der Server sendet gelegentlich Nachrichten.
- Zwischen zwei Meldungen erkennt der Browser, dass er außer der Netzwerkaktivität, die zum Erhalt der TCP-Verbindung erforderlich ist, im Leerlauf ist, und beschließt, in den Ruhemodus zu wechseln, um Strom zu sparen.
- Der Browser trennt die Verbindung zum Server.
- Der Browser kontaktiert einen Dienst im Netzwerk und fordert stattdessen den Dienst, einen „Push-Proxy“, auf, die Verbindung aufrechtzuerhalten.
- Der „Push-Proxy“-Dienst kontaktiert den entfernten HTTP-Server und fordert die vom Autor im EventSource-Konstruktor angegebene Ressource an (möglicherweise einschließlich eines
Last-Event-IDHTTP-Headers usw.). - Der Browser lässt zu, dass das mobile Gerät in den Ruhezustand wechselt.
- Der Server sendet eine weitere Nachricht.
- Der „Push-Proxy“-Dienst verwendet eine Technologie wie OMA-Push, um das Ereignis an das mobile Gerät zu übermitteln, das nur so weit aufwacht, dass es das Ereignis verarbeitet, und dann in den Ruhezustand zurückkehrt.
Dies kann die Gesamtdatennutzung reduzieren und kann daher zu erheblichen Energieeinsparungen führen.
Neben der Implementierung des bestehenden API- und Text-/Ereignisstrom-Drahtformats, wie es durch die Spezifikation definiert ist, und auf verteiltere Weise (wie oben beschrieben), können Formate des Ereignisrahmens, die durch andere anwendbare Spezifikationen definiert sind, unterstützt werden.
Zusammenfassung
Nach langen und erschöpfenden POCs, einschließlich Server- und Client-Implementierungen, sieht es so aus, als wäre SSE die Antwort auf unsere Probleme mit der Datenbereitstellung. Es gibt auch einige Fallstricke, die sich jedoch als trivial zu beheben erwiesen.
So sieht unser Produktionsaufbau am Ende aus:
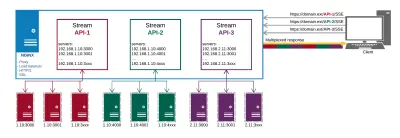
Von NGINX bekommen wir folgendes:
- Proxy zu API-Endpunkten an verschiedenen Orten;
- HTTP/2 und all seine Vorteile wie Multiplexing für die Verbindungen;
- Lastverteilung;
- SSL.
Auf diese Weise verwalten wir unsere Datenlieferung und Zertifikate an einem Ort, anstatt dies auf jedem Endpunkt separat zu tun.
Die wichtigsten Vorteile, die wir aus diesem Ansatz ziehen, sind:
- Dateneffizient;
- Einfachere Implementierung;
- Es wird automatisch über HTTP/2 gemultiplext;
- Begrenzt die Anzahl der Verbindungen für Daten auf dem Client auf eine;
- Stellt einen Mechanismus bereit, um den Akku zu schonen, indem die Verbindung zu einem Proxy ausgelagert wird.
SSE ist nicht nur eine praktikable Alternative zu den anderen Methoden zur Bereitstellung schneller Updates; Es sieht so aus, als ob es in einer eigenen Liga spielt, wenn es um Optimierungen für mobile Geräte geht. Es gibt keinen Mehraufwand bei der Implementierung im Vergleich zu den Alternativen. In Bezug auf die serverseitige Implementierung unterscheidet es sich nicht wesentlich von der Abfrage. Auf dem Client ist es viel einfacher als das Polling, da es ein anfängliches Abonnement und die Zuweisung von Event-Handlern erfordert – ähnlich wie bei der Verwaltung von WebSockets.
Sehen Sie sich die Code-Demo an, wenn Sie eine einfache Client-Server-Implementierung erhalten möchten.
Ressourcen
- „Bekannte Probleme und Best Practices für die Verwendung von Long Polling und Streaming in bidirektionalem HTTP“, IETF (PDF)
- W3C-Empfehlung, W3C
- „Wird WebSocket HTTP/2 überleben?“, Allan Denis, InfoQ
- „Stream-Updates mit vom Server gesendeten Ereignissen“, Eric Bidelman, HTML5 Rocks
- „Daten-Push-Apps mit HTML5 SSE“, Darren Cook, O'Reilly Media