
Wie wir die Leistung von SmashingMag verbessert haben
Veröffentlicht: 2022-03-10Dieser Artikel wird freundlicherweise von unseren lieben Freunden bei Media Temple unterstützt, die ein vollständiges Spektrum an Webhosting-Lösungen für Designer, Entwickler und Ihre Kunden anbieten. Danke, liebe Freunde!

Jede Web-Performance-Geschichte ist ähnlich, nicht wahr? Es beginnt immer mit der lang ersehnten Website-Überholung. Ein Tag, an dem ein vollständig ausgefeiltes und sorgfältig optimiertes Projekt gestartet wird, das in Lighthouse und WebPageTest einen hohen Rang einnimmt und die Leistungswerte übertrifft. Es liegt eine Feier und ein vollmundiges Erfolgserlebnis in der Luft – was sich wunderbar in Retweets und Kommentaren, Newslettern und Slack-Threads widerspiegelt.
Doch mit der Zeit lässt die Aufregung langsam nach und dringende Anpassungen, dringend benötigte Funktionen und neue Geschäftsanforderungen schleichen sich ein. Und plötzlich, bevor Sie es wissen, wird die Codebasis ein wenig übergewichtig und fragmentiert , Drittanbieter Skripte müssen nur ein wenig früher geladen werden, und glänzende neue dynamische Inhalte finden ihren Weg in das DOM durch die Hintertüren von Skripten von Drittanbietern und ihren ungebetenen Gästen.
Wir waren auch beim Smashing dabei. Nicht viele wissen es, aber wir sind ein sehr kleines Team von etwa 12 Personen, von denen viele Teilzeit arbeiten und die meisten an einem bestimmten Tag viele verschiedene Aufgaben tragen. Obwohl Leistung seit fast einem Jahrzehnt unser Ziel ist, hatten wir nie wirklich ein engagiertes Leistungsteam.
Nach dem letzten Redesign Ende 2017 war es Ilya Pukhalski auf der JavaScript-Seite der Dinge (Teilzeit), Michael Riethmueller auf der CSS-Seite der Dinge (ein paar Stunden pro Woche) und mit freundlichen Grüßen, die Gedankenspiele mit kritischem CSS spielten und versuchen, ein paar zu viele Dinge zu jonglieren.
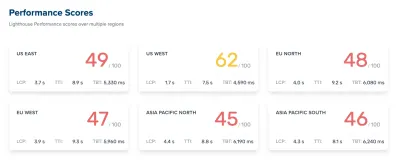
Zufällig verloren wir in der Hektik des Alltags den Überblick über die Leistung. Wir entwarfen und bauten Dinge, richteten neue Produkte ein, überarbeiteten die Komponenten und veröffentlichten Artikel. Ende 2020 gerieten die Dinge also etwas außer Kontrolle, und gelblich-rote Lighthouse-Ergebnisse tauchten langsam auf der ganzen Linie auf. Das mussten wir beheben.
Das ist, wo wir waren
Einige von Ihnen wissen vielleicht, dass wir auf JAMStack laufen, mit allen Artikeln und Seiten, die als Markdown-Dateien gespeichert sind, Sass-Dateien in CSS kompiliert, JavaScript in Chunks mit Webpack aufgeteilt und Hugo statische Seiten erstellt, die wir dann direkt von einem Edge-CDN aus bedienen. 2017 haben wir die gesamte Website mit Preact erstellt, sind dann aber 2019 zu React gewechselt – und verwenden es zusammen mit einigen APIs für Suche, Kommentare, Authentifizierung und Checkout.
Die gesamte Website wurde mit Blick auf die progressive Verbesserung erstellt, was bedeutet, dass Sie, lieber Leser, jeden Smashing-Artikel vollständig lesen können, ohne die Anwendung überhaupt starten zu müssen. Es ist auch nicht sehr überraschend – am Ende ändert sich ein veröffentlichter Artikel im Laufe der Jahre nicht viel, während dynamische Teile wie Mitgliedschaftsauthentifizierung und Checkout die Ausführung der Anwendung erfordern.
Der gesamte Build zum Bereitstellen von rund 2500 Artikeln dauert derzeit etwa 6 Minuten . Der Build-Prozess selbst ist im Laufe der Zeit ebenfalls zu einer ziemlichen Bestie geworden, mit kritischen CSS-Injektionen, Code-Splitting von Webpack, dynamischen Einfügungen von Werbung und Feature-Panels, RSS- (Neu-) Generierung und eventuellen A/B-Tests am Rande.
Anfang 2020 haben wir mit dem großen Refactoring der CSS-Layout-Komponenten begonnen. Wir haben nie CSS-in-JS oder Styled-Components verwendet, sondern stattdessen ein gutes altes komponentenbasiertes System von Sass-Modulen, die in CSS kompiliert wurden. Bereits 2017 wurde das gesamte Layout mit Flexbox erstellt und Mitte 2019 mit CSS Grid und CSS Custom Properties neu erstellt. Einige Seiten mussten jedoch aufgrund neuer Werbespots und neuer Produktpanels speziell behandelt werden. Während also das Layout funktionierte, funktionierte es nicht sehr gut, und es war ziemlich schwierig, es zu warten.
Außerdem musste die Kopfzeile mit der Hauptnavigation geändert werden, um mehr Elemente aufzunehmen, die wir dynamisch anzeigen wollten. Außerdem wollten wir einige häufig verwendete Komponenten, die auf der gesamten Website verwendet werden, umgestalten, und das dort verwendete CSS musste ebenfalls überarbeitet werden – die Newsletter-Box war der bemerkenswerteste Übeltäter. Wir begannen damit, einige Komponenten mit Utility-First-CSS umzugestalten, aber wir kamen nie zu dem Punkt, dass es konsistent auf der gesamten Website verwendet wurde.
Das größere Problem war das große JavaScript-Bundle , das – nicht sehr überraschend – den Haupt-Thread für Hunderte von Millisekunden blockierte. Ein großes JavaScript-Paket mag in einem Magazin, das nur Artikel veröffentlicht, fehl am Platz erscheinen, aber tatsächlich findet hinter den Kulissen eine Menge Skripting statt.
Wir haben verschiedene Zustände von Komponenten für authentifizierte und nicht authentifizierte Kunden. Sobald Sie sich angemeldet haben, möchten wir alle Produkte zum Endpreis anzeigen, und wenn Sie ein Buch in den Warenkorb legen, möchten wir, dass der Warenkorb mit einem Klick auf eine Schaltfläche zugänglich ist – egal auf welcher Seite Sie sich befinden. Werbung muss schnell eintreffen, ohne störende Layoutverschiebungen zu verursachen, und das Gleiche gilt für die nativen Produktpanels, die unsere Produkte hervorheben. Plus ein Servicemitarbeiter, der alle statischen Assets zwischenspeichert und für wiederholte Aufrufe bereitstellt, zusammen mit zwischengespeicherten Versionen von Artikeln, die ein Leser bereits besucht hat.
All dieses Skripting musste also irgendwann passieren, und es belastete die Leseerfahrung, obwohl das Skript ziemlich spät eintraf. Ehrlich gesagt haben wir akribisch an der Website und neuen Komponenten gearbeitet, ohne die Leistung genau im Auge zu behalten (und wir hatten für 2020 noch ein paar andere Dinge zu beachten). Die Wende kam unerwartet. Harry Roberts führte seine (ausgezeichnete) Web Performance Masterclass als Online-Workshop mit uns durch, und während des gesamten Workshops verwendete er Smashing als Beispiel, indem er Probleme hervorhob, die wir hatten, und Lösungen für diese Probleme neben nützlichen Tools und Richtlinien vorschlug.
Während des gesamten Workshops habe ich mir fleißig Notizen gemacht und die Codebasis noch einmal durchgesehen. Zum Zeitpunkt des Workshops lagen unsere Lighthouse-Scores bei 60–68 auf der Startseite und bei etwa 40–60 auf Artikelseiten – und offensichtlich noch schlechter auf Mobilgeräten. Nach dem Workshop ging es an die Arbeit.
Identifizieren der Engpässe
Wir neigen oft dazu, uns auf bestimmte Punktzahlen zu verlassen, um zu verstehen, wie gut wir abschneiden, aber zu oft liefern einzelne Punktzahlen kein vollständiges Bild. Wie David East in seinem Artikel eloquent feststellte, ist die Web-Performance kein einzelner Wert; es ist eine Verteilung. Auch wenn ein Web-Erlebnis stark und durch und durch eine optimierte Rundum-Performance ist, kann es nicht nur schnell sein. Es mag für einige Besucher schnell sein, aber letztendlich wird es für einige andere auch langsamer (oder langsamer) sein.
Die Gründe dafür sind zahlreich, aber der wichtigste ist ein großer Unterschied in den Netzwerkbedingungen und der Gerätehardware auf der ganzen Welt. Meistens können wir diese Dinge nicht wirklich beeinflussen, also müssen wir sicherstellen, dass unsere Erfahrung sie stattdessen berücksichtigt.
Im Wesentlichen besteht unsere Aufgabe dann darin, den Anteil an bissigen Erfahrungen zu erhöhen und den Anteil an trägen Erfahrungen zu verringern. Aber dafür müssen wir uns ein genaues Bild davon machen, was die Verteilung tatsächlich ist. Jetzt liefern Analysetools und Leistungsüberwachungstools diese Daten bei Bedarf, aber wir haben uns speziell CrUX, Chrome User Experience Report, angesehen. CrUX generiert einen Überblick über die Leistungsverteilung im Laufe der Zeit, wobei der Datenverkehr von Chrome-Benutzern erfasst wird. Viele dieser Daten beziehen sich auf Core Web Vitals, die Google bereits im Jahr 2020 angekündigt hat und die auch zu Lighthouse beitragen und dort angezeigt werden.
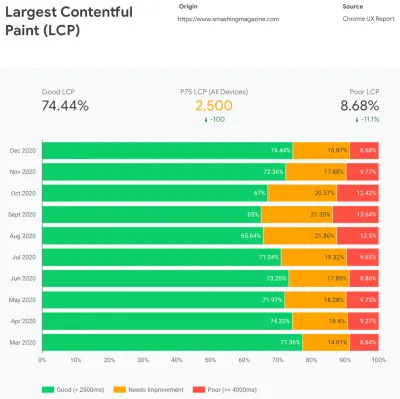
Uns ist aufgefallen, dass unsere Performance das ganze Jahr über dramatisch zurückgegangen ist, mit besonderen Rückgängen im August und September. Sobald wir diese Diagramme sahen, konnten wir auf einige der PRs zurückblicken, die wir damals live gepusht haben, um zu untersuchen, was tatsächlich passiert ist.
Es hat nicht lange gedauert, bis wir herausgefunden haben, dass wir genau zu diesen Zeiten eine neue Navigationsleiste live gestartet haben. Diese Navigationsleiste – die auf allen Seiten verwendet wird – stützte sich auf JavaScript, um Navigationselemente in einem Menü beim Antippen oder Klicken anzuzeigen, aber das JavaScript-Bit davon war tatsächlich im app.js- Bundle gebündelt. Um Time To Interactive zu verbessern, haben wir uns entschieden, das Navigationsskript aus dem Paket zu extrahieren und es inline bereitzustellen.
Etwa zur gleichen Zeit wechselten wir von einer (veralteten) manuell erstellten kritischen CSS -Datei zu einem automatisierten System, das kritisches CSS für jede Vorlage – Homepage, Artikel, Produktseite, Veranstaltung, Jobbörse usw. – und währenddessen Inline-kritisches CSS generierte die Bauzeit. Wir haben jedoch nicht wirklich bemerkt, wie viel schwerer das automatisch generierte kritische CSS war. Wir mussten es genauer untersuchen.
Und ungefähr zur gleichen Zeit passten wir das Laden von Webfonts an und versuchten, Webfonts mit Ressourcenhinweisen wie Preload aggressiver zu pushen. Dies scheint jedoch unsere Leistungsbemühungen zu beeinträchtigen, da Webfonts das Rendern des Inhalts verzögerten und neben der vollständigen CSS-Datei überpriorisiert wurden.
Nun, einer der häufigsten Gründe für die Regression sind die hohen Kosten von JavaScript, also haben wir uns auch Webpack Bundle Analyzer und Simon Hearnes Request Map angesehen, um ein visuelles Bild unserer JavaScript-Abhängigkeiten zu bekommen. Am Anfang sah es ganz gesund aus.
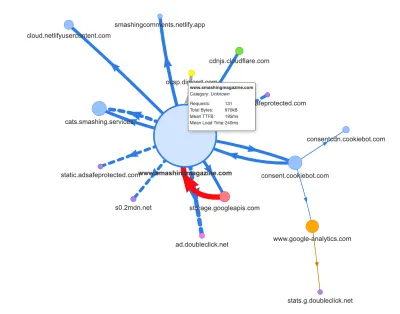
Es gingen einige Anfragen an das CDN, einen Cookie-Zustimmungsdienst Cookiebot, Google Analytics und unsere internen Dienste für die Bereitstellung von Produktpanels und benutzerdefinierter Werbung. Es schien nicht viele Engpässe zu geben – bis wir etwas genauer hinsahen.
Bei der Leistungsarbeit ist es üblich, die Leistung einiger kritischer Seiten zu betrachten – höchstwahrscheinlich die Startseite und höchstwahrscheinlich einige Artikel-/Produktseiten. Obwohl es nur eine Homepage gibt, kann es viele verschiedene Produktseiten geben, also müssen wir diejenigen auswählen, die für unser Publikum repräsentativ sind.
Da wir auf SmashingMag einige Artikel mit viel Code und Design veröffentlichen, haben wir im Laufe der Jahre buchstäblich Tausende von Artikeln angesammelt, die schwere GIFs, Codeschnipsel mit Syntaxhervorhebung, CodePen-Einbettungen, Video/Audio enthielten Einbettungen und verschachtelte Threads mit endlosen Kommentaren.
Zusammengenommen verursachten viele von ihnen zusammen mit übermäßiger Haupt-Thread-Arbeit eine Explosion der DOM-Größe – was die Erfahrung auf Tausenden von Seiten verlangsamte. Ganz zu schweigen davon, dass bei vorhandener Werbung einige DOM-Elemente spät in den Lebenszyklus der Seite eingefügt wurden, was eine Kaskade von Neuberechnungen und Neuzeichnungen des Stils verursachte – ebenfalls teure Aufgaben, die lange Aufgaben nach sich ziehen können.
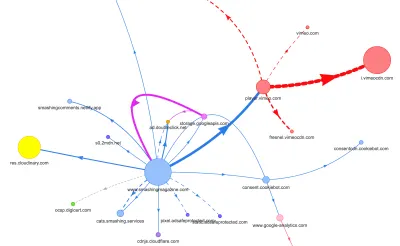
All dies wurde in der Karte, die wir für eine ziemlich schlanke Artikelseite im obigen Diagramm erstellt haben, nicht angezeigt. Also haben wir die schwersten Seiten ausgewählt, die wir hatten – die allmächtige Homepage, die längste, die mit vielen Videoeinbettungen und die mit vielen CodePen-Einbettungen – und beschlossen, sie so weit wie möglich zu optimieren. Denn wenn sie schnell sind, dann sollten auch Seiten mit einer einzelnen CodePen-Einbettung schneller sein.
Mit diesen Seiten im Hinterkopf sah die Karte etwas anders aus. Beachten Sie die riesige dicke Linie, die zum Vimeo-Player und zum Vimeo-CDN übergeht, mit 78 Anfragen, die von einem Smashing-Artikel stammen.
Um die Auswirkungen auf den Hauptthread zu untersuchen, haben wir einen tiefen Einblick in das Leistungspanel in DevTools genommen. Genauer gesagt haben wir nach Aufgaben gesucht, die länger als 50 ms dauern (hervorgehoben durch ein rotes Rechteck in der rechten oberen Ecke) und Aufgaben, die Neuberechnungsstile enthalten (lila Balken). Ersteres würde auf eine teure JavaScript-Ausführung hindeuten, während letzteres Stilungültigkeiten aufdecken würde, die durch dynamisches Einfügen von Inhalten in das DOM und suboptimales CSS verursacht werden. Dies gab uns einige umsetzbare Hinweise, wo wir anfangen sollten. Zum Beispiel stellten wir schnell fest, dass das Laden unserer Webfonts erhebliche Repaint-Kosten verursachte, während JavaScript-Chunks immer noch schwer genug waren, um den Hauptthread zu blockieren.
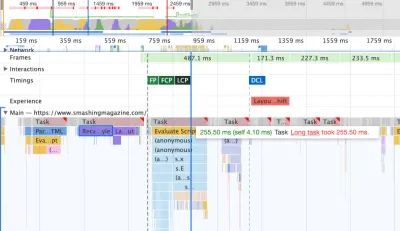
Als Grundlage haben wir uns die Core Web Vitals sehr genau angesehen und versucht sicherzustellen, dass wir bei allen gut abschneiden. Wir haben uns entschieden, uns speziell auf langsame mobile Geräte zu konzentrieren – mit langsamem 3G, 400 ms RTT und 400 kbps Übertragungsgeschwindigkeit, nur um auf der pessimistischen Seite der Dinge zu bleiben. Es ist daher nicht verwunderlich, dass Lighthouse auch mit unserer Website nicht sehr zufrieden war, da es für die schwersten Artikel durchgehend rote Punktzahlen lieferte und sich unermüdlich über unbenutztes JavaScript, CSS, Offscreen-Bilder und deren Größe beschwerte.
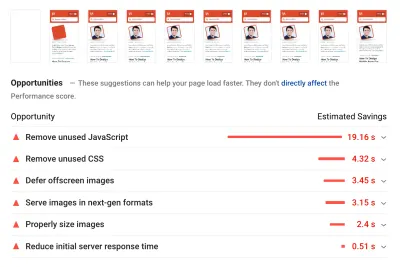
Sobald wir einige Daten vor uns hatten, konnten wir uns auf die Optimierung der drei schwersten Artikelseiten konzentrieren, mit einem Fokus auf kritisches (und nicht kritisches) CSS, JavaScript-Bundle, lange Aufgaben, Laden von Webfonts, Layoutverschiebungen und Drittanbieter -bettet. Später würden wir auch die Codebasis überarbeiten, um Legacy-Code zu entfernen und neue moderne Browserfunktionen zu verwenden. Es schien eine Menge Arbeit vor uns zu liegen, und tatsächlich waren wir für die kommenden Monate ziemlich beschäftigt.
Verbessern der Reihenfolge der Assets im <head>
Ironischerweise war das Allererste, was wir untersucht haben, nicht einmal eng mit all den Aufgaben verbunden, die wir oben identifiziert haben. Im Performance-Workshop verbrachte Harry viel Zeit damit, die Reihenfolge der Assets im <head> jeder Seite zu erklären, und wies darauf hin, dass die schnelle Bereitstellung kritischer Inhalte bedeutet, sehr strategisch und aufmerksam bei der Reihenfolge der Assets im Quellcode vorzugehen .
Jetzt sollte es keine große Offenbarung sein, dass kritisches CSS für die Webleistung von Vorteil ist. Es war jedoch etwas überraschend, wie groß der Unterschied in der Reihenfolge aller anderen Assets – Ressourcenhinweise, Vorladen von Webfonts, synchrone und asynchrone Skripte, vollständiges CSS und Metadaten – ist.
Wir haben den gesamten <head> auf den Kopf gestellt und wichtiges CSS vor allen asynchronen Skripten und allen vorab geladenen Assets wie Schriftarten, Bildern usw. platziert Dateityp, sodass kritische Bilder, Syntaxhervorhebungen und Videoeinbettungen frühzeitig nur für eine bestimmte Art von Artikeln und Seiten angefordert werden.
Im Allgemeinen haben wir die Reihenfolge im <head> sorgfältig orchestriert, die Anzahl der vorab geladenen Assets reduziert, die um Bandbreite konkurrierten, und uns darauf konzentriert, kritisches CSS richtig zu machen. Wenn Sie tiefer in einige der kritischen Überlegungen zur <head> -Reihenfolge eintauchen möchten, hebt Harry sie im Artikel über CSS und Netzwerkleistung hervor. Allein diese Änderung brachte uns rund 3–4 Lighthouse-Score-Punkte auf ganzer Linie ein.
Wechsel von automatisiertem Critical CSS zurück zu manuellem Critical CSS
Das Verschieben der <head> -Tags war jedoch ein einfacher Teil der Geschichte. Schwieriger war die Generierung und Verwaltung kritischer CSS-Dateien. Im Jahr 2017 haben wir kritische CSS für jede Vorlage manuell erstellt, indem wir alle Stile gesammelt haben, die erforderlich sind, um die ersten 1000 Pixel in der Höhe über alle Bildschirmbreiten zu rendern. Dies war natürlich eine umständliche und wenig inspirierende Aufgabe, ganz zu schweigen von den Wartungsproblemen für die Zähmung einer ganzen Familie kritischer CSS-Dateien und einer vollständigen CSS-Datei.
Also haben wir nach Möglichkeiten gesucht, diesen Prozess als Teil der Build-Routine zu automatisieren . Es gab nicht wirklich einen Mangel an verfügbaren Tools, also haben wir ein paar getestet und beschlossen, ein paar Tests durchzuführen. Wir haben es geschafft, sie ziemlich schnell einzurichten und in Betrieb zu nehmen. Die Ausgabe schien für einen automatisierten Prozess gut genug zu sein, also haben wir sie nach einigen Konfigurationsänderungen angeschlossen und in die Produktion überführt. Das geschah etwa im Juli und August letzten Jahres, was gut in der Spitze und dem Leistungsabfall in den CrUX-Daten oben dargestellt wird. Wir gingen mit der Konfiguration hin und her und hatten oft Probleme mit einfachen Dingen wie dem Hinzufügen bestimmter Stile oder dem Entfernen anderer. ZB Cookie-Einwilligungsaufforderungsstile, die nicht wirklich auf einer Seite enthalten sind, es sei denn, das Cookie-Skript wurde initialisiert.
Im Oktober haben wir einige größere Layout-Änderungen an der Website vorgenommen, und als wir uns das kritische CSS ansahen, sind wir wieder auf genau die gleichen Probleme gestoßen – das generierte Ergebnis war ziemlich ausführlich und nicht ganz das, was wir wollten . Als Experiment haben wir Ende Oktober alle unsere Kräfte gebündelt, um unseren kritischen CSS-Ansatz zu überdenken und zu untersuchen, wie viel kleiner ein handgefertigtes kritisches CSS wäre. Wir holten tief Luft und verbrachten Tage mit dem Code-Coverage-Tool auf Schlüsselseiten. Wir haben CSS-Regeln manuell gruppiert und Duplikate und Legacy-Code an beiden Stellen entfernt – dem kritischen CSS und dem Haupt-CSS. Es war in der Tat eine dringend benötigte Bereinigung, da viele Stile, die in den Jahren 2017–2018 geschrieben wurden, im Laufe der Jahre veraltet sind.
Als Ergebnis haben wir drei handgefertigte kritische CSS-Dateien und drei weitere Dateien, die derzeit in Arbeit sind:
- kritische-homepage-manual.css (8,2 KB, Brotlified)
- kritische-artikel-manual.css (8 KB, Brotlified)
- kritische-artikel-manual.css (6 KB, Brotlified)
- kritische-bücher-manual.css ( noch zu erledigende Arbeit )
- critical-events-manual.css ( noch zu erledigende Arbeit )
- kritische-job-board-manual.css ( noch zu erledigende Arbeit )
Die Dateien sind in den Kopf jedes Templates eingebettet und im Moment werden sie in dem monolithischen CSS-Bundle dupliziert, das alles enthält, was jemals auf der Website verwendet (oder nicht mehr wirklich verwendet) wurde. Im Moment versuchen wir, das vollständige CSS-Bundle in einige wenige CSS-Pakete zu zerlegen, damit ein Leser des Magazins keine Stile von der Jobbörse oder den Buchseiten herunterladen würde, aber dann, wenn er diese Seiten erreicht, schnell gerendert würde mit kritischem CSS und holen Sie sich den Rest des CSS für diese Seite asynchron – nur auf dieser Seite.
Zugegeben, handgefertigte kritische CSS-Dateien waren nicht viel kleiner: Wir haben die Größe kritischer CSS-Dateien um etwa 14 % reduziert . Sie enthielten jedoch alles, was wir brauchten, in der richtigen Reihenfolge von oben nach unten, ohne Duplikate und überschreibende Stile. Dies schien ein Schritt in die richtige Richtung zu sein und gab uns einen Lighthouse-Boost von weiteren 3–4 Punkten. Wir machten Fortschritte.
Ändern des Ladens von Webfonts
Mit font-display an unseren Fingerspitzen scheint das Laden von Schriften in der Vergangenheit ein Problem zu sein. Leider ist es in unserem Fall nicht ganz richtig. Sie, liebe Leser, scheinen eine Reihe von Artikeln im Smashing Magazine zu besuchen. Sie kehren auch häufig auf die Website zurück, um einen weiteren Artikel zu lesen – vielleicht ein paar Stunden oder Tage später oder vielleicht eine Woche später. Eines der Probleme, das wir mit der auf der gesamten Website verwendeten font-display hatten, war, dass wir bei Lesern, die häufig zwischen Artikeln wechselten, viele Blitze zwischen der Fallback-Schriftart und der Webschriftart bemerkten (was normalerweise nicht passieren sollte, wie es bei Schriftarten der Fall wäre richtig zwischengespeichert).
Das fühlte sich nicht wie eine anständige Benutzererfahrung an, also haben wir nach Optionen gesucht. Bei Smashing verwenden wir zwei Hauptschriftarten – Mija für Überschriften und Elena für Text. Mija ist in zwei Strichstärken (Regular und Bold) erhältlich, während Elena in drei Strichstärken (Regular, Italic, Bold) erhältlich ist. Wir haben Elenas Bold Italic vor Jahren während der Neugestaltung fallen gelassen, nur weil wir es nur auf wenigen Seiten verwendet haben. Wir unterteilen die anderen Schriftarten, indem wir nicht verwendete Zeichen und Unicode-Bereiche entfernen.
Unsere Artikel sind meistens in Text gesetzt, daher haben wir festgestellt, dass die größte inhaltsreiche Farbe auf der Website die meiste Zeit entweder der erste Textabsatz in einem Artikel oder das Foto des Autors ist. Das bedeutet, dass wir besonders darauf achten müssen, dass der erste Absatz schnell in einer Fallback-Schriftart erscheint, während wir mit minimalen Umbrüchen elegant zur Webschriftart wechseln.
Schauen Sie sich das anfängliche Ladeerlebnis der Startseite (dreimal verlangsamt) genau an:
Bei der Suche nach einer Lösung hatten wir vier Hauptziele:
- Rendern Sie den Text beim allerersten Besuch sofort mit einer Fallback-Schriftart;
- Passen Sie Schriftartmetriken von Fallback-Schriftarten und Webschriftarten an, um Layoutverschiebungen zu minimieren;
- Alle Webfonts asynchron laden und auf einmal anwenden (max. 1 Reflow);
- Rendern Sie bei späteren Besuchen den gesamten Text direkt in Webfonts (ohne Blinken oder Reflows).
Anfangs haben wir tatsächlich versucht, font-display: swap on font-face zu verwenden. Dies schien die einfachste Option zu sein, aber wie oben erwähnt, werden einige Leser eine Reihe von Seiten besuchen, so dass wir am Ende viel Flackern mit den sechs Schriftarten hatten, die wir auf der gesamten Website gerendert haben. Außerdem konnten wir mit der Schriftanzeige allein keine Anfragen gruppieren oder neu zeichnen.
Eine andere Idee war, beim ersten Besuch alles in Fallback-Schriftart zu rendern, dann alle Schriftarten asynchron anzufordern und zwischenzuspeichern und erst bei nachfolgenden Besuchen Webschriftarten direkt aus dem Cache zu liefern. Das Problem bei diesem Ansatz war, dass eine Reihe von Lesern von Suchmaschinen kommen und zumindest einige von ihnen nur diese eine Seite sehen werden – und wir wollten einen Artikel nicht nur in einer Systemschrift darstellen.
Also was ist dann?
Seit 2017 verwenden wir den Two-Stage-Render-Ansatz für das Laden von Webfonts, der im Wesentlichen zwei Stufen des Renderings beschreibt: eine mit einer minimalen Teilmenge von Webfonts und die andere mit einer vollständigen Familie von Schriftstärken. Früher haben wir minimale Untergruppen von Mija Bold und Elena Regular erstellt, die die am häufigsten verwendeten Gewichte auf der Website waren. Beide Teilmengen enthalten nur lateinische Zeichen, Satzzeichen, Zahlen und einige Sonderzeichen. Diese Schriftarten ( ElenaInitial.woff2 und MijaInitial.woff2 ) waren sehr klein – oft nur etwa 10–15 KB groß. Wir stellen sie in der ersten Stufe des Font-Renderings bereit und zeigen die gesamte Seite in diesen beiden Schriftarten an.

Wir tun dies mit einer API zum Laden von Schriftarten, die uns Informationen darüber gibt, welche Schriftarten erfolgreich geladen wurden und welche noch nicht. Hinter den Kulissen geschieht dies durch Hinzufügen einer Klasse .wf-loaded-stage1 zum body , wobei Stile den Inhalt in diesen Schriftarten wiedergeben:
.wf-loaded-stage1 article, .wf-loaded-stage1 promo-box, .wf-loaded-stage1 comments { font-family: ElenaInitial,sans-serif; } .wf-loaded-stage1 h1, .wf-loaded-stage1 h2, .wf-loaded-stage1 .btn { font-family: MijaInitial,sans-serif; }Da Schriftdateien recht klein sind, kommen sie hoffentlich recht schnell durch das Netzwerk. Da der Leser dann tatsächlich mit dem Lesen eines Artikels beginnen kann, laden wir die vollen Gewichte der Schriftarten asynchron und fügen .wf-loaded-stage2 zum Hauptteil hinzu:
.wf-loaded-stage2 article, .wf-loaded-stage2 promo-box, .wf-loaded-stage2 comments { font-family: Elena,sans-serif; } .wf-loaded-stage2 h1, .wf-loaded-stage2 h2, .wf-loaded-stage2 .btn { font-family: Mija,sans-serif; }Beim Laden einer Seite erhalten die Leser also schnell zuerst eine kleine Teilmenge von Webfonts, und dann wechseln wir zur vollständigen Fontfamilie. Diese Wechsel zwischen Fallback-Fonts und Web-Fonts erfolgen jetzt standardmäßig nach dem Zufallsprinzip, basierend darauf, was zuerst durch das Netzwerk kommt. Das kann sich ziemlich störend anfühlen, wenn Sie mit dem Lesen eines Artikels begonnen haben. Anstatt es also dem Browser zu überlassen, wann er die Schriftart wechselt, gruppieren wir Repaints und reduzieren so die Auswirkungen des Reflows auf ein Minimum.
/* Loading web fonts with Font Loading API to avoid multiple repaints. With help by Irina Lipovaya. */ /* Credit to initial work by Zach Leatherman: https://noti.st/zachleat/KNaZEg/the-five-whys-of-web-font-loading-performance#sWkN4u4 */ // If the Font Loading API is supported... // (If not, we stick to fallback fonts) if ("fonts" in document) { // Create new FontFace objects, one for each font let ElenaRegular = new FontFace( "Elena", "url(/fonts/ElenaWebRegular/ElenaWebRegular.woff2) format('woff2')" ); let ElenaBold = new FontFace( "Elena", "url(/fonts/ElenaWebBold/ElenaWebBold.woff2) format('woff2')", { weight: "700" } ); let ElenaItalic = new FontFace( "Elena", "url(/fonts/ElenaWebRegularItalic/ElenaWebRegularItalic.woff2) format('woff2')", { style: "italic" } ); let MijaBold = new FontFace( "Mija", "url(/fonts/MijaBold/Mija_Bold-webfont.woff2) format('woff2')", { weight: "700" } ); // Load all the fonts but render them at once // if they have successfully loaded let loadedFonts = Promise.all([ ElenaRegular.load(), ElenaBold.load(), ElenaItalic.load(), MijaBold.load() ]).then(result => { result.forEach(font => document.fonts.add(font)); document.documentElement.classList.add('wf-loaded-stage2'); // Used for repeat views sessionStorage.foutFontsStage2Loaded = true; }).catch(error => { throw new Error(`Error caught: ${error}`); }); }Was aber, wenn die erste kleine Teilmenge von Schriftarten nicht schnell durch das Netzwerk kommt? Wir haben festgestellt, dass dies öfter vorkommt, als uns lieb ist. In diesem Fall greifen moderne Browser nach Ablauf eines Timeouts von 3s auf einen Systemfont zurück (in unserem Font-Stack wäre es Arial), wechseln dann zu ElenaInitial oder MijaInitial , nur um später auf die vollständige Elena bzw. Mija umzuschalten . Das hat bei unserer Verkostung nur ein bisschen zu viel Blitzen erzeugt. Wir haben darüber nachgedacht, das Rendern der ersten Stufe zunächst nur für langsame Netzwerke zu entfernen (über die Netzwerkinformations-API), aber dann haben wir uns entschieden, es vollständig zu entfernen.
Also haben wir im Oktober die Teilmengen zusammen mit der Zwischenstufe vollständig entfernt. Immer wenn alle Gewichte sowohl der Elena- als auch der Mija-Schriftarten erfolgreich vom Kunden heruntergeladen wurden und bereit sind, angewendet zu werden, leiten wir Phase 2 ein und zeichnen alles auf einmal neu. Und um Reflows noch unauffälliger zu machen, haben wir ein wenig Zeit damit verbracht , Fallback-Schriftarten und Web-Schriftarten aufeinander abzustimmen . Das bedeutete meistens, leicht unterschiedliche Schriftgrößen und Zeilenhöhen für Elemente anzuwenden, die im ersten sichtbaren Teil der Seite gemalt wurden.
Dafür haben wir den font-style-matcher und (ähm, ähm) ein paar magische Zahlen verwendet. Das ist auch der Grund, warum wir uns zunächst für -apple-system und Arial als globale Fallback-Fonts entschieden haben; San Francisco (über -apple-system gerendert) schien ein bisschen schöner zu sein als Arial, aber wenn es nicht verfügbar ist, haben wir uns für Arial entschieden, nur weil es in den meisten Betriebssystemen weit verbreitet ist.
In CSS würde das so aussehen:
.article__summary { font-family: -apple-system,Arial,BlinkMacSystemFont,Roboto Slab,Droid Serif,Segoe UI,Ubuntu,Cantarell,Georgia,sans-serif; font-style: italic; /* Warning: magic numbers ahead! */ /* San Francisco Italic and Arial Italic have larger x-height, compared to Elena */ font-size: 0.9213em; line-height: 1.487em; } .wf-loaded-stage2 .article__summary { font-family: Elena,sans-serif; font-size: 1em; /* Original font-size for Elena Italic */ line-height: 1.55em; /* Original line-height for Elena Italic */ }Dies funktionierte ziemlich gut. Wir zeigen Text sofort an, und Webfonts werden gruppiert auf dem Bildschirm angezeigt, was im Idealfall genau einen Reflow bei der ersten Ansicht und überhaupt keinen Reflow bei nachfolgenden Ansichten verursacht.
Sobald die Schriftarten heruntergeladen wurden, speichern wir sie im Cache eines Servicemitarbeiters. Bei späteren Besuchen prüfen wir zunächst, ob sich die Schriften bereits im Cache befinden. Wenn dies der Fall ist, rufen wir sie aus dem Cache des Servicemitarbeiters ab und wenden sie sofort an. Und wenn nicht, fangen wir mit dem fallback-web-font-switcheroo von vorne an.
Diese Lösung reduzierte die Anzahl der Reflows auf ein Minimum (einen) bei relativ schnellen Verbindungen, während die Schriftarten auch dauerhaft und zuverlässig im Cache gehalten wurden. In Zukunft hoffen wir aufrichtig, magische Zahlen durch F-Mods zu ersetzen. Vielleicht wäre Zach Leatherman stolz.
Identifizieren und Aufschlüsseln des monolithischen JS
Als wir den Hauptthread im Performance-Panel von DevTools untersuchten, wussten wir genau, was wir tun mussten. Es gab acht lange Aufgaben, die zwischen 70 ms und 580 ms dauerten, die Schnittstelle blockierten und sie nicht mehr reagierten. Im Allgemeinen waren dies die Skripte, die am meisten kosteten:
- uc.js , ein Cookie-Prompt-Scripting (70 ms)
- Stil-Neuberechnungen, verursacht durch eingehende full.css -Datei (176 ms) (das kritische CSS enthält keine Stile unter der Höhe von 1000 Pixeln in allen Darstellungsbereichen)
- Werbeskripte, die beim Ladeereignis ausgeführt werden, um Panels, Einkaufswagen usw. zu verwalten + Stil-Neuberechnungen (276 ms)
- Wechsel der Webschriftart, Neuberechnung des Stils (290 ms)
- app.js- Evaluierung (580 ms)
Wir haben uns zuerst auf die schädlichsten konzentriert – sozusagen die längsten Long Tasks.
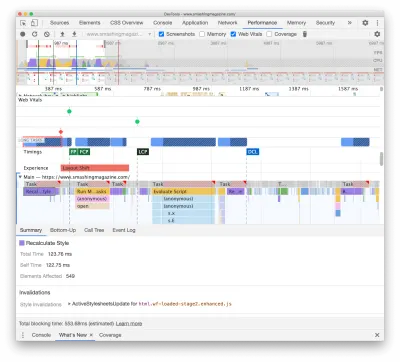
Der erste trat aufgrund teurer Layout-Neuberechnungen auf, die durch die Änderung der Schriftarten (von Fallback-Schriftart zu Web-Schriftart) verursacht wurden und über 290 ms zusätzliche Arbeit verursachten (auf einem schnellen Laptop und einer schnellen Verbindung). Allein durch das Entfernen von Stufe eins aus dem Laden von Schriftarten konnten wir etwa 80 ms zurückgewinnen. Es war jedoch nicht gut genug, weil es weit über dem Budget von 50 ms lag. Also fingen wir an, tiefer zu graben.
Der Hauptgrund für die Neuberechnungen waren lediglich die großen Unterschiede zwischen Fallback-Fonts und Web-Fonts. Durch Anpassen der Zeilenhöhe und -größe für Fallback-Schriftarten und Webschriftarten konnten wir viele Situationen vermeiden, in denen eine Textzeile in einer neuen Zeile in der Fallback-Schriftart umgebrochen wurde, dann aber etwas kleiner wurde und in die vorherige Zeile passte. was zu einer großen Änderung der Geometrie der gesamten Seite und folglich zu massiven Layoutverschiebungen führt. Wir haben auch mit letter-spacing und word-spacing gespielt, aber es hat keine guten Ergebnisse erzielt.
Mit diesen Änderungen konnten wir weitere 50-80 ms einsparen, aber wir konnten sie nicht unter 120 ms reduzieren, ohne den Inhalt in einer Fallback-Schriftart anzuzeigen und den Inhalt anschließend in der Webschriftart anzuzeigen. Offensichtlich sollte dies nur Erstbesucher massiv beeinträchtigen, da nachfolgende Seitenaufrufe mit den Schriftarten gerendert würden, die direkt aus dem Cache des Servicemitarbeiters abgerufen würden, ohne kostspielige Umbrüche aufgrund des Schriftartwechsels.
Übrigens ist es ziemlich wichtig zu beachten, dass wir in unserem Fall festgestellt haben, dass die meisten langen Aufgaben nicht durch massives JavaScript verursacht wurden, sondern durch Layout-Neuberechnungen und Parsen des CSS, was bedeutete, dass wir ein bisschen CSS machen mussten cleaning, especially watching out for situations when styles are overwritten. In some way, it was good news because we didn't have to deal with complex JavaScript issues that much. However, it turned out not to be straightforward as we are still cleaning up the CSS this very day. We were able to remove two Long Tasks for good, but we still have a few outstanding ones and quite a way to go. Fortunately, most of the time we aren't way above the magical 50ms threshold.
The much bigger issue was the JavaScript bundle we were serving, occupying the main thread for a whopping 580ms. Most of this time was spent in booting up app.js which contains React, Redux, Lodash, and a Webpack module loader. The only way to improve performance with this massive beast was to break it down into smaller pieces. So we looked into doing just that.
With Webpack, we've split up the monolithic bundle into smaller chunks with code-splitting , about 30Kb per chunk. We did some package.json cleansing and version upgrade for all production dependencies, adjusted the browserlistrc setup to address the two latest browser versions, upgraded to Webpack and Babel to the latest versions, moved to Terser for minification, and used ES2017 (+ browserlistrc) as a target for script compilation.
We also used BabelEsmPlugin to generate modern versions of existing dependencies. Finally, we've added prefetch links to the header for all necessary script chunks and refactored the service worker, migrating to Workbox with Webpack (workbox-webpack-plugin).
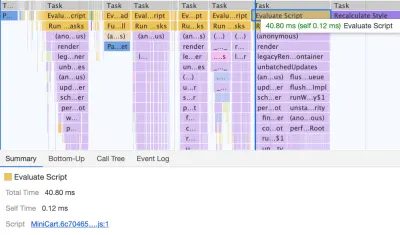
Remember when we switched to the new navigation back in mid-2020, just to see a huge performance penalty as a result? The reason for it was quite simple. While in the past the navigation was just static plain HTML and a bit of CSS, with the new navigation, we needed a bit of JavaScript to act on opening and closing of the menu on mobile and on desktop. That was causing rage clicks when you would click on the navigation menu and nothing would happen, and of course, had a penalty cost in Time-To-Interactive scores in Lighthouse.
We removed the script from the bundle and extracted it as a separate script . Additionally, we did the same thing for other standalone scripts that were used rarely — for syntax highlighting, tables, video embeds and code embeds — and removed them from the main bundle; instead, we granularly load them only when needed.
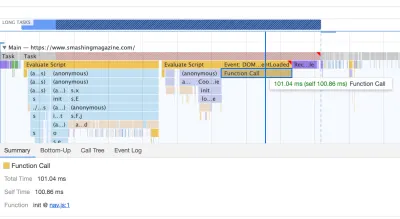
However, what we didn't notice for months was that although we removed the navigation script from the bundle, it was loading after the entire app.js bundle was evaluated, which wasn't really helping Time-To-Interactive (see image above). We fixed it by preloading nav.js and deferring it to execute in the order of appearance in the DOM, and managed to save another 100ms with that operation alone. By the end, with everything in place we were able to bring the task to around 220ms.
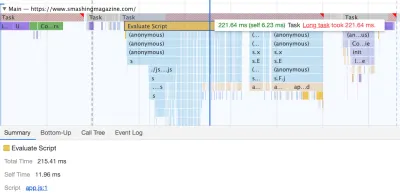
We managed to get some improvement in place, but still have quite a way to go, with further React and Webpack optimizations on our to-do list. At the moment we still have three major Long Tasks — font switch (120ms), app.js execution (220ms) and style recalculations due to the size of full CSS (140ms). For us, it means cleaning up and breaking up the monolithic CSS next.
It's worth mentioning that these results are really the best-scenario- results. On a given article page we might have a large number of code embeds and video embeds, along with other third-party scripts and customer's browser extensions that would require a separate conversation.
Dealing With 3rd-Parties
Fortunately, our third-party scripts footprint (and the impact of their friends' fourth-party-scripts) wasn't huge from the start. But when these third-party scripts accumulated, they would drive performance down significantly. This goes especially for video embedding scripts , but also syntax highlighting, advertising scripts, promo panels scripts and any external iframe embeds.
Obviously, we defer all of these scripts to start loading after the DOMContentLoaded event, but once they finally come on stage, they cause quite a bit of work on the main thread. This shows up especially on article pages, which are obviously the vast majority of content on the site.
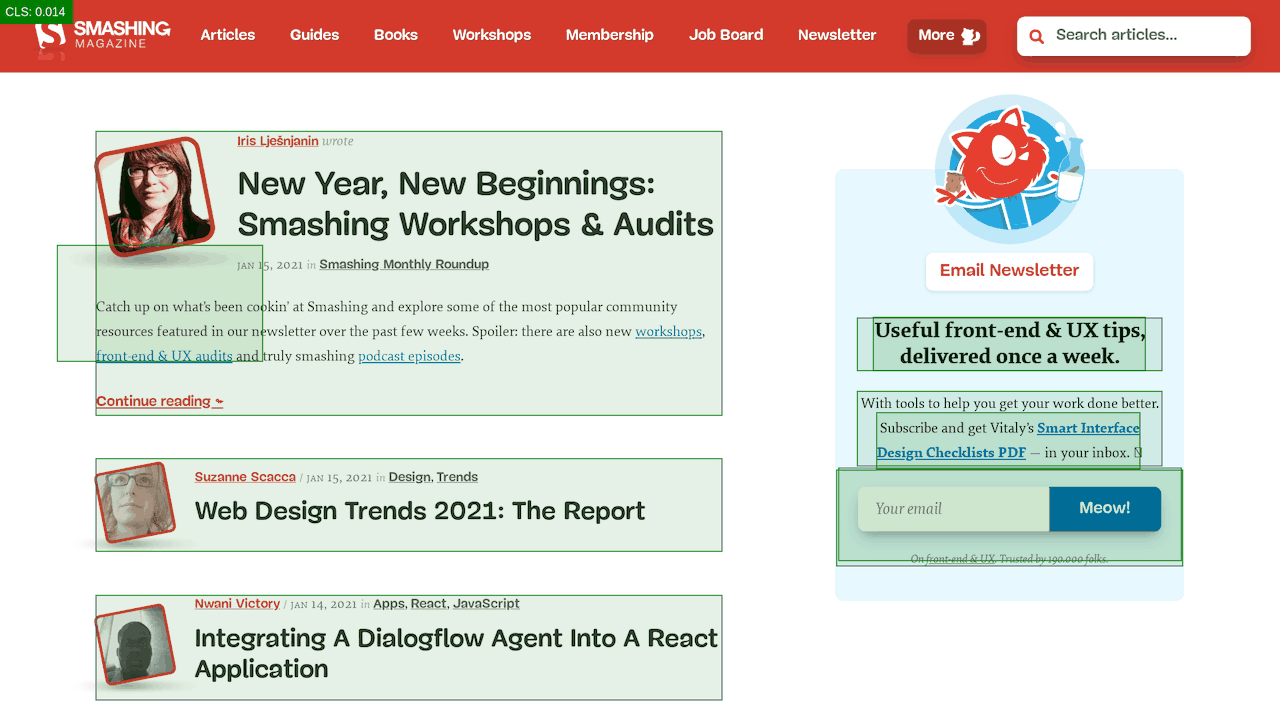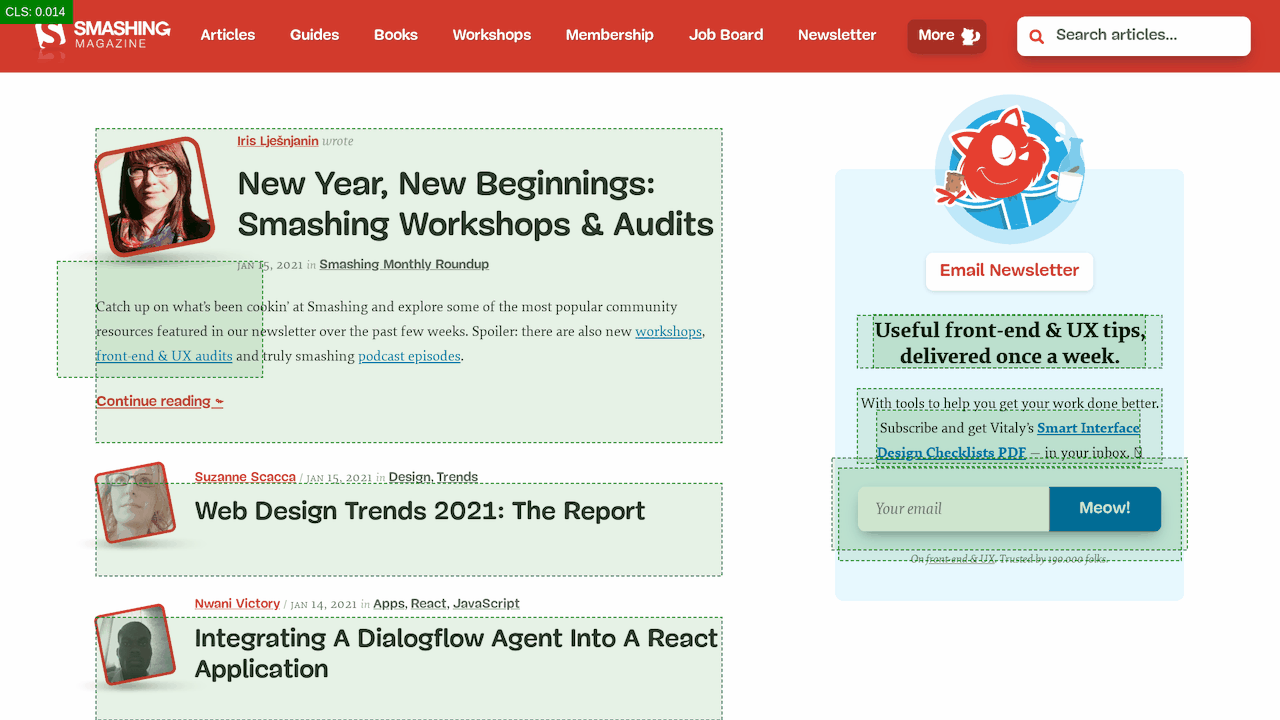
The first thing we did was allocating proper space to all assets that are being injected into the DOM after the initial page render. It meant width and height for all advertising images and the styling of code snippets. We found out that because all the scripts were deferred, new styles were invalidating existing styles, causing massive layout shifts for every code snippet that was displayed. We fixed that by adding the necessary styles to the critical CSS on the article pages.
We've re-established a strategy for optimizing images (preferably AVIF or WebP — still work in progress though). All images below the 1000px height threshold are natively lazy-loaded (with <img loading=lazy> ), while the ones on the top are prioritized ( <img loading=eager> ). The same goes for all third-party embeds.
We replaced some dynamic parts with their static counterparts — eg while a note about an article saved for offline reading was appearing dynamically after the article was added to the service worker's cache, now it appears statically as we are, well, a bit optimistic and expect it to be happening in all modern browsers.
As of the moment of writing, we're preparing facades for code embeds and video embeds as well. Plus, all images that are offscreen will get decoding=async attribute, so the browser has a free reign over when and how it loads images offscreen, asynchronously and in parallel.
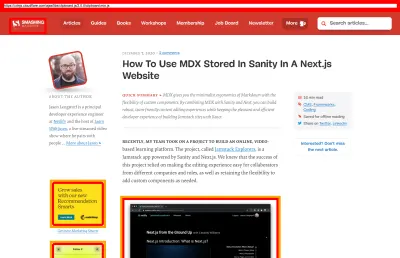
To ensure that our images always include width and height attributes, we've also modified Harry Roberts' snippet and Tim Kadlec's diagnostics CSS to highlight whenever an image isn't served properly. It's used in development and editing but obviously not in production.
One technique that we used frequently to track what exactly is happening as the page is being loaded, was slow-motion loading .
First, we've added a simple line of code to the diagnostics CSS, which provides a noticeable outline for all elements on the page.
* { outline: 3px solid red }* { outline: 3px solid red }
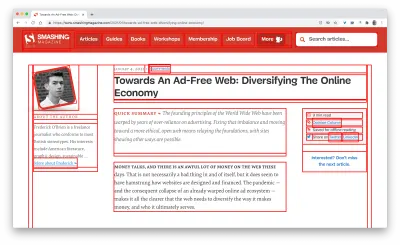
* { outline: 3px red } and observing the boxes as the browser is rendering the page. (Große Vorschau)Then we record a video of the page loaded on a slow and fast connection. Then we rewatch the video by slowing down the playback and moving back and forward to identify where massive layout shifts happen.
Here's the recording of a page being loaded on a fast connection:
And here's the recording of a recording being played to study what happens with the layout:
By auditing the layout shifts this way, we were able to quickly notice what's not quite right on the page, and where massive recalculation costs are happening. As you probably have noticed, adjusting the line-height and font-size on headings might go a long way to avoid large shifts.
With these simple changes alone, we were able to boost performance score by a whopping 25 Lighthouse points for the video-heaviest article, and gain a few points for code embeds.
Enhancing The Experience
We've tried to be quite strategic in pretty much everything from loading web fonts to serving critical CSS. However, we've done our best to use some of the new technologies that have become available last year.
We are planning on using AVIF by default to serve images on SmashingMag, but we aren't quite there yet, as many of our images are served from Cloudinary (which already has beta support for AVIF), but many are directly from our CDN yet we don't really have a logic in place just yet to generate AVIFs on the fly. That would need to be a manual process for now.
We're lazy rendering some of the offset components of the page with content-visibility: auto . For example, the footer, the comments section, as well as the panels way below the first 1000px height threshold, are all rendered later after the visible portion of each page has been rendered.
Wir haben ein bisschen mit link rel="prefetch" gespielt und sogar link rel="prerender" (NoPush prefetch) einige Teile der Seite, die sehr wahrscheinlich für die weitere Navigation verwendet werden – zum Beispiel, um Assets für den ersten vorab abzurufen Artikel auf der Titelseite (noch in Diskussion).
Wir laden auch Autorenbilder vorab, um den Largest Contentful Paint zu reduzieren, und einige wichtige Assets, die auf jeder Seite verwendet werden, wie z. B. tanzende Katzenbilder (für die Navigation) und Schatten, die für alle Autorenbilder verwendet werden. Sie werden jedoch alle nur dann vorinstalliert, wenn sich ein Leser zufällig auf einem größeren Bildschirm (> 800 Pixel) befindet, obwohl wir stattdessen die Verwendung der Netzwerkinformations-API prüfen, um genauer zu sein.
Wir haben auch die Größe des vollständigen CSS und aller kritischen CSS-Dateien reduziert , indem wir Legacy-Code entfernt, eine Reihe von Komponenten umgestaltet und den Text-Schatten- Trick entfernt haben, den wir verwendet haben, um perfekte Unterstreichungen mit einer Kombination aus Text-Dekoration-Überspringen zu erzielen -Tinte und Textdekorationsdicke (endlich!).
Arbeit zu tun
Wir haben ziemlich viel Zeit damit verbracht, all die kleineren und größeren Änderungen auf der Seite zu bearbeiten. Wir haben erhebliche Verbesserungen auf dem Desktop und einen deutlichen Schub auf Mobilgeräten festgestellt. Zum Zeitpunkt des Schreibens erreichen unsere Artikel durchschnittlich zwischen 90 und 100 Lighthouse-Punktzahlen auf dem Desktop und etwa 65 bis 80 auf Mobilgeräten .
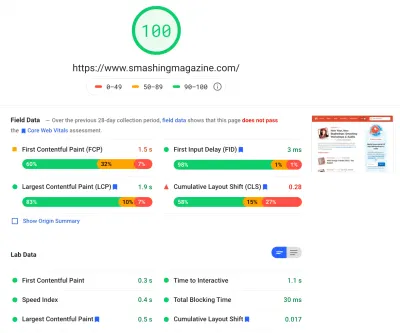
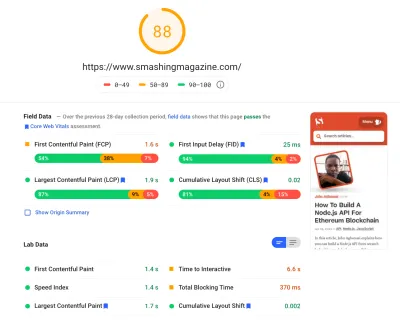
Der Grund für die schlechte Punktzahl auf Mobilgeräten ist eindeutig eine schlechte Time to Interactive und eine schlechte Total Blocking Time aufgrund des Bootens der App und der Größe der vollständigen CSS-Datei. Da ist also noch einiges zu tun.
Was die nächsten Schritte betrifft, prüfen wir derzeit , die Größe des CSS weiter zu reduzieren und es speziell in Module zu zerlegen, ähnlich wie JavaScript, und einige Teile des CSS (z. B. Checkout oder Jobbörse oder Bücher/eBooks) nur dann zu laden erforderlich.
Wir untersuchen auch Optionen für weitere Bündelungsexperimente auf Mobilgeräten, um die Auswirkungen auf die Leistung von app.js zu reduzieren, obwohl dies im Moment nicht trivial zu sein scheint. Schließlich werden wir nach Alternativen zu unserer Cookie-Prompt-Lösung suchen, unsere Container mit CSS clamp() neu erstellen, die Padding-Bottom-Ratio-Technik durch das aspect-ratio ersetzen und versuchen, so viele Bilder wie möglich in AVIF bereitzustellen.
Das ist es, Leute!
Hoffentlich ist diese kleine Fallstudie für Sie nützlich, und vielleicht gibt es die eine oder andere Technik, die Sie vielleicht sofort auf Ihr Projekt anwenden können. Letztendlich dreht sich bei der Leistung alles um die Summe all der feinen kleinen Details, die zusammengenommen das Erlebnis Ihrer Kunden ausmachen oder brechen.
Während wir uns sehr dafür einsetzen, die Leistung zu verbessern, arbeiten wir auch an der Verbesserung der Zugänglichkeit und des Inhalts der Website. Wenn Sie also etwas entdecken, das nicht ganz stimmt oder wir etwas tun könnten, um das Smashing Magazine weiter zu verbessern, teilen Sie uns dies bitte in den Kommentaren zu diesem Artikel mit.
Wenn Sie über Artikel wie diesen auf dem Laufenden bleiben möchten , abonnieren Sie bitte unseren E-Mail-Newsletter für freundliche Webtipps, Goodies, Tools und Artikel sowie eine saisonale Auswahl an Smashing Cats.