
Erstellen von serverlosen Front-End-Anwendungen mit der Google Cloud Platform
Veröffentlicht: 2022-03-10In letzter Zeit hat sich das Entwicklungsparadigma von Anwendungen von der Notwendigkeit, die in einer Anwendung verwendeten Ressourcen manuell bereitzustellen, zu skalieren und zu aktualisieren, hin zur Abhängigkeit von Cloud-Dienstanbietern von Drittanbietern für die Verwaltung dieser Ressourcen verlagert.
Als Entwickler oder Unternehmen, das innerhalb kürzester Zeit eine markttaugliche Anwendung erstellen möchte, liegt Ihr Hauptaugenmerk möglicherweise auf der Bereitstellung Ihres zentralen Anwendungsdienstes für Ihre Benutzer, während Sie weniger Zeit für die Konfiguration, Bereitstellung und Belastungstests aufwenden Ihre Bewerbung. Wenn dies Ihr Anwendungsfall ist, ist die serverlose Handhabung der Geschäftslogik Ihrer Anwendung möglicherweise die beste Option. Aber wie?
Dieser Artikel ist hilfreich für Front-End-Ingenieure, die bestimmte Funktionalitäten in ihrer Anwendung erstellen möchten, oder für Back-End-Ingenieure, die eine bestimmte Funktionalität aus einem vorhandenen Back-End-Dienst extrahieren und verarbeiten möchten, indem sie eine serverlose Anwendung verwenden, die auf der Google Cloud Platform bereitgestellt wird.
Hinweis : Um von dem zu profitieren, was hier behandelt wird, müssen Sie Erfahrung in der Arbeit mit React haben. Es sind keine Vorkenntnisse in serverlosen Anwendungen erforderlich.
Bevor wir beginnen, lassen Sie uns verstehen, was serverlose Anwendungen wirklich sind und wie die serverlose Architektur beim Erstellen einer Anwendung im Kontext eines Front-End-Ingenieurs verwendet werden kann.
Serverlose Anwendungen
Serverlose Anwendungen sind Anwendungen, die in kleine, wiederverwendbare, ereignisgesteuerte Funktionen unterteilt sind, die von Drittanbietern von Cloud-Diensten innerhalb der öffentlichen Cloud im Auftrag des Anwendungsautors gehostet und verwaltet werden. Diese werden durch bestimmte Ereignisse ausgelöst und bei Bedarf ausgeführt. Obwohl das Suffix „ less “ an das Wort serverless angehängt ist, weist dies auf das Fehlen eines Servers hin, dies ist jedoch nicht zu 100 % der Fall. Diese Anwendungen werden weiterhin auf Servern und anderen Hardwareressourcen ausgeführt, aber in diesem Fall werden diese Ressourcen nicht vom Entwickler bereitgestellt, sondern von einem Drittanbieter von Cloud-Diensten. Sie sind also für den Anwendungsautor serverlos , laufen aber dennoch auf Servern und sind über das öffentliche Internet zugänglich.
Ein beispielhafter Anwendungsfall einer serverlosen Anwendung wäre das Versenden von E-Mails an potenzielle Benutzer, die Ihre Zielseite besuchen und den Erhalt von E-Mails zur Produkteinführung abonnieren. Zu diesem Zeitpunkt haben Sie wahrscheinlich noch keinen Back-End-Dienst ausgeführt und möchten nicht die Zeit und die Ressourcen opfern, die zum Erstellen, Bereitstellen und Verwalten eines Dienstes erforderlich sind, nur weil Sie E-Mails senden müssen. Hier können Sie eine einzelne Datei schreiben, die einen E-Mail-Client verwendet, und bei jedem Cloud-Anbieter bereitstellen, der serverlose Anwendungen unterstützt, und sie diese Anwendung in Ihrem Namen verwalten lassen, während Sie diese serverlose Anwendung mit Ihrer Zielseite verbinden.
Während es eine Menge Gründe gibt, warum Sie Serverless-Anwendungen oder Functions As A Service (FAAS), wie sie genannt werden, für Ihre Front-End-Anwendung in Betracht ziehen könnten, sind hier einige sehr bemerkenswerte Gründe, die Sie berücksichtigen sollten:
- Automatische Skalierung der Anwendung
Serverlose Anwendungen werden horizontal skaliert, und dieses „Scale- out “ wird automatisch vom Cloud-Anbieter basierend auf der Anzahl der Aufrufe durchgeführt, sodass der Entwickler Ressourcen nicht manuell hinzufügen oder entfernen muss, wenn die Anwendung stark ausgelastet ist. - Kosteneffektivität
Da sie ereignisgesteuert sind, werden serverlose Anwendungen nur bei Bedarf ausgeführt, und dies spiegelt sich in den Gebühren wider, da sie basierend auf der Anzahl der aufgerufenen Zeiten in Rechnung gestellt werden. - Flexibilität
Serverlose Anwendungen sind so konzipiert, dass sie in hohem Maße wiederverwendbar sind, und das bedeutet, dass sie nicht an ein einzelnes Projekt oder eine einzelne Anwendung gebunden sind. Eine bestimmte Funktionalität kann in eine serverlose Anwendung extrahiert, bereitgestellt und über mehrere Projekte oder Anwendungen hinweg verwendet werden. Serverlose Anwendungen können auch in der bevorzugten Sprache des Anwendungsautors geschrieben werden, obwohl einige Cloud-Anbieter nur eine geringere Anzahl von Sprachen unterstützen.
Bei der Nutzung von serverlosen Anwendungen stehen jedem Entwickler eine Vielzahl von Cloud-Anbietern innerhalb der Public Cloud zur Verfügung. Im Kontext dieses Artikels konzentrieren wir uns auf serverlose Anwendungen auf der Google Cloud Platform – wie sie erstellt, verwaltet, bereitgestellt und wie sie sich auch in andere Produkte in der Google Cloud integrieren lassen. Dazu werden wir dieser bestehenden React-Anwendung neue Funktionalitäten hinzufügen, während wir den Prozess durchlaufen:
- Speichern und Abrufen von Benutzerdaten in der Cloud;
- Erstellen und Verwalten von Cron-Jobs in der Google Cloud;
- Bereitstellen von Cloud-Funktionen in der Google Cloud.
Hinweis : Serverlose Anwendungen sind nicht nur an React gebunden, solange Ihr bevorzugtes Front-End-Framework oder Ihre Bibliothek eine HTTP -Anfrage stellen kann, kann es eine serverlose Anwendung verwenden.
Google Cloud-Funktionen
Die Google Cloud ermöglicht es Entwicklern, serverlose Anwendungen mit den Cloud Functions zu erstellen und sie mit dem Functions Framework auszuführen. Wie sie genannt werden, sind Cloud-Funktionen wiederverwendbare ereignisgesteuerte Funktionen, die in der Google Cloud bereitgestellt werden, um auf einen bestimmten Auslöser aus den sechs verfügbaren Ereignisauslösern zu lauschen und dann die Operation auszuführen, für deren Ausführung sie geschrieben wurde.
Kurzlebige Cloud-Funktionen ( mit einem standardmäßigen Ausführungs-Timeout von 60 Sekunden und maximal 9 Minuten ) können mit JavaScript, Python, Golang und Java geschrieben und mit ihrer Laufzeit ausgeführt werden. In JavaScript können sie nur unter Verwendung einiger verfügbarer Versionen der Node-Laufzeit ausgeführt werden und sind in Form von CommonJS-Modulen geschrieben, die einfaches JavaScript verwenden, da sie als primäre Funktion exportiert werden, die in der Google Cloud ausgeführt werden soll.
Ein Beispiel für eine Cloud-Funktion ist die unten stehende, die eine leere Textbausteine für die Funktion zum Umgang mit den Daten eines Benutzers ist.
// index.js exports.firestoreFunction = function (req, res) { return res.status(200).send({ data: `Hello ${req.query.name}` }); } Oben haben wir ein Modul, das eine Funktion exportiert. Bei der Ausführung erhält es die Anfrage- und Antwortargumente ähnlich einer HTTP Route.
Hinweis : Eine Cloud-Funktion gleicht jedes HTTP -Protokoll ab, wenn eine Anfrage gestellt wird. Dies ist erwähnenswert, wenn Daten im Anforderungsargument erwartet werden, da die angehängten Daten bei einer Anforderung zur Ausführung einer Cloud-Funktion im Anforderungstext für POST -Anforderungen und im Abfragetext für GET -Anforderungen vorhanden wären.
Cloud-Funktionen können während der Entwicklung lokal ausgeführt werden, indem das @google-cloud/functions-framework Paket in demselben Ordner installiert wird, in dem sich die geschriebene Funktion befindet, oder indem Sie eine globale Installation durchführen, um es für mehrere Funktionen zu verwenden, indem Sie npm i -g @google-cloud/functions-framework von Ihrer Befehlszeile aus. Nach der Installation sollte es dem Skript package.json mit dem Namen des exportierten Moduls ähnlich dem folgenden hinzugefügt werden:
"scripts": { "start": "functions-framework --target=firestoreFunction --port=8000", } Oben haben wir einen einzelnen Befehl in unseren Skripten in der Datei package.json , der das Funktionsframework ausführt und auch die firestoreFunction als Zielfunktion angibt, die lokal auf Port 8000 ausgeführt werden soll.
Wir können den Endpunkt dieser Funktion testen, indem wir mit curl eine GET -Anforderung an Port 8000 auf localhost stellen. Das Einfügen des folgenden Befehls in ein Terminal wird dies tun und eine Antwort zurückgeben.
curl https://localhost:8000?name="Smashing Magazine Author" Der obige Befehl stellt eine Anforderung mit einer GET HTTP -Methode und antwortet mit einem 200 -Statuscode und Objektdaten, die den in der Abfrage hinzugefügten Namen enthalten.
Bereitstellen einer Cloud-Funktion
Von den verfügbaren Bereitstellungsmethoden besteht eine schnelle Möglichkeit zum Bereitstellen einer Cloud-Funktion von einem lokalen Computer darin, das Cloud-SDK nach der Installation zu verwenden. Wenn Sie den folgenden Befehl über das Terminal ausführen, nachdem Sie das gcloud-SDK mit Ihrem Projekt in der Google Cloud authentifiziert haben, würde eine lokal erstellte Funktion für den Cloud-Funktionsdienst bereitgestellt.
gcloud functions deploy "demo-function" --runtime nodejs10 --trigger-http --entry-point=demo --timeout=60 --set-env-vars=[name="Developer"] --allow-unauthenticatedUnter Verwendung der unten erläuterten Flags stellt der obige Befehl eine HTTP-ausgelöste Funktion mit dem Namen „ demo-function “ in der Google Cloud bereit.
- NAME
Dies ist der Name, der einer Cloud-Funktion bei der Bereitstellung gegeben wird und erforderlich ist. -
region
Dies ist die Region, in der die Cloud-Funktion bereitgestellt werden soll. Standardmäßig wird es aufus-central1. -
trigger-http
Dadurch wird HTTP als Triggertyp der Funktion ausgewählt. -
allow-unauthenticated
Dadurch kann die Funktion mithilfe des generierten Endpunkts außerhalb der Google Cloud über das Internet aufgerufen werden, ohne zu prüfen, ob der Aufrufer authentifiziert ist. -
source
Lokaler Pfad vom Terminal zur Datei, die die bereitzustellende Funktion enthält. -
entry-point
Dies ist das spezifische exportierte Modul, das aus der Datei bereitgestellt werden soll, in der die Funktionen geschrieben wurden. -
runtime
Dies ist die Sprachlaufzeit, die für die Funktion aus dieser Liste akzeptierter Laufzeitumgebungen verwendet werden soll. -
timeout
Dies ist die maximale Zeit, die eine Funktion ausgeführt werden kann, bevor eine Zeitüberschreitung eintritt. Sie beträgt standardmäßig 60 Sekunden und kann auf maximal 9 Minuten eingestellt werden.
Hinweis : Wenn Sie festlegen, dass eine Funktion nicht authentifizierte Anforderungen zulässt, bedeutet dies, dass jeder mit dem Endpunkt Ihrer Funktion auch Anforderungen stellen kann, ohne dass Sie dies gewähren. Um dies abzumildern, können wir sicherstellen, dass der Endpunkt privat bleibt, indem wir ihn über Umgebungsvariablen verwenden oder bei jeder Anfrage Autorisierungsheader anfordern.
Nachdem unsere Demofunktion bereitgestellt wurde und wir den Endpunkt haben, können wir diese Funktion testen, als ob sie in einer realen Anwendung mit einer globalen Installation von Autocannon verwendet würde. Das Ausführen von autocannon -d=5 -c=300 CLOUD_FUNCTION_URL über das geöffnete Terminal würde 300 gleichzeitige Anfragen an die Cloud-Funktion innerhalb von 5 Sekunden generieren. Dies ist mehr als genug, um die Cloud-Funktion zu starten und auch einige Metriken zu generieren, die wir auf dem Dashboard der Funktion untersuchen können.
Hinweis : Der Endpunkt einer Funktion wird nach der Bereitstellung im Terminal ausgedruckt. Wenn dies nicht der Fall ist, führen gcloud function describe FUNCTION_NAME vom Terminal aus, um die Details zur bereitgestellten Funktion einschließlich des Endpunkts abzurufen.
Unter Verwendung der Registerkarte „Metriken“ im Dashboard können wir eine visuelle Darstellung der letzten Anfrage sehen, die aus der Anzahl der Aufrufe besteht, wie lange sie gedauert haben, dem Speicherbedarf der Funktion und wie viele Instanzen gedreht wurden, um die gestellten Anfragen zu verarbeiten.
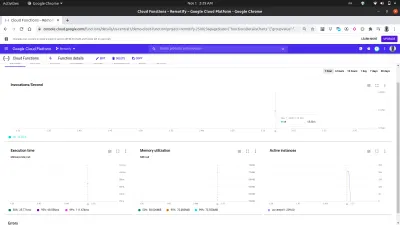
Ein genauerer Blick auf das Diagramm „Aktive Instanzen“ im obigen Bild zeigt die horizontale Skalierungskapazität der Cloud Functions, da wir sehen können, dass 209 Instanzen innerhalb weniger Sekunden hochgefahren wurden, um die mit Autocannon gestellten Anfragen zu verarbeiten.
Cloud-Funktionsprotokolle
Jede Funktion, die in der Google Cloud bereitgestellt wird, hat ein Protokoll und jedes Mal, wenn diese Funktion ausgeführt wird, wird ein neuer Eintrag in dieses Protokoll vorgenommen. Auf der Registerkarte Protokoll im Dashboard der Funktion können wir eine Liste aller Protokolleinträge aus einer Cloud-Funktion sehen.
Nachfolgend sind die Protokolleinträge unserer bereitgestellten demo-function die als Ergebnis der Anfragen erstellt wurden, die wir mit autocannon gestellt haben.
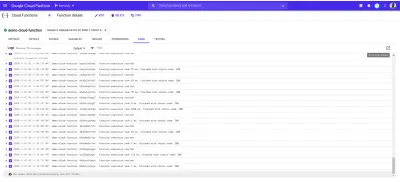
Jeder der obigen Protokolleinträge zeigt genau, wann eine Funktion ausgeführt wurde, wie lange die Ausführung gedauert hat und mit welchem Statuscode sie beendet wurde. Wenn aus einer Funktion Fehler resultieren, werden Details des Fehlers einschließlich der Zeile, in der er aufgetreten ist, hier in den Protokollen angezeigt.
Der Logs Explorer in der Google Cloud kann verwendet werden, um umfassendere Details zu den Protokollen einer Cloud-Funktion anzuzeigen.
Cloud-Funktionen mit Front-End-Anwendungen
Cloud-Funktionen sind für Front-End-Ingenieure sehr nützlich und leistungsfähig. Ein Front-End-Ingenieur ohne Kenntnisse über die Verwaltung von Back-End-Anwendungen kann eine Funktionalität in eine Cloud-Funktion extrahieren, in der Google Cloud bereitstellen und in einer Front-End-Anwendung verwenden, indem er HTTP -Anfragen an die Cloud-Funktion über ihren Endpunkt sendet.
Um zu zeigen, wie Cloud-Funktionen in einer Frontend-Anwendung verwendet werden können, werden wir dieser React-Anwendung weitere Funktionen hinzufügen. Die Anwendung verfügt bereits über ein grundlegendes Routing zwischen der Authentifizierung und der Einrichtung von Homepages. Wir werden es erweitern, um die React Context API zu verwenden, um unseren Anwendungsstatus zu verwalten, da die Verwendung der erstellten Cloud-Funktionen innerhalb der Anwendungsreduzierer erfolgen würde.
Um zu beginnen, erstellen wir den Kontext unserer Anwendung mit der createContext API und erstellen auch einen Reducer für die Handhabung der Aktionen innerhalb unserer Anwendung.
// state/index.js import { createContext } from “react”;export const UserReducer = (action, state) => { switch (action.type) { case „CREATE-USER“: break; Fall „UPLOAD-USER-IMAGE“: Pause; case „FETCH-DATA“ : Pause case „LOGOUT“ : Pause; Standard: console.log(
${action.type} is not recognized) } };export const userState = { user: null, isLoggedIn : false };
export const UserContext = createContext(userState);
Oben haben wir damit begonnen, eine UserReducer Funktion zu erstellen, die eine switch-Anweisung enthält, die es ihr ermöglicht, eine Operation basierend auf der Art der darin abgesetzten Aktion auszuführen. Die switch-Anweisung hat vier Fälle und dies sind die Aktionen, die wir behandeln werden. Im Moment tun sie noch nichts, aber wenn wir mit der Integration in unsere Cloud-Funktionen beginnen, würden wir die Aktionen, die in ihnen ausgeführt werden sollen, schrittweise implementieren.
Wir haben auch den Kontext unserer Anwendung mit der React createContext-API erstellt und exportiert und ihm einen Standardwert des userState Objekts gegeben, das derzeit einen Benutzerwert enthält, der nach der Authentifizierung von null auf die Daten des Benutzers aktualisiert würde, sowie einen isLoggedIn -Boolean-Wert, um zu wissen, ob ob der Benutzer angemeldet ist oder nicht.
Jetzt können wir damit fortfahren, unseren Kontext zu konsumieren, aber bevor wir das tun, müssen wir unseren gesamten Anwendungsbaum mit dem Provider umschließen, der an den UserContext angehängt ist, damit die untergeordneten Komponenten die Wertänderung unseres Kontexts abonnieren können.
// index.js import React from "react"; import ReactDOM from "react-dom"; import "./index.css"; import App from "./app"; import { UserContext, userState } from "./state/"; ReactDOM.render( <React.StrictMode> <UserContext.Provider value={userState}> <App /> </UserContext.Provider> </React.StrictMode>, document.getElementById("root") ); serviceWorker.unregister(); Wir umschließen unsere Enter-Anwendung mit dem UserContext -Provider in der Root-Komponente und übergeben unseren zuvor erstellten userState Standardwert in der Value-Prop.
Nachdem wir unseren Anwendungsstatus vollständig eingerichtet haben, können wir mit der Erstellung des Datenmodells des Benutzers fortfahren, indem wir Google Cloud Firestore über eine Cloud-Funktion verwenden.
Umgang mit Bewerbungsdaten
Die Daten eines Benutzers innerhalb dieser Anwendung bestehen aus einer eindeutigen ID, einer E-Mail, einem Passwort und der URL zu einem Bild. Über eine Cloud-Funktion werden diese Daten über den Cloud Firestore Service, der auf der Google Cloud Platform angeboten wird, in der Cloud gespeichert.
Der Google Cloud Firestore , eine flexible NoSQL-Datenbank, wurde aus der Firebase-Echtzeitdatenbank mit neuen erweiterten Funktionen herausgearbeitet, die neben der Offline-Datenunterstützung umfangreichere und schnellere Abfragen ermöglichen. Daten innerhalb des Firestore-Dienstes sind ähnlich wie andere NoSQL-Datenbanken wie MongoDB in Sammlungen und Dokumenten organisiert.
Auf den Firestore kann visuell über die Google Cloud Console zugegriffen werden. Um es zu starten, öffnen Sie den linken Navigationsbereich und scrollen Sie nach unten zum Abschnitt Datenbank und klicken Sie auf Firestore. Dies würde die Liste der Sammlungen für Benutzer mit vorhandenen Daten anzeigen oder den Benutzer auffordern, eine neue Sammlung zu erstellen, wenn keine vorhandene Sammlung vorhanden ist. Wir würden eine Benutzersammlung erstellen, die von unserer Anwendung verwendet wird.
Ähnlich wie andere Dienste auf der Google Cloud-Plattform verfügt Cloud Firestore auch über eine JavaScript-Clientbibliothek, die für die Verwendung in einer Knotenumgebung entwickelt wurde ( bei Verwendung im Browser wird ein Fehler ausgegeben ). Um zu improvisieren, verwenden wir die Cloud Firestore in einer Cloud-Funktion mit dem Paket @google-cloud/firestore .
Verwenden von Cloud Firestore mit einer Cloud-Funktion
Zu Beginn benennen wir die erste Funktion, die wir erstellt haben, von demo-function in firestoreFunction um und erweitern sie dann, um eine Verbindung mit Firestore herzustellen und Daten in der Sammlung unserer Benutzer zu speichern.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const { SecretManagerServiceClient } = require("@google-cloud/secret-manager"); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); console.log(document) // prints details of the collection to the function logs if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": break case "LOGIN-USER": break; default: res.status(422).send(`${type} is not a valid function action`) } }; Um mehr Operationen zu bewältigen, die den Fire-Store betreffen, haben wir eine switch-Anweisung mit zwei Fällen hinzugefügt, um die Authentifizierungsanforderungen unserer Anwendung zu erfüllen. Unsere switch-Anweisung wertet einen type aus, den wir dem Anfragetext hinzufügen, wenn wir eine Anfrage an diese Funktion von unserer Anwendung aus stellen, und wenn diese type nicht in unserem Anfragetext vorhanden sind, wird die Anfrage als Bad Request und mit einem 400 -Statuscode identifiziert neben einer Nachricht, die den fehlenden type angibt, wird als Antwort gesendet.
Wir stellen eine Verbindung mit Firestore her, indem wir die Application Default Credentials (ADC)-Bibliothek in der Cloud Firestore-Clientbibliothek verwenden. In der nächsten Zeile rufen wir die Sammlungsmethode in einer anderen Variablen auf und übergeben den Namen unserer Sammlung. Wir werden dies verwenden, um weitere Operationen zur Sammlung der enthaltenen Dokumente durchzuführen.
Hinweis : Clientbibliotheken für Dienste in der Google Cloud stellen eine Verbindung zu ihrem jeweiligen Dienst her, indem sie einen erstellten Dienstkontoschlüssel verwenden, der beim Initialisieren des Konstruktors übergeben wird. Wenn der Dienstkontoschlüssel nicht vorhanden ist, werden standardmäßig die Standardanmeldeinformationen der Anwendung verwendet, die wiederum eine Verbindung mit den IAM -Rollen herstellen, die der Cloud-Funktion zugewiesen sind.

Nachdem wir den Quellcode einer Funktion bearbeitet haben, die lokal mit dem Gcloud SDK bereitgestellt wurde, können wir den vorherigen Befehl von einem Terminal aus erneut ausführen, um die Cloud-Funktion zu aktualisieren und erneut bereitzustellen.
Nachdem eine Verbindung hergestellt wurde, können wir den Fall CREATE-USER implementieren, um einen neuen Benutzer mit Daten aus dem Anforderungstext zu erstellen.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const path = require("path"); const { v4 : uuid } = require("uuid") const cors = require("cors")({ origin: true }); const client = new SecretManagerServiceClient(); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); if (!type) { res.status(422).send("An action type was not specified"); } switch (type) { case "CREATE-USER": if (!email || !password) { res.status(422).send("email and password fields missing"); } const id = uuid() return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document.doc(id) .set({ id : id email: email, password: hash, img_uri : null }) .then((response) => res.status(200).send(response)) .catch((e) => res.status(501).send({ error : e }) ); }); }); case "LOGIN": break; default: res.status(400).send(`${type} is not a valid function action`) } }); }; Wir haben eine UUID mit dem uuid-Paket generiert, die als ID des zu speichernden Dokuments verwendet werden soll, indem wir sie an die set Methode des Dokuments und auch die Benutzer-ID übergeben. Standardmäßig wird für jedes eingefügte Dokument eine zufällige ID generiert, aber in diesem Fall aktualisieren wir das Dokument, wenn der Bildupload durchgeführt wird, und die UUID wird verwendet, um ein bestimmtes Dokument zu aktualisieren. Anstatt das Passwort des Benutzers im Klartext zu speichern, salzen wir es zuerst mit bcryptjs und speichern dann den Ergebnis-Hash als Passwort des Benutzers.
Indem wir die Cloud-Funktion firestoreFunction in die App integrieren, verwenden wir sie aus dem CREATE_USER Fall innerhalb des Benutzerreduzierers.
Nachdem Sie auf die Schaltfläche Konto erstellen geklickt haben, wird eine Aktion mit einem CREATE_USER Typ an die Reduzierer gesendet, um eine POST -Anforderung mit der eingegebenen E-Mail-Adresse und dem Kennwort an den Endpunkt der firestoreFunction -Funktion zu senden.
import { createContext } from "react"; import { navigate } from "@reach/router"; import Axios from "axios"; export const userState = { user : null, isLoggedIn: false, }; export const UserReducer = (state, action) => { switch (action.type) { case "CREATE_USER": const FIRESTORE_FUNCTION = process.env.REACT_APP_FIRESTORE_FUNCTION; const { userEmail, userPassword } = action; const data = { type: "CREATE-USER", email: userEmail, password: userPassword, }; Axios.post(`${FIRESTORE_FUNCTION}`, data) .then((res) => { navigate("/home"); return { ...state, isLoggedIn: true }; }) .catch((e) => console.log(`couldnt create user. error : ${e}`)); break; case "LOGIN-USER": break; case "UPLOAD-USER-IMAGE": break; case "FETCH-DATA" : break case "LOGOUT": navigate("/login"); return { ...state, isLoggedIn: false }; default: break; } }; export const UserContext = createContext(userState); Oben haben wir Axios verwendet, um die Anfrage an die firestoreFunction zu stellen, und nachdem diese Anfrage aufgelöst wurde, setzen wir den Anfangszustand des Benutzers von null auf die von der Anfrage zurückgegebenen Daten und leiten den Benutzer schließlich als authentifizierten Benutzer zur Homepage weiter .
An diesem Punkt kann ein neuer Benutzer erfolgreich ein Konto erstellen und zur Startseite weitergeleitet werden. Dieser Prozess zeigt, wie wir den Firestore verwenden, um eine grundlegende Erstellung von Daten aus einer Cloud-Funktion durchzuführen.
Handhabung der Dateispeicherung
Das Speichern und Abrufen von Dateien eines Benutzers in einer Anwendung ist meistens eine dringend benötigte Funktion innerhalb einer Anwendung. In einer Anwendung, die mit einem node.js-Backend verbunden ist, wird Multer häufig als Middleware verwendet, um die Multipart-/Formulardaten zu verarbeiten, die eine hochgeladene Datei enthält. Aber in Abwesenheit des node.js-Backends könnten wir eine Online-Datei verwenden Speicherdienst wie Google Cloud Storage zum Speichern statischer Anwendungs-Assets.
Der Google Cloud Storage ist ein weltweit verfügbarer Dateispeicherdienst, der verwendet wird, um beliebige Datenmengen als Objekte für Anwendungen in Buckets zu speichern. Es ist flexibel genug, um die Speicherung statischer Assets für kleine und große Anwendungen zu handhaben.
Um den Cloud Storage-Dienst innerhalb einer Anwendung zu verwenden, können wir die verfügbaren Storage-API-Endpunkte oder die offizielle Node-Storage-Client-Bibliothek verwenden. Die Node Storage-Clientbibliothek funktioniert jedoch nicht in einem Browserfenster, sodass wir eine Cloud-Funktion nutzen könnten, in der wir die Bibliothek verwenden.
Ein Beispiel dafür ist die Cloud-Funktion unten, die eine Verbindung herstellt und eine Datei in einen erstellten Cloud-Bucket hochlädt.
const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); exports.Uploader = (req, res) => { const { file } = req.body; StorageClient.bucket("TEST_BUCKET") .file(file.name) .then((response) => { console.log(response); res.status(200).send(response) }) .catch((e) => res.status(422).send({error : e})); }); };Von der Cloud-Funktion oben führen wir die beiden folgenden Hauptoperationen aus:
Zunächst erstellen wir im
Storage constructoreine Verbindung zum Cloud-Speicher und verwenden die Funktion „Application Default Credentials“ (ADC) in Google Cloud, um sich beim Cloud-Speicher zu authentifizieren.Zweitens laden wir die im Anforderungstext enthaltene Datei in unseren
TEST_BUCKET, indem wir die Methode.fileaufrufen und den Namen der Datei übergeben. Da dies eine asynchrone Operation ist, verwenden wir ein Versprechen, um zu wissen, wann diese Aktion aufgelöst wurde, und wir senden eine200-Antwort zurück, wodurch der Lebenszyklus des Aufrufs beendet wird.
Jetzt können wir die obige Uploader -Cloud-Funktion erweitern, um das Hochladen des Profilbilds eines Benutzers zu handhaben. Die Cloud-Funktion empfängt das Profilbild eines Benutzers, speichert es im Cloud-Bucket unserer Anwendung und aktualisiert dann die img_uri -Daten des Benutzers in unserer Benutzersammlung im Firestore-Dienst.
require("dotenv").config(); const { Firestore } = require("@google-cloud/firestore"); const cors = require("cors")({ origin: true }); const { Storage } = require("@google-cloud/storage"); const StorageClient = new Storage(); const BucketName = process.env.STORAGE_BUCKET exports.Uploader = (req, res) => { return Cors(req, res, () => { const { file , userId } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); StorageClient.bucket(BucketName) .file(file.name) .on("finish", () => { StorageClient.bucket(BucketName) .file(file.name) .makePublic() .then(() => { const img_uri = `https://storage.googleapis.com/${Bucket}/${file.path}`; document .doc(userId) .update({ img_uri, }) .then((updateResult) => res.status(200).send(updateResult)) .catch((e) => res.status(500).send(e)); }) .catch((e) => console.log(e)); }); }); };Jetzt haben wir die Upload-Funktion oben erweitert, um die folgenden zusätzlichen Operationen auszuführen:
- Zuerst stellt es eine neue Verbindung zum Firestore-Dienst her, um unsere
usersabzurufen, indem es den Firestore-Konstruktor initialisiert, und es verwendet die Application Default Credentials (ADC), um sich beim Cloud Storage zu authentifizieren. - Nach dem Hochladen der im Anforderungstext hinzugefügten Datei machen wir sie öffentlich, damit sie über eine öffentliche URL zugänglich ist, indem wir die
makePublicMethode für die hochgeladene Datei aufrufen. Gemäß der standardmäßigen Zugriffskontrolle von Cloud Storage kann auf eine Datei nicht über das Internet zugegriffen werden, ohne eine Datei öffentlich zu machen, und dies ist nicht möglich, wenn die Anwendung geladen wird.
Hinweis : Das Veröffentlichen einer Datei bedeutet, dass jeder, der Ihre Anwendung verwendet, den Dateilink kopieren und uneingeschränkten Zugriff auf die Datei haben kann. Eine Möglichkeit, dies zu verhindern, besteht darin, eine signierte URL zu verwenden, um temporären Zugriff auf eine Datei in Ihrem Bucket zu gewähren, anstatt sie vollständig öffentlich zu machen.
- Als Nächstes aktualisieren wir die vorhandenen Daten des Benutzers, sodass sie die URL der hochgeladenen Datei enthalten. Wir finden die Daten des jeweiligen Benutzers mithilfe der
WHERE-Abfrage von Firestore und verwenden die im Anforderungstext enthalteneuserId. Anschließend legen wir das Feldimg_uriso fest, dass es die URL des neu aktualisierten Bildes enthält.
Die obige Cloud- Upload -Funktion kann in jeder Anwendung mit registrierten Benutzern im Firestore-Dienst verwendet werden. Alles, was erforderlich ist, um eine POST -Anforderung an den Endpunkt zu stellen, wobei der IS des Benutzers und ein Bild in den Anforderungstext eingefügt werden.
Ein Beispiel dafür innerhalb der Anwendung ist der UPLOAD-FILE Fall, der eine POST -Anforderung an die Funktion richtet und den von der Anforderung zurückgegebenen Bildlink in den Anwendungszustand versetzt.
# index.js import Axios from 'axios' const UPLOAD_FUNCTION = process.env.REACT_APP_UPLOAD_FUNCTION export const UserReducer = (state, action) => { switch (action.type) { case "CREATE-USER" : # .....CREATE-USER-LOGIC .... case "UPLOAD-FILE": const { file, id } = action return Axios.post(UPLOAD_FUNCTION, { file, id }, { headers: { "Content-Type": "image/png", }, }) .then((response) => {}) .catch((e) => console.log(e)); default : return console.log(`${action.type} case not recognized`) } } Aus dem obigen Switch-Fall machen wir eine POST -Anfrage mit Axios an die UPLOAD_FUNCTION , indem wir die hinzugefügte Datei übergeben, die in den Anfragetext aufgenommen werden soll, und wir haben auch einen Bild Content-Type im Anfrage-Header hinzugefügt.
Nach einem erfolgreichen Upload enthält die von der Cloud-Funktion zurückgegebene Antwort das Datendokument des Benutzers, das aktualisiert wurde, um eine gültige URL des Bildes zu enthalten, das in den Google Cloud-Speicher hochgeladen wurde. Wir können dann den Status des Benutzers aktualisieren, damit er die neuen Daten enthält, und dadurch wird auch das src -Element des Profilbilds des Benutzers in der Profilkomponente aktualisiert.
Umgang mit Cron-Jobs
Sich wiederholende automatisierte Aufgaben wie das Versenden von E-Mails an Benutzer oder das Ausführen einer internen Aktion zu einem bestimmten Zeitpunkt sind meistens eine integrierte Funktion von Anwendungen. In einer regulären node.js-Anwendung könnten solche Aufgaben als Cron-Jobs mit node-cron oder node-schedule behandelt werden. Beim Erstellen von serverlosen Anwendungen mit der Google Cloud Platform ist der Cloud Scheduler auch so konzipiert, dass er einen Cron-Vorgang ausführt.
Hinweis : Obwohl der Cloud Scheduler beim Erstellen von Jobs, die in der Zukunft ausgeführt werden, ähnlich wie das Unix-Cron-Dienstprogramm funktioniert, ist es wichtig zu beachten, dass der Cloud Scheduler keinen Befehl ausführt, wie es das Cron-Dienstprogramm tut. Vielmehr führt es eine Operation unter Verwendung eines angegebenen Ziels durch.
Wie der Name schon sagt, ermöglicht der Cloud Scheduler Benutzern, eine Operation zu planen, die zu einem späteren Zeitpunkt ausgeführt werden soll. Jeder Vorgang wird als Job bezeichnet, und Jobs können im Abschnitt "Scheduler" der Cloud Console visuell erstellt, aktualisiert und sogar gelöscht werden. Abgesehen von einem Namens- und Beschreibungsfeld bestehen Jobs im Cloud Scheduler aus Folgendem:
- Frequenz
Dies wird verwendet, um die Ausführung des Cron-Jobs zu planen. Zeitpläne werden mit dem unix-cron-Format angegeben, das ursprünglich verwendet wird, wenn Hintergrundjobs in der Cron-Tabelle in einer Linux-Umgebung erstellt werden. Das Unix-Cron-Format besteht aus einer Zeichenfolge mit fünf Werten, die jeweils einen Zeitpunkt darstellen. Unten sehen wir jede der fünf Zeichenfolgen und die Werte, die sie darstellen.
- - - - - - - - - - - - - - - - minute ( - 59 ) | - - - - - - - - - - - - - hour ( 0 - 23 ) | | - - - - - - - - - - - - day of month ( 1 - 31 ) | | | - - - - - - - - - month ( 1 - 12 ) | | | | - - - - - -- day of week ( 0 - 6 ) | | | | | | | | | | | | | | | | | | | | | | | | | * * * * *Das Crontab-Generator-Tool ist praktisch, wenn Sie versuchen, einen Frequenz-Zeit-Wert für einen Job zu generieren. Wenn Sie Schwierigkeiten haben, die Zeitwerte zusammenzustellen, verfügt der Crontab-Generator über ein visuelles Dropdown-Menü, in dem Sie die Werte auswählen können, aus denen ein Zeitplan besteht, und Sie kopieren den generierten Wert und verwenden ihn als Häufigkeit.
- Zeitzone
Die Zeitzone, von der aus der Cronjob ausgeführt wird. Aufgrund des Zeitunterschieds zwischen Zeitzonen haben Cron-Jobs, die mit verschiedenen angegebenen Zeitzonen ausgeführt werden, unterschiedliche Ausführungszeiten. - Ziel
Dies wird bei der Ausführung des angegebenen Jobs verwendet. Ein Ziel könnte einHTTP-Typ sein, bei dem der Job zur angegebenen Zeit eine Anfrage an die URL oder ein Pub/Sub-Thema stellt, an das der Job Nachrichten veröffentlichen oder von dem er Nachrichten abrufen kann, und schließlich eine App Engine-Anwendung.
Der Cloud Scheduler lässt sich perfekt mit HTTP-ausgelösten Cloud-Funktionen kombinieren. Wenn ein Job im Cloud Scheduler erstellt wird, dessen Ziel auf HTTP gesetzt ist, kann dieser Job verwendet werden, um eine Cloud-Funktion auszuführen. Alles, was getan werden muss, ist, den Endpunkt der Cloud-Funktion anzugeben, das HTTP-Verb der Anfrage anzugeben und dann alle Daten hinzuzufügen, die übergeben werden müssen, um im angezeigten Textfeld zu funktionieren. Wie im folgenden Beispiel gezeigt:
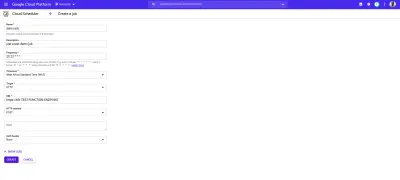
Der Cron-Job im obigen Bild wird jeden Tag um 9:00 Uhr ausgeführt und sendet eine POST -Anforderung an den Beispielendpunkt einer Cloud-Funktion.
Ein realistischerer Anwendungsfall eines Cron-Jobs ist das Versenden geplanter E-Mails an Benutzer in einem bestimmten Intervall mithilfe eines externen Mailing-Dienstes wie Mailgun. Um dies in Aktion zu sehen, erstellen wir eine neue Cloud-Funktion, die eine HTML-E-Mail an eine angegebene E-Mail-Adresse sendet, wobei das JavaScript-Paket nodemailer verwendet wird, um eine Verbindung zu Mailgun herzustellen:
# index.js require("dotenv").config(); const nodemailer = require("nodemailer"); exports.Emailer = (req, res) => { let sender = process.env.SENDER; const { reciever, type } = req.body var transport = nodemailer.createTransport({ host: process.env.HOST, port: process.env.PORT, secure: false, auth: { user: process.env.SMTP_USERNAME, pass: process.env.SMTP_PASSWORD, }, }); if (!reciever) { res.status(400).send({ error: `Empty email address` }); } transport.verify(function (error, success) { if (error) { res .status(401) .send({ error: `failed to connect with stmp. check credentials` }); } }); switch (type) { case "statistics": return transport.sendMail( { from: sender, to: reciever, subject: "Your usage satistics of demo app", html: { path: "./welcome.html" }, }, (error, info) => { if (error) { res.status(401).send({ error : error }); } transport.close(); res.status(200).send({data : info}); } ); default: res.status(500).send({ error: "An available email template type has not been matched.", }); } };Using the cloud function above we can send an email to any user's email address specified as the receiver value in the request body. It performs the sending of emails through the following steps:
- It creates an SMTP transport for sending messages by passing the
host,userandpasswhich stands for password, all displayed on the user's Mailgun dashboard when a new account is created. - Next, it verifies if the SMTP transport has the credentials needed in order to establish a connection. If there's an error in establishing the connection, it ends the function's invocation and sends back a
401 unauthenticatedstatus code. - Next, it calls the
sendMailmethod to send the email containing the HTML file as the email's body to the receiver's email address specified in thetofield.
Note : We use a switch statement in the cloud function above to make it more reusable for sending several emails for different recipients. This way we can send different emails based on the type field included in the request body when calling this cloud function.
Now that there is a function that can send an email to a user; we are left with creating the cron job to invoke this cloud function. This time, the cron jobs are created dynamically each time a new user is created using the official Google cloud client library for the Cloud Scheduler from the initial firestoreFunction .
We expand the CREATE-USER case to create the job which sends the email to the created user at a one-day interval.
require("dotenv").config();cloc const { Firestore } = require("@google-cloud/firestore"); const scheduler = require("@google-cloud/scheduler") const cors = require("cors")({ origin: true }); const EMAILER = proccess.env.EMAILER_ENDPOINT const parent = ScheduleClient.locationPath( process.env.PROJECT_ID, process.env.LOCATION_ID ); exports.firestoreFunction = function (req, res) { return cors(req, res, () => { const { email, password, type } = req.body; const firestore = new Firestore(); const document = firestore.collection("users"); const client = new Scheduler.CloudSchedulerClient() if (!type) { res.status(422).send({ error : "An action type was not specified"}); } switch (type) { case "CREATE-USER":const job = { httpTarget: { uri: process.env.EMAIL_FUNCTION_ENDPOINT, httpMethod: "POST", body: { email: email, }, }, schedule: "*/30 */6 */5 10 4", timezone: "Africa/Lagos", }if (!email || !password) { res.status(422).send("email and password fields missing"); } return bcrypt.genSalt(10, (err, salt) => { bcrypt.hash(password, salt, (err, hash) => { document .add({ email: email, password: hash, }) .then((response) => {client.createJob({ parent : parent, job : job }).then(() => res.status(200).send(response)) .catch(e => console.log(`unable to create job : ${e}`) )}) .catch((e) => res.status(501).send(`error inserting data : ${e}`) ); }); }); default: res.status(422).send(`${type} is not a valid function action`) } }); };
From the snippet above, we can see the following:
- A connection to the Cloud Scheduler from the Scheduler constructor using the Application Default Credentials (ADC) is made.
- We create an object consisting of the following details which make up the cron job to be created:
-
uri
The endpoint of our email cloud function in which a request would be made to. -
body
This is the data containing the email address of the user to be included when the request is made. -
schedule
The unix cron format representing the time when this cron job is to be performed.
-
- After the promise from inserting the user's data document is resolved, we create the cron job by calling the
createJobmethod and passing in the job object and the parent. - The function's execution is ended with a
200status code after the promise from thecreateJoboperation has been resolved.
After the job is created, we'll see it listed on the scheduler page.
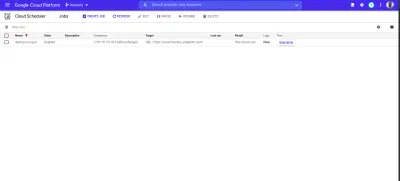
From the image above we can see the time scheduled for this job to be executed. We can decide to manually run this job or wait for it to be executed at the scheduled time.
Fazit
Within this article, we have had a good look into serverless applications and the benefits of using them. We also had an extensive look at how developers can manage their serverless applications on the Google Cloud using Cloud Functions so you now know how the Google Cloud is supporting the use of serverless applications.
Within the next years to come, we will certainly see a large number of developers adapt to the use of serverless applications when building applications. If you are using cloud functions in a production environment, it is recommended that you read this article from a Google Cloud advocate on “6 Strategies For Scaling Your Serverless Applications”.
The source code of the created cloud functions are available within this Github repository and also the used front-end application within this Github repository. The front-end application has been deployed using Netlify and can be tested live here.
Verweise
- Google-Cloud
- Cloud Functions
- Cloud Source Repositories
- Cloud Scheduler overview
- Cloud-Firestore
- “6 Strategies For Scaling Your Serverless Applications,” Preston Holmes