
Quantitative Datentools für UX-Designer
Veröffentlicht: 2022-03-10Viele UX-Designer haben etwas Angst vor Daten, weil sie glauben, dass sie tiefgreifende Kenntnisse in Statistik und Mathematik erfordern. Das mag zwar für fortgeschrittene Data Science gelten, aber nicht für die grundlegende Forschungsdatenanalyse, die von den meisten UX-Designern verlangt wird. Da wir in einer zunehmend datengesteuerten Welt leben, ist grundlegende Datenkompetenz für fast jeden Fachmann nützlich – nicht nur für UX-Designer.
Aaron Gitlin, Interaction Designer bei Google, argumentiert, dass viele Designer noch nicht datengetrieben sind:
„Während sich viele Unternehmen als datengetrieben präsentieren, werden die meisten Designer von Instinkt, Zusammenarbeit und qualitativen Forschungsmethoden getrieben.“
— Aaron Gitlin, „Ein datenbewusster Designer werden“
Mit diesem Artikel möchte ich UX-Designern das Wissen und die Werkzeuge an die Hand geben, um Daten in ihren Alltag zu integrieren.
Aber zuerst einige Datenkonzepte
In diesem Artikel werde ich über strukturierte Daten sprechen, also Daten, die in einer Tabelle mit Zeilen und Spalten dargestellt werden können. Da unstrukturierte Daten ein eigenständiges Thema sind, sind sie schwieriger zu analysieren, wie Devin Pickell (Content-Marketing-Spezialist bei G2 Crowd, der über Daten und Analysen schreibt) in seinem Artikel „Structured vs Unstructured Data – What’s the Difference?“ herausstellte. Wenn die strukturierten Daten in Tabellenform dargestellt werden können, sind die Hauptkonzepte:
Datensatz
Der gesamte Datensatz, den wir analysieren möchten. Dies kann beispielsweise eine Excel-Tabelle sein. Ein weiteres beliebtes Format zum Speichern von Datensätzen ist die kommagetrennte Wertedatei (CSV). CSV-Dateien sind einfache Textdateien, die zum Speichern von tabellenähnlichen Informationen verwendet werden. Jede CSV-Zeile entspricht einer Zeile in der Tabelle, und jede CSV-Zeile hat (natürlich) durch Kommas getrennte Werte, die Tabellenzellen entsprechen.
Datenpunkt
Eine einzelne Zeile aus einer Datensatztabelle ist ein Datenpunkt. Auf diese Weise ist ein Datensatz eine Sammlung von Datenpunkten.
Datenvariable
Ein einzelner Wert aus einer Datenpunktzeile stellt eine Datenvariable dar – einfach gesagt eine Tabellenzelle. Wir können zwei Arten von Datenvariablen haben: qualitative Variablen und quantitative Variablen. Qualitative Variablen (auch als kategoriale Variablen bekannt) haben einen diskreten Satz von Werten, z. B. color = red/green/blue . Quantitative Variablen haben numerische Werte, z. B. height = 167 . Eine quantitative Variable kann im Gegensatz zu einer qualitativen jeden beliebigen Wert annehmen.
Erstellen unseres Datenprojekts
Jetzt kennen wir die Grundlagen, es ist Zeit, sich die Hände schmutzig zu machen und unser erstes Datenprojekt zu erstellen. Der Umfang des Projekts besteht darin, einen Datensatz zu analysieren, indem der gesamte Datenfluss des Importierens, Verarbeitens und Plottens von Daten durchlaufen wird. Zuerst wählen wir unseren Datensatz aus, dann laden wir die Tools zur Analyse der Daten herunter und installieren sie.
Auto-Datensatz
Für den Zweck dieses Artikels habe ich einen Auto-Datensatz gewählt, weil er einfach und intuitiv ist. Die Datenanalyse wird einfach bestätigen, was wir bereits über die Autos wissen – was in Ordnung ist, da unser Fokus auf Datenfluss und Tools liegt.
Wir können einen Gebrauchtwagen-Datensatz von Kaggle herunterladen, einer der größten Quellen für kostenlose Datensätze. Sie müssen sich zuerst registrieren.
Nachdem Sie die Datei heruntergeladen haben, öffnen Sie sie und werfen Sie einen Blick darauf. Es ist eine wirklich große CSV-Datei, aber Sie sollten das Wesentliche verstehen. Eine Zeile in dieser Datei sieht folgendermaßen aus:
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3Wie Sie sehen können, hat dieser Datenpunkt mehrere Variablen, die durch Kommas getrennt sind. Da wir jetzt den Datensatz haben, lassen Sie uns ein wenig über Werkzeuge sprechen.
Werkzeuge des Handels
Wir werden die R-Sprache und RStudio verwenden, um den Datensatz zu analysieren. R ist eine sehr beliebte und leicht zu erlernende Sprache, die nicht nur von Datenwissenschaftlern, sondern auch von Menschen in Finanzmärkten, Medizin und vielen anderen Bereichen verwendet wird. RStudio ist die Umgebung, in der R-Projekte entwickelt werden, und es gibt eine kostenlose Version, die für unsere Bedürfnisse als UX-Designer mehr als ausreichend ist.
Es ist wahrscheinlich, dass einige UX-Designer Excel für ihren Datenworkflow verwenden. Wenn das auf Sie zutrifft, versuchen Sie es mit R – es besteht eine gute Chance, dass es Ihnen gefallen wird, da es leicht zu erlernen und flexibler und leistungsfähiger als Excel ist. Das Hinzufügen von R zu Ihrem Toolkit wird einen Unterschied machen.
Installieren der Tools
Zuerst müssen wir R und RStudio herunterladen und installieren. Sie sollten zuerst R installieren, dann RStudio. Die Installationsprozesse für R und RStudio sind einfach und unkompliziert.
Projektaufbau
Sobald die Installation abgeschlossen ist, erstellen Sie einen Projektordner – ich habe ihn used-cars-prj genannt . Erstellen Sie in diesem Ordner einen Unterordner namens data , kopieren Sie dann die Datensatzdatei (heruntergeladen von Kaggle) in diesen Ordner und benennen Sie sie in used-cars.csv um . Gehen Sie nun zurück zu unserem Projektordner ( used-cars-prj ) und erstellen Sie eine einfache Textdatei namens used-cars.r . Sie sollten am Ende dieselbe Struktur wie im folgenden Screenshot haben.
Jetzt haben wir die Ordnerstruktur eingerichtet, wir können RStudio öffnen und ein neues R-Projekt erstellen. Wählen Sie „Neues Projekt…“ aus dem Menü „ Datei “ und wählen Sie die zweite Option „ Vorhandenes Verzeichnis “ aus. Wählen Sie dann das Projektverzeichnis ( used-cars-prj ). Drücken Sie abschließend auf die Schaltfläche Projekt erstellen , und Sie sind fertig. Sobald das Projekt erstellt ist, öffnen Sie used-cars.r in RStudio – das ist die Datei, in der wir unseren gesamten R-Code hinzufügen werden.
Importieren von Daten
Wir werden unsere erste Zeile in used-cars.r hinzufügen , um Daten aus der Datei used -cars.csv zu lesen. Denken Sie daran, dass CSV-Dateien nur einfache Textdateien sind, die zum Speichern von Daten verwendet werden. Unsere erste Zeile des R-Codes sieht folgendermaßen aus:
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") Es mag ein wenig einschüchternd aussehen, ist es aber wirklich nicht – übrigens ist dies die komplexeste Zeile im gesamten Artikel. Was wir hier haben, ist die read.csv Funktion, die drei Parameter akzeptiert.
Der erste Parameter ist die auszulesende Datei, in unserem Fall used-cars.csv , die sich im Ordner data befindet. Der zweite Parameter, stringsAsFactors=FALSE , wird gesetzt, um sicherzustellen, dass Zeichenfolgen wie „BMW“ oder „Audi“ nicht in Faktoren umgewandelt werden (der R-Jargon für kategoriale Daten) – wie Sie sich erinnern, können qualitative oder kategoriale Variablen nur diskrete Werte wie haben red/green/blue . Schließlich gibt der dritte Parameter, sep="," die Art des Trennzeichens an, das zum Trennen von Werten in der CSV-Datei verwendet wird: ein Komma.
Nach dem Lesen der CSV-Datei werden die Daten im Datenrahmenobjekt cars gespeichert. Ein Datenrahmen ist eine zweidimensionale Datenstruktur (wie eine Excel-Tabelle), die in R sehr nützlich ist, um Daten zu manipulieren. Nachdem Sie die Linie eingeführt und ausgeführt haben, wird ein cars für Sie erstellt. Wenn Sie in RStudio im oberen rechten Quadranten nachsehen, werden Sie den Datenrahmen „ cars “ im Abschnitt „ Daten “ auf der Registerkarte „ Umgebung “ bemerken. Wenn Sie auf cars doppelklicken, öffnet sich eine neue Registerkarte im oberen linken Quadranten von RStudio und zeigt den Datenrahmen für cars . Wie zu erwarten, sieht es aus wie eine Excel-Tabelle.
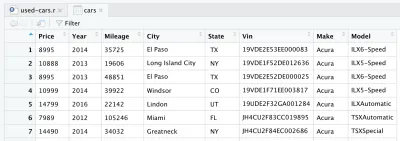
Dies sind eigentlich die Rohdaten, die wir von Kaggle heruntergeladen haben. Da wir jedoch eine Datenanalyse durchführen möchten, müssen wir unseren Datensatz zuerst verarbeiten.
Datenverarbeitung
Unter Verarbeitung verstehen wir das Entfernen, Transformieren oder Hinzufügen von Informationen zu unserem Datensatz, um uns auf die Art von Analyse vorzubereiten, die wir durchführen möchten. Wir haben die Daten in einem Datenrahmenobjekt, also müssen wir jetzt die dplyr Bibliothek installieren, eine leistungsstarke Bibliothek zum Bearbeiten von Daten. Um die Bibliothek in unserer R-Umgebung zu installieren, müssen wir die folgende Zeile an den Anfang unserer R-Datei schreiben.
install.packages("dplyr")Um die Bibliothek dann zu unserem aktuellen Projekt hinzuzufügen, verwenden wir die nächste Zeile:
library(dplyr) Sobald die dplyr Bibliothek zu unserem Projekt hinzugefügt wurde, können wir mit der Datenverarbeitung beginnen. Wir haben einen wirklich großen Datensatz, und wir brauchen nur die Daten, die denselben Autohersteller und dasselbe Modell repräsentieren, um dies mit dem Preis zu korrelieren. Wir verwenden den folgenden R-Code, um nur Daten zu behalten, die den BMW 3er betreffen, und entfernen den Rest. Natürlich könnten Sie jeden anderen Hersteller und jedes andere Modell aus dem Datensatz auswählen und dieselben Dateneigenschaften erwarten.
cars <- cars %>% filter(Make == "BMW", Model == "3")Jetzt haben wir einen handlicheren Datensatz, der aber immer noch mehr als 11.000 Datenpunkte enthält, der zu unserem beabsichtigten Zweck passt: die Preis-, Alters- und Kilometerverteilung der Autos sowie die Korrelationen zwischen ihnen zu analysieren. Dazu müssen wir nur die Spalten „Preis“, „Jahr“ und „Kilometerstand“ behalten und den Rest entfernen – dies geschieht mit der folgenden Zeile.

cars <- cars %>% select(Price, Year, Mileage)Nach dem Entfernen anderer Spalten sieht unser Datenrahmen folgendermaßen aus:
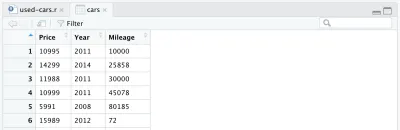
Es gibt noch eine weitere Änderung, die wir an unserem Datensatz vornehmen möchten: das Herstellungsjahr durch das Alter des Autos zu ersetzen. Wir können die folgenden zwei Zeilen hinzufügen, die erste, um das Alter zu berechnen, die zweite, um den Spaltennamen zu ändern.
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Schließlich sieht unser vollständig verarbeiteter Datenrahmen so aus:
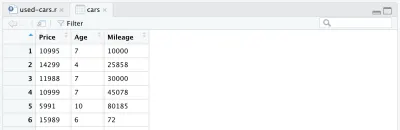
An diesem Punkt sieht unser R-Code wie folgt aus, und das ist alles für die Datenverarbeitung. Wir können jetzt sehen, wie einfach und leistungsfähig die R-Sprache ist. Wir haben den anfänglichen Datensatz mit nur wenigen Codezeilen ziemlich dramatisch verarbeitet.
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)Datenanalyse
Unsere Daten sind jetzt in der richtigen Form, also können wir ein paar Diagramme erstellen. Wie bereits erwähnt, konzentrieren wir uns auf zwei Aspekte: die Verteilung der einzelnen Variablen und die Korrelationen zwischen ihnen. Die variable Verteilung hilft uns zu verstehen, was als mittlerer oder hoher Preis für einen Gebrauchtwagen angesehen wird – oder den Prozentsatz der Autos über einem bestimmten Preis. Gleiches gilt für Alter und Laufleistung der Autos. Korrelationen hingegen sind hilfreich, um zu verstehen, wie Variablen wie Alter und Laufleistung miteinander zusammenhängen.
Allerdings werden wir zwei Arten der Datenvisualisierung verwenden: Histogramme für die Variablenverteilung und Streudiagramme für Korrelationen.
Preisverteilung
Das Plotten des Autopreishistogramms in der R-Sprache ist so einfach:
hist(cars$Price)Kleiner Tipp: Wenn Sie in RStudio sind, können Sie den Code Zeile für Zeile ausführen; In unserem Fall müssen Sie beispielsweise nur die obige Zeile ausführen, um das Histogramm anzuzeigen. Es ist nicht erforderlich, den gesamten Code erneut auszuführen, da Sie ihn bereits einmal ausgeführt haben. Das Histogramm sollte so aussehen:
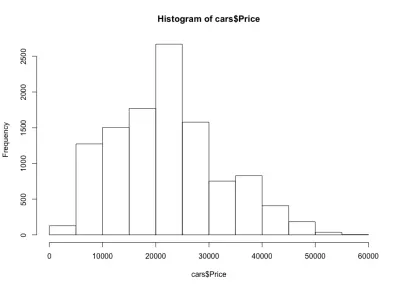
Wenn wir uns das Histogramm ansehen, bemerken wir eine glockenförmige Verteilung der Autopreise, was wir erwartet haben. Die meisten Autos fallen in den mittleren Bereich, und wir haben immer weniger, je weiter wir uns zu jeder Seite bewegen. Fast 80 % der Autos kosten zwischen 10.000 und 30.000 USD, und wir haben maximal mehr als 2.500 Autos zwischen 20.000 und 25.000 USD. Auf der linken Seite haben wir wahrscheinlich etwa 150 Autos unter 5.000 USD und auf der rechten Seite noch weniger. Wir können leicht erkennen, wie nützlich solche Diagramme sind, um Einblicke in Daten zu erhalten.
Altersverteilung
Genau wie für die Preise der Autos verwenden wir eine ähnliche Linie, um das Altershistogramm der Autos zu zeichnen.
hist(cars$Age)Und hier ist das Histogramm:
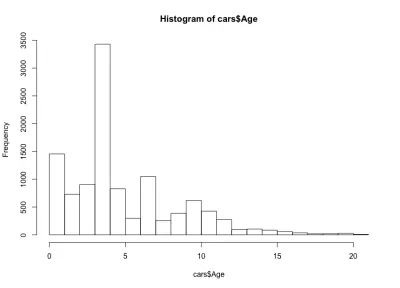
Dieses Mal sieht das Histogramm kontraintuitiv aus – statt einer einfachen Glockenform haben wir hier vier Glocken. Grundsätzlich hat die Verteilung drei lokale und ein globales Maximum, was unerwartet ist. Es wäre interessant zu sehen, ob diese seltsame Verteilung des Alters der Autos für einen anderen Autohersteller und ein anderes Modell gilt. Für die Zwecke dieses Artikels bleiben wir beim BMW 3er-Datensatz, aber Sie können tiefer in die Daten eintauchen, wenn Sie neugierig sind. In Bezug auf unsere Altersverteilung der Autos stellen wir fest, dass mehr als 90 % der Autos jünger als 10 Jahre und mehr als 80 % weniger als 7 Jahre alt sind. Außerdem stellen wir fest, dass die meisten Autos weniger als 5 Jahre alt sind.
Meilenverteilung
Was können wir nun über die Laufleistung sagen? Natürlich erwarten wir, dass wir die gleiche Glockenform haben, die wir für den Preis hatten. Hier ist der R-Code und das Histogramm:
hist(cars$Mileage) 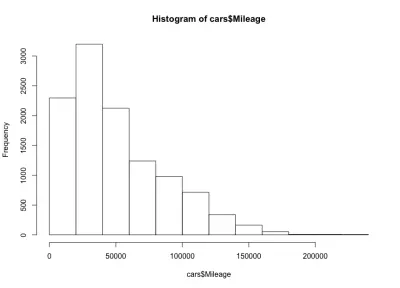
Hier haben wir eine linksschiefe Glockenform, was bedeutet, dass mehr Autos mit weniger Laufleistung auf dem Markt sind. Wir stellen auch fest, dass die Mehrheit der Autos weniger als 60.000 Meilen hat, und wir haben maximal etwa 20.000 bis 40.000 Meilen.
Alters-Preis-Korrelation
Sehen wir uns in Bezug auf Korrelationen die Korrelation zwischen Autoalter und Preis genauer an. Wir könnten erwarten, dass der Preis negativ mit dem Alter korreliert – mit zunehmendem Alter eines Autos wird sein Preis sinken. Wir werden die R- plot -Funktion verwenden, um die Preis-Alters-Korrelation wie folgt anzuzeigen:
plot(cars$Age, cars$Price)Und die Handlung sieht so aus:
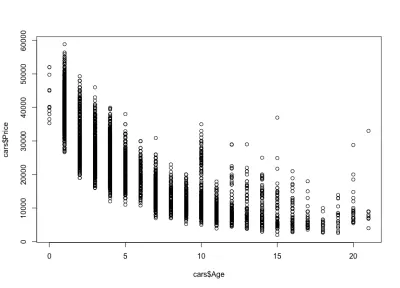
Wir merken, wie die Preise der Autos mit dem Alter sinken: Es gibt teure Neuwagen und billigere Altwagen. Wir können auch das Preisschwankungsintervall für ein bestimmtes Alter sehen, eine Schwankung, die mit dem Alter eines Autos abnimmt. Diese Variation wird weitgehend von der Laufleistung, der Konfiguration und dem Gesamtzustand des Autos bestimmt. Bei einem 4 Jahre alten Auto variiert der Preis beispielsweise zwischen 10.000 und 40.000 USD.
Kilometer-Alters-Korrelation
Unter Berücksichtigung der Laufleistung-Alters-Korrelation würden wir erwarten, dass die Laufleistung mit dem Alter zunimmt, was eine positive Korrelation bedeutet. Hier ist der Code:
plot(cars$Mileage, cars$Age)Und hier ist die Handlung:
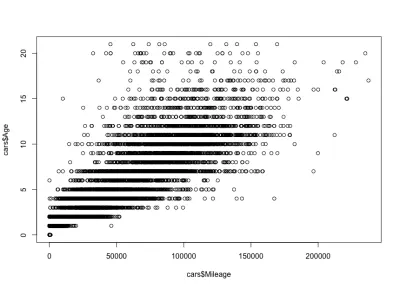
Wie Sie sehen können, sind das Alter und die Kilometerleistung eines Autos positiv korreliert, im Gegensatz zu Preis und Alter eines Autos, die negativ korreliert sind. Wir haben auch eine erwartete Laufleistungsvariation für ein bestimmtes Alter; Das heißt, Autos des gleichen Alters haben unterschiedliche Laufleistungen. Beispielsweise haben die meisten 4 Jahre alten Autos eine Laufleistung zwischen 10.000 und 80.000 Meilen. Aber es gibt auch Ausreißer mit größerer Laufleistung.
Kilometer-Preis-Korrelation
Wie erwartet wird es eine negative Korrelation zwischen der Laufleistung der Autos und dem Preis geben, was bedeutet, dass eine Erhöhung der Laufleistung den Preis senkt.
plot(cars$Mileage, cars$Price)Und hier ist die Handlung:
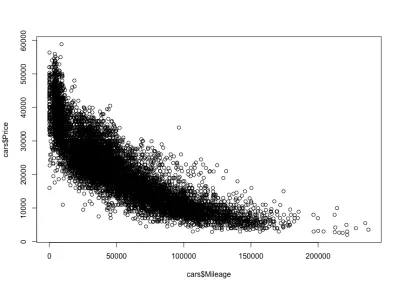
Wie wir erwartet haben, eine negative Korrelation. Wir können auch das Bruttopreisintervall zwischen 3.000 und 50.000 USD und die Laufleistung zwischen 0 und 150.000 erkennen. Wenn wir uns die Verteilungsform genauer ansehen, sehen wir, dass der Preis für Autos mit weniger Kilometerleistung viel schneller sinkt als für Autos mit mehr Kilometerleistung. Es gibt Autos mit fast null Kilometerstand, bei denen der Preis dramatisch sinkt. Auch über 200.000 Meilen Reichweite – weil die Laufleistung sehr hoch ist – bleibt der Preis konstant.
Von Zahlen zu Datenvisualisierungen
In diesem Artikel haben wir zwei Arten der Visualisierung verwendet: Histogramme für Datenverteilungen und Streudiagramme für Datenkorrelationen. Histogramme sind visuelle Darstellungen, die die Werte einer Datenvariablen (tatsächliche Zahlen ) aufnehmen und zeigen, wie sie über einen Bereich verteilt sind. Wir haben die Funktion R hist() verwendet, um ein Histogramm zu zeichnen.
Streudiagramme hingegen nehmen Zahlenpaare und stellen sie auf zwei Achsen dar. Streudiagramme verwenden die Funktion plot() und liefern zwei Parameter: die erste und die zweite Datenvariable der Korrelation, die wir untersuchen möchten. So helfen uns die beiden R-Funktionen hist() und plot() , Zahlenmengen in aussagekräftige visuelle Darstellungen zu übersetzen.
Fazit
Nachdem wir uns die Hände schmutzig gemacht haben, indem wir den gesamten Datenfluss des Importierens, Verarbeitens und Plottens von Daten durchlaufen haben, sieht die Sache jetzt viel klarer aus. Sie können denselben Datenfluss auf jeden glänzenden neuen Datensatz anwenden, auf den Sie stoßen. In der Benutzerforschung könnten Sie beispielsweise die Zeit für Aufgaben- oder Fehlerverteilungen grafisch darstellen, und Sie könnten auch eine Zeit für die Korrelation von Aufgaben und Fehlern grafisch darstellen.
Um mehr über die R-Sprache zu erfahren, ist Quick-R ein guter Ausgangspunkt, aber Sie können auch R Bloggers in Betracht ziehen. Dokumentation zu R-Paketen wie dplyr finden Sie unter RDocumentation. Das Spielen mit Daten kann Spaß machen, ist aber auch für jeden UX-Designer in einer datengesteuerten Welt äußerst hilfreich. Je mehr Daten gesammelt und verwendet werden, um Geschäftsentscheidungen zu treffen, desto größer ist die Chance für Designer, an Datenvisualisierungen oder Datenprodukten zu arbeiten, bei denen das Verständnis der Natur von Daten von entscheidender Bedeutung ist.