
Aufbau eines internen Pub/Sub-Dienstes mit Node.js und Redis
Veröffentlicht: 2022-03-10Die heutige Welt arbeitet in Echtzeit. Ob es um den Handel mit Aktien oder die Bestellung von Lebensmitteln geht, Verbraucher erwarten heute sofortige Ergebnisse. Ebenso erwarten wir alle, Dinge sofort zu wissen – ob es sich um Nachrichten oder Sport handelt. Mit anderen Worten, Zero ist der neue Held.
Dies gilt auch für Softwareentwickler – wohl einige der ungeduldigsten Menschen! Bevor ich in die Geschichte von BrowserStack eintauche, wäre es nachlässig von mir, keine Hintergrundinformationen zu Pub/Sub zu geben. Für diejenigen unter Ihnen, die mit den Grundlagen vertraut sind, können Sie die nächsten beiden Absätze überspringen.
Viele Anwendungen sind heute auf Echtzeit-Datenübertragung angewiesen. Schauen wir uns ein Beispiel genauer an: soziale Netzwerke. Facebook und Twitter generieren relevante Feeds , und Sie (über ihre App) konsumieren sie und spionieren Ihre Freunde aus. Sie erreichen dies mit einer Messaging-Funktion, bei der, wenn ein Benutzer Daten generiert, diese gepostet werden, damit andere sie im Handumdrehen konsumieren können. Bei erheblichen Verzögerungen werden sich die Benutzer beschweren, die Nutzung wird sinken und, wenn sie bestehen bleibt, abwandern. Die Einsätze sind hoch, und die Erwartungen der Benutzer sind es auch. Wie unterstützen also Dienste wie WhatsApp, Facebook, TD Ameritrade, Wall Street Journal und GrubHub große Mengen an Echtzeit-Datenübertragungen?
Alle von ihnen verwenden eine ähnliche Softwarearchitektur auf hohem Niveau, die als „Publish-Subscribe“-Modell bezeichnet wird und allgemein als Pub/Sub bezeichnet wird.
„In der Softwarearchitektur ist Publish-Subscribe ein Messaging-Muster, bei dem Sender von Nachrichten, sogenannte Publisher, die Nachrichten nicht so programmieren, dass sie direkt an bestimmte Empfänger, sogenannte Subscriber, gesendet werden, sondern stattdessen veröffentlichte Nachrichten in Klassen kategorisieren, ohne zu wissen, welche Subscriber, wenn irgendwelche, es kann sein. Ebenso bekunden Abonnenten Interesse an einer oder mehreren Klassen und erhalten nur Nachrichten, die sie interessieren, ohne zu wissen, welche Verlage es gibt.“
— Wikipedia
Gelangweilt von der Definition? Zurück zu unserer Geschichte.
Bei BrowserStack unterstützen alle unsere Produkte (auf die eine oder andere Weise) Software mit einer erheblichen Echtzeit-Abhängigkeitskomponente – ob es sich um automatisierte Testprotokolle, frisch gebackene Browser-Screenshots oder mobiles Streaming mit 15 fps handelt.
Wenn in solchen Fällen eine einzelne Nachricht verloren geht, kann ein Kunde wichtige Informationen verlieren, um einen Fehler zu verhindern . Daher mussten wir für unterschiedliche Datengrößenanforderungen skalieren. Beispielsweise können bei Geräteprotokollierungsdiensten zu einem bestimmten Zeitpunkt 50 MB an Daten in einer einzigen Nachricht generiert werden. Solche Größen können den Browser zum Absturz bringen. Ganz zu schweigen davon, dass das System von BrowserStack in Zukunft für zusätzliche Produkte skaliert werden muss.
Da die Datengröße für jede Nachricht von wenigen Bytes bis zu 100 MB variiert, benötigten wir eine skalierbare Lösung, die eine Vielzahl von Szenarien unterstützen kann. Mit anderen Worten, wir haben nach einem Schwert gesucht, das alle Kuchen schneiden kann. In diesem Artikel werde ich das Warum, Wie und die Ergebnisse des internen Aufbaus unseres Pub/Sub-Dienstes erörtern.
Durch die Linse des realen Problems von BrowserStack erhalten Sie ein tieferes Verständnis der Anforderungen und des Prozesses zum Erstellen Ihres eigenen Pub/Sub .
Unser Bedürfnis nach einem Pub/Sub-Service
BrowserStack hat etwa 100 Millionen+ Nachrichten, von denen jede zwischen etwa 2 Bytes und 100+ MB groß ist. Diese werden zu jedem Zeitpunkt um die Welt weitergegeben, alle mit unterschiedlichen Internetgeschwindigkeiten.
Die größten Erzeuger dieser Nachrichten nach Nachrichtengröße sind unsere BrowserStack Automate-Produkte. Beide haben Echtzeit-Dashboards, die alle Anfragen und Antworten für jeden Befehl eines Benutzertests anzeigen. Wenn also jemand einen Test mit 100 Anfragen durchführt, bei dem die durchschnittliche Anfrage-Antwort-Größe 10 Bytes beträgt, werden 1 × 100 × 10 = 1000 Bytes übertragen.
Betrachten wir nun das größere Bild, da wir natürlich nicht nur einen Test pro Tag durchführen. Jeden Tag werden mehr als etwa 850.000 BrowserStack Automate- und App Automate-Tests mit BrowserStack durchgeführt. Und ja, wir haben durchschnittlich etwa 235 Request-Response pro Test. Da Benutzer in Selenium Screenshots machen oder nach Seitenquellen fragen können, beträgt unsere durchschnittliche Anfrage-Antwort-Größe ungefähr 220 Bytes.
Zurück zu unserem Rechner:
850.000 × 235 × 220 = 43.945.000.000 Bytes (ca.) oder nur 43,945 GB pro Tag
Lassen Sie uns nun über BrowserStack Live und App Live sprechen. Sicherlich haben wir Automate als unseren Gewinner in Form der Datengröße. Live-Produkte sind jedoch führend, wenn es um die Anzahl der übermittelten Nachrichten geht. Für jeden Live-Test werden etwa 20 Nachrichten pro Minute weitergeleitet. Wir führen rund 100.000 Live-Tests durch, wobei jeder Test im Durchschnitt etwa 12 Minuten dauert, was bedeutet:
100.000 × 12 × 20 = 24.000.000 Nachrichten pro Tag
Nun zu dem großartigen und bemerkenswerten Teil: Wir erstellen, betreiben und warten die Anwendung für diesen sogenannten Pusher mit 6 t1.micro-Instanzen von ec2. Die Kosten für den Betrieb des Dienstes? Ungefähr 70 $ pro Monat .
Die Wahl zwischen Bauen und Kaufen
Das Wichtigste zuerst: Als Startup waren wir wie die meisten anderen immer begeistert, Dinge im eigenen Haus zu bauen. Aber wir haben trotzdem ein paar Dienste da draußen evaluiert. Die primären Anforderungen, die wir hatten, waren:
- Zuverlässigkeit und Stabilität,
- Hohe Leistung und
- Kosteneffektivität.
Lassen wir die Kosteneffizienzkriterien weg, da mir keine externen Dienste einfallen, die weniger als 70 US-Dollar im Monat kosten (twittern Sie mich, wenn Sie einen kennen, der das tut!). Unsere Antwort liegt also auf der Hand.
In Bezug auf Zuverlässigkeit und Stabilität haben wir Unternehmen gefunden, die Pub/Sub als Service mit SLAs für eine Betriebszeit von über 99,9 % bereitgestellt haben, denen jedoch viele AGB beigefügt waren. Das Problem ist nicht so einfach, wie Sie denken, besonders wenn Sie die riesigen Ländereien des offenen Internets berücksichtigen, die zwischen dem System und dem Client liegen. Jeder, der mit der Internetinfrastruktur vertraut ist, weiß, dass eine stabile Konnektivität die größte Herausforderung ist. Außerdem hängt die gesendete Datenmenge vom Datenverkehr ab. Beispielsweise kann eine Datenleitung, die für eine Minute auf Null ist, in der nächsten platzen. Dienste, die in solchen Burst-Momenten eine ausreichende Zuverlässigkeit bieten, sind selten (Google und Amazon).
Leistung für unser Projekt bedeutet , Daten nahezu ohne Latenz zu erhalten und an alle lauschenden Knoten zu senden . Bei BrowserStack nutzen wir Cloud-Dienste (AWS) zusammen mit Co-Location-Hosting. Unsere Herausgeber und/oder Abonnenten könnten jedoch überall platziert werden. Beispielsweise kann es sich um einen AWS-Anwendungsserver handeln, der dringend benötigte Protokolldaten generiert, oder um Terminals (Maschinen, auf denen sich Benutzer zu Testzwecken sicher verbinden können). Um noch einmal auf das offene Internet zurückzukommen: Wenn wir unser Risiko reduzieren wollten, müssten wir sicherstellen, dass unser Pub/Sub die besten Host-Services und AWS nutzt.
Eine weitere wesentliche Anforderung war die Fähigkeit, alle Arten von Daten (Bytes, Text, seltsame Mediendaten usw.) übertragen zu können. Alles in allem war es nicht sinnvoll, sich zur Unterstützung unserer Produkte auf eine Drittanbieterlösung zu verlassen. Im Gegenzug beschlossen wir, unseren Startup-Spirit wiederzubeleben, indem wir die Ärmel hochkrempelten, um unsere eigene Lösung zu programmieren.

Aufbau unserer Lösung
Pub/Sub bedeutet, dass es einen Herausgeber gibt, der Daten generiert und sendet, und einen Abonnenten, der sie akzeptiert und verarbeitet. Das ist ähnlich wie bei einem Radio: Ein Radiosender sendet (veröffentlicht) Inhalte überall innerhalb einer Reichweite. Als Abonnent können Sie entscheiden, ob Sie diesen Kanal einstellen und zuhören (oder Ihr Radio ganz ausschalten).
Im Gegensatz zur Radioanalogie, bei der Daten für alle kostenlos sind und jeder sich entscheiden kann, sich einzuschalten, benötigen wir in unserem digitalen Szenario eine Authentifizierung, was bedeutet, dass vom Herausgeber generierte Daten nur für einen einzigen bestimmten Kunden oder Abonnenten bestimmt sein können.
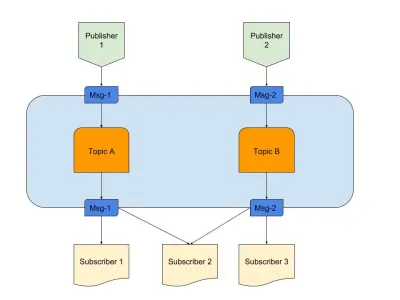
Oben ist ein Diagramm, das ein Beispiel für ein gutes Pub/Sub zeigt mit:
- Verlag
Hier haben wir zwei Herausgeber, die Nachrichten basierend auf vordefinierter Logik generieren. In unserer Radioanalogie sind dies unsere Radiojockeys, die den Inhalt erstellen. - Themen
Hier gibt es zwei, was bedeutet, dass es zwei Arten von Daten gibt. Wir können sagen, dass dies unsere Funkkanäle 1 und 2 sind. - Abonnenten
Wir haben drei, die jeweils Daten zu einem bestimmten Thema lesen. Beachten Sie, dass Abonnent 2 aus mehreren Themen liest. In unserer Radioanalogie sind dies die Leute, die auf einen Radiokanal eingestellt sind.
Beginnen wir damit, die notwendigen Anforderungen für den Dienst zu verstehen.
- Eine ereignisgesteuerte Komponente
Dies tritt nur ein, wenn es etwas zu tun gibt. - Transiente Speicherung
Dadurch bleiben die Daten für kurze Zeit bestehen, sodass der Abonnent, wenn er langsam ist, immer noch ein Fenster hat, um sie zu verbrauchen. - Reduzierung der Latenz
Verbinden zweier Entitäten über ein Netzwerk mit minimalen Sprüngen und Entfernungen.
Wir haben einen Technologie-Stack ausgewählt, der die oben genannten Anforderungen erfüllt:
- Node.js
Weil warum nicht? Evented bräuchten wir keine umfangreiche Datenverarbeitung, außerdem ist das Onboarding einfach. - Redis
Unterstützt perfekt kurzlebige Daten. Es verfügt über alle Funktionen zum Initiieren, Aktualisieren und automatischen Ablaufen. Außerdem wird die Anwendung weniger belastet.
Node.js für Geschäftslogik-Konnektivität
Node.js ist eine nahezu perfekte Sprache, wenn es darum geht, Code zu schreiben, der IO und Events enthält. Unser spezielles gegebenes Problem hatte beides, was diese Option für unsere Bedürfnisse am praktischsten macht.
Sicherlich könnten andere Sprachen wie Java optimierter sein, oder eine Sprache wie Python bietet Skalierbarkeit. Die Kosten für den Einstieg in diese Sprachen sind jedoch so hoch, dass ein Entwickler das Schreiben von Code in Node in der gleichen Zeit fertigstellen könnte.
Um ehrlich zu sein, wenn der Dienst die Möglichkeit gehabt hätte, kompliziertere Funktionen hinzuzufügen, hätten wir uns andere Sprachen oder einen vollständigen Stack ansehen können. Aber hier ist es eine himmlische Ehe. Hier ist unsere package.json :
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }Ganz einfach gesagt, wir glauben an Minimalismus, besonders wenn es um das Schreiben von Code geht. Andererseits hätten wir Bibliotheken wie Express verwenden können, um erweiterbaren Code für dieses Projekt zu schreiben. Unser Startup-Instinkt entschied sich jedoch, dies weiterzugeben und für das nächste Projekt aufzuheben. Zusätzliche Tools, die wir verwendet haben:
- ioredis
Dies ist eine der am meisten unterstützten Bibliotheken für Redis-Konnektivität mit Node.js, die von Unternehmen wie Alibaba verwendet wird. - socket.io
Die beste Bibliothek für elegante Konnektivität und Fallback mit WebSocket und HTTP.
Redis für vorübergehende Speicherung
Redis as a Service Scales ist äußerst zuverlässig und konfigurierbar. Außerdem gibt es viele zuverlässige Managed Service Provider für Redis, einschließlich AWS. Auch wenn Sie keinen Anbieter verwenden möchten, ist Redis ein einfacher Einstieg.
Lassen Sie uns den konfigurierbaren Teil aufschlüsseln. Wir haben mit der üblichen Master-Slave-Konfiguration begonnen, aber Redis bietet auch Cluster- oder Sentinel-Modi. Jeder Modus hat seine eigenen Vorteile.
Wenn wir die Daten auf irgendeine Weise teilen könnten, wäre ein Redis-Cluster die beste Wahl. Aber wenn wir die Daten durch Heuristiken teilen, haben wir weniger Flexibilität, da die Heuristik übergreifend befolgt werden muss . Weniger Regeln, mehr Kontrolle ist gut fürs Leben!
Redis Sentinel funktioniert für uns am besten, da die Datensuche in nur einem Knoten erfolgt und die Verbindung zu einem bestimmten Zeitpunkt hergestellt wird, während die Daten nicht aufgeteilt werden. Das bedeutet auch, dass selbst wenn mehrere Knoten verloren gehen, die Daten immer noch verteilt und in anderen Knoten vorhanden sind. Sie haben also mehr HA und weniger Verlustchancen. Natürlich hat dies die Profis davon abgehalten, einen Cluster zu haben, aber unser Anwendungsfall ist anders.
Architektur auf 30000 Fuß
Das folgende Diagramm bietet ein sehr allgemeines Bild davon, wie unsere Automate- und App Automate-Dashboards funktionieren. Erinnern Sie sich an das Echtzeitsystem, das wir aus dem vorherigen Abschnitt hatten?
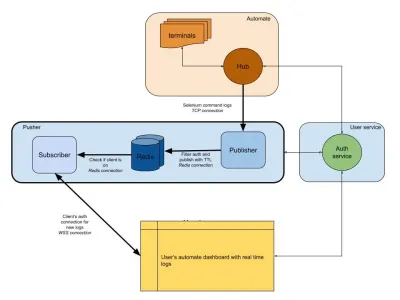
In unserem Diagramm ist unser Hauptworkflow mit dickeren Rändern hervorgehoben. Der Abschnitt „Automatisieren“ besteht aus:
- Terminals
Besteht aus den ursprünglichen Versionen von Windows, OSX, Android oder iOS, die Sie beim Testen auf BrowserStack erhalten. - Hub
Die Anlaufstelle für alle Ihre Selenium- und Appium-Tests mit BrowserStack.
Der Abschnitt „Benutzerservice“ hier ist unser Torwächter, der sicherstellt, dass Daten an die richtige Person gesendet und für sie gespeichert werden. Es ist auch unser Sicherheitsbeamter. Der Abschnitt „Pusher“ enthält das Herzstück dessen, was wir in diesem Artikel besprochen haben. Es besteht aus den üblichen Verdächtigen, darunter:
- Redis
Unser vorübergehender Speicher für Nachrichten, wobei in unserem Fall automatisierte Protokolle zwischengespeichert werden. - Herausgeber
Dies ist im Grunde die Entität, die Daten vom Hub erhält. Alle Ihre Anfrageantworten werden von dieser Komponente erfasst, die mitsession_idals Kanal in Redis schreibt. - Teilnehmer
Dies liest Daten aus Redis, die für diesession_idgeneriert wurden. Es ist auch der Webserver für Clients, die sich über WebSocket (oder HTTP) verbinden, um Daten abzurufen und diese dann an authentifizierte Clients zu senden.
Schließlich haben wir den Browserabschnitt des Benutzers, der eine authentifizierte WebSocket-Verbindung darstellt, um sicherzustellen, dass session_id Protokolle gesendet werden. Dadurch kann das Front-End-JS es für Benutzer analysieren und verschönern.
Ähnlich wie beim Protokolldienst haben wir hier einen Pusher, der für andere Produktintegrationen verwendet wird. Anstelle von session_id verwenden wir eine andere Form der ID, um diesen Kanal darzustellen. Das alles funktioniert aus Drücker heraus!
Fazit (TLDR)
Wir hatten beachtlichen Erfolg beim Aufbau von Pub/Sub. Um zusammenzufassen, warum wir es intern gebaut haben:
- Skaliert besser für unsere Bedürfnisse;
- Billiger als ausgelagerte Dienstleistungen;
- Volle Kontrolle über die Gesamtarchitektur.
Ganz zu schweigen davon, dass JS für diese Art von Szenario perfekt geeignet ist. Ereignisschleife und eine enorme Menge an IO ist das, was das Problem braucht! JavaScript ist die Magie eines einzelnen Pseudo-Threads.
Ereignisse und Redis als System machen die Dinge für Entwickler einfach, da Sie Daten von einer Quelle abrufen und über Redis an eine andere übertragen können. Also haben wir es gebaut.
Wenn die Verwendung in Ihr System passt, empfehle ich, dasselbe zu tun!