
Polynomiale Regression: Bedeutung, schrittweise Implementierung
Veröffentlicht: 2021-01-29Inhaltsverzeichnis
Einführung
Was wäre in diesem riesigen Bereich des maschinellen Lernens der erste Algorithmus, den die meisten von uns studiert hätten? Ja, es ist die lineare Regression. Lineare Regression ist größtenteils das erste Programm und der erste Algorithmus, den man in den ersten Tagen der maschinellen Lernprogrammierung gelernt hätte, und hat seine eigene Bedeutung und Kraft mit einem linearen Datentyp.
Was ist, wenn der Datensatz, auf den wir stoßen, nicht linear trennbar ist? Was ist, wenn das lineare Regressionsmodell keine Art von Beziehung zwischen den unabhängigen und abhängigen Variablen ableiten kann?
Es gibt eine andere Art der Regression, die als polynomiale Regression bekannt ist. Die polynomiale Regression ist ihrem Namen entsprechend ein Regressionsalgorithmus, der die Beziehung zwischen der abhängigen (y) Variablen und der unabhängigen Variablen (x) als Polynom n-ten Grades modelliert. In diesem Artikel werden wir den Algorithmus und die Mathematik hinter der polynomialen Regression zusammen mit ihrer Implementierung in Python verstehen.
Was ist polynomiale Regression?
Wie zuvor definiert, ist Polynomregression ein Sonderfall der linearen Regression, bei der eine Polynomgleichung mit einem bestimmten (n) Grad an die nichtlinearen Daten angepasst wird, die eine krummlinige Beziehung zwischen den abhängigen und unabhängigen Variablen bildet.
y= b 0 + b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +…… b n x 1 n
Hier,

y ist die abhängige Variable (Ausgangsvariable)
x1 ist die unabhängige Variable (Prädiktoren)
b 0 ist die Vorspannung
b 1 , b 2 , ….b n sind die Gewichte in der Regressionsgleichung.
Wenn der Grad der Polynomgleichung ( n ) höher wird, wird die Polynomgleichung komplizierter und es besteht die Möglichkeit, dass das Modell zu einer Überanpassung neigt, was im späteren Teil diskutiert wird.
Vergleich von Regressionsgleichungen
Einfache lineare Regression ===> y= b0+b1x
Mehrfache lineare Regression ===> y= b0+b1x1+ b2x2+ b3x3+…… bnxn
Polynomische Regression ===> y= b0+b1x1+ b2x12+ b3x13+…… bnx1n
Aus den obigen drei Gleichungen sehen wir, dass es mehrere subtile Unterschiede gibt. Die einfache und multiple lineare Regression unterscheiden sich von der polynomialen Regressionsgleichung dadurch, dass sie nur einen Grad von 1 hat. Die multiple lineare Regression besteht aus mehreren Variablen x1, x2 usw. Obwohl die polynomiale Regressionsgleichung nur eine Variable x1 hat, hat sie einen Grad n, der sie von den anderen beiden unterscheidet.
Notwendigkeit einer polynomialen Regression
Aus den folgenden Diagrammen können wir ersehen, dass im ersten Diagramm versucht wird, eine lineare Linie an den gegebenen Satz nichtlinearer Datenpunkte anzupassen. Es versteht sich, dass es für eine gerade Linie sehr schwierig wird, eine Beziehung zu diesen nichtlinearen Daten herzustellen. Aus diesem Grund erhöht sich beim Trainieren des Modells die Verlustfunktion, was den hohen Fehler verursacht.
Wenn wir andererseits die polynomiale Regression anwenden, ist deutlich sichtbar, dass die Linie gut auf die Datenpunkte passt. Dies bedeutet, dass die Polynomgleichung, die zu den Datenpunkten passt, eine Art Beziehung zwischen den Variablen im Datensatz herleitet. Daher benötigen wir für solche Fälle, in denen die Datenpunkte nichtlinear angeordnet sind, das polynomiale Regressionsmodell.
Implementierung der polynomialen Regression in Python
Von hier aus werden wir ein maschinelles Lernmodell in Python erstellen, das die polynomiale Regression implementiert. Wir werden die Ergebnisse der linearen Regression und der polynomialen Regression vergleichen. Lassen Sie uns zunächst das Problem verstehen, das wir mit Polynomial Regression lösen werden.
Problembeschreibung
Betrachten Sie in diesem Zusammenhang den Fall eines Start-ups, das mehrere Kandidaten aus einem Unternehmen einstellen möchte. Es gibt verschiedene Stellenangebote für unterschiedliche Stellen im Unternehmen. Das Start-up verfügt über Details zum Gehalt für jede Rolle im vorherigen Unternehmen. Wenn also ein Kandidat sein bisheriges Gehalt nennt, muss die Personalabteilung des Start-ups dies mit den vorhandenen Daten abgleichen. Somit haben wir zwei unabhängige Variablen, nämlich Position und Level. Die abhängige Variable (Output) ist das Gehalt , das mittels polynomialer Regression vorhergesagt werden soll.
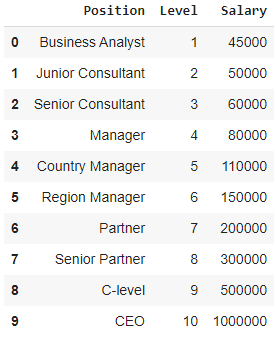
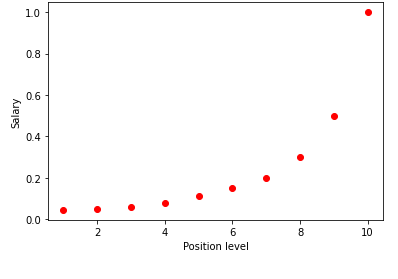
Wenn wir die obige Tabelle in einem Diagramm visualisieren, sehen wir, dass die Daten nichtlinearer Natur sind. Mit anderen Worten, wenn das Niveau steigt, steigt das Gehalt mit einer höheren Rate, was uns eine Kurve wie unten gezeigt gibt.
Schritt 1: DatenvorverarbeitungDer erste Schritt beim Erstellen eines Machine Learning-Modells ist das Importieren der Bibliotheken. Hier müssen nur drei grundlegende Bibliotheken importiert werden. Danach wird der Datensatz aus meinem GitHub-Repository importiert und die abhängigen Variablen und unabhängigen Variablen zugewiesen. Die unabhängigen Variablen werden in der Variablen X gespeichert und die abhängige Variable wird in der Variablen y gespeichert.
importiere numpy als np
importiere matplotlib.pyplot als plt
pandas als pd importieren
Datensatz = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalaries_Data.csv')
X = dataset.iloc[:, 1:-1].values
y = dataset.iloc[:, -1].values
Hier im Begriff [:, 1:-1] steht der erste Doppelpunkt dafür, dass alle Zeilen genommen werden müssen, und der Begriff 1:-1 gibt an, dass die einzuschließenden Spalten von der ersten Spalte bis zur vorletzten Spalte reichen, die durch gegeben ist -1.
Schritt 2: Lineares RegressionsmodellIm nächsten Schritt werden wir ein multiples lineares Regressionsmodell erstellen und es verwenden, um die Gehaltsdaten aus den unabhängigen Variablen vorherzusagen. Dazu wird die Klasse LinearRegression aus der sklearn-Bibliothek importiert. Es wird dann zu Trainingszwecken an die Variablen X und y angepasst.

aus sklearn.linear_model import LinearRegression
Regressor = LinearRegression()
regressor.fit(X, y)
Sobald das Modell erstellt ist, erhalten wir beim Visualisieren der Ergebnisse das folgende Diagramm.
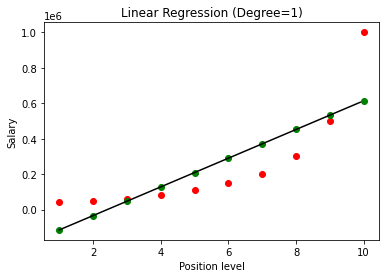
Wie deutlich zu sehen ist, gibt es beim Versuch, eine gerade Linie an einen nichtlinearen Datensatz anzupassen, keine Beziehung, die vom Modell des maschinellen Lernens abgeleitet wird. Daher müssen wir uns für die polynomiale Regression entscheiden, um eine Beziehung zwischen den Variablen zu erhalten.
Schritt 3: Polynomiales RegressionsmodellIn diesem nächsten Schritt passen wir ein polynomiales Regressionsmodell an diesen Datensatz an und visualisieren die Ergebnisse. Dazu importieren wir eine weitere Klasse aus dem sklearn-Modul namens PolynomialFeatures, in der wir den Grad der zu erstellenden Polynomgleichung angeben. Dann wird die Klasse LinearRegression verwendet, um die Polynomgleichung an das Dataset anzupassen.
aus sklearn.preprocessing import PolynomialFeatures
aus sklearn.linear_model import LinearRegression
poly_reg = PolynomialFeatures(Grad = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = LineareRegression()
lin_reg.fit(X_poly, y)
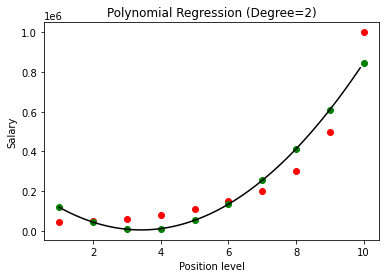
Im obigen Fall haben wir den Grad der Polynomgleichung mit 2 angegeben. Beim Zeichnen des Diagramms sehen wir, dass eine Art Kurve abgeleitet wird, aber immer noch eine große Abweichung von den realen Daten besteht (in Rot ) und die vorhergesagten Kurvenpunkte (in grün). Daher werden wir im nächsten Schritt den Grad des Polynoms auf höhere Zahlen wie 3 & 4 erhöhen und dann miteinander vergleichen.
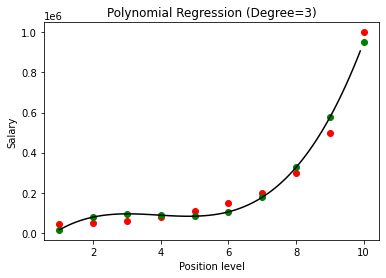
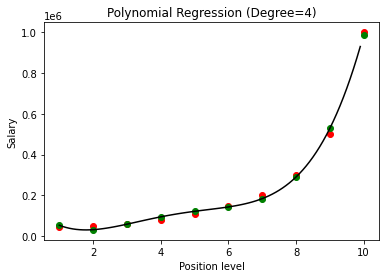
Beim Vergleich der Ergebnisse der polynomialen Regression mit den Graden 3 und 4 sehen wir, dass das Modell mit zunehmendem Grad gut mit den Daten trainiert. Daraus können wir schließen, dass ein höherer Grad es der Polynomgleichung ermöglicht, genauer auf die Trainingsdaten zu passen. Dies ist jedoch der perfekte Fall von Überanpassung. Daher ist es wichtig, den Wert von n genau zu wählen, um eine Überanpassung zu verhindern.
Was ist Overfitting?
Wie der Name schon sagt, wird Overfitting in der Statistik als eine Situation bezeichnet, in der eine Funktion (oder in diesem Fall ein maschinelles Lernmodell) zu eng an eine Reihe begrenzter Datenpunkte angepasst ist. Dies führt dazu, dass die Funktion mit neuen Datenpunkten schlecht abschneidet.
Wenn beim maschinellen Lernen gesagt wird, dass ein Modell an einem bestimmten Satz von Trainingsdatenpunkten überangepasst ist, dann schneidet es sehr schlecht ab, wenn dasselbe Modell in einen völlig neuen Satz von Punkten (z. B. den Testdatensatz) eingeführt wird Das Overfitting-Modell hat sich mit den Daten nicht gut verallgemeinert und überpasst nur die Trainingsdatenpunkte.
Bei der Polynomregression besteht eine gute Chance, dass das Modell an die Trainingsdaten überangepasst wird, wenn der Grad des Polynoms erhöht wird. In dem oben gezeigten Beispiel sehen wir einen typischen Fall einer Überanpassung bei der polynomialen Regression, die nur mit einer Trial-and-Error-Basis zur Auswahl des optimalen Werts des Grads korrigiert werden kann.
Lesen Sie auch: Projektideen für maschinelles Lernen
Fazit
Zusammenfassend lässt sich sagen, dass die polynomiale Regression in vielen Situationen verwendet wird, in denen eine nichtlineare Beziehung zwischen den abhängigen und unabhängigen Variablen besteht. Obwohl dieser Algorithmus an Empfindlichkeit gegenüber Ausreißern leidet, kann er korrigiert werden, indem man sie behandelt, bevor man die Regressionslinie anpasst. Daher wurde uns in diesem Artikel das Konzept der polynomialen Regression zusammen mit einem Beispiel für seine Implementierung in der Python-Programmierung auf einem einfachen Datensatz vorgestellt.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.
Lernen Sie ML-Kurse von den besten Universitäten der Welt. Erwerben Sie Master-, Executive PGP- oder Advanced Certificate-Programme, um Ihre Karriere zu beschleunigen.
Was meinst du mit linearer Regression?
Die lineare Regression ist eine Art prädiktive numerische Analyse, durch die wir den Wert einer unbekannten Variablen mit Hilfe einer abhängigen Variablen finden können. Es erklärt auch den Zusammenhang zwischen einer abhängigen und einer oder mehreren unabhängigen Variablen. Die lineare Regression ist eine statistische Technik zum Nachweis einer Verbindung zwischen zwei Variablen. Die lineare Regression zeichnet eine Trendlinie aus einer Reihe von Datenpunkten. Die lineare Regression kann verwendet werden, um aus scheinbar zufälligen Daten wie Krebsdiagnosen oder Aktienkursen ein Vorhersagemodell zu generieren. Es gibt mehrere Methoden zur Berechnung der linearen Regression. Der gewöhnliche Ansatz der kleinsten Quadrate, der unbekannte Variablen in Daten schätzt und visuell in die Summe der vertikalen Abstände zwischen den Datenpunkten und der Trendlinie umwandelt, ist einer der am weitesten verbreiteten.
Was sind einige der Nachteile der linearen Regression?
In den meisten Fällen wird die Regressionsanalyse in der Forschung verwendet, um festzustellen, ob es einen Zusammenhang zwischen Variablen gibt. Korrelation impliziert jedoch keine Kausalität, da eine Verbindung zwischen zwei Variablen nicht impliziert, dass die eine das andere verursacht. Selbst eine Linie in einer einfachen linearen Regression, die gut zu den Datenpunkten passt, stellt möglicherweise keine Beziehung zwischen Umständen und logischen Ergebnissen sicher. Mithilfe eines linearen Regressionsmodells können Sie bestimmen, ob es eine Korrelation zwischen Variablen gibt oder nicht. Zusätzliche Untersuchungen und statistische Analysen sind erforderlich, um die genaue Art der Verbindung zu bestimmen und festzustellen, ob eine Variable die andere verursacht.
Was sind die Grundannahmen der linearen Regression?
Bei der linearen Regression gibt es drei Schlüsselannahmen. Die abhängigen und unabhängigen Variablen müssen in erster Linie einen linearen Zusammenhang haben. Um diesen Zusammenhang zu überprüfen, wird ein Streudiagramm der abhängigen und unabhängigen Variablen verwendet. Zweitens sollte zwischen den unabhängigen Variablen im Datensatz eine minimale oder keine Multikollinearität bestehen. Dies impliziert, dass die unabhängigen Variablen unabhängig sind. Der Wert muss begrenzt werden, was durch die Domänenanforderung bestimmt wird. Homoskedastizität ist der dritte Faktor. Die Annahme, dass Fehler gleichmäßig verteilt sind, ist eine der wesentlichsten Annahmen.