
Node.js schnell halten: Tools, Techniken und Tipps zum Erstellen hochleistungsfähiger Node.js-Server
Veröffentlicht: 2022-03-10Wenn Sie lange genug mit Node.js erstellt haben, haben Sie zweifellos den Schmerz unerwarteter Geschwindigkeitsprobleme erlebt. JavaScript ist eine ereignisgesteuerte, asynchrone Sprache. Das kann die Argumentation über die Leistung schwierig machen, wie sich noch herausstellen wird. Die zunehmende Popularität von Node.js hat den Bedarf an Tools, Techniken und Denkweisen deutlich gemacht, die für die Einschränkungen von serverseitigem JavaScript geeignet sind.
Was im Browser funktioniert, passt in Sachen Performance nicht unbedingt zu Node.js. Wie stellen wir also sicher, dass eine Node.js-Implementierung schnell und zweckmäßig ist? Lassen Sie uns ein praktisches Beispiel durchgehen.
Werkzeuge
Node ist eine sehr vielseitige Plattform, aber eine der vorherrschenden Anwendungen ist die Erstellung vernetzter Prozesse. Wir werden uns auf die Erstellung von Profilen für die häufigsten davon konzentrieren: HTTP-Webserver.
Wir brauchen ein Tool, das einen Server mit vielen Anfragen bombardieren und gleichzeitig die Leistung messen kann. Zum Beispiel können wir AutoCannon verwenden:
npm install -g autocannonAndere gute HTTP-Benchmarking-Tools sind Apache Bench (ab) und wrk2, aber AutoCannon ist in Node geschrieben, bietet einen ähnlichen (oder manchmal höheren) Lastdruck und ist sehr einfach unter Windows, Linux und Mac OS X zu installieren.
Nachdem wir eine grundlegende Leistungsmessung eingerichtet haben, benötigen wir, wenn wir entscheiden, dass unser Prozess schneller sein könnte, eine Möglichkeit, Probleme mit dem Prozess zu diagnostizieren. Ein großartiges Tool zur Diagnose verschiedener Leistungsprobleme ist Node Clinic, das auch mit npm installiert werden kann:
npm install -g clinicDies installiert tatsächlich eine Reihe von Tools. Wir werden dabei Clinic Doctor und Clinic Flame (ein Wrapper um 0x) verwenden.
Hinweis : Für dieses praktische Beispiel benötigen wir Node 8.11.2 oder höher.
Der Code
Unser Beispielfall ist ein einfacher REST-Server mit einer einzigen Ressource: eine große JSON-Nutzlast, die als GET-Route unter /seed/v1 wird. Der Server ist ein app -Ordner, der aus einer package.json -Datei (abhängig von restify 7.1.0 ), einer index.js -Datei und einer util.js -Datei besteht.
Die Datei index.js für unseren Server sieht so aus:
'use strict' const restify = require('restify') const { etagger, timestamp, fetchContent } = require('./util')() const server = restify.createServer() server.use(etagger().bind(server)) server.get('/seed/v1', function (req, res, next) { fetchContent(req.url, (err, content) => { if (err) return next(err) res.send({data: content, url: req.url, ts: timestamp()}) next() }) }) server.listen(3000) Dieser Server ist repräsentativ für den üblichen Fall der Bereitstellung von vom Client zwischengespeicherten dynamischen Inhalten. Dies wird mit der etagger Middleware erreicht, die einen ETag -Header für den neuesten Stand des Inhalts berechnet.
Die Datei util.js bietet Implementierungsteile, die in einem solchen Szenario häufig verwendet werden, eine Funktion zum Abrufen der relevanten Inhalte von einem Backend, die etag-Middleware und eine Zeitstempelfunktion, die Zeitstempel im Minutentakt liefert:
'use strict' require('events').defaultMaxListeners = Infinity const crypto = require('crypto') module.exports = () => { const content = crypto.rng(5000).toString('hex') const ONE_MINUTE = 60000 var last = Date.now() function timestamp () { var now = Date.now() if (now — last >= ONE_MINUTE) last = now return last } function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } function fetchContent (url, cb) { setImmediate(() => { if (url !== '/seed/v1') cb(Object.assign(Error('Not Found'), {statusCode: 404})) else cb(null, content) }) } return { timestamp, etagger, fetchContent } }Nehmen Sie diesen Kodex keinesfalls als Beispiel für Best Practices! Es gibt mehrere Code-Smells in dieser Datei, aber wir werden sie lokalisieren, während wir die Anwendung messen und profilieren.
Um die vollständige Quelle für unseren Ausgangspunkt zu erhalten, kann der langsame Server hier gefunden werden.
Profilierung
Für die Profilerstellung benötigen wir zwei Terminals, eines zum Starten der Anwendung und das andere zum Auslasten der Anwendung.
In einem Terminal, innerhalb der app , können wir den Ordner ausführen:
node index.jsIn einem anderen Terminal können wir es so profilieren:
autocannon -c100 localhost:3000/seed/v1Dadurch werden 100 gleichzeitige Verbindungen geöffnet und der Server zehn Sekunden lang mit Anfragen bombardiert.
Die Ergebnisse sollten in etwa so aussehen (Laufender 10s-Test @ https://localhost:3000/seed/v1 – 100 Verbindungen):
| Stat | Durchschn | Stdabw | max |
|---|---|---|---|
| Latenz (ms) | 3086.81 | 1725.2 | 5554 |
| Anf./Sek | 23.1 | 19.18 | 65 |
| Bytes/Sek | 237,98 KB | 197,7 KB | 688,13 KB |
Die Ergebnisse variieren je nach Maschine. Bedenkt man jedoch, dass ein „Hello World“-Node.js-Server problemlos dreißigtausend Anfragen pro Sekunde auf der Maschine verarbeiten kann, die diese Ergebnisse produziert hat, sind 23 Anfragen pro Sekunde mit einer durchschnittlichen Latenzzeit von mehr als 3 Sekunden düster.
Diagnose
Den Problembereich entdecken
Dank des „–on-port“-Befehls von Clinic Doctor können wir die Anwendung mit einem einzigen Befehl diagnostizieren. Innerhalb des app -Ordners führen wir Folgendes aus:
clinic doctor --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsDadurch wird eine HTML-Datei erstellt, die automatisch in unserem Browser geöffnet wird, wenn die Profilerstellung abgeschlossen ist.
Die Ergebnisse sollten in etwa so aussehen:
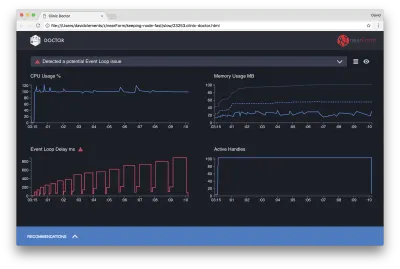
Der Doktor sagt uns, dass wir wahrscheinlich ein Problem mit der Ereignisschleife hatten.
Zusammen mit der Meldung am oberen Rand der Benutzeroberfläche können wir auch sehen, dass das Event Loop-Diagramm rot ist und eine ständig zunehmende Verzögerung anzeigt. Bevor wir näher darauf eingehen, was dies bedeutet, wollen wir zunächst verstehen, welche Auswirkungen das diagnostizierte Problem auf die anderen Metriken hat.
Wir können sehen, dass die CPU konstant bei oder über 100 % liegt, da der Prozess hart arbeitet, um Anfragen in der Warteschlange zu verarbeiten. Die JavaScript-Engine (V8) von Node verwendet in diesem Fall tatsächlich zwei CPU-Kerne, da die Maschine mehrkernig ist und V8 zwei Threads verwendet. Eine für die Ereignisschleife und die andere für die Garbage Collection. Wenn wir sehen, dass die CPU in einigen Fällen bis zu 120 % ansteigt, sammelt der Prozess Objekte, die sich auf verarbeitete Anfragen beziehen.
Wir sehen dies im Speicherdiagramm korreliert. Die durchgezogene Linie im Arbeitsspeicherdiagramm ist die Metrik Heap Used. Jedes Mal, wenn die CPU-Spitze auftritt, sehen wir einen Rückgang der Heap Used-Linie, was anzeigt, dass Speicher freigegeben wird.
Aktive Handles sind von der Verzögerung der Ereignisschleife nicht betroffen. Ein aktives Handle ist ein Objekt, das entweder E/A (z. B. ein Socket- oder Dateihandle) oder einen Timer (z. B. setInterval ) darstellt. Wir haben AutoCannon angewiesen, 100 Verbindungen zu öffnen ( -c100 ). Aktive Handles bleiben eine konsistente Anzahl von 103. Die anderen drei sind Handles für STDOUT, STDERR und das Handle für den Server selbst.
Wenn wir unten auf dem Bildschirm auf das Feld „Empfehlungen“ klicken, sollten wir etwa Folgendes sehen:
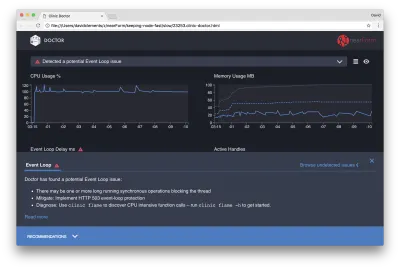
Kurzfristige Minderung
Die Ursachenanalyse schwerwiegender Leistungsprobleme kann einige Zeit in Anspruch nehmen. Im Falle eines live bereitgestellten Projekts lohnt es sich, Server oder Dienste mit einem Überlastschutz zu versehen. Die Idee des Überlastschutzes besteht darin, die Verzögerung der Ereignisschleife (unter anderem) zu überwachen und mit „503 Service Unavailable“ zu reagieren, wenn ein Schwellenwert überschritten wird. Dies ermöglicht einem Load Balancer ein Failover auf andere Instanzen oder bedeutet im schlimmsten Fall, dass Benutzer aktualisieren müssen. Das Überlastschutzmodul kann dies mit minimalem Overhead für Express, Koa und Restify bereitstellen. Das Hapi-Framework verfügt über eine Ladekonfigurationseinstellung, die den gleichen Schutz bietet.
Den Problembereich verstehen
Wie die kurze Erklärung in Clinic Doctor erklärt, ist es sehr wahrscheinlich, dass eine oder mehrere Funktionen die Ereignisschleife „blockieren“, wenn die Ereignisschleife auf das von uns beobachtete Niveau verzögert wird.
Bei Node.js ist es besonders wichtig, dieses primäre JavaScript-Merkmal zu erkennen: asynchrone Ereignisse können erst auftreten, wenn der aktuell ausgeführte Code abgeschlossen ist.
Aus diesem Grund kann ein setTimeout nicht genau sein.
Versuchen Sie beispielsweise, Folgendes in den DevTools eines Browsers oder in Node REPL auszuführen:
console.time('timeout') setTimeout(console.timeEnd, 100, 'timeout') let n = 1e7 while (n--) Math.random() Die resultierende Zeitmessung wird niemals 100 ms sein. Sie wird wahrscheinlich im Bereich von 150 ms bis 250 ms liegen. setTimeout einen asynchronen Vorgang ( console.timeEnd ) geplant, aber der aktuell ausgeführte Code ist noch nicht abgeschlossen; Es gibt noch zwei weitere Zeilen. Der aktuell ausgeführte Code wird als aktueller „Tick“ bezeichnet. Damit der Tick abgeschlossen ist, muss Math.random zehn Millionen Mal aufgerufen werden. Wenn dies 100 ms dauert, beträgt die Gesamtzeit bis zur Auflösung des Timeouts 200 ms (zuzüglich der Zeit, die die setTimeout Funktion benötigt, um das Timeout tatsächlich vorher in die Warteschlange zu stellen, normalerweise einige Millisekunden).
Wenn in einem serverseitigen Kontext eine Operation im aktuellen Tick lange dauert, um Anforderungen abzuschließen, können Anforderungen nicht verarbeitet werden, und das Abrufen von Daten kann nicht erfolgen, da asynchroner Code nicht ausgeführt wird, bis der aktuelle Tick abgeschlossen ist. Das bedeutet, dass rechenintensiver Code alle Interaktionen mit dem Server verlangsamt. Es wird daher empfohlen, ressourcenintensive Arbeit in separate Prozesse aufzuteilen und sie vom Hauptserver aufzurufen. Dadurch werden Fälle vermieden, in denen eine selten verwendete, aber teure Route die Leistung anderer häufig verwendeter, aber kostengünstiger Routen verlangsamt.
Der Beispielserver hat einen Code, der die Ereignisschleife blockiert, also besteht der nächste Schritt darin, diesen Code zu lokalisieren.
Analysieren
Eine Möglichkeit, schlecht funktionierenden Code schnell zu identifizieren, besteht darin, ein Flammendiagramm zu erstellen und zu analysieren. Ein Flammendiagramm stellt Funktionsaufrufe als Blöcke dar, die übereinander sitzen – nicht über die Zeit, sondern insgesamt. Der Grund, warum es als „Flammendiagramm“ bezeichnet wird, liegt darin, dass es normalerweise ein orangefarbenes bis rotes Farbschema verwendet, wobei je röter ein Block ist, desto „heißer“ eine Funktion ist, was bedeutet, dass es wahrscheinlicher ist, dass sie die Ereignisschleife blockiert. Das Erfassen von Daten für ein Flame-Diagramm erfolgt durch Abtasten der CPU – was bedeutet, dass ein Schnappschuss der aktuell ausgeführten Funktion und ihres Stacks erstellt wird. Die Hitze wird durch den Prozentsatz der Zeit während der Profilerstellung bestimmt, in der sich eine bestimmte Funktion für jede Probe an der Spitze des Stapels befindet (z. B. die Funktion, die gerade ausgeführt wird). Wenn es nicht die letzte Funktion ist, die jemals innerhalb dieses Stacks aufgerufen wurde, blockiert sie wahrscheinlich die Ereignisschleife.
Lassen Sie uns eine clinic flame verwenden, um ein Flammendiagramm der Beispielanwendung zu erstellen:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsDas Ergebnis sollte in unserem Browser etwa wie folgt geöffnet werden:
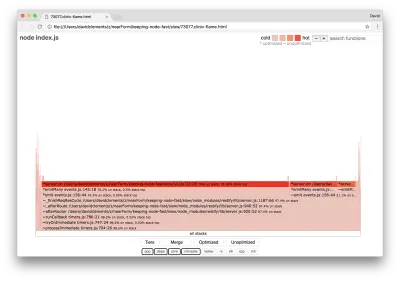
Die Breite eines Blocks gibt an, wie viel Zeit er insgesamt für die CPU aufgewendet hat. Drei Hauptstapel nehmen die meiste Zeit in Anspruch, wobei alle server.on als die heißeste Funktion hervorheben. In Wahrheit sind alle drei Stacks gleich. Sie weichen voneinander ab, da während der Profilerstellung optimierte und nicht optimierte Funktionen als separate Aufrufrahmen behandelt werden. Funktionen, denen ein * vorangestellt ist, werden von der JavaScript-Engine optimiert, und Funktionen, denen ein ~ vorangestellt ist, sind nicht optimiert. Wenn uns der optimierte Zustand nicht wichtig ist, können wir den Graphen weiter vereinfachen, indem wir auf die Schaltfläche Zusammenführen klicken. Dies sollte zu einer ähnlichen Ansicht wie der folgenden führen:
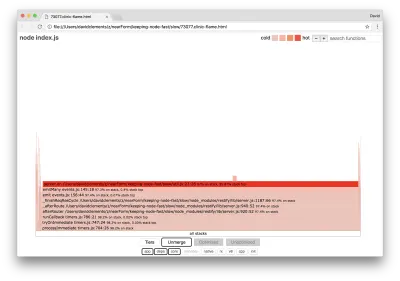
Wir können von vornherein darauf schließen, dass sich der anstößige Code in der Datei util.js des Anwendungscodes befindet.
Die langsame Funktion ist auch ein Event-Handler: Die Funktionen, die zu der Funktion führen, sind Teil des zentralen events , und server.on ist ein Fallback-Name für eine anonyme Funktion, die als Event-Handling-Funktion bereitgestellt wird. Wir können auch sehen, dass sich dieser Code nicht im selben Tick befindet wie der Code, der die Anfrage tatsächlich verarbeitet. Wenn dies der Fall wäre, wären Funktionen aus den Kernmodulen http , net und stream im Stack enthalten.
Solche Kernfunktionen können gefunden werden, indem andere, viel kleinere Teile des Flammendiagramms erweitert werden. Versuchen Sie beispielsweise, die Sucheingabe oben rechts auf der Benutzeroberfläche zu verwenden, um nach send zu suchen (der Name sowohl der internen Methoden restify als auch http ). Es sollte rechts vom Diagramm stehen (Funktionen sind alphabetisch sortiert):
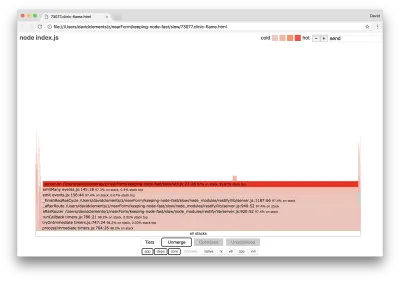
Beachten Sie, wie vergleichsweise klein alle eigentlichen HTTP-Verarbeitungsblöcke sind.

Wir können auf einen der blau hervorgehobenen Blöcke klicken, der erweitert wird, um Funktionen wie writeHead und in die Datei http_outgoing.js (Teil der http -Bibliothek des Node-Kerns) zu write :
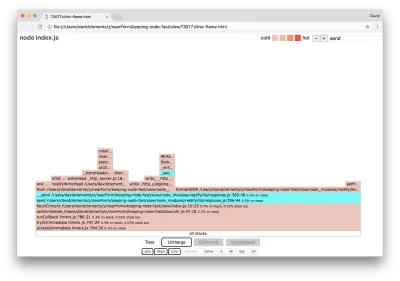
Wir können auf alle Stapel klicken, um zur Hauptansicht zurückzukehren.
Der entscheidende Punkt hierbei ist, dass sich die server.on Funktion zwar nicht im selben Tick befindet wie der eigentliche Code zur Anforderungsbehandlung, aber dennoch die Gesamtleistung des Servers beeinflusst, indem sie die Ausführung von ansonsten performantem Code verzögert.
Debuggen
Wir wissen aus dem Flammendiagramm, dass die problematische Funktion der Event-Handler ist, der in der Datei util.js an server.on übergeben wird.
Lass uns einen Blick darauf werfen:
server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) Es ist bekannt, dass Kryptographie teuer ist, ebenso wie die Serialisierung ( JSON.stringify ), aber warum erscheinen sie nicht im Flammendiagramm? Diese Operationen befinden sich in den erfassten Samples, sind aber hinter dem cpp -Filter verborgen. Wenn wir die cpp -Taste drücken, sollten wir so etwas wie das Folgende sehen:
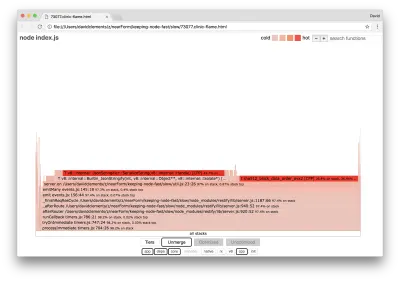
Die internen V8-Anweisungen, die sich sowohl auf die Serialisierung als auch auf die Kryptographie beziehen, werden jetzt als die heißesten Stapel angezeigt und nehmen die meiste Zeit in Anspruch. Die JSON.stringify Methode ruft C++-Code direkt auf; Aus diesem Grund sehen wir keine JavaScript-Funktion. Im Fall der Kryptografie befinden sich Funktionen wie createHash und update in den Daten, aber sie sind entweder eingebettet (was bedeutet, dass sie in der zusammengeführten Ansicht verschwinden) oder zu klein zum Rendern.
Sobald wir anfangen, über den Code in der etagger Funktion nachzudenken, kann schnell klar werden, dass er schlecht entworfen ist. Warum nehmen wir die server aus dem Funktionskontext? Es wird viel gehasht, ist das alles nötig? Es gibt auch keine If-None-Match Header-Unterstützung in der Implementierung, die einen Teil der Last in einigen realen Szenarien verringern würde, da Clients nur eine Head-Anfrage stellen würden, um die Aktualität zu bestimmen.
Lassen Sie uns all diese Punkte für den Moment ignorieren und die Feststellung validieren, dass die eigentliche Arbeit, die in server.on wird, tatsächlich der Engpass ist. Dies kann erreicht werden, indem der server.on -Code auf eine leere Funktion gesetzt und ein neues Flammendiagramm generiert wird.
Ändern Sie die etagger Funktion wie folgt:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } } Die an server.on übergebene Ereignis-Listener-Funktion ist jetzt ein no-op.
Lassen Sie uns die clinic flame noch einmal laufen lassen:
clinic flame --on-port='autocannon -c100 localhost:$PORT/seed/v1' -- node index.jsDies sollte ein Flammendiagramm ähnlich dem folgenden erzeugen:
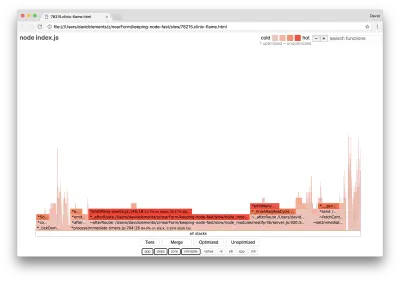
Das sieht besser aus, und wir hätten eine Zunahme der Anfragen pro Sekunde bemerken müssen. Aber warum ist der Code, der das Ereignis aussendet, so heiß? Wir würden an dieser Stelle davon ausgehen, dass der HTTP-Verarbeitungscode den größten Teil der CPU-Zeit beansprucht, da im server.on Ereignis überhaupt nichts ausgeführt wird.
Diese Art von Engpass wird dadurch verursacht, dass eine Funktion häufiger ausgeführt wird, als sie sollte.
Der folgende verdächtige Code oben in util.js könnte ein Hinweis sein:
require('events').defaultMaxListeners = Infinity Lassen Sie uns diese Zeile entfernen und unseren Prozess mit dem --trace-warnings starten:
node --trace-warnings index.jsWenn wir mit AutoCannon in einem anderen Terminal profilieren, etwa so:
autocannon -c100 localhost:3000/seed/v1Unser Prozess wird etwas Ähnliches ausgeben wie:
(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)(node:96371) MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 after listeners added. Use emitter.setMaxListeners() to increase limit at _addListener (events.js:280:19) at Server.addListener (events.js:297:10) at attachAfterEvent (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:22:14) at Server. (/Users/davidclements/z/nearForm/keeping-node-fast/slow/util.js:25:7) at call (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:164:9) at next (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:120:9) at Chain.run (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/chain.js:123:5) at Server._runUse (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:976:19) at Server._runRoute (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:918:10) at Server._afterPre (/Users/davidclements/z/nearForm/keeping-node-fast/slow/node_modules/restify/lib/server.js:888:10)
Node teilt uns mit, dass viele Ereignisse an das Serverobjekt angehängt werden. Das ist seltsam, weil es einen booleschen Wert gibt, der prüft, ob das Ereignis angehängt wurde, und dann früh zurückkehrt, was im Wesentlichen dazu führt, dass attachmentAfterEvent ein No-Op ist, nachdem das erste Ereignis angehängt wurde.
Schauen wir uns die Funktion attachAfterEvent " an:
var afterEventAttached = false function attachAfterEvent (server) { if (attachAfterEvent === true) return afterEventAttached = true server.on('after', (req, res) => {}) } Die Bedingungsprüfung ist falsch! Es prüft, ob attachAfterEvent wahr ist und nicht afterEventAttached . Das bedeutet, dass bei jeder Anfrage ein neues Ereignis an die server angehängt wird und dann alle zuvor angefügten Ereignisse nach jeder Anfrage ausgelöst werden. Hoppla!
Optimierung
Nachdem wir nun die Problembereiche entdeckt haben, wollen wir sehen, ob wir den Server schneller machen können.
Niedrig hängende Frucht
Lassen Sie uns den Listener-Code server.on (anstelle einer leeren Funktion) und den korrekten booleschen Namen in der bedingten Prüfung verwenden. Unsere etagger Funktion sieht wie folgt aus:
function etagger () { var cache = {} var afterEventAttached = false function attachAfterEvent (server) { if (afterEventAttached === true) return afterEventAttached = true server.on('after', (req, res) => { if (res.statusCode !== 200) return if (!res._body) return const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') const etag = crypto.createHash('sha512') .update(JSON.stringify(res._body)) .digest() .toString('hex') if (cache[key] !== etag) cache[key] = etag }) } return function (req, res, next) { attachAfterEvent(this) const key = crypto.createHash('sha512') .update(req.url) .digest() .toString('hex') if (key in cache) res.set('Etag', cache[key]) res.set('Cache-Control', 'public, max-age=120') next() } }Jetzt überprüfen wir unseren Fix, indem wir erneut ein Profil erstellen. Starten Sie den Server in einem Terminal:
node index.jsDann Profil mit AutoCannon:
autocannon -c100 localhost:3000/seed/v1 Wir sollten Ergebnisse irgendwo im Bereich einer 200-fachen Verbesserung sehen (Running 10s test @ https://localhost:3000/seed/v1 – 100 Verbindungen):
| Stat | Durchschn | Stdabw | max |
|---|---|---|---|
| Latenz (ms) | 19.47 | 4.29 | 103 |
| Anf./Sek | 5011.11 | 506.2 | 5487 |
| Bytes/Sek | 51,8 MB | 5,45 MB | 58,72 MB |
Es ist wichtig, potenzielle Serverkostensenkungen mit Entwicklungskosten abzuwägen. Wir müssen in unseren eigenen situativen Kontexten definieren, wie weit wir bei der Optimierung eines Projekts gehen müssen. Andernfalls kann es allzu leicht werden, 80 % der Mühe in 20 % der Geschwindigkeitsverbesserungen zu stecken. Rechtfertigen die Einschränkungen des Projekts dies?
In manchen Szenarien könnte es angemessen sein, eine 200-fache Verbesserung mit einer niedrig hängenden Frucht zu erreichen und es einen Tag zu nennen. In anderen möchten wir unsere Implementierung vielleicht so schnell wie möglich machen. Es hängt wirklich von den Projektprioritäten ab.
Eine Möglichkeit, die Ressourcenausgaben zu kontrollieren, besteht darin, sich ein Ziel zu setzen. Zum Beispiel 10-fache Verbesserung oder 4000 Anfragen pro Sekunde. Es ist am sinnvollsten, dies an den geschäftlichen Anforderungen auszurichten. Wenn die Serverkosten beispielsweise 100 % über dem Budget liegen, können wir uns das Ziel einer zweifachen Verbesserung setzen.
Es weiter bringen
Wenn wir ein neues Flame-Diagramm unseres Servers erstellen, sollten wir etwas Ähnliches wie das Folgende sehen:
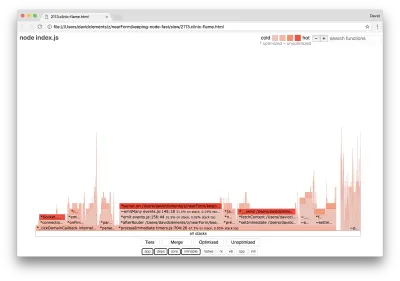
Der Ereignis-Listener ist immer noch der Engpass, er nimmt während der Profilerstellung immer noch ein Drittel der CPU-Zeit in Anspruch (die Breite beträgt etwa ein Drittel des gesamten Diagramms).
Welche zusätzlichen Gewinne können erzielt werden, und sind die Änderungen (zusammen mit den damit verbundenen Störungen) lohnenswert?
Mit einer optimierten Implementierung, die jedoch etwas eingeschränkter ist, können die folgenden Leistungsmerkmale erreicht werden (Laufender 10s-Test @ https://localhost:3000/seed/v1 — 10 Verbindungen):
| Stat | Durchschn | Stdabw | max |
|---|---|---|---|
| Latenz (ms) | 0,64 | 0,86 | 17 |
| Anf./Sek | 8330.91 | 757.63 | 8991 |
| Bytes/Sek | 84,17 MB | 7,64 MB | 92,27 MB |
Während eine 1,6-fache Verbesserung signifikant ist, hängt es von der Situation ab, ob der Aufwand, die Änderungen und die Codeunterbrechung, die erforderlich sind, um diese Verbesserung zu erzielen, gerechtfertigt sind. Besonders im Vergleich zur 200-fachen Verbesserung der ursprünglichen Implementierung mit einer einzigen Fehlerbehebung.
Um diese Verbesserung zu erreichen, wurde dieselbe iterative Technik von Profilierung, Flamegraph-Erzeugung, Analyse, Debugging und Optimierung verwendet, um zum endgültigen optimierten Server zu gelangen, dessen Code hier zu finden ist.
Die letzten Änderungen, um 8000 Anforderungen/s zu erreichen, waren:
- Erstellen Sie keine Objekte und serialisieren Sie sie dann, sondern erstellen Sie direkt eine JSON-Zeichenfolge.
- Verwenden Sie etwas Einzigartiges über den Inhalt, um seinen Etag zu definieren, anstatt einen Hash zu erstellen;
- Hashen Sie die URL nicht, verwenden Sie sie direkt als Schlüssel.
Diese Änderungen sind etwas komplizierter, stören die Codebasis etwas mehr und lassen die etagger Middleware etwas weniger flexibel, da sie die Route zur Bereitstellung des Etag Werts belasten. Aber es erreicht zusätzliche 3000 Anfragen pro Sekunde auf der Profiling-Maschine.
Werfen wir einen Blick auf ein Flammendiagramm für diese letzten Verbesserungen:
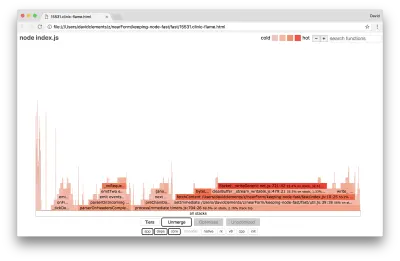
Der heißeste Teil des Flammendiagramms ist Teil des Node-Kerns im net . Das ist optimal.
Leistungsproblemen vorbeugen
Abschließend finden Sie hier einige Vorschläge zur Vermeidung von Leistungsproblemen, bevor sie bereitgestellt werden.
Durch die Verwendung von Leistungstools als informelle Prüfpunkte während der Entwicklung können Leistungsfehler herausgefiltert werden, bevor sie in die Produktion gelangen. Es wird empfohlen, AutoCannon und Clinic (oder Äquivalente) zu einem Teil der täglichen Entwicklungswerkzeuge zu machen.
Informieren Sie sich beim Kauf eines Frameworks über dessen Leistungsrichtlinie. Wenn das Framework die Leistung nicht priorisiert, ist es wichtig zu prüfen, ob dies mit den infrastrukturellen Praktiken und Geschäftszielen übereinstimmt. Zum Beispiel hat Restify (seit der Veröffentlichung von Version 7) eindeutig in die Verbesserung der Leistung der Bibliothek investiert. Wenn niedrige Kosten und hohe Geschwindigkeit jedoch absolute Priorität haben, ziehen Sie Fastify in Betracht, das von einem Restify-Mitarbeiter als 17 % schneller gemessen wurde.
Achten Sie auf andere Bibliotheksoptionen mit weitreichenden Auswirkungen – ziehen Sie insbesondere die Protokollierung in Betracht. Wenn Entwickler Probleme beheben, können sie entscheiden, zusätzliche Protokollausgaben hinzuzufügen, um in Zukunft beim Debuggen verwandter Probleme zu helfen. Wenn ein leistungsschwacher Logger verwendet wird, kann dies die Leistung im Laufe der Zeit nach Art der Siedefrosch-Fabel ersticken. Der Pino-Logger ist der schnellste JSON-Logger mit Zeilenumbrüchen, der für Node.js verfügbar ist.
Denken Sie schließlich immer daran, dass die Ereignisschleife eine gemeinsam genutzte Ressource ist. Ein Node.js-Server wird letztendlich durch die langsamste Logik auf dem heißesten Pfad eingeschränkt.