
Erste Schritte mit Node: Eine Einführung in APIs, HTTP und ES6+ JavaScript
Veröffentlicht: 2022-03-10Sie haben wahrscheinlich schon von Node.js als einer „asynchronen JavaScript-Laufzeitumgebung gehört, die auf der V8-JavaScript-Engine von Chrome basiert“ und dass es „ein ereignisgesteuertes, nicht blockierendes I/O-Modell verwendet, das es leicht und effizient macht“. Aber für einige ist das nicht die beste Erklärung.
Was ist Node überhaupt? Was genau bedeutet es, dass Node „asynchron“ ist, und wie unterscheidet sich das von „synchron“? Was bedeutet überhaupt „ereignisgesteuert“ und „nicht blockierend“ und wie passt Node in das Gesamtbild von Anwendungen, Internetnetzwerken und Servern?
Wir werden versuchen, all diese Fragen und mehr in dieser Serie zu beantworten, während wir uns eingehend mit dem Innenleben von Node befassen, etwas über das HyperText-Übertragungsprotokoll, APIs und JSON erfahren und unsere eigene Bookshelf-API verwenden MongoDB, Express, Lodash, Mokka und Lenker.
Was ist Node.js
Node ist nur eine Umgebung oder Laufzeit, in der normales JavaScript (mit geringfügigen Unterschieden) außerhalb des Browsers ausgeführt wird. Wir können damit Desktop-Anwendungen erstellen (mit Frameworks wie Electron), Web- oder App-Server schreiben und vieles mehr.
Blockierend/nicht blockierend und synchron/asynchron
Angenommen, wir führen einen Datenbankaufruf durch, um Eigenschaften über einen Benutzer abzurufen. Dieser Aufruf wird einige Zeit in Anspruch nehmen, und wenn die Anfrage „blockiert“, bedeutet dies, dass sie die Ausführung unseres Programms blockiert, bis der Aufruf abgeschlossen ist. In diesem Fall haben wir eine „synchrone“ Anfrage gestellt, da sie den Thread blockiert hat.
Eine synchrone Operation blockiert also einen Prozess oder Thread, bis diese Operation abgeschlossen ist, und lässt den Thread in einem „Wartezustand“. Eine asynchrone Operation hingegen ist nicht blockierend . Es ermöglicht, dass die Ausführung des Threads fortgesetzt wird, unabhängig von der Zeit, die für den Abschluss der Operation benötigt wird, oder dem Ergebnis, mit dem sie abgeschlossen wird, und kein Teil des Threads fällt zu irgendeinem Zeitpunkt in einen Wartezustand.
Sehen wir uns ein weiteres Beispiel für einen synchronen Aufruf an, der einen Thread blockiert . Angenommen, wir erstellen eine Anwendung, die die Ergebnisse zweier Wetter-APIs vergleicht, um ihren prozentualen Temperaturunterschied zu ermitteln. Blockierend rufen wir Weather API One auf und warten auf das Ergebnis. Sobald wir ein Ergebnis erhalten, rufen wir Weather API Two auf und warten auf das Ergebnis. Machen Sie sich an dieser Stelle keine Sorgen, wenn Sie mit APIs nicht vertraut sind. Wir werden sie in einem der nächsten Abschnitte behandeln. Stellen Sie sich eine API vorerst einfach als das Medium vor, über das zwei Computer miteinander kommunizieren können.
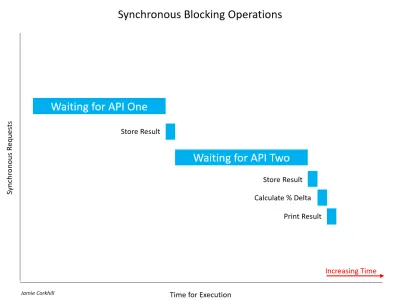
Lassen Sie mich anmerken, dass es wichtig ist zu erkennen, dass nicht alle synchronen Aufrufe notwendigerweise blockieren. Wenn ein synchroner Vorgang abgeschlossen werden kann, ohne den Thread zu blockieren oder einen Wartezustand zu verursachen, war er nicht blockierend. Meistens werden synchrone Aufrufe blockiert, und die Zeit, die sie benötigen, hängt von einer Vielzahl von Faktoren ab, wie z. B. der Geschwindigkeit der API-Server, der Download-Geschwindigkeit der Internetverbindung des Endbenutzers usw.
Im Fall des obigen Bildes mussten wir eine ganze Weile warten, um die ersten Ergebnisse von API One abzurufen. Danach mussten wir genauso lange auf eine Antwort von API Two warten. Während er auf beide Antworten wartet, bemerkt der Benutzer, dass unsere Anwendung hängen bleibt – die Benutzeroberfläche würde buchstäblich abstürzen – und das wäre schlecht für die Benutzererfahrung.
Im Falle eines nicht blockierenden Anrufs hätten wir so etwas:

Sie können deutlich sehen, wie viel schneller wir die Ausführung abgeschlossen haben. Anstatt auf API Eins und dann auf API Zwei zu warten, könnten wir warten, bis beide gleichzeitig abgeschlossen sind, und unsere Ergebnisse fast 50 % schneller erzielen. Beachten Sie, dass wir, nachdem wir API Eins aufgerufen und auf seine Antwort gewartet hatten, auch API Zwei aufgerufen und zur gleichen Zeit wie Eins auf seine Antwort gewartet hatten.
An dieser Stelle, bevor wir zu konkreteren und greifbaren Beispielen übergehen, ist es wichtig zu erwähnen, dass der Begriff „Synchronous“ der Einfachheit halber im Allgemeinen zu „Sync“ abgekürzt wird und der Begriff „Asynchronous“ im Allgemeinen zu „Async“ abgekürzt wird. Sie werden diese Notation in Methoden-/Funktionsnamen sehen.
Callback-Funktionen
Sie fragen sich vielleicht: „Wenn wir einen Anruf asynchron bearbeiten können, woher wissen wir, wann dieser Anruf beendet ist und wir eine Antwort haben?“ Im Allgemeinen übergeben wir unserer asynchronen Methode eine Callback-Funktion als Argument, und diese Methode wird diese Funktion zu einem späteren Zeitpunkt mit einer Antwort „zurückrufen“. Ich verwende hier ES5-Funktionen, aber wir werden später auf ES6-Standards aktualisieren.
function asyncAddFunction(a, b, callback) { callback(a + b); //This callback is the one passed in to the function call below. } asyncAddFunction(2, 4, function(sum) { //Here we have the sum, 2 + 4 = 6. }); Eine solche Funktion wird als „Higher-Order Function“ bezeichnet, da sie eine Funktion (unser Callback) als Argument verwendet. Alternativ könnte eine Callback-Funktion ein Fehlerobjekt und ein Antwortobjekt als Argumente annehmen und sie präsentieren, wenn die asynchrone Funktion abgeschlossen ist. Wir werden dies später mit Express sehen. Als wir asyncAddFunction(...) aufgerufen haben, werden Sie feststellen, dass wir eine Rückruffunktion für den Rückrufparameter aus der Methodendefinition bereitgestellt haben. Diese Funktion ist eine anonyme Funktion (sie hat keinen Namen) und wird mit der Ausdruckssyntax geschrieben. Die Methodendefinition hingegen ist eine Funktionsanweisung. Es ist nicht anonym, da es tatsächlich einen Namen hat (das heißt „asyncAddFunction“).
Einige mögen Verwirrung feststellen, da wir in der Methodendefinition einen Namen angeben, nämlich „Callback“. Die anonyme Funktion, die als dritter Parameter an asyncAddFunction(...) wird, weiß jedoch nichts über den Namen und bleibt daher anonym. Wir können diese Funktion auch nicht zu einem späteren Zeitpunkt namentlich ausführen, wir müssten die asynchrone Aufruffunktion erneut durchlaufen, um sie auszulösen.
Als Beispiel für einen synchronen Aufruf können wir die readFileSync(...) Methode von Node.js verwenden. Auch hier werden wir später zu ES6+ wechseln.
var fs = require('fs'); var data = fs.readFileSync('/example.txt'); // The thread will be blocked here until complete.Wenn wir dies asynchron tun würden, würden wir eine Rückruffunktion übergeben, die ausgelöst wird, wenn der asynchrone Vorgang abgeschlossen ist.
var fs = require('fs'); var data = fs.readFile('/example.txt', function(err, data) { //Move on, this will fire when ready. if(err) return console.log('Error: ', err); console.log('Data: ', data); // Assume var data is defined above. }); // Keep executing below, don't wait on the data. Wenn Sie noch nie gesehen haben, dass return auf diese Weise verwendet wird, sagen wir nur, dass Sie die Ausführung der Funktion stoppen sollen, damit wir das Datenobjekt nicht drucken, wenn das Fehlerobjekt definiert ist. Wir hätten die log-Anweisung auch einfach in eine else -Klausel packen können.
Wie bei unserer asyncAddFunction(...) würde der Code hinter der Funktion fs.readFile(...) so aussehen:
function readFile(path, callback) { // Behind the scenes code to read a file stream. // The data variable is defined up here. callback(undefined, data); //Or, callback(err, undefined); }Erlauben Sie uns einen Blick auf eine letzte Implementierung eines asynchronen Funktionsaufrufs. Dies wird dazu beitragen, die Idee zu festigen, dass Callback-Funktionen zu einem späteren Zeitpunkt ausgelöst werden, und es wird uns helfen, die Ausführung eines typischen Node.js-Programms zu verstehen.
setTimeout(function() { // ... }, 1000); Die Methode setTimeout(...) nimmt eine Callback-Funktion für den ersten Parameter, die ausgelöst wird, nachdem die als zweites Argument angegebene Anzahl von Millisekunden aufgetreten ist.
Schauen wir uns ein komplexeres Beispiel an:
console.log('Initiated program.'); setTimeout(function() { console.log('3000 ms (3 sec) have passed.'); }, 3000); setTimeout(function() { console.log('0 ms (0 sec) have passed.'); }, 0); setTimeout(function() { console.log('1000 ms (1 sec) has passed.'); }, 1000); console.log('Terminated program');Die Ausgabe, die wir erhalten, ist:
Initiated program. Terminated program. 0 ms (0 sec) have passed. 1000 ms (1 sec) has passed. 3000 ms (3 sec) have passed. Sie können sehen, dass die erste Protokollanweisung wie erwartet ausgeführt wird. Sofort wird die letzte Protokollanweisung auf dem Bildschirm ausgegeben, da dies geschieht, bevor 0 Sekunden nach dem zweiten setTimeout(...) überschritten wurden. Unmittelbar danach werden die zweite, dritte und erste setTimeout(...) Methode ausgeführt.
Wenn Node.js nicht nicht blockierend wäre, würden wir die erste Protokollanweisung sehen, 3 Sekunden warten, um die nächste zu sehen, sofort die dritte sehen (das 0-Sekunden- setTimeout(...) und dann noch eine warten müssen Sekunden, um die letzten beiden Protokollanweisungen zu sehen. Die nicht blockierende Natur von Node bewirkt, dass alle Timer ab dem Moment der Programmausführung herunterzählen, und nicht in der Reihenfolge, in der sie eingegeben werden. Vielleicht möchten Sie sich die Node-APIs ansehen, die Callstack und Event Loop für weitere Informationen darüber, wie Node unter der Haube funktioniert.
Es ist wichtig zu beachten, dass nur weil Sie eine Callback-Funktion sehen, nicht unbedingt bedeutet, dass es einen asynchronen Aufruf im Code gibt. Wir haben die asyncAddFunction(…) -Methode oben „async“ genannt, weil wir davon ausgehen, dass der Vorgang Zeit braucht, um abgeschlossen zu werden – wie z. B. das Tätigen eines Anrufs bei einem Server. In Wirklichkeit ist das Hinzufügen von zwei Zahlen nicht asynchron, und das wäre tatsächlich ein Beispiel für die Verwendung einer Rückruffunktion auf eine Weise, die den Thread nicht tatsächlich blockiert.
Versprechen über Rückrufe
Callbacks können in JavaScript schnell chaotisch werden, insbesondere mehrfach verschachtelte Callbacks. Wir sind damit vertraut, einen Callback als Argument an eine Funktion zu übergeben, aber Promises ermöglichen es uns, einen Callback an ein von einer Funktion zurückgegebenes Objekt anzuheften oder anzuhängen. Dies würde es uns ermöglichen, mehrere asynchrone Aufrufe eleganter zu handhaben.
Nehmen wir als Beispiel an, wir führen einen API-Aufruf durch und unsere Funktion mit dem nicht so eindeutigen Namen ' makeAPICall(...) ' nimmt eine URL und einen Rückruf entgegen.
Unsere Funktion makeAPICall(...) wäre definiert als
function makeAPICall(path, callback) { // Attempt to make API call to path argument. // ... callback(undefined, res); // Or, callback(err, undefined); depending upon the API's response. }und wir würden es nennen mit:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); // ... }); Wenn wir einen weiteren API-Aufruf mit der Antwort des ersten durchführen wollten, müssten wir beide Callbacks verschachteln. Angenommen, ich muss die userName Eigenschaft aus dem res1 Objekt in den Pfad des zweiten API-Aufrufs einfügen. Wir würden haben:
makeAPICall('/example', function(err1, res1) { if(err1) return console.log('Error: ', err1); makeAPICall('/newExample/' + res1.userName, function(err2, res2) { if(err2) return console.log('Error: ', err2); console.log(res2); }); }); Hinweis : Die ES6+-Methode zum Einfügen der res1.userName Eigenschaft anstelle der Zeichenfolgenverkettung wäre die Verwendung von „Template Strings“. Auf diese Weise würden wir, anstatt unsere Zeichenfolge in Anführungszeichen ( ' , oder " ) einzuschließen, Backticks ( ` ) verwenden, die sich unter der Escape-Taste auf Ihrer Tastatur befinden. Dann würden wir die Notation ${} verwenden, um einen beliebigen JS-Ausdruck darin einzubetten Am Ende wäre unser früherer Pfad: /newExample/${res.UserName} , eingeschlossen in Backticks.
Es ist klar, dass diese Methode der Verschachtelung von Callbacks schnell recht unelegant werden kann, die sogenannte „JavaScript Pyramid of Doom“. Wenn wir Versprechungen anstelle von Rückrufen verwenden würden, könnten wir unseren Code aus dem ersten Beispiel wie folgt umgestalten:
makeAPICall('/example').then(function(res) { // Success callback. // ... }, function(err) { // Failure callback. console.log('Error:', err); }); Das erste Argument der Funktion then() ist unser Erfolgs-Callback und das zweite Argument ist unser Fehler-Callback. Alternativ könnten wir das zweite Argument an .then() verlieren und stattdessen .catch() () aufrufen. Argumente für .then() sind optional, und der Aufruf .catch() wäre äquivalent zu .then(successCallback, null) .
Mit .catch() haben wir:
makeAPICall('/example').then(function(res) { // Success callback. // ... }).catch(function(err) { // Failure Callback console.log('Error: ', err); });Wir können dies auch für die Lesbarkeit umstrukturieren:
makeAPICall('/example') .then(function(res) { // ... }) .catch(function(err) { console.log('Error: ', err); }); Es ist wichtig zu beachten, dass wir nicht einfach einen .then() Aufruf an eine beliebige Funktion anhängen und erwarten können, dass sie funktioniert. Die Funktion, die wir aufrufen, muss tatsächlich ein Versprechen zurückgeben, ein Versprechen, das .then() , wenn diese asynchrone Operation abgeschlossen ist. In diesem Fall makeAPICall(...) seine Aufgabe, indem es entweder den then() -Block oder den catch() -Block auslöst, wenn es fertig ist.
Damit makeAPICall(...) ein Promise zurückgibt, weisen wir einer Variablen eine Funktion zu, wobei diese Funktion der Promise-Konstruktor ist. Versprechen können entweder erfüllt oder abgelehnt werden, wobei erfüllt bedeutet, dass die Aktion in Bezug auf das Versprechen erfolgreich abgeschlossen wurde, und abgelehnt bedeutet das Gegenteil. Sobald das Versprechen entweder erfüllt oder abgelehnt wurde, sagen wir, dass es sich erledigt hat, und während wir darauf warten, dass es sich erledigt, vielleicht während eines asynchronen Anrufs, sagen wir, dass das Versprechen aussteht .
Der Promise-Konstruktor übernimmt eine Callback-Funktion als Argument, die zwei Parameter erhält – resolve und reject , die wir zu einem späteren Zeitpunkt aufrufen werden, um entweder den Erfolgs-Callback in .then() oder den .then() Fehler auszulösen Callback oder .catch() , falls vorhanden.
Hier ist ein Beispiel, wie das aussieht:
var examplePromise = new Promise(function(resolve, reject) { // Do whatever we are going to do and then make the appropiate call below: resolve('Happy!'); // — Everything worked. reject('Sad!'); // — We noticed that something went wrong. }):Dann können wir verwenden:
examplePromise.then(/* Both callback functions in here */); // Or, the success callback in .then() and the failure callback in .catch(). Beachten Sie jedoch, dass examplePromise keine Argumente entgegennehmen kann. Das verfehlt den Zweck, also können wir stattdessen ein Versprechen zurückgeben.
function makeAPICall(path) { return new Promise(function(resolve, reject) { // Make our async API call here. if (/* All is good */) return resolve(res); //res is the response, would be defined above. else return reject(err); //err is error, would be defined above. }); } Promises glänzen wirklich, um die Struktur und damit die Eleganz unseres Codes mit dem Konzept des „Promise Chaining“ zu verbessern. Dies würde es uns ermöglichen, ein neues Promise innerhalb einer .then() -Klausel zurückzugeben, sodass wir danach ein zweites .then() anhängen könnten, das den entsprechenden Callback aus dem zweiten Promise auslösen würde.
Wenn wir unseren Multi-API-URL-Aufruf oben mit Promises umgestalten, erhalten wir:
makeAPICall('/example').then(function(res) { // First response callback. Fires on success to '/example' call. return makeAPICall(`/newExample/${res.UserName}`); // Returning new call allows for Promise Chaining. }, function(err) { // First failure callback. Fires if there is a failure calling with '/example'. console.log('Error:', err); }).then(function(res) { // Second response callback. Fires on success to returned '/newExample/...' call. console.log(res); }, function(err) { // Second failure callback. Fire if there is a failure calling with '/newExample/...' console.log('Error:', err); }); Beachten Sie, dass wir zuerst makeAPICall('/example') aufrufen. Das gibt ein Versprechen zurück, und so hängen wir ein .then() an. Innerhalb von then() geben wir einen neuen Aufruf an makeAPICall(...) zurück, der an und für sich, wie zuvor gesehen, ein Versprechen zurückgibt, das es uns ermöglicht, ein neues .then() nach dem ersten zu verketten.
Wie oben können wir dies für die Lesbarkeit umstrukturieren und die Fehler-Callbacks für eine generische catch() all-Klausel entfernen. Dann können wir dem DRY-Prinzip (Don't Repeat Yourself) folgen und müssen die Fehlerbehandlung nur einmal implementieren.
makeAPICall('/example') .then(function(res) { // Like earlier, fires with success and response from '/example'. return makeAPICall(`/newExample/${res.UserName}`); // Returning here lets us chain on a new .then(). }) .then(function(res) { // Like earlier, fires with success and response from '/newExample'. console.log(res); }) .catch(function(err) { // Generic catch all method. Fires if there is an err with either earlier call. console.log('Error: ', err); }); Beachten Sie, dass die Erfolgs- und Fehlerrückrufe in .then() nur für den Status des einzelnen Promise ausgelöst werden, dem .then() entspricht. Der catch -Block fängt jedoch alle Fehler ab, die in einem der .then() s ausgelöst werden.
ES6 Const vs. Let
In all unseren Beispielen haben wir ES5-Funktionen und das alte Schlüsselwort var verwendet. Auch wenn heute noch Millionen von Codezeilen mit diesen ES5-Methoden ausgeführt werden, ist es sinnvoll, auf aktuelle ES6+-Standards zu aktualisieren, und wir werden einen Teil unseres obigen Codes umgestalten. Beginnen wir mit const und let .
Möglicherweise sind Sie daran gewöhnt, eine Variable mit dem Schlüsselwort var zu deklarieren:
var pi = 3.14;Mit ES6+ Standards könnten wir das auch machen
let pi = 3.14;oder
const pi = 3.14; wobei const „Konstante“ bedeutet – ein Wert, der später nicht mehr neu zugewiesen werden kann. (Außer Objekteigenschaften – darauf kommen wir gleich noch zu sprechen. Außerdem sind als const deklarierte Variablen nicht unveränderlich, sondern nur die Referenz auf die Variable.)
Blockieren Sie in altem JavaScript Bereiche wie die in if , while , {} . for usw. hat var in keiner Weise beeinflusst, und das ist ganz anders als bei eher statisch typisierten Sprachen wie Java oder C++. Das heißt, der Gültigkeitsbereich von var ist die gesamte einschließende Funktion – und das kann global sein (wenn sie außerhalb einer Funktion platziert wird) oder lokal (wenn sie innerhalb einer Funktion platziert wird). Um dies zu demonstrieren, sehen Sie sich das folgende Beispiel an:
function myFunction() { var num = 5; console.log(num); // 5 console.log('--'); for(var i = 0; i < 10; i++) { var num = i; console.log(num); //num becomes 0 — 9 } console.log('--'); console.log(num); // 9 console.log(i); // 10 } myFunction();Ausgabe:
5 --- 0 1 2 3 ... 7 8 9 --- 9 10 Das Wichtige, was hier zu beachten ist, ist, dass das Definieren einer neuen var num innerhalb des for -Bereichs direkt die var num außerhalb und oberhalb von for beeinflusst. Dies liegt daran, dass der Geltungsbereich von var immer der der einschließenden Funktion und nicht eines Blocks ist.
Auch hier ist var i innerhalb for() standardmäßig auf den Gültigkeitsbereich von myFunction , sodass wir außerhalb der Schleife auf i zugreifen und 10 erhalten können.
In Bezug auf die Zuweisung von Werten zu Variablen ist let äquivalent zu var , es ist nur so, dass let einen Blockbereich hat, und daher werden die Anomalien, die mit var oben aufgetreten sind, nicht auftreten.
function myFunction() { let num = 5; console.log(num); // 5 for(let i = 0; i < 10; i++) { let num = i; console.log('--'); console.log(num); // num becomes 0 — 9 } console.log('--'); console.log(num); // 5 console.log(i); // undefined, ReferenceError } Wenn Sie sich das Schlüsselwort const ansehen, können Sie sehen, dass wir einen Fehler erhalten, wenn wir versuchen, es neu zuzuweisen:
const c = 299792458; // Fact: The constant "c" is the speed of light in a vacuum in meters per second. c = 10; // TypeError: Assignment to constant variable. Interessant wird es, wenn wir einem Objekt eine const Variable zuweisen:
const myObject = { name: 'Jane Doe' }; // This is illegal: TypeError: Assignment to constant variable. myObject = { name: 'John Doe' }; // This is legal. console.log(myObject.name) -> John Doe myObject.name = 'John Doe'; Wie Sie sehen können, ist nur die Referenz im Speicher auf das Objekt, das einem const Objekt zugewiesen ist, unveränderlich, nicht der Wert selbst.
ES6 Pfeilfunktionen
Möglicherweise sind Sie es gewohnt, eine Funktion wie diese zu erstellen:
function printHelloWorld() { console.log('Hello, World!'); }Mit Pfeilfunktionen würde das werden:
const printHelloWorld = () => { console.log('Hello, World!'); };Angenommen, wir haben eine einfache Funktion, die das Quadrat einer Zahl zurückgibt:
const squareNumber = (x) => { return x * x; } squareNumber(5); // We can call an arrow function like an ES5 functions. Returns 25.Sie können sehen, dass wir, genau wie bei ES5-Funktionen, Argumente mit Klammern aufnehmen, normale Rückgabeanweisungen verwenden und die Funktion wie jede andere aufrufen können.
Es ist wichtig zu beachten, dass Klammern zwar erforderlich sind, wenn unsere Funktion keine Argumente akzeptiert (wie bei printHelloWorld() oben), wir die Klammern jedoch fallen lassen können, wenn sie nur eines akzeptiert, sodass unsere frühere squareNumber() Methodendefinition wie folgt umgeschrieben werden kann:
const squareNumber = x => { // Notice we have dropped the parentheses for we only take in one argument. return x * x; }Ob Sie sich dafür entscheiden, ein einzelnes Argument in Klammern zu setzen oder nicht, ist eine Frage des persönlichen Geschmacks, und Sie werden wahrscheinlich sehen, dass Entwickler beide Methoden verwenden.
Wenn wir schließlich nur einen Ausdruck implizit zurückgeben wollen, wie bei squareNumber(...) oben, können wir die return-Anweisung mit der Methodensignatur in Einklang bringen:
const squareNumber = x => x * x;Das ist,
const test = (a, b, c) => expressionist das gleiche wie
const test = (a, b, c) => { return expression }Beachten Sie, dass die Dinge unklar werden, wenn Sie die obige Abkürzung verwenden, um ein Objekt implizit zurückzugeben. Was hindert JavaScript daran zu glauben, dass die Klammern, in die wir unser Objekt kapseln müssen, nicht unser Funktionskörper sind? Um dies zu umgehen, setzen wir die Klammern des Objekts in Klammern. Dies lässt JavaScript explizit wissen, dass wir tatsächlich ein Objekt zurückgeben und nicht nur einen Körper definieren.
const test = () => ({ pi: 3.14 }); // Spaces between brackets are a formality to make the code look cleaner.Um das Konzept der ES6-Funktionen zu festigen, werden wir einen Teil unseres früheren Codes umgestalten, sodass wir die Unterschiede zwischen beiden Notationen vergleichen können.
asyncAddFunction(...) von oben könnte umgestaltet werden von:
function asyncAddFunction(a, b, callback){ callback(a + b); }zu:
const aysncAddFunction = (a, b, callback) => { callback(a + b); };oder sogar zu:
const aysncAddFunction = (a, b, callback) => callback(a + b); // This will return callback(a + b).Beim Aufruf der Funktion könnten wir eine Pfeilfunktion für den Callback übergeben:
asyncAddFunction(10, 12, sum => { // No parentheses because we only take one argument. console.log(sum); }Es ist deutlich zu sehen, wie diese Methode die Lesbarkeit des Codes verbessert. Um Ihnen nur einen Fall zu zeigen, können wir unser altes ES5 Promise-basiertes Beispiel oben nehmen und es so umgestalten, dass Pfeilfunktionen verwendet werden.
makeAPICall('/example') .then(res => makeAPICall(`/newExample/${res.UserName}`)) .then(res => console.log(res)) .catch(err => console.log('Error: ', err)); Nun, es gibt einige Vorbehalte mit Pfeilfunktionen. Zum einen binden sie kein this -Schlüsselwort. Angenommen, ich habe das folgende Objekt:
const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Sie könnten erwarten, dass ein Aufruf von Person.greeting() „Hi. Mein Name ist John Doe.“ Stattdessen bekommen wir: „Hallo. Mein Name ist undefiniert.“ Das liegt daran, dass Pfeilfunktionen kein this haben, und daher wird beim Versuch, this innerhalb einer Pfeilfunktion zu verwenden, standardmäßig das this des einschließenden Bereichs verwendet, und der einschließende Bereich des Person -Objekts ist window , im Browser oder module.exports in Knoten.
Um dies zu beweisen, wenn wir dasselbe Objekt erneut verwenden, aber die name des globalen this auf etwas wie „Jane Doe“ setzen, dann this.name in der Pfeilfunktion „Jane Doe“ zurück, weil das globale this innerhalb von ist umschließenden Bereich oder ist das übergeordnete Objekt des Person Objekts.
this.name = 'Jane Doe'; const Person = { name: 'John Doe', greeting: () => { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting(); // Hi. My name is Jane DoeDies ist als "Lexical Scoping" bekannt, und wir können es umgehen, indem wir die sogenannte "Short Syntax" verwenden, bei der wir den Doppelpunkt und den Pfeil verlieren, um unser Objekt als solches umzugestalten:
const Person = { name: 'John Doe', greeting() { console.log(`Hi. My name is ${this.name}.`); } } Person.greeting() //Hi. My name is John Doe.ES6-Klassen
Während JavaScript Klassen nie unterstützte, könnten Sie sie immer mit Objekten wie den obigen emulieren. EcmaScript 6 bietet Unterstützung für Klassen, die die Schlüsselwörter class und new verwenden:
class Person { constructor(name) { this.name = name; } greeting() { console.log(`Hi. My name is ${this.name}.`); } } const person = new Person('John'); person.greeting(); // Hi. My name is John. Die Konstruktorfunktion wird automatisch aufgerufen, wenn das Schlüsselwort new verwendet wird, an das wir Argumente übergeben können, um das Objekt anfänglich einzurichten. Dies sollte jedem Leser bekannt sein, der Erfahrung mit eher statisch typisierten objektorientierten Programmiersprachen wie Java, C++ und C# hat.
Ohne zu sehr ins Detail auf OOP-Konzepte einzugehen, ist ein weiteres solches Paradigma die „Vererbung“, die es einer Klasse ermöglicht, von einer anderen zu erben. Eine Klasse namens Car ist beispielsweise sehr allgemein und enthält Methoden wie „stop“, „start“ usw., wie sie alle Autos brauchen. Eine Teilmenge der Klasse namens SportsCar könnte dann grundlegende Operationen von Car erben und alles überschreiben, was angepasst werden muss. Wir könnten eine solche Klasse wie folgt bezeichnen:
class Car { constructor(licensePlateNumber) { this.licensePlateNumber = licensePlateNumber; } start() {} stop() {} getLicensePlate() { return this.licensePlateNumber; } // … } class SportsCar extends Car { constructor(engineRevCount, licensePlateNumber) { super(licensePlateNumber); // Pass licensePlateNumber up to the parent class. this.engineRevCount = engineRevCount; } start() { super.start(); } stop() { super.stop(); } getLicensePlate() { return super.getLicensePlate(); } getEngineRevCount() { return this.engineRevCount; } } Sie können deutlich sehen, dass das Schlüsselwort super uns den Zugriff auf Eigenschaften und Methoden der übergeordneten oder übergeordneten Klasse ermöglicht.
JavaScript-Ereignisse
Ein Ereignis ist eine Aktion, auf die Sie reagieren können. Angenommen, Sie erstellen ein Anmeldeformular für Ihre Anwendung. Wenn der Benutzer auf die Schaltfläche „Senden“ klickt, können Sie auf dieses Ereignis über einen „Event-Handler“ in Ihrem Code reagieren – normalerweise eine Funktion. Wenn diese Funktion als Event-Handler definiert ist, sagen wir, dass wir „einen Event-Handler registrieren“. Der Ereignishandler für den Klick auf die Schaltfläche „Senden“ überprüft wahrscheinlich die Formatierung der vom Benutzer bereitgestellten Eingaben und bereinigt sie, um Angriffe wie SQL-Injektionen oder Cross-Site-Scripting zu verhindern (bitte beachten Sie, dass kein Code auf der Clientseite jemals berücksichtigt werden kann Daten auf dem Server immer bereinigen – niemals irgendetwas vom Browser vertrauen) und dann prüfen, ob diese Kombination aus Benutzername und Passwort in einer Datenbank vorhanden ist, um einen Benutzer zu authentifizieren und ihm ein Token bereitzustellen.
Da dies ein Artikel über Node ist, konzentrieren wir uns auf das Node-Ereignismodell.
Wir können das events von Node verwenden, um bestimmte Ereignisse auszugeben und darauf zu reagieren. Jedes Objekt, das ein Ereignis ausgibt, ist eine Instanz der EventEmitter -Klasse.
Wir können ein Ereignis ausgeben, indem wir die emit emit() -Methode aufrufen, und wir lauschen auf dieses Ereignis über die on() -Methode, die beide durch die EventEmitter -Klasse verfügbar gemacht werden.
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); Da myEmitter jetzt eine Instanz der EventEmitter -Klasse ist, können wir auf emit emit() und on() zugreifen:
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', () => { console.log('The "someEvent" event was fired (emitted)'); }); myEmitter.emit('someEvent'); // This will call the callback function above. Der zweite Parameter von myEmitter.on() ist die Rückruffunktion, die ausgelöst wird, wenn das Ereignis ausgegeben wird – dies ist der Ereignishandler. Der erste Parameter ist der Name des Ereignisses, der beliebig sein kann, obwohl die camelCase-Namenskonvention empfohlen wird.
Darüber hinaus kann der Ereignishandler eine beliebige Anzahl von Argumenten annehmen, die beim Ausgeben des Ereignisses weitergegeben werden:
const EventEmitter = require('events'); const myEmitter = new EventEmitter(); myEmitter.on('someEvent', (data) => { console.log(`The "someEvent" event was fired (emitted) with data: ${data}`); }); myEmitter.emit('someEvent', 'This is the data payload'); Durch die Verwendung von Vererbung können wir die Methoden emit emit() und on() von 'EventEmitter' für jede Klasse verfügbar machen. Dies geschieht durch Erstellen einer Node.js-Klasse und Verwenden des reservierten Schlüsselworts EventEmitter extends Eigenschaften zu erben:
const EventEmitter = require('events'); class MyEmitter extends EventEmitter { // This is my class. I can emit events from a MyEmitter object. } Angenommen, wir bauen ein Fahrzeugkollisionsmeldeprogramm, das Daten von Gyroskopen, Beschleunigungsmessern und Druckmessern am Rumpf des Autos empfängt. Wenn ein Fahrzeug mit einem Objekt kollidiert, erkennen diese externen Sensoren den Aufprall, führen die collide(...) Funktion aus und übergeben die aggregierten Sensordaten als nettes JavaScript-Objekt an sie. Diese Funktion gibt ein collision aus und benachrichtigt den Anbieter über den Absturz.

const EventEmitter = require('events'); class Vehicle extends EventEmitter { collide(collisionStatistics) { this.emit('collision', collisionStatistics) } } const myVehicle = new Vehicle(); myVehicle.on('collision', collisionStatistics => { console.log('WARNING! Vehicle Impact Detected: ', collisionStatistics); notifyVendor(collisionStatistics); }); myVehicle.collide({ ... }); Dies ist ein verworrenes Beispiel, denn wir könnten den Code innerhalb des Ereignishandlers einfach in die Kollisionsfunktion der Klasse einfügen, aber es zeigt, wie das Knotenereignismodell dennoch funktioniert. Beachten Sie, dass einige Tutorials die Methode util.inherits() zeigen, um einem Objekt zu erlauben, Ereignisse auszugeben. Das wurde zugunsten von ES6-Klassen und Erweiterungen extends .
Der Node Package Manager
Beim Programmieren mit Node und JavaScript hört man häufig von npm . Npm ist ein Paketmanager, der genau das tut – das Herunterladen von Paketen von Drittanbietern zulässt, die häufige Probleme in JavaScript lösen. Es gibt auch andere Lösungen wie Yarn, Npx, Grunt und Bower, aber in diesem Abschnitt konzentrieren wir uns nur auf npm und darauf, wie Sie Abhängigkeiten für Ihre Anwendung über eine einfache Befehlszeilenschnittstelle (CLI) installieren können.
Beginnen wir einfach, mit nur npm . Besuchen Sie die NpmJS-Homepage, um alle von NPM verfügbaren Pakete anzuzeigen. Wenn Sie ein neues Projekt starten, das von NPM-Paketen abhängt, müssen Sie npm init über das Terminal im Stammverzeichnis Ihres Projekts ausführen. Ihnen werden eine Reihe von Fragen gestellt, die zum Erstellen einer package.json -Datei verwendet werden. Diese Datei speichert alle Ihre Abhängigkeiten – Module, von denen Ihre Anwendung abhängig ist, Skripte – vordefinierte Terminalbefehle zum Ausführen von Tests, Erstellen des Projekts, Starten des Entwicklungsservers usw. und mehr.
Um ein Paket zu installieren, führen Sie einfach npm install [package-name] --save . Das save -Flag stellt sicher, dass das Paket und seine Version in der Datei package.json “ protokolliert werden. Seit npm Version 5 werden Abhängigkeiten standardmäßig gespeichert, daher kann --save weggelassen werden. Sie werden auch einen neuen Ordner node_modules bemerken, der den Code für das Paket enthält, das Sie gerade installiert haben. Dies kann auch auf nur npm i [package-name] abgekürzt werden. Als hilfreicher Hinweis sollte der Ordner node_modules aufgrund seiner Größe niemals in ein GitHub-Repository aufgenommen werden. Wenn Sie ein Repo von GitHub (oder einem anderen Versionsverwaltungssystem) klonen, müssen Sie unbedingt den Befehl npm install ausführen, um alle in der Datei package.json definierten Pakete abzurufen und automatisch das Verzeichnis node_modules zu erstellen. Sie können auch ein Paket mit einer bestimmten Version installieren: npm i [package-name]@1.10.1 --save , zum Beispiel.
Das Entfernen eines Pakets ähnelt dem Installieren eines Pakets: npm remove [package-name] .
Sie können ein Paket auch global installieren. Dieses Paket ist für alle Projekte verfügbar, nicht nur für das, an dem Sie gerade arbeiten. Sie tun dies mit dem Flag -g nach npm i [package-name] . Dies wird häufig für CLIs wie Google Firebase und Heroku verwendet. Trotz der Leichtigkeit, die diese Methode bietet, wird es im Allgemeinen als schlechte Praxis angesehen, Pakete global zu installieren, da sie nicht in der Datei package.json gespeichert werden und wenn ein anderer Entwickler versucht, Ihr Projekt zu verwenden, er nicht alle erforderlichen Abhängigkeiten von erhält npm install .
APIs und JSON
APIs sind ein sehr verbreitetes Paradigma in der Programmierung, und selbst wenn Sie gerade erst mit Ihrer Karriere als Entwickler beginnen, werden APIs und ihre Verwendung, insbesondere in der Web- und Mobilentwicklung, wahrscheinlich häufiger vorkommen als nicht.
Eine API ist eine Anwendungsprogrammierschnittstelle und im Grunde eine Methode, mit der zwei entkoppelte Systeme miteinander kommunizieren können. Technisch gesehen erlaubt eine API einem System oder Computerprogramm (normalerweise einem Server), Anfragen zu empfangen und entsprechende Antworten zu senden (an einen Client, auch bekannt als Host).
Angenommen, Sie erstellen eine Wetteranwendung. Sie benötigen eine Möglichkeit, die Adresse eines Benutzers in einen Breiten- und Längengrad zu geokodieren, und dann eine Möglichkeit, das aktuelle oder vorhergesagte Wetter an diesem bestimmten Ort abzurufen.
As a developer, you want to focus on building your app and monetizing it, not putting the infrastructure in place to geocode addresses or placing weather stations in every city.
Luckily for you, companies like Google and OpenWeatherMap have already put that infrastructure in place, you just need a way to talk to it — that is where the API comes in. While, as of now, we have developed a very abstract and ambiguous definition of the API, bear with me. We'll be getting to tangible examples soon.
Now, it costs money for companies to develop, maintain, and secure that aforementioned infrastructure, and so it is common for corporations to sell you access to their API. This is done with that is known as an API key, a unique alphanumeric identifier associating you, the developer, with the API. Every time you ask the API to send you data, you pass along your API key. The server can then authenticate you and keep track of how many API calls you are making, and you will be charged appropriately. The API key also permits Rate-Limiting or API Call Throttling (a method of throttling the number of API calls in a certain timeframe as to not overwhelm the server, preventing DOS attacks — Denial of Service). Most companies, however, will provide a free quota, giving you, as an example, 25,000 free API calls a day before charging you.
Up to this point, we have established that an API is a method by which two computer programs can communicate with each other. If a server is storing data, such as a website, and your browser makes a request to download the code for that site, that was the API in action.
Let us look at a more tangible example, and then we'll look at a more real-world, technical one. Suppose you are eating out at a restaurant for dinner. You are equivalent to the client, sitting at the table, and the chef in the back is equivalent to the server.
Since you will never directly talk to the chef, there is no way for him/her to receive your request (for what order you would like to make) or for him/her to provide you with your meal once you order it. We need someone in the middle. In this case, it's the waiter, analogous to the API. The API provides a medium with which you (the client) may talk to the server (the chef), as well as a set of rules for how that communication should be made (the menu — one meal is allowed two sides, etc.)
Now, how do you actually talk to the API (the waiter)? You might speak English, but the chef might speak Spanish. Is the waiter expected to know both languages to translate? What if a third person comes in who only speaks Mandarin? What then? Well, all clients and servers have to agree to speak a common language, and in computer programming, that language is JSON, pronounced JAY-sun, and it stands for JavaScript Object Notation.
At this point, we don't quite know what JSON looks like. It's not a computer programming language, it's just, well, a language, like English or Spanish, that everyone (everyone being computers) understands on a guaranteed basis. It's guaranteed because it's a standard, notably RFC 8259 , the JavaScript Object Notation (JSON) Data Interchange Format by the Internet Engineering Task Force (IETF).
Even without formal knowledge of what JSON actually is and what it looks like (we'll see in an upcoming article in this series), we can go ahead introduce a technical example operating on the Internet today that employs APIs and JSON. APIs and JSON are not just something you can choose to use, it's not equivalent to one out of a thousand JavaScript frameworks you can pick to do the same thing. It is THE standard for data exchange on the web.
Suppose you are building a travel website that compares prices for aircraft, rental car, and hotel ticket prices. Let us walk through, step-by-step, on a high level, how we would build such an application. Of course, we need our User Interface, the front-end, but that is out of scope for this article.
We want to provide our users with the lowest price booking method. Well, that means we need to somehow attain all possible booking prices, and then compare all of the elements in that set (perhaps we store them in an array) to find the smallest element (known as the infimum in mathematics.)
How will we get this data? Well, suppose all of the booking sites have a database full of prices. Those sites will provide an API, which exposes the data in those databases for use by you. You will call each API for each site to attain all possible booking prices, store them in your own array, find the lowest or minimum element of that array, and then provide the price and booking link to your user. We'll ask the API to query its database for the price in JSON, and it will respond with said price in JSON to us. We can then use, or parse, that accordingly. We have to parse it because APIs will return JSON as a string, not the actual JavaScript data type of JSON. This might not make sense now, and that's okay. We'll be covering it more in a future article.
Also, note that just because something is called an API does not necessarily mean it operates on the web and sends and receives JSON. The Java API, for example, is just the list of classes, packages, and interfaces that are part of the Java Development Kit (JDK), providing programming functionality to the programmer.
In Ordnung. We know we can talk to a program running on a server by way of an Application Programming Interface, and we know that the common language with which we do this is known as JSON. But in the web development and networking world, everything has a protocol. What do we actually do to make an API call, and what does that look like code-wise? That's where HTTP Requests enter the picture, the HyperText Transfer Protocol, defining how messages are formatted and transmitted across the Internet. Once we have an understanding of HTTP (and HTTP verbs, you'll see that in the next section), we can look into actual JavaScript frameworks and methods (like fetch() ) offered by the JavaScript API (similar to the Java API), that actually allow us to make API calls.
HTTP And HTTP Requests
HTTP is the HyperText Transfer Protocol. It is the underlying protocol that determines how messages are formatted as they are transmitted and received across the web. Let's think about what happens when, for example, you attempt to load the home page of Smashing Magazine in your web browser.
You type the website URL (Uniform Resource Locator) in the URL bar, where the DNS server (Domain Name Server, out of scope for this article) resolves the URL into the appropriate IP Address. The browser makes a request, called a GET Request, to the Web Server to, well, GET the underlying HTML behind the site. The Web Server will respond with a message such as “OK”, and then will go ahead and send the HTML down to the browser where it will be parsed and rendered accordingly.
There are a few things to note here. First, the GET Request, and then the “OK” response. Suppose you have a specific database, and you want to write an API to expose that database to your users. Suppose the database contains books the user wants to read (as it will in a future article in this series). Then there are four fundamental operations your user may want to perform on this database, that is, Create a record, Read a record, Update a record, or Delete a record, known collectively as CRUD operations.
Let's look at the Read operation for a moment. Without incorrectly assimilating or conflating the notion of a web server and a database, that Read operation is very similar to your web browser attempting to get the site from the server, just as to read a record is to get the record from the database.
Dies wird als HTTP-Anforderung bezeichnet. Sie stellen irgendwo eine Anfrage an einen Server, um einige Daten zu erhalten, und als solche wird die Anfrage passenderweise „GET“ genannt, wobei Großschreibung eine Standardmethode ist, um solche Anfragen zu kennzeichnen.
Was ist mit dem Create-Teil von CRUD? Nun, wenn es um HTTP-Anforderungen geht, ist dies als POST-Anforderung bekannt. Genauso wie Sie eine Nachricht auf einer Social-Media-Plattform posten , können Sie auch einen neuen Datensatz in einer Datenbank posten .
Das Update von CRUD ermöglicht es uns, entweder eine PUT- oder eine PATCH-Anforderung zu verwenden, um eine Ressource zu aktualisieren. PUT von HTTP erstellt entweder einen neuen Datensatz oder aktualisiert/ersetzt den alten.
Sehen wir uns das etwas genauer an, und dann kommen wir zu PATCH.
Eine API funktioniert im Allgemeinen, indem sie HTTP-Anforderungen an bestimmte Routen in einer URL sendet. Angenommen, wir erstellen eine API, um mit einer Datenbank zu kommunizieren, die die Bücherliste eines Benutzers enthält. Dann können wir diese Bücher möglicherweise unter der URL .../books anzeigen. Eine POST-Anforderung an .../books erstellt ein neues Buch mit den von Ihnen definierten Eigenschaften (denken Sie an ID, Titel, ISBN, Autor, Veröffentlichungsdaten usw.) auf der Route .../books . Es spielt keine Rolle, was die zugrunde liegende Datenstruktur ist, die gerade alle Bücher unter .../books speichert. Wir kümmern uns nur darum, dass die API diesen Endpunkt (auf den über die Route zugegriffen wird) verfügbar macht, um Daten zu manipulieren. Der vorherige Satz war entscheidend: Eine POST-Anforderung erstellt ein neues Buch auf der Route ...books/ . Der Unterschied zwischen PUT und POST besteht also darin, dass PUT ein neues Buch erstellt (wie bei POST), wenn kein solches Buch existiert, oder ein vorhandenes Buch ersetzt, wenn das Buch bereits in dieser oben genannten Datenstruktur existiert.
Angenommen, jedes Buch hat die folgenden Eigenschaften: id, title, ISBN, author, hasRead (boolean).
Um dann, wie bereits erwähnt, ein neues Buch hinzuzufügen, würden wir eine POST-Anfrage an .../books stellen. Wenn wir ein Buch vollständig aktualisieren oder ersetzen wollten, würden wir eine PUT-Anforderung an .../books/id stellen, wobei id die ID des Buchs ist, das wir ersetzen möchten.
Während PUT ein vorhandenes Buch vollständig ersetzt, aktualisiert PATCH etwas, das mit einem bestimmten Buch zu tun hat, indem es vielleicht die oben definierte boolesche Eigenschaft hasRead – also würden wir eine PATCH-Anfrage an …/books/id stellen und die neuen Daten mitsenden.
Es kann im Moment schwierig sein, die Bedeutung davon zu verstehen, denn bisher haben wir alles theoretisch festgestellt, aber keinen greifbaren Code gesehen, der tatsächlich eine HTTP-Anfrage stellt. Wir werden jedoch bald darauf zurückkommen und GET in diesem Artikel behandeln, den Rest in einem zukünftigen Artikel.
Es gibt noch eine letzte grundlegende CRUD-Operation, die Delete heißt. Wie zu erwarten, lautet der Name einer solchen HTTP-Anforderung „DELETE“, und sie funktioniert ähnlich wie PATCH, wobei die ID des Buchs in einer Route angegeben werden muss.
Wir haben also bisher gelernt, dass Routen spezifische URLs sind, an die Sie eine HTTP-Anfrage stellen, und dass Endpunkte Funktionen sind, die die API bereitstellt und etwas mit den Daten macht, die sie offenlegt. Das heißt, der Endpunkt ist eine Programmiersprachenfunktion, die sich am anderen Ende der Route befindet und die von Ihnen angegebene HTTP-Anforderung ausführt. Wir haben auch erfahren, dass es Begriffe wie POST, GET, PUT, PATCH, DELETE und mehr (bekannt als HTTP-Verben) gibt, die tatsächlich angeben, welche Anforderungen Sie an die API stellen. Wie JSON sind diese HTTP-Anforderungsmethoden Internetstandards, die von der Internet Engineering Task Force (IETF) definiert wurden, insbesondere RFC 7231, Abschnitt 4: Anforderungsmethoden, und RFC 5789, Abschnitt 2: Patch-Methode, wobei RFC ein Akronym für ist Anfrage für Kommentare.
Wir könnten also eine GET-Anforderung an die URL .../books/id stellen, wobei die übergebene ID als Parameter bekannt ist. Wir könnten eine POST-, PUT- oder PATCH-Anforderung an .../books senden, um eine Ressource zu erstellen, oder an .../books/id , um eine Ressource zu ändern/ersetzen/aktualisieren. Und wir können auch eine DELETE-Anfrage an .../books/id stellen, um ein bestimmtes Buch zu löschen.
Eine vollständige Liste der HTTP-Anforderungsmethoden finden Sie hier.
Es ist auch wichtig zu beachten, dass wir nach einer HTTP-Anfrage eine Antwort erhalten. Die spezifische Antwort wird dadurch bestimmt, wie wir die API erstellen, aber Sie sollten immer einen Statuscode erhalten. Wir haben bereits gesagt, dass Ihr Webbrowser, wenn er den HTML-Code vom Webserver anfordert, mit „OK“ antwortet. Dies ist als HTTP-Statuscode bekannt, genauer gesagt HTTP 200 OK. Der Statuscode gibt lediglich an, wie die im Endpunkt angegebene Operation oder Aktion (denken Sie daran, das ist unsere Funktion, die die ganze Arbeit erledigt) abgeschlossen wurde. HTTP .../books/id Statuscodes werden vom Server zurückgesendet, und es gibt wahrscheinlich viele, mit denen Sie vertraut sind, wie z. .../books/id , wo keine solche ID existiert.)
Eine vollständige Liste der HTTP-Statuscodes finden Sie hier.
MongoDB
MongoDB ist eine nicht relationale NoSQL-Datenbank, ähnlich der Firebase-Echtzeitdatenbank. Sie kommunizieren mit der Datenbank über ein Node-Paket wie den MongoDB Native Driver oder Mongoose.
In MongoDB werden Daten in JSON gespeichert, was sich deutlich von relationalen Datenbanken wie MySQL, PostgreSQL oder SQLite unterscheidet. Beide werden als Datenbanken bezeichnet, wobei SQL-Tabellen als Sammlungen, SQL-Tabellenzeilen als Dokumente und SQL-Tabellenspalten als Felder bezeichnet werden.
Wir werden die MongoDB-Datenbank in einem der nächsten Artikel dieser Serie verwenden, wenn wir unsere allererste Bookshelf-API erstellen. Die oben aufgeführten grundlegenden CRUD-Operationen können auf einer MongoDB-Datenbank ausgeführt werden.
Es wird empfohlen, dass Sie die MongoDB-Dokumentation durchlesen, um zu erfahren, wie Sie eine Live-Datenbank auf einem Atlas-Cluster erstellen und CRUD-Vorgänge mit dem nativen MongoDB-Treiber ausführen. Im nächsten Artikel dieser Serie erfahren Sie, wie Sie eine lokale Datenbank und eine Cloud-Produktionsdatenbank einrichten.
Erstellen einer Befehlszeilenknotenanwendung
Beim Erstellen einer Anwendung werden Sie sehen, dass viele Autoren ihre gesamte Codebasis am Anfang des Artikels ausgeben und dann versuchen, jede Zeile danach zu erklären. In diesem Text gehe ich einen anderen Weg. Ich erkläre meinen Code Zeile für Zeile und erstelle dabei die App. Ich werde mir keine Gedanken über Modularität oder Leistung machen, ich werde die Codebasis nicht in separate Dateien aufteilen und ich werde nicht dem DRY-Prinzip folgen oder versuchen, den Code wiederverwendbar zu machen. Beim Lernen ist es sinnvoll, die Dinge so einfach wie möglich zu gestalten, und das ist der Ansatz, den ich hier verfolgen werde.
Lassen Sie uns klarstellen, was wir bauen. Wir kümmern uns nicht um Benutzereingaben und verwenden daher keine Pakete wie Yargs. Wir werden auch keine eigene API erstellen. Das wird in einem späteren Artikel dieser Serie kommen, wenn wir das Express Web Application Framework verwenden. Ich verfolge diesen Ansatz, um Node.js nicht mit der Leistungsfähigkeit von Express und APIs zu verschmelzen, da dies in den meisten Tutorials der Fall ist. Stattdessen stelle ich eine Methode (von vielen) bereit, mit der Daten von einer externen API aufgerufen und empfangen werden können, die eine JavaScript-Bibliothek eines Drittanbieters verwendet. Die API, die wir aufrufen werden, ist eine Wetter-API, auf die wir von Node aus zugreifen und ihre Ausgabe an das Terminal ausgeben, vielleicht mit einer gewissen Formatierung, bekannt als „Pretty-Printing“. Ich werde den gesamten Prozess abdecken, einschließlich der Einrichtung der API und des Erhalts des API-Schlüssels, dessen Schritte ab Januar 2019 die richtigen Ergebnisse liefern.
Wir werden die OpenWeatherMap-API für dieses Projekt verwenden. Navigieren Sie also zunächst zur OpenWeatherMap-Anmeldeseite und erstellen Sie mit dem Formular ein Konto. Suchen Sie nach der Anmeldung den Menüpunkt API-Schlüssel auf der Dashboard-Seite (hier zu finden). Wenn Sie gerade ein Konto erstellt haben, müssen Sie einen Namen für Ihren API-Schlüssel auswählen und auf „Generieren“ klicken. Es kann mindestens 2 Stunden dauern, bis Ihr neuer API-Schlüssel funktionsfähig und Ihrem Konto zugeordnet ist.
Bevor wir mit der Erstellung der Anwendung beginnen, besuchen wir die API-Dokumentation, um zu erfahren, wie wir unseren API-Schlüssel formatieren. In diesem Projekt geben wir eine Postleitzahl und eine Ländervorwahl an, um die Wetterinformationen an diesem Ort zu erhalten.
Aus den Dokumenten können wir ersehen, dass die Methode, mit der wir dies tun, darin besteht, die folgende URL bereitzustellen:
api.openweathermap.org/data/2.5/weather?zip={zip code},{country code}In die wir Daten eingeben könnten:
api.openweathermap.org/data/2.5/weather?zip=94040,usBevor wir nun tatsächlich relevante Daten von dieser API abrufen können, müssen wir unseren neuen API-Schlüssel als Abfrageparameter bereitstellen:
api.openweathermap.org/data/2.5/weather?zip=94040,us&appid={YOUR_API_KEY} Kopieren Sie diese URL zunächst in eine neue Registerkarte Ihres Webbrowsers und ersetzen Sie den Platzhalter {YOUR_API_KEY} durch den API-Schlüssel, den Sie zuvor bei der Registrierung für ein Konto erhalten haben.
Der Text, den Sie sehen können, ist eigentlich JSON – die vereinbarte Sprache des Webs, wie bereits erwähnt.
Um dies weiter zu untersuchen, drücken Sie in Google Chrome Strg + Umschalt + I , um die Chrome-Entwicklertools zu öffnen, und navigieren Sie dann zur Registerkarte Netzwerk. Derzeit sollten hier keine Daten vorhanden sein.
Um die Netzwerkdaten tatsächlich zu überwachen, laden Sie die Seite neu und beobachten Sie, wie die Registerkarte mit nützlichen Informationen gefüllt wird. Klicken Sie auf den ersten Link, wie im Bild unten dargestellt.
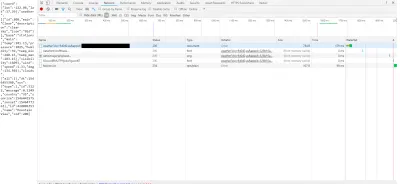
Sobald Sie auf diesen Link klicken, können wir tatsächlich HTTP-spezifische Informationen anzeigen, z. B. die Header. Header werden in der Antwort von der API gesendet (in einigen Fällen können Sie auch Ihre eigenen Header an die API senden oder Sie können sogar Ihre eigenen benutzerdefinierten Header (oft mit dem Präfix x- ) erstellen, die beim Erstellen Ihrer eigenen API zurückgesendet werden ) und enthalten nur zusätzliche Informationen, die entweder der Client oder der Server benötigen.
In diesem Fall können Sie sehen, dass wir eine HTTP GET-Anforderung an die API gesendet haben und diese mit einem HTTP-Status 200 OK geantwortet hat. Sie können auch sehen, dass die zurückgesendeten Daten in JSON waren, wie im Abschnitt „Antwort-Header“ aufgeführt.
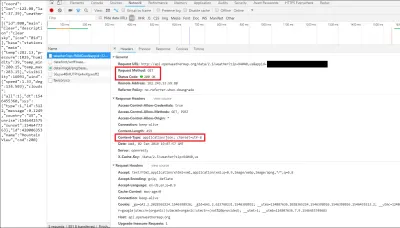
Wenn Sie auf die Registerkarte „Vorschau“ klicken, können Sie JSON tatsächlich als JavaScript-Objekt anzeigen. Die Textversion, die Sie in Ihrem Browser sehen können, ist ein String, da JSON immer als String über das Web gesendet und empfangen wird. Deshalb müssen wir den JSON in unserem Code parsen, um ihn in ein besser lesbares Format zu bringen – in diesem Fall (und in so ziemlich jedem Fall) – ein JavaScript-Objekt.
Sie können dies auch automatisch über die Google Chrome-Erweiterung „JSON View“ tun.
Um mit dem Aufbau unserer Anwendung zu beginnen, öffne ich ein Terminal und erstelle ein neues Stammverzeichnis und dann cd hinein. Sobald ich drinnen bin, erstelle ich eine neue app.js -Datei, führe npm init aus, um eine package.json -Datei mit den Standardeinstellungen zu generieren, und öffne dann Visual Studio Code.
mkdir command-line-weather-app && cd command-line-weather-app touch app.js npm init code . Danach lade ich Axios herunter, vergewissere mich, dass es meiner Datei package.json “ hinzugefügt wurde, und stelle fest, dass der Ordner „ node_modules “ erfolgreich erstellt wurde.
Im Browser können Sie sehen, dass wir eine GET-Anforderung von Hand erstellt haben, indem Sie die richtige URL manuell in die URL-Leiste eingeben. Axios ermöglicht es mir, dies innerhalb von Node zu tun.
Ab sofort befindet sich der gesamte folgende Code in der Datei app.js , wobei jedes Snippet nacheinander platziert wird.
Als erstes benötige ich das Axios-Paket, mit dem wir zuvor installiert haben
const axios = require('axios'); Wir haben jetzt Zugriff auf Axios und können relevante HTTP-Anforderungen über die axios Konstante stellen.
Im Allgemeinen sind unsere API-Aufrufe dynamisch – in diesem Fall möchten wir möglicherweise verschiedene Postleitzahlen und Ländercodes in unsere URL einfügen. Ich erstelle also konstante Variablen für jeden Teil der URL und füge sie dann mit ES6-Vorlagenzeichenfolgen zusammen. Zuerst haben wir den Teil unserer URL, der sich nie ändern wird, sowie unseren API-Schlüssel:
const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; Ich werde auch unsere Postleitzahl und Ländervorwahl zuweisen. Da wir keine Benutzereingaben erwarten und die Daten eher fest codieren, mache ich diese ebenfalls konstant, obwohl es in vielen Fällen sinnvoller sein wird, let zu verwenden.
const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us';Wir müssen diese Variablen nun zu einer URL zusammenfügen, an die wir Axios verwenden können, um GET-Anforderungen zu stellen:
const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Hier ist der Inhalt unserer app.js -Datei bis zu diesem Punkt:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; Alles, was noch zu tun bleibt, ist, axios tatsächlich zu verwenden, um eine GET-Anfrage an diese URL zu stellen. Dazu verwenden wir die von axios bereitgestellte Methode get(url) .
axios.get(ENTIRE_API_URL) axios.get(...) gibt tatsächlich ein Promise zurück, und die Success-Callback-Funktion nimmt ein Antwortargument entgegen, das es uns ermöglicht, auf die Antwort von der API zuzugreifen – dasselbe, was Sie im Browser gesehen haben. Ich werde auch eine .catch() Klausel hinzufügen, um Fehler abzufangen.
axios.get(ENTIRE_API_URL) .then(response => console.log(response)) .catch(error => console.log('Error', error)); Wenn wir diesen Code jetzt mit node app.js im Terminal ausführen, können Sie die vollständige Antwort sehen, die wir zurückbekommen. Angenommen, Sie möchten nur die Temperatur für diese Postleitzahl sehen – dann sind die meisten dieser Daten in der Antwort für Sie nicht nützlich. Axios gibt die Antwort von der API tatsächlich im Datenobjekt zurück, das eine Eigenschaft der Antwort ist. Das bedeutet, dass sich die Antwort vom Server tatsächlich unter response.data befindet, also geben wir das stattdessen in der Callback-Funktion aus: console.log(response.data) .
Nun, wir haben gesagt, dass Webserver JSON immer als Zeichenfolge behandeln, und das ist wahr. Möglicherweise stellen Sie jedoch fest, dass response.data bereits ein Objekt ist (durch Ausführen von console.log(typeof response.data) ersichtlich) – wir mussten es nicht mit JSON.parse() parsen. Denn Axios erledigt das bereits hinter den Kulissen für uns.
Die Ausgabe im Terminal durch Ausführen von console.log(response.data) kann formatiert werden – „hübsch gedruckt“ – durch Ausführen von console.log(JSON.stringify(response.data, undefined, 2)) . JSON.stringify() konvertiert ein JSON-Objekt in einen String und übernimmt das Objekt, einen Filter und die Anzahl der Zeichen, um die beim Drucken eingerückt werden soll. Sie können die Antwort sehen, die dies liefert:
{ "coord": { "lon": -118.24, "lat": 33.97 }, "weather": [ { "id": 800, "main": "Clear", "description": "clear sky", "icon": "01d" } ], "base": "stations", "main": { "temp": 288.21, "pressure": 1022, "humidity": 15, "temp_min": 286.15, "temp_max": 289.75 }, "visibility": 16093, "wind": { "speed": 2.1, "deg": 110 }, "clouds": { "all": 1 }, "dt": 1546459080, "sys": { "type": 1, "id": 4361, "message": 0.0072, "country": "US", "sunrise": 1546441120, "sunset": 1546476978 }, "id": 420003677, "name": "Lynwood", "cod": 200 } Nun ist klar ersichtlich, dass sich die gesuchte Temperatur auf der Eigenschaft main des Objekts response.data befindet, sodass wir darauf zugreifen können, indem wir response.data.main.temp aufrufen. Schauen wir uns den bisherigen Code unserer Anwendung an:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => console.log(response.data.main.temp)) .catch(error => console.log('Error', error));Die Temperatur, die wir zurückerhalten, ist eigentlich in Kelvin, einer Temperaturskala, die allgemein in Physik, Chemie und Thermodynamik verwendet wird, da sie einen „absoluten Nullpunkt“ liefert, bei dem es sich um die Temperatur handelt, bei der alle thermischen Bewegungen von innen ablaufen Teilchen aufhören. Wir müssen dies nur mit den folgenden Formeln in Fahrenheit oder Celsius umwandeln:
F = K * 9/5 - 459,67
C = K - 273,15
Lassen Sie uns unseren Erfolgsrückruf aktualisieren, um die neuen Daten mit dieser Konvertierung zu drucken. Wir werden auch einen richtigen Satz für die Zwecke der Benutzererfahrung hinzufügen:
axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error)); Die Klammern um die message Variable sind nicht erforderlich, sie sehen einfach gut aus – ähnlich wie bei der Arbeit mit JSX in React. Die umgekehrten Schrägstriche verhindern, dass der Vorlagenstring eine neue Zeile formatiert, und die Prototypmethode replace() String entfernt Leerzeichen mithilfe von regulären Ausdrücken (RegEx). Die Prototypmethode toFixed() Number rundet eine Gleitkommazahl auf eine bestimmte Anzahl von Dezimalstellen – in diesem Fall zwei.
Damit sieht unsere finale app.js wie folgt aus:
const axios = require('axios'); // API specific settings. const API_URL = 'https://api.openweathermap.org/data/2.5/weather?zip='; const API_KEY = 'Your API Key Here'; const LOCATION_ZIP_CODE = '90001'; const COUNTRY_CODE = 'us'; const ENTIRE_API_URL = `${API_URL}${LOCATION_ZIP_CODE},${COUNTRY_CODE}&appid=${API_KEY}`; axios.get(ENTIRE_API_URL) .then(response => { // Getting the current temperature and the city from the response object. const kelvinTemperature = response.data.main.temp; const cityName = response.data.name; const countryName = response.data.sys.country; // Making K to F and K to C conversions. const fahrenheitTemperature = (kelvinTemperature * 9/5) — 459.67; const celciusTemperature = kelvinTemperature — 273.15; // Building the final message. const message = ( `Right now, in \ ${cityName}, ${countryName} the current temperature is \ ${fahrenheitTemperature.toFixed(2)} deg F or \ ${celciusTemperature.toFixed(2)} deg C.`.replace(/\s+/g, ' ') ); console.log(message); }) .catch(error => console.log('Error', error));Fazit
Wir haben in diesem Artikel viel über die Funktionsweise von Node gelernt, von den Unterschieden zwischen synchronen und asynchronen Anfragen über Callback-Funktionen bis hin zu neuen ES6-Funktionen, Ereignissen, Paketmanagern, APIs, JSON und dem HyperText Transfer Protocol, nicht relationalen Datenbanken , und wir haben sogar unsere eigene Befehlszeilenanwendung entwickelt, die den größten Teil dieses neu gewonnenen Wissens nutzt.
In zukünftigen Artikeln dieser Reihe werden wir uns eingehender mit dem Aufrufstapel, der Ereignisschleife und den Knoten-APIs befassen, wir werden über Cross-Origin Resource Sharing (CORS) sprechen und wir werden eine vollständige erstellen Stack Bookshelf API unter Verwendung von Datenbanken, Endpunkten, Benutzerauthentifizierung, Tokens, serverseitigem Template-Rendering und mehr.
Beginnen Sie von hier aus mit der Erstellung Ihrer eigenen Node-Anwendungen, lesen Sie die Node-Dokumentation, finden Sie interessante APIs oder Node-Module und implementieren Sie sie selbst. Die Welt steht Ihnen offen und Sie haben Zugriff auf das größte Wissensnetzwerk der Welt – das Internet. Nutzen Sie es zu Ihrem Vorteil.
Weiterführende Literatur zu SmashingMag:
- Verständnis und Verwendung von REST-APIs
- Neue JavaScript-Funktionen, die das Schreiben von Regex verändern werden
- Node.js schnell halten: Tools, Techniken und Tipps zum Erstellen hochleistungsfähiger Node.js-Server
- Erstellen eines einfachen KI-Chatbots mit Web Speech API und Node.js