
Lernen Sie den Naive-Bayes-Algorithmus für maschinelles Lernen [mit Beispielen]
Veröffentlicht: 2021-02-25Inhaltsverzeichnis
Einführung
In Mathematik und Programmierung sind einige der einfachsten Lösungen normalerweise die mächtigsten. Der naive Bayes-Algorithmus ist ein klassisches Beispiel für diese Aussage. Trotz des starken und schnellen Fortschritts und der Entwicklung im Bereich des maschinellen Lernens gilt dieser Naive-Bayes-Algorithmus immer noch als einer der am weitesten verbreiteten und effizientesten Algorithmen. Der naive Bayes-Algorithmus findet seine Anwendungen in einer Vielzahl von Problemen, einschließlich Klassifizierungsaufgaben und Problemen der Verarbeitung natürlicher Sprache (NLP).
Die mathematische Hypothese des Bayes-Theorems dient als grundlegendes Konzept hinter diesem Naive-Bayes-Algorithmus. In diesem Artikel werden wir die Grundlagen des Bayes-Theorems, des Naive-Bayes-Algorithmus, zusammen mit seiner Implementierung in Python mit einem Echtzeit-Beispielproblem durchgehen. Daneben werden wir auch einige Vor- und Nachteile des Naive-Bayes-Algorithmus im Vergleich zu seinen Konkurrenten betrachten.
Grundlagen der Wahrscheinlichkeit
Bevor wir uns daran machen, das Bayes-Theorem und den Naive-Bayes-Algorithmus zu verstehen, wollen wir unser vorhandenes Wissen über die Grundlagen der Wahrscheinlichkeit auffrischen.
Wie wir alle per Definition wissen, ist bei einem gegebenen Ereignis A die Wahrscheinlichkeit des Eintretens dieses Ereignisses durch P(A) gegeben. In der Wahrscheinlichkeit werden zwei Ereignisse A und B als unabhängige Ereignisse bezeichnet, wenn das Eintreten von Ereignis A die Eintrittswahrscheinlichkeit von Ereignis B nicht verändert und umgekehrt. Wenn andererseits das Eintreten des einen die Wahrscheinlichkeit des anderen ändert, werden sie als abhängige Ereignisse bezeichnet.
Lassen Sie uns einen neuen Begriff namens Bedingte Wahrscheinlichkeit vorstellen . In der Mathematik ist die bedingte Wahrscheinlichkeit für zwei Ereignisse A und B, gegeben durch P (A | B), definiert als die Wahrscheinlichkeit des Eintretens von Ereignis A, vorausgesetzt, dass Ereignis B bereits eingetreten ist. Abhängig von der Beziehung zwischen den beiden Ereignissen A und B, ob sie abhängig oder unabhängig sind, wird die bedingte Wahrscheinlichkeit auf zwei Arten berechnet.
- Die bedingte Wahrscheinlichkeit zweier abhängiger Ereignisse A und B ist gegeben durch P (A| B) = P (A und B) / P (B)
- Der Ausdruck für die bedingte Wahrscheinlichkeit zweier unabhängiger Ereignisse A und B ist gegeben durch: P (A| B) = P (A)
Nachdem wir die Mathematik hinter Wahrscheinlichkeit und bedingten Wahrscheinlichkeiten kennen, wollen wir uns nun dem Bayes-Theorem zuwenden.

Satz von Bayes
In der Statistik und Wahrscheinlichkeitstheorie wird das Theorem von Bayes, auch als Bayes-Regel bekannt, verwendet, um die bedingte Wahrscheinlichkeit von Ereignissen zu bestimmen. Mit anderen Worten, das Theorem von Bayes beschreibt die Wahrscheinlichkeit eines Ereignisses basierend auf vorheriger Kenntnis der Bedingungen, die für das Ereignis relevant sein könnten.
Um es einfacher zu verstehen, bedenken Sie, dass wir wissen müssen, dass die Wahrscheinlichkeit, dass der Preis eines Hauses sehr hoch ist, hoch ist. Wenn wir die anderen Parameter wie das Vorhandensein von Schulen, Ärzten und Krankenhäusern in der Nähe kennen, können wir diese genauer einschätzen. Genau das leistet das Bayes Theorem.
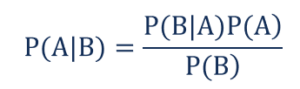
So dass,
- P(A|B) – die bedingte Wahrscheinlichkeit des Eintretens von Ereignis A, wenn Ereignis B eingetreten ist, auch als Posterior Probability bekannt .
- P(B|A) – die bedingte Wahrscheinlichkeit des Eintretens von Ereignis B, wenn Ereignis A eingetreten ist, auch als Wahrscheinlichkeitswahrscheinlichkeit bekannt .
- P(A) – die Wahrscheinlichkeit des Eintretens von Ereignis A, auch bekannt als vorherige Wahrscheinlichkeit.
- P(B) – die Wahrscheinlichkeit des Eintretens von Ereignis B, auch bekannt als Grenzwahrscheinlichkeit.
Angenommen, wir haben ein einfaches maschinelles Lernproblem mit 'n' unabhängigen Variablen und die abhängige Variable, die die Ausgabe ist, ist ein boolescher Wert (Wahr oder Falsch). Angenommen, die unabhängigen Attribute sind kategorialer Natur, betrachten wir für dieses Beispiel 2 Kategorien. Daher müssen wir mit diesen Daten den Wert der Wahrscheinlichkeitswahrscheinlichkeit P(B|A) berechnen.
Wenn wir also das Obige beobachten, stellen wir fest, dass wir 2*(2^ n -1 ) Parameter berechnen müssen, um dieses maschinelle Lernmodell zu lernen. Wenn wir 30 boolesche unabhängige Attribute haben, beträgt die Gesamtzahl der zu berechnenden Parameter in ähnlicher Weise fast 3 Milliarden, was einen extrem hohen Rechenaufwand bedeutet.
Diese Schwierigkeit beim Erstellen eines maschinellen Lernmodells mit dem Bayes-Theorem führte zur Geburt und Entwicklung des Naive-Bayes-Algorithmus.
Naive-Bayes-Algorithmus
Um praktikabel zu sein, muss die oben erwähnte Komplexität des Satzes von Bayes reduziert werden. Genau dies wird im Naive-Bayes-Algorithmus erreicht, indem wenige Annahmen getroffen werden. Die getroffenen Annahmen sind, dass jedes Merkmal einen unabhängigen und gleichberechtigten Beitrag zum Ergebnis leistet.
Der naive Bayes-Algorithmus ist ein überwachter Lernalgorithmus und basiert auf dem Bayes-Theorem, das hauptsächlich zur Lösung von Klassifikationsproblemen verwendet wird. Es ist einer der einfachsten und genauesten Klassifikatoren, der Modelle für maschinelles Lernen erstellt, um schnelle Vorhersagen zu treffen. Mathematisch gesehen ist es ein probabilistischer Klassifikator, da es Vorhersagen unter Verwendung der Wahrscheinlichkeitsfunktion der Ereignisse macht.
Beispielproblem
Um die Logik hinter den Annahmen zu verstehen, lassen Sie uns einen einfachen Datensatz durchgehen, um eine bessere Intuition zu bekommen.
| Farbe | Art | Herkunft | Diebstahl? |
| Schwarz | Limousine | Importiert | Jawohl |
| Schwarz | Geländewagen | Importiert | Nein |
| Schwarz | Limousine | Inländisch | Jawohl |
| Schwarz | Limousine | Importiert | Nein |
| Braun | Geländewagen | Inländisch | Jawohl |
| Braun | Geländewagen | Inländisch | Nein |
| Braun | Limousine | Importiert | Nein |
| Braun | Geländewagen | Importiert | Jawohl |
| Braun | Limousine | Inländisch | Nein |
Aus dem oben angegebenen Datensatz können wir die Konzepte der beiden Annahmen ableiten, die wir oben für den Naive-Bayes-Algorithmus definiert haben.
- Die erste Annahme ist, dass alle Merkmale unabhängig voneinander sind. Hier sehen wir, dass jedes Attribut unabhängig ist, wie z. B. die Farbe „Rot“ unabhängig von Typ und Herkunft des Autos ist.
- Als nächstes ist jedem Merkmal die gleiche Bedeutung beizumessen. Ebenso reicht es nicht aus, nur den Typ und die Herkunft des Autos zu kennen, um das Ergebnis des Problems vorherzusagen. Daher ist keine der Variablen irrelevant und daher tragen sie alle gleichermaßen zum Ergebnis bei.
Zusammenfassend sind A und B bei gegebenem C genau dann bedingt unabhängig, wenn angesichts des Wissens, dass C eintritt, das Wissen, ob A eintritt, keine Informationen über die Wahrscheinlichkeit des Auftretens von B liefert, und das Wissen, ob B eintritt, keine Informationen darüber liefert die Wahrscheinlichkeit, dass A eintritt. Diese Annahmen machen den Bayes-Algorithmus – naiv . Daher der Name Naive-Bayes-Algorithmus.
Daher kann das Bayes-Theorem für das oben angegebene Problem umgeschrieben werden als –
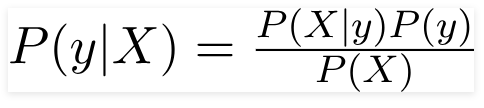
So dass,
- Der unabhängige Merkmalsvektor X = (x 1 , x 2 , x 3 ……x n ) repräsentiert die Merkmale wie Farbe, Typ und Herkunft des Autos.
- Die Ausgangsvariable y hat nur zwei Ergebnisse Ja oder Nein.
Daher erhalten wir durch Ersetzen der obigen Werte die Naive-Bayes-Formel als
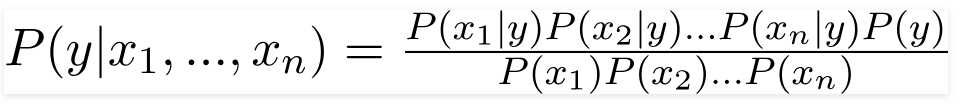
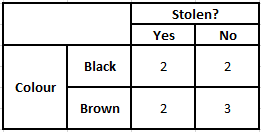
Um die spätere Wahrscheinlichkeit P(y|X) zu berechnen, müssen wir für jedes Attribut eine Häufigkeitstabelle für die Ausgabe erstellen. Dann wandeln wir die Häufigkeitstabellen in Wahrscheinlichkeitstabellen um, wonach wir schließlich die Naive-Bayes-Gleichung verwenden, um die spätere Wahrscheinlichkeit für jede Klasse zu berechnen. Als Ergebnis der Vorhersage wird die Klasse mit der höchsten A-posteriori-Wahrscheinlichkeit gewählt. Nachfolgend finden Sie die Häufigkeits- und Wahrscheinlichkeitstabellen für alle drei Prädiktoren.
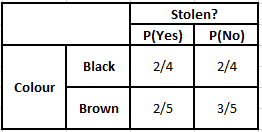
Häufigkeitstabelle der Farbe Wahrscheinlichkeitstabelle der Farbe
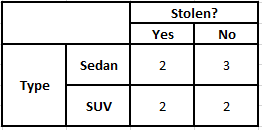
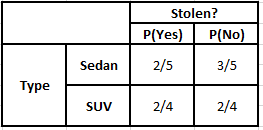
Häufigkeitstabelle des Typs Wahrscheinlichkeitstabelle des Typs

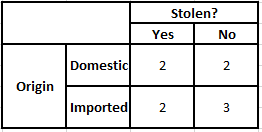
Häufigkeitstabelle der Herkunft Wahrscheinlichkeitstabelle der Herkunft
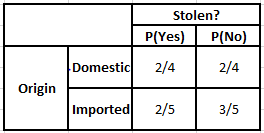
Betrachten Sie den Fall, in dem wir die späteren Wahrscheinlichkeiten für die unten angegebenen Bedingungen berechnen müssen –
| Farbe | Art | Herkunft |
| Braun | Geländewagen | Importiert |
Somit können wir aus der oben angegebenen Formel die späteren Wahrscheinlichkeiten wie unten gezeigt berechnen:
P(Ja | X) = P(Braun | Ja) * P(SUV | Ja) * P(Importiert | Ja) * P(Ja)
= 2/5 * 2/4 * 2/5 * 1
= 0,08
P(Nein | X) = P(Braun | Nein) * P(SUV | Nein) * P(Importiert | Nein) * P(Nein)
= 3/5 * 2/4 * 3/5 * 1
= 0,18
Da die A-Posteriori-Wahrscheinlichkeiten für Nein größer als Ja sind (0,18 > 0,08), kann aus den oben berechneten Werten gefolgert werden, dass ein Auto mit brauner Farbe, SUV-Typ importierter Herkunft, als „Nein“ klassifiziert wird. Daher wird das Auto nicht gestohlen.
Implementierung in Python
Nachdem wir nun die Mathematik hinter dem Naive-Bayes-Algorithmus verstanden und ihn auch anhand eines Beispiels visualisiert haben, lassen Sie uns den Code für maschinelles Lernen in Python-Sprache durchgehen.
Verwandte: Naive Bayes-Klassifikator
Problemanalyse
Um das Naive-Bayes-Klassifizierungsprogramm im maschinellen Lernen mit Python zu implementieren, werden wir den sehr berühmten „Iris Flower Dataset“ verwenden. Der Irisblüten-Datensatz oder Fisher's Iris-Datensatz ist ein multivariater Datensatz, der 1998 vom britischen Statistiker, Eugeniker und Biologen Ronald Fisher eingeführt wurde. Dies ist ein sehr kleiner und grundlegender Datensatz, der aus sehr wenigen numerischen Daten besteht, die Informationen über 3 Klassen enthalten von Blumen der Iris-Arten, die –
- Iris Setosa
- Iris Versicolor
- Iris Virginia
Es gibt 50 Proben von jeder der drei Arten , was einem Gesamtdatensatz von 150 Zeilen entspricht. Die 4 Attribute (oder) unabhängigen Variablen, die in diesem Datensatz verwendet werden, sind –
- Kelchblattlänge in cm
- Kelchblattbreite in cm
- Blütenblattlänge in cm
- Blütenblattbreite in cm
Die abhängige Variable ist die „ Art “ der Blume, die durch die oben angegebenen vier Attribute identifiziert wird.
Schritt 1 – Importieren der Bibliotheken
Wie immer besteht der erste Schritt beim Erstellen eines Modells für maschinelles Lernen darin, die relevanten Bibliotheken zu importieren. Dazu laden wir die NumPy-, Mathplotlib- und die Pandas-Bibliotheken zur Vorverarbeitung der Daten.
importiere numpy als np
importiere matplotlib.pyplot als plt
pandas als pd importieren
Schritt 2 – Laden des Datensatzes
Der zum Training des Naive-Bayes-Klassifikators zu verwendende Irisblüten-Datensatz soll in einen Pandas-Datenrahmen geladen werden. Die 4 unabhängigen Variablen werden der Variablen X zugewiesen und die endgültige Ausgabeartvariable wird y zugewiesen.
dataset = pd.read_csv(' https://raw.githubusercontent.com/mk-gurucharan/Classification/master/IrisDataset.csv' )X = dataset.iloc[:,:4].values
y = Datensatz['Spezies'].WerteDatensatz.Kopf(5)>>
kelch_länge kelch_breite blütenblatt_länge blütenblatt_breite art
5,1 3,5 1,4 0,2 Setosa
4,9 3,0 1,4 0,2 Setosa
4,7 3,2 1,3 0,2 Setosa
4,6 3,1 1,5 0,2 Setosa
5,0 3,6 1,4 0,2 Setosa
Schritt 3 – Aufteilen des Datensatzes in Trainingssatz und Testsatz
Nach dem Laden des Datensatzes und der Variablen besteht der nächste Schritt darin, die Variablen vorzubereiten, die dem Trainingsprozess unterzogen werden. In diesem Schritt müssen wir die X- und Y-Variablen in Trainings- und Testdatensätze aufteilen. Dazu ordnen wir 80 % der Daten zufällig dem Trainingsset zu, das zu Trainingszwecken verwendet wird, und die restlichen 20 % der Daten dem Testset, auf dem der trainierte Naive-Bayes-Klassifikator auf Genauigkeit getestet werden soll.
aus sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0,2)
Schritt 4 – Funktionsskalierung
Obwohl dies ein zusätzlicher Prozess zu diesem kleinen Datensatz ist, füge ich diesen hinzu, damit Sie ihn in einem größeren Datensatz verwenden können. Dabei werden die Daten in den Trainings- und Testsets auf einen Wertebereich zwischen 0 und 1 herunterskaliert. Das reduziert den Rechenaufwand.
aus sklearn.preprocessing importieren Sie StandardScaler
sc = StandardSkalierer()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
Schritt 5 – Trainieren des Naive-Bayes-Klassifizierungsmodells auf dem Trainingssatz
In diesem Schritt importieren wir die Klasse Naive Bayes aus der sklearn-Bibliothek. Für dieses Modell verwenden wir das Gaußsche Modell, es gibt mehrere andere Modelle wie Bernoulli, Kategorial und Multinomial. Somit werden X_train und y_train zu Trainingszwecken an die Klassifikatorvariable angepasst.
aus sklearn.naive_bayes import GaussianNB
Klassifikator = GaussianNB()
classifier.fit(X_Zug, y_Zug)
Schritt 6 – Vorhersage der Ergebnisse des Testsets –
Wir sagen die Klasse der Art für den Testsatz unter Verwendung des trainierten Modells voraus und vergleichen sie mit den realen Werten der Artklasse.
y_pred = classifier.predict(X_test)
df = pd.DataFrame({'Echte Werte':y_test, 'Vorhergesagte Werte':y_pred})
df>>
Reale Werte Vorhergesagte Werte
Setosa Setosa
Setosa Setosa
jungfräuliche jungfräuliche
versicolor versicolor
Setosa Setosa
Setosa Setosa
… … … … …
virginica versicolor
jungfräuliche jungfräuliche
Setosa Setosa
Setosa Setosa
versicolor versicolor
versicolor versicolor
Im obigen Vergleich sehen wir, dass es eine falsche Vorhersage gibt, die Versicolor anstelle von Virginia vorhergesagt hat.
Schritt 7 – Verwirrungsmatrix und Genauigkeit
Da wir es mit der Klassifizierung zu tun haben, besteht die beste Möglichkeit zur Bewertung unseres Klassifikatormodells darin, die Verwirrungsmatrix zusammen mit ihrer Genauigkeit auf dem Testset auszudrucken.
aus sklearn.metrics importieren verwirrte_matrix
cm = Verwirrungsmatrix (y_test, y_pred) aus sklearn.metrics import precision_score
print („Genauigkeit : “, precision_score(y_test, y_pred))
cm>>Genauigkeit: 0,9666666666666667
>>array([[14, 0, 0],
[ 0, 7, 0],
[ 0, 1, 8]])
Fazit
Daher sind wir in diesem Artikel die Grundlagen des Naive-Bayes-Algorithmus durchgegangen, haben die Mathematik hinter der Klassifizierung zusammen mit einem von Hand gelösten Beispiel verstanden. Schließlich haben wir einen Code für maschinelles Lernen implementiert, um einen beliebten Datensatz mit dem Naive-Bayes-Klassifizierungsalgorithmus zu lösen.
Wenn Sie mehr über KI und maschinelles Lernen erfahren möchten, schauen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet. IIIT-B Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Wie hilfreich ist die Wahrscheinlichkeit beim maschinellen Lernen?
Möglicherweise müssen wir Entscheidungen auf der Grundlage von teilweisen oder unvollständigen Informationen in realen Szenarien treffen. Die Wahrscheinlichkeit hilft uns, die Unsicherheiten in solchen Systemen zu quantifizieren und das Risiko für die Aufgabe zu managen. Die traditionelle Methode funktioniert nur für die deterministischen Ergebnisse für bestimmte Aktionen, aber jedes Vorhersagemodell enthält immer einen gewissen Unsicherheitsbereich. Diese Unsicherheit kann von vielen Parametern aus den Eingabedaten herrühren, wie z. B. Rauschen in Daten. Auch bayessche Ansichten aus Wahrscheinlichkeitstheoremen können bei der Mustererkennung aus den Eingabedaten helfen. Hierfür verwendet Wahrscheinlichkeit das Konzept der Maximum-Likelihood-Schätzung und ist daher hilfreich, um relevante Ergebnisse zu erzielen.
Wozu dient die Confusion Matrix?
Die Konfusionsmatrix ist eine 2x2-Matrix, die verwendet wird, um die Leistung des Klassifizierungsmodells zu interpretieren. Damit dies funktioniert, müssen die wahren Werte für die Eingabedaten bekannt sein, daher können sie nicht für unbeschriftete Daten dargestellt werden. Sie besteht aus der Anzahl der falsch positiven (FP), richtig positiven (TP), falsch negativen (FN) und richtig negativen (TN). Die Vorhersagen werden anhand der Zählung aus dem Trainingssatz und dem Testsatz in diese Klassen eingeteilt. Es hilft uns, nützliche Parameter wie Genauigkeit, Präzision, Erinnerung und Spezifität zu visualisieren. Es ist relativ einfach zu verstehen und gibt Ihnen eine klare Vorstellung vom Algorithmus.
Welche Arten von Naive-Bayes-Modellen gibt es?
Alle Typen basieren hauptsächlich auf dem Satz von Bayes. Das Naive-Bayes-Modell hat im Allgemeinen drei Typen: Gaussian, Bernoulli und Multinomial. Das Gaussian Naive Bayes unterstützt mit kontinuierlichen Werten aus den Eingabeparametern und geht von der Annahme aus, dass alle Klassen von Eingabedaten gleichmäßig verteilt sind. Bernoulli's Naive Bayes ist ein ereignisbasiertes Modell, bei dem die Datenmerkmale unabhängig sind und in booleschen Werten vorhanden sind. Multinomial Naive Bayes basiert ebenfalls auf einem ereignisbasierten Modell. Es hat die Datenmerkmale in Vektorform, die relevante Häufigkeiten basierend auf dem Auftreten der Ereignisse darstellen.