
Materielles und immaterielles Mischen: Entwerfen multimodaler Schnittstellen mit Adobe XD
Veröffentlicht: 2022-03-10(Dieser Artikel wird freundlicherweise von Adobe gesponsert.) Benutzeroberflächen entwickeln sich weiter. Sprachgesteuerte Schnittstellen fordern die lange Dominanz grafischer Benutzeroberflächen heraus und werden schnell zu einem alltäglichen Bestandteil unseres täglichen Lebens. Bedeutende Fortschritte bei der automatischen Spracherkennung (APS) und der Verarbeitung natürlicher Sprache (NLP) sowie eine beeindruckende Kundenbasis (Millionen mobiler Geräte mit integrierten Sprachassistenten) haben die schnelle Entwicklung und Einführung sprachbasierter Schnittstellen beeinflusst.
Produkte, die Sprache als primäre Schnittstelle verwenden, werden immer beliebter. Allein in den USA haben 47,3 Millionen Erwachsene Zugang zu einem Smart Speaker (das ist ein Fünftel der erwachsenen US-Bevölkerung), Tendenz steigend. Aber Sprachschnittstellen haben nicht nur im persönlichen und privaten Gebrauch eine glänzende Zukunft. Wenn sich die Menschen an Sprachschnittstellen gewöhnen, werden sie diese auch im geschäftlichen Kontext erwarten. Stellen Sie sich vor, Sie könnten bald einen Projektor im Konferenzraum ansteuern, indem Sie etwas sagen wie „Zeigen Sie meine Präsentation“.
Es ist offensichtlich, dass sich die Mensch-Maschine-Kommunikation schnell ausdehnt und sowohl schriftliche als auch gesprochene Interaktionen umfasst. Aber bedeutet das, dass zukünftige Schnittstellen rein sprachlich sein werden? Trotz einiger Science-Fiction-Darstellungen wird Sprache grafische Benutzeroberflächen nicht vollständig ersetzen. Stattdessen haben wir eine Synergie aus Stimme, Bild und Gestik in einem neuen Schnittstellenformat: einer sprachgesteuerten, multimodalen Schnittstelle.
In diesem Artikel werden wir:
- Erforschen Sie das Konzept einer sprachaktivierten Schnittstelle und sehen Sie sich verschiedene Arten von sprachaktivierten Schnittstellen an;
- herauszufinden, warum sprachgesteuerte, multimodale Benutzeroberflächen die bevorzugte Benutzererfahrung sein werden;
- Sehen Sie, wie Sie mit Adobe XD eine multimodale Benutzeroberfläche erstellen können.
Der Zustand der Sprachbenutzeroberflächen (VUI)
Bevor wir in die Details von Sprachbenutzerschnittstellen eintauchen, müssen wir definieren, was Spracheingabe ist. Die Spracheingabe ist eine Mensch-Computer-Interaktion, bei der ein Benutzer Befehle spricht, anstatt sie zu schreiben. Das Schöne an der Spracheingabe ist, dass es sich um eine natürlichere Interaktion für Menschen handelt – Benutzer sind bei der Interaktion mit einem System nicht auf eine bestimmte Syntax beschränkt; Sie können ihre Eingaben auf viele verschiedene Arten strukturieren, genau wie sie es in einem menschlichen Gespräch tun würden.
Sprachbenutzerschnittstellen bieten ihren Benutzern die folgenden Vorteile:
- Weniger Interaktionskosten
Obwohl die Verwendung einer sprachgesteuerten Schnittstelle mit Interaktionskosten verbunden ist, sind diese Kosten (theoretisch) geringer als die Kosten für das Erlernen einer neuen GUI. - Freihändige Steuerung
VUIs eignen sich hervorragend, wenn die Hände des Benutzers beschäftigt sind – zum Beispiel beim Autofahren, Kochen oder Trainieren. - Geschwindigkeit
Die Stimme ist hervorragend, wenn das Stellen einer Frage schneller ist, als sie zu tippen und die Ergebnisse durchzulesen. Wenn Sie beispielsweise die Stimme in einem Auto verwenden, ist es schneller, den Ort zu einem Navigationssystem zu sagen, als den Ort auf einem Touchscreen einzugeben. - Emotion und Persönlichkeit
Selbst wenn wir eine Stimme hören, aber kein Bild eines Sprechers sehen, können wir uns den Sprecher in unserem Kopf vorstellen. Dies hat die Möglichkeit, die Benutzerbindung zu verbessern. - Barrierefreiheit
Sehbehinderte Benutzer und Benutzer mit eingeschränkter Mobilität können Sprache verwenden, um mit einem System zu interagieren.
Drei Arten von sprachgesteuerten Schnittstellen
Abhängig davon, wie Sprache verwendet wird, könnte es sich um eine der folgenden Arten von Schnittstellen handeln.
Sprachagenten in Screen-First-Geräten
Apple Siri und Google Assistant sind Paradebeispiele für Sprachagenten. Für solche Systeme wirkt die Stimme eher wie eine Erweiterung für die vorhandene GUI. In vielen Fällen fungiert der Agent als erster Schritt auf der Reise des Benutzers: Der Benutzer löst den Sprachagenten aus und gibt einen Befehl per Sprache, während alle anderen Interaktionen über den Touchscreen erfolgen. Wenn Sie Siri beispielsweise eine Frage stellen, werden Antworten im Format einer Liste bereitgestellt, und Sie müssen mit dieser Liste interagieren. Infolgedessen wird die Benutzererfahrung fragmentiert – wir verwenden die Stimme, um die Interaktion zu initiieren, und wechseln dann zur Berührung, um sie fortzusetzen.
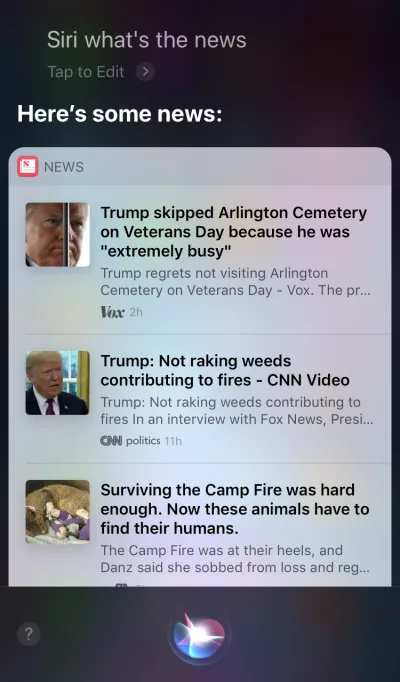
Nur-Voice-Geräte
Diese Geräte haben keine visuellen Anzeigen; Benutzer verlassen sich sowohl für die Eingabe als auch für die Ausgabe auf Audio. Amazon Echo und Google Home Smart Speakers sind Paradebeispiele für Produkte in dieser Kategorie. Das Fehlen einer visuellen Anzeige ist eine erhebliche Einschränkung der Fähigkeit des Geräts, Informationen und Optionen an den Benutzer zu übermitteln. Infolgedessen verwenden die meisten Menschen diese Geräte, um einfache Aufgaben zu erledigen, z. B. Musik abzuspielen und Antworten auf einfache Fragen zu erhalten.

Voice-First-Geräte
Bei Voice-First-Systemen akzeptiert das Gerät Benutzereingaben hauptsächlich über Sprachbefehle, verfügt aber auch über eine integrierte Bildschirmanzeige. Das bedeutet, dass Sprache die primäre Benutzerschnittstelle ist, aber nicht die einzige. Das alte Sprichwort „Ein Bild sagt mehr als tausend Worte“ gilt immer noch für moderne sprachgesteuerte Systeme. Das menschliche Gehirn hat unglaubliche Fähigkeiten zur Bildverarbeitung – wir können komplexe Informationen schneller verstehen, wenn wir sie visuell sehen. Im Vergleich zu reinen Sprachgeräten ermöglichen Voice-First-Geräte Benutzern den Zugriff auf eine größere Menge an Informationen und erleichtern viele Aufgaben erheblich.
Die Amazon Echo Show ist ein Paradebeispiel für ein Gerät, das ein Voice-First-System verwendet. Visuelle Informationen werden nach und nach als Teil eines ganzheitlichen Systems integriert – der Bildschirm wird nicht mit App-Symbolen geladen; Vielmehr ermutigt das System die Benutzer, verschiedene Sprachbefehle auszuprobieren (es schlägt verbale Befehle vor wie „Versuch es mit ‚Alexa, zeig mir das Wetter um 17:00 Uhr'“). Der Bildschirm macht sogar alltägliche Aufgaben wie das Überprüfen eines Rezepts beim Kochen viel einfacher – Benutzer müssen nicht genau zuhören und alle Informationen im Kopf behalten; Wenn sie die Informationen benötigen, schauen sie einfach auf den Bildschirm.

Einführung in multimodale Schnittstellen
Wenn es um die Verwendung von Sprache im UI-Design geht, denken Sie nicht an Sprache als etwas, das Sie alleine verwenden können. Geräte wie Amazon Echo Show verfügen über einen Bildschirm, verwenden jedoch Sprache als primäre Eingabemethode, was für ein ganzheitlicheres Benutzererlebnis sorgt. Dies ist der erste Schritt zu einer neuen Generation von Benutzerschnittstellen: multimodale Schnittstellen.
Eine multimodale Schnittstelle ist eine Schnittstelle, die Sprache, Berührung, Audio und verschiedene Arten von visuellen Elementen in einer einzigen, nahtlosen Benutzeroberfläche vereint. Amazon Echo Show ist ein hervorragendes Beispiel für ein Gerät, das die Vorteile einer sprachgesteuerten multimodalen Schnittstelle voll ausschöpft. Wenn Benutzer mit Show interagieren, stellen sie Anfragen, genau wie bei einem reinen Sprachgerät. Die Antwort, die sie erhalten, wird jedoch wahrscheinlich multimodal sein und sowohl sprachliche als auch visuelle Antworten enthalten.
Multimodale Produkte sind komplexer als Produkte, die nur auf Bild oder nur auf Sprache angewiesen sind. Warum sollte überhaupt jemand eine multimodale Schnittstelle erstellen? Um diese Frage zu beantworten, müssen wir einen Schritt zurücktreten und sehen, wie Menschen die Umwelt um sich herum wahrnehmen. Menschen haben fünf Sinne, und die Kombination unserer Sinne, die zusammenarbeiten, ist, wie wir Dinge wahrnehmen. Zum Beispiel arbeiten unsere Sinne zusammen, wenn wir bei einem Live-Konzert Musik hören. Entfernen Sie einen Sinn (z. B. das Hören), und die Erfahrung erhält einen völlig anderen Kontext.

Zu lange haben wir die Benutzererfahrung ausschließlich als visuelles oder gestisches Design betrachtet. Es ist an der Zeit, dieses Denken zu ändern. Multimodales Design ist eine Möglichkeit, über Erfahrungen nachzudenken und diese zu entwerfen, die unsere sensorischen Fähigkeiten miteinander verbinden.
Multimodale Schnittstellen fühlen sich wie eine menschlichere Art der Kommunikation zwischen Benutzer und Maschine an. Sie eröffnen neue Möglichkeiten für tiefere Interaktionen. Und heute ist es viel einfacher, multimodale Schnittstellen zu entwerfen, weil die technischen Einschränkungen, die in der Vergangenheit die Interaktion mit Produkten beschränkten, beseitigt wurden.
Der Unterschied zwischen einer GUI und einer multimodalen Schnittstelle
Der Hauptunterschied besteht darin, dass multimodale Schnittstellen wie Amazon Echo Show Sprach- und visuelle Schnittstellen synchronisieren. Wenn wir das Erlebnis entwerfen, sind daher die Stimme und die visuellen Elemente keine unabhängigen Teile mehr; Sie sind integrale Bestandteile der Erfahrung, die das System bietet.
Visueller und Sprachkanal: Wann jeweils zu verwenden
Es ist wichtig, Sprache und Bildmaterial als Kanäle für Ein- und Ausgabe zu betrachten. Jeder Kanal hat seine eigenen Stärken und Schwächen.
Beginnen wir mit der Optik. Es ist klar, dass manche Informationen einfach leichter zu verstehen sind, wenn wir sie sehen, als wenn wir sie hören. Visuals funktionieren besser, wenn Sie Folgendes bereitstellen müssen:
- eine lange Liste von Optionen (das Lesen einer langen Liste wird viel Zeit in Anspruch nehmen und schwer zu befolgen sein);
- datenintensive Informationen (wie Diagramme und Grafiken);
- Produktinformationen (z. B. Produkte in Online-Shops; höchstwahrscheinlich möchten Sie ein Produkt vor dem Kauf sehen) und Produktvergleich (wie bei der langen Liste von Optionen wäre es schwierig, alle Informationen nur mit Sprache bereitzustellen) .
Bei einigen Informationen können wir uns jedoch problemlos auf die mündliche Kommunikation verlassen. Voice könnte für die folgenden Fälle die richtige Lösung sein:
- Benutzerbefehle (Sprache ist eine effiziente Eingabemodalität, die es Benutzern ermöglicht, dem System schnell Befehle zu erteilen und komplexe Navigationsmenüs zu umgehen);
- einfache Gebrauchsanweisung (z. B. eine routinemäßige Überprüfung eines Rezepts);
- Warnungen und Benachrichtigungen (z. B. eine akustische Warnung gepaart mit Sprachbenachrichtigungen während der Fahrt).
Während dies einige typische Fälle von visueller und sprachlicher Kombination sind, ist es wichtig zu wissen, dass wir die beiden nicht voneinander trennen können. Wir können nur dann ein besseres Benutzererlebnis schaffen, wenn sowohl Sprache als auch visuelle Elemente zusammenarbeiten. Angenommen, wir möchten ein neues Paar Schuhe kaufen. Wir könnten die Stimme verwenden, um vom System zu verlangen: „Zeig mir New Balance-Schuhe.“ Das System würde Ihre Anfrage verarbeiten und Produktinformationen visuell bereitstellen (eine einfachere Möglichkeit für uns, Schuhe zu vergleichen).
Was Sie wissen müssen, um sprachgesteuerte, multimodale Schnittstellen zu entwerfen
Voice ist eine der spannendsten Herausforderungen für UX-Designer. Trotz seiner Neuartigkeit sind die grundlegenden Regeln für das Entwerfen einer sprachgesteuerten, multimodalen Benutzeroberfläche die gleichen wie die, die wir zum Erstellen visueller Designs verwenden. Designer sollten sich um ihre Benutzer kümmern. Sie sollten darauf abzielen, die Reibung für den Benutzer zu verringern, indem sie ihre Probleme auf effiziente Weise lösen, und Klarheit priorisieren, um die Entscheidungen des Benutzers klar zu machen.
Aber es gibt auch einige einzigartige Designprinzipien für multimodale Schnittstellen.
Stellen Sie sicher, dass Sie das richtige Problem lösen
Design soll Probleme lösen. Aber es ist wichtig, die richtigen Probleme zu lösen; Andernfalls könnten Sie viel Zeit damit verbringen, ein Erlebnis zu schaffen, das den Benutzern nicht viel Wert bringt. Stellen Sie daher sicher, dass Sie sich auf die Lösung des richtigen Problems konzentrieren. Sprachinteraktionen sollten für den Benutzer sinnvoll sein; Benutzer sollten einen überzeugenden Grund haben, Voice-over-andere Interaktionsmethoden (z. B. Klicken oder Tippen) zu verwenden. Aus diesem Grund ist es bei der Erstellung eines neuen Produkts – noch bevor mit dem Design begonnen wird – unerlässlich, eine Benutzerforschung durchzuführen und festzustellen, ob Sprache die UX verbessern würde.
Beginnen Sie mit der Erstellung einer User Journey Map. Analysieren Sie die Reisekarte und finden Sie Orte, an denen die Einbeziehung von Sprache als Kanal der UX zugute kommen würde.
- Finden Sie Stellen in der Journey, an denen Benutzer auf Reibung und Frustration stoßen könnten. Würde die Verwendung von Sprache die Reibung verringern?
- Denken Sie an den Kontext des Benutzers. Würde die Stimme für einen bestimmten Kontext funktionieren?
- Denken Sie darüber nach, was auf einzigartige Weise durch Sprache ermöglicht wird. Denken Sie an die einzigartigen Vorteile der Verwendung von Sprache, wie z. B. freihändige und augenfreie Interaktion. Könnte Sprache das Erlebnis aufwerten?
Konversationsflüsse erstellen
Idealerweise sollten die von Ihnen entworfenen Schnittstellen keine Interaktionskosten verursachen: Benutzer sollten in der Lage sein, ihre Bedürfnisse zu erfüllen, ohne zusätzliche Zeit damit zu verbringen, die Interaktion mit dem System zu lernen. Dies geschieht nur, wenn die Sprachinteraktion einem echten Gespräch ähnelt und nicht einem Systemdialog, der in das Format von Sprachbefehlen verpackt ist. Die Grundregel einer guten Benutzeroberfläche ist einfach: Computer sollten sich an den Menschen anpassen, nicht umgekehrt.
Menschen führen selten flache, lineare Gespräche (Gespräche, die nur eine Runde dauern). Damit sich die Interaktion mit einem System wie ein Live-Gespräch anfühlt, sollten sich Designer daher darauf konzentrieren, Gesprächsabläufe zu erstellen. Jeder Konversationsfluss besteht aus Dialogen – den Pfaden, die zwischen dem System und dem Benutzer auftreten. Jeder Dialog würde die Eingabeaufforderungen des Systems und die möglichen Antworten des Benutzers enthalten.
Ein Konversationsfluss kann in Form eines Flussdiagramms dargestellt werden. Jeder Flow sollte sich auf einen bestimmten Anwendungsfall konzentrieren (z. B. das Einstellen eines Weckers mit einem System). Für die meisten Dialoge in einem Flow ist es wichtig, Fehlerpfade zu berücksichtigen, wenn die Dinge aus dem Ruder laufen.
Jeder Sprachbefehl des Benutzers besteht aus drei Schlüsselelementen: Absicht, Äußerung und Slot.
- Die Absicht ist das Ziel der Interaktion des Benutzers mit einem sprachgesteuerten System.
Eine Absicht ist nur eine ausgefallene Art, den Zweck hinter einer Reihe von Wörtern zu definieren. Jede Interaktion mit einem System bringt dem Benutzer einen gewissen Nutzen. Ob es sich um Informationen oder eine Aktion handelt, das Dienstprogramm ist beabsichtigt. Die Absicht des Benutzers zu verstehen, ist ein entscheidender Teil sprachgesteuerter Schnittstellen. Wenn wir VUI entwerfen, wissen wir nicht immer genau, was die Absicht eines Benutzers ist, aber wir können es mit hoher Genauigkeit erraten. - Äußerung ist, wie der Benutzer seine Anfrage formuliert.
Normalerweise haben Benutzer mehr als eine Möglichkeit, einen Sprachbefehl zu formulieren. Zum Beispiel können wir einen Wecker stellen, indem wir sagen „Stelle den Wecker auf 8 Uhr“, oder „Wecker 8 Uhr morgen“ oder sogar „Ich muss um 8 Uhr aufwachen“. Designer müssen jede mögliche Variation der Äußerung berücksichtigen. - Slots sind Variablen, die Benutzer in einem Befehl verwenden. Manchmal müssen Benutzer in der Anfrage zusätzliche Informationen angeben. In unserem Beispiel des Weckers ist „8 Uhr“ ein Slot.
Legen Sie dem Benutzer keine Worte in den Mund
Die Leute wissen, wie man spricht. Versuchen Sie nicht, ihnen Befehle beizubringen. Vermeiden Sie Sätze wie „Um einen Besprechungstermin zu senden, müssen Sie „Kalender, Besprechungen, neue Besprechung erstellen“ sagen.“ Wenn Sie Befehle erklären müssen, müssen Sie die Art und Weise überdenken, wie Sie das System entwerfen. Streben Sie immer eine Konversation in natürlicher Sprache an und versuchen Sie, unterschiedliche Sprechstile zu berücksichtigen).
Strebe nach Konsistenz
Sie müssen kontextübergreifend Konsistenz in Sprache und Stimme erreichen. Konsistenz wird helfen, Vertrautheit in Interaktionen aufzubauen.
Geben Sie immer Feedback
Die Sichtbarkeit des Systemstatus ist eines der Grundprinzipien eines guten GUI-Designs. Das System sollte die Benutzer durch angemessenes Feedback innerhalb einer angemessenen Zeit immer darüber auf dem Laufenden halten, was vor sich geht. Die gleiche Regel gilt für das VUI-Design.
- Machen Sie dem Benutzer bewusst, dass das System zuhört.
Zeigen Sie visuelle Indikatoren an, wenn das Gerät die Anfrage des Benutzers abhört oder verarbeitet. Ohne Feedback kann der Benutzer nur raten, ob das System etwas tut. Deshalb geben uns sogar reine Sprachgeräte wie Amazon Echo und Google Home ein schönes visuelles Feedback (Blinklichter), wenn sie zuhören oder nach einer Antwort suchen. - Stellen Sie Gesprächsmarkierungen bereit.
Konversationsmarkierungen teilen dem Benutzer mit, wo er sich in der Konversation befindet. - Bestätigen, wenn eine Aufgabe abgeschlossen ist.
Wenn Benutzer beispielsweise das sprachgesteuerte Smart-Home-System fragen: „Schalte das Licht in der Garage aus“, sollte das System den Benutzer darüber informieren, dass der Befehl erfolgreich ausgeführt wurde. Ohne Bestätigung müssen Benutzer in die Garage gehen und die Lichter überprüfen. Es vereitelt den Zweck des Smart-Home-Systems, das Leben des Benutzers einfacher zu machen.
Vermeiden Sie lange Sätze
Berücksichtigen Sie beim Entwerfen eines sprachgesteuerten Systems die Art und Weise, wie Sie den Benutzern Informationen bereitstellen. Es ist relativ einfach, Benutzer mit zu vielen Informationen zu überfordern, wenn Sie lange Sätze verwenden. Erstens können Benutzer nicht viele Informationen in ihrem Kurzzeitgedächtnis behalten, sodass sie einige wichtige Informationen leicht vergessen können. Außerdem ist Audio ein langsames Medium – die meisten Menschen können viel schneller lesen als zuhören.
Gehen Sie respektvoll mit der Zeit Ihrer Benutzer um; lesen Sie keine langen Hörmonologe vor. Wenn Sie eine Antwort entwerfen, gilt: Je weniger Wörter Sie verwenden, desto besser. Aber denken Sie daran, dass Sie immer noch genügend Informationen bereitstellen müssen, damit der Benutzer seine Aufgabe ausführen kann. Wenn Sie also eine Antwort nicht in wenigen Worten zusammenfassen können, zeigen Sie sie stattdessen auf dem Bildschirm an.

Geben Sie der Reihe nach die nächsten Schritte an
Benutzer können nicht nur von langen Sätzen überwältigt werden, sondern auch von der Anzahl der Optionen auf einmal. Es ist wichtig, den Prozess der Interaktion mit einem sprachgesteuerten System in mundgerechte Stücke zu zerlegen. Beschränken Sie die Anzahl der Auswahlmöglichkeiten, die der Benutzer zu jedem Zeitpunkt hat, und stellen Sie sicher, dass er jederzeit weiß, was zu tun ist.
Wenn Sie ein komplexes sprachgesteuertes System mit vielen Funktionen entwerfen, können Sie die Technik der progressiven Offenlegung verwenden: Präsentieren Sie nur die Optionen oder Informationen, die zum Ausführen der Aufgabe erforderlich sind.
Haben Sie eine starke Fehlerbehandlungsstrategie
Natürlich soll das System Fehler erst gar nicht entstehen lassen. Aber egal wie gut Ihr sprachgesteuertes System ist, Sie sollten immer für das Szenario entwerfen, in dem das System den Benutzer nicht versteht. Es liegt in Ihrer Verantwortung, für solche Fälle zu entwerfen.
Hier sind ein paar praktische Tipps zum Erstellen einer Strategie:
- Geben Sie dem Benutzer keine Schuld.
Im Gespräch gibt es keine Fehler. Vermeiden Sie Antworten wie „Ihre Antwort ist falsch“. - Stellen Sie Flows zur Fehlerbehebung bereit.
Bieten Sie die Möglichkeit, in einem Gespräch hin und her zu gehen oder sogar das System zu verlassen, ohne wichtige Informationen zu verlieren. Speichern Sie den Status des Benutzers während der Reise, damit er direkt dort, wo er aufgehört hat, wieder mit dem System interagieren kann. - Lassen Sie Benutzer Informationen wiedergeben.
Geben Sie eine Option an, damit das System die Frage oder Antwort wiederholt. Dies kann bei komplexen Fragen oder Antworten hilfreich sein, bei denen es für den Benutzer schwierig wäre, alle Informationen in seinem Arbeitsgedächtnis festzuhalten. - Geben Sie einen Stoppwortlaut an.
In einigen Fällen ist der Benutzer nicht daran interessiert, sich eine Option anzuhören, und möchte, dass das System aufhört, darüber zu sprechen. Stop Wording sollte ihnen dabei helfen. - Gehen Sie elegant mit unerwarteten Äußerungen um.
Egal wie viel Sie in das Design eines Systems investieren, es wird Situationen geben, in denen das System den Benutzer nicht versteht. Es ist wichtig, mit solchen Fällen elegant umzugehen. Scheuen Sie sich nicht, dem System Unverständnis einzugestehen. Das System sollte kommunizieren, was es verstanden hat, und hilfreiche Rückmeldungen geben. - Verwenden Sie Analysen, um Ihre Fehlerstrategie zu verbessern.
Analytics kann Ihnen helfen, falsche Abzweigungen und Fehlinterpretationen zu erkennen.
Behalten Sie den Kontext im Auge
Stellen Sie sicher, dass das System den Kontext der Benutzereingabe versteht. Wenn beispielsweise jemand sagt, dass er nächste Woche einen Flug nach San Francisco buchen möchte, bezieht er sich während des Gesprächsflusses möglicherweise auf „es“ oder „die Stadt“. Das System sollte sich merken, was gesagt wurde, und es mit den neu erhaltenen Informationen abgleichen können.
Erfahren Sie mehr über Ihre Benutzer, um leistungsfähigere Interaktionen zu erstellen
Ein sprachgesteuertes System wird anspruchsvoller, wenn es zusätzliche Informationen (z. B. Benutzerkontext oder vergangenes Verhalten) verwendet, um zu verstehen, was der Benutzer möchte. Diese Technik wird als intelligente Interpretation bezeichnet und erfordert, dass das System aktiv etwas über den Benutzer lernt und in der Lage ist, sein Verhalten entsprechend anzupassen. Dieses Wissen hilft dem System, auch komplexe Fragen wie „Welches Geschenk soll ich zum Geburtstag meiner Frau kaufen?“ zu beantworten.
Verleihen Sie Ihrem VUI eine Persönlichkeit
Jedes sprachgesteuerte System hat eine emotionale Wirkung auf den Benutzer, ob Sie dies planen oder nicht. Menschen assoziieren Stimme eher mit Menschen als mit Maschinen. Laut einer Studie von Speak Easy Global Edition erwarten 74 % der regelmäßigen Nutzer von Sprachtechnologie, dass Marken einzigartige Stimmen und Persönlichkeiten für ihre sprachgesteuerten Produkte haben. Es ist möglich, Empathie durch Persönlichkeit aufzubauen und ein höheres Maß an Benutzerbindung zu erreichen.
Versuchen Sie, Ihre einzigartige Marke und Identität in der Stimme und im Ton widerzuspiegeln, die Sie präsentieren. Erstellen Sie eine Persona Ihres sprachaktivierten Agenten und verlassen Sie sich beim Erstellen von Dialogen auf diese Persona.
Vertrauen aufbauen
Wenn Benutzer einem System nicht vertrauen, fehlt ihnen die Motivation, es zu verwenden. Deshalb ist der Aufbau von Vertrauen eine Anforderung an das Produktdesign. Zwei Faktoren haben einen erheblichen Einfluss auf das aufgebaute Vertrauen: Systemfähigkeiten und valide Ergebnisse.
Der Aufbau von Vertrauen beginnt damit, die Erwartungen der Benutzer festzulegen. Herkömmliche GUIs haben viele visuelle Details, die dem Benutzer helfen zu verstehen, wozu das System in der Lage ist. Mit einem sprachgesteuerten System haben Designer weniger Werkzeuge, auf die sie sich verlassen können. Dennoch ist es wichtig, das System auf natürliche Weise erkennbar zu machen; der Benutzer sollte verstehen, was mit dem System möglich ist und was nicht. Aus diesem Grund erfordert ein sprachgesteuertes System möglicherweise ein Benutzer-Onboarding, bei dem darüber gesprochen wird, was das System kann oder was es weiß. Versuchen Sie beim Entwerfen des Onboardings, aussagekräftige Beispiele anzubieten, damit die Leute wissen, was es tun kann (Beispiele funktionieren besser als Anweisungen).
Wenn es um gültige Ergebnisse geht, wissen die Leute, dass sprachgesteuerte Systeme unvollkommen sind. Wenn ein System eine Antwort liefert, könnten einige Benutzer an der Richtigkeit der Antwort zweifeln. Dies geschieht, weil Benutzer keine Informationen darüber haben, ob ihre Anfrage richtig verstanden wurde oder welcher Algorithmus verwendet wurde, um die Antwort zu finden. Um Vertrauensproblemen vorzubeugen, verwenden Sie den Bildschirm für unterstützende Beweise – zeigen Sie die ursprüngliche Abfrage auf dem Bildschirm an – und geben Sie einige wichtige Informationen über den Algorithmus an. Wenn ein Benutzer beispielsweise fragt: „Zeig mir die fünf besten Filme des Jahres 2018“, kann das System sagen: „Hier sind die fünf besten Filme des Jahres 2018 nach Einspielzahlen in den USA“.
Ignorieren Sie Sicherheit und Datenschutz nicht
Im Gegensatz zu mobilen Geräten, die einer Person gehören, gehören Sprachgeräte eher einem Ort, wie einer Küche. Und normalerweise gibt es mehr als eine Person am selben Ort. Stellen Sie sich vor, jemand anderes könnte mit einem System interagieren, das Zugriff auf alle Ihre persönlichen Daten hat. Einige VUI-Systeme wie Amazon Alexa, Google Assistant und Apple Siri können einzelne Stimmen erkennen, was dem System eine zusätzliche Sicherheitsebene hinzufügt. Dennoch garantiert es nicht, dass das System Benutzer in 100 % der Fälle anhand ihrer eindeutigen Sprachsignatur erkennen kann.
Die Spracherkennung wird ständig verbessert, und es wird in naher Zukunft schwierig oder fast unmöglich sein, eine Stimme zu imitieren. In der aktuellen Realität ist es jedoch unerlässlich, eine zusätzliche Authentifizierungsebene bereitzustellen, um dem Benutzer zu versichern, dass seine Daten sicher sind. Wenn Sie eine App entwickeln, die mit sensiblen Daten wie Gesundheitsinformationen oder Bankdaten arbeitet, möchten Sie möglicherweise einen zusätzlichen Authentifizierungsschritt wie ein Passwort oder einen Fingerabdruck oder eine Gesichtserkennung einbeziehen.
Usability-Tests durchführen
Usability-Tests sind eine zwingende Voraussetzung für jedes System. Früh testen, oft testen sollte eine Grundregel Ihres Designprozesses sein. Sammeln Sie frühzeitig Daten aus der Benutzerforschung und iterieren Sie Ihre Designs. Das Testen multimodaler Schnittstellen hat jedoch seine eigenen Besonderheiten. Dabei sind zwei Phasen zu beachten:
- Ideenfindungsphase
Testen Sie Ihre Beispieldialoge. Üben Sie, Beispieldialoge laut zu lesen. Sobald Sie einige Konversationsabläufe haben, zeichnen Sie beide Seiten der Konversation auf (die Äußerungen des Benutzers und die Antworten des Systems) und hören Sie sich die Aufzeichnung an, um zu verstehen, ob sie natürlich klingen. - Frühe Phasen der Produktentwicklung (Testen mit Lo-Fi-Prototypen)
Wizard of Oz-Tests eignen sich gut zum Testen von Konversationsschnittstellen. Wizard of Oz-Tests sind eine Art von Tests, bei denen ein Teilnehmer mit einem System interagiert, von dem er glaubt, dass es von einem Computer betrieben wird, tatsächlich aber von einem Menschen betrieben wird. Der Testteilnehmer formuliert eine Anfrage, am anderen Ende antwortet eine reale Person. Diese Methode hat ihren Namen von dem Buch The Wonderful Wizard of Oz von Frank Baum. In dem Buch versteckt sich ein gewöhnlicher Mann hinter einem Vorhang und gibt vor, ein mächtiger Zauberer zu sein. Mit diesem Test können Sie jedes mögliche Interaktionsszenario abbilden und dadurch natürlichere Interaktionen erstellen. Say Wizard ist ein großartiges Tool, mit dem Sie einen Wizard of Oz-Sprachschnittstellentest unter macOS ausführen können. - Spätere Phasen der Produktentwicklung (Testen mit HiFi-Prototypen)
Bei Usability-Tests von grafischen Benutzeroberflächen bitten wir Benutzer oft, laut zu sprechen, wenn sie mit einem System interagieren. Für ein sprachaktiviertes System ist das nicht immer möglich, da das System dieser Erzählung zuhören würde. Daher ist es möglicherweise besser, die Interaktionen des Benutzers mit dem System zu beobachten, anstatt ihn zu bitten, laut zu sprechen.
So erstellen Sie eine multimodale Schnittstelle mit Adobe XD
Nachdem Sie nun ein solides Verständnis dafür haben, was eine multimodale Schnittstelle ist und welche Regeln Sie beim Entwerfen beachten müssen, können wir besprechen, wie Sie einen Prototyp einer multimodalen Schnittstelle erstellen.
Prototyping ist ein grundlegender Bestandteil des Designprozesses. In der Lage zu sein, eine Idee zum Leben zu erwecken und sie mit anderen zu teilen, ist extrem wichtig. Bisher hatten Designer, die Sprache in das Prototyping integrieren wollten, nur wenige Werkzeuge, auf die sie sich verlassen konnten, von denen das leistungsfähigste ein Flussdiagramm war. Sich vorzustellen, wie ein Benutzer mit einem System interagieren würde, erforderte viel Vorstellungskraft von jemandem, der sich das Flussdiagramm ansah. Mit Adobe XD haben Designer jetzt Zugriff auf das Medium Sprache und können es in ihren Prototypen verwenden. XD verbindet nahtlos Bildschirm- und Sprachprototyping in einer App.
Neue Erfahrungen, gleicher Prozess
Auch wenn Sprache ein völlig anderes Medium als visuelles Medium ist, ist der Prozess des Prototypings für Sprache in Adobe XD so ziemlich derselbe wie der Prototyping für eine GUI. Das Adobe XD-Team integriert Sprache auf eine Weise, die sich für jeden Designer natürlich und intuitiv anfühlt. Designer können Sprachauslöser und Sprachwiedergabe verwenden, um mit Prototypen zu interagieren:
- Sprachauslöser starten eine Interaktion, wenn ein Benutzer ein bestimmtes Wort oder einen Satz (Äußerung) sagt.
- Die Sprachwiedergabe gibt Designern Zugriff auf eine Text-to-Speech-Engine. XD spricht Wörter und Sätze, die von einem Designer definiert wurden. Die Sprachwiedergabe kann für viele verschiedene Zwecke verwendet werden. Beispielsweise kann es als Bestätigung (um Benutzer zu beruhigen) oder als Anleitung (damit Benutzer wissen, was als nächstes zu tun ist) dienen.
Das Tolle an XD ist, dass es Sie nicht dazu zwingt, sich mit der Komplexität der einzelnen Sprachplattformen vertraut zu machen.
Genug der Worte – mal sehen, wie es in Aktion funktioniert. Für alle Beispiele, die Sie unten sehen, habe ich Zeichenflächen verwendet, die mit dem Adobe XD UI-Kit für Amazon Alexa erstellt wurden (dies ist ein Link zum Herunterladen des Kits). Das Kit enthält alle Stile und Komponenten, die zum Erstellen von Erlebnissen für Amazon Alexa erforderlich sind.
Angenommen, wir haben die folgenden Zeichenflächen:
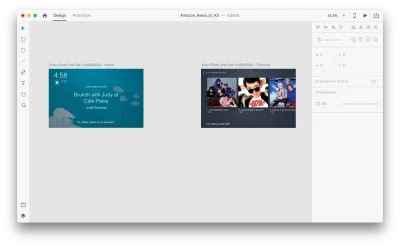
Gehen wir in den Prototyping-Modus, um einige Sprachinteraktionen hinzuzufügen. Wir beginnen mit Sprachauslösern. Neben Auslösern wie Tippen und Ziehen können wir jetzt auch die Stimme als Auslöser verwenden. Wir können beliebige Ebenen für Sprachauslöser verwenden, solange sie einen Griff haben, der zu einer anderen Zeichenfläche führt. Lassen Sie uns die Zeichenflächen miteinander verbinden.
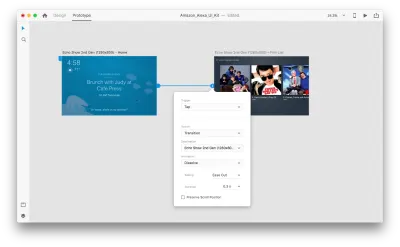
Sobald wir das getan haben, finden wir unter „Trigger“ eine neue „Voice“-Option. Wenn wir diese Option auswählen, sehen wir ein „Command“-Feld, das wir verwenden können, um eine Äußerung einzugeben – darauf wird XD tatsächlich hören. Benutzer müssen diesen Befehl sprechen, um den Auslöser zu aktivieren.
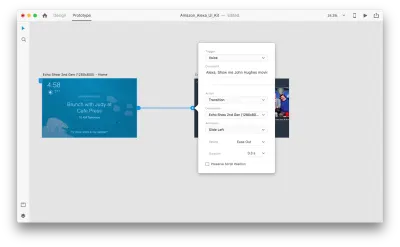
Das ist alles! Wir haben unsere erste Sprachinteraktion definiert. Jetzt können Benutzer etwas sagen, und ein Prototyp antwortet darauf. Aber wir können diese Interaktion viel leistungsfähiger machen, indem wir die Sprachwiedergabe hinzufügen. Wie ich bereits erwähnt habe, ermöglicht die Sprachwiedergabe einem System, einige Wörter zu sprechen.
Wählen Sie eine ganze zweite Zeichenfläche aus und klicken Sie auf den blauen Ziehpunkt. Wählen Sie einen „Time“-Trigger mit einer Verzögerung und stellen Sie ihn auf 0,2 s ein. Unter der Aktion finden Sie „Sprachwiedergabe“. Wir schreiben auf, was der virtuelle Assistent zu uns zurückspricht.
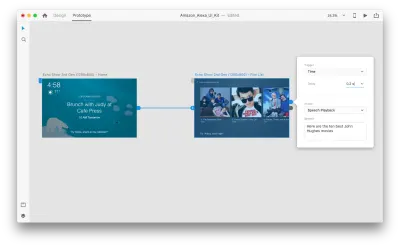
Wir sind bereit, unseren Prototypen zu testen. Wählen Sie die erste Zeichenfläche aus und klicken Sie oben rechts auf die Wiedergabeschaltfläche, um ein Vorschaufenster zu öffnen. Stellen Sie bei der Interaktion mit Voice Prototyping sicher, dass Ihr Mikrofon eingeschaltet ist. Halten Sie dann die Leertaste gedrückt, um den Sprachbefehl zu sprechen. Diese Eingabe löst die nächste Aktion im Prototyp aus.
Verwenden Sie Auto-Animate, um das Erlebnis dynamischer zu gestalten
Animation bringt viele Vorteile für das UI-Design. Es dient klaren funktionalen Zwecken, wie zum Beispiel:
- Kommunikation der räumlichen Beziehungen zwischen Objekten (Woher kommt das Objekt? Sind diese Objekte verwandt?);
- Erschwinglichkeit kommunizieren (Was kann ich als nächstes tun?)
Aber funktionale Zwecke sind nicht die einzigen Vorteile der Animation; Animation macht das Erlebnis auch lebendiger und dynamischer. Aus diesem Grund sollten UI-Animationen ein natürlicher Bestandteil multimodaler Schnittstellen sein.
Mit „Auto-Animate“, das in Adobe XD verfügbar ist, wird es viel einfacher, Prototypen mit immersiven animierten Übergängen zu erstellen. Adobe XD erledigt die ganze harte Arbeit für Sie, sodass Sie sich darüber keine Gedanken machen müssen. Alles, was Sie tun müssen, um einen animierten Übergang zwischen zwei Zeichenflächen zu erstellen, ist einfach eine Zeichenfläche zu duplizieren, die Objekteigenschaften im Klon zu ändern (Eigenschaften wie Größe, Position und Drehung) und eine Auto-Animate-Aktion anzuwenden. XD animiert automatisch die Unterschiede in den Eigenschaften zwischen den einzelnen Zeichenflächen.
Mal sehen, wie es in unserem Design funktioniert. Angenommen, wir haben eine vorhandene Einkaufsliste in Amazon Echo Show und möchten der Liste per Sprache ein neues Objekt hinzufügen. Duplizieren Sie die folgende Zeichenfläche:
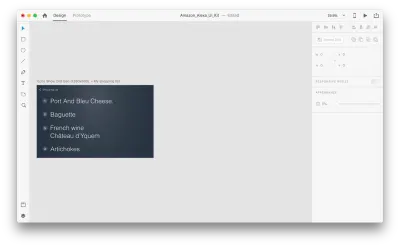
Lassen Sie uns einige Änderungen im Layout einführen: Fügen Sie ein neues Objekt hinzu. Wir sind hier nicht eingeschränkt, sodass wir alle Eigenschaften wie Textattribute, Farbe, Deckkraft und Position des Objekts problemlos ändern können – im Grunde genommen animiert XD alle Änderungen, die wir vornehmen, zwischen ihnen.
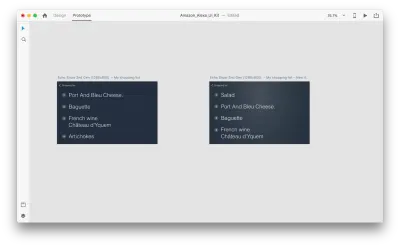
Wenn Sie zwei Zeichenflächen im Prototypmodus mit Auto-Animate in „Action“ miteinander verbinden, animiert XD automatisch die Unterschiede in den Eigenschaften zwischen jeder Zeichenfläche.
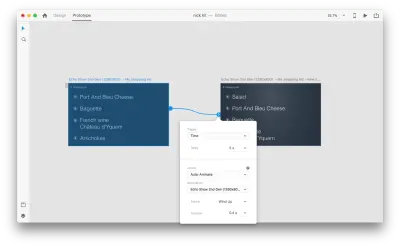
Und so sieht die Interaktion für die Benutzer aus:

Eine wichtige Sache, die erwähnt werden muss: Lassen Sie die Namen aller Ebenen gleich; Andernfalls kann Adobe XD die automatische Animation nicht anwenden.
Fazit
Wir stehen am Beginn einer Revolution der Benutzeroberfläche. Eine neue Generation von Schnittstellen – multimodale Schnittstellen – wird den Benutzern nicht nur mehr Macht geben, sondern auch die Art und Weise verändern, wie Benutzer mit Systemen interagieren. We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. You can start today.
Dieser Artikel ist Teil der von Adobe gesponserten UX-Designreihe. Das Adobe XD-Tool wurde für einen schnellen und flüssigen UX-Designprozess entwickelt, da Sie damit schneller von der Idee zum Prototyp gelangen können. Entwerfen, prototypisieren und teilen – alles in einer App. Sie können sich weitere inspirierende Projekte ansehen, die mit Adobe XD auf Behance erstellt wurden, und sich auch für den Adobe Experience Design-Newsletter anmelden, um auf dem Laufenden zu bleiben und über die neuesten Trends und Erkenntnisse für UX/UI-Design informiert zu bleiben.