
Lernprogramm für maschinelles Lernen: Lernen Sie ML von Grund auf neu
Veröffentlicht: 2022-02-17Der Einsatz von Lösungen für künstliche Intelligenz (KI) und maschinelles Lernen (ML) treibt weiterhin verschiedene Geschäftsprozesse voran , wobei die Verbesserung des Kundenerlebnisses der wichtigste Anwendungsfall ist.
Maschinelles Lernen hat heute ein breites Anwendungsspektrum, und die meisten davon sind Technologien, denen wir täglich begegnen. Beispielsweise verwenden Netflix oder ähnliche OTT-Plattformen maschinelles Lernen, um Vorschläge für jeden Benutzer zu personalisieren. Wenn sich ein Benutzer also häufig Krimis ansieht oder danach sucht, schlägt das ML-basierte Empfehlungssystem der Plattform weitere Filme eines ähnlichen Genres vor. Ebenso personalisieren Facebook und Instagram den Feed eines Benutzers basierend auf Posts, mit denen sie häufig interagieren.
In diesem Python-Tutorial zum maschinellen Lernen tauchen wir in die Grundlagen des maschinellen Lernens ein. Wir haben auch ein kurzes Deep-Learning-Tutorial hinzugefügt, um Anfängern das Konzept vorzustellen.
Inhaltsverzeichnis
Was ist maschinelles Lernen?
Der Begriff „Machine Learning“ wurde 1959 von Arthur Samuel geprägt, einem Wegbereiter für Computerspiele und künstliche Intelligenz.
Maschinelles Lernen ist eine Teilmenge der künstlichen Intelligenz. Es basiert auf dem Konzept, dass Software (Programme) aus Daten lernen, Muster entschlüsseln und Entscheidungen mit minimalem menschlichen Eingriff treffen kann. Mit anderen Worten, ML ist ein Bereich der Computational Science, der es einem Benutzer ermöglicht, eine enorme Datenmenge in einen Algorithmus einzuspeisen und das System analysieren zu lassen und datengesteuerte Entscheidungen basierend auf den Eingabedaten zu treffen. Daher verlassen sich ML-Algorithmen nicht auf ein vorgegebenes Modell, sondern „lernen“ Informationen direkt aus den eingespeisten Daten.
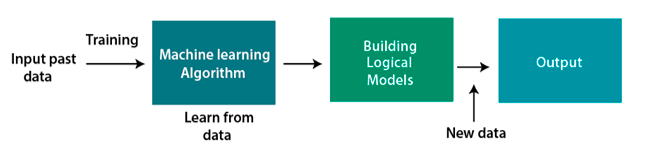
Quelle

Hier ist ein vereinfachtes Beispiel –
Wie schreiben wir ein Programm, das Blumen anhand von Farbe, Blütenblattform oder anderen Eigenschaften identifiziert? Während der naheliegendste Weg darin bestünde, Hardcore-Identifikationsregeln aufzustellen, wird ein solcher Ansatz nicht in allen Fällen ideale Regeln anwendbar machen. Maschinelles Lernen verfolgt jedoch eine praktischere und robustere Strategie und trainiert das System, anstatt vorgegebene Regeln aufzustellen, indem es Daten (Bilder) verschiedener Blumen füttert. Wenn dem System also das nächste Mal eine Rose und eine Sonnenblume gezeigt werden, kann es die beiden basierend auf früheren Erfahrungen klassifizieren.
Lesen Sie , wie man maschinelles Lernen lernt – Schritt für Schritt
Arten des maschinellen Lernens
Die Klassifizierung durch maschinelles Lernen basiert darauf, wie ein Algorithmus lernt, Ergebnisse genauer vorherzusagen. Daher gibt es drei grundlegende Ansätze für maschinelles Lernen: überwachtes Lernen, unüberwachtes Lernen und bestärkendes Lernen.
Überwachtes Lernen
Beim überwachten maschinellen Lernen werden die Algorithmen mit gelabelten Trainingsdaten versorgt. Außerdem definiert der Benutzer die Variablen, die der Algorithmus bewerten soll; Die Zielvariablen sind die Variablen, die wir vorhersagen möchten, und Merkmale sind die Variablen, die uns helfen, das Ziel vorherzusagen. Es ist also eher so, dass wir dem Algorithmus das Bild eines Fisches zeigen und sagen: „Das ist ein Fisch“, und dann zeigen wir einen Frosch und weisen darauf hin, dass es ein Frosch ist. Wenn der Algorithmus dann mit genügend Fisch- und Froschdaten trainiert wurde, lernt er, zwischen ihnen zu unterscheiden.
Unbeaufsichtigtes Lernen
Unüberwachtes maschinelles Lernen beinhaltet Algorithmen, die aus unbeschrifteten Trainingsdaten lernen. Es gibt also nur die Merkmale (Eingabevariablen) und keine Zielvariablen. Zu den Problemen des unbeaufsichtigten Lernens gehört das Clustering, bei dem Eingabevariablen mit denselben Merkmalen gruppiert und verknüpft werden, um sinnvolle Beziehungen innerhalb des Datensatzes zu entschlüsseln. Ein Beispiel für Clustering ist die Gruppierung von Menschen in Raucher und Nichtraucher. Im Gegenteil, die Entdeckung, dass Kunden, die Smartphones verwenden, auch Handyhüllen kaufen, ist eine Assoziation.
Verstärkungslernen
Reinforcement Learning ist eine Feed-basierte Technik, bei der die Modelle des maschinellen Lernens lernen, eine Reihe von Entscheidungen auf der Grundlage des Feedbacks zu treffen, das sie für ihre Aktionen erhalten. Für jede gute Aktion erhält die Maschine ein positives Feedback, und für jede schlechte eine Strafe oder ein negatives Feedback. Im Gegensatz zum überwachten maschinellen Lernen lernt ein verstärktes Modell also automatisch anhand von Feedback anstelle von beschrifteten Daten.
Lesen Sie auch, was maschinelles Lernen ist und warum es wichtig ist
Warum Python für maschinelles Lernen verwenden?
Machine-Learning-Projekte unterscheiden sich von traditionellen Softwareprojekten dadurch, dass Erstere unterschiedliche Fähigkeiten, Technologie-Stacks und tiefgreifende Forschung beinhalten. Daher erfordert die Implementierung eines erfolgreichen maschinellen Lernprojekts eine Programmiersprache, die stabil und flexibel ist und robuste Tools bietet. Python bietet alles, daher sehen wir hauptsächlich Python-basierte Machine-Learning-Projekte.
Plattformunabhängigkeit
Die Popularität von Python ist größtenteils darauf zurückzuführen, dass es sich um eine plattformunabhängige Sprache handelt, die von den meisten Plattformen unterstützt wird, einschließlich Windows, macOS und Linux. So können Entwickler eigenständige ausführbare Programme auf einer Plattform erstellen und diese auf andere Betriebssysteme verteilen, ohne dass ein Python-Interpreter erforderlich ist. Daher werden Trainingsmodelle für maschinelles Lernen überschaubarer und billiger.

Einfachheit und Flexibilität
Hinter jedem maschinellen Lernmodell stehen komplexe Algorithmen und Arbeitsabläufe, die für Benutzer einschüchternd und überwältigend sein können. Aber der prägnante und lesbare Code von Python ermöglicht es Entwicklern, sich auf das maschinelle Lernmodell zu konzentrieren, anstatt sich um die technischen Einzelheiten der Sprache zu kümmern. Darüber hinaus ist Python leicht zu erlernen und kann komplizierte Aufgaben des maschinellen Lernens bewältigen, was zu einem schnellen Erstellen und Testen von Prototypen führt.
Eine große Auswahl an Frameworks und Bibliotheken
Python bietet eine umfangreiche Auswahl an Frameworks und Bibliotheken, die die Entwicklungszeit deutlich verkürzen. Solche Bibliotheken haben vorgefertigte Codes, die Entwickler verwenden, um allgemeine Programmieraufgaben zu erledigen. Pythons Repertoire an Softwaretools umfasst Scikit-learn, TensorFlow und Keras für maschinelles Lernen, Pandas für allgemeine Datenanalyse, NumPy und SciPy für Datenanalyse und wissenschaftliches Rechnen, Seaborn für Datenvisualisierung und mehr.
Lernen Sie auch die Datenvorverarbeitung beim maschinellen Lernen: 7 einfache Schritte zum Befolgen
Schritte zum Implementieren eines Python-Projekts für maschinelles Lernen
Wenn Sie mit maschinellem Lernen noch nicht vertraut sind, können Sie sich am besten mit einem Projekt auseinandersetzen, indem Sie die wichtigsten Schritte auflisten, die Sie abdecken müssen. Sobald Sie die Schritte haben, können Sie sie als Vorlage für nachfolgende Datensätze verwenden, Lücken füllen und Ihren Arbeitsablauf ändern, wenn Sie in fortgeschrittene Phasen übergehen.
Hier ist eine Übersicht, wie Sie ein Machine-Learning-Projekt mit Python implementieren:
- Definiere das Problem.
- Installieren Sie Python und SciPy.
- Laden Sie den Datensatz.
- Fassen Sie den Datensatz zusammen.
- Visualisieren Sie den Datensatz.
- Algorithmen auswerten.
- Voraussagen machen.
- Ergebnisse präsentieren.
Was ist ein Deep-Learning-Netzwerk?
Deep Learning Networks oder Deep Neural Networks (DNNs) sind ein Zweig des maschinellen Lernens, der auf der Nachahmung des menschlichen Gehirns basiert. DNNs umfassen Einheiten, die mehrere Eingaben kombinieren, um eine einzige Ausgabe zu erzeugen. Sie sind analog zu den biologischen Neuronen, die mehrere Signale über Synapsen empfangen und einen einzelnen Strom eines Aktionspotentials durch ihr Neuron senden.
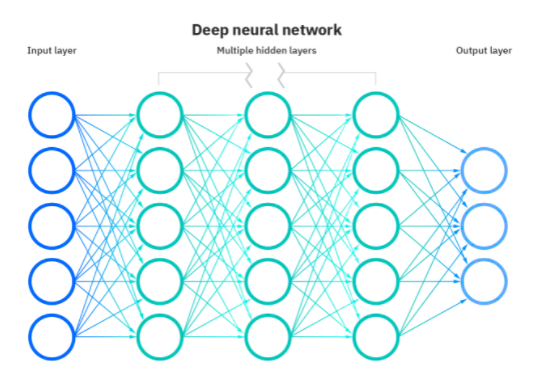
Quelle
In einem neuronalen Netzwerk wird die gehirnähnliche Funktionalität durch Knotenschichten erreicht, die aus einer Eingabeschicht, einer oder mehreren verborgenen Schichten und einer Ausgabeschicht bestehen. Jedes künstliche Neuron oder jeder Knoten hat einen zugehörigen Schwellenwert und ein Gewicht und ist mit einem anderen verbunden. Wenn die Ausgabe eines Knotens über dem definierten Schwellenwert liegt, wird er aktiviert und sendet Daten an die nächste Schicht im Netzwerk.
DNNs sind auf Trainingsdaten angewiesen, um ihre Genauigkeit im Laufe der Zeit zu lernen und zu optimieren. Sie stellen robuste Werkzeuge der künstlichen Intelligenz dar, die Datenklassifizierung und Clustering mit hoher Geschwindigkeit ermöglichen. Zwei der häufigsten Anwendungsdomänen tiefer neuronaler Netze sind die Bilderkennung und die Spracherkennung.
Weg nach vorn
Sei es das Entsperren eines Smartphones mit Face ID, das Durchsuchen von Filmen oder das Suchen eines zufälligen Themas bei Google, moderne, digital orientierte Verbraucher verlangen oberflächliche Empfehlungen und eine bessere Personalisierung. Unabhängig von der Branche oder Domäne hat und spielt KI eine bedeutende Rolle bei der Verbesserung der Benutzererfahrung. Hinzu kommt, dass die Einfachheit und Vielseitigkeit von Python die Entwicklung, Bereitstellung und Wartung von KI-Projekten plattformübergreifend bequem und effizient gemacht haben.
Lernen Sie ML-Kurse von den besten Universitäten der Welt. Erwerben Sie Master-, Executive PGP- oder Advanced Certificate-Programme, um Ihre Karriere zu beschleunigen.
Wenn Sie dieses Python-Tutorial für maschinelles Lernen für Anfänger interessant fanden, tauchen Sie mit upGrads Master of Science in Machine Learning & AI tiefer in das Thema ein . Das Online-Programm richtet sich an Berufstätige, die fortgeschrittene KI-Fähigkeiten wie NLP, Deep Learning, Reinforcement Learning und mehr erlernen möchten.
Kurs-Highlights:
- Master-Abschluss an der LJMU
- Executive PGP von IIIT Bangalore
- Über 750 Stunden Inhalt
- Über 40 Live-Sessions
- Über 12 Fallstudien und Projekte
- 11 Codierungsaufgaben
- Ausführliche Abdeckung von 20 Tools, Sprachen und Bibliotheken
- 360-Grad-Karrierehilfe
1. Ist Python gut für maschinelles Lernen?
Python ist eine der besten Programmiersprachen für die Implementierung von Modellen für maschinelles Lernen. Python spricht Entwickler und Anfänger gleichermaßen aufgrund seiner Einfachheit, Flexibilität und sanften Lernkurve an. Darüber hinaus ist Python plattformunabhängig und hat Zugriff auf Bibliotheken und Frameworks, die das Erstellen und Testen von Modellen für maschinelles Lernen schneller und einfacher machen.
2. Ist maschinelles Lernen mit Python schwer?
Aufgrund der weit verbreiteten Popularität von Python als Allzweck-Programmiersprache und ihrer Einführung in maschinelles Lernen und wissenschaftliches Rechnen ist es ziemlich einfach, ein Python-Tutorial für maschinelles Lernen zu finden. Außerdem machen die sanfte Lernkurve, der lesbare und präzise Code von Python Python zu einer anfängerfreundlichen Programmiersprache.
3. Ist KI und maschinelles Lernen dasselbe?
Obwohl die Begriffe KI und maschinelles Lernen oft synonym verwendet werden, sind sie nicht dasselbe. Künstliche Intelligenz (KI) ist der Überbegriff für den Zweig der Informatik, der sich mit Maschinen befasst, die in der Lage sind, Aufgaben zu erledigen, die normalerweise von Menschen erledigt werden. Maschinelles Lernen ist jedoch eine Teilmenge der KI, bei der Maschinen mit Daten gefüttert und darauf trainiert werden, Entscheidungen auf der Grundlage der Eingabedaten zu treffen.