
15 Fragen und Antworten zu maschinellen Lerninterviews für 2022
Veröffentlicht: 2021-01-08Sie möchten im Bereich Machine Learning erfolgreich Karriere machen? Wenn ja, toll für dich!
Aber zuerst müssen Sie sich auf den Eisbrecher vorbereiten – das ML-Interview.
Da die Vorbereitung auf ein Vorstellungsgespräch überwältigend sein kann, haben wir uns entschieden, einzugreifen – hier ist eine kuratierte Liste der 15 am häufigsten gestellten Fragen in Interviews mit maschinellem Lernen!
- Was ist der Unterschied zwischen Deep Learning und maschinellem Lernen?
Während maschinelles Lernen die Anwendung und Verwendung fortschrittlicher Algorithmen zum Analysieren von Daten beinhaltet, entdecken Sie die verborgenen Muster in den Daten und lernen Sie daraus und wenden Sie schließlich die erlernten Erkenntnisse an, um fundierte Geschäftsentscheidungen zu treffen. Deep Learning ist eine Teilmenge des maschinellen Lernens, bei der künstliche neuronale Netze verwendet werden, die sich von der neuronalen Netzstruktur des menschlichen Gehirns inspirieren lassen. Deep Learning wird häufig in der Merkmalserkennung eingesetzt.
- Definieren – Präzision und Rückruf.
Präzision oder positiver Vorhersagewert misst oder sagt genauer die Anzahl der von einem Modell behaupteten wahren Positiven im Vergleich zu der Anzahl der tatsächlich behaupteten Positiven voraus.
Die Rückruf- oder Richtig-Positiv-Rate bezieht sich auf die Anzahl der von einem Modell behaupteten positiven Ergebnisse im Vergleich zur tatsächlichen Anzahl der in den Daten vorhandenen positiven Ergebnisse.

Nehmen Sie online am Machine Learning-Kurs der weltbesten Universitäten teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
- Erklären Sie die Begriffe „Bias“ und „Varianz“. '
Während des Trainingsprozesses wird der erwartete Fehler eines Lernalgorithmus im Allgemeinen klassifiziert oder in zwei Teile zerlegt – Bias und Varianz. Während „Bias“ eine Fehlersituation ist, die durch die Verwendung einfacher Annahmen im Lernalgorithmus verursacht wird, bezeichnet „Varianz“ einen Fehler, der durch die Komplexität dieses Lernalgorithmus bei der Datenanalyse verursacht wird. Bias misst die Nähe des vom Lernalgorithmus erstellten durchschnittlichen Klassifikators zur Zielfunktion, und die Varianz misst, wie stark die Vorhersage des Lernalgorithmus für verschiedene Trainingsdatensätze variiert.
- Wie funktioniert eine ROC-Kurve?
Die ROC- oder Receiver Operating Characteristic-Kurve ist eine grafische Darstellung der Variation zwischen True-Positive-Raten und Falsch-Positiv-Raten bei unterschiedlichen Schwellenwerten. Es ist ein grundlegendes Werkzeug für die Bewertung diagnostischer Tests und wird häufig als Darstellung des Kompromisses zwischen der Empfindlichkeit des Modells (wahre positive Ergebnisse) und der Wahrscheinlichkeit des Auslösens von Fehlalarmen (falsche positive Ergebnisse) verwendet.
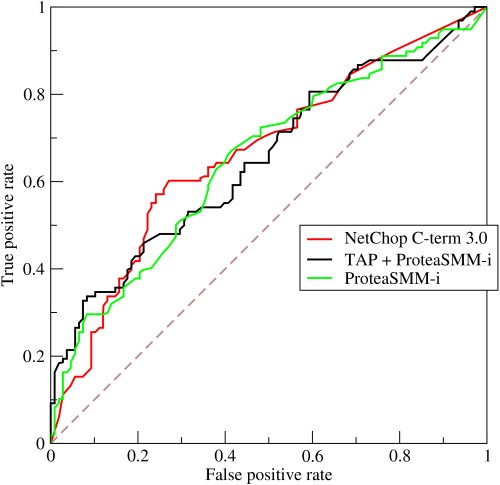
Quelle
- Die Kurve zeigt den Kompromiss zwischen Sensitivität und Spezifität – wenn die Sensitivität zunimmt, nimmt die Spezifität ab.
- Wenn die Kurve mehr an die linke Achse und den oberen Rand des ROC-Raums grenzt, ist der Test normalerweise genauer. Kommt die Kurve jedoch näher an die 45-Grad-Diagonale des ROC-Raums heran, ist der Test weniger genau oder zuverlässig.
- Die Steigung der Tangente an einem Schnittpunkt gibt das Wahrscheinlichkeitsverhältnis (LR) für diesen bestimmten Testwert an.
- Die Fläche unter der Kurve misst die Testgenauigkeit.
- Erklären Sie den Unterschied zwischen Fehlern vom Typ 1 und Typ 2?
Fehler vom Typ 1 ist ein falsch positiver Fehler, der „behauptet“, dass ein Vorfall aufgetreten ist, obwohl tatsächlich nichts passiert ist. Das beste Beispiel für einen falsch positiven Fehler ist ein falscher Feueralarm – der Alarm beginnt zu läuten, wenn es kein Feuer gibt. Im Gegensatz dazu ist ein Typ-2-Fehler ein falsch negativer Fehler, der „behauptet“, dass nichts passiert ist, obwohl definitiv etwas passiert ist. Es wäre ein Typ-2-Fehler, einer schwangeren Frau zu sagen, dass sie kein Baby trägt.
- Warum wird Bayes als „Naive Bayes“ bezeichnet?
Naive Bayes wird als „naiv“ bezeichnet, weil es, obwohl es viele praktische Anwendungen hat, auf der Annahme basiert, dass es unmöglich ist, in realen Daten zu finden – alle Merkmale in einem Datensatz sind entscheidend, unabhängig und gleich. Beim Naive-Bayes-Ansatz wird die bedingte Wahrscheinlichkeit als reines Produkt der Wahrscheinlichkeiten einzelner Komponenten berechnet, wodurch die vollständige Unabhängigkeit von Merkmalen impliziert wird. Leider kann diese Annahme in einem realen Szenario niemals erfüllt werden.
- Was versteht man unter dem Begriff „Overfitting“? Kannst du es vermeiden? Wenn das so ist, wie?
Üblicherweise wird ein Modell während des Trainingsprozesses mit großen Datenmengen gefüttert. Im Laufe des Prozesses lernen die Daten sogar aus den im Beispieldatensatz vorhandenen ungenauen Informationen und Rauschen. Dies erzeugt einen negativen Einfluss auf die Leistung des Modells bei neuen Daten, das heißt, das Modell kann neue Instanzen/Daten abgesehen von denen des Trainingssatzes nicht genau klassifizieren. Dies wird als Überanpassung bezeichnet.
Ja, es ist möglich, Overfitting zu vermeiden. Hier ist wie:
- Sammeln Sie mehr Daten (aus unterschiedlichen Quellen), um das Modell mit verschiedenen Stichproben zu trainieren.
- Wenden Sie Ensembling-Methoden (z. B. Random Forest) an, die den Bagging-Ansatz verwenden, um die Variation in den Vorhersagen zu minimieren, indem Sie die Ergebnisse mehrerer Entscheidungsbäume auf verschiedenen Einheiten des Datensatzes nebeneinander stellen.
- Stellen Sie sicher, dass Sie Kreuzvalidierungstechniken verwenden.
- Nennen Sie die zwei Methoden, die für die Kalibrierung im überwachten Lernen verwendet werden.
Die beiden Kalibrierungsmethoden im überwachten Lernen sind – Platt-Kalibrierung und isotonische Regression. Diese beiden Verfahren sind speziell für die binäre Klassifikation ausgelegt.
- Warum beschneidet man einen Entscheidungsbaum?
Entscheidungsbäume müssen beschnitten werden, um die Zweige mit schwachen Vorhersagefähigkeiten loszuwerden. Dies trägt dazu bei, den Komplexitätsquotienten des Entscheidungsbaummodells zu minimieren und seine Vorhersagegenauigkeit zu optimieren. Der Schnitt kann entweder von oben nach unten oder von unten nach oben erfolgen. Reduzierte Fehlerbereinigung, Kostenkomplexitätsbereinigung, Fehlerkomplexitätsbereinigung und minimale Fehlerbereinigung sind einige der am häufigsten verwendeten Entscheidungsbaum-Bereinigungsmethoden.

- Was ist mit F1-Score gemeint?
Einfach ausgedrückt ist der F1-Score ein Maß für die Leistung eines Modells – ein Durchschnitt der Genauigkeit und der Wiedererkennung eines Modells, wobei Ergebnisse nahe 1 die besten und solche nahe 0 die schlechtesten sind. Der F1-Score kann in Klassifizierungstests verwendet werden, die keinen Wert auf echte Negative legen.
- Unterscheiden Sie zwischen einem generativen und einem diskriminativen Algorithmus.
Während ein generativer Algorithmus die Datenkategorien lernt, lernt ein diskriminativer Algorithmus die Unterscheidung zwischen verschiedenen Datenkategorien. Wenn es um Klassifikationsaufgaben geht, übertreffen diskriminative Modelle typischerweise generative Modelle.
- Was ist Ensemble-Lernen?
Ensemble Learning verwendet eine Kombination von Lernalgorithmen, um die Vorhersageleistung von Modellen zu optimieren. Bei dieser Methode werden mehrere Modelle wie Klassifikatoren oder Experten strategisch generiert und kombiniert, um eine Überanpassung in Modellen zu verhindern. Es wird hauptsächlich verwendet, um die Vorhersage, Klassifizierung, Funktionsnäherung, Leistung usw. eines Modells zu verbessern.
- Definiere "Kernel-Trick".
Die Kernel-Trick-Methode beinhaltet die Verwendung von Kernel-Funktionen, die in einem höherdimensionalen und impliziten Merkmalsraum arbeiten können, ohne dass die Koordinaten von Punkten innerhalb dieser Dimension explizit berechnet werden müssen. Kernfunktionen berechnen die Skalarprodukte zwischen den Bildern aller Datenpaare, die in einem Merkmalsraum vorhanden sind. Dieses Verfahren ist im Vergleich zur expliziten Berechnung der Koordinaten rechengünstiger und wird als Kernel-Trick bezeichnet.
- Wie sollten Sie mit fehlenden oder beschädigten Daten in einem Datensatz umgehen?
Um die fehlenden/beschädigten Daten in einem Datensatz zu finden, müssen Sie die Zeilen und Spalten entweder löschen oder durch andere Werte ersetzen. Die Pandas-Bibliothek hat zwei großartige Methoden, um fehlende/beschädigte Daten zu finden – isnull() und dropna(). Diese beiden Funktionen wurden speziell entwickelt, um Ihnen zu helfen, die Zeilen/Spalten von Daten mit fehlenden/beschädigten Daten zu finden und diese Werte zu löschen.
- Was ist eine Hash-Tabelle?
Eine Hash-Tabelle ist eine Datenstruktur, die ein assoziatives Array erstellt, wobei ein Schlüssel mithilfe einer Hash-Funktion bestimmten Werten zugeordnet wird. Hash-Tabellen werden hauptsächlich bei der Datenbankindizierung verwendet.
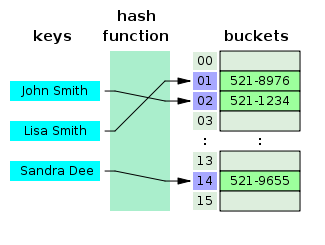
Quelle
Diese Liste von Fragen soll Sie nur in die Grundlagen des maschinellen Lernens einführen, und ehrlich gesagt sind diese zwanzig Fragen nur ein Tropfen auf den heißen Stein. Maschinelles Lernen schreitet voran, während wir hier sprechen, und daher werden mit der Zeit neue Konzepte entstehen. Der Schlüssel zum Erfolg Ihrer ML-Interviews liegt daher in einem ständigen Drang zu lernen und sich weiterzubilden. Fangen Sie also an und durchforsten Sie das Internet, lesen Sie Zeitschriften, treten Sie Online-Communities bei, besuchen Sie ML-Konferenzen und -Seminare – es gibt so viele Möglichkeiten zu lernen.
Um in eine große Organisation einzutreten, ist ein Zertifikat einer renommierten Institution unerlässlich. Informieren Sie sich über das Executive PG-Programm von IIIT-B für maschinelles Lernen und KI und erhalten Sie Unterstützung bei der Arbeit von führenden ML- und KI-Unternehmen.
Was sind die Grenzen des Ensemble-Lernens?
Ensemble-Ansätze können bei der Reduzierung der Varianz und der Entwicklung robusterer Modelle helfen. Es gibt jedoch bestimmte Nachteile bei der Verwendung von Ensemble-Techniken, wie z. B. mangelnde Erklärbarkeit und Leistung. Denken Sie außerdem daran, dass die Wirksamkeit von Ensembles von ihrer Fähigkeit herrührt, mehrere Modelle zu aggregieren, die sich auf verschiedene Aspekte des Problems konzentrieren. Sie haben jedoch einen längeren Prognosezeitraum, da Sie möglicherweise Prognosen von Hunderten von Modellen benötigen. Selbst wenn sie bessere Projektionen haben, lohnt sich der Gewinn an Genauigkeit möglicherweise nicht.
Wie viel Zeit wird benötigt, um Machine Learning zu lernen?
Wenn es um maschinelles Lernen geht, können die dafür verwendeten komplexen Technologien die Menschen leicht erschrecken. Es ist jedoch nicht schwierig, es Stück für Stück zu verstehen. Vorkenntnisse in Statistik, fortgeschrittener Mathematik usw. werden Ihnen zweifellos dabei helfen, alle Konzepte schnell zu verstehen. Da jedoch der Bildungshintergrund und die Fähigkeiten von Person zu Person unterschiedlich sind, kann eine Person ML in drei Wochen lernen, während eine andere ein Jahr benötigen kann.
Wie wird maschinelles Lernen in unserem täglichen Leben eingesetzt?
Google Mail kategorisiert E-Mails als wesentlich, indem es sie mithilfe von maschinellem Lernen als primär, Werbeaktionen, soziale Netzwerke und Aktualisierungen sortiert. Unternehmen nutzen neuronale Netze, um betrügerische Transaktionen anhand von Daten wie der letzten Transaktionshäufigkeit, dem Transaktionsbetrag und dem Händlertyp zu erkennen. Auch Plagiatsdetektoren nutzen maschinelles Lernen. Beim ML-Engineering dauert es etwa sechs Monate, bis es fertig ist.