
KNN-Klassifikator für maschinelles Lernen: Alles, was Sie wissen müssen
Veröffentlicht: 2021-09-28Erinnern Sie sich an die Zeit, als künstliche Intelligenz (KI) nur ein Konzept war, das auf Science-Fiction-Romane und -Filme beschränkt war? Nun, dank des technologischen Fortschritts ist KI etwas, mit dem wir jetzt jeden Tag leben. Von Alexa und Siri, die uns zur Verfügung stehen, bis hin zu OTT-Plattformen, die die Filme, die wir sehen möchten, „handverlesen“ haben, ist KI fast zur Tagesordnung geworden und wird es auf absehbare Zeit geben.
All dies ist dank fortschrittlicher ML-Algorithmen möglich. Heute werden wir über einen solchen nützlichen ML-Algorithmus sprechen, den K-NN-Klassifikator.
Maschinelles Lernen, ein Zweig der KI und Informatik, verwendet Daten und Algorithmen, um das menschliche Verständnis nachzuahmen und gleichzeitig die Genauigkeit der Algorithmen schrittweise zu verbessern. Beim maschinellen Lernen werden Algorithmen trainiert, um Vorhersagen oder Klassifizierungen zu treffen und wichtige Erkenntnisse zu gewinnen, die die strategische Entscheidungsfindung in Unternehmen und Anwendungen vorantreiben.
Der KNN-Algorithmus (k-nächster Nachbar) ist ein grundlegender überwachter maschineller Lernalgorithmus, der zur Lösung von Regressions- und Klassifizierungsproblemen verwendet wird. Lassen Sie uns also eintauchen, um mehr über den K-NN-Klassifikator zu erfahren.
Inhaltsverzeichnis
Überwachtes vs. unbeaufsichtigtes maschinelles Lernen
Überwachtes und unüberwachtes Lernen sind zwei grundlegende datenwissenschaftliche Ansätze, und es ist wichtig, den Unterschied zu kennen, bevor wir auf die Details von KNN eingehen.
Überwachtes Lernen ist ein maschineller Lernansatz, der beschriftete Datensätze verwendet, um Ergebnisse vorherzusagen. Solche Datensätze sollen Algorithmen „überwachen“ oder trainieren, um Ergebnisse vorherzusagen oder Daten genau zu klassifizieren. Daher ermöglichen beschriftete Eingaben und Ausgaben dem Modell, im Laufe der Zeit zu lernen und gleichzeitig seine Genauigkeit zu verbessern.

Überwachtes Lernen beinhaltet zwei Arten von Problemen – Klassifikation und Regression. Bei Klassifikationsproblemen ordnen Algorithmen Testdaten diskreten Kategorien zu, etwa um Katzen von Hunden zu trennen.
Ein bedeutendes Beispiel aus der Praxis wäre das Einordnen von Spam-Mails in einen von Ihrem Posteingang getrennten Ordner. Andererseits trainiert die Regressionsmethode des überwachten Lernens Algorithmen, um die Beziehung zwischen unabhängigen und abhängigen Variablen zu verstehen. Es verwendet verschiedene Datenpunkte, um numerische Werte vorherzusagen, beispielsweise um den Umsatz eines Unternehmens zu prognostizieren.
Beim unüberwachten Lernen hingegen werden maschinelle Lernalgorithmen für die Analyse und das Clustering von unbeschrifteten Datensätzen verwendet. Daher ist kein menschliches Eingreifen („unbeaufsichtigt“) erforderlich, damit die Algorithmen verborgene Muster in Daten erkennen.
Unüberwachte Lernmodelle haben drei Hauptanwendungen – Assoziation, Clustering und Dimensionsreduktion. Wir werden jedoch nicht auf die Details eingehen, da dies außerhalb unseres Diskussionsbereichs liegt.
K-nächster Nachbar (KNN)
Der K-Nearest Neighbor oder der KNN-Algorithmus ist ein maschineller Lernalgorithmus, der auf dem überwachten Lernmodell basiert. Der K-NN-Algorithmus geht davon aus, dass ähnliche Dinge nahe beieinander existieren. Daher nutzt der K-NN-Algorithmus Merkmalsähnlichkeit zwischen den neuen Datenpunkten und den Punkten im Trainingssatz (verfügbare Fälle), um die Werte der neuen Datenpunkte vorherzusagen. Im Wesentlichen weist der K-NN-Algorithmus dem neuesten Datenpunkt einen Wert zu, basierend darauf, wie sehr er den Punkten im Trainingssatz ähnelt. Der K-NN-Algorithmus findet sowohl bei Klassifizierungs- als auch bei Regressionsproblemen Anwendung, wird jedoch hauptsächlich für Klassifizierungsprobleme verwendet.
Hier ist ein Beispiel, um den K-NN-Klassifikator zu verstehen.

Quelle
Im obigen Bild ist der Eingabewert eine Kreatur mit Ähnlichkeiten sowohl zu einer Katze als auch zu einem Hund. Wir möchten es jedoch entweder in eine Katze oder einen Hund einteilen. Wir können also den K-NN-Algorithmus für diese Klassifizierung verwenden. Das K-NN-Modell findet Ähnlichkeiten zwischen dem neuen Datensatz (Eingabe) und den verfügbaren Katzen- und Hundebildern (Trainingsdatensatz). Anschließend ordnet das Modell den neuen Datenpunkt basierend auf den ähnlichsten Merkmalen entweder der Katzen- oder der Hundekategorie zu.
Ebenso haben Kategorie A (grüne Punkte) und Kategorie B (orange Punkte) das obige grafische Beispiel. Wir haben auch einen neuen Datenpunkt (blauer Punkt), der in eine der beiden Kategorien fallen wird. Wir können dieses Klassifizierungsproblem mit einem K-NN-Algorithmus lösen und die neue Datenpunktkategorie identifizieren.
Eigenschaften des K-NN-Algorithmus definieren
Die folgenden zwei Eigenschaften definieren den K-NN-Algorithmus am besten:
- Es ist ein fauler Lernalgorithmus, da der K-NN-Algorithmus nicht sofort aus dem Trainingssatz lernt, sondern den Datensatz speichert und zum Zeitpunkt der Klassifizierung aus dem Datensatz trainiert.
- K-NN ist auch ein nichtparametrischer Algorithmus , was bedeutet, dass er keine Annahmen über die zugrunde liegenden Daten trifft.
Funktionsweise des K-NN-Algorithmus
Sehen wir uns nun die folgenden Schritte an, um zu verstehen, wie der K-NN-Algorithmus funktioniert.
Schritt 1: Laden Sie die Trainings- und Testdaten.
Schritt 2: Wählen Sie die nächstgelegenen Datenpunkte, d. h. den Wert von K.
Schritt 3: Berechnen Sie den Abstand von K Nachbarn (den Abstand zwischen jeder Reihe von Trainingsdaten und Testdaten). Die euklidische Methode wird am häufigsten zur Berechnung der Entfernung verwendet.
Schritt 4: Nimm die K nächsten Nachbarn basierend auf der berechneten euklidischen Distanz.
Schritt 5: Zählen Sie unter den nächsten K Nachbarn die Anzahl der Datenpunkte in jeder Kategorie.
Schritt 6: Ordnen Sie die neuen Datenpunkte derjenigen Kategorie zu, für die die Anzahl der Nachbarn maximal ist.
Schritt 7: Ende. Das Modell ist nun fertig.
Nehmen Sie online an Kursen zur künstlichen Intelligenz von den besten Universitäten der Welt teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
Auswahl des Wertes von K
K ist ein kritischer Parameter im K-NN-Algorithmus. Daher müssen wir einige Punkte beachten, bevor wir uns für einen Wert von K entscheiden.
Die Verwendung von Fehlerkurven ist eine gängige Methode, um den Wert von K zu bestimmen. Das folgende Bild zeigt Fehlerkurven für verschiedene K-Werte für Test- und Trainingsdaten.


Quelle
Im obigen grafischen Beispiel ist der Trainingsfehler bei K = 1 in den Trainingsdaten null, da der nächste Nachbar des Punktes dieser Punkt selbst ist. Der Testfehler ist jedoch auch bei niedrigen Werten von K hoch. Dies wird als hohe Varianz oder Überanpassung von Daten bezeichnet. Der Testfehler verringert sich, wenn wir den Wert von K erhöhen. Ab einem bestimmten Wert von K sehen wir jedoch, dass der Testfehler wieder zunimmt, was als Bias oder Underfitting bezeichnet wird. So ist der Testdatenfehler aufgrund der Varianz zunächst hoch, er sinkt anschließend ab und stabilisiert sich, und bei weiterer Erhöhung des Wertes von K schießt der Testfehler aufgrund der Verzerrung wieder in die Höhe.
Daher wird der Wert von K, bei dem sich der Testfehler stabilisiert und niedrig ist, als optimaler Wert von K angenommen. Unter Berücksichtigung der obigen Fehlerkurve ist K = 8 der optimale Wert.
Ein Beispiel zum Verständnis der Funktionsweise des K-NN-Algorithmus
Stellen Sie sich einen Datensatz vor, der wie folgt gezeichnet wurde:

Quelle
Angenommen, es gibt einen neuen Datenpunkt (schwarzer Punkt) bei (60,60), den wir entweder in die violette oder die rote Klasse klassifizieren müssen. Wir verwenden K=3, was bedeutet, dass der neue Datenpunkt drei nächste Datenpunkte finden wird, zwei in der roten Klasse und einen in der violetten Klasse.
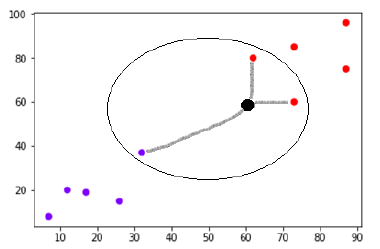
Quelle
Die nächsten Nachbarn werden durch Berechnung der euklidischen Distanz zwischen zwei Punkten bestimmt. Hier ist eine Illustration, die zeigt, wie die Berechnung durchgeführt wird.

Quelle
Da nun zwei (von drei) der nächsten Nachbarn des neuen Datenpunkts (schwarzer Punkt) in der roten Klasse liegen, wird der neue Datenpunkt auch der roten Klasse zugeordnet.
Nehmen Sie online am Machine Learning-Kurs der weltbesten Universitäten teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
K-NN als Klassifikator (Implementierung in Python)
Nachdem wir nun eine vereinfachte Erklärung des K-NN-Algorithmus erhalten haben, lassen Sie uns die Implementierung des K-NN-Algorithmus in Python durchgehen. Wir konzentrieren uns nur auf den K-NN-Klassifikator.
Schritt 1: Importieren Sie die erforderlichen Python-Pakete.

Quelle
Schritt 2: Laden Sie den Iris-Datensatz aus dem UCI Machine Learning Repository herunter. Sein Weblink lautet „https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data“
Schritt 3: Weisen Sie dem Datensatz Spaltennamen zu.

Quelle
Schritt 4: Lesen Sie den Datensatz in Pandas DataFrame ein.

Quelle
Schritt 5: Die Datenvorverarbeitung erfolgt mit den folgenden Skriptzeilen.

Quelle
Schritt 6: Aufteilen des Datensatzes in Test- und Trainingsaufteilung. Der folgende Code teilt das Dataset in 40 % Testdaten und 60 % Trainingsdaten auf.

Quelle
Schritt 7: Die Datenskalierung erfolgt wie folgt:

Quelle
Schritt 8: Trainieren Sie das Modell mit der KNeighborsClassifier-Klasse von sklearn.

Quelle
Schritt 9: Machen Sie eine Vorhersage mit dem folgenden Skript:

Quelle
Schritt 10: Drucken Sie die Ergebnisse aus.

Quelle
Ausgabe:

Quelle
Was als nächstes? Melden Sie sich für das Advanced Certificate Program in Machine Learning von IIT Madras und upGrad an
Angenommen, Sie streben danach, ein erfahrener Datenwissenschaftler oder Experte für maschinelles Lernen zu werden. Dann ist der Advanced Certification Course in Machine Learning and Cloud von IIT Madras und upGrad genau das Richtige für Sie!
Das 12-monatige Online-Programm wurde speziell für Berufstätige entwickelt, die Konzepte in maschinellem Lernen, Big Data-Verarbeitung, Datenmanagement, Data Warehousing, Cloud und Bereitstellung von Modellen für maschinelles Lernen beherrschen möchten.
Hier sind einige Kurshighlights, um Ihnen eine bessere Vorstellung davon zu geben, was das Programm bietet:
- Weltweit anerkannte prestigeträchtige Zertifizierung von IIT Madras
- Mehr als 500 Lernstunden, mehr als 20 Fallstudien und Projekte, mehr als 25 Branchen-Mentoring-Sitzungen, mehr als 8 Programmieraufgaben
- Umfassende Abdeckung von 7 Programmiersprachen und Tools
- 4 Wochen Industrieabschlussprojekt
- Praktische Hands-on-Workshops
- Offline-Peer-to-Peer-Netzwerke
Melden Sie sich noch heute an, um mehr über das Programm zu erfahren!
Fazit
Mit der Zeit wächst Big Data weiter und künstliche Intelligenz wird immer mehr mit unserem Leben verwoben. Infolgedessen steigt die Nachfrage nach Datenwissenschaftsexperten, die die Leistungsfähigkeit von Modellen für maschinelles Lernen nutzen können, um Datenerkenntnisse zu sammeln und kritische Geschäftsprozesse und im Allgemeinen unsere Welt zu verbessern. Zweifellos sieht der Bereich der künstlichen Intelligenz und des maschinellen Lernens in der Tat vielversprechend aus. Mit upGrad können Sie sicher sein, dass Ihre Karriere im maschinellen Lernen und in der Cloud eine lohnende ist!
Warum ist K-NN ein guter Klassifikator?
Der Hauptvorteil von K-NN gegenüber anderen maschinellen Lernalgorithmen besteht darin, dass wir K-NN bequem für die Mehrklassenklassifizierung verwenden können. Daher ist K-NN der beste Algorithmus, wenn wir Daten in mehr als zwei Kategorien klassifizieren müssen oder wenn die Daten mehr als zwei Labels umfassen. Außerdem ist es ideal für nichtlineare Daten und hat eine relativ hohe Genauigkeit.
Was ist die Einschränkung des K-NN-Algorithmus?
Der K-NN-Algorithmus berechnet den Abstand zwischen den Datenpunkten. Daher ist es ziemlich offensichtlich, dass es sich um einen relativ zeitaufwändigeren Algorithmus handelt und dass die Klassifizierung in einigen Fällen mehr Zeit in Anspruch nehmen wird. Daher ist es am besten, nicht zu viele Datenpunkte zu verwenden, während Sie K-NN für die Mehrklassenklassifizierung verwenden. Weitere Einschränkungen sind eine hohe Speicherkapazität und die Empfindlichkeit gegenüber irrelevanten Funktionen.
Was sind die realen Anwendungen von K-NN?
K-NN hat mehrere reale Anwendungsfälle im maschinellen Lernen, wie z. B. Handschrifterkennung, Spracherkennung, Videoerkennung und Bilderkennung. Im Bankwesen wird K-NN verwendet, um vorherzusagen, ob eine Person für einen Kredit in Frage kommt, basierend darauf, ob sie ähnliche Merkmale wie säumige Personen aufweist. In der Politik kann K-NN verwendet werden, um potenzielle Wähler in verschiedene Klassen einzuteilen, wie „wird Partei X wählen“ oder „wird Partei Y wählen“ usw.