
Einführung in die komponentenbasierte API
Veröffentlicht: 2022-03-10Dieser Artikel wurde am 31. Januar 2019 aktualisiert, um auf das Feedback der Leser zu reagieren. Der Autor hat der komponentenbasierten API benutzerdefinierte Abfragefunktionen hinzugefügt und beschreibt, wie sie funktioniert .
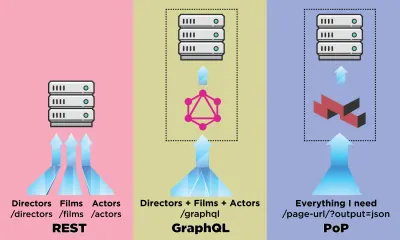
Eine API ist der Kommunikationskanal für eine Anwendung, um Daten vom Server zu laden. In der Welt der APIs war REST die etabliertere Methode, wurde aber in letzter Zeit von GraphQL überschattet, das wichtige Vorteile gegenüber REST bietet. Während REST mehrere HTTP-Anfragen erfordert, um einen Satz von Daten zum Rendern einer Komponente abzurufen, kann GraphQL solche Daten in einer einzigen Anfrage abfragen und abrufen, und die Antwort wird genau das sein, was erforderlich ist, ohne dass Daten zu viel oder zu wenig abgerufen werden, wie dies normalerweise der Fall ist SICH AUSRUHEN.
In diesem Artikel werde ich eine andere Methode zum Abrufen von Daten beschreiben, die ich entworfen und „PoP“ genannt habe (und hier als Open Source verfügbar ist), die die von GraphQL eingeführte Idee des Abrufens von Daten für mehrere Entitäten in einer einzigen Anfrage erweitert und a einen Schritt weiter, dh während REST die Daten für eine Ressource abruft und GraphQL die Daten für alle Ressourcen in einer Komponente abruft, kann die komponentenbasierte API die Daten für alle Ressourcen von allen Komponenten auf einer Seite abrufen.
Die Verwendung einer komponentenbasierten API ist am sinnvollsten, wenn die Website selbst mit Komponenten erstellt wird, dh wenn die Webseite iterativ aus Komponenten zusammengesetzt wird, die andere Komponenten umhüllen, bis wir ganz oben eine einzelne Komponente erhalten, die die Seite darstellt. Die im Bild unten gezeigte Webseite ist beispielsweise aus Komponenten aufgebaut, die mit Quadraten umrandet sind:
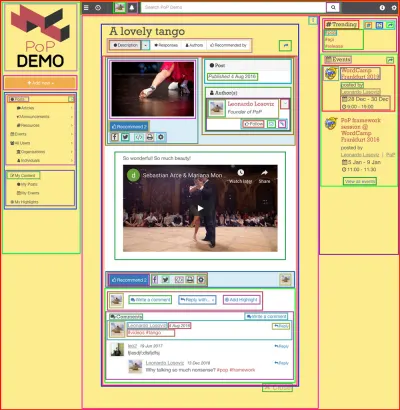
Eine komponentenbasierte API ist in der Lage, eine einzige Anfrage an den Server zu stellen, indem sie die Daten für alle Ressourcen in jeder Komponente (sowie für alle Komponenten auf der Seite) anfordert, was erreicht wird, indem die Beziehungen zwischen den Komponenten beibehalten werden die API-Struktur selbst.
Diese Struktur bietet unter anderem die folgenden Vorteile:
- Eine Seite mit vielen Komponenten löst nur eine Anfrage statt vieler aus;
- Über Komponenten hinweg geteilte Daten können nur einmal aus der DB abgerufen und nur einmal in der Antwort gedruckt werden;
- Es kann die Notwendigkeit eines Datenspeichers erheblich reduzieren – sogar vollständig beseitigen.
Wir werden diese im Laufe des Artikels im Detail untersuchen, aber zuerst wollen wir untersuchen, was Komponenten eigentlich sind und wie wir eine Website basierend auf solchen Komponenten erstellen können, und schließlich untersuchen, wie eine komponentenbasierte API funktioniert.
Empfohlene Lektüre : A GraphQL Primer: Why We Need A New Art of API
Erstellen einer Website durch Komponenten
Eine Komponente ist einfach eine Reihe von Teilen von HTML-, JavaScript- und CSS-Code, die alle zusammengefügt werden, um eine autonome Einheit zu erstellen. Dies kann dann andere Komponenten umhüllen, um komplexere Strukturen zu erstellen, und selbst auch von anderen Komponenten umhüllt werden. Eine Komponente hat einen Zweck, der von etwas sehr Einfachem (wie einem Link oder einer Schaltfläche) bis zu etwas sehr Ausgefeiltem (wie einem Karussell oder einem Drag-and-Drop-Bild-Uploader) reichen kann. Komponenten sind am nützlichsten, wenn sie generisch sind und eine Anpassung durch eingefügte Eigenschaften (oder „Requisiten“) ermöglichen, sodass sie eine Vielzahl von Anwendungsfällen bedienen können. Im äußersten Fall wird die Site selbst zu einer Komponente.
Der Begriff „Komponente“ wird häufig verwendet, um sich sowohl auf die Funktionalität als auch auf das Design zu beziehen. In Bezug auf die Funktionalität ermöglichen beispielsweise JavaScript-Frameworks wie React oder Vue die Erstellung clientseitiger Komponenten, die in der Lage sind, sich selbst zu rendern (z. B. nachdem die API ihre erforderlichen Daten abgerufen hat) und Requisiten zu verwenden, um Konfigurationswerte für sie festzulegen umschlossene Komponenten, wodurch die Wiederverwendbarkeit von Code ermöglicht wird. In Bezug auf das Design hat Bootstrap das Aussehen und Verhalten von Websites durch seine Front-End-Komponentenbibliothek standardisiert, und es ist zu einem gesunden Trend für Teams geworden, Designsysteme zur Pflege ihrer Websites zu erstellen, wodurch die verschiedenen Teammitglieder (Designer und Entwickler, aber auch Vermarkter und Verkäufer), um eine einheitliche Sprache zu sprechen und eine konsistente Identität auszudrücken.
Eine Website zu komponentisieren ist dann ein sehr vernünftiger Weg, um die Website wartbarer zu machen. Websites, die JavaScript-Frameworks wie React und Vue verwenden, sind bereits komponentenbasiert (zumindest clientseitig). Die Verwendung einer Komponentenbibliothek wie Bootstrap macht die Site nicht unbedingt komponentenbasiert (es könnte ein großer HTML-Blob sein), enthält jedoch das Konzept wiederverwendbarer Elemente für die Benutzeroberfläche.
Wenn die Website ein großer HTML-Blob ist , müssen wir das Layout in eine Reihe wiederkehrender Muster aufteilen, um es in Komponenten zu zerlegen, für die wir Abschnitte auf der Seite basierend auf ihrer Ähnlichkeit von Funktionalität und Stil identifizieren und katalogisieren und diese aufteilen müssen Unterteilen Sie die Abschnitte in Schichten, so granular wie möglich, und versuchen Sie, jede Schicht auf ein einziges Ziel oder eine einzelne Aktion zu konzentrieren, und versuchen Sie auch, gemeinsame Schichten in verschiedenen Abschnitten aufeinander abzustimmen.
Hinweis : Brad Frosts „Atomic Design“ ist eine großartige Methode, um diese gemeinsamen Muster zu identifizieren und ein wiederverwendbares Designsystem aufzubauen.
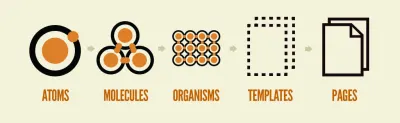
Daher ist das Erstellen einer Website durch Komponenten dem Spielen mit LEGO ähnlich. Jede Komponente ist entweder eine atomare Funktionalität, eine Zusammensetzung anderer Komponenten oder eine Kombination aus beidem.
Wie unten gezeigt, wird eine grundlegende Komponente (ein Avatar) iterativ aus anderen Komponenten zusammengesetzt, bis die Webseite ganz oben erhalten wird:

Die komponentenbasierte API-Spezifikation
Für die von mir entworfene komponentenbasierte API wird eine Komponente als „Modul“ bezeichnet, daher werden die Begriffe „Komponente“ und „Modul“ von nun an synonym verwendet.
Die Beziehung aller Module, die sich gegenseitig umschließen, vom obersten Modul bis hinunter zur letzten Ebene, wird als „Komponentenhierarchie“ bezeichnet. Diese Beziehung kann serverseitig durch ein assoziatives Array (ein Array von key => Eigenschaft) ausgedrückt werden, in dem jedes Modul seinen Namen als Schlüsselattribut und seine inneren Module unter der Eigenschaft modules angibt. Die API codiert dieses Array dann einfach als JSON-Objekt zur Nutzung:
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }Die Beziehung zwischen Modulen wird streng von oben nach unten definiert: Ein Modul umhüllt andere Module und weiß, wer sie sind, aber es weiß nicht – und es ist ihm egal – welche Module es umhüllen.
Beispielsweise weiß das Modul module-level1 im obigen JSON-Code, dass es die Module module-level11 und module-level12 , und transitiv weiß es auch, dass es module-level121 ; aber das Modul module-level11 kümmert sich nicht darum, wer es umschließt, folglich ist es dem module-level1 nicht bekannt.
Mit der komponentenbasierten Struktur können wir nun die tatsächlichen Informationen hinzufügen, die von jedem Modul benötigt werden, die entweder in Einstellungen (wie Konfigurationswerte und andere Eigenschaften) und Daten (wie die IDs der abgefragten Datenbankobjekte und andere Eigenschaften) kategorisiert sind. , und entsprechend unter den Einträgen modulesettings und moduledata :
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } Anschließend fügt die API die Datenbankobjektdaten hinzu. Diese Informationen werden nicht unter jedem Modul platziert, sondern unter einem gemeinsam genutzten Abschnitt namens databases , um doppelte Informationen zu vermeiden, wenn zwei oder mehr verschiedene Module dieselben Objekte aus der Datenbank abrufen.
Darüber hinaus stellt die API die Datenbankobjektdaten auf relationale Weise dar, um doppelte Informationen zu vermeiden, wenn zwei oder mehr unterschiedliche Datenbankobjekte mit einem gemeinsamen Objekt in Beziehung stehen (z. B. zwei Posts mit demselben Autor). Mit anderen Worten, Datenbankobjektdaten werden normalisiert.
Empfohlene Lektüre : Erstellen eines serverlosen Kontaktformulars für Ihre statische Website
Die Struktur ist ein Wörterbuch, das zuerst nach Objekttyp und dann nach Objekt-ID organisiert ist und aus dem wir die Objekteigenschaften abrufen können:
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }Dieses JSON-Objekt ist bereits die Antwort von der komponentenbasierten API. Sein Format ist eine eigenständige Spezifikation: Solange der Server die JSON-Antwort im erforderlichen Format zurückgibt, kann der Client die API unabhängig davon verwenden, wie sie implementiert ist. Daher kann die API in jeder Sprache implementiert werden (was eine der Schönheiten von GraphQL ist: Da es sich um eine Spezifikation und nicht um eine tatsächliche Implementierung handelt, wurde es in unzähligen Sprachen verfügbar.)
Hinweis : In einem kommenden Artikel werde ich meine Implementierung der komponentenbasierten API in PHP beschreiben (die im Repo verfügbar ist).
Beispiel für eine API-Antwort
Die folgende API-Antwort enthält beispielsweise eine Komponentenhierarchie mit zwei Modulen, page => post-feed , wobei das Modul post-feed Blogbeiträge abruft. Bitte beachten Sie Folgendes:
- Jedes Modul kennt seine abgefragten Objekte aus der Eigenschaft
dbobjectids(IDs4und9für die Blogbeiträge) - Jedes Modul kennt den Objekttyp für seine abgefragten Objekte aus der Eigenschaft
dbkeys(die Daten jedes Beitrags befinden sich unterposts, und die Autorendaten des Beitrags, die dem Autor mit der ID entsprechen, die unter der Eigenschaftauthordes Beitrags angegeben ist, befinden sich unterusers) - Da die Datenbankobjektdaten relational sind, enthält die Eigenschaft
authordie ID des Autorenobjekts, anstatt die Autorendaten direkt zu drucken.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }Unterschiede beim Abrufen von Daten aus ressourcenbasierten, schemabasierten und komponentenbasierten APIs
Sehen wir uns an, wie sich eine komponentenbasierte API wie PoP beim Abrufen von Daten mit einer ressourcenbasierten API wie REST und einer schemabasierten API wie GraphQL vergleicht.
Nehmen wir an, IMDB hat eine Seite mit zwei Komponenten, die Daten abrufen müssen: „Vorgestellter Regisseur“ (zeigt eine Beschreibung von George Lucas und eine Liste seiner Filme) und „Für Sie empfohlene Filme“ (zeigt Filme wie Star Wars: Episode I – Die dunkle Bedrohung und Der Terminator ). Es könnte so aussehen:
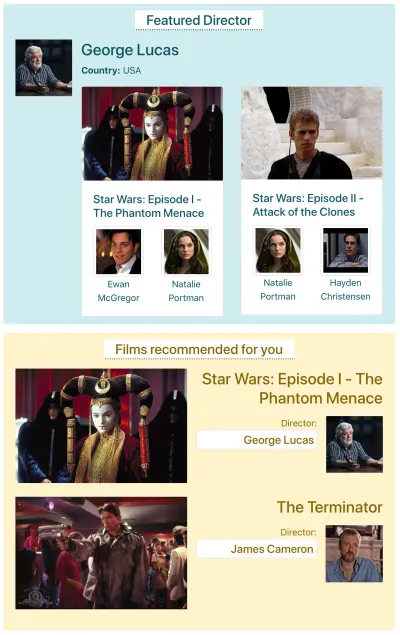
Mal sehen, wie viele Anfragen erforderlich sind, um die Daten über jede API-Methode abzurufen. Für dieses Beispiel liefert die Komponente „Vorgestellter Regisseur“ ein Ergebnis („George Lucas“), aus dem zwei Filme abgerufen werden ( Star Wars: Episode I – The Phantom Menace und Star Wars: Episode II – Attack of the Clones ), und für jeden Film zwei Schauspieler („Ewan McGregor“ und „Natalie Portman“ für den ersten Film und „Natalie Portman“ und „Hayden Christensen“ für den zweiten Film). Die Komponente „Für Sie empfohlene Filme“ bringt zwei Ergebnisse ( Star Wars: Episode I – The Phantom Menace und The Terminator ) und holt dann deren Regisseure („George Lucas“ bzw. „James Cameron“).
Wenn wir REST verwenden, um die Komponente featured-director zu rendern, benötigen wir möglicherweise die folgenden 7 Anforderungen (diese Anzahl kann variieren, je nachdem, wie viele Daten von jedem Endpunkt bereitgestellt werden, dh wie viel Overfetching implementiert wurde):
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL ermöglicht durch stark typisierte Schemas, alle erforderlichen Daten in einer einzigen Anfrage pro Komponente abzurufen. Die Abfrage zum Abrufen von Daten über GraphQL für die Komponente featuredDirector sieht wie folgt aus (nachdem wir das entsprechende Schema implementiert haben):
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }Und es erzeugt die folgende Antwort:
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }Und die Abfrage nach der Komponente „Für Sie empfohlene Filme“ führt zu folgender Antwort:
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP gibt nur eine Anfrage aus, um alle Daten für alle Komponenten auf der Seite abzurufen und die Ergebnisse zu normalisieren. Der aufzurufende Endpunkt ist einfach derselbe wie die URL, für die wir die Daten abrufen müssen. Fügen Sie einfach einen zusätzlichen Parameter hinzu output=json um anzugeben, dass die Daten im JSON-Format gebracht werden sollen, anstatt sie als HTML zu drucken:
GET - /url-of-the-page/?output=json Angenommen, die Modulstruktur hat ein oberstes Modul namens page mit den Modulen featured-director und „ films-recommended-for-you und diese haben auch Untermodule wie dieses:
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"Die einzelne zurückgegebene JSON-Antwort sieht folgendermaßen aus:
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }Lassen Sie uns analysieren, wie diese drei Methoden in Bezug auf Geschwindigkeit und abgerufene Datenmenge miteinander verglichen werden.
Geschwindigkeit
Durch REST kann das Abrufen von 7 Anfragen nur zum Rendern einer Komponente sehr langsam sein, hauptsächlich bei mobilen und wackeligen Datenverbindungen. Daher stellt der Sprung von REST zu GraphQL viel für die Geschwindigkeit dar, da wir in der Lage sind, eine Komponente mit nur einer Anfrage zu rendern.
Da PoP alle Daten für viele Komponenten in einer Anfrage abrufen kann, ist es schneller, viele Komponenten gleichzeitig zu rendern; Dies ist jedoch höchstwahrscheinlich nicht erforderlich. Das Rendern der Komponenten in der Reihenfolge (wie sie auf der Seite erscheinen) ist bereits eine gute Praxis, und für die Komponenten, die unter der Falte erscheinen, besteht sicherlich keine Eile, sie zu rendern. Daher sind sowohl die schemabasierten als auch die komponentenbasierten APIs bereits ziemlich gut und einer ressourcenbasierten API deutlich überlegen.
Datenmenge
Bei jeder Anfrage können Daten in der GraphQL-Antwort dupliziert werden: Die Schauspielerin „Natalie Portman“ wird in der Antwort von der ersten Komponente zweimal abgerufen, und wenn wir die gemeinsame Ausgabe für die beiden Komponenten betrachten, können wir auch gemeinsame Daten wie Film finden Star Wars: Episode I – Die dunkle Bedrohung .
PoP hingegen normalisiert die Datenbankdaten und druckt sie nur einmal, trägt jedoch den Overhead des Druckens der Modulstruktur. Abhängig von der bestimmten Anforderung, die duplizierte Daten hat oder nicht, wird daher entweder die schemabasierte API oder die komponentenbasierte API eine kleinere Größe haben.
Zusammenfassend sind eine schemabasierte API wie GraphQL und eine komponentenbasierte API wie PoP in Bezug auf die Leistung ähnlich gut und einer ressourcenbasierten API wie REST überlegen.
Empfohlene Lektüre : REST-APIs verstehen und verwenden
Besondere Eigenschaften einer komponentenbasierten API
Wenn eine komponentenbasierte API in Bezug auf die Leistung nicht unbedingt besser ist als eine schemabasierte API, fragen Sie sich vielleicht, was ich dann mit diesem Artikel versuche?
In diesem Abschnitt werde ich versuchen, Sie davon zu überzeugen, dass eine solche API ein unglaubliches Potenzial hat, da sie mehrere sehr wünschenswerte Funktionen bietet, die sie zu einem ernsthaften Konkurrenten in der Welt der APIs machen. Ich beschreibe und demonstriere jede seiner einzigartigen großartigen Funktionen unten.
Die aus der Datenbank abzurufenden Daten können aus der Komponentenhierarchie abgeleitet werden
Wenn ein Modul eine Eigenschaft von einem DB-Objekt anzeigt, weiß das Modul möglicherweise nicht, um welches Objekt es sich handelt, oder kümmert sich nicht darum; alles, worum es sich kümmert, ist zu definieren, welche Eigenschaften des geladenen Objekts erforderlich sind.
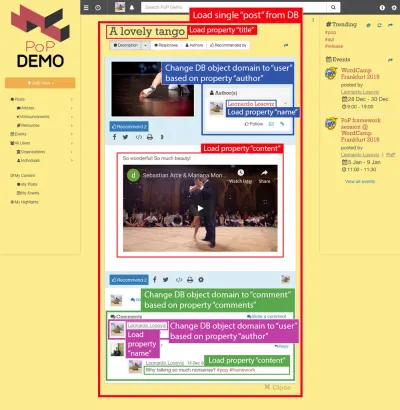
Betrachten Sie zum Beispiel das Bild unten. Ein Modul lädt ein Objekt aus der Datenbank (in diesem Fall einen einzelnen Beitrag), und dann zeigen seine untergeordneten Module bestimmte Eigenschaften des Objekts an, z. B. title und content :
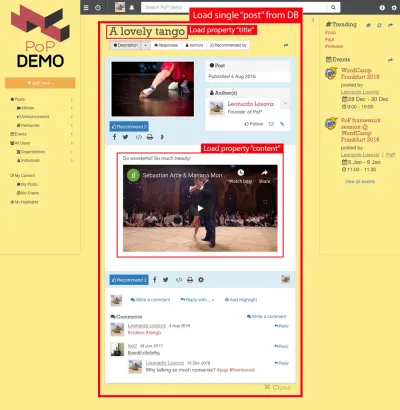
Daher sind entlang der Komponentenhierarchie die „dataloading“-Module für das Laden der abgefragten Objekte zuständig (in diesem Fall das Modul, das den einzelnen Post lädt), und seine Nachkommen-Module definieren, welche Eigenschaften aus dem DB-Objekt erforderlich sind ( title und content , in diesem Fall).
Das Abrufen aller erforderlichen Eigenschaften für das DB-Objekt kann automatisch erfolgen, indem die Komponentenhierarchie durchlaufen wird: Beginnend mit dem Datenlademodul durchlaufen wir alle seine Nachkommenmodule bis zum Erreichen eines neuen Datenlademoduls oder bis zum Ende des Baums; Auf jeder Ebene erhalten wir alle erforderlichen Eigenschaften, führen dann alle Eigenschaften zusammen und fragen sie aus der Datenbank ab, alle nur einmal.
In der Struktur unten holt das Modul single-post die Ergebnisse aus der DB (dem Post mit der ID 37), und die Untermodule post-title und post-content definieren Eigenschaften, die für das abgefragte DB-Objekt geladen werden sollen ( title bzw. content ); Die Submodule post-layout und fetch-next-post-button benötigen keine Datenfelder.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"Die auszuführende Abfrage wird automatisch aus der Komponentenhierarchie und ihren erforderlichen Datenfeldern berechnet, die alle Eigenschaften enthält, die von allen Modulen und ihren Untermodulen benötigt werden:
SELECT title, content FROM posts WHERE id = 37 Indem die abzurufenden Eigenschaften direkt aus den Modulen abgerufen werden, wird die Abfrage automatisch aktualisiert, wenn sich die Komponentenhierarchie ändert. Wenn wir dann zum Beispiel das Submodul post-thumbnail hinzufügen, was das Datenfeld thumbnail erfordert:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"Dann wird die Abfrage automatisch aktualisiert, um die zusätzliche Eigenschaft abzurufen:
SELECT title, content, thumbnail FROM posts WHERE id = 37Da wir die abzurufenden Datenbankobjektdaten relational festgelegt haben, können wir diese Strategie auch auf die Beziehungen zwischen Datenbankobjekten selbst anwenden.
Betrachten Sie das folgende Bild: Beginnend mit dem Objekttyp post und nach unten in der Komponentenhierarchie müssen wir den DB-Objekttyp auf user und comment verschieben, entsprechend dem Autor des Posts und jedem Kommentar des Posts, und dann für jeden Kommentar, muss es den Objekttyp erneut auf user ändern, der dem Autor des Kommentars entspricht.
Der Wechsel von einem Datenbankobjekt zu einem relationalen Objekt (möglicherweise das Ändern des Objekttyps, wie in post => author , der von post zu user wechselt, oder nicht, wie in author => Follower, die von user zu user wechseln) nenne ich „Domänenwechsel “.
Nach dem Wechsel zu einer neuen Domäne werden ab dieser Ebene in der Komponentenhierarchie alle erforderlichen Eigenschaften der neuen Domäne unterworfen:
-
namewird aus demuserabgerufen (das den Autor des Beitrags darstellt), -
contentwird aus demcommentabgerufen (das jeden Kommentar des Beitrags darstellt), -
namewird aus demuserabgerufen (das den Autor jedes Kommentars darstellt).
Beim Durchlaufen der Komponentenhierarchie weiß die API, wann sie zu einer neuen Domäne wechselt, und aktualisiert die Abfrage entsprechend, um das relationale Objekt abzurufen.
Wenn wir beispielsweise Daten vom Autor des Beitrags anzeigen müssen, ändert das Stacking-Submodul post-author die Domäne auf dieser Ebene von post auf den entsprechenden user , und ab dieser Ebene nach unten wird das DB-Objekt in den an das Modul übergebenen Kontext geladen der Benutzer. Dann laden die Submodule user-name und user-avatar unter post-author die Eigenschaften name und avatar unter dem user -Objekt:
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"Daraus ergibt sich folgende Abfrage:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.idZusammenfassend lässt sich sagen, dass durch die geeignete Konfiguration jedes Moduls keine Notwendigkeit besteht, die Abfrage zu schreiben, um Daten für eine komponentenbasierte API abzurufen. Die Abfrage wird automatisch aus der Struktur der Komponentenhierarchie selbst erzeugt, wobei ermittelt wird, welche Objekte von den Datenlademodulen geladen werden müssen, die für jedes geladene Objekt abzurufenden Felder, die in jedem untergeordneten Modul definiert sind, und die Domänenumschaltung, die in jedem untergeordneten Modul definiert ist.
Durch das Hinzufügen, Entfernen, Ersetzen oder Ändern eines Moduls wird die Abfrage automatisch aktualisiert. Nach dem Ausführen der Abfrage sind die abgerufenen Daten genau das, was benötigt wird – nicht mehr oder weniger.
Beobachtung von Daten und Berechnung zusätzlicher Eigenschaften
Beginnend mit dem Datenlademodul nach unten in der Komponentenhierarchie kann jedes Modul die zurückgegebenen Ergebnisse beobachten und basierend darauf zusätzliche Datenelemente oder feedback berechnen, die unter dem Eintrag moduledata platziert werden.
Beispielsweise kann das Modul fetch-next-post-button eine Eigenschaft hinzufügen, die angibt, ob weitere Ergebnisse zum Abrufen vorhanden sind oder nicht (basierend auf diesem Feedback-Wert wird die Schaltfläche deaktiviert oder ausgeblendet, wenn es keine weiteren Ergebnisse gibt):
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }Die implizite Kenntnis der erforderlichen Daten verringert die Komplexität und macht das Konzept eines „Endpoints“ obsolet
Wie oben gezeigt, kann die komponentenbasierte API genau die erforderlichen Daten abrufen, da sie das Modell aller Komponenten auf dem Server hat und welche Datenfelder von jeder Komponente benötigt werden. Dann kann es die Kenntnis der erforderlichen Datenfelder implizit machen.

Der Vorteil besteht darin, dass die Definition, welche Daten von der Komponente benötigt werden, nur auf der Serverseite aktualisiert werden kann, ohne dass JavaScript-Dateien erneut bereitgestellt werden müssen, und der Client kann dumm gemacht werden, indem er einfach den Server auffordert, die Daten bereitzustellen, die er benötigt , wodurch die Komplexität der clientseitigen Anwendung verringert wird.
Darüber hinaus kann das Aufrufen der API zum Abrufen der Daten für alle Komponenten für eine bestimmte URL einfach durch Abfragen dieser URL und Hinzufügen des zusätzlichen Parameters output=json ausgeführt werden, um anzugeben, dass API-Daten zurückgegeben werden, anstatt die Seite zu drucken. Damit wird die URL zu ihrem eigenen Endpunkt oder, anders betrachtet, wird der Begriff „Endpunkt“ obsolet.
Abrufen von Teilmengen von Daten: Daten können für bestimmte Module abgerufen werden, die sich auf jeder Ebene der Komponentenhierarchie befinden
Was passiert, wenn wir nicht die Daten für alle Module auf einer Seite abrufen müssen, sondern einfach die Daten für ein bestimmtes Modul beginnend auf einer beliebigen Ebene der Komponentenhierarchie? Wenn beispielsweise ein Modul ein unendliches Scrollen implementiert, müssen wir beim Herunterscrollen nur neue Daten für dieses Modul abrufen und nicht für die anderen Module auf der Seite.
Dies kann erreicht werden, indem die Zweige der Komponentenhierarchie, die in die Antwort eingeschlossen werden, gefiltert werden, um Eigenschaften nur ab dem angegebenen Modul einzubeziehen und alles oberhalb dieser Ebene zu ignorieren. In meiner Implementierung (die ich in einem kommenden Artikel beschreiben werde) wird die Filterung aktiviert, indem der URL der Parameter modulefilter=modulepaths hinzugefügt wird, und das ausgewählte Modul (oder Module) wird durch einen Parameter modulepaths[] angegeben, wobei ein „Modulpfad ” ist die Liste der Module, beginnend vom obersten Modul bis zum spezifischen Modul (z. B. module1 => module2 => module3 hat den Modulpfad [ module1 , module2 , module3 ] und wird als URL-Parameter als module1.module2.module3 ) .
Beispielsweise hat in der Komponentenhierarchie darunter jedes Modul einen Eintrag dbobjectids :
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Wenn Sie dann die URL der Webseite anfordern und die Parameter modulefilter=modulepaths und modulepaths[]=module1.module2.module5 , wird die folgende Antwort erzeugt:
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] Im Wesentlichen beginnt die API mit dem Laden von Daten ab module1 => module2 => module5 . Deshalb bringt module6 , das unter module5 , auch seine Daten, während module3 und module4 dies nicht tun.
Darüber hinaus können wir benutzerdefinierte Modulfilter erstellen, um einen vorab arrangierten Satz von Modulen einzuschließen. Beispielsweise kann das Aufrufen einer Seite mit modulefilter=userstate nur die Module drucken, für deren Darstellung im Client ein Benutzerstatus erforderlich ist, z. B. die Module module3 und module6 :
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] Die Informationen darüber, welche Startmodule es sind, finden sich im Abschnitt requestmeta unter dem Eintrag filteredmodules als Array von Modulpfaden:
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }Dieses Feature ermöglicht es, eine unkomplizierte Single-Page-Anwendung zu implementieren, bei der der Frame der Seite bei der ersten Anfrage geladen wird:
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] Aber von da an können wir den Parameter modulefilter=page an alle angeforderten URLs anhängen, den Frame herausfiltern und nur den Seiteninhalt bringen:
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] Ähnlich wie bei den oben beschriebenen userstate und page können wir jeden benutzerdefinierten Modulfilter implementieren und umfassende Benutzererfahrungen erstellen.
Das Modul ist eine eigene API
Wie oben gezeigt, können wir die API-Antwort filtern, um Daten von jedem Modul abzurufen. Infolgedessen kann jedes Modul vom Client zum Server mit sich selbst interagieren, indem es einfach seinen Modulpfad zur URL der Webseite hinzufügt, in der es enthalten ist.
Ich hoffe, Sie entschuldigen meine übermäßige Aufregung, aber ich kann wirklich nicht genug betonen, wie wunderbar diese Funktion ist. Beim Erstellen einer Komponente müssen wir keine API erstellen, um Daten abzurufen (REST, GraphQL oder irgendetwas anderes), da die Komponente bereits auf dem Server mit sich selbst kommunizieren und ihre eigenen laden kann Daten – es ist völlig autonom und eigennützig .
Jedes Dataloading-Modul exportiert die URL, um mit ihm unter dem Eintrag dataloadsource aus dem Abschnitt datasetmodulemeta zu interagieren:
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }Das Abrufen von Daten ist modulübergreifend und DRY entkoppelt
Um meinen Standpunkt zu verdeutlichen, dass das Abrufen von Daten in einer komponentenbasierten API stark entkoppelt und DRY (Don’t Repeat Yourself) ist, muss ich zunächst zeigen, wie es in einer schemabasierten API wie GraphQL weniger entkoppelt ist und nicht trocken.
In GraphQL muss die Abfrage zum Abrufen von Daten die Datenfelder für die Komponente angeben, die Unterkomponenten enthalten kann, und diese können auch Unterkomponenten usw. enthalten. Dann muss die oberste Komponente auch wissen, welche Daten von jeder ihrer Unterkomponenten benötigt werden, um diese Daten abzurufen.
Das Rendern der <FeaturedDirector> -Komponente könnte beispielsweise die folgenden Unterkomponenten erfordern:
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> In diesem Szenario wird die GraphQL-Abfrage auf der <FeaturedDirector> -Ebene implementiert. Wenn dann die Unterkomponente <Film> aktualisiert wird und den Titel über die Eigenschaft filmTitle anstelle von title anfordert, muss die Abfrage von der Komponente <FeaturedDirector> ebenfalls aktualisiert werden, um diese neuen Informationen widerzuspiegeln (GraphQL verfügt über einen Versionierungsmechanismus, der damit umgehen kann mit diesem Problem, aber früher oder später sollten wir die Informationen noch aktualisieren). Dies führt zu Wartungskomplexität, die schwierig zu handhaben sein könnte, wenn sich die inneren Komponenten häufig ändern oder von Drittentwicklern produziert werden. Daher sind die Komponenten nicht vollständig voneinander entkoppelt.
In ähnlicher Weise möchten wir möglicherweise die Komponente <Film> für einen bestimmten Film direkt rendern, für den wir dann auch eine GraphQL-Abfrage auf dieser Ebene implementieren müssen, um die Daten für den Film und seine Schauspieler abzurufen, wodurch redundanter Code hinzugefügt wird: Teile von Dieselbe Abfrage lebt auf verschiedenen Ebenen der Komponentenstruktur. GraphQL ist also nicht DRY .
Da eine komponentenbasierte API bereits weiß, wie sich ihre Komponenten in ihrer eigenen Struktur umschließen, werden diese Probleme vollständig vermieden. Zum einen ist der Client in der Lage, die erforderlichen Daten, die er benötigt, einfach anzufordern, egal um welche Daten es sich handelt; if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
In der komponentenbasierten API können wir jedoch ohne weiteres die bereits in der API beschriebenen Beziehungen zwischen Modulen verwenden, um die Module miteinander zu koppeln. Während wir ursprünglich diese Antwort haben werden:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Nach dem Hinzufügen von Instagram erhalten wir die aktualisierte Antwort:
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } Und durch einfaches Iterieren aller Werte unter modulesettings["share-on-social-media"].modules kann die Komponente <ShareOnSocialMedia> aktualisiert werden, um die <InstagramShare> -Komponente anzuzeigen, ohne dass eine JavaScript-Datei erneut bereitgestellt werden muss. Daher unterstützt die API das Hinzufügen und Entfernen von Modulen, ohne den Code anderer Module zu beeinträchtigen, wodurch ein höherer Grad an Modularität erreicht wird.
Nativer clientseitiger Cache/Datenspeicher
Die abgerufenen Datenbankdaten werden in einer Wörterbuchstruktur normalisiert und so standardisiert, dass ausgehend vom Wert auf dbobjectids jedes Datenelement unter databases erreicht werden kann, indem man einfach dem Pfad zu ihm folgt, der durch die Einträge dbkeys angegeben ist, unabhängig davon, wie es strukturiert war . Daher ist die Logik zum Organisieren von Daten bereits in der API selbst enthalten.
Von dieser Situation können wir in mehrfacher Hinsicht profitieren. Beispielsweise können die zurückgegebenen Daten für jede Anfrage einem clientseitigen Cache hinzugefügt werden, der alle vom Benutzer während der gesamten Sitzung angeforderten Daten enthält. Daher ist es möglich, das Hinzufügen eines externen Datenspeichers wie Redux zur Anwendung zu vermeiden (ich meine die Handhabung von Daten, nicht andere Funktionen wie das Undo/Redo, die kollaborative Umgebung oder das Time-Travel-Debugging).
Außerdem fördert die komponentenbasierte Struktur das Caching: Die Komponentenhierarchie hängt nicht von der URL ab, sondern davon, welche Komponenten in dieser URL benötigt werden. Auf diese Weise teilen sich zwei Ereignisse unter /events/1/ und /events/2/ dieselbe Komponentenhierarchie, und die Informationen darüber, welche Module erforderlich sind, können über sie hinweg wiederverwendet werden. Folglich können alle Eigenschaften (außer Datenbankdaten) nach dem Abrufen des ersten Ereignisses auf dem Client zwischengespeichert und von da an wiederverwendet werden, sodass nur Datenbankdaten für jedes nachfolgende Ereignis abgerufen werden müssen und sonst nichts.
Erweiterbarkeit und Umnutzung
Der databases der API kann erweitert werden, sodass seine Informationen in benutzerdefinierte Unterabschnitte kategorisiert werden können. Standardmäßig werden alle Datenbankobjektdaten unter dem Eintrag primary platziert, wir können jedoch auch benutzerdefinierte Einträge erstellen, in denen bestimmte DB-Objekteigenschaften platziert werden.
Wenn zum Beispiel die weiter oben beschriebene Komponente „Für Sie empfohlene Filme“ eine Liste der Freunde des angemeldeten Benutzers anzeigt, die diesen Film unter der Eigenschaft friendsWhoWatchedFilm auf dem film DB-Objekt gesehen haben, da sich dieser Wert je nach Anmeldung ändert user dann speichern wir diese Eigenschaft stattdessen unter einem userstate Eintrag. Wenn sich der Benutzer also abmeldet, löschen wir nur diesen Zweig aus der zwischengespeicherten Datenbank auf dem Client, aber alle primary Daten bleiben erhalten:
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }Darüber hinaus kann die Struktur der API-Antwort bis zu einem bestimmten Punkt umfunktioniert werden. Insbesondere können die Datenbankergebnisse in einer anderen Datenstruktur gedruckt werden, beispielsweise in einem Array anstelle des Standardwörterbuchs.
Wenn der Objekttyp beispielsweise nur einer ist (z. B. films ), kann er als Array formatiert werden, um direkt in eine Typeahead-Komponente eingespeist zu werden:
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Unterstützung für aspektorientierte Programmierung
Neben dem Abrufen von Daten kann die komponentenbasierte API auch Daten posten, z. B. zum Erstellen eines Beitrags oder zum Hinzufügen eines Kommentars, und jede Art von Operation ausführen, z. und so weiter. Es gibt keine Einschränkungen: Jede vom zugrunde liegenden CMS bereitgestellte Funktionalität kann über ein Modul aufgerufen werden – auf jeder Ebene.
Entlang der Komponentenhierarchie können wir eine beliebige Anzahl von Modulen hinzufügen, und jedes Modul kann seine eigene Operation ausführen. Daher müssen sich nicht alle Operationen unbedingt auf die erwartete Aktion der Anfrage beziehen, wie bei einer POST-, PUT- oder DELETE-Operation in REST oder beim Senden einer Mutation in GraphQL, sondern können hinzugefügt werden, um zusätzliche Funktionen wie das Senden einer E-Mail bereitzustellen an den Administrator, wenn ein Benutzer einen neuen Beitrag erstellt.
Durch die Definition der Komponentenhierarchie durch Abhängigkeitsinjektion oder Konfigurationsdateien kann also gesagt werden, dass die API die aspektorientierte Programmierung unterstützt, „ein Programmierparadigma, das darauf abzielt, die Modularität zu erhöhen, indem es die Trennung von Querschnittsthemen ermöglicht“.
Empfohlene Lektüre : Schützen Sie Ihre Website mit Feature-Richtlinien
Verbesserte Sicherheit
Die Namen der Module sind bei der Ausgabe nicht unbedingt fest vorgegeben, sondern können beliebig gekürzt, verstümmelt, zufällig verändert oder (kurz) variabel gemacht werden. Obwohl ursprünglich für die Kürzung der API-Ausgabe gedacht (damit Modulnamen carousel-featured-posts oder drag-and-drop-user-images auf eine Base-64-Notation wie a1 , a2 usw. für die Produktionsumgebung gekürzt werden könnten ), ermöglicht diese Funktion aus Sicherheitsgründen, die Modulnamen in der Antwort von der API häufig zu ändern.
Eingabenamen werden beispielsweise standardmäßig nach ihrem entsprechenden Modul benannt; dann Module namens username und password , die im Client als <input type="text" name="{input_name}"> bzw. <input type="password" name="{input_name}"> werden sollen, können verschiedene zufällige Werte für ihre Eingabenamen festgelegt werden (wie zwH8DSeG und QBG7m6EF heute und c3oMLBjo und c46oVgN6 morgen), wodurch es für Spammer und Bots schwieriger wird, die Website anzugreifen.
Vielseitigkeit durch alternative Modelle
Die Verschachtelung von Modulen ermöglicht es, zu einem anderen Modul zu verzweigen, um die Kompatibilität für ein bestimmtes Medium oder eine bestimmte Technologie hinzuzufügen, oder einige Stile oder Funktionen zu ändern und dann zum ursprünglichen Zweig zurückzukehren.
Nehmen wir zum Beispiel an, die Webseite hat die folgende Struktur:
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" In diesem Fall möchten wir, dass die Website auch für AMP funktioniert, die Module module2 , module4 und module5 sind jedoch nicht AMP-kompatibel. Wir können diese Module in ähnliche, AMP-kompatible Module module2AMP , module4AMP und module5AMP , danach laden wir weiterhin die ursprüngliche Komponentenhierarchie, sodass dann nur diese drei Module ersetzt werden (und sonst nichts):
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"Dies macht es ziemlich einfach, unterschiedliche Ausgaben aus einer einzigen Codebasis zu generieren, Gabeln nur hier und da nach Bedarf hinzuzufügen und immer auf einzelne Module beschränkt und beschränkt zu sein.
Demonstrationszeit
Der Code, der die in diesem Artikel erläuterte API implementiert, ist in diesem Open-Source-Repository verfügbar.
Ich habe die PoP-API zu Demonstrationszwecken unter https://nextapi.getpop.org bereitgestellt. Die Website läuft auf WordPress, daher sind die URL-Permalinks die typischen für WordPress. Wie bereits erwähnt, werden diese URLs durch Hinzufügen des Parameters output=json zu ihren eigenen API-Endpunkten.
Die Website wird von derselben Datenbank wie die PoP-Demo-Website unterstützt, sodass eine Visualisierung der Komponentenhierarchie und der abgerufenen Daten durch Abfrage derselben URL auf dieser anderen Website erfolgen kann (z. B. Besuch von https://demo.getpop.org/u/leo/ erklärt die Daten von https://nextapi.getpop.org/u/leo/?output=json ).
Die folgenden Links zeigen die API für die zuvor beschriebenen Fälle:
- Die Homepage, ein einzelner Beitrag, ein Autor, eine Liste von Beiträgen und eine Liste von Benutzern.
- Ein Ereignis, das aus einem bestimmten Modul herausgefiltert wird.
- Ein Tag, das Module filtert, die einen Benutzerstatus erfordern, und filtert, um nur eine Seite aus einer Single-Page-Anwendung zu bringen.
- Ein Array von Positionen, die in eine Textvervollständigung eingespeist werden.
- Alternative Modelle für die Seite „Wer wir sind“: Normal, Printable, Embeddable.
- Ändern der Modulnamen: Original vs. entstellt.
- Informationen filtern: nur Moduleinstellungen, Moduldaten plus Datenbankdaten.
Fazit
Eine gute API ist ein Sprungbrett für die Erstellung zuverlässiger, leicht wartbarer und leistungsstarker Anwendungen. In diesem Artikel habe ich die Konzepte einer komponentenbasierten API beschrieben, die meiner Meinung nach eine ziemlich gute API ist, und ich hoffe, dass ich auch Sie überzeugt habe.
Bisher haben das Design und die Implementierung der API mehrere Iterationen umfasst und mehr als fünf Jahre gedauert – und sie ist noch nicht vollständig fertig. Es ist jedoch in einem ziemlich anständigen Zustand, nicht produktionsreif, sondern als stabile Alpha. An diesen Tagen arbeite ich immer noch daran; Arbeit an der Definition der offenen Spezifikation, Implementierung der zusätzlichen Schichten (z. B. Rendering) und Schreiben der Dokumentation.
In einem kommenden Artikel werde ich beschreiben, wie meine Implementierung der API funktioniert. Wenn Sie bis dahin irgendwelche Gedanken dazu haben – egal ob positiv oder negativ – würde ich gerne Ihre Kommentare unten lesen.
Update (31. Januar): Benutzerdefinierte Abfragefunktionen
Alain Schlesser kommentierte, dass eine API, die nicht vom Client abgefragt werden kann, wertlos sei, was uns zurück zu SOAP bringt, da sie als solche weder mit REST noch mit GraphQL konkurrieren könne. Nachdem ich einige Tage über seinen Kommentar nachgedacht hatte, musste ich ihm Recht geben. Anstatt jedoch die komponentenbasierte API als gut gemeintes, aber noch nicht ganz fertiges Unterfangen abzutun, habe ich etwas viel Besseres getan: Ich musste die benutzerdefinierte Abfragefunktion dafür implementieren. Und es funktioniert wie ein Zauber!
In den folgenden Links werden Daten für eine Ressource oder Sammlung von Ressourcen abgerufen, wie dies normalerweise über REST erfolgt. Durch Parameterfelder fields wir jedoch auch angeben, welche spezifischen Daten für jede Ressource abgerufen werden sollen, um ein Über- oder Unterholen von Daten zu vermeiden:
- Ein einzelner Beitrag und eine Sammlung von Beiträgen, die Parameterfelder hinzufügen
fields=title,content,datetime - Ein Benutzer und eine Sammlung von Benutzern, die Parameterfelder
fields=name,username,descriptionhinzufügen
Die obigen Links zeigen das Abrufen von Daten nur für die abgefragten Ressourcen. Was ist mit ihren Beziehungen? Angenommen, wir möchten eine Liste von Posts mit den Feldern "title" und "content" abrufen, die Kommentare zu jedem Post mit den Feldern "content" und "date" und den Autor jedes Kommentars mit den Feldern "name" und "url" . Um dies in GraphQL zu erreichen, würden wir die folgende Abfrage implementieren:
query { post { title content comments { content date author { name url } } } } Für die Implementierung der komponentenbasierten API habe ich die Abfrage in ihren entsprechenden „Punkt-Syntax“ fields übersetzt, der dann über Parameterfelder bereitgestellt werden kann. Bei der Abfrage einer „Post“-Ressource lautet dieser Wert:
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url Oder es kann mit | vereinfacht werden So gruppieren Sie alle Felder, die auf dieselbe Ressource angewendet werden:
fields=title|content,comments.content|date,comments.author.name|urlWenn wir diese Abfrage auf einen einzelnen Post ausführen, erhalten wir genau die erforderlichen Daten für alle beteiligten Ressourcen:
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } Daher können wir Ressourcen auf REST-Art abfragen und schemabasierte Abfragen auf GraphQL-Art spezifizieren, und wir erhalten genau das, was erforderlich ist, ohne Daten zu über- oder unterabzuholen und Daten in der Datenbank zu normalisieren, sodass keine Daten dupliziert werden. Vorteilhafterweise kann die Abfrage eine beliebige Anzahl tief verschachtelter Beziehungen enthalten, und diese werden mit linearer Komplexitätszeit aufgelöst: schlimmster Fall von O(n+m), wobei n die Anzahl der Knoten ist, die die Domäne wechseln (in diesem Fall 2: comments und comments.author ) und m ist die Anzahl der abgerufenen Ergebnisse (in diesem Fall 5: 1 Beitrag + 2 Kommentare + 2 Benutzer) und der durchschnittliche Fall von O(n). (Dies ist effizienter als GraphQL, das eine polynomische Komplexitätszeit O (n ^ c) hat und unter einer zunehmenden Ausführungszeit leidet, wenn die Ebenentiefe zunimmt).
Schließlich kann diese API auch Modifikatoren anwenden, wenn Daten abgefragt werden, beispielsweise um zu filtern, welche Ressourcen abgerufen werden, wie dies über GraphQL möglich ist. Um dies zu erreichen, sitzt die API einfach auf der Anwendung und kann ihre Funktionalität bequem nutzen, sodass das Rad nicht neu erfunden werden muss. Wenn Sie beispielsweise die Parameter filter=posts&searchfor=internet hinzufügen, werden alle Posts, die "internet" enthalten, aus einer Sammlung von Posts herausgefiltert.
Die Implementierung dieser neuen Funktion wird in einem kommenden Artikel beschrieben.