
Veröffentlichen Imposter-Domains Ihre Website neu?
Veröffentlicht: 2022-03-10Wir betrachten Web Scraping als ein Werkzeug, das zum Sammeln von Webinhalten für Informationsanalysezwecke verwendet wird, manchmal zum Nachteil des Websitebesitzers. Beispielsweise könnte jemand alle Produktseiten der Einzelhandelswebsite eines Konkurrenten webscrapen, um Informationen über die angebotenen Produkte und die aktuellen Preise zu sammeln, um zu versuchen, einen Wettbewerbsvorteil zu erlangen.
Web Scraping kann verwendet werden, um Marketingdaten zu sammeln, z. B. um gute Keywords für Werbekampagnen zu identifizieren, Trendthemen für Blog-Posts zu identifizieren oder Influencer in wichtigen Blogs und Nachrichtenseiten zu identifizieren. Hersteller können Einzelhandelsseiten durchsuchen, um sicherzustellen, dass die von den Herstellern angekündigten Preise ( MAP ) eingehalten werden, und Sicherheitsprüfer können Websites durchsuchen , um nach Schwachstellen oder Verstößen gegen Datenschutzrichtlinien zu suchen. Und natürlich könnten Scraper Ihre Website durchsuchen, um nach Sicherheitslücken oder offengelegten Kontakt- oder Vertriebsdetails zu suchen. Keine dieser Aktivitäten würde dazu führen, dass der abgekratzte Inhalt erneut veröffentlicht oder an Endbenutzer geliefert wird.
Es gibt jedoch Situationen, in denen der geschabte Webseiteninhalt als Seite selbst direkt an die Besucher geliefert wird. Wie wir weiter unten sehen werden, kann dies aus harmlosen oder weniger harmlosen Gründen geschehen. Im schlimmsten Fall können dies echte Imposter-Domains sein, die versuchen, mit echten Nutzern in Kontakt zu treten, ohne die wahre Quelle Ihrer Inhalte zu nennen . Selbst in gutartigen Anwendungsfällen verlieren Sie jedoch etwas Kontrolle über die Erfahrung des Besuchers. Wenn Ihre Inhalte auf andere Weise, von anderen Servern oder Plattformen bereitgestellt werden, kann dies die Benutzererfahrung und die Geschäftsbeziehung, die Sie mit Ihren Benutzern aufgebaut haben, gefährden.
Wie können Sie dieses Risiko für Ihr Unternehmen identifizieren, nachverfolgen und steuern? Wir untersuchen, wie Sie Webanalysen oder echte Benutzermessdaten auf Ihrer Website verwenden können, um einen Einblick in betrügerische Domains zu erhalten, die Ihre Arbeit erneut veröffentlichen. Wir beschreiben auch die häufigsten Arten der Neuveröffentlichung von Inhalten, die wir in realen Daten sehen, die wir in Akamai mPulse gesammelt haben, sowohl harmlos als auch problematisch, damit Sie wissen, worauf Sie in Ihren Daten achten müssen.
So verfolgen Sie verdächtige Aktivitäten
Wenn Sie sich gerade erst fragen, ob jemand Ihre Webinhalte erneut veröffentlicht, ist das Einfachste, was Sie tun können, eine Google-Suche. Kopieren Sie einen Satz mit zehn oder zwölf Wörtern von einer interessanten Seite Ihrer Website in die Google-Suchleiste, setzen Sie ihn in doppelte Anführungszeichen und klicken Sie auf Suchen. Sie sollten hoffentlich Ihre eigene Website in den Suchergebnissen sehen, aber wenn Sie genau diesen Satz auf anderen Websites finden, werden Sie möglicherweise Opfer einer erneuten Veröffentlichung . Dieser Ansatz ist offensichtlich ein bisschen ad-hoc. Sie könnten vielleicht einige Google-Suchanfragen skripten, um diese Art von Überprüfungen regelmäßig durchzuführen. Aber wie viele Seiten überprüfen Sie? Wie können Sie zuverlässig die Inhalte auf den Seiten auswählen, die durch die Neuveröffentlichung nicht geändert werden? Und was ist, wenn die erneut veröffentlichten Seitenaufrufe es nie in die Suchergebnisse von Google schaffen?
Ein besserer Ansatz besteht darin, die Daten zu verwenden, die Sie bereits mit Ihren Webanalyse- oder R eal User M easurement ( RUM )-Diensten sammeln. Diese Dienste unterscheiden sich erheblich in ihren Fähigkeiten und der Tiefe der gesammelten Daten. Sie alle sind im Allgemeinen als JavaScript-Prozesse instrumentiert, die über ein Tag oder ein Snippet von Loader-Code auf die Webseiten Ihrer Website geladen werden. Wenn der Dienst feststellt, dass ein Seitenaufruf (und/oder eine andere Benutzeraktivität von Interesse) abgeschlossen ist, sendet er einen „Beacon“ von Daten zurück an ein Erfassungssystem, wo die Daten dann weiter verarbeitet, aggregiert und für die Zukunft gespeichert werden Analyse.
Um die Wiederveröffentlichung von Webseiten durch betrügerische Domains zu erkennen, benötigen Sie einen Dienst, der:
- Sammelt Daten für jeden Seitenaufruf auf der Website (idealerweise);
- Erfasst die vollständige URL der Basisseiten- HTML-Ressource der Seitenansicht;
- Akzeptiert Beacons , selbst wenn der Hostname in dieser Basisseiten-URL nicht der ist, unter dem Ihre Website veröffentlicht wird;
- Ermöglicht es Ihnen, die gesammelten Daten selbst abzufragen und/oder verfügt bereits über Datenabfragen, die darauf ausgelegt sind, „Betrüger-Domains“ zu finden.
Was passiert, wenn eine Webseite erneut veröffentlicht wird?
Wenn eine Webseite mit der Absicht gescrappt wird, sie als vollständige Seitenansicht an einen Endbenutzer zu liefern, kann der Scraper den Inhalt ändern. Die Modifikationen können umfangreich sein. Das Ändern einiger Inhalte ist einfacher als andere, und während eine betrügerische Domain Text oder Bilder ändern kann, kann das Ändern von JavaScript eine schwierigere Angelegenheit sein. Versuchte Änderungen in JavaScript können die Seitenfunktionalität beeinträchtigen, die ordnungsgemäße Wiedergabe verhindern oder andere Probleme verursachen.
Die gute Nachricht für uns ist, dass Webanalyse-Tracker oder echte Benutzermessdienste als JavaScript instrumentiert sind und viele betrügerische Domains wahrscheinlich nicht versuchen werden, den Inhalt zu ändern, um sie zu entfernen, da die Gefahr besteht, dass die Seite beschädigt wird. Wenn der Scraper den Loader-Snippet-Code oder das Tag für Ihren Webanalyse- oder RUM-Dienst nicht absichtlich entfernt, werden sie im Allgemeinen erfolgreich geladen und ein Beacon für den Seitenaufruf generiert, wodurch Sie einen Beweis für die Aktivität der betrügerischen Domain erhalten .
Dies ist der Schlüssel zum Tracking von Betrüger-Domains mit Webanalyse- oder RUM-Daten. Selbst wenn kein Seiteninhalt von Ihrer Plattform oder Ihren Servern bereitgestellt wird, können Sie Daten über den Seitenaufruf erhalten, solange der JavaScript-Code, den Sie für Analysen oder Leistungsverfolgung verwenden, geladen wird.
Die Daten in Informationen umwandeln
Jetzt, wo Sie Daten haben, können Sie sie nach Beweisen für betrügerische Domains durchsuchen. Im Grunde ist dies eine Datenbankabfrage, die die Anzahl der Seitenaufrufe nach jedem Hostnamen in der Seiten-URL zählt, etwa wie dieser Pseudocode:
results = query(""" select host, count(*) as count from $(tableName) where timestamp between '$(startTime)' and '$(endTime)' and url not like 'file:%' group by 1 order by 2 desc """);Jeder Hostname in den Ergebnissen, der nicht von Ihrer Website verwendet wird, ist eine betrügerische Domain und es lohnt sich, sie zu untersuchen. Zur fortlaufenden Überwachung der Daten möchten Sie wahrscheinlich die Betrügerdomänen, die Sie in den Daten sehen und identifiziert haben, kategorisieren.
Beispielsweise könnten einige Domains, die von Natural Language Translation-Diensten verwendet werden, die ganze Webseiten neu veröffentlichen , so aussehen:
# Translation domains translationDomains = ["convertlanguage.com","dichtienghoa.com","dict.longdo.com", "motionpoint.com","motionpoint.net","opentrad.com","papago.naver.net","rewordify.com", "trans.hiragana.jp","translate.baiducontent.com","translate.goog", "translate.googleusercontent.com","translate.sogoucdn.com","translate.weblio.jp", "translatetheweb.com","translatoruser-int.com","transperfect.com","webtrans.yodao.com", "webtranslate.tilde.com","worldlingo.com"]Abhängig von Ihren Anforderungen können Sie Arrays von „akzeptablen“ und „problematischen“ Domänen erstellen oder die betrügerischen Domänen nach ihrer Funktion oder ihrem Typ kategorisieren. Nachfolgend sind die häufigsten Arten von betrügerischen Domains aufgeführt, die Sie möglicherweise in realen Daten sehen.
Gutartige Neuveröffentlichung
Nicht alle gekratzten Webseiten, die von einer Drittanbieter-Domain bereitgestellt werden, sind bösartig. Basierend auf der Betrachtung von Akamai mPulse-Daten über ein breites Spektrum von Kunden sind die meisten Seitenaufrufe von betrügerischen Domains tatsächlich Dienste, die ein Website-Besucher absichtlich verwendet. Ein Website-Besucher kann möglicherweise Seiteninhalte genießen, die er für unzugänglich halten würde. In einigen Fällen werden die Dienste wahrscheinlich von den Mitarbeitern des Websitebesitzers selbst genutzt.
Die hier beschriebenen Hauptkategorien sind keineswegs erschöpfend.
Übersetzung in natürliche Sprache
Die häufigsten Betrügerdomänen werden von Übersetzungsdiensten für natürliche Sprachen verwendet. Diese Dienste können eine Webseite kratzen, den verschlüsselten Text auf der Seite in eine andere Sprache übersetzen und diesen modifizierten Inhalt an den Endbenutzer liefern.
Die Seite, die der Endnutzer sieht, hat eine URL von der Top-Level-Domain des Übersetzungsdienstes (wie unter anderem translate.goog, translateuser-int.com oder translate.weblio.jp). rewordify.com wandelt den englischen Text auf einer Seite in einfachere Sätze für Englisch-Anfänger um. Sie haben zwar keine Kontrolle über die Qualität der Übersetzungen oder die Leistung des gelieferten Seitenerlebnisses, es kann jedoch davon ausgegangen werden, dass die meisten Websitebesitzer dies nicht als geschäftliches Risiko oder Bedenken betrachten würden.
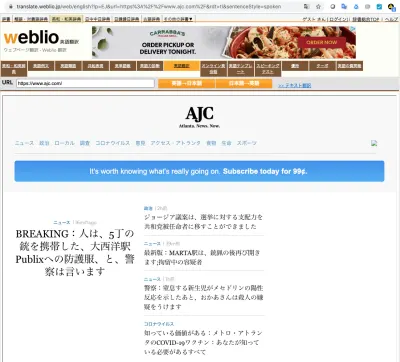
Zwischengespeicherte Ergebnisse von Suchmaschinen und Webarchiven
Eine weitere häufige Kategorie von Imposter-Domains sind Domains, die von Suchmaschinen verwendet werden, um zwischengespeicherte Ergebnisse oder archivierte Versionen von Seitenaufrufen bereitzustellen. In der Regel handelt es sich dabei um Seiten, die möglicherweise nicht mehr auf der Website verfügbar sind, aber in Archiven von Drittanbietern verfügbar sind.
Vielleicht möchten Sie etwas über die Häufigkeit dieser Seitenaufrufe wissen, und eine tiefere Analyse könnte die Einzelheiten dessen bestimmen, wonach Endbenutzer in den Online-Caches und -Archiven gesucht haben. Mit der vollständigen URL für jede Anfrage an die Online-Caches und -Archive sollten Sie in der Lage sein, Schlüsselwörter oder Themen zu identifizieren, die in solchen Seitenaufrufen am häufigsten vorkommen.

Entwicklerwerkzeuge
Diese Dienste werden in der Regel von Ihren eigenen Mitarbeitern als Teil des natürlichen Geschäfts der Entwicklung und des Betriebs Ihrer Website genutzt. Ein typisches Entwicklertool kann eine ganze Webseite kratzen, sie auf Syntaxfehler in JavaScript, XML, HTML oder CSS analysieren und eine markierte Version der Seite anzeigen, die der Entwickler erkunden kann.
Zusätzlich zu Syntaxfehlern können Tools eine Website auch auf die Einhaltung von Zugänglichkeits- oder anderen gesetzlich vorgeschriebenen Standards auswerten. Einige Beispieldienste, die in der realen Welt zu sehen sind, sind codebeautify.org, webaim.org und jsonformatter.org.
Content-Publishing-Tools
Entwicklertools sind Tools sehr ähnlich, die Sie verwenden können, um Ihre Anforderungen an die Veröffentlichung von Inhalten zu verwalten. Das am häufigsten gesehene Beispiel ist das Google Ads Preview-Tool, das eine Seite abruft, sie so ändert, dass sie ein Anzeigen-Tag und Anzeigeninhalte von Google enthält, und sie dem Websitebesitzer anzeigt, um zu sehen, wie das Ergebnis aussehen würde, wenn es veröffentlicht würde.
Eine andere Art von Content-Publishing-Tool ist ein Dienst, der eine Webseite abruft, sie mit Datenbanken auf potenzielle Urheberrechtsverletzungen oder Plagiate überprüft und die Seite mit Markup anzeigt, um potenziell anstößige Inhalte zu identifizieren.
Transcoder-Domänen
Einige Dienste liefern eine Webseite in veränderter Form entweder für eine verbesserte Leistung oder verbesserte Anzeigeeigenschaften. Der gebräuchlichste Dienst dieser Art ist Google Web Light. Google Web Light ist in einer begrenzten Anzahl von Ländern auf Android-Geräten mit langsamen Mobilfunknetzverbindungen verfügbar und transkodiert die Webseite, um bis zu 80 % weniger Bytes bereitzustellen , während ein „Mehrheitswert des relevanten Inhalts“ erhalten bleibt, alles im Namen der Bereitstellung des Inhalts so viel schneller in den Android Mobile Browser.

Andere Transcoder-Dienste modifizieren den Seiteninhalt, um seine Darstellung zu ändern, z. B. entfernt printwhatyoulike.com Werbeelemente in Vorbereitung auf das Drucken auf Papier, und marker.to lässt einen Benutzer eine Webseite mit einem virtuellen gelben Textmarker „markieren“ und die Seite teilen Andere. Obwohl Transcoder-Dienste gut gemeint sein können, gibt es sowohl Missbrauchspotenzial (Entfernen von Werbung) als auch potenzielle Fragen der Inhaltsintegrität, die Sie als Websitebesitzer beachten müssen.
Lokal gespeicherte Kopien von Webseiten
Obwohl dies nicht üblich ist, sehen wir Beacons in den Akamai mPulse-Daten mit Seiten, die von file:// URLs bereitgestellt werden. Dies sind Seitenaufrufe, die von einer zuvor angesehenen Webseite geladen wurden, die im lokalen Speicher des Geräts gespeichert wurde. Da jedes Gerät eine andere Dateisystemstruktur haben könnte, was zu unendlich vielen „Domains“ in den URL-Daten führt, ist es im Allgemeinen nicht sinnvoll, diese zu Mustern zu aggregieren. Es kann davon ausgegangen werden, dass Websitebesitzer dies nicht als geschäftliches Risiko oder Bedenken betrachten würden.
Web-Proxy-Dienste
Eine andere Kategorie von Imposter-Domains, die akzeptabel sein können , sind die, die von Web-Proxy-Diensten verwendet werden. Es gibt zwei große Unterkategorien von mutmaßlich harmlosen Proxy-Diensten. Eine davon sind institutionelle Proxys , wie z. B. ein Universitätsbibliothekssystem, das eine Online-Nachrichtenveröffentlichung abonniert, um seiner Studentenschaft Zugang zu gewähren. Wenn ein Student die Site aufruft, kann die Seite von einem Hostnamen in der Top-Level-Domain der Universität geliefert werden.
Es kann davon ausgegangen werden, dass die meisten Verlage dies nicht als Geschäftsrisiko oder Bedenken betrachten würden, wenn es Teil ihres Geschäftsmodells ist. Die andere wichtige Art gutartiger Proxys sind Websites, die darauf abzielen, Anonymität zu bieten , sodass Besucher den Inhalt einer Website nutzen können, ohne verfolgt oder identifiziert zu werden. Das bekannteste Beispiel für diese letztere Unterkategorie ist der Dienst anonymousbrowser.org. Die Nutzer dieser Dienste können gute Absichten haben oder nicht.
Böswillige Neuveröffentlichung
Wir haben zwar gesehen, dass es harmlose Gründe dafür geben kann, dass eine Webseite gescraped und dann von einer alternativen Domain bereitgestellt wird (und tatsächlich zeigt die Forschung, dass harmlose Anwendungsfälle bei weitem am häufigsten in den Messdaten der realen Benutzer von Akamai mPulse zu sehen sind ), gibt es sicherlich Fälle, in denen die Scraper böswillige Absichten haben. Scraped Content kann verwendet werden, um Einnahmen auf vielfältige Weise zu generieren , von der einfachen Weitergabe gestohlener Inhalte als eigene bis hin zu dem Versuch, Zugangsdaten oder andere Geheimnisse zu stehlen. Böswillige Anwendungsfälle können sowohl dem Websitebesitzer als auch dem Websitebesucher schaden.
Ad-Scraping
In der Verlagsbranche sind Werbeeinnahmen entscheidend für den kommerziellen Erfolg oder Misserfolg von Websites. Natürlich erfordert der Verkauf von Anzeigen Inhalte, die Besucher konsumieren möchten, und einige schlechte Schauspieler finden es möglicherweise einfacher, diese Inhalte zu stehlen, als sie selbst zu erstellen. Ad Scraper können ganze Artikel von einer Website ernten und sie auf einer anderen Top-Level-Domain mit völlig neuen Werbe-Tags erneut veröffentlichen. Wenn der Scraper nicht ausgefeilt genug ist, um den Inhalt vollständig von der Seitenstruktur zu trennen, und beispielsweise JavaScript-Code der Kernseite einschließlich des Loader-Snippets für Ihren Webanalyse- oder RUM-Dienst enthält, können Sie Beacons von Daten für diese Seitenaufrufe erhalten.
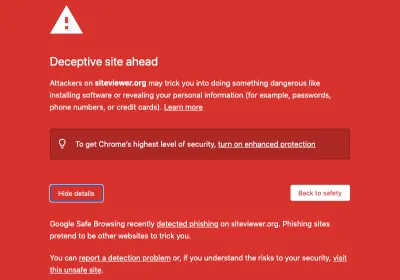
Phishing
Phishing ist ein betrügerischer Versuch, Benutzer dazu zu bringen, vertrauliche oder private Informationen wie Zugangsdaten, Kreditkartennummern, Sozialversicherungsnummern oder andere Daten preiszugeben, indem sie sich als vertrauenswürdige Website ausgeben. Um so authentisch wie möglich auszusehen, werden Phishing-Sites oft erstellt, indem die legitime Site, die sie imitieren sollen, abgekratzt wird . Auch hier gilt: Wenn der Scraper nicht ausgefeilt genug ist, um den Inhalt vollständig von der Seitenstruktur zu trennen, und beispielsweise den Kernseitencode einschließlich des Loader-Snippets für Ihren Webanalyse- oder RUM-Dienst enthält, können Sie Beacons für diese Seitenaufrufe in mPulse erhalten.
Browser- oder Suchhijacking
Eine Webseite kann mit zusätzlichem JavaScript, das Browser- oder Such-Hijacking-Angriffscode enthält, gescraped und erneut veröffentlicht werden. Im Gegensatz zu Phishing, bei dem Benutzer dazu verleitet werden, wertvolle Daten preiszugeben, versucht diese Art von Angriff , Änderungen an den Browsereinstellungen vorzunehmen . Einfach die Standardsuchmaschine des Browsers so zu ändern, dass sie auf eine verweist, von der der Angreifer Einnahmen aus Affiliate-Suchergebnissen erhält, könnte für einen schlechten Akteur profitabel sein. Wenn der Scraper nicht ausgefeilt ist und neuen Angriffscode einfügt, aber den bereits vorhandenen Kernseitencode einschließlich des Loader-Snippets für Ihren Webanalyse- oder RUM-Dienst nicht ändert, können Sie Beacons für diese Seitenaufrufe in mPulse erhalten.
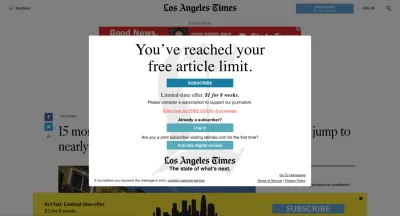
Paywall- oder Abonnement-Bypass-Proxys
Einige Dienste geben vor, Endbenutzern dabei zu helfen, auf Seiten auf Websites zuzugreifen, für deren Anzeige Abonnements erforderlich sind, ohne über eine gültige Anmeldung zu verfügen. Für einige Content-Publisher können Abonnementgebühren einen sehr wichtigen Teil der Website-Einnahmen ausmachen. Für andere können Anmeldungen erforderlich sein, um gesetzeskonform zu bleiben, damit Benutzer Inhalte konsumieren können, die durch Alter, Staatsbürgerschaft, Wohnsitz oder andere Kriterien eingeschränkt sind.
Proxy-Dienste, die diese Zugriffsbeschränkungen umgehen (oder zu umgehen versuchen), stellen finanzielle und rechtliche Risiken für Ihr Unternehmen dar . Subjektiv scheinen sich viele dieser Dienste speziell auf Pornoseiten zu konzentrieren, aber alle Websitebesitzer sollten nach diesen schlechten Schauspielern Ausschau halten.
Fehlinformationen
Zusätzlich zu dem Versuch, vom Web Scraping zu profitieren, können einige betrügerische Domains verwendet werden, um Inhalte bereitzustellen, die so modifiziert wurden, dass sie absichtlich Fehlinformationen verbreiten, den Ruf schädigen oder für politische oder andere Zwecke.
Verwaltung der Ergebnisse
Da Sie nun erkennen und nachverfolgen können, wann betrügerische Domains Ihre Website erneut veröffentlichen, was sind die nächsten Schritte? Tools sind nur so wertvoll wie unsere Fähigkeit, sie effektiv zu nutzen, daher ist es wichtig, eine Strategie für die Verwendung einer betrügerischen Domain-Tracking-Lösung als Teil Ihrer Geschäftsprozesse zu entwickeln. Auf hoher Ebene reduziert sich dies meiner Meinung nach darauf, Entscheidungen über einen dreistufigen Managementprozess zu treffen:
- Identifizieren Sie die Bedrohung,
- Priorisieren Sie die Bedrohung,
- Beheben Sie die Bedrohung.
1. Identifizierung von Bedrohungen durch regelmäßige Berichterstattung
Sobald Sie die Datenbankabfragen entwickelt haben, um potenzielle Betrügerdomänendaten aus Ihren Webanalyse- oder Real User Measurement-Daten zu extrahieren, müssen Sie sich die Daten regelmäßig ansehen.
Als Ausgangspunkt würde ich einen wöchentlichen Bericht empfehlen, der schnell nach neuen Aktivitäten durchsucht werden kann. Ein wöchentlicher Bericht scheint der beste Rhythmus zu sein, um Probleme zu erkennen, bevor sie zu schwerwiegend werden. Ein täglicher Bericht kann sich langweilig anfühlen und nach einer Weile leicht ignoriert werden. Tägliche Zahlen können auch schwieriger zu interpretieren sein, da Sie eine recht kleine Anzahl von Seitenaufrufen betrachten können, die möglicherweise einen besorgniserregenden Trend darstellen oder nicht.
Andererseits kann die monatliche Berichterstattung dazu führen, dass Probleme zu lange andauern, bevor sie entdeckt werden. Ein wöchentlicher Bericht scheint für die meisten Websites die richtige Balance zu sein und ist wahrscheinlich der beste Startrhythmus für regelmäßige Berichte.
2. Kategorisierung der potenziellen Bedrohung
Wie wir oben betrachtet haben, sind nicht alle betrügerischen Domains, die Ihre Website-Inhalte erneut veröffentlichen, notwendigerweise böswilliger Natur oder ein Problem für Ihr Unternehmen. Wenn Sie Erfahrung mit der Landschaft der Daten Ihrer eigenen Website sammeln, können Sie Ihre regelmäßige Berichterstattung verbessern, indem Sie Domänen, die Sie kennen und die Sie als nicht bösartig betrachten, farblich kennzeichnen oder trennen, um sich auf die unbekannten, neuen oder bekannten problematischen Domänen zu konzentrieren am wichtigsten.
Je nach Ihren Anforderungen können Sie Arrays von „akzeptablen“ und „problematischen“ Domains aufbauen oder die betrügerischen Domains nach ihrer Funktion oder ihrem Typ kategorisieren (z. B. die oben beschriebenen Kategorien „natürliche Sprachübersetzung“ oder „Inhaltsveröffentlichungstools“). Jede Website hat unterschiedliche Anforderungen, aber das Ziel besteht darin, die problematischen Domänen von den nicht besorgniserregenden Domänen zu trennen.
3. Handeln Sie gegen die schlechten Schauspieler
Bestimmen Sie für jede der von Ihnen identifizierten problematischen Kategorien die Parameter, die Sie verwenden möchten, wenn Sie entscheiden, wie auf die Bedrohung reagiert werden soll:
- Was ist die Mindestzahl der Seitenaufrufe, bevor wir Maßnahmen ergreifen?
- Was ist der erste Eskalationspunkt und wer ist dafür verantwortlich ?
- Welche Stakeholder innerhalb des Unternehmens müssen sich der böswilligen Aktivität bewusst sein und wann?
- Werden die zu ergreifenden Maßnahmen dokumentiert und von allen Beteiligten (Führungskräfte, Rechtsabteilung usw.) regelmäßig überprüft ?
- Wenn Maßnahmen ergriffen werden (z. B. das Einreichen einer „DMCA Takedown“-Mitteilung beim Täter oder seinem Dienstanbieter oder das Aktualisieren der Regeln der Webanwendungs-Firewall, um zu versuchen, den Zugriff auf die Inhaltsdiebe zu beschränken), werden die Ergebnisse dieser Maßnahmen nachverfolgt und bestätigt?
- Wie wird die Wirksamkeit dieser Maßnahmen für Führungskräfte im Laufe der Zeit zusammengefasst?
Selbst wenn es Ihnen nicht gelingt, jede böswillige Wiederveröffentlichung Ihrer Website-Inhalte zu unterdrücken, sollten Sie dennoch einen soliden Prozess aufbauen , um die Risiken wie jedes andere Risiko für das Unternehmen zu managen. Es schafft Vertrauen und Autorität bei Ihren Geschäftspartnern, Investoren, Mitarbeitern und Mitwirkenden.
Fazit
Unter den richtigen Umständen können Ihre Webanalyse- oder echten Benutzermessdaten einen Einblick in die Welt der betrügerischen Domains bieten, die von Web Scrapern verwendet werden, um Ihre Website-Inhalte auf ihren Servern erneut zu veröffentlichen. Viele dieser betrügerischen Domains sind tatsächlich gutartige Dienste, die entweder Endbenutzern helfen oder Ihnen auf verschiedene produktive Weise helfen.
In anderen Fällen haben die Betrüger-Domains böswillige Motive, entweder Inhalte für Profit zu stehlen oder sie auf eine Weise zu manipulieren, die Ihrem Unternehmen oder Ihrem Website-Besucher Schaden zufügt. Webanalyse- oder RUM-Daten sind Ihre Geheimwaffe, um potenziell bösartige Betrüger-Domains zu identifizieren, die sofortige Maßnahmen erfordern , und um die Verbreitung der harmloseren Domains besser zu verstehen. Die von Ihnen gesammelten Daten nutzen die Position des Webanalyse- oder RUM-Dienstes als Beobachter im eigenen Browser des Besuchers, um das zu sehen, was Ihre Plattformüberwachungs- und Berichtstools nicht können.
Durch die Analyse der Daten im Laufe der Zeit können Sie mehr und mehr über betrügerische Domains und ihre Absichten erfahren, um Ihr Unternehmen besser über die Risiken zu informieren, die sie für Ihren Ruf und die Erfahrungen Ihrer Besucher darstellen, und Mechanismen zum Schutz Ihres geistigen Eigentums entwickeln und durchsetzen.
Weiterführende Literatur zum Smashing Magazine
- Schützen Sie Ihre Website mit Feature-Richtlinien
- Machen Sie Ihre Websites mithilfe von Google schnell, zugänglich und sicher
- Was Sie über OAuth2 und die Anmeldung mit Facebook wissen müssen
- Inhaltssicherheitsrichtlinie, Ihr zukünftiger bester Freund
- Gegen Datenschutzverletzungen im Internet vorgehen