
Bild-zu-Text-Konvertierung mit React und Tesseract.js (OCR)
Veröffentlicht: 2022-03-10Daten sind das Rückgrat jeder Softwareanwendung, da der Hauptzweck einer Anwendung darin besteht, menschliche Probleme zu lösen. Um menschliche Probleme zu lösen, ist es notwendig, einige Informationen über sie zu haben.
Solche Informationen werden als Daten dargestellt, insbesondere durch Berechnung. Im Web werden Daten meist in Form von Texten, Bildern, Videos und vielem mehr gesammelt. Manchmal enthalten Bilder wesentliche Texte, die verarbeitet werden sollen, um einen bestimmten Zweck zu erreichen. Diese Bilder wurden größtenteils manuell verarbeitet, da es keine Möglichkeit gab, sie programmgesteuert zu verarbeiten.
Die Unfähigkeit, Text aus Bildern zu extrahieren, war eine Einschränkung der Datenverarbeitung, die ich in meiner letzten Firma aus erster Hand erlebt habe. Wir mussten gescannte Geschenkkarten verarbeiten, und zwar manuell, da wir keinen Text aus Bildern extrahieren konnten.
Innerhalb des Unternehmens gab es eine Abteilung namens „Operations“, die für die manuelle Bestätigung von Geschenkkarten und die Gutschrift auf Benutzerkonten zuständig war. Obwohl wir eine Website hatten, über die Benutzer mit uns verbunden waren, wurde die Verarbeitung von Geschenkkarten hinter den Kulissen manuell durchgeführt.
Unsere Website wurde damals hauptsächlich mit PHP (Laravel) für das Backend und JavaScript (jQuery und Vue) für das Frontend erstellt. Unser technischer Stack war gut genug, um mit Tesseract.js zu arbeiten, vorausgesetzt, das Problem wurde vom Management als wichtig erachtet.
Ich war bereit, das Problem zu lösen, aber es war nicht notwendig, das Problem aus der Sicht des Unternehmens oder des Managements zu lösen. Nachdem ich das Unternehmen verlassen hatte, beschloss ich, etwas zu recherchieren und mögliche Lösungen zu finden. Schließlich entdeckte ich OCR.
Was ist OCR?
OCR steht für „Optical Character Recognition“ oder „Optical Character Reader“. Es wird verwendet, um Texte aus Bildern zu extrahieren.
Die Entwicklung der OCR lässt sich auf mehrere Erfindungen zurückführen, aber Optophone, „Gismo“, CCD-Flachbettscanner, Newton MesssagePad und Tesseract sind die wichtigsten Erfindungen, die die Zeichenerkennung auf eine andere Nützlichkeitsebene heben.
Warum also OCR verwenden? Nun, die optische Zeichenerkennung löst viele Probleme, von denen mich eines veranlasst hat, diesen Artikel zu schreiben. Mir wurde klar, dass die Möglichkeit, Texte aus einem Bild zu extrahieren, viele Möglichkeiten bietet, wie zum Beispiel:
- Verordnung
Jede Organisation muss aus bestimmten Gründen die Aktivitäten der Benutzer regulieren. Die Verordnung könnte verwendet werden, um die Rechte der Benutzer zu schützen und sie vor Bedrohungen oder Betrug zu schützen.
Das Extrahieren von Texten aus einem Bild ermöglicht es einer Organisation, Textinformationen zu einem Bild für die Regulierung zu verarbeiten, insbesondere wenn die Bilder von einigen der Benutzer bereitgestellt werden.
Beispielsweise kann mit OCR eine Facebook-ähnliche Regulierung der Anzahl von Texten auf Bildern erreicht werden, die für Anzeigen verwendet werden. Auch das Ausblenden sensibler Inhalte auf Twitter wird durch OCR ermöglicht. - Durchsuchbarkeit
Das Suchen ist eine der häufigsten Aktivitäten, insbesondere im Internet. Suchalgorithmen basieren meist auf der Manipulation von Texten. Mit der optischen Zeichenerkennung ist es möglich, Zeichen auf Bildern zu erkennen und sie zu verwenden, um Benutzern relevante Bildergebnisse bereitzustellen. Kurz gesagt, Bilder und Videos sind jetzt mit Hilfe von OCR durchsuchbar. - Barrierefreiheit
Texte auf Bildern zu haben, war schon immer eine Herausforderung für Barrierefreiheit und es ist die Faustregel, wenige Texte auf einem Bild zu haben. Mit OCR können Screenreader auf Texte auf Bildern zugreifen, um ihren Benutzern die notwendige Erfahrung zu bieten. - Automatisierung der Datenverarbeitung Die Verarbeitung von Daten wird größtenteils automatisiert, um eine Skalierung zu erreichen. Texte auf Bildern zu haben, ist eine Einschränkung der Datenverarbeitung, da die Texte nur manuell verarbeitet werden können. Optical Character Recognition (OCR) ermöglicht es, Texte auf Bildern programmgesteuert zu extrahieren und sorgt so für eine Automatisierung der Datenverarbeitung, insbesondere wenn es um die Verarbeitung von Texten auf Bildern geht.
- Digitalisierung gedruckter Materialien
Alles wird digital und es müssen noch viele Dokumente digitalisiert werden. Schecks, Zertifikate und andere physische Dokumente können jetzt mit Hilfe der optischen Zeichenerkennung digitalisiert werden.
Das Herausfinden aller oben genannten Verwendungen vertiefte mein Interesse, also beschloss ich, weiter zu gehen, indem ich eine Frage stellte:
„Wie kann ich OCR im Web verwenden, insbesondere in einer React-Anwendung?“
Diese Frage führte mich zu Tesseract.js.
Was ist Tesseract.js?
Tesseract.js ist eine JavaScript-Bibliothek, die das ursprüngliche Tesseract von C zu JavaScript WebAssembly kompiliert und dadurch OCR im Browser zugänglich macht. Die Tesseract.js-Engine wurde ursprünglich in ASM.js geschrieben und später auf WebAssembly portiert, aber ASM.js dient in einigen Fällen immer noch als Backup, wenn WebAssembly nicht unterstützt wird.
Wie auf der Website von Tesseract.js angegeben, unterstützt es mehr als 100 Sprachen , automatische Textausrichtung und Skripterkennung, eine einfache Schnittstelle zum Lesen von Absätzen, Wörtern und Zeichenbegrenzungsrahmen.
Tesseract ist eine optische Zeichenerkennungsmaschine für verschiedene Betriebssysteme. Es ist freie Software, veröffentlicht unter der Apache-Lizenz. Hewlett-Packard entwickelte Tesseract als proprietäre Software in den 1980er Jahren. Es wurde 2005 als Open Source veröffentlicht und seine Entwicklung wird seit 2006 von Google gesponsert.
Die neueste Version, Version 4, von Tesseract wurde im Oktober 2018 veröffentlicht und enthält eine neue OCR-Engine, die ein neuronales Netzwerksystem auf Basis von Long Short-Term Memory (LSTM) verwendet und genauere Ergebnisse liefern soll.
Tesseract-APIs verstehen
Um wirklich zu verstehen, wie Tesseract funktioniert, müssen wir einige seiner APIs und ihre Komponenten aufschlüsseln. Laut der Tesseract.js-Dokumentation gibt es zwei Möglichkeiten, es zu verwenden. Unten ist der erste Ansatz und seine Aufschlüsselung:
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } Die Methode " recognize " nimmt "image" als erstes Argument, "language" (kann mehrere sein) als zweites Argument und { logger: m => console.log(me) } als letztes Argument. Die von Tesseract unterstützten Bildformate sind jpg, png, bmp und pbm, die nur als Elemente (img, video oder canvas), Dateiobjekt ( <input> ), Blob-Objekt, Pfad oder URL zu einem Bild und base64-codiertes Bild geliefert werden können . (Lesen Sie hier weitere Informationen zu allen Bildformaten, die Tesseract verarbeiten kann.)
Die Sprache wird als Zeichenfolge bereitgestellt, z. B. eng . Das + -Zeichen könnte verwendet werden, um mehrere Sprachen zu verketten, wie in eng+chi_tra . Das Sprachargument wird verwendet, um die trainierten Sprachdaten zu bestimmen, die bei der Verarbeitung von Bildern verwendet werden sollen.
Hinweis : Hier finden Sie alle verfügbaren Sprachen und ihre Codes.
{ logger: m => console.log(m) } ist sehr nützlich, um Informationen über den Fortschritt eines verarbeiteten Bildes zu erhalten. Die Logger-Eigenschaft übernimmt eine Funktion, die mehrmals aufgerufen wird, wenn Tesseract ein Bild verarbeitet. Der Parameter für die Logger-Funktion sollte ein Objekt mit workerId , jobId , status und progress als Eigenschaften sein:
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress ist eine Zahl zwischen 0 und 1 und wird in Prozent angegeben, um den Fortschritt eines Bilderkennungsprozesses anzuzeigen.
Tesseract generiert das Objekt automatisch als Parameter für die Logger-Funktion, es kann aber auch manuell bereitgestellt werden. Da ein Erkennungsprozess stattfindet, werden die Objekteigenschaften des logger bei jedem Aufruf der Funktion aktualisiert . So kann es verwendet werden, um einen Konvertierungsfortschrittsbalken anzuzeigen, einen Teil einer Anwendung zu ändern oder jedes gewünschte Ergebnis zu erzielen.
Das result im obigen Code ist das Ergebnis des Bilderkennungsprozesses. Jede der Eigenschaften von result hat die Eigenschaft bbox als x/y-Koordinaten ihres Begrenzungsrahmens.
Hier sind die Eigenschaften des result , ihre Bedeutung oder Verwendung:
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: Der gesamte erkannte Text als Zeichenfolge. -
lines: Ein Array mit allen erkannten Textzeilen. -
words: Ein Array aller erkannten Wörter. -
symbols: Ein Array aller erkannten Zeichen. -
paragraphs: Ein Array aller erkannten Absätze. Wir werden „Vertrauen“ später in diesem Artikel besprechen.
Tesseract kann auch zwingender verwendet werden wie in:
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();Dieser Ansatz ist mit dem ersten Ansatz verwandt, jedoch mit unterschiedlichen Implementierungen.
createWorker(options) erstellt einen Web-Worker oder einen untergeordneten Knotenprozess, der einen Tesseract-Worker erstellt. Der Mitarbeiter hilft beim Einrichten der Tesseract-OCR-Engine. Die load() Methode lädt die Tesseract-Kernskripte, loadLanguage() lädt jede ihm bereitgestellte Sprache als Zeichenfolge, initialize() stellt sicher, dass Tesseract vollständig einsatzbereit ist, und dann wird die detect-Methode verwendet, um das bereitgestellte Bild zu verarbeiten. Die Methode "terminate()" stoppt den Worker und bereinigt alles.
Hinweis : Weitere Informationen finden Sie in der Tesseract-API-Dokumentation.
Jetzt müssen wir etwas bauen, um wirklich zu sehen, wie effektiv Tesseract.js ist.
Was werden wir bauen?
Wir werden einen PIN-Extraktor für Geschenkkarten bauen, weil das Extrahieren der PIN aus einer Geschenkkarte das Problem war, das überhaupt zu diesem Schreibabenteuer geführt hat.
Wir werden eine einfache Anwendung erstellen, die die PIN aus einer gescannten Geschenkkarte extrahiert . Während ich mich daran machte, einen einfachen Pin-Extraktor für Geschenkkarten zu bauen, werde ich Sie durch einige der Herausforderungen führen, mit denen ich unterwegs konfrontiert war, die Lösungen, die ich bereitgestellt habe, und meine Schlussfolgerung, die auf meiner Erfahrung basiert.
- Gehen Sie zu Quellcode →
Unten ist das Bild, das wir zum Testen verwenden werden, da es einige realistische Eigenschaften hat, die in der realen Welt möglich sind.

Wir extrahieren AQUX-QWMB6L-R6JAU von der Karte. Also lasst uns anfangen.
Installation von React und Tesseract
Es gibt eine Frage, die vor der Installation von React und Tesseract.js beantwortet werden muss, und die Frage ist, warum React mit Tesseract verwendet werden sollte. Praktisch können wir Tesseract mit Vanilla JavaScript, beliebigen JavaScript-Bibliotheken oder Frameworks wie React, Vue und Angular verwenden.
Die Verwendung von React ist in diesem Fall eine persönliche Präferenz. Ursprünglich wollte ich Vue verwenden, aber ich habe mich für React entschieden, weil ich mit React besser vertraut bin als mit Vue.
Fahren wir nun mit den Installationen fort.
Um React mit create-react-app zu installieren, müssen Sie den folgenden Code ausführen:
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.jsoder
npm install tesseract.jsIch habe mich für die Installation von Tesseract.js mit Garn entschieden, da ich Tesseract nicht mit npm installieren konnte, aber Garn hat die Arbeit ohne Stress erledigt. Sie können npm verwenden, aber ich empfehle, Tesseract mit Garn nach meiner Erfahrung zu installieren.
Lassen Sie uns nun unseren Entwicklungsserver starten, indem Sie den folgenden Code ausführen:
yarn startoder
npm startNach dem Ausführen von thread start oder npm start sollte Ihr Standardbrowser eine Webseite öffnen, die wie folgt aussieht:

Sie können im Browser auch zu localhost:3000 navigieren, sofern die Seite nicht automatisch gestartet wird.
Was kommt nach der Installation von React und Tesseract.js?
Einrichten eines Upload-Formulars
In diesem Fall passen wir die Startseite (App.js), die wir gerade im Browser angezeigt haben, so an, dass sie das benötigte Formular enthält:
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App Der Teil des obigen Codes, der an dieser Stelle unsere Aufmerksamkeit erfordert, ist die Funktion handleChange .
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } In der Funktion nimmt URL.createObjectURL eine ausgewählte Datei durch event.target.files[0] und erstellt eine Referenz-URL, die mit HTML-Tags wie img, audio und video verwendet werden kann. Wir setImagePath verwendet, um die URL zum Zustand hinzuzufügen. Nun kann mit imagePath auf die URL zugegriffen werden.
<img src={imagePath} className="App-logo" alt="image"/> Wir setzen das src-Attribut des Bildes auf {imagePath} , um eine Vorschau im Browser anzuzeigen, bevor es verarbeitet wird.
Konvertieren ausgewählter Bilder in Texte
Da wir den Pfad zum ausgewählten Bild erfasst haben, können wir den Pfad des Bildes an Tesseract.js übergeben, um Texte daraus zu extrahieren.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default AppWir fügen die Funktion „handleClick“ zu „App.js“ hinzu und sie enthält die Tesseract.js-API, die den Pfad zum ausgewählten Bild übernimmt. Tesseract.js nimmt „imagePath“, „language“, „ein Einstellungsobjekt“.
Die Schaltfläche unten wird dem Formular hinzugefügt, um „handClick“ aufzurufen, das die Bild-zu-Text-Konvertierung auslöst, wenn auf die Schaltfläche geklickt wird.
<button onClick={handleClick} style={{height:50}}> convert to text</button>Wenn die Verarbeitung erfolgreich ist, greifen wir aus dem Ergebnis sowohl auf „Vertrauen“ als auch auf „Text“ zu. Dann fügen wir dem Zustand mit „setText(text)“ „text“ hinzu.
Durch Hinzufügen zu <p> {text} </p> zeigen wir den extrahierten Text an.
Es ist offensichtlich, dass „Text“ aus dem Bild extrahiert wird, aber was ist Vertrauen?
Vertrauen zeigt, wie genau die Konvertierung ist. Das Konfidenzniveau liegt zwischen 1 und 100. 1 steht für die schlechteste, während 100 für die beste Genauigkeit steht. Es kann auch verwendet werden, um zu bestimmen, ob ein extrahierter Text als genau akzeptiert werden soll oder nicht.
Dann stellt sich die Frage, welche Faktoren den Vertrauenswert oder die Genauigkeit der gesamten Konvertierung beeinflussen können. Es wird hauptsächlich von drei Hauptfaktoren beeinflusst – der Qualität und Art des verwendeten Dokuments, der Qualität des aus dem Dokument erstellten Scans und den Verarbeitungsfähigkeiten der Tesseract-Engine.
Lassen Sie uns nun den folgenden Code zu „App.css“ hinzufügen, um die Anwendung ein wenig zu stylen.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }Hier das Ergebnis meines ersten Tests :
Ergebnis in Firefox
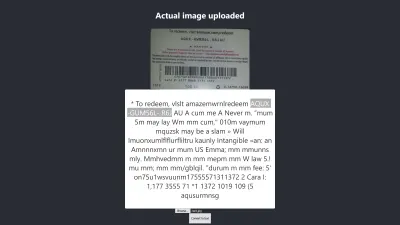
Das Vertrauensniveau des obigen Ergebnisses beträgt 64. Es ist erwähnenswert, dass das Bild der Geschenkkarte eine dunkle Farbe hat und sich definitiv auf das Ergebnis auswirkt, das wir erhalten.

Wenn Sie sich das obige Bild genauer ansehen, sehen Sie, dass der Pin von der Karte im extrahierten Text fast genau ist. Es ist nicht genau, weil die Geschenkkarte nicht wirklich klar ist.
Oh, Moment mal! Wie wird es in Chrome aussehen?
Ergebnis in Chrome
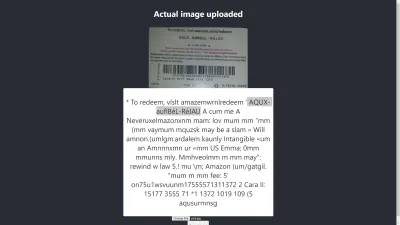
Ah! Noch schlimmer ist das Ergebnis in Chrome. Aber warum unterscheidet sich das Ergebnis in Chrome von Mozilla Firefox? Verschiedene Browser behandeln Bilder und ihre Farbprofile unterschiedlich. Das heißt, ein Bild kann je nach Browser unterschiedlich gerendert werden . Durch die Bereitstellung vorgerenderter image.data an Tesseract wird es wahrscheinlich zu unterschiedlichen Ergebnissen in verschiedenen Browsern kommen, da Tesseract je nach verwendetem Browser unterschiedliche image.data bereitgestellt werden. Die Vorverarbeitung eines Bildes, wie wir später in diesem Artikel sehen werden, trägt dazu bei, ein konsistentes Ergebnis zu erzielen.
Wir müssen genauer sein, damit wir sicher sein können, dass wir die richtigen Informationen erhalten oder geben. Wir müssen also etwas weiter ausholen.
Lassen Sie uns mehr versuchen, um zu sehen, ob wir das Ziel am Ende erreichen können.
Prüfung auf Genauigkeit
Es gibt viele Faktoren, die eine Bild-zu-Text-Konvertierung mit Tesseract.js beeinflussen. Die meisten dieser Faktoren drehen sich um die Art des Bildes, das wir verarbeiten möchten, und der Rest hängt davon ab, wie die Tesseract-Engine die Konvertierung handhabt.
Intern verarbeitet Tesseract Bilder vor der eigentlichen OCR-Konvertierung, liefert aber nicht immer genaue Ergebnisse.
Als Lösung können wir Bilder vorverarbeiten, um genaue Konvertierungen zu erzielen. Wir können ein Bild binarisieren, invertieren, dilatieren, geraderichten oder neu skalieren, um es für Tesseract.js vorzuverarbeiten.
Die Bildvorverarbeitung ist viel Arbeit oder ein weites Feld für sich. Glücklicherweise hat P5.js alle Bildvorverarbeitungstechniken bereitgestellt, die wir verwenden möchten. Anstatt das Rad neu zu erfinden oder die gesamte Bibliothek zu verwenden, nur weil wir einen winzigen Teil davon verwenden möchten, habe ich die benötigten kopiert. Alle Bildvorverarbeitungstechniken sind in preprocess.js enthalten.
Was ist Binarisierung?
Binarisierung ist die Umwandlung der Pixel eines Bildes in Schwarz oder Weiß. Wir möchten die vorherige Geschenkkarte binarisieren, um zu prüfen, ob die Genauigkeit besser ist oder nicht.
Zuvor haben wir einige Texte aus einer Geschenkkarte extrahiert, aber die Ziel-PIN war nicht so genau wie wir wollten. Es muss also ein anderer Weg gefunden werden, um ein genaues Ergebnis zu erhalten.
Jetzt wollen wir den Geschenkgutschein binarisieren , dh wir wollen seine Pixel in Schwarzweiß umwandeln, damit wir sehen können, ob eine bessere Genauigkeit erreicht werden kann oder nicht.
Die folgenden Funktionen werden für die Binarisierung verwendet und sind in einer separaten Datei namens preprocess.js enthalten.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImageWas macht der obige Code?
Wir führen Canvas ein, um Bilddaten zu speichern, um einige Filter anzuwenden, um das Bild vorzuverarbeiten, bevor es zur Konvertierung an Tesseract übergeben wird.
Die erste preprocessImage Funktion befindet sich in preprocess.js und bereitet die Leinwand für die Verwendung vor, indem sie ihre Pixel erhält. Die Funktion „ thresholdFilter “ digitalisiert das Bild, indem es seine Pixel entweder in Schwarz oder Weiß umwandelt .
Rufen wir preprocessImage auf, um zu sehen, ob der aus der vorherigen Geschenkkarte extrahierte Text genauer sein kann.
Wenn wir App.js aktualisieren, sollte es jetzt wie folgt aussehen:
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default AppZuerst müssen wir „preprocessImage“ aus „preprocess.js“ mit dem folgenden Code importieren:
import preprocessImage from './preprocess'; Dann fügen wir dem Formular ein Canvas-Tag hinzu. Wir setzen das ref-Attribut sowohl des canvas- als auch des img-Tags auf { canvasRef } bzw. { imageRef } . Die Refs werden verwendet, um auf die Zeichenfläche und das Bild von der App-Komponente zuzugreifen. Wir erhalten sowohl die Leinwand als auch das Bild mit „useRef“ wie in:
const canvasRef = useRef(null); const imageRef = useRef(null);In diesem Teil des Codes führen wir das Bild mit der Leinwand zusammen, da wir eine Leinwand nur in JavaScript vorverarbeiten können. Wir konvertieren es dann in eine Daten-URL mit „jpeg“ als Bildformat.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");„dataUrl“ wird als zu verarbeitendes Bild an Tesseract übergeben.
Lassen Sie uns nun prüfen, ob der extrahierte Text genauer ist.
Test Nr. 2

Das obige Bild zeigt das Ergebnis in Firefox. Es ist offensichtlich, dass der dunkle Teil des Bildes in Weiß geändert wurde, aber eine Vorverarbeitung des Bildes führt nicht zu einem genaueren Ergebnis. Es ist noch schlimmer.
Die erste Konvertierung hat nur zwei falsche Zeichen , aber diese hat vier falsche Zeichen. Ich habe sogar versucht, den Schwellenwert zu ändern, aber ohne Erfolg. Wir erhalten kein besseres Ergebnis, nicht weil die Binarisierung schlecht ist, sondern weil die Binarisierung des Bildes die Natur des Bildes nicht auf eine Weise festlegt, die für die Tesseract-Engine geeignet ist.
Lassen Sie uns überprüfen, wie es auch in Chrome aussieht:

Wir erhalten das gleiche Ergebnis.
Nachdem durch die Binarisierung des Bildes ein schlechteres Ergebnis erzielt wurde, müssen andere Bildvorverarbeitungstechniken überprüft werden, um festzustellen, ob wir das Problem lösen können oder nicht. Also werden wir als nächstes Dilatation, Inversion und Unschärfe ausprobieren.
Holen wir uns einfach den Code für jede der Techniken aus P5.js, wie er in diesem Artikel verwendet wird. Wir werden die Bildverarbeitungstechniken zu preprocess.js hinzufügen und sie nacheinander verwenden. Es ist notwendig, jede der Bildvorverarbeitungstechniken zu verstehen, die wir verwenden möchten, bevor wir sie verwenden, also werden wir sie zuerst besprechen.
Was ist Dilatation?
Dilatation fügt Pixel zu den Grenzen von Objekten in einem Bild hinzu, um es breiter, größer oder offener zu machen. Die „Dilate“-Technik wird verwendet, um unsere Bilder vorzuverarbeiten, um die Helligkeit der Objekte auf den Bildern zu erhöhen. Wir benötigen eine Funktion zum Erweitern von Bildern mit JavaScript, daher wird das Code-Snippet zum Erweitern eines Bildes zu preprocess.js hinzugefügt.
Was ist Unschärfe?
Beim Weichzeichnen werden die Farben eines Bildes geglättet, indem dessen Schärfe verringert wird. Manchmal haben Bilder kleine Punkte/Flecken. Um diese Patches zu entfernen, können wir die Bilder verwischen. Das Code-Snippet zum Weichzeichnen eines Bildes ist in preprocess.js enthalten.
Was ist Inversion?
Inversion ändert helle Bereiche eines Bildes in eine dunkle Farbe und dunkle Bereiche in eine helle Farbe. Wenn ein Bild beispielsweise einen schwarzen Hintergrund und einen weißen Vordergrund hat, können wir es umkehren, sodass sein Hintergrund weiß und sein Vordergrund schwarz ist. Wir haben auch das Code-Snippet hinzugefügt, um ein Bild in preprocess.js umzuwandeln.
Nachdem wir dilate , invertColors und blurARGB zu „preprocess.js“ hinzugefügt haben, können wir sie nun zur Vorverarbeitung von Bildern verwenden. Um sie zu verwenden, müssen wir die anfängliche „preprocessImage“-Funktion in preprocess.js aktualisieren:
preprocessImage(...) sieht nun so aus:
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } In preprocessImage oben wenden wir vier Vorverarbeitungstechniken auf ein Bild an: blurARGB() , um die Punkte auf dem Bild zu entfernen, dilate( dilate() , um die Helligkeit des Bildes zu erhöhen, invertColors() , um die Vorder- und Hintergrundfarbe des Bildes zu wechseln, und thresholdFilter() , um das Bild in Schwarzweiß zu konvertieren, was besser für die Tesseract-Konvertierung geeignet ist.
Der thresholdFilter() nimmt image.data und level als seine Parameter. level wird verwendet, um festzulegen, wie weiß oder schwarz das Bild sein soll. Wir haben den thresholdFilter und den blurRGB Radius durch Versuch und Irrtum bestimmt, da wir nicht sicher sind, wie weiß, dunkel oder glatt das Bild sein sollte, damit Tesseract ein großartiges Ergebnis erzielt.
Prüfung Nr. 3
Hier ist das neue Ergebnis nach Anwendung von vier Techniken:

Das obige Bild stellt das Ergebnis dar, das wir sowohl in Chrome als auch in Firefox erhalten.
Hoppla! Das Ergebnis ist schrecklich.
Anstatt alle vier Techniken zu verwenden, warum verwenden wir nicht einfach zwei davon gleichzeitig?
Ja! Wir können einfach invertColors und thresholdFilter -Techniken verwenden, um das Bild in Schwarzweiß umzuwandeln und Vorder- und Hintergrund des Bilds zu vertauschen. Aber woher wissen wir, welche und welche Techniken zu kombinieren sind? Wir wissen, was zu kombinieren ist, basierend auf der Art des Bildes, das wir vorverarbeiten möchten.
Beispielsweise muss ein digitales Bild in Schwarzweiß konvertiert werden, und ein Bild mit Flecken muss unkenntlich gemacht werden, um die Punkte/Flecken zu entfernen. Was wirklich zählt, ist zu verstehen, wofür jede der Techniken verwendet wird.
Um invertColors und „ thresholdFilter “ zu verwenden, müssen wir „ blurARGB und „ dilate “ in „ preprocessImage “ auskommentieren:
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }Prüfung Nr. 4
Hier nun das neue Ergebnis:

Das Ergebnis ist immer noch schlechter als das ohne jegliche Vorverarbeitung. Nachdem ich jede der Techniken für dieses spezielle Bild und einige andere Bilder angepasst habe, bin ich zu dem Schluss gekommen, dass Bilder mit unterschiedlicher Beschaffenheit unterschiedliche Vorverarbeitungstechniken erfordern.
Kurz gesagt, die Verwendung von Tesseract.js ohne Bildvorverarbeitung lieferte das beste Ergebnis für die obige Geschenkkarte. Alle anderen Experimente mit Bildvorverarbeitung lieferten weniger genaue Ergebnisse.
Problem
Ursprünglich wollte ich die PIN von einer beliebigen Amazon-Geschenkkarte extrahieren, aber das konnte ich nicht erreichen, da es keinen Sinn macht, eine inkonsistente PIN abzugleichen, um ein konsistentes Ergebnis zu erhalten. Obwohl es möglich ist, ein Bild zu verarbeiten, um eine genaue PIN zu erhalten, wird eine solche Vorverarbeitung jedoch inkonsistent sein, wenn ein anderes Bild mit anderer Art verwendet wird.
Das beste Ergebnis produziert
Das Bild unten zeigt das beste Ergebnis der Experimente.
Test Nr. 5

Die Texte auf dem Bild und die extrahierten sind völlig gleich. Die Konvertierung hat 100% Genauigkeit. Ich habe versucht, das Ergebnis zu reproduzieren, aber ich konnte es nur reproduzieren, wenn ich Bilder mit ähnlicher Natur verwendete.
Beobachtung und Unterricht
- Einige Bilder, die nicht vorverarbeitet wurden, können in verschiedenen Browsern unterschiedliche Ergebnisse liefern. Dieser Anspruch wird im ersten Test deutlich. Das Ergebnis in Firefox unterscheidet sich von dem in Chrome. Die Vorverarbeitung von Bildern hilft jedoch, bei anderen Tests ein konsistentes Ergebnis zu erzielen.
- Schwarze Farbe auf weißem Hintergrund liefert tendenziell überschaubare Ergebnisse. Das Bild unten ist ein Beispiel für ein genaues Ergebnis ohne Vorverarbeitung . Ich war auch in der Lage, das gleiche Maß an Genauigkeit zu erreichen, indem ich das Bild vorverarbeitete, aber ich brauchte viele Anpassungen, die unnötig waren.
Die Umrechnung ist 100% genau.
- Ein Text mit einer großen Schriftgröße ist tendenziell genauer.
- Schriftarten mit gekrümmten Kanten neigen dazu, Tesseract zu verwirren. Das beste Ergebnis, das ich erzielt habe, wurde mit Arial (Schriftart) erzielt.
- OCR ist derzeit nicht gut genug für die Automatisierung der Bild-zu-Text-Konvertierung, insbesondere wenn eine Genauigkeit von mehr als 80 % erforderlich ist. Es kann jedoch verwendet werden, um die manuelle Bearbeitung von Texten auf Bildern weniger stressig zu gestalten, indem Texte zur manuellen Korrektur extrahiert werden.
- OCR ist derzeit nicht gut genug, um nützliche Informationen zur Barrierefreiheit an Screenreader weiterzugeben. Die Bereitstellung ungenauer Informationen für einen Bildschirmleser kann Benutzer leicht irreführen oder ablenken.
- OCR ist sehr vielversprechend, da neuronale Netze es ermöglichen, zu lernen und sich zu verbessern. Deep Learning wird OCR in naher Zukunft zu einem Game-Changer machen .
- Souverän Entscheidungen treffen. Ein Konfidenzwert kann verwendet werden, um Entscheidungen zu treffen, die unsere Anwendungen stark beeinflussen können. Der Konfidenzwert kann verwendet werden, um zu bestimmen, ob ein Ergebnis akzeptiert oder abgelehnt werden soll. Aus meiner Erfahrung und meinem Experiment habe ich erkannt, dass ein Vertrauenswert unter 90 nicht wirklich nützlich ist. Wenn ich nur einige Pins aus einem Text extrahieren muss, erwarte ich einen Vertrauenswert zwischen 75 und 100, und alles unter 75 wird abgelehnt .
Falls ich es mit Texten zu tun habe, ohne dass Teile davon extrahiert werden müssen, akzeptiere ich auf jeden Fall einen Vertrauenswert zwischen 90 und 100, lehne jedoch jeden Wert darunter ab. Zum Beispiel wird eine Genauigkeit von 90 und mehr erwartet, wenn ich Dokumente wie Schecks, einen historischen Wechsel digitalisieren möchte oder wenn eine exakte Kopie erforderlich ist. Ein Wert zwischen 75 und 90 ist jedoch akzeptabel, wenn eine exakte Kopie nicht wichtig ist, z. B. um die PIN von einer Geschenkkarte zu erhalten. Kurz gesagt, ein Vertrauenswert hilft beim Treffen von Entscheidungen , die sich auf unsere Anwendungen auswirken.
Fazit
Angesichts der Einschränkungen bei der Datenverarbeitung durch Texte auf Bildern und der damit verbundenen Nachteile ist die optische Zeichenerkennung (OCR) eine nützliche Technologie, die man sich zu eigen machen sollte. Obwohl OCR seine Grenzen hat, ist es aufgrund der Verwendung neuronaler Netze sehr vielversprechend.
Im Laufe der Zeit wird OCR die meisten seiner Einschränkungen mit Hilfe von Deep Learning überwinden, aber bis dahin können die in diesem Artikel hervorgehobenen Ansätze zumindest für die Textextraktion aus Bildern verwendet werden, um die Schwierigkeiten und Verluste zu reduzieren, die mit der manuellen Methode verbunden sind Verarbeitung – insbesondere aus betriebswirtschaftlicher Sicht.
Jetzt sind Sie an der Reihe, OCR auszuprobieren, um Texte aus Bildern zu extrahieren. Viel Glück!
Weiterführende Lektüre
- P5.js
- Vorverarbeitung in OCR
- Verbesserung der Qualität der Ausgabe
- Verwendung von JavaScript zur Vorverarbeitung von Bildern für OCR
- OCR im Browser mit Tesseract.js
- Eine kurze Geschichte der optischen Zeichenerkennung
- Die Zukunft von OCR ist Deep Learning
- Zeitleiste der optischen Zeichenerkennung