
Bildklassifizierung in CNN: Alles, was Sie wissen müssen
Veröffentlicht: 2021-02-25Inhaltsverzeichnis
Einführung
Haben Sie sich beim Durchsuchen des Facebook-Feeds jemals gefragt, wie die Personen auf einem Gruppenfoto automatisch von der Facebook-Software gekennzeichnet werden? Hinter jeder interaktiven Benutzeroberfläche von Facebook, die Sie sehen, steckt ein komplexer und starker Algorithmus, der verwendet wird, um jedes Bild, das von uns auf die Social-Media-Plattform hochgeladen wird, zu erkennen und zu kennzeichnen. Mit jedem Bild von uns tragen wir nur dazu bei, die Effizienz des Algorithmus zu verbessern. Ja, die Bildklassifizierung ist einer der am häufigsten verwendeten Algorithmen, bei denen wir die Anwendung künstlicher Intelligenz sehen.
In letzter Zeit hat sich Convolutional Neural Networks (CNN) zu einem der stärksten Befürworter von Deep Learning entwickelt. Eine beliebte Anwendung dieser Convolutional Networks ist die Bildklassifizierung. In diesem Tutorial werden wir die Grundlagen von Convolutional Neural Networks durchgehen, die verschiedenen Schichten sehen, die beim Erstellen eines CNN-Modells beteiligt sind, und schließlich ein Beispiel für die Bildklassifizierungsaufgabe visualisieren.
Bildklassifizierung
Bevor wir uns mit den Details von Deep Learning und Convolutional Neural Networks befassen, lassen Sie uns die Grundlagen der Bildklassifizierung verstehen. Im Allgemeinen ist die Bildklassifizierung als die Aufgabe definiert, bei der wir ein Bild als Eingabe für ein Modell geben, das mit einem bestimmten Algorithmus erstellt wurde, der die Klasse oder die Wahrscheinlichkeit der Klasse ausgibt, zu der das Bild gehört. Dieser Prozess, bei dem wir ein Bild einer bestimmten Klasse zuordnen, wird überwachtes Lernen genannt.
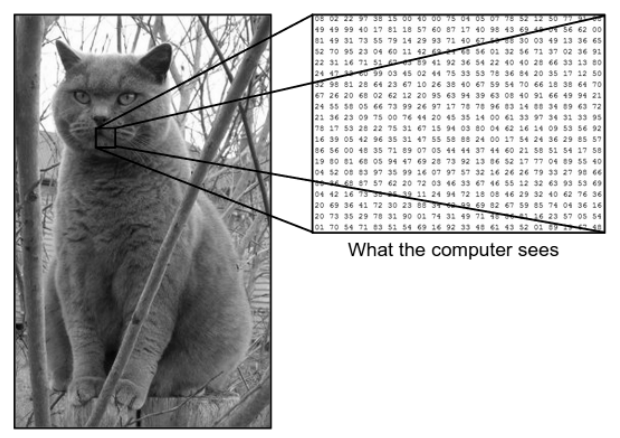
Es gibt einen großen Unterschied zwischen der Art und Weise, wie wir ein Bild sehen, und der Art, wie die Maschine (der Computer) dasselbe Bild sieht. Für uns sind wir in der Lage, das Bild zu visualisieren und anhand von Farbe und Größe zu charakterisieren. Auf der anderen Seite sieht die Maschine nur Zahlen. Die sichtbaren Zahlen werden Pixel genannt.
Jedes Pixel hat einen Wert zwischen 0 und 255. Daher erfordert die Maschine mit diesen numerischen Daten einige Vorverarbeitungsschritte, um einige spezifische Muster oder Merkmale abzuleiten, die ein Bild vom anderen unterscheiden. Convolutional Neural Networks helfen uns, Algorithmen zu bauen, die in der Lage sind, das spezifische Muster aus Bildern abzuleiten.
Was wir sehen vs. was der Computer sieht
 Quelle – Unterschied zwischen Computer und menschlichem Auge
Quelle – Unterschied zwischen Computer und menschlichem Auge

Deep Learning für die Bildklassifizierung
Nachdem wir nun verstanden haben, was Bildklassifizierung ist, wollen wir nun sehen, wie wir sie mit künstlicher Intelligenz implementieren können. Dazu nutzen wir die gängigen Deep-Learning-Methoden. Deep Learning ist eine Teilmenge der künstlichen Intelligenz, die große Bilddatensätze verwendet, um Muster aus verschiedenen Bildern zu erkennen und abzuleiten, um zwischen verschiedenen Klassen zu unterscheiden, die im Bilddatensatz vorhanden sind.
Die größte Herausforderung für Deep Learning besteht darin, dass es für eine riesige Datenbank sehr lange dauert und einen hohen Rechenaufwand verursacht. Die Convolutional Neural Networks, eine Art Deep-Learning-Algorithmus, gehen dieses Problem jedoch gut an.
Faltungsneuronale Netze
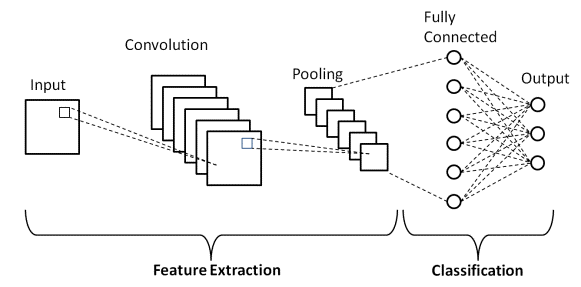
Beim Deep Learning sind Convolutional Neural Networks eine Klasse von Deep Neural Networks, die hauptsächlich in visuellen Bildern verwendet werden. Sie sind eine spezielle Architektur der Artificial Neural Networks (ANN), die 1998 von Yann LeCunn vorgeschlagen wurde. Die Convolutional Neural Networks bestehen aus zwei Teilen.
Der erste Teil besteht aus den Convolutional-Layern und den Pooling-Layern, in denen der Hauptmerkmalsextraktionsprozess stattfindet. Im zweiten Teil führen die Layer „Fully Connected“ und „Dense“ mehrere nichtlineare Transformationen an den extrahierten Merkmalen durch und fungieren als Klassifikatorteil. Lernen Sie CNN für die Bildklassifizierung.
Betrachten Sie das oben gezeigte Bildbeispiel dessen, was der Mensch und die Maschine sehen. Wie wir sehen, sieht der Computer eine Reihe von Pixeln. Wenn die Bildgröße beispielsweise 500 x 500 beträgt, beträgt die Größe des Arrays 500 x 500 x 3. Hier steht 500 für jede Höhe und Breite, 3 steht für den RGB-Kanal, wobei jeder Farbkanal durch ein separates Array dargestellt wird. Die Pixelintensität variiert von 0 bis 255.
Für die Bildklassifizierung sucht der Computer nun nach den Merkmalen auf der Basisebene. Nach Ansicht von uns Menschen sind diese grundlegenden Merkmale der Katze ihre Ohren, Nase und Schnurrhaare. Während für den Computer diese grundlegenden Merkmale die Krümmungen und Grenzen sind. Auf diese Weise extrahiert der Computer unter Verwendung mehrerer unterschiedlicher Schichten, wie etwa der Faltungsschichten und der Pooling-Schichten, die Grundebenenmerkmale aus den Bildern.
Im Convolutional Neural Network-Modell gibt es mehrere Arten von Schichten, wie z.
- Eingabeschicht
- Faltungsschicht
- Pooling-Schicht
- Vollständig verbundene Schicht
- Ausgabeschicht
- Aktivierungsfunktionen
Lassen Sie uns kurz durch jede der Schichten gehen, bevor wir uns mit ihrer Anwendung in der Bildklassifizierung befassen.
Eingabeschicht
Aus dem Namen geht hervor, dass dies die Schicht ist, in der das Eingabebild in das CNN-Modell eingespeist wird. Abhängig von unseren Anforderungen können wir das Bild in verschiedene Größen umformen, z. B. (28,28,3)
Faltungsschicht
Dann kommt die wichtigste Schicht, die aus einem Filter (auch Kernel genannt) mit fester Größe besteht. Die mathematische Operation der Faltung wird zwischen dem Eingabebild und dem Filter durchgeführt. Dies ist die Phase, in der die meisten Basismerkmale wie scharfe Kanten und Kurven aus dem Bild extrahiert werden, und daher wird diese Ebene auch als Merkmalsextraktionsebene bezeichnet.
Pooling-Schicht
Nach Durchführung der Faltungsoperation führen wir die Pooling-Operation durch. Dies wird auch als Downsampling bezeichnet, bei dem das räumliche Volumen des Bildes reduziert wird. Wenn wir beispielsweise einen Pooling-Vorgang mit einem Schritt von 2 auf einem Bild mit den Abmessungen 28 × 28 durchführen, wird die Bildgröße auf 14 × 14 reduziert, es wird auf die Hälfte seiner ursprünglichen Größe reduziert.
Vollständig verbundene Schicht
Der Fully Connected Layer (FC) wird unmittelbar vor der endgültigen Klassifizierungsausgabe des CNN-Modells platziert. Diese Schichten werden verwendet, um die Ergebnisse vor dem Klassifizieren zu glätten. Es beinhaltet mehrere Vorspannungen, Gewichtungen und Neuronen. Das Anhängen einer FC-Schicht vor der Klassifizierung führt zu einem N-dimensionalen Vektor, wobei N eine Anzahl von Klassen ist, aus denen das Modell eine Klasse auswählen muss.
Ausgabeschicht
Der Output Layer schließlich besteht aus dem Label, das meist nach dem One-Hot-Encoding-Verfahren kodiert wird.
Aktivierungsfunktion
Diese Aktivierungsfunktionen sind der Kern jedes Convolutional Neural Network-Modells. Diese Funktionen werden verwendet, um die Ausgabe eines neuronalen Netzes zu bestimmen. Kurz gesagt bestimmt es, ob ein bestimmtes Neuron aktiviert („gefeuert“) werden soll oder nicht. Dies sind normalerweise nichtlineare Funktionen, die auf die Eingangssignale angewendet werden. Diese transformierte Ausgabe wird dann als Eingabe an die nächste Schicht von Neuronen gesendet. Es gibt mehrere Aktivierungsfunktionen wie Sigmoid, ReLU, Leaky ReLU, TanH und Softmax.
Grundlegende CNN-Architektur
Quelle : Grundlegende CNN-Architektur
Wie zuvor definiert, ist das oben gezeigte Diagramm die grundlegende Architektur eines Convolutional Neural Network-Modells. Nachdem wir nun mit den Grundlagen der Bildklassifizierung und CNN fertig sind, lassen Sie uns nun mit einem Echtzeitproblem in die Anwendung eintauchen. Erfahren Sie mehr über die grundlegende CNN-Architektur.
Implementierung von Convolutional Neural Networks
Nachdem wir nun die Grundlagen der Bildklassifizierung und Convolutional Neural Networks verstanden haben, lassen Sie uns ihre Implementierung in TensorFlow/Keras mit Python-Codierung visualisieren. Dabei werden wir ein einfaches Convolutional Neural Network Model mit einer Basic LeNet Architecture bauen, das Modell auf einem Trainingsset & Testset trainieren und schließlich die Genauigkeit des Modells auf den Testsetdaten erhalten.
Problem gesetzt
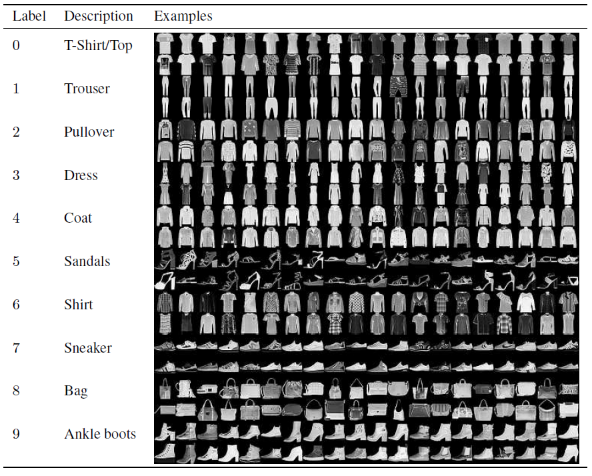
In diesem Artikel zum Erstellen und Trainieren des Convolutional Neural Network Model verwenden wir den berühmten Fashion MNIST-Datensatz. MNIST steht für Modified National Institute of Standards and Technology. Fashion-MNIST ist ein Datensatz von Zalandos Artikelbildern – bestehend aus einem Trainingsset mit 60.000 Beispielen und einem Testset mit 10.000 Beispielen. Jedes Beispiel ist ein 28 × 28-Graustufenbild, das mit einem Etikett aus 10 Klassen verknüpft ist.

Jedes Trainings- und Testbeispiel ist einem der folgenden Labels zugeordnet:
0 – T-Shirt/Oberteil
1 – Hose
2 – Pullover
3 – Kleid
4 – Mantel
5 – Sandale
6 – Hemd
7 – Sneaker
8 – Tasche
9 – Stiefeletten
Quelle : Fashion MNIST Dataset Images
Programmcode
Schritt 1 – Importieren der Bibliotheken
Der erste Schritt zum Erstellen eines Deep-Learning-Modells besteht darin, die für das Programm erforderlichen Bibliotheken zu importieren. Da wir in unserem Beispiel das TensorFlow-Framework verwenden, importieren wir die Keras-Bibliothek und auch andere wichtige Bibliotheken wie die Zahl für die Berechnung und die Matplotlib zum Zeichnen der Diagramme.
#TensorFlow – Importieren der Bibliotheken
importiere numpy als np
importiere matplotlib.pyplot als plt
%matplotlib inline
Tensorflow als tf importieren
von Tensorflow-Import Keras
Schritt 2 – Abrufen und Aufteilen des Datensatzes
Nachdem wir die Bibliotheken importiert haben, besteht der nächste Schritt darin, den Datensatz herunterzuladen und den Fashion MNIST-Datensatz in die entsprechenden 60.000 Trainings- und 10.000 Testdaten aufzuteilen. Glücklicherweise stellt uns Keras eine vordefinierte Funktion zum Importieren des Fashion MNIST-Datensatzes zur Verfügung, und wir können sie in der nächsten Zeile mit einer einfachen, selbstverständlichen Codezeile aufteilen.
#TensorFlow – Abrufen und Aufteilen des Datensatzes
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
Schritt 3 – Visualisierung der Daten
Da der Datensatz zusammen mit den Bildern und den entsprechenden Beschriftungen heruntergeladen wird, wird zur Verdeutlichung für den Benutzer immer empfohlen, die Daten anzuzeigen, damit wir verstehen können, mit welcher Art von Daten wir es beim Erstellen des Convolutional Neural zu tun haben Netzwerkmodell entsprechend. Hier werden wir mit diesem einfachen Codeblock unten die ersten 3 Bilder des zufällig gemischten Trainingsdatensatzes visualisieren.
#TensorFlow – Visualisierung der Daten
def imshowTensorFlow(img):
plt.imshow(img, cmap='gray')
print("Label:", img[0])
imshowTensorFlow(train_images_tf[0])
Bezeichnung: 9 Bezeichnung: 0 Bezeichnung: 3
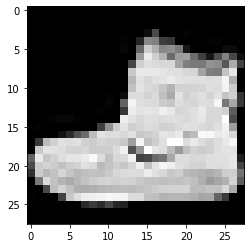


Das oben angegebene Bild und seine Labels können mit den Labels verifiziert werden, die in den Details des Fashion MNIST-Datensatzes oben angegeben sind. Daraus schließen wir, dass unser Datenbild ein Graustufenbild mit einer Höhe von 28 Pixeln und einer Breite von 28 Pixeln ist.
Daher kann das Modell mit einer Eingabegröße von (28,28,1) erstellt werden, wobei 1 für das Graustufenbild steht.
Schritt 4 – Erstellen des Modells
Wie oben erwähnt, werden wir in diesem Artikel ein einfaches Convolutional Neural Network mit der LeNet-Architektur aufbauen. LeNet ist eine von Yann LeCun et al. im Jahr 1989. Im Allgemeinen bezieht sich LeNet auf LeNet-5 und ist ein einfaches Convolutional Neural Network.
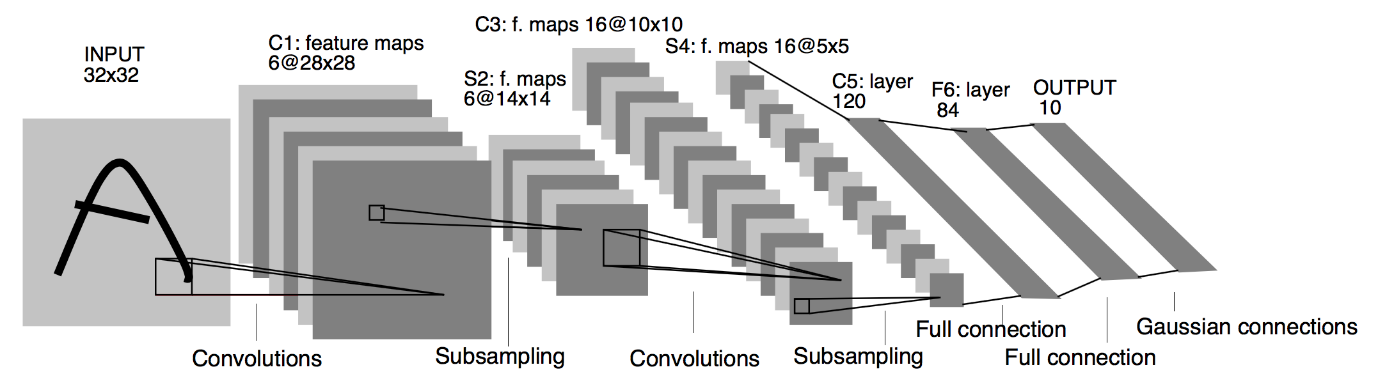
Quelle : Die LeNet-Architektur
Aus dem oben angegebenen Architekturdiagramm des LeNet CNN-Modells sehen wir, dass es 5 + 2 Schichten gibt. Die erste und zweite Schicht sind eine Convolutional-Schicht, gefolgt von einer Pooling-Schicht. Auch hier bestehen die dritte und vierte Schicht aus einer Convolutional-Schicht und einer Pooling-Schicht. Als Ergebnis dieser Operationen wird die Größe des Eingangsbildes von 28 × 28 auf 7 × 7 reduziert.
Die fünfte Schicht des LeNet-Modells ist die vollständig verbundene Schicht, die die Ausgabe der vorherigen Schicht glättet. Gefolgt von zwei Dense-Schichten, besteht die letzte Ausgabeschicht des CNN-Modells aus einer Softmax-Aktivierungsfunktion mit 10 Einheiten. Die Softmax-Funktion sagt eine Klassenwahrscheinlichkeit für jede der 10 Klassen des Fashion MNIST-Datensatzes voraus.
#TensorFlow – Erstellen des Modells
model = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), filter=6, kernel_size=5, strides=1, padding=“same“, activation=tf.nn.relu),
keras.layers.AveragePooling2D (pool_size=2, strides=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, padding=“same“, activation=tf.nn.relu),
keras.layers.AveragePooling2D (pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, activation=tf.nn.relu),
keras.layers.Dense(84, activation=tf.nn.relu),
keras.layers.Dense(10, activation=tf.nn.softmax)
])
Schritt 5 – Modellzusammenfassung
Sobald die Schichten des LeNet-Modells fertiggestellt sind, können wir mit der Kompilierung des Modells fortfahren und eine zusammengefasste Version des entworfenen CNN-Modells anzeigen.
#TensorFlow – Modellzusammenfassung
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer='adam',
metrics=['acc'])
model.summary()
Da die endgültige Ausgabe mehr als 2 Klassen (10 Klassen) hat, verwenden wir dabei die kategoriale Kreuzentropie als Verlustfunktion und den Adam-Optimierer für unser erstelltes Modell. Die Modellzusammenfassung ist unten angegeben.
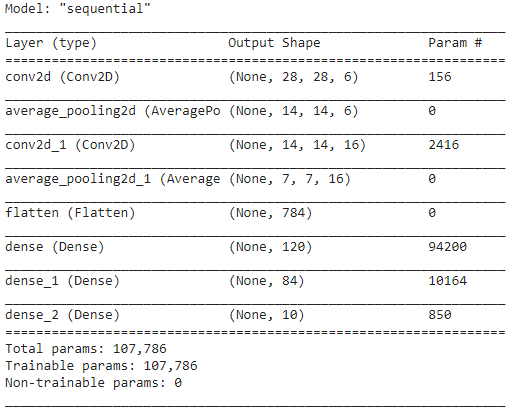
Schritt 6 – Modell trainieren
Schließlich kommen wir zu dem Teil, in dem wir mit dem Trainingsprozess des LeNet-CNN-Modells beginnen. Zuerst formen wir den Trainingsdatensatz um und normalisieren ihn auf kleinere Werte, indem wir ihn durch 255,0 dividieren, um den Rechenaufwand zu reduzieren. Dann werden die Trainingsetiketten von einem ganzzahligen Klassenvektor in eine binäre Klassenmatrix umgewandelt. Beispielsweise wird Label 3 in [0, 0, 0, 1, 0, 0, 0, 0, 0] umgewandelt.
#TensorFlow – Training des Modells
train_images_tensorflow = (train_images_tf / 255.0).reshape(train_images_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28 ,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
Am Ende des Trainings nach 30 Epochen erhalten wir die endgültige Trainingsgenauigkeit und den Verlust als:
Epoche 30/30
1875/1875 [==============================] – 4s 2ms/Schritt – Verlust: 0,0421 – Acc: 0,9850
Trainingsgenauigkeit: 98,294997215271 %
Trainingsverlust: 0,04584110900759697
Schritt 7 – Vorhersage der Ergebnisse
Schließlich, sobald wir mit unserem Trainingsprozess des CNN-Modells fertig sind, werden wir dasselbe Modell an den Testdatensatz anpassen und die Genauigkeit von 10.000 Testbildern vorhersagen.
#TensorFlow – Vergleich der Ergebnisse
Vorhersagen = model.predict(test_images_tensorflow)
richtig = 0
für i, pred in enumerate(predictions):
if np.argmax(pred) == test_labels_tf[i]:
richtig += 1
print('Testgenauigkeit des Modells auf den {} Testbildern: {}% mit TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
Die Ausgabe, die wir erhalten, ist
Testgenauigkeit des Modells auf den 10000 Testbildern: 90,67 % mit TensorFlow
Damit beenden wir das Programm zum Aufbau eines Bildklassifizierungsmodells mit Convolutional Neural Networks.
Lesen Sie auch: Projektideen für maschinelles Lernen
Fazit
Daher haben wir in diesem Tutorial zur Implementierung von Bildklassifizierung in CNN die grundlegenden Konzepte hinter Bildklassifizierung, Convolutional Neural Networks und ihrer Implementierung in der Programmiersprache Python mit dem TensorFlow-Framework verstanden.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben bietet, IIIT- B-Alumni-Status, mehr als 5 praktische, praktische Abschlussprojekte und Jobunterstützung bei Top-Unternehmen.
Welches CNN-Modell gilt als optimal für die Bildklassifizierung?
Das beste CNN-Modell zur Bildklassifizierung ist das VGG-16, was für Very Deep Convolutional Networks for Large-Scale Image Recognition steht. VGG, das als Deep CNN konzipiert wurde, übertrifft Baselines bei einer Vielzahl von Aufgaben und Datensätzen außerhalb von ImageNet. Die Besonderheit des Modells besteht darin, dass bei seiner Erstellung mehr Wert auf die Integration exzellenter Faltungsschichten gelegt wurde als auf das Hinzufügen einer großen Anzahl von Hyperparametern. Es hat insgesamt 16 Schichten, 5 Blöcke, und jeder Block hat eine maximale Pooling-Schicht, was es zu einem ziemlich großen Netzwerk macht.
Welche Nachteile hat die Verwendung von CNN-Modellen zur Bildklassifizierung?
Bei der Bildklassifizierung sind CNN-Modelle sehr erfolgreich. Es gibt jedoch mehrere Nachteile bei der Verwendung von CNNs. Wenn das zu identifizierende Bild geneigt oder gedreht ist, hat das CNN-Modell Probleme, das Bild genau zu identifizieren. Wenn CNN die Bilder visualisiert, gibt es keine internen Darstellungen der Komponenten und ihrer Teil-Ganzes-Verbindungen. Wenn das zu verwendende CNN-Modell außerdem zahlreiche Faltungsschichten enthält, wird der Klassifizierungsprozess lange dauern.
Warum wird die Verwendung des CNN-Modells gegenüber dem KNN für Bilddaten als Eingabe bevorzugt?
Durch die Kombination von Filtern oder Transformationen kann CNN viele Ebenen von Merkmalsdarstellungen für jedes als Eingabe bereitgestellte Bild lernen. Die Überanpassung wird verringert, da die Anzahl der Parameter, die das Netzwerk in CNN lernen muss, wesentlich kleiner ist als in mehrschichtigen neuronalen Netzwerken. Bei der Verwendung von KNN lernen neuronale Netze möglicherweise eine einzelne Merkmalsdarstellung des Bildes, aber im Fall komplexer Bilder liefert KNN keine verbesserten Visualisierungen oder Klassifizierungen, da es keine Pixelabhängigkeiten lernen kann, die in den Eingabebildern vorhanden sind.