
HTTP/3: Leistungsverbesserungen (Teil 2)
Veröffentlicht: 2022-03-10Willkommen zurück zu dieser Serie über das neue HTTP/3-Protokoll. In Teil 1 haben wir uns angesehen, warum genau wir HTTP/3 und das zugrunde liegende QUIC-Protokoll benötigen und was ihre wichtigsten neuen Funktionen sind.
In diesem zweiten Teil werden wir uns mit den Leistungsverbesserungen befassen , die QUIC und HTTP/3 für das Laden von Webseiten mit sich bringen. Wir werden allerdings auch etwas skeptisch sein, was wir von diesen Neuerungen in der Praxis erwarten können.
Wie wir sehen werden, haben QUIC und HTTP/3 in der Tat ein großes Web-Performance-Potenzial, aber hauptsächlich für Benutzer in langsamen Netzwerken . Wenn sich Ihr durchschnittlicher Besucher in einem schnellen Kabel- oder Mobilfunknetz befindet, wird er wahrscheinlich nicht so sehr von den neuen Protokollen profitieren. Beachten Sie jedoch, dass selbst in Ländern und Regionen mit normalerweise schnellen Uplinks die langsamsten 1 % bis sogar 10 % Ihrer Zielgruppe (das sogenannte 99. oder 90. Perzentil ) möglicherweise noch viel gewinnen können. Dies liegt daran, dass HTTP/3 und QUIC hauptsächlich dabei helfen, die etwas ungewöhnlichen, aber potenziell schwerwiegenden Probleme zu bewältigen, die im heutigen Internet auftreten können.
Dieser Teil ist etwas technischer als der erste, obwohl er den größten Teil des wirklich tiefen Materials an externe Quellen auslagert und sich darauf konzentriert zu erklären, warum diese Dinge für den durchschnittlichen Webentwickler wichtig sind.
- Teil 1: Geschichte und Kernkonzepte von HTTP/3
Dieser Artikel richtet sich an Personen, die neu bei HTTP/3 und Protokollen im Allgemeinen sind, und behandelt hauptsächlich die Grundlagen. - Teil 2: HTTP/3-Leistungsmerkmale
Dieser ist mehr in die Tiefe und technisch. Leute, die bereits die Grundlagen kennen, können hier anfangen. - Teil 3: Praktische HTTP/3-Bereitstellungsoptionen
Dieser dritte Artikel der Reihe erläutert die Herausforderungen, die mit der Bereitstellung und dem Testen von HTTP/3 selbst verbunden sind. Es beschreibt auch, wie und ob Sie Ihre Webseiten und Ressourcen ändern sollten.
Eine Einführung in die Geschwindigkeit
Die Diskussion über Leistung und „Geschwindigkeit“ kann schnell komplex werden, da viele zugrunde liegende Aspekte dazu beitragen, dass eine Webseite „langsam“ lädt. Da wir uns hier mit Netzwerkprotokollen befassen, werden wir uns hauptsächlich mit Netzwerkaspekten befassen, von denen zwei am wichtigsten sind: Latenz und Bandbreite.
Die Latenz kann grob als die Zeit definiert werden, die benötigt wird, um ein Paket von Punkt A (z. B. dem Client) nach Punkt B (dem Server) zu senden . Sie ist physikalisch begrenzt durch die Lichtgeschwindigkeit oder praktisch, wie schnell sich Signale in Drähten oder im Freien ausbreiten können. Dies bedeutet, dass die Latenz häufig von der physischen, realen Entfernung zwischen A und B abhängt.
Auf der Erde bedeutet dies, dass typische Latenzen konzeptionell gering sind und zwischen etwa 10 und 200 Millisekunden liegen. Dies ist jedoch nur eine Möglichkeit: Es müssen auch Antworten auf die Pakete zurückkommen. Die Zwei-Wege-Latenz wird oft als Round-Trip-Time (RTT) bezeichnet.
Aufgrund von Funktionen wie der Staukontrolle (siehe unten) benötigen wir oft einige Roundtrips, um auch nur eine einzige Datei zu laden. Daher können sich selbst niedrige Latenzen von weniger als 50 Millisekunden zu erheblichen Verzögerungen summieren. Dies ist einer der Hauptgründe, warum es Content Delivery Networks (CDNs) gibt: Sie platzieren Server physisch näher am Endbenutzer, um die Latenz und damit die Verzögerung so weit wie möglich zu reduzieren.
Die Bandbreite kann also grob als die Anzahl der Pakete bezeichnet werden, die gleichzeitig gesendet werden können . Dies ist etwas schwieriger zu erklären, da es von den physikalischen Eigenschaften des Mediums (z.B. der verwendeten Frequenz von Funkwellen), der Anzahl der Benutzer im Netzwerk und auch den Geräten abhängt, die verschiedene Teilnetze miteinander verbinden (weil sie kann typischerweise nur eine bestimmte Anzahl von Paketen pro Sekunde verarbeiten).
Eine oft verwendete Metapher ist die eines Rohrs, das zum Transport von Wasser verwendet wird. Die Länge der Pipe ist die Latenz, während die Breite der Pipe die Bandbreite ist. Im Internet haben wir jedoch normalerweise eine lange Reihe verbundener Leitungen , von denen einige breiter sein können als andere (was zu sogenannten Engpässen an den engsten Verbindungen führt). Daher ist die End-to-End-Bandbreite zwischen den Punkten A und B oft durch die langsamsten Unterabschnitte begrenzt.
Während ein perfektes Verständnis dieser Konzepte für den Rest dieses Beitrags nicht erforderlich ist, wäre es gut, eine allgemeine Definition auf hoher Ebene zu haben. Für weitere Informationen empfehle ich, Ilya Grigoriks ausgezeichnetes Kapitel über Latenz und Bandbreite in seinem Buch High Performance Browser Networking zu lesen.
Staukontrolle
Ein Aspekt der Leistung betrifft die Frage, wie effizient ein Transportprotokoll die volle (physikalische) Bandbreite eines Netzwerks nutzen kann (dh ungefähr, wie viele Pakete pro Sekunde gesendet oder empfangen werden können). Dies wirkt sich wiederum darauf aus, wie schnell die Ressourcen einer Seite heruntergeladen werden können. Einige behaupten, dass QUIC dies irgendwie viel besser macht als TCP, aber das stimmt nicht.
Wusstest du schon?
Eine TCP-Verbindung beginnt beispielsweise nicht einfach damit, Daten mit voller Bandbreite zu senden, da dies zu einer Überlastung (oder Überlastung) des Netzwerks führen könnte. Denn wie gesagt, jede Netzwerkverbindung hat nur eine bestimmte Menge an Daten, die sie (physikalisch) pro Sekunde verarbeiten kann. Geben Sie es weiter und es gibt keine andere Möglichkeit, als die übermäßigen Pakete zu verwerfen, was zu Paketverlust führt .
Wie in Teil 1 besprochen, besteht für ein zuverlässiges Protokoll wie TCP die einzige Möglichkeit, einen Paketverlust zu beheben, darin, eine neue Kopie der Daten erneut zu übertragen, was einen Hin- und Rückweg erfordert. Insbesondere in Netzwerken mit hoher Latenz (z. B. mit einer RTT von über 50 Millisekunden) kann Paketverlust die Leistung ernsthaft beeinträchtigen.
Ein weiteres Problem ist, dass wir im Voraus nicht wissen, wie hoch die maximale Bandbreite sein wird. Es hängt oft von einem Engpass irgendwo in der End-to-End-Verbindung ab, aber wir können nicht vorhersagen oder wissen, wo dieser sein wird. Das Internet verfügt auch (noch) nicht über Mechanismen, um Link-Kapazitäten an die Endpunkte zurückzumelden.
Selbst wenn wir die verfügbare physische Bandbreite kennen würden, würde das nicht bedeuten, dass wir sie vollständig selbst nutzen könnten. Typischerweise sind mehrere Benutzer gleichzeitig in einem Netzwerk aktiv, von denen jeder einen angemessenen Anteil an der verfügbaren Bandbreite benötigt.
Daher weiß eine Verbindung nicht, wie viel Bandbreite sie sicher oder fair im Voraus verwenden kann, und diese Bandbreite kann sich ändern, wenn Benutzer dem Netzwerk beitreten, es verlassen und verwenden. Um dieses Problem zu lösen, versucht TCP ständig, die verfügbare Bandbreite im Laufe der Zeit zu ermitteln, indem es einen Mechanismus namens Congestion Control verwendet .
Zu Beginn der Verbindung sendet es nur wenige Pakete (in der Praxis zwischen 10 und 100 Paketen oder etwa 14 und 140 KB Daten) und wartet einen Roundtrip, bis der Empfänger Bestätigungen dieser Pakete zurücksendet. Wenn sie alle bestätigt werden, bedeutet dies, dass das Netzwerk diese Senderate verarbeiten kann, und wir können versuchen, den Vorgang zu wiederholen, aber mit mehr Daten (in der Praxis verdoppelt sich die Senderate normalerweise mit jeder Iteration).
Auf diese Weise steigt die Senderate weiter an, bis einige Pakete nicht bestätigt werden (was auf Paketverlust und Netzwerküberlastung hinweist). Diese erste Phase wird typischerweise als „langsamer Start“ bezeichnet. Wenn ein Paketverlust erkannt wird, reduziert TCP die Senderate und beginnt (nach einer Weile) damit, die Senderate wieder zu erhöhen, wenn auch in (viel) kleineren Schritten. Diese Reduzieren-dann-Erhöhen-Logik wird danach für jeden Paketverlust wiederholt. Letztendlich bedeutet dies, dass TCP ständig versucht, seinen idealen, fairen Bandbreitenanteil zu erreichen. Dieser Mechanismus ist in Abbildung 1 dargestellt.
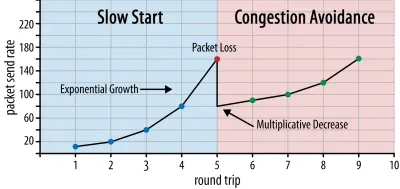
Dies ist eine extrem vereinfachte Erklärung der Staukontrolle. In der Praxis spielen viele andere Faktoren eine Rolle, wie z. B. Bufferbloat, die Schwankung von RTTs aufgrund von Überlastung und die Tatsache, dass mehrere gleichzeitige Sender ihren gerechten Anteil an der Bandbreite erhalten müssen. Daher gibt es viele verschiedene Überlastungskontrollalgorithmen, und viele werden noch heute erfunden, wobei keiner in allen Situationen optimal funktioniert.
Obwohl die Überlastungssteuerung TCP robust macht, bedeutet dies auch, dass es je nach RTT und tatsächlich verfügbarer Bandbreite eine Weile dauert, um optimale Senderaten zu erreichen . Beim Laden von Webseiten kann sich dieser Slow-Start-Ansatz auch auf Metriken wie das erste Contentful Paint auswirken, da in den ersten paar Runden nur eine kleine Datenmenge (zig bis einige hundert KB) übertragen werden kann. (Möglicherweise haben Sie die Empfehlung gehört, Ihre kritischen Daten kleiner als 14 KB zu halten.)
Die Wahl eines aggressiveren Ansatzes könnte daher zu besseren Ergebnissen in Netzwerken mit hoher Bandbreite und hoher Latenz führen, insbesondere wenn Sie sich nicht um gelegentliche Paketverluste kümmern. Hier habe ich wieder viele Fehlinterpretationen darüber gesehen, wie QUIC funktioniert.
Wie in Teil 1 besprochen, leidet QUIC theoretisch weniger unter Paketverlust (und der damit verbundenen HOL-Blockierung (head-of-line)), da es Paketverluste im Bytestrom jeder Ressource unabhängig behandelt. Darüber hinaus läuft QUIC über das User Datagram Protocol (UDP), das im Gegensatz zu TCP keine eingebaute Überlastungskontrollfunktion hat; Sie können versuchen, mit einer beliebigen Geschwindigkeit zu senden, und übertragen verlorene Daten nicht erneut.
Dies hat zu vielen Artikeln geführt, in denen behauptet wird, dass QUIC auch keine Staukontrolle verwendet, dass QUIC stattdessen mit dem Senden von Daten mit einer viel höheren Rate über UDP beginnen kann (aufgrund der Entfernung der HOL-Blockierung, um Paketverluste zu bewältigen), dass dies der Grund ist QUIC ist viel schneller als TCP.
In Wirklichkeit könnte nichts weiter von der Wahrheit entfernt sein: QUIC verwendet tatsächlich sehr ähnliche Techniken zur Bandbreitenverwaltung wie TCP . Auch sie beginnt mit einer niedrigeren Senderate und erhöht sie im Laufe der Zeit, wobei Bestätigungen als Schlüsselmechanismus zur Messung der Netzwerkkapazität verwendet werden. Dies liegt (unter anderem) daran, dass QUIC zuverlässig sein muss, um für etwas wie HTTP nützlich zu sein, weil es gegenüber anderen QUIC- (und TCP!) Verbindungen fair sein muss und weil die Entfernung der HOL-Blockierung dies nicht tut tatsächlich sehr gut gegen Paketverlust helfen (wie wir weiter unten sehen werden).
Das bedeutet jedoch nicht, dass QUIC nicht (ein bisschen) klüger sein kann, wie es Bandbreite verwaltet als TCP. Dies liegt hauptsächlich daran, dass QUIC flexibler und einfacher zu entwickeln ist als TCP . Wie wir bereits gesagt haben, entwickeln sich die Algorithmen zur Staukontrolle auch heute noch stark, und wir werden wahrscheinlich zum Beispiel einige Dinge optimieren müssen, um das Beste aus 5G herauszuholen.
TCP wird jedoch normalerweise im Kernel des Betriebssystems (OS) implementiert, einer sicheren und eingeschränkteren Umgebung, die für die meisten Betriebssysteme nicht einmal Open Source ist. Daher wird die Optimierung der Überlastungslogik normalerweise nur von wenigen ausgewählten Entwicklern durchgeführt, und die Entwicklung ist langsam.
Im Gegensatz dazu werden die meisten QUIC-Implementierungen derzeit im „User Space“ (wo wir normalerweise native Apps ausführen) durchgeführt und sind Open Source, explizit um Experimente durch einen viel breiteren Pool von Entwicklern zu fördern (wie bereits gezeigt wurde, z. B. von Facebook ).
Ein weiteres konkretes Beispiel ist der Vorschlag zur Verlängerung der Frequenz der verzögerten Bestätigung für QUIC. Während QUIC standardmäßig alle 2 empfangenen Pakete eine Bestätigung sendet, ermöglicht diese Erweiterung den Endpunkten, stattdessen beispielsweise alle 10 Pakete zu bestätigen. Es hat sich gezeigt, dass dies große Geschwindigkeitsvorteile auf Satelliten- und Netzwerken mit sehr hoher Bandbreite bringt, weil der Aufwand für die Übertragung der Bestätigungspakete verringert wird. Das Hinzufügen einer solchen Erweiterung für TCP würde lange dauern, bis sie angenommen wird, während es für QUIC viel einfacher zu implementieren ist.
Daher können wir erwarten, dass die Flexibilität von QUIC im Laufe der Zeit zu mehr Experimenten und besseren Überlastungskontrollalgorithmen führen wird, die wiederum auch auf TCP zurückportiert werden könnten, um es ebenfalls zu verbessern.
Wusstest du schon?
Der offizielle QUIC Recovery RFC 9002 spezifiziert die Verwendung des NewReno-Algorithmus zur Staukontrolle. Dieser Ansatz ist zwar robust, aber auch etwas veraltet und wird in der Praxis nicht mehr umfassend verwendet. Warum ist es also im QUIC RFC? Der erste Grund ist, dass, als QUIC gestartet wurde, NewReno der neueste Überlastungskontrollalgorithmus war, der selbst standardisiert war. Fortgeschrittenere Algorithmen wie BBR und CUBIC sind entweder noch nicht standardisiert oder wurden erst kürzlich zu RFCs.
Der zweite Grund ist, dass NewReno eine relativ einfache Einrichtung ist. Da die Algorithmen einige Optimierungen benötigen, um mit den Unterschieden von QUIC zu TCP fertig zu werden, ist es einfacher, diese Änderungen mit einem einfacheren Algorithmus zu erklären. Daher sollte RFC 9002 eher gelesen werden als „wie man einen Überlastungskontrollalgorithmus an QUIC anpasst“ und nicht „das ist das, was man für QUIC verwenden sollte“. Tatsächlich haben die meisten QUIC-Implementierungen auf Produktionsebene benutzerdefinierte Implementierungen sowohl von Cubic als auch von BBR vorgenommen.
Es muss wiederholt werden, dass Überlastungskontrollalgorithmen nicht TCP- oder QUIC-spezifisch sind ; Sie können von beiden Protokollen verwendet werden, und die Hoffnung ist, dass die Fortschritte bei QUIC schließlich auch ihren Weg in TCP-Stacks finden werden.
Wusstest du schon?
Beachten Sie, dass es neben der Überlastungssteuerung ein verwandtes Konzept gibt, das als Flusssteuerung bezeichnet wird. Diese beiden Features werden bei TCP oft verwechselt, weil sie angeblich beide das „TCP-Fenster“ verwenden, obwohl es tatsächlich zwei Fenster gibt: das Congestion-Window und das TCP-Receive-Window. Die Flusskontrolle spielt jedoch für den Anwendungsfall des Ladens von Webseiten, an dem wir interessiert sind, viel weniger eine Rolle, daher überspringen wir sie hier. Weiterführende Informationen stehen zur Verfügung.
Was soll das alles heißen?
QUIC ist nach wie vor den Gesetzen der Physik und dem Zwang verpflichtet, nett zu anderen Versendern im Internet zu sein. Dies bedeutet, dass Ihre Website-Ressourcen nicht auf magische Weise viel schneller als TCP heruntergeladen werden. Die Flexibilität von QUIC bedeutet jedoch, dass das Experimentieren mit neuen Überlastungskontrollalgorithmen einfacher wird, was die Dinge in der Zukunft sowohl für TCP als auch für QUIC verbessern sollte.
0-RTT Verbindungsaufbau
Ein zweiter Leistungsaspekt betrifft die Anzahl der Roundtrips , bevor Sie nützliche HTTP-Daten (z. B. Seitenressourcen) über eine neue Verbindung senden können. Einige behaupten, dass QUIC zwei bis drei Roundtrips schneller ist als TCP + TLS, aber wir werden sehen, dass es wirklich nur einer ist.
Wusstest du schon?
Wie wir in Teil 1 gesagt haben, führt eine Verbindung normalerweise einen (TCP) oder zwei (TCP + TLS) Handshakes durch, bevor HTTP-Anforderungen und -Antworten ausgetauscht werden können. Diese Handshakes tauschen Anfangsparameter aus, die sowohl Client als auch Server kennen müssen, um beispielsweise die Daten zu verschlüsseln.
Wie Sie in Abbildung 2 unten sehen können, benötigt jeder einzelne Handshake mindestens einen Roundtrip (TCP + TLS 1.3, (b)) und manchmal zwei (TLS 1.2 und früher (a)). Dies ist ineffizient, da wir mindestens zwei Roundtrips der Handshake-Wartezeit (Overhead) benötigen, bevor wir unsere erste HTTP-Anforderung senden können, was bedeutet, dass wir mindestens drei Roundtrips warten müssen, bis die ersten HTTP-Antwortdaten (der zurückkehrende rote Pfeil) eintreffen in. In langsamen Netzwerken kann dies einen Overhead von 100 bis 200 Millisekunden bedeuten.
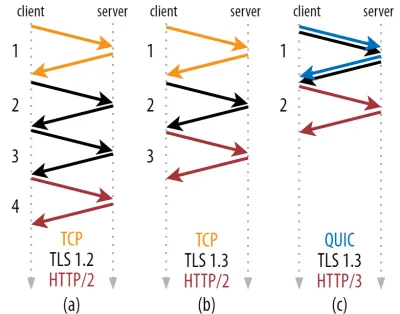
Sie fragen sich vielleicht, warum der TCP + TLS-Handshake nicht einfach kombiniert werden kann, und zwar im selben Roundtrip. Während dies konzeptionell möglich ist (QUIC macht genau das), waren die Dinge anfangs nicht so konzipiert, weil wir in der Lage sein müssen, TCP mit und ohne TLS obendrauf zu verwenden. Anders ausgedrückt unterstützt TCP das Senden von Nicht-TCP-Daten während des Handshakes einfach nicht . Es gab Bemühungen, dies mit der TCP Fast Open-Erweiterung hinzuzufügen; Wie in Teil 1 besprochen, hat sich dies jedoch als schwierig in großem Maßstab zu implementieren erwiesen.
Glücklicherweise wurde QUIC von Anfang an mit Blick auf TLS entwickelt und kombiniert daher sowohl den Transport als auch kryptografische Handshakes in einem einzigen Mechanismus. Das bedeutet, dass der QUIC-Handshake insgesamt nur einen Roundtrip benötigt, also einen Roundtrip weniger als bei TCP + TLS 1.3 (siehe Abbildung 2c oben).
Sie könnten verwirrt sein, weil Sie wahrscheinlich gelesen haben, dass QUIC zwei oder sogar drei Roundtrips schneller ist als TCP, nicht nur einen. Das liegt daran, dass die meisten Artikel nur den Worst Case betrachten (TCP + TLS 1.2, (a)), ganz zu schweigen davon, dass das moderne TCP + TLS 1.3 auch „nur“ zwei Roundtrips braucht ((b) wird selten gezeigt). Während ein Geschwindigkeitsschub von einer Hin- und Rückfahrt nett ist, ist es kaum erstaunlich. Besonders in schnellen Netzwerken (z. B. weniger als 50 Millisekunden RTT) wird dies kaum wahrnehmbar sein, obwohl langsame Netzwerke und Verbindungen zu entfernten Servern etwas mehr profitieren würden.
Als nächstes fragen Sie sich vielleicht, warum wir überhaupt auf den/die Handshake(s) warten müssen. Warum können wir im ersten Roundtrip keine HTTP-Anfrage senden? Dies liegt hauptsächlich daran, dass diese erste Anfrage unverschlüsselt gesendet würde, lesbar für jeden Lauscher auf der Leitung, was offensichtlich nicht gut für die Privatsphäre und Sicherheit ist. Daher müssen wir warten, bis der kryptografische Handshake abgeschlossen ist, bevor wir die erste HTTP-Anforderung senden. Oder wir?
Hier kommt in der Praxis ein cleverer Trick zum Einsatz. Wir wissen, dass Benutzer Webseiten häufig innerhalb kurzer Zeit nach ihrem ersten Besuch erneut besuchen. Daher können wir die anfängliche verschlüsselte Verbindung verwenden, um in Zukunft eine zweite Verbindung zu booten. Einfach ausgedrückt, wird die erste Verbindung irgendwann während ihrer Lebensdauer verwendet, um neue kryptografische Parameter sicher zwischen dem Client und dem Server zu kommunizieren. Diese Parameter können dann verwendet werden, um die zweite Verbindung von Anfang an zu verschlüsseln , ohne warten zu müssen, bis der vollständige TLS-Handshake abgeschlossen ist. Dieser Ansatz wird als „Sitzungswiederaufnahme“ bezeichnet .
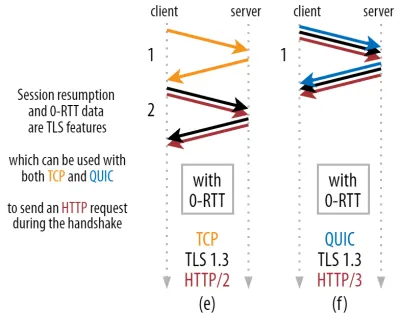
Es ermöglicht eine leistungsstarke Optimierung: Wir können jetzt unsere erste HTTP-Anfrage sicher zusammen mit dem QUIC/TLS-Handshake senden und sparen so einen weiteren Roundtrip ! Wie bei TLS 1.3 beseitigt dies effektiv die Wartezeit des TLS-Handshakes. Diese Methode wird oft als 0-RTT bezeichnet (obwohl es natürlich immer noch einen Roundtrip dauert, bis die HTTP-Antwortdaten ankommen).
Sowohl die Sitzungswiederaufnahme als auch 0-RTT sind wiederum Dinge, die ich oft falsch als QUIC-spezifische Funktionen erklärt gesehen habe. In Wirklichkeit handelt es sich dabei eigentlich um TLS-Features , die in irgendeiner Form schon in TLS 1.2 vorhanden waren und nun in TLS 1.3 vollwertig sind.
Anders ausgedrückt, wie Sie in Abbildung 3 unten sehen können, können wir die Leistungsvorteile dieser Funktionen auch über TCP (und damit auch HTTP/2 und sogar HTTP/1.1) nutzen! Wir sehen, dass QUIC selbst mit 0-RTT immer noch nur einen Roundtrip schneller ist als ein optimal funktionierender TCP + TLS 1.3-Stack. Die Behauptung, dass QUIC drei Runden schneller ist, ergibt sich aus dem Vergleich von Abbildung 2 (a) mit Abbildung 3 (f), was, wie wir gesehen haben, nicht wirklich fair ist.
Das Schlimmste ist, dass QUIC bei Verwendung von 0-RTT aus Sicherheitsgründen nicht einmal den gewonnenen Roundtrip wirklich gut nutzen kann. Um dies zu verstehen, müssen wir einen der Gründe verstehen, warum der TCP-Handshake existiert. Erstens kann der Client sicher sein, dass der Server tatsächlich unter der angegebenen IP-Adresse verfügbar ist, bevor er ihm Daten höherer Schichten sendet.
Zweitens, und das ist hier entscheidend, ermöglicht es dem Server, sicherzustellen, dass der Client, der die Verbindung öffnet, tatsächlich der ist, von dem er sagt, dass er sich dort aufhält, bevor er ihm Daten sendet. Wenn Sie sich daran erinnern, wie wir in Teil 1 eine Verbindung mit dem 4-Tupel definiert haben, wissen Sie, dass der Client hauptsächlich über seine IP-Adresse identifiziert wird. Und das ist das Problem: IP-Adressen können gespooft werden !
Angenommen, ein Angreifer fordert eine sehr große Datei per HTTP über QUIC 0-RTT an. Sie fälschen jedoch ihre IP-Adresse, sodass es so aussieht, als käme die 0-RTT-Anfrage vom Computer ihres Opfers. Dies ist in Abbildung 4 unten dargestellt. Der QUIC-Server kann nicht erkennen, ob die IP gespooft wurde, da dies das allererste Paket ist, das er von diesem Client sieht.

Wenn der Server dann einfach anfängt, die große Datei an die gefälschte IP zurückzusenden, könnte dies dazu führen, dass die Netzwerkbandbreite des Opfers überlastet wird (insbesondere, wenn der Angreifer viele dieser gefälschten Anfragen parallel ausführen würde). Beachten Sie, dass die QUIC-Antwort vom Opfer verworfen würde, da es keine eingehenden Daten erwartet, aber das spielt keine Rolle: Ihr Netzwerk muss die Pakete noch verarbeiten!
Dies wird als Reflection- oder Amplification-Angriff bezeichnet und ist eine wichtige Methode, mit der Hacker Distributed-Denial-of-Service-Angriffe (DDoS) ausführen. Beachten Sie, dass dies nicht passiert, wenn 0-RTT über TCP + TLS verwendet wird, gerade weil der TCP-Handshake zuerst abgeschlossen werden muss, bevor die 0-RTT-Anforderung überhaupt zusammen mit dem TLS-Handshake gesendet wird.
Daher muss QUIC bei der Beantwortung von 0-RTT-Anforderungen konservativ sein und die Menge der als Antwort gesendeten Daten begrenzen, bis der Client als echter Client und nicht als Opfer verifiziert wurde. Für QUIC wurde diese Datenmenge auf das Dreifache der vom Kunden erhaltenen Menge festgelegt.
Anders ausgedrückt, QUIC hat einen maximalen „Verstärkungsfaktor“ von drei, was als akzeptabler Kompromiss zwischen Leistungsnutzen und Sicherheitsrisiko bestimmt wurde (insbesondere im Vergleich zu einigen Vorfällen, die einen Verstärkungsfaktor von über 51.000 hatten). Da der Client normalerweise zuerst nur ein bis zwei Pakete sendet, wird die 0-RTT-Antwort des QUIC-Servers auf nur 4 bis 6 KB begrenzt (einschließlich anderer QUIC- und TLS-Overheads!), was etwas weniger als beeindruckend ist.
Darüber hinaus können andere Sicherheitsprobleme beispielsweise zu „Replay-Angriffen“ führen, die die Art der HTTP-Anfrage einschränken, die Sie ausführen können. Beispielsweise erlaubt Cloudflare nur HTTP GET-Anfragen ohne Abfrageparameter in 0-RTT. Diese schränken die Nützlichkeit von 0-RTT noch mehr ein.
Glücklicherweise hat QUIC Optionen, um dies ein bisschen besser zu machen. Beispielsweise kann der Server prüfen, ob die 0-RTT von einer IP stammt, mit der er zuvor eine gültige Verbindung hatte. Dies funktioniert jedoch nur, wenn der Client im selben Netzwerk bleibt (was die Verbindungsmigrationsfunktion von QUIC etwas einschränkt). Und selbst wenn es funktioniert, ist die Reaktion von QUIC immer noch durch die oben besprochene Langsamstartlogik des Staureglers begrenzt; Es gibt also keinen zusätzlichen massiven Geschwindigkeitsschub außer der eingesparten Hin- und Rückfahrt.
Wusstest du schon?
Es ist interessant festzustellen, dass die dreifache Verstärkungsgrenze von QUIC auch für seinen normalen Nicht-0-RTT-Handshake-Prozess in Abbildung 2c gilt. Dies kann ein Problem sein, wenn beispielsweise das TLS-Zertifikat des Servers zu groß ist, um in 4 bis 6 KB zu passen. In diesem Fall müsste es aufgeteilt werden, wobei der zweite Chunk auf das Senden des zweiten Roundtrips warten müsste (nachdem Bestätigungen der ersten paar Pakete eingehen, die darauf hinweisen, dass die IP des Clients nicht gespooft wurde). In diesem Fall könnte der Handshake von QUIC am Ende immer noch zwei Rundreisen machen , was TCP + TLS entspricht! Aus diesem Grund werden für QUIC Techniken wie die Komprimierung von Zertifikaten besonders wichtig sein.
Wusstest du schon?
Es könnte sein, dass bestimmte fortschrittliche Setups in der Lage sind, diese Probleme ausreichend zu mildern, um 0-RTT nützlicher zu machen. Beispielsweise könnte sich der Server daran erinnern, wie viel Bandbreite ein Client verfügbar hatte, als er das letzte Mal gesehen wurde, wodurch er weniger durch den langsamen Start der Überlastungssteuerung für die Wiederverbindung von (nicht gespooften) Clients eingeschränkt wird. Dies wurde in der Wissenschaft untersucht, und es gibt sogar eine vorgeschlagene Erweiterung in QUIC, um dies zu tun. Mehrere Unternehmen tun dies bereits, um TCP ebenfalls zu beschleunigen.
Eine andere Option wäre, Clients mehr als ein oder zwei Pakete senden zu lassen (z. B. 7 weitere Pakete mit Padding), sodass das dreifache Limit zu einer interessanteren 12- bis 14-KB-Antwort führt, selbst nach der Verbindungsmigration. Ich habe darüber in einer meiner Zeitungen geschrieben.
Schließlich könnten (sich schlecht benehmende) QUIC-Server das Dreifach-Limit auch absichtlich erhöhen, wenn sie das Gefühl haben, dass dies irgendwie sicher ist, oder wenn sie sich nicht um die potenziellen Sicherheitsprobleme kümmern (schließlich gibt es keine Protokollpolizei, die dies verhindert).
Was soll das alles heißen?
Der schnellere Verbindungsaufbau von QUIC mit 0-RTT ist wirklich eher eine Mikrooptimierung als ein revolutionäres neues Feature. Im Vergleich zu einem hochmodernen TCP + TLS 1.3-Setup würde es maximal einen Roundtrip einsparen. Die Datenmenge, die im ersten Roundtrip tatsächlich gesendet werden kann, wird zusätzlich durch eine Reihe von Sicherheitsaspekten begrenzt.
Daher wird diese Funktion meistens glänzen, wenn sich Ihre Benutzer in Netzwerken mit sehr hoher Latenz befinden (z. B. Satellitennetzwerke mit RTTs von mehr als 200 Millisekunden) oder wenn Sie normalerweise nicht viele Daten senden. Einige Beispiele für letztere sind stark zwischengespeicherte Websites sowie Single-Page-Apps, die regelmäßig kleine Updates über APIs und andere Protokolle wie DNS-over-QUIC abrufen. Einer der Gründe, warum Google sehr gute 0-RTT-Ergebnisse für QUIC sah, war, dass es es auf seiner bereits stark optimierten Suchseite getestet hat, auf der die Abfrageantworten recht gering sind.
In anderen Fällen gewinnen Sie bestenfalls nur ein paar Dutzend Millisekunden , noch weniger, wenn Sie bereits ein CDN verwenden (was Sie tun sollten, wenn Ihnen die Leistung wichtig ist!).
Verbindungsmigration
Ein drittes Leistungsmerkmal macht QUIC bei der Übertragung zwischen Netzwerken schneller, indem bestehende Verbindungen intakt bleiben . Obwohl dies tatsächlich funktioniert, kommt diese Art von Netzwerkänderung nicht allzu oft vor und Verbindungen müssen ihre Senderaten noch zurücksetzen.
Wie in Teil 1 besprochen, ermöglichen die Verbindungs-IDs (CIDs) von QUIC die Durchführung einer Verbindungsmigration beim Netzwerkwechsel . Wir haben dies anhand eines Clients veranschaulicht, der von einem Wi-Fi-Netzwerk zu 4G wechselt, während er eine große Datei herunterlädt. Bei TCP muss dieser Download möglicherweise abgebrochen werden, während er bei QUIC möglicherweise fortgesetzt wird.
Überlegen Sie jedoch zunächst, wie oft ein solches Szenario tatsächlich eintritt. Sie könnten denken, dass dies auch passiert, wenn Sie sich zwischen Wi-Fi-Zugangspunkten innerhalb eines Gebäudes oder zwischen Mobilfunkmasten bewegen, während Sie unterwegs sind. In diesen Konfigurationen behält Ihr Gerät jedoch (bei korrekter Ausführung) seine IP-Adresse in der Regel bei, da der Übergang zwischen drahtlosen Basisstationen auf einer niedrigeren Protokollschicht erfolgt. Als solches tritt es nur auf, wenn Sie zwischen völlig unterschiedlichen Netzwerken wechseln , was meiner Meinung nach nicht allzu oft vorkommt.
Zweitens können wir fragen, ob dies neben dem Herunterladen großer Dateien und Live-Videokonferenzen und -Streaming auch für andere Anwendungsfälle funktioniert. Wenn Sie eine Webseite genau in dem Moment laden, in dem Sie das Netzwerk wechseln, müssen Sie möglicherweise einige der (späteren) Ressourcen tatsächlich erneut anfordern.
Das Laden einer Seite dauert jedoch normalerweise in der Größenordnung von Sekunden, so dass das Zusammenfallen mit einem Netzwerkwechsel ebenfalls nicht sehr häufig ist. Darüber hinaus sind für Anwendungsfälle, in denen dies ein dringendes Problem darstellt, in der Regel bereits andere Abhilfemaßnahmen vorhanden . Beispielsweise können Server, die große Dateidownloads anbieten, HTTP-Bereichsanforderungen unterstützen, um fortsetzbare Downloads zu ermöglichen.
Da zwischen dem Abbruch von Netzwerk 1 und der Verfügbarkeit von Netzwerk 2 in der Regel eine gewisse Überschneidungszeit besteht, können Video-Apps mehrere Verbindungen (1 pro Netzwerk) öffnen und sie synchronisieren, bevor das alte Netzwerk vollständig verschwindet. Der Benutzer wird den Wechsel immer noch bemerken, aber der Video-Feed wird nicht vollständig gelöscht.
Drittens gibt es keine Garantie dafür, dass das neue Netzwerk genauso viel Bandbreite zur Verfügung hat wie das alte. Obwohl die konzeptionelle Verbindung intakt bleibt, kann der QUIC-Server daher nicht einfach weiterhin Daten mit hoher Geschwindigkeit senden. Um das neue Netzwerk nicht zu überlasten, muss es stattdessen die Senderate zurücksetzen (oder zumindest verringern) und in der Slow-Start-Phase des Congestion Controllers neu starten.
Da diese anfängliche Senderate normalerweise zu niedrig ist, um Dinge wie Videostreaming wirklich zu unterstützen, werden Sie selbst bei QUIC einige Qualitätsverluste oder Schluckauf feststellen. In gewisser Weise geht es bei der Verbindungsmigration mehr darum, Verbindungskontextänderungen und Overhead auf dem Server zu verhindern, als die Leistung zu verbessern.
Wusstest du schon?
Beachten Sie, dass wir, wie oben für 0-RTT besprochen, einige fortgeschrittene Techniken entwickeln können, um die Verbindungsmigration zu verbessern. Beispielsweise können wir erneut versuchen, uns daran zu erinnern, wie viel Bandbreite beim letzten Mal in einem bestimmten Netzwerk verfügbar war, und versuchen, für eine neue Migration schneller auf dieses Niveau hochzufahren. Außerdem könnten wir uns vorstellen, nicht einfach zwischen den Netzwerken zu wechseln, sondern beide gleichzeitig zu nutzen. Dieses Konzept wird Multipath genannt und wir diskutieren es weiter unten ausführlicher.
Bisher haben wir hauptsächlich über die aktive Verbindungsmigration gesprochen, bei der Benutzer zwischen verschiedenen Netzwerken wechseln. Es gibt jedoch auch Fälle von passiver Verbindungsmigration, bei denen ein bestimmtes Netzwerk selbst Parameter ändert. Ein gutes Beispiel dafür ist Network Address Translation (NAT) Rebinding. Obwohl eine vollständige Erörterung von NAT den Rahmen dieses Artikels sprengen würde, bedeutet dies hauptsächlich, dass sich die Portnummern der Verbindung jederzeit ohne Vorwarnung ändern können . Dies passiert bei den meisten Routern auch viel häufiger bei UDP als bei TCP.
Wenn dies auftritt, ändert sich die QUIC-CID nicht, und die meisten Implementierungen gehen davon aus, dass sich der Benutzer immer noch im selben physischen Netzwerk befindet, und setzen daher das Überlastungsfenster oder andere Parameter nicht zurück. QUIC enthält auch einige Funktionen wie PINGs und Zeitüberschreitungsanzeigen, um dies zu verhindern, da dies normalerweise bei Verbindungen mit langem Leerlauf auftritt.
Wir haben in Teil 1 besprochen, dass QUIC aus Sicherheitsgründen nicht nur eine einzige CID verwendet. Stattdessen werden CIDs geändert, wenn eine aktive Migration durchgeführt wird. In der Praxis ist es noch komplizierter, da sowohl der Client als auch der Server separate Listen von CIDs haben (im QUIC-RFC als Quell- und Ziel-CIDs bezeichnet). Dies ist in Abbildung 5 unten dargestellt.
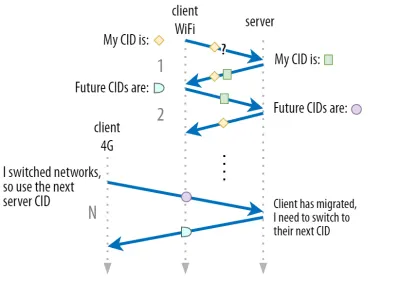
Dies geschieht, damit jeder Endpunkt sein eigenes CID-Format und seinen eigenen Inhalt auswählen kann, was wiederum entscheidend ist, um eine erweiterte Routing- und Lastausgleichslogik zu ermöglichen. Mit der Verbindungsmigration können Load Balancer nicht mehr nur das 4-Tupel betrachten, um eine Verbindung zu identifizieren und sie an den richtigen Back-End-Server zu senden. Wenn jedoch alle QUIC-Verbindungen zufällige CIDs verwenden würden, würde dies die Speicheranforderungen beim Load Balancer stark erhöhen, da er Zuordnungen von CIDs zu Back-End-Servern speichern müsste. Außerdem würde dies bei der Verbindungsmigration immer noch nicht funktionieren, da die CIDs auf neue zufällige Werte geändert werden.
Daher ist es wichtig, dass QUIC-Back-End-Server, die hinter einem Load Balancer bereitgestellt werden, ein vorhersagbares Format ihrer CIDs haben, damit der Load Balancer auch nach der Migration den richtigen Back-End-Server von der CID ableiten kann. Einige Optionen dafür sind in dem von der IETF vorgeschlagenen Dokument beschrieben. Um dies alles zu ermöglichen, müssen die Server in der Lage sein, ihre eigene CID auszuwählen, was nicht möglich wäre, wenn der Verbindungsinitiator (der für QUIC immer der Client ist) die CID auswählen würde. Aus diesem Grund gibt es in QUIC eine Aufteilung zwischen Client- und Server-CIDs.

Was soll das alles heißen?
Somit ist die Verbindungsmigration ein situatives Merkmal. Erste Tests von Google beispielsweise zeigen geringe prozentuale Verbesserungen für seine Anwendungsfälle. Viele QUIC-Implementierungen implementieren diese Funktion noch nicht. Selbst diejenigen, die dies tun, beschränken es normalerweise auf mobile Clients und Apps und nicht auf ihre Desktop-Äquivalente. Einige Leute sind sogar der Meinung, dass das Feature nicht benötigt wird, da das Öffnen einer neuen Verbindung mit 0-RTT in den meisten Fällen ähnliche Leistungseigenschaften haben sollte.
Abhängig von Ihrem Anwendungsfall oder Benutzerprofil kann dies jedoch große Auswirkungen haben. Wenn Ihre Website oder App am häufigsten unterwegs verwendet wird (z. B. Uber oder Google Maps), profitieren Sie wahrscheinlich mehr, als wenn Ihre Benutzer normalerweise hinter einem Schreibtisch sitzen würden. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
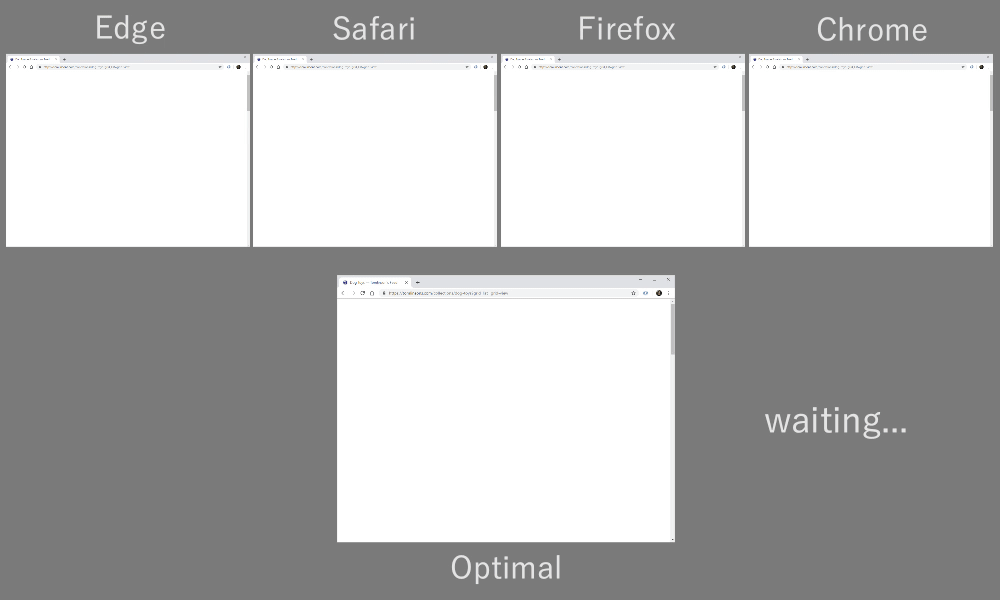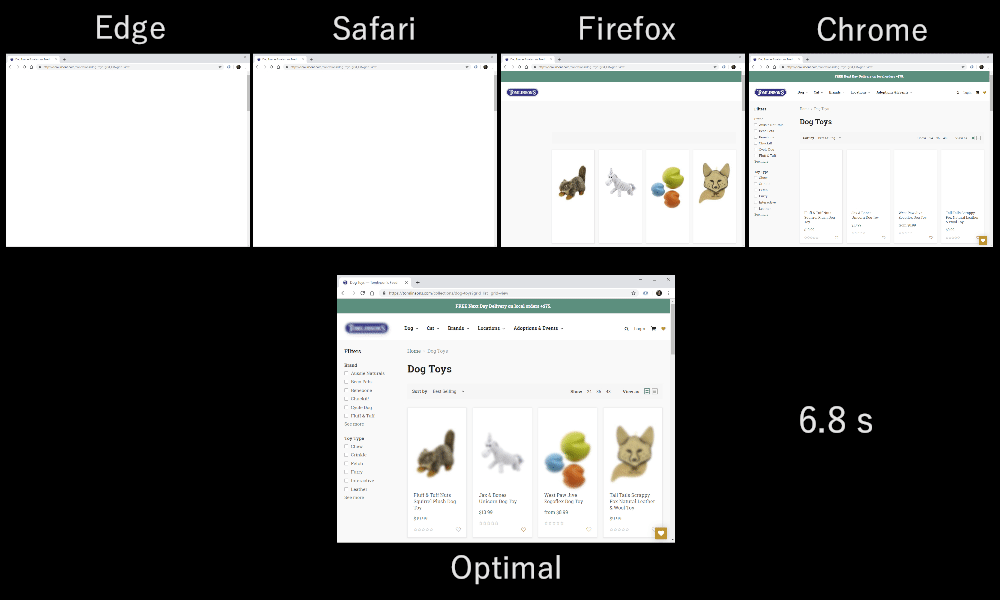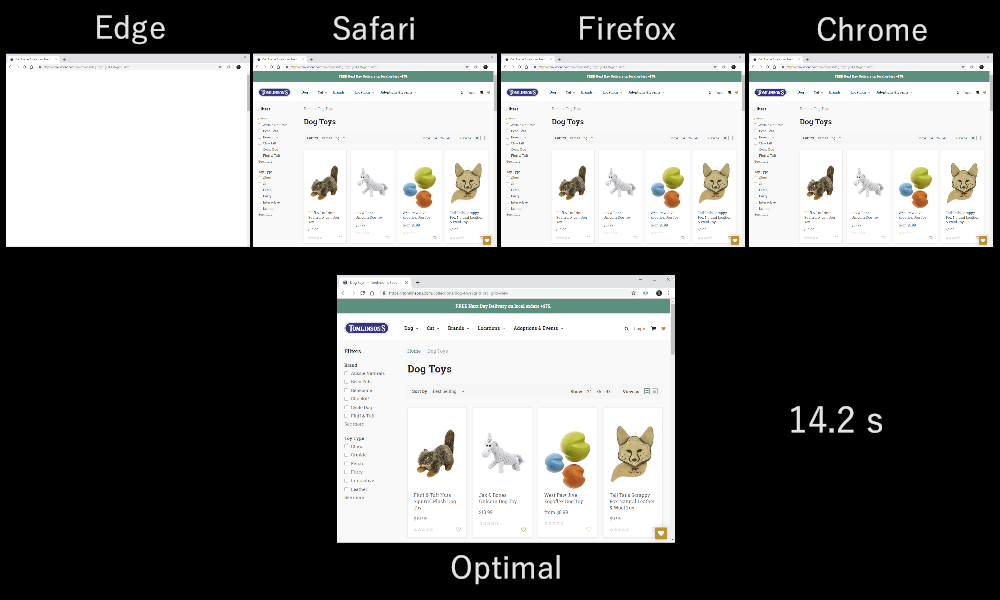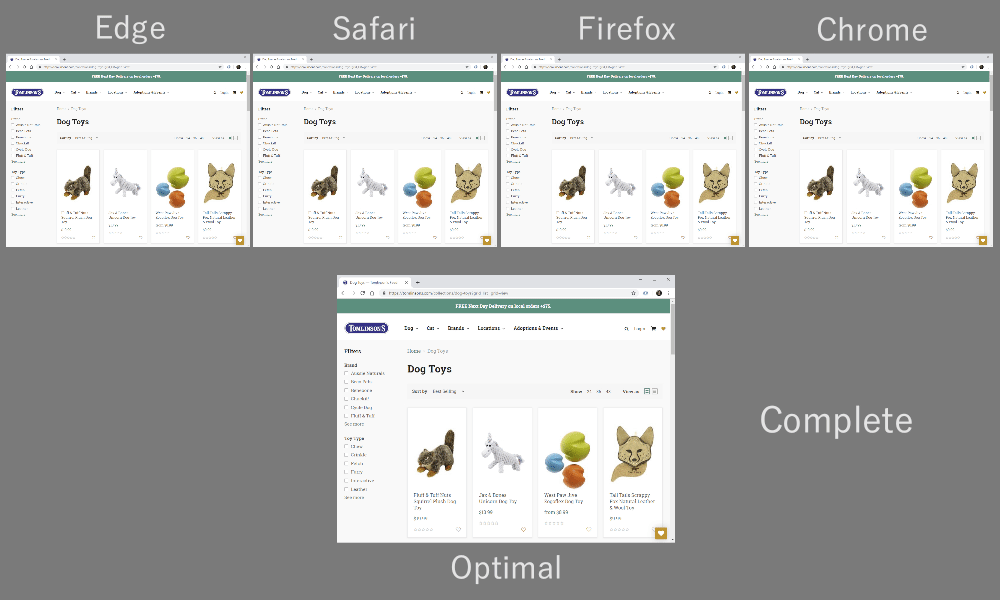
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).
What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
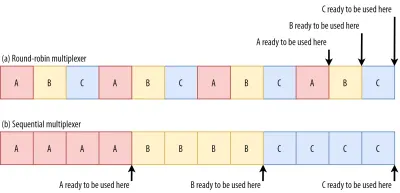
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
And it gets worse. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
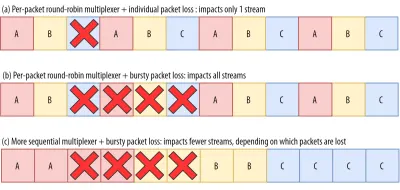
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
Was soll das alles heißen?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
UDP- und TLS-Leistung
Ein fünfter Leistungsaspekt von QUIC und HTTP/3 betrifft die Frage, wie effizient und leistungsfähig sie tatsächlich Pakete im Netzwerk erstellen und senden können. Wir werden sehen, dass die Verwendung von UDP und starker Verschlüsselung durch QUIC es ein gutes Stück langsamer als TCP machen kann (aber die Dinge verbessern sich).
Erstens haben wir bereits besprochen, dass es bei der Verwendung von UDP durch QUIC mehr um Flexibilität und Bereitstellungsfähigkeit als um Leistung ging. Dies wird noch deutlicher durch die Tatsache, dass das Senden von QUIC-Paketen über UDP bis vor kurzem typischerweise viel langsamer war als das Senden von TCP-Paketen. Dies liegt teilweise daran, wo und wie diese Protokolle typischerweise implementiert werden (siehe Abbildung 9 unten).
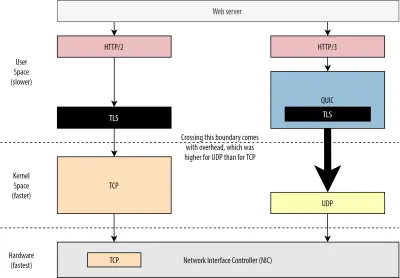
Wie oben diskutiert, werden TCP und UDP typischerweise direkt im schnellen Kernel des Betriebssystems implementiert. Im Gegensatz dazu befinden sich TLS- und QUIC-Implementierungen meist in einem langsameren Benutzerbereich (beachten Sie, dass dies für QUIC nicht wirklich erforderlich ist – es wird meistens getan, weil es viel flexibler ist). Damit ist QUIC schon etwas langsamer als TCP.
Wenn wir Daten von unserer User-Space-Software (z. B. Browser und Webserver) senden, müssen wir diese Daten außerdem an den Betriebssystemkernel weitergeben , der sie dann mithilfe von TCP oder UDP tatsächlich in das Netzwerk stellt. Die Weitergabe dieser Daten erfolgt über Kernel-APIs (Systemaufrufe), was einen gewissen Overhead pro API-Aufruf mit sich bringt. Bei TCP waren diese Overheads viel geringer als bei UDP.
Dies liegt hauptsächlich daran, dass TCP in der Vergangenheit viel häufiger verwendet wurde als UDP. Daher wurden im Laufe der Zeit viele Optimierungen zu TCP-Implementierungen und Kernel-APIs hinzugefügt, um den Overhead für das Senden und Empfangen von Paketen auf ein Minimum zu reduzieren. Viele Netzwerkschnittstellencontroller (NICs) verfügen sogar über integrierte Hardware-Offload-Funktionen für TCP. UDP hatte jedoch nicht so viel Glück, da seine eingeschränktere Verwendung die Investition in zusätzliche Optimierungen nicht rechtfertigte. In den letzten fünf Jahren hat sich dies glücklicherweise geändert, und die meisten Betriebssysteme haben seitdem auch optimierte Optionen für UDP hinzugefügt .
Zweitens hat QUIC viel Overhead, weil es jedes Paket einzeln verschlüsselt . Dies ist langsamer als die Verwendung von TLS über TCP, da Sie dort Pakete in Blöcken (bis zu etwa 16 KB oder 11 Pakete gleichzeitig) verschlüsseln können, was effizienter ist. Dies war ein bewusster Kompromiss, der in QUIC eingegangen wurde, da die Massenverschlüsselung zu eigenen Formen der HoL-Blockierung führen kann.
Im Gegensatz zum ersten Punkt, wo wir zusätzliche APIs hinzufügen könnten, um UDP (und damit QUIC) schneller zu machen, wird QUIC hier immer einen inhärenten Nachteil gegenüber TCP + TLS haben. Aber auch das ist in der Praxis gut beherrschbar, beispielsweise mit optimierten Verschlüsselungsbibliotheken und cleveren Methoden, die es ermöglichen, Header von QUIC-Paketen massenhaft zu verschlüsseln.
Während die frühesten QUIC-Versionen von Google immer noch doppelt so langsam waren wie TCP + TLS, haben sich die Dinge seitdem sicherlich verbessert. In kürzlich durchgeführten Tests konnte beispielsweise der stark optimierte QUIC-Stack von Microsoft 7,85 Gbit/s erreichen, verglichen mit 11,85 Gbit/s für TCP + TLS auf demselben System (hier ist QUIC also etwa 66 % so schnell wie TCP + TLS).
Dies liegt an den jüngsten Windows-Updates, die UDP schneller gemacht haben (für einen vollständigen Vergleich betrug der UDP-Durchsatz auf diesem System 19,5 Gbit/s). Die am besten optimierte Version von Googles QUIC-Stack ist derzeit etwa 20 % langsamer als TCP + TLS. Frühere Tests von Fastly auf einem weniger fortschrittlichen System und mit ein paar Tricks behaupten sogar eine gleiche Leistung (ca. 450 Mbit / s), was zeigt, dass QUIC je nach Anwendungsfall durchaus mit TCP konkurrieren kann.
Aber selbst wenn QUIC doppelt so langsam wäre wie TCP + TLS, ist es nicht so schlimm. Erstens ist die QUIC- und TCP + TLS-Verarbeitung normalerweise nicht das Schwerste, was auf einem Server passiert, da andere Logik (z. B. HTTP, Caching, Proxying usw.) ebenfalls ausgeführt werden muss. Daher benötigen Sie nicht doppelt so viele Server, um QUIC auszuführen (es ist jedoch etwas unklar, wie viel Einfluss dies auf ein echtes Rechenzentrum haben wird , da keines der großen Unternehmen Daten dazu veröffentlicht hat).
Zweitens gibt es noch viele Möglichkeiten, QUIC-Implementierungen in Zukunft zu optimieren. Beispielsweise werden einige QUIC-Implementierungen im Laufe der Zeit (teilweise) in den Betriebssystemkern verschoben (ähnlich wie TCP) oder ihn umgehen (einige tun dies bereits, wie MsQuic und Quant). Wir können auch damit rechnen, dass QUIC-spezifische Hardware verfügbar wird.
Dennoch wird es wahrscheinlich einige Anwendungsfälle geben, für die TCP + TLS die bevorzugte Option bleiben wird. Zum Beispiel hat Netflix angedeutet, dass es wahrscheinlich nicht so bald zu QUIC wechseln wird, da es stark in benutzerdefinierte FreeBSD-Setups investiert hat, um seine Videos über TCP + TLS zu streamen.
In ähnlicher Weise hat Facebook gesagt, dass QUIC aufgrund seines größeren Overheads wahrscheinlich hauptsächlich zwischen Endbenutzern und dem Rand des CDN verwendet wird , aber nicht zwischen Rechenzentren oder zwischen Randknoten und Ursprungsservern. Generell dürften Szenarien mit sehr hoher Bandbreite TCP + TLS vor allem in den nächsten Jahren weiter favorisieren.
Wusstest du schon?
Die Optimierung von Netzwerkstacks ist ein tiefes und technisches Kaninchenloch, von dem das oben Genannte nur an der Oberfläche kratzt (und viele Nuancen vermisst). Wenn Sie mutig genug sind oder wissen möchten, was Begriffe wieGRO/GSO,SO_TXTIME, Kernel-Bypass undsendmmsg()undrecvmmsg()bedeuten, kann ich Ihnen auch einige hervorragende Artikel zur Optimierung von QUIC von Cloudflare und Fastly empfehlen B. eine ausführliche Code-Komplettlösung von Microsoft und ein ausführlicher Vortrag von Cisco. Schließlich hielt ein Google-Ingenieur eine sehr interessante Keynote über die Optimierung ihrer QUIC-Implementierung im Laufe der Zeit.
Was soll das alles heißen?
Die besondere Verwendung der UDP- und TLS-Protokolle durch QUIC hat es in der Vergangenheit viel langsamer gemacht als TCP + TLS. Im Laufe der Zeit wurden jedoch einige Verbesserungen vorgenommen (und werden weiterhin implementiert), die die Lücke etwas geschlossen haben. Sie werden diese Diskrepanzen in typischen Anwendungsfällen beim Laden von Webseiten wahrscheinlich nicht bemerken, aber sie könnten Ihnen Kopfschmerzen bereiten, wenn Sie große Serverfarmen unterhalten.
HTTP/3-Funktionen
Bisher haben wir hauptsächlich über neue Leistungsmerkmale in QUIC versus TCP gesprochen. Aber was ist mit HTTP/3 im Vergleich zu HTTP/2? Wie in Teil 1 besprochen, ist HTTP/3 wirklich HTTP/2-over-QUIC , und als solches wurden in der neuen Version keine wirklich großen neuen Funktionen eingeführt. Dies ist anders als bei der Umstellung von HTTP/1.1 auf HTTP/2, die viel größer war und neue Funktionen wie Header-Komprimierung, Stream-Priorisierung und Server-Push einführte. Diese Funktionen sind alle noch in HTTP/3 enthalten, aber es gibt einige wichtige Unterschiede darin, wie sie unter der Haube implementiert werden.
Dies liegt hauptsächlich daran, wie QUICs Aufhebung der HoL-Blockierung funktioniert. Wie wir besprochen haben, bedeutet ein Verlust auf Stream B nicht mehr, dass die Streams A und C auf die Neuübertragungen von B warten müssen, wie sie es bei TCP getan haben. Wenn also A, B und C jeweils ein QUIC-Paket in dieser Reihenfolge senden, könnten ihre Daten durchaus als A, C, B an den Browser geliefert (und von ihm verarbeitet) werden! Anders ausgedrückt, im Gegensatz zu TCP ist QUIC nicht mehr vollständig über verschiedene Streams geordnet !
Dies ist ein Problem für HTTP/2, das sich beim Design vieler seiner Funktionen wirklich auf die strenge Reihenfolge von TCP verlassen hat, die spezielle Steuernachrichten verwendet, die mit Datenblöcken durchsetzt sind. In QUIC können diese Steuernachrichten in beliebiger Reihenfolge eintreffen (und angewendet werden), was möglicherweise sogar dazu führt, dass die Funktionen das Gegenteil von dem bewirken, was beabsichtigt war! Die technischen Details sind für diesen Artikel wiederum unnötig, aber die erste Hälfte dieses Papiers sollte Ihnen eine Vorstellung davon geben, wie dumm dies werden kann.
Daher mussten die internen Mechanismen und Implementierungen der Funktionen für HTTP/3 geändert werden. Ein konkretes Beispiel ist die HTTP-Header-Komprimierung , die den Overhead wiederholter großer HTTP-Header (z. B. Cookies und User-Agent-Strings) senkt. Bei HTTP/2 wurde dies mit dem HPACK-Setup durchgeführt, während dies bei HTTP/3 auf das komplexere QPACK umgearbeitet wurde. Beide Systeme liefern dieselbe Funktion (dh Header-Komprimierung), jedoch auf ganz unterschiedliche Weise. Einige hervorragende technische Diskussionen und Diagramme zu diesem Thema finden Sie im Litespeed-Blog.
Ähnliches gilt für die Priorisierungsfunktion, die die Stream-Multiplexing-Logik steuert und die wir oben kurz besprochen haben. In HTTP/2 wurde dies durch ein komplexes „Abhängigkeitsbaum“-Setup implementiert, das explizit versuchte, alle Seitenressourcen und ihre Beziehungen zueinander zu modellieren (weitere Informationen finden Sie im Vortrag „The Ultimate Guide to HTTP Resource Prioritization“). Die Verwendung dieses Systems direkt über QUIC würde zu einigen möglicherweise sehr falschen Baumlayouts führen, da das Hinzufügen jeder Ressource zum Baum eine separate Steuernachricht wäre.
Darüber hinaus stellte sich dieser Ansatz als unnötig komplex heraus, was zu vielen Implementierungsfehlern und Ineffizienzen und einer unterdurchschnittlichen Leistung auf vielen Servern führte. Beide Probleme haben dazu geführt, dass das Priorisierungssystem für HTTP/3 auf eine viel einfachere Weise umgestaltet wurde. Diese unkompliziertere Einrichtung macht es schwierig oder unmöglich, einige fortgeschrittene Szenarien durchzusetzen (z. B. das Proxying von Datenverkehr von mehreren Clients auf einer einzigen Verbindung), ermöglicht aber dennoch eine Vielzahl von Optionen für die Optimierung des Ladens von Webseiten.
Obwohl die beiden Ansätze wiederum die gleiche grundlegende Funktion liefern (Leitstream-Multiplexing), besteht die Hoffnung, dass die einfachere Einrichtung von HTTP/3 zu weniger Implementierungsfehlern führen wird.
Schließlich gibt es Server-Push . Diese Funktion ermöglicht es dem Server, HTTP-Antworten zu senden, ohne zuerst auf eine explizite Anforderung für sie zu warten. Theoretisch könnte dies zu hervorragenden Leistungssteigerungen führen. In der Praxis stellte sich jedoch heraus, dass es schwierig war, es richtig zu verwenden, und dass es nicht konsistent implementiert wurde. Infolgedessen wird es wahrscheinlich sogar aus Google Chrome entfernt.
Trotz alledem ist es immer noch als Feature in HTTP/3 definiert (obwohl nur wenige Implementierungen es unterstützen). Obwohl sich seine internen Abläufe nicht so stark verändert haben wie die beiden vorherigen Funktionen, wurde es ebenfalls angepasst, um die nicht deterministische Reihenfolge von QUIC zu umgehen. Leider wird dies jedoch wenig dazu beitragen, einige seiner langjährigen Probleme zu lösen.
Was soll das alles heißen?
Wie wir bereits gesagt haben, stammt das meiste Potenzial von HTTP/3 aus dem zugrunde liegenden QUIC, nicht aus HTTP/3 selbst. Während sich die interne Implementierung des Protokolls stark von der von HTTP/2 unterscheidet, sind seine Leistungsmerkmale auf hohem Niveau und wie sie verwendet werden können und sollten, gleich geblieben.
Zukünftige Entwicklungen, auf die Sie achten sollten
In dieser Serie habe ich regelmäßig hervorgehoben, dass eine schnellere Entwicklung und höhere Flexibilität Kernaspekte von QUIC (und damit auch von HTTP/3) sind. Daher sollte es nicht überraschen, dass bereits an neuen Erweiterungen und Anwendungen der Protokolle gearbeitet wird. Nachfolgend sind die wichtigsten aufgeführt, denen Sie wahrscheinlich irgendwann begegnen werden:
Vorwärtsfehlerkorrektur
Der Zweck dieser Technik besteht wiederum darin, die Widerstandsfähigkeit von QUIC gegenüber Paketverlusten zu verbessern . Dazu werden redundante Kopien der Daten gesendet (allerdings geschickt codiert und komprimiert, damit sie nicht so groß sind). Wenn dann ein Paket verloren geht, aber die redundanten Daten ankommen, ist eine erneute Übertragung nicht länger erforderlich.
Dies war ursprünglich ein Teil von Google QUIC (und einer der Gründe, warum Leute sagen, dass QUIC gut gegen Paketverlust ist), aber es ist nicht in der standardisierten QUIC-Version 1 enthalten, da seine Auswirkungen auf die Leistung noch nicht nachgewiesen wurden. Forscher führen jetzt jedoch aktive Experimente damit durch, und Sie können ihnen dabei helfen, indem Sie die PQUIC-FEC Download Experiments App verwenden.Multipath QUIC
Wir haben bereits die Verbindungsmigration besprochen und wie sie beim Wechsel von beispielsweise Wi-Fi zu Mobilfunk helfen kann. Bedeutet dies jedoch nicht auch, dass wir möglicherweise gleichzeitig Wi-Fi und Mobilfunk verwenden? Die gleichzeitige Nutzung beider Netzwerke würde uns mehr verfügbare Bandbreite und erhöhte Robustheit geben! Das ist das Hauptkonzept hinter Multipath.
Dies ist wiederum etwas, mit dem Google experimentiert hat, das es aber aufgrund seiner inhärenten Komplexität nicht in die QUIC-Version 1 geschafft hat. Forscher haben jedoch inzwischen sein hohes Potenzial gezeigt, und es könnte es in QUIC-Version 2 schaffen. Beachten Sie, dass es auch TCP-Multipath gibt, aber es hat fast ein Jahrzehnt gedauert, bis es praktisch nutzbar wurde.Unzuverlässige Daten über QUIC und HTTP/3
Wie wir gesehen haben, ist QUIC ein absolut zuverlässiges Protokoll. Da es jedoch über UDP läuft, was unzuverlässig ist, können wir QUIC eine Funktion hinzufügen, um auch unzuverlässige Daten zu senden. Dies ist in der vorgeschlagenen Datagrammerweiterung umrissen. Sie möchten dies natürlich nicht zum Senden von Webseiten-Ressourcen verwenden, aber es könnte für Dinge wie Spiele und Live-Video-Streaming praktisch sein. Auf diese Weise würden Benutzer alle Vorteile von UDP nutzen, jedoch mit QUIC-Level-Verschlüsselung und (optionaler) Überlastungssteuerung.WebTransport
Browser setzen TCP oder UDP JavaScript nicht direkt aus, hauptsächlich aus Sicherheitsgründen. Stattdessen müssen wir uns auf APIs auf HTTP-Ebene wie Fetch und die etwas flexibleren Protokolle WebSocket und WebRTC verlassen. Die neueste in dieser Reihe von Optionen heißt WebTransport, mit dem Sie hauptsächlich HTTP/3 (und damit auch QUIC) auf einer niedrigeren Ebene verwenden können (obwohl es bei Bedarf auch auf TCP und HTTP/2 zurückgreifen kann). ).
Entscheidend ist, dass es die Möglichkeit beinhalten wird, unzuverlässige Daten über HTTP/3 zu verwenden (siehe den vorherigen Punkt), was die Implementierung von Dingen wie Spielen im Browser erheblich erleichtern sollte. Für normale (JSON-)API-Aufrufe verwenden Sie natürlich weiterhin Fetch, das nach Möglichkeit auch automatisch HTTP/3 verwendet. WebTransport wird derzeit noch heftig diskutiert, daher ist noch nicht klar, wie es letztendlich aussehen wird. Von den Browsern arbeitet derzeit nur Chromium an einer öffentlichen Proof-of-Concept-Implementierung.DASH- und HLS-Videostreaming
Für Nicht-Live-Videos (denken Sie an YouTube und Netflix) verwenden Browser normalerweise die Protokolle Dynamic Adaptive Streaming over HTTP (DASH) oder HTTP Live Streaming (HLS). Beides bedeutet im Grunde, dass Sie Ihre Videos in kleinere Stücke (von 2 bis 10 Sekunden) und unterschiedliche Qualitätsstufen (720p, 1080p, 4K usw.) codieren.
Zur Laufzeit schätzt der Browser die höchste Qualität, die Ihr Netzwerk verarbeiten kann (oder die optimale für einen bestimmten Anwendungsfall), und fordert die relevanten Dateien vom Server über HTTP an. Da der Browser keinen direkten Zugriff auf den TCP-Stack hat (wie dies normalerweise im Kernel implementiert ist), macht er gelegentlich einige Fehler bei diesen Schätzungen oder es dauert eine Weile, bis er auf sich ändernde Netzwerkbedingungen reagiert (was zu Videostillständen führt). .
Da QUIC als Teil des Browsers implementiert ist, könnte dies erheblich verbessert werden, indem den Streaming-Schätzern Zugriff auf Low-Level-Protokollinformationen (wie Verlustraten, Bandbreitenschätzungen usw.) gewährt wird. Andere Forscher haben auch mit dem Mischen zuverlässiger und unzuverlässiger Daten für das Videostreaming experimentiert, mit einigen vielversprechenden Ergebnissen.Andere Protokolle als HTTP/3
Da QUIC ein Allzweck-Transportprotokoll ist, können wir davon ausgehen, dass viele Protokolle der Anwendungsschicht, die jetzt über TCP laufen, auch auf QUIC laufen. Einige laufende Arbeiten umfassen DNS-over-QUIC, SMB-over-QUIC und sogar SSH-over-QUIC. Da diese Protokolle normalerweise sehr unterschiedliche Anforderungen haben als HTTP und das Laden von Webseiten, funktionieren die Leistungsverbesserungen von QUIC, die wir besprochen haben, möglicherweise viel besser für diese Protokolle.
Was soll das alles heißen?
QUIC Version 1 ist nur der Anfang . Viele fortschrittliche leistungsorientierte Funktionen, mit denen Google früher experimentiert hatte, schafften es nicht in diese erste Iteration. Das Ziel ist jedoch, das Protokoll schnell weiterzuentwickeln und neue Erweiterungen und Funktionen mit hoher Frequenz einzuführen. Daher sollte QUIC (und HTTP/3) im Laufe der Zeit deutlich schneller und flexibler als TCP (und HTTP/2) werden.
Fazit
In diesem zweiten Teil der Serie haben wir die vielen verschiedenen Leistungsmerkmale und Aspekte von HTTP/3 und insbesondere QUIC besprochen. Wir haben gesehen, dass die meisten dieser Funktionen zwar sehr wirkungsvoll erscheinen, in der Praxis jedoch für den durchschnittlichen Benutzer in dem von uns in Betracht gezogenen Anwendungsfall des Ladens von Webseiten möglicherweise nicht allzu viel bewirken.
Zum Beispiel haben wir gesehen, dass die Verwendung von UDP durch QUIC nicht bedeutet, dass es plötzlich mehr Bandbreite als TCP verwenden kann, noch bedeutet es, dass es Ihre Ressourcen schneller herunterladen kann. Das oft gepriesene 0-RTT-Feature ist wirklich eine Mikrooptimierung, die Ihnen einen Hin- und Rückweg erspart, bei dem Sie (im schlimmsten Fall) etwa 5 KB senden können.
Das Entfernen der HoL-Blockierung funktioniert nicht gut, wenn ein plötzlicher Paketverlust auftritt oder wenn Sie Render-Blocking-Ressourcen laden. Die Verbindungsmigration ist stark situativ und HTTP/3 hat keine wichtigen neuen Funktionen, die es schneller als HTTP/2 machen könnten.
Daher erwarten Sie vielleicht, dass ich Ihnen empfehle, HTTP/3 und QUIC einfach zu überspringen. Warum sich die Mühe machen, oder? Das werde ich aber definitiv nicht tun! Auch wenn diese neuen Protokolle Benutzern in schnellen (städtischen) Netzwerken möglicherweise nicht viel helfen, haben die neuen Funktionen sicherlich das Potenzial, für hochgradig mobile Benutzer und Personen in langsamen Netzwerken eine große Wirkung zu erzielen.
Selbst in westlichen Märkten wie meinem eigenen Belgien, wo wir im Allgemeinen über schnelle Geräte und Zugang zu Hochgeschwindigkeits-Mobilfunknetzen verfügen, können diese Situationen je nach Produkt 1 % bis sogar 10 % Ihrer Benutzerbasis betreffen. Ein Beispiel ist jemand in einem Zug, der verzweifelt versucht, eine wichtige Information auf Ihrer Website nachzuschlagen, aber 45 Sekunden warten muss, bis sie geladen ist. Ich weiß mit Sicherheit, dass ich in dieser Situation war und mir wünschte, jemand hätte QUIC eingesetzt, um mich da herauszuholen.
Es gibt jedoch andere Länder und Regionen, in denen es noch viel schlimmer ist. Dort sieht der durchschnittliche Benutzer möglicherweise viel mehr aus wie die langsamsten 10 % in Belgien, und die langsamsten 1 % sehen möglicherweise überhaupt keine geladene Seite. In vielen Teilen der Welt ist die Webleistung ein Problem der Zugänglichkeit und Inklusivität.
Aus diesem Grund sollten wir unsere Seiten niemals nur auf unserer eigenen Hardware testen (sondern auch einen Dienst wie Webpagetest verwenden) und Sie sollten auch unbedingt QUIC und HTTP/3 einsetzen . Besonders wenn Ihre Benutzer oft unterwegs sind oder wahrscheinlich keinen Zugang zu schnellen Mobilfunknetzen haben, können diese neuen Protokolle einen großen Unterschied machen, auch wenn Sie auf Ihrem verkabelten MacBook Pro nicht viel davon mitbekommen. Für weitere Details empfehle ich den Beitrag von Fastly zu diesem Thema.
Wenn Sie das nicht vollständig überzeugt, dann bedenken Sie, dass sich QUIC und HTTP/3 in den kommenden Jahren weiterentwickeln und schneller werden. Das Sammeln von ersten Erfahrungen mit den Protokollen wird sich später auszahlen, sodass Sie so schnell wie möglich von den Vorteilen der neuen Funktionen profitieren können. Darüber hinaus setzt QUIC im Hintergrund Best Practices für Sicherheit und Datenschutz durch, von denen alle Benutzer überall profitieren.
Endlich überzeugt? Fahren Sie dann mit Teil 3 der Serie fort, um zu lesen, wie Sie die neuen Protokolle in der Praxis anwenden können.
- Teil 1: Geschichte und Kernkonzepte von HTTP/3
Dieser Artikel richtet sich an Personen, die neu bei HTTP/3 und Protokollen im Allgemeinen sind, und behandelt hauptsächlich die Grundlagen. - Teil 2: HTTP/3-Leistungsmerkmale
Dieser ist mehr in die Tiefe und technisch. Leute, die bereits die Grundlagen kennen, können hier anfangen. - Teil 3: Praktische HTTP/3-Bereitstellungsoptionen
Dieser dritte Artikel der Reihe erläutert die Herausforderungen, die mit der Bereitstellung und dem Testen von HTTP/3 selbst verbunden sind. Es beschreibt auch, wie und ob Sie Ihre Webseiten und Ressourcen ändern sollten.