So erstellen Sie ein neuronales Netzwerk: Architektur, Parameter und Code
Veröffentlicht: 2021-02-12Neuronale Netze sind, wie der Name schon sagt, Schaltkreise von Neuronen. Es gibt verschiedene Arten von neuronalen Netzen. Biologische neuronale Netze bestehen aus echten biologischen Neuronen. Während künstliche neuronale Netze (KNN) ein System sind, das auf dem biologischen neuronalen Netz basiert, wie es im Gehirn vorhanden ist. Die geschätzte Anzahl von Neuronen im Gehirn beträgt etwa 100 Milliarden, die durch elektrochemische Signale kommunizieren.
Das ANN versucht, die in den biologischen Neuronen vorhandene Rechenkomplexität nachzubilden, aber es ist nicht so vergleichbar damit, und sie sind viel einfachere und nicht komplexe Versionen biologischer neuronaler Netzwerke. In diesem Artikel verstehen wir die Struktur eines KNN und lernen, wie man ein neuronales Netzwerk mit Python erstellt.
Inhaltsverzeichnis
Neuronale Netzwerkarchitektur
Das künstliche neuronale Netz besteht aus künstlichen Neuronen, die auch „Knoten“ genannt werden. Diese Knoten werden so miteinander verbunden, dass ein Netzwerk oder Mesh entsteht. Der Stärke dieser Verbindungen untereinander wird ein Wert zugeordnet. Dieser Wert liegt zwischen -1 bis 1.
Wenn der Wert der Verbindung hoch ist, zeigt dies eine starke Verbindung zwischen diesen Knoten an. Jeder Knoten hat eine charakteristische Funktion. Das Ändern dieser Funktion wird das Verhalten und die Komplexität des neuronalen Netzwerks ändern. Es gibt drei Arten von Neuronen in einem KNN, Eingangsknoten, verborgene Knoten und Ausgangsknoten, wie unten gezeigt:
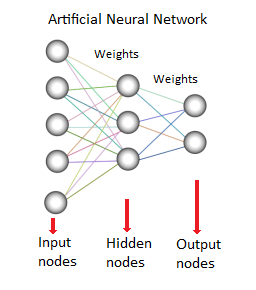
Quelle
Der Eingabeknoten ist für den Empfang der Informationen zuständig, die im Allgemeinen in Form von Zahlenwerten oder Ausdrücken vorliegen. Die Informationen werden als Aktivierungswerte dargestellt, wobei jeder Knoten eine Nummer erhält, je höher die Nummer, desto größer die Aktivierung.
Die Informationen werden weiter über das Netzwerk weitergegeben. Basierend auf den Knotenverbindungsgewichten und der Aktivierungsfunktion, die zu den bestimmten Neuronen bestimmter Schichten gehören, wird die Information von Neuron zu Neuron weitergegeben. Jeder der Knoten addiert die Aktivierungswerte beim Empfang, die Werte werden auf der Grundlage der Übertragungsfunktion modifiziert.
Die Informationen fließen durch das gesamte Netzwerk, durch verborgene Schichten, bis sie die Ausgangsknoten erreichen. Die Output Nodes sind sehr wichtig, da sie den Input sinnvoll nach außen reflektieren. Hier ist ein erstaunlicher Aspekt neuronaler Netze zu sehen, der zur Anpassung der Gewichte für jede Schicht und jeden Knoten führt.

Die Differenz zwischen dem vorhergesagten Wert und dem tatsächlichen Wert (Fehler) wird rückwärts propagiert. Das neuronale Netzwerk wird daher aus den gemachten Fehlern lernen und versuchen, die Gewichtungen auf der Grundlage des festgelegten Lernratenansatzes anzupassen.
Daher können wir durch Anpassen der Parameter wie einer Anzahl verborgener Schichten, einer Anzahl von Neuronen pro Schicht, einer Gewichtsaktualisierungsstrategie und einer Aktivierungsfunktion ein neuronales Netzwerk erstellen.
Definieren Sie die Parameter
Aktivierungsfunktion
Je nach Problemstellung stehen verschiedene Aktivierungsfunktionen zur Auswahl, die im Neuronalen Netz genutzt werden können.
Aktivierungsfunktionen sind mathematische Gleichungen, die jedes Neuron hat. Es bestimmt die Ausgabe eines neuronalen Netzwerks.
Diese Aktivierungsfunktion ist an jedes Neuron im Netzwerk angehängt und bestimmt, ob es aktiviert werden soll oder nicht, was darauf basiert, ob die Aktivierung dieses bestimmten Neurons hilft, relevante Vorhersagen auf der Ausgabeschicht abzuleiten. Unterschiedliche Schichten können mit unterschiedlichen Aktivierungsfunktionen verbunden sein. Aktivierungsfunktionen helfen auch dabei, die Ausgabe jedes Neurons auf einen Bereich zwischen 1 und 0 oder zwischen -1 und 1 zu normalisieren.
Moderne neuronale Netze verwenden eine wichtige Technik namens Backpropagation, um das Modell durch Anpassen der Gewichte zu trainieren, was eine erhöhte Rechenbelastung für die Aktivierungsfunktion und ihre Ableitungsfunktion bedeutet.
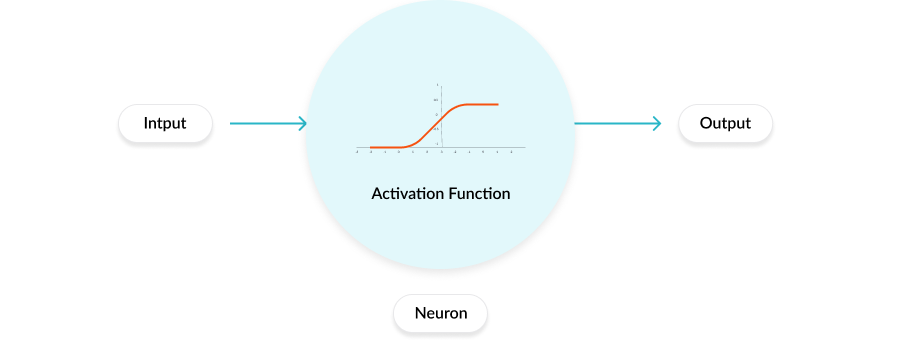
Arbeiten einer Aktivierungsfunktion
Fehlender Link
Es gibt 3 Arten von Aktivierungsfunktionen:
Binär- x<0 y=0 , x>0 y=1
Linear – x=y
Nicht linear – Verschiedene Typen: Sigmoid, TanH, Logistik, ReLU, Softmax usw.
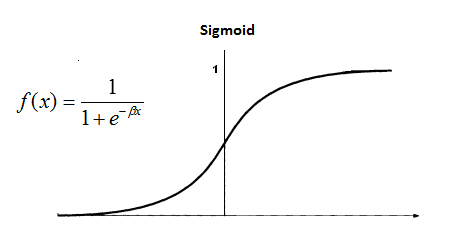
Quelle: Blog
Typ: ReLU
Fehlender Link
Algorithmus
Es gibt viele Arten von neuronalen Netzen, aber sie werden oft in Feed-Forward- und Feedback-Netze (Backpropagation) unterteilt.
1) Das Forward-Feed-Netzwerk ist ein sich nicht wiederholendes Netzwerk, das Eingänge, Ausgänge und verborgene Schichten enthält; da sich die Signale nur in eine Richtung bewegen können. Die Eingabedaten werden an die Verarbeitungsausrüstungsschicht übertragen, wo sie die Berechnungen durchführt. Jeder Verarbeitungsfaktor führt seine Berechnung basierend auf dem Gewicht der Eingabe durch. Neue Werte werden berechnet und dann speisen neue Eingabewerte die nächste Schicht.

Dieser Prozess wird fortgesetzt, bis er alle Schichten durchläuft und das Ergebnis bestimmt. Eine Grenzübertragungsfunktion wird manchmal verwendet, um die Neuronenausgabe in der Ausgabeschicht zu messen. Feed-Forward-Netzwerke sind bekannt als und umfassen (direkte und indirekte) Perceptron-Netzwerke. Feed-Forward-Netzwerke werden häufig für das Data Mining verwendet.
2) Das Feedback-Netzwerk (z. B. ein rekurrentes neuronales Netzwerk oder RNN) hat retrospektive Mechanismen, was bedeutet, dass sie Signale haben können, die sich unter Verwendung von Fallen/Schleifen in beide Richtungen bewegen. Jede mögliche Kommunikation zwischen Neuronen ist erlaubt.
Da die Schleifen in dieser Art von Netzwerk vorhanden sind, wird es zu einem nichtlinearen System, das sich ständig ändert, bis es einen Zustand der Stabilität erreicht. Rückkopplungsnetzwerke werden häufig für Erinnerungen verwendet, die mit Leistungsproblemen verbunden sind, wenn das Netzwerk nach einem guten Satz verbundener Objekte sucht.
Ausbildung
Der Feed-Forward-Pass bedeutet, dass eine Eingabe gegeben ist, und gewichtet, wie die Ausgabe berechnet wird. Nach Trainingsabschluss laufen wir nur noch den Vorwärtspass, um die Vorhersagen zu bilden.
Aber wir müssen unser Modell zuerst trainieren, um die Gewichte wirklich zu lernen, und deshalb funktioniert das Training wie folgt:
- Wählen Sie die Gewichte für alle Knoten zufällig aus und initialisieren Sie sie. Es gibt intelligente Initialisierungsmethoden, die in TensorFlow und Keras (Python) integriert sind.
- Führen Sie für jedes Trainingsbeispiel einen Vorwärtsdurchlauf mit den vorhandenen Gewichtungen durch und berechnen Sie die Ausgabe jedes Knotens von links nach rechts. Die endgültige Ausgabe ist der Wert des letzten Knotens.
- Vergleichen Sie die endgültige Ausgabe mit dem tatsächlichen Ziel innerhalb der Trainingsdaten und messen Sie den Fehler mithilfe einer Verlustfunktion.
- Führen Sie einen Rückwärtsdurchlauf von rechts nach links durch und propagieren Sie den im letzten Schritt berechneten Fehler mittels Backpropagation an jeden einzelnen Knoten.
- Berechnen Sie den Gewichtsbeitrag jedes Neurons zum Fehler und passen Sie die Gewichte der Verbindung entsprechend an, indem Sie den Gradientenabstieg verwenden. Propagieren Sie die Fehlergradienten zurück, die von der letzten Schicht reichen.
Python-Code für neuronale Netzwerke
Nachdem wir nun verstanden haben, wie ein neuronales Netzwerk theoretisch erstellt wird, implementieren wir dasselbe mit Python.
Neurales Netzwerk in Python
Wir werden die Keras-API mit Tensorflow- oder Theano-Backends verwenden, um unser neuronales Netzwerk zu erstellen.
Bibliotheken installieren
Theano
>>> pip install –upgrade –no-deps git+git://github.com/Theano/Theano.git
Tensorflow und Keras
>>> pip3 installiere Tensorflow
>>> pip install –Keras aktualisieren
Importieren Sie die Bibliotheken
Kera importieren
aus keras.models import Sequential
aus keras.layers import Dense
Initialisierung des künstlichen neuronalen Netzes
Modell = Sequentiell ()
Erstellt Input- und Hidden-Layer-
model.add(Dense(input_dim = 2, units = 10, activation='relu', kernel_initializer='uniform'))
Dieser Code fügt dem sequentiellen Netzwerk die Eingabeschicht und eine verborgene Schicht hinzu
Dense(): lässt uns ein dicht verbundenes neuronales Netzwerk erstellen
input_dim: Form oder Anzahl der Knoten in der Eingabeschicht
Einheiten: die Anzahl der Neuronen oder Knoten in der aktuellen Schicht (verborgene Schicht)
Aktivierung: die auf jeden Knoten angewendete Aktivierungsfunktion. „relu“ steht für Rectified Linear Unit
kernel_initializer: anfängliche Zufallsgewichte der Schicht
Zweite verborgene Schicht
model.add(Dense(units = 20, activation='relu', kernel_initializer='uniform'))
Der Code erstellt und fügt dem Modell eine weitere verborgene Schicht mit 20 Knoten und der Aktivierungsfunktion „korrigierte lineare“ hinzu. Je nach Problem und Komplexität können auf ähnliche Weise weitere Schichten hinzugefügt werden.
Ausgabeschicht
model.add(Dense(units = 1, activation='sigmoid', kernel_initializer='uniform'))
Eine einzelne Ausgabeschicht mit Sigmoid oder Softmax sind die häufig verwendeten Aktivierungsfunktionen für eine Ausgabeschicht.
ANN-Zusammenstellung:
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Das ANN wird mit einer Optimierungsfunktion und einer Verlustfunktion kompiliert, bevor es trainiert wird.
Optimizer: eine Optimierungsfunktion für das Netzwerk. Es gibt verschiedene Arten von Optimierern und Adam wird meistens verwendet.
Verlust: Wird zur Berechnung der Verluste und Fehler verwendet. Es gibt verschiedene Arten und die Wahl hängt von der Art des behandelten Problems ab.
Metriken: Die Metrik, die verwendet wird, um die Leistung des Modells zu messen.
Anpassung des Modells an die Trainingsdaten:
model.fit(X_train,Y_train,batch_size=64, Epochen=30)
Dieser Code erstellt das Modell
Fazit
Wir können jetzt ein künstliches neuronales Netzwerk (auf Python) von Grund auf neu erstellen, da wir die verschiedenen Parameter verstanden haben, die je nach vorliegendem Problem geändert werden können.
Wenn Sie mehr über Deep-Learning-Techniken und maschinelles Lernen erfahren möchten, sehen Sie sich das PG-Diplom in maschinellem Lernen und KI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben, IIIT-B-Alumni-Status, mehr als 5 praktische praktische Abschlussprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Lernen Sie ML-Kurse von den besten Universitäten der Welt. Erwerben Sie Master-, Executive PGP- oder Advanced Certificate-Programme, um Ihre Karriere zu beschleunigen.