
Wie implementiert man die Klassifizierung im maschinellen Lernen?
Veröffentlicht: 2021-03-12Die Anwendung des maschinellen Lernens in verschiedenen Bereichen hat in den letzten Jahren sprunghaft zugenommen und tut dies weiterhin. Eine der beliebtesten Aufgaben des Modells für maschinelles Lernen besteht darin, Objekte zu erkennen und sie in die ihnen zugewiesenen Klassen zu unterteilen.
Dies ist die Klassifizierungsmethode, die eine der beliebtesten Anwendungen des maschinellen Lernens ist. Die Klassifizierung wird verwendet, um eine große Datenmenge in eine Reihe diskreter Werte aufzuteilen, die binär wie 0/1, Ja/Nein oder mehrere Klassen wie Tiere, Autos, Vögel usw. sein können.
Im folgenden Artikel werden wir das Konzept der Klassifizierung beim maschinellen Lernen und die beteiligten Datentypen verstehen und einige der beliebtesten Klassifizierungsalgorithmen sehen, die beim maschinellen Lernen verwendet werden, um mehrere Daten zu klassifizieren.
Inhaltsverzeichnis
Was ist überwachtes Lernen?
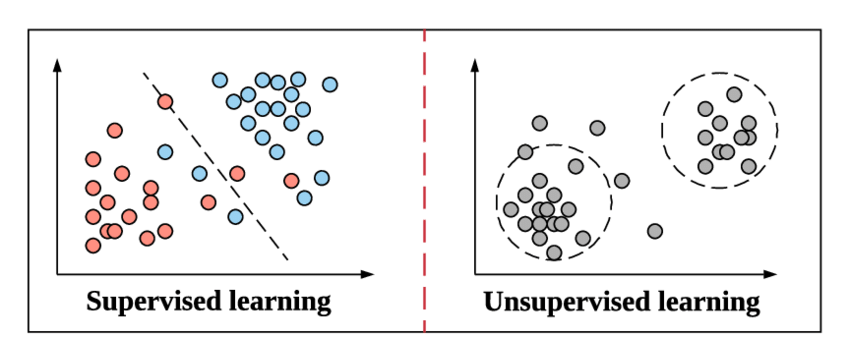
Während wir uns darauf vorbereiten, in das Konzept der Klassifizierung und ihrer Arten einzutauchen, sollten wir uns kurz damit befassen, was mit überwachtem Lernen gemeint ist und wie es sich von der anderen Methode des unüberwachten Lernens beim maschinellen Lernen unterscheidet.
Lassen Sie uns dies verstehen, indem wir ein einfaches Beispiel aus unserem Physikunterricht in der High School nehmen. Angenommen, es gibt ein einfaches Problem, das eine neue Methode betrifft. Wenn uns eine Frage gestellt wird, die wir mit der gleichen Methode lösen müssen, würden wir uns dann nicht alle auf ein Beispielproblem mit der gleichen Methode beziehen und versuchen, es zu lösen. Sobald wir mit dieser Methode vertraut sind, brauchen wir nicht noch einmal darauf zurückzukommen und mit der Lösung fortzufahren.
Quelle

Genauso funktioniert Supervised Learning beim Machine Learning. Es lernt am Beispiel. Um es noch einfacher zu machen, werden beim überwachten Lernen die gesamten Daten mit ihren entsprechenden Labels gefüttert, und daher vergleicht das Modell des maschinellen Lernens während des Trainingsprozesses seine Ausgabe für bestimmte Daten mit der tatsächlichen Ausgabe derselben Daten und versucht es Minimieren Sie den Fehler zwischen dem vorhergesagten und dem tatsächlichen Etikettenwert.
Die Klassifizierungsalgorithmen, die wir in diesem Artikel behandeln werden, folgen dieser Methode des überwachten Lernens – zum Beispiel Spam-Erkennung und Objekterkennung.
Unsupervised Learning ist eine Stufe darüber, bei der die Daten nicht mit ihren Labels gefüttert werden. Es liegt in der Verantwortung und Effizienz des Machine-Learning-Modells, Muster aus den Daten abzuleiten und die Ausgabe zu liefern. Clustering-Algorithmen folgen dieser unüberwachten Lernmethode.
Was ist Klassifizierung?
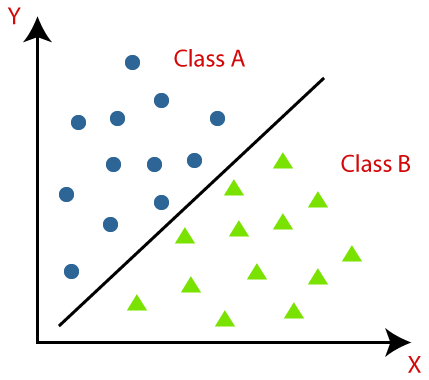
Klassifizierung ist definiert als Erkennen, Verstehen und Gruppieren der Objekte oder Daten in voreingestellte Klassen. Indem wir die Daten vor dem Trainingsprozess des Machine Learning-Modells kategorisieren, können wir verschiedene Klassifizierungsalgorithmen verwenden, um die Daten in mehrere Klassen zu klassifizieren. Anders als bei der Regression liegt ein Klassifizierungsproblem vor, wenn die Ausgabevariable eine Kategorie ist, z. B. „Ja“ oder „Nein“ oder „Krankheit“ oder „Keine Krankheit“.
Bei den meisten Machine-Learning-Problemen wird nach dem Laden des Datensatzes in das Programm vor dem Training der Datensatz in einen Trainingssatz und den Testsatz mit einem festen Verhältnis aufgeteilt (normalerweise 70 % Trainingssatz und 30 % Testsatz). Dieser Teilungsprozess ermöglicht es dem Modell, eine Backpropagation durchzuführen, bei der es versucht, seinen Fehler des vorhergesagten Werts gegenüber dem wahren Wert durch mehrere mathematische Annäherungen zu korrigieren.
Auf ähnliche Weise wird das Trainings-Dataset erstellt, bevor wir mit der Klassifizierung beginnen. Der Klassifizierungsalgorithmus wird darauf trainiert, während er bei jeder Iteration, die als Epoche bezeichnet wird, am Testdatensatz getestet wird.
Quelle
Eine der häufigsten Anwendungen von Klassifizierungsalgorithmen ist das Filtern von E-Mails danach, ob es sich um „Spam“ oder „Nicht-Spam“ handelt. Kurz gesagt, wir können die Klassifizierung im maschinellen Lernen als eine Form der „Mustererkennung“ definieren, bei der diese Algorithmen, die auf die Trainingsdaten angewendet werden, verwendet werden, um mehrere Muster aus den Daten zu extrahieren (z. B. ähnliche Wörter oder Zahlenfolgen, Stimmungen usw.). .).
Klassifizierung ist ein Prozess der Kategorisierung eines bestimmten Datensatzes in Klassen; Es kann sowohl mit strukturierten als auch mit unstrukturierten Daten durchgeführt werden. Es beginnt mit der Vorhersage der Klasse der gegebenen Datenpunkte. Diese Klassen werden auch als Ausgabevariablen, Zieletiketten usw. bezeichnet. Mehrere Algorithmen haben eingebaute mathematische Funktionen, um die Abbildungsfunktion von den Eingabedatenpunktvariablen auf die Ausgabezielklasse anzunähern. Das Hauptziel der Klassifizierung besteht darin, zu identifizieren, in welche Klasse/Kategorie die neuen Daten fallen werden.
Arten von Klassifizierungsalgorithmen im maschinellen Lernen
Abhängig von der Art der Daten, auf die die Klassifizierungsalgorithmen angewendet werden, gibt es zwei große Kategorien von Algorithmen, das lineare und das nichtlineare Modell.
Lineare Modelle
- Logistische Regression
- Support-Vektor-Maschinen (SVM)
Nichtlineare Modelle
- K-Klassifizierung der nächsten Nachbarn (KNN).
- Kernel-SVM
- Naive Bayes-Klassifikation
- Entscheidungsbaumklassifizierung
- Random Forest-Klassifizierung
In diesem Artikel gehen wir kurz auf das Konzept hinter jedem der oben genannten Algorithmen ein.
Evaluation eines Klassifikationsmodells im maschinellen Lernen
Bevor wir uns mit den oben erwähnten Konzepten dieser Algorithmen befassen, müssen wir verstehen, wie wir unser Machine-Learning-Modell, das auf diesen Algorithmen aufbaut, bewerten können. Es ist wichtig, unser Modell sowohl auf der Trainingsmenge als auch auf der Testmenge auf Genauigkeit zu evaluieren.
Entropieübergreifender Verlust oder Protokollverlust
Dies ist die erste Art von Verlustfunktion, die wir zur Bewertung der Leistung eines Klassifikators verwenden, dessen Ausgabe zwischen 0 und 1 liegt. Dies wird hauptsächlich für binäre Klassifizierungsmodelle verwendet. Die Log-Loss-Formel ist gegeben durch:
Protokollverlust = -((1 – y) * log(1 – yhat) + y * log(yhat))
Wobei dies der vorhergesagte Wert und y der tatsächliche Wert ist.
Verwirrung Matrix
Eine Konfusionsmatrix ist eine NXN-Matrix, wobei N die Anzahl der vorhergesagten Klassen ist. Die Konfusionsmatrix liefert uns eine Matrix/Tabelle als Ausgabe und beschreibt die Leistung des Modells. Es besteht aus dem Vorhersageergebnis in Form einer Matrix, aus der wir mehrere Leistungsmetriken zur Bewertung des Klassifizierungsmodells ableiten können. Es ist von der Form,
| Eigentlich positiv | Tatsächliches Negativ | |
| Positiv vorhergesagt | Richtig positiv | Falsch positiv |
| Vorhergesagtes Negativ | Falsch negativ | Wahres Negativ |
Einige der Leistungsmetriken, die aus der obigen Tabelle abgeleitet werden können, sind unten angegeben.
1.Genauigkeit – der Anteil an der Gesamtzahl richtiger Vorhersagen.
2. Positiver Vorhersagewert oder Präzision – der Anteil positiver Fälle, die korrekt identifiziert wurden.
3. Negativer Vorhersagewert – der Anteil der korrekt identifizierten negativen Fälle.
4. Sensitivität oder Rückruf – der Anteil tatsächlich positiver Fälle, die korrekt identifiziert werden.
5. Spezifität – der Anteil tatsächlich negativer Fälle, die korrekt identifiziert werden.
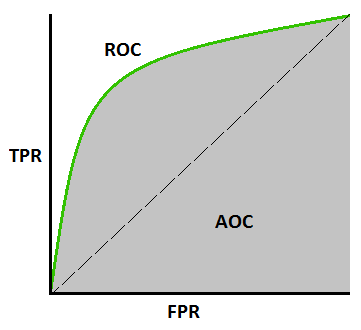
AUC-ROC-Kurve –
Dies ist eine weitere wichtige Kurvenmetrik, die jedes Machine Learning-Modell bewertet. ROC-Kurve steht für Receiver Operating Characteristics Curve und AUC steht für Area Under the Curve. Die ROC-Kurve wird mit TPR und FPR dargestellt, wobei TPR (Wahr-Positiv-Rate) auf der Y-Achse und FPR (Falsch-Positiv-Rate) auf der X-Achse ist. Es zeigt die Leistung des Klassifizierungsmodells bei verschiedenen Schwellenwerten.
Quelle
1. Logistische Regression
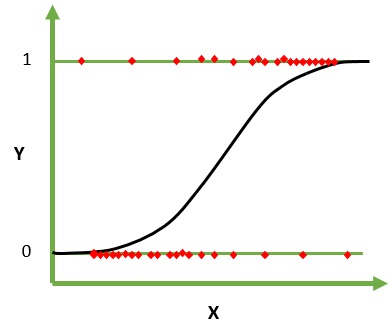
Die logistische Regression ist ein maschineller Lernalgorithmus für die Klassifizierung. In diesem Algorithmus werden die Wahrscheinlichkeiten, die die möglichen Ergebnisse eines einzelnen Versuchs beschreiben, unter Verwendung einer logistischen Funktion modelliert. Es wird davon ausgegangen, dass die Eingabevariablen numerisch sind und eine Gaußsche (Glockenkurve) Verteilung haben.
Die logistische Funktion, auch Sigmoidfunktion genannt, wurde ursprünglich von Statistikern verwendet, um das Bevölkerungswachstum in der Ökologie zu beschreiben. Die Sigmoidfunktion ist eine mathematische Funktion, die verwendet wird, um die vorhergesagten Werte auf Wahrscheinlichkeiten abzubilden. Die logistische Regression hat eine S-förmige Kurve und kann Werte zwischen 0 und 1 annehmen, aber nie genau an diesen Grenzen.

Quelle
Die logistische Regression wird hauptsächlich verwendet, um ein binäres Ergebnis wie Ja/Nein und Bestanden/Nicht bestanden vorherzusagen. Die unabhängigen Variablen können kategorial oder numerisch sein, aber die abhängige Variable ist immer kategorisch. Die Formel für die logistische Regression ist gegeben durch:
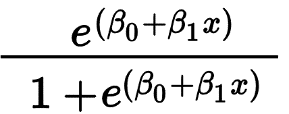
Wobei e die S-förmige Kurve darstellt, die Werte zwischen 0 und 1 hat.
2. Unterstützung von Vektormaschinen
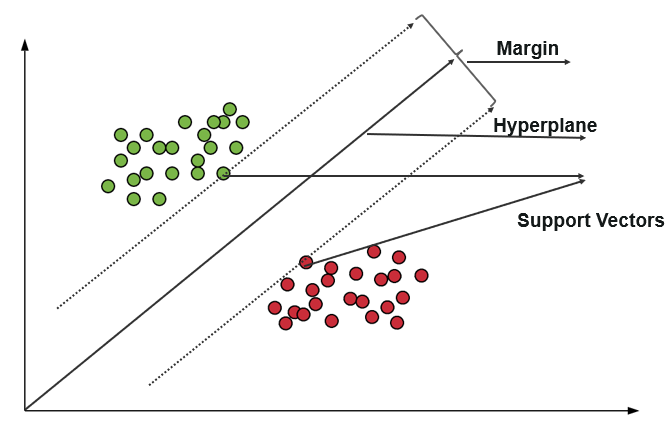
Eine Support-Vektor-Maschine (SVM) verwendet Algorithmen, um Daten innerhalb von Polaritätsgraden zu trainieren und zu klassifizieren und sie auf einen Grad zu bringen, der über die X/Y-Vorhersage hinausgeht. In SVM wird die Linie, die zum Trennen der Klassen verwendet wird, als Hyperebene bezeichnet. Die Datenpunkte auf beiden Seiten der Hyperebene, die der Hyperebene am nächsten liegen, werden als Stützvektoren bezeichnet, die zum Zeichnen der Grenzlinie verwendet werden.
Diese Support-Vektor-Maschine in der Klassifizierung stellt die Trainingsdaten als Datenpunkte in einem Raum dar, in dem viele Kategorien in die Kategorien der Hyperebene unterteilt sind. Wenn ein neuer Punkt eintritt, wird er klassifiziert, indem vorhergesagt wird, in welche Kategorie er fällt und zu einem bestimmten Raum gehört.
Quelle
Das Hauptziel der Support-Vektor-Maschine ist es, den Spielraum zwischen den beiden Support-Vektoren zu maximieren.
Nehmen Sie online am ML-Kurs von den besten Universitäten der Welt teil – Masters, Executive Post Graduate Programs und Advanced Certificate Program in ML & AI, um Ihre Karriere zu beschleunigen.
3. K-Klassifizierung der nächsten Nachbarn (KNN).
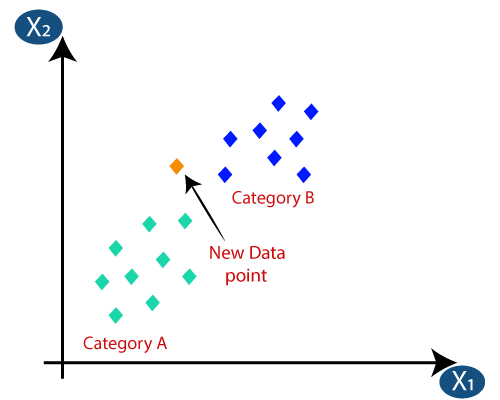
Die KNN-Klassifizierung ist einer der einfachsten Klassifizierungsalgorithmen, wird jedoch aufgrund ihrer hohen Effizienz und Benutzerfreundlichkeit häufig eingesetzt. Bei diesem Verfahren wird zunächst der gesamte Datensatz in der Maschine gespeichert. Dann wird ein Wert – k gewählt, der die Anzahl der Nachbarn darstellt. Wenn dem Datensatz ein neuer Datenpunkt hinzugefügt wird, nimmt er auf diese Weise das Mehrheitsvotum des Klassenetiketts der k nächsten Nachbarn für diesen neuen Datenpunkt. Mit diesem Votum wird der neue Datenpunkt zu der bestimmten Klasse mit dem höchsten Votum hinzugefügt.
Quelle
4. Kernel-SVM
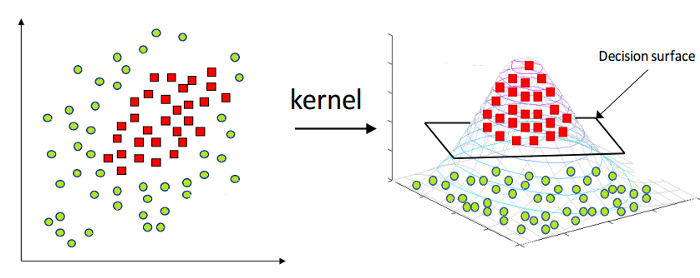
Wie oben erwähnt, kann die Linear Support Vector Machine nur auf lineare Daten in der Natur angewendet werden. Allerdings sind nicht alle Daten dieser Welt linear trennbar. Daher müssen wir eine Support Vector Machine entwickeln, um Daten zu berücksichtigen, die auch nichtlinear trennbar sind. Hier kommt der Kernel-Trick, auch bekannt als Kernel Support Vector Machine oder Kernel SVM.
In Kernel SVM wählen wir einen Kernel wie den RBF oder den Gaussian Kernel aus. Alle Datenpunkte werden auf eine höhere Dimension abgebildet, wo sie linear trennbar werden. Auf diese Weise können wir eine Entscheidungsgrenze zwischen den verschiedenen Klassen des Datensatzes erstellen.
Quelle
Daher können wir auf diese Weise unter Verwendung der grundlegenden Konzepte von Support Vector Machines eine Kernel-SVM für nicht-lineare entwerfen.
5. Naive-Bayes-Klassifizierung
Die Naive-Bayes-Klassifikation hat ihre Wurzeln im Bayes-Theorem, das davon ausgeht, dass alle unabhängigen Variablen (Merkmale) des Datensatzes unabhängig sind. Sie haben die gleiche Bedeutung bei der Vorhersage des Ergebnisses. Diese Annahme des Satzes von Bayes gibt den Namen „naiv“. Es wird für verschiedene Aufgaben verwendet, wie z. B. Spam-Filterung und andere Bereiche der Textklassifizierung. Naive Bayes berechnet die Möglichkeit, ob ein Datenpunkt in eine bestimmte Kategorie gehört oder nicht.
Die Formel der Naive-Bayes-Klassifikation ist gegeben durch:
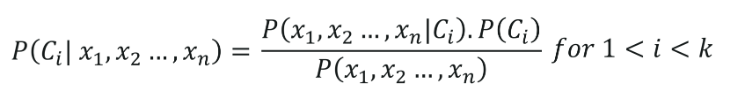
6. Entscheidungsbaumklassifizierung
Ein Entscheidungsbaum ist ein überwachter Lernalgorithmus, der sich perfekt für Klassifizierungsprobleme eignet, da er Klassen auf einer genauen Ebene ordnen kann. Es arbeitet in Form eines Flussdiagramms, in dem es die Datenpunkte auf jeder Ebene trennt. Die endgültige Struktur sieht aus wie ein Baum mit Knoten und Blättern.

Quelle
Ein Entscheidungsknoten hat zwei oder mehr Zweige, und ein Blatt repräsentiert eine Klassifikation oder Entscheidung. Im obigen Beispiel eines Entscheidungsbaums wird durch das Stellen mehrerer Fragen ein Flussdiagramm erstellt, das uns hilft, das einfache Problem der Vorhersage zu lösen, ob wir auf den Markt gehen oder nicht.
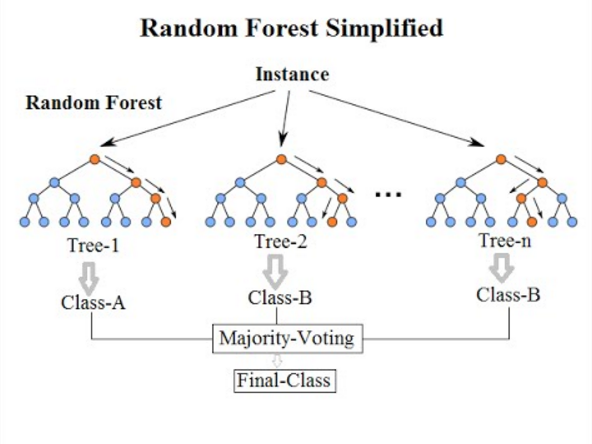
7. Random Forest-Klassifizierung
Kommen wir zum letzten Klassifikationsalgorithmus dieser Liste: The Random Forest ist nur eine Erweiterung des Entscheidungsbaumalgorithmus. Ein Random Forest ist eine Ensemble-Lernmethode mit mehreren Entscheidungsbäumen. Es funktioniert auf die gleiche Weise wie Entscheidungsbäume.
Quelle
Der Random-Forest-Algorithmus ist eine Weiterentwicklung des bestehenden Entscheidungsbaum-Algorithmus, der unter dem großen Problem des „Overfitting“ leidet . Er gilt auch als schneller und genauer im Vergleich zum Entscheidungsbaumalgorithmus.
Lesen Sie auch: Ideen und Themen für Machine Learning-Projekte
Fazit
Daher haben wir in diesem Artikel über Methoden des maschinellen Lernens für die Klassifizierung die Grundlagen der Klassifizierung und des überwachten Lernens, Typen und Bewertungsmetriken von Klassifizierungsmodellen und schließlich eine Zusammenfassung aller am häufigsten verwendeten Klassifizierungsmodelle des maschinellen Lernens verstanden.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das Executive PG-Programm von IIIT-B & upGrad für maschinelles Lernen und KI an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben, IIIT, bietet -B Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Q1. Welche Algorithmen werden beim maschinellen Lernen am häufigsten verwendet?
Maschinelles Lernen verwendet viele verschiedene Algorithmen, die grob in drei Hauptarten eingeteilt werden können – Algorithmen für überwachtes Lernen, Algorithmen für unüberwachtes Lernen und Algorithmen für bestärkendes Lernen. Um nun einige der am häufigsten verwendeten Algorithmen einzugrenzen und zu nennen, müssen diejenigen erwähnt werden, die lineare Regression, logistische Regression, SVM, Entscheidungsbäume, Random-Forest-Algorithmus, kNN, Naive-Bayes-Theorie, K-Means, Dimensionsreduktion, und Gradientenverstärkungsalgorithmen. XGBoost-, GBM-, LightGBM- und CatBoost-Algorithmen verdienen eine besondere Erwähnung bei Gradienten-Boosting-Algorithmen. Diese Algorithmen können angewendet werden, um fast jede Art von Datenproblem zu lösen.
Q2. Was ist Klassifizierung und Regression beim maschinellen Lernen?
Sowohl Klassifizierungs- als auch Regressionsalgorithmen werden beim maschinellen Lernen häufig verwendet. Es gibt jedoch viele Unterschiede zwischen ihnen, die letztendlich ihre Verwendung oder ihren Zweck bestimmen. Der Hauptunterschied besteht darin, dass Klassifizierungsalgorithmen verwendet werden, um diskrete Werte wie männlich-weiblich oder richtig-falsch zu klassifizieren oder vorherzusagen, während Regressionsalgorithmen verwendet werden, um nicht-diskrete, kontinuierliche Werte wie Gehalt, Alter, Preis usw. zu prognostizieren. Entscheidungsbäume, Random Forest, Kernel SVM und logistische Regression sind einige der gebräuchlichsten Klassifizierungsalgorithmen, während einfache und multiple lineare Regression, Support Vector Regression, Polynomial Regression und Decision Tree Regression einige der beliebtesten Regressionsalgorithmen sind, die beim maschinellen Lernen verwendet werden.
Q3. Was sind die Voraussetzungen für maschinelles Lernen?
Um mit maschinellem Lernen zu beginnen, müssen Sie kein erfahrener Mathematiker oder Programmierexperte sein. Angesichts der Weite des Feldes kann es jedoch einschüchternd wirken, wenn Sie gerade erst mit Ihrer Reise zum maschinellen Lernen beginnen. In solchen Fällen kann Ihnen die Kenntnis der Voraussetzungen zu einem reibungslosen Start verhelfen. Die Voraussetzungen sind im Wesentlichen die Kernkompetenzen, die Sie erwerben müssen, um die Konzepte des maschinellen Lernens zu verstehen. Stellen Sie also in erster Linie sicher, dass Sie lernen, wie man mit Python programmiert. Als nächstes wird ein grundlegendes Verständnis von Statistik und Mathematik, insbesondere von linearer Algebra und multivariablen Kalkül, ein zusätzlicher Vorteil sein.