
So wählen Sie eine Feature-Auswahlmethode für maschinelles Lernen aus
Veröffentlicht: 2021-06-22Inhaltsverzeichnis
Einführung in die Funktionsauswahl
Viele Funktionen werden von einem maschinellen Lernmodell verwendet, von denen nur wenige wichtig sind. Es gibt eine verringerte Genauigkeit des Modells, wenn unnötige Merkmale verwendet werden, um ein Datenmodell zu trainieren. Darüber hinaus gibt es eine Zunahme der Komplexität des Modells und eine Abnahme der Verallgemeinerungsfähigkeit, was zu einem voreingenommenen Modell führt. Das Sprichwort „weniger ist manchmal besser“ passt gut zum Konzept des maschinellen Lernens. Viele Benutzer sind mit dem Problem konfrontiert, dass sie es schwierig finden, den Satz relevanter Merkmale aus ihren Daten zu identifizieren und alle irrelevanten Sätze von Merkmalen zu ignorieren. Die weniger wichtigen Merkmale werden so bezeichnet, dass sie nicht zur Zielvariablen beitragen.
Daher ist einer der wichtigsten Prozesse die Merkmalsauswahl beim maschinellen Lernen . Ziel ist es, das bestmögliche Set an Features für die Entwicklung eines Machine-Learning-Modells auszuwählen. Die Funktionsauswahl hat einen großen Einfluss auf die Leistung des Modells. Zusammen mit der Datenbereinigung sollte die Funktionsauswahl der erste Schritt in einem Modelldesign sein.
Die Funktionsauswahl beim maschinellen Lernen kann zusammengefasst werden als
- Automatische oder manuelle Auswahl der Merkmale, die am meisten zur Vorhersagevariablen oder zum Ergebnis beitragen.
- Das Vorhandensein irrelevanter Merkmale kann zu einer verringerten Genauigkeit des Modells führen, da es von irrelevanten Merkmalen lernt.
Vorteile der Merkmalsauswahl
- Reduziert die Überanpassung von Daten: Eine geringere Anzahl von Daten führt zu geringerer Redundanz. Daher gibt es weniger Möglichkeiten, Entscheidungen über Lärm zu treffen.
- Verbessert die Genauigkeit des Modells: Mit einer geringeren Wahrscheinlichkeit irreführender Daten wird die Genauigkeit des Modells erhöht.
- Die Trainingszeit wird reduziert: Das Entfernen irrelevanter Merkmale reduziert die Komplexität des Algorithmus, da nur weniger Datenpunkte vorhanden sind. Daher trainieren die Algorithmen schneller.
- Die Komplexität des Modells wird durch eine bessere Interpretation der Daten reduziert.
Überwachte und nicht überwachte Methoden der Merkmalsauswahl
Das Hauptziel der Merkmalsauswahlalgorithmen besteht darin, eine Menge der besten Merkmale für die Entwicklung des Modells auszuwählen. Merkmalsauswahlmethoden beim maschinellen Lernen können in überwachte und nicht überwachte Methoden eingeteilt werden.
- Überwachte Methode: Die überwachte Methode wird für die Auswahl von Merkmalen aus gekennzeichneten Daten verwendet und auch für die Klassifizierung der relevanten Merkmale verwendet. Daher wird die Effizienz der aufgebauten Modelle erhöht.
- Unüberwachte Methode : Diese Methode der Merkmalsauswahl wird für die unbeschrifteten Daten verwendet.
Liste der Methoden unter überwachten Methoden
Überwachte Methoden der Merkmalsauswahl beim maschinellen Lernen können eingeteilt werden in

1. Wrapper-Methoden
Diese Art von Merkmalsauswahlalgorithmus bewertet den Leistungsfähigkeitsprozess der Merkmale basierend auf den Ergebnissen des Algorithmus. Auch als Greedy-Algorithmus bekannt, trainiert er den Algorithmus iterativ mit einer Teilmenge von Merkmalen. Stoppkriterien werden normalerweise von der Person definiert, die den Algorithmus trainiert. Das Hinzufügen und Entfernen von Merkmalen im Modell erfolgt basierend auf dem vorherigen Training des Modells. Bei dieser Suchstrategie kann jede Art von Lernalgorithmus angewendet werden. Die Modelle sind im Vergleich zu den Filtermethoden genauer.
Bei Wrapper-Methoden verwendete Techniken sind:
- Vorwärtsauswahl: Der Vorwärtsauswahlprozess ist ein iterativer Prozess, bei dem nach jeder Iteration neue Funktionen hinzugefügt werden, die das Modell verbessern. Es beginnt mit einem leeren Satz von Funktionen. Die Iteration wird fortgesetzt und angehalten, bis ein Feature hinzugefügt wird, das die Leistung des Modells nicht weiter verbessert.
- Rückwärtsselektion/Eliminierung: Der Prozess ist ein iterativer Prozess, der mit allen Merkmalen beginnt. Nach jeder Iteration werden die Merkmale mit der geringsten Bedeutung aus der Menge der Anfangsmerkmale entfernt. Das Abbruchkriterium für die Iteration ist, wenn sich die Leistung des Modells durch das Entfernen des Features nicht weiter verbessert. Diese Algorithmen sind im Paket mlxtend implementiert.
- Bidirektionale Eliminierung : Beide Methoden der Vorwärtsauswahl und der Rückwärts-Eliminierungstechnik werden gleichzeitig in der bidirektionalen Eliminierungsmethode angewendet , um eine einzigartige Lösung zu erreichen.
- Erschöpfende Merkmalsauswahl: Es wird auch als Brute-Force-Ansatz zur Bewertung von Teilmengen von Merkmalen bezeichnet. Es wird eine Menge möglicher Teilmengen erstellt und für jede Teilmenge ein Lernalgorithmus erstellt. Es wird die Teilmenge ausgewählt, deren Modell die beste Leistung liefert.
- Recursive Feature Elimination (RFE): Das Verfahren wird als gierig bezeichnet, da es Features auswählt, indem es rekursiv den immer kleineren Satz von Features berücksichtigt. Ein Anfangssatz von Merkmalen wird zum Trainieren des Schätzers verwendet, und ihre Wichtigkeit wird unter Verwendung von feature_importance_attribute erhalten. Anschließend werden die am wenigsten wichtigen Merkmale entfernt, wobei nur die erforderliche Anzahl von Merkmalen zurückbleibt. Die Algorithmen sind im Paket scikit-learn implementiert.
Abbildung 4: Ein Codebeispiel, das die rekursive Feature-Eliminierungstechnik zeigt
2. Eingebettete Methoden
Die eingebetteten Merkmalsauswahlverfahren beim maschinellen Lernen haben einen gewissen Vorteil gegenüber den Filter- und Wrapper-Verfahren, indem sie die Merkmalsinteraktion einbeziehen und auch einen angemessenen Rechenaufwand aufrechterhalten. Techniken, die in eingebetteten Methoden verwendet werden, sind:
- Regularisierung: Eine Überanpassung von Daten wird durch das Modell vermieden, indem den Parametern des Modells eine Strafe hinzugefügt wird. Koeffizienten werden mit der Strafe hinzugefügt, was dazu führt, dass einige Koeffizienten null sind. Daher werden diejenigen Merkmale, die einen Koeffizienten von Null haben, aus dem Satz von Merkmalen entfernt. Der Ansatz der Merkmalsauswahl verwendet Lasso (L1-Regularisierung) und elastische Netze (L1- und L2-Regularisierung).
- SMLR (Sparse Multinomial Logistic Regression): Der Algorithmus implementiert eine spärliche Regularisierung durch ARD prior (Automatische Relevanzbestimmung) für die klassische multinationale logistische Regression. Diese Regularisierung schätzt die Wichtigkeit jedes Merkmals und beschneidet die Dimensionen, die für die Vorhersage nicht nützlich sind. Die Implementierung des Algorithmus erfolgt in SMLR.
- ARD (Automatic Relevance Determination Regression): Der Algorithmus verschiebt die Koeffizientengewichte in Richtung Null und basiert auf einer Bayesian Ridge Regression. Der Algorithmus kann in scikit-learn implementiert werden.
- Random Forest Importance: Dieser Merkmalsauswahlalgorithmus ist eine Aggregation einer bestimmten Anzahl von Bäumen. Baumbasierte Strategien in diesem Algorithmus rangieren auf der Grundlage der Erhöhung der Verunreinigung eines Knotens oder der Verringerung der Verunreinigung (Gini-Verunreinigung). Das Ende der Bäume besteht aus den Knoten mit der geringsten Verunreinigungsabnahme und der Anfang der Bäume besteht aus den Knoten mit der größten Verunreinigungsabnahme. Daher können wichtige Merkmale durch Beschneiden des Baums unterhalb eines bestimmten Knotens ausgewählt werden.
3. Filtermethoden
Die Methoden werden während der Vorverarbeitungsschritte angewendet. Die Verfahren sind ziemlich schnell und kostengünstig und funktionieren am besten beim Entfernen von duplizierten, korrelierten und redundanten Merkmalen. Anstatt überwachte Lernmethoden anzuwenden, wird die Wichtigkeit von Merkmalen anhand ihrer inhärenten Eigenschaften bewertet. Der Rechenaufwand des Algorithmus ist im Vergleich zu den Wrapper-Methoden der Merkmalsauswahl geringer. Wenn jedoch nicht genügend Daten vorhanden sind, um die statistische Korrelation zwischen den Merkmalen abzuleiten, können die Ergebnisse schlechter sein als bei den Wrapper-Methoden. Daher werden die Algorithmen über hochdimensionalen Daten verwendet, was zu einem höheren Rechenaufwand führen würde, wenn Wrapper-Methoden angewendet werden sollen.

Techniken, die in den Filtermethoden verwendet werden, sind :
- Informationsgewinn : Der Informationsgewinn bezieht sich darauf, wie viele Informationen aus den Merkmalen gewonnen werden, um den Zielwert zu identifizieren. Es misst dann die Abnahme der Entropiewerte. Der Informationsgewinn jedes Attributs wird unter Berücksichtigung der Zielwerte für die Merkmalsauswahl berechnet.
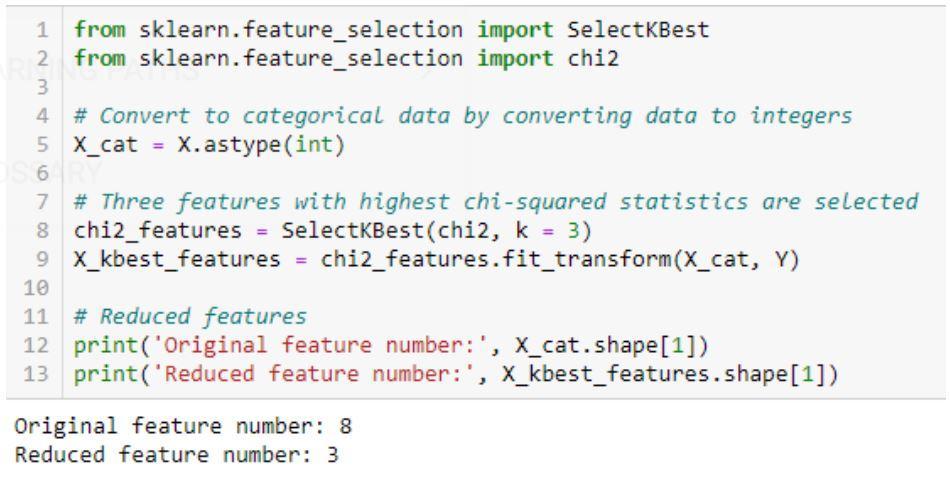
- Chi-Quadrat-Test : Die Chi-Quadrat-Methode (X 2 ) wird im Allgemeinen verwendet, um die Beziehung zwischen zwei kategorialen Variablen zu testen. Der Test wird verwendet, um festzustellen, ob es einen signifikanten Unterschied zwischen den beobachteten Werten von verschiedenen Attributen des Datensatzes und seinem erwarteten Wert gibt. Eine Nullhypothese besagt, dass zwischen zwei Variablen kein Zusammenhang besteht.
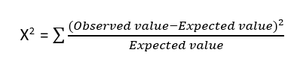
Quelle
Die Formel für den Chi-Quadrat-Test
Implementierung des Chi-Quadrat-Algorithmus: sklearn, scipy
Ein Codebeispiel für den Chi-Quadrat-Test
Quelle
- CFS (korrelationsbasierte Merkmalsauswahl): Die Methode folgt „ Implementierung von CFS (Correlation-based feature selection): scikit-feature
Nehmen Sie online an den KI- und ML-Kursen der weltbesten Universitäten teil – Master, Executive Post Graduate Programs und Advanced Certificate Program in ML & KI, um Ihre Karriere zu beschleunigen.
- FCBF (Schneller korrelationsbasierter Filter): Im Vergleich zu den oben genannten Verfahren von Relief und CFS ist das FCBF-Verfahren schneller und effizienter. Zunächst wird die Berechnung der symmetrischen Unsicherheit für alle Merkmale durchgeführt. Anhand dieser Kriterien werden die Merkmale dann aussortiert und redundante Merkmale entfernt.
Symmetrische Unsicherheit = der Informationsgewinn von x | y dividiert durch die Summe ihrer Entropien. Implementierung von FCBF: skfeature
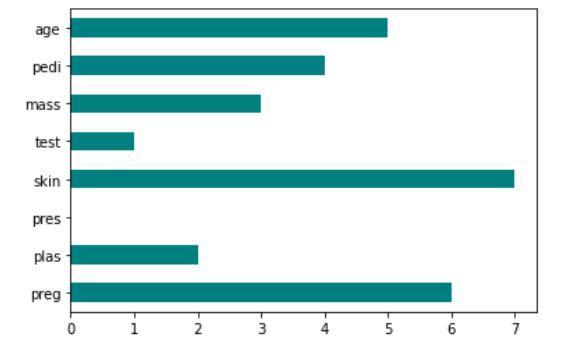
- Fischer-Score: Das Fischer-Verhältnis (FIR) ist definiert als der Abstand zwischen den Stichprobenmittelwerten für jede Klasse pro Merkmal dividiert durch ihre Varianzen. Jedes Merkmal wird unabhängig gemäß seiner Punktzahl nach dem Fisher-Kriterium ausgewählt. Dies führt zu einem suboptimalen Funktionsumfang. Ein größerer Fisher-Score zeigt ein besser ausgewähltes Merkmal an.
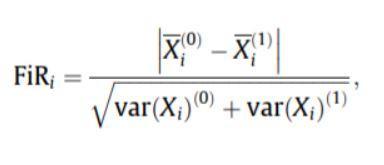
Quelle
Die Formel für den Fischer-Score
Implementierung von Fisher-Score: scikit-Funktion
Die Ausgabe des Codes zeigt die Fisher-Score-Technik
Quelle
Korrelationskoeffizient nach Pearson: Es ist ein Maß zur Quantifizierung der Assoziation zwischen den beiden kontinuierlichen Variablen. Die Werte des Korrelationskoeffizienten reichen von -1 bis 1, was die Richtung der Beziehung zwischen den Variablen definiert.
- Varianzschwellenwert : Die Features, deren Varianz den spezifischen Schwellenwert nicht erreicht, werden entfernt. Merkmale mit Nullvarianz werden durch dieses Verfahren entfernt. Die berücksichtigte Annahme ist, dass Merkmale mit höherer Varianz wahrscheinlich mehr Informationen enthalten.
Abbildung 15: Ein Codebeispiel, das die Implementierung des Varianzschwellenwerts zeigt
- Mittlere absolute Differenz (MAD): Die Methode berechnet den absoluten Mittelwert
Differenz zum Mittelwert.
Ein Beispiel für Code und seine Ausgabe, die die Implementierung von Mean Absolute Difference (MAD) zeigen
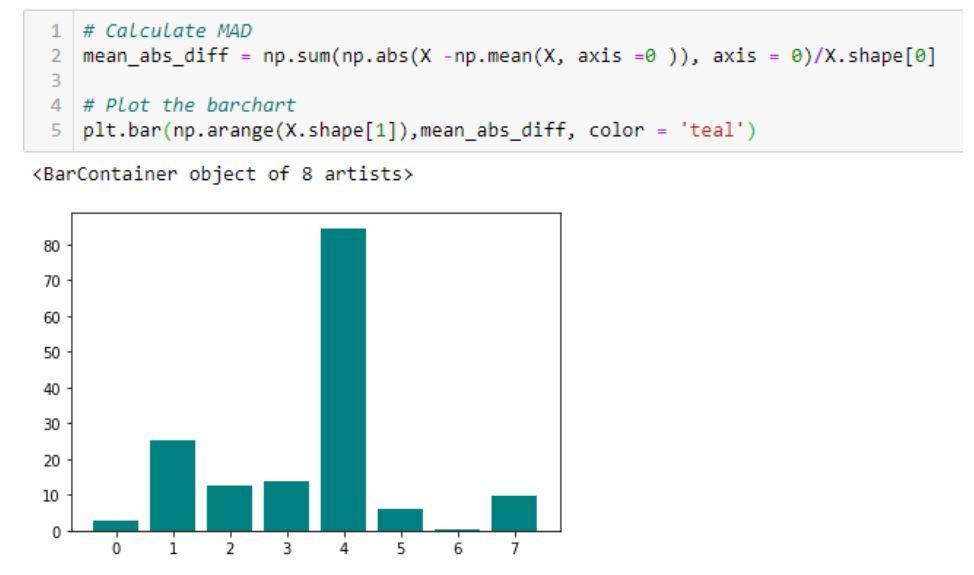
Quelle
- Streuungsverhältnis: Das Streuungsverhältnis ist definiert als das Verhältnis des arithmetischen Mittels (AM) zum geometrischen Mittel (GM) für ein bestimmtes Merkmal. Sein Wert reicht von +1 bis ∞ als AM ≥ GM für ein bestimmtes Merkmal.
Ein höheres Dispersionsverhältnis impliziert einen höheren Wert von Ri und daher ein relevanteres Merkmal. Wenn dagegen Ri nahe bei 1 liegt, zeigt dies ein Merkmal mit geringer Relevanz an.
- Gegenseitige Abhängigkeit: Die Methode wird verwendet, um die gegenseitige Abhängigkeit zwischen zwei Variablen zu messen. Von einer Variablen erhaltene Informationen können verwendet werden, um Informationen für die andere Variable zu erhalten.
- Laplace-Score: Daten derselben Klasse liegen oft nahe beieinander. Die Wichtigkeit eines Merkmals kann anhand seiner Fähigkeit zur Lokalitätserhaltung bewertet werden. Der Laplace-Score für jedes Merkmal wird berechnet. Die kleinsten Werte bestimmen wichtige Dimensionen. Implementierung des Laplace-Scores: Scikit-Funktion.
Fazit
Die Merkmalsauswahl im maschinellen Lernprozess kann als einer der wichtigen Schritte zur Entwicklung eines maschinellen Lernmodells zusammengefasst werden. Der Prozess des Merkmalsauswahlalgorithmus führt zur Reduzierung der Dimensionalität der Daten, wobei Merkmale entfernt werden, die für das betrachtete Modell nicht relevant oder wichtig sind. Relevante Funktionen könnten die Trainingszeit der Modelle beschleunigen, was zu einer hohen Leistung führt.
Wenn Sie mehr über maschinelles Lernen erfahren möchten, sehen Sie sich das Executive PG-Programm von IIIT-B & upGrad für maschinelles Lernen und KI an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben, IIIT, bietet -B Alumni-Status, mehr als 5 praktische Schlusssteinprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Wie unterscheidet sich die Filtermethode von der Wrapper-Methode?
Die Wrapper-Methode hilft zu messen, wie hilfreich die Funktionen basierend auf der Leistung des Klassifikators sind. Die Filtermethode hingegen bewertet die intrinsischen Qualitäten der Merkmale mithilfe univariater Statistiken und nicht anhand der Kreuzvalidierungsleistung, was impliziert, dass sie die Relevanz der Merkmale beurteilen. Infolgedessen ist die Wrapper-Methode effektiver, da sie die Klassifikatorleistung optimiert. Aufgrund der wiederholten Lernprozesse und der Kreuzvalidierung ist die Wrapper-Technik jedoch rechenaufwändiger als die Filtermethode.
Was ist sequenzielle Vorwärtsauswahl beim maschinellen Lernen?
Es ist eine Art sequentielle Merkmalsauswahl, obwohl es viel kostspieliger ist als die Filterauswahl. Es handelt sich um eine gierige Suchtechnik, die Merkmale basierend auf der Klassifikatorleistung iterativ auswählt, um die ideale Teilmenge von Merkmalen zu ermitteln. Es beginnt mit einer leeren Feature-Teilmenge und fügt in jeder Runde ein Feature hinzu. Dieses eine Feature wird aus einem Pool aller Features ausgewählt, die nicht in unserer Feature-Teilmenge enthalten sind, und es ist dasjenige, das in Kombination mit den anderen zur besten Klassifikatorleistung führt.
Welche Einschränkungen gibt es bei der Verwendung der Filtermethode für die Funktionsauswahl?
Der Filteransatz ist rechnerisch weniger aufwendig als die Wrapper- und Embedded-Feature-Selection-Methoden, hat aber einige Nachteile. Im Fall von univariaten Ansätzen ignoriert diese Strategie häufig die gegenseitige Abhängigkeit von Merkmalen, während sie Merkmale auswählt, und wertet jedes Merkmal unabhängig voneinander aus. Im Vergleich zu den anderen beiden Methoden der Merkmalsauswahl kann dies manchmal zu einer schlechten Rechenleistung führen.